[大语言模型-论文精读] ACL2024-长尾知识在检索增强型大型语言模型中的作用
ACL2024-长尾知识在检索增强型大型语言模型中的作用

On the Role of Long-tail Knowledge in Retrieval Augmented Large Language Models
Authors: Dongyang Li, Junbing Yan, Taolin Zhang, Chengyu Wang, Xiaofeng He, Longtao Huang, Hui Xue, Jun Huang
1.概览

问题解决:
这篇论文研究了在大型语言模型(LLMs)中,如何通过检索增强生成(RAG)技术来提升模型对长尾知识(long-tail knowledge)的处理能力。长尾知识指的是那些在大规模预训练中不常见,但在实际应用中又非常重要的知识。论文指出,尽管RAG技术能够通过检索相关文档来增强LLMs的回答质量,但它通常不加区分地增强所有查询,而忽略了LLMs真正需要的长尾知识。
研究成果:
研究者提出了一种基于生成预期校准误差(Generative Expected Calibration Error, GECE)的方法来检测长尾知识,并只在查询涉及长尾知识时才进行文档检索和知识融合。实验结果表明,与现有的RAG流程相比,该方法在平均推理时间上实现了超过4倍的加速,并且在下游任务中性能得到了一致性提升。
2. 研究背景
技术背景:
大型语言模型(LLMs)在自然语言处理(NLP)领域取得了显著的成就,但它们在处理长尾知识时仍然存在挑战。RAG技术通过检索补充知识并将其注入模型来增强LLMs的生成能力,但这种方法往往忽略了对长尾知识的特别关注。
发展历史:
RAG技术的发展可以追溯到早期的检索-生成模型,随着深度学习技术的进步,尤其是Transformer架构的出现,RAG技术得到了快速发展。近年来,研究者们开始关注如何更有效地利用RAG技术来提升LLMs在特定任务上的表现。
3. 技术挑战
困难:
- 知识冗余: 在预训练阶段,LLMs已经学习了大量的通用知识,RAG技术在处理常见知识时可能会导致计算资源的浪费。
- 长尾知识检测: 如何有效地检测和区分LLMs在处理查询时是否需要长尾知识是一个挑战。
- 效率与性能的平衡: 在提升模型性能的同时,如何保持或提升推理效率是一个关键问题。
4. 破局方法
解决方法:
- GECE指标: 论文提出了一种新的指标GECE,结合了统计学和语义学的方法来衡量知识的“长尾性”, 通过METEOR分数和LLMs生成文本的平均token概率来计算。
- 长尾知识检测: 使用GECE值来检测输入查询是否涉及长尾知识。
- 选择性增强: 改进的RAG流程, 只有当查询涉及长尾知识时,才进行文档检索和知识融合,从而提高了推理效率。
ECE:
ECE = ∑ i = 1 B n b i N ∣ a c c ( b i ) − c o n f ( b i ) ∣ \text{ECE} = \sum_{i=1}^{B}\frac{n_{b_i}}{N}|acc(b_i) - conf(b_i)| ECE=i=1∑BNnbi∣acc(bi)−conf(bi)∣
GECE:
GECE = ∣ M ( p r e d , r e f ) − 1 n ∑ i = 1 n p ( t i ) ∣ α ⋅ [ E ( ▽ i n s ) ⋅ ▽ i n s ] \text{GECE} = \frac{|M(pred, ref) - \frac{1}{n}\sum_{i=1}^{n}p(t_i)|}{\alpha \cdot [E({\bigtriangledown_{ins}) \cdot {\bigtriangledown}_{ins}}]} GECE=α⋅[E(▽ins)⋅▽ins]∣M(pred,ref)−n1∑i=1np(ti)∣
这里 ▽ i n s {\bigtriangledown_{ins}} ▽ins是当前实例的梯度, E ( ▽ i n s ) E({\bigtriangledown_{ins}}) E(▽ins)是整个数据集的平均梯度。
5. 技术应用
实验设置:
- 使用了NQ、TriviaQA和MMLU等数据集进行实验。
- 与多个基线模型进行了比较,如Llama2-7B、IRCoT、SKR等。
- 实验中考虑了不同数量的增强文档(10、15、20篇)对性能的影响。
**实验效果: **
- NQ数据集:使用GECE后,Rouge-1和Bleu-4指标分别达到了42.9和43.7,平均推理速度提升了2.1倍。
- TriviaQA数据集:使用GECE后,Rouge-1和Bleu-4指标分别达到了24.8和24.0,平均推理速度提升了2.2倍。
- MMLU数据集:使用GECE后,准确率提升到了85.9%,推理速度提升了2.4倍。


结论:
通过GECE过滤数据后,所有基线模型的处理速度都有所提升,特别是迭代方法(如ITER-RETGEN和IRCoT)显著加速。此外,通过引入较少的普通实例噪声,还提升了任务性能。
潜在应用:
- 问答系统: 提升问答系统在处理长尾问题时的准确性和效率。
- 知识检索: 在需要精确知识检索的场景下,如法律、医疗等领域,提高检索的准确性。
- 教育辅助: 在教育领域,帮助学生快速准确地获取稀有或专业性知识。
6. 主要参考工作
- ECE相关研究: 如Aimar等人在2023年的工作,提供了校准误差的新视角。
- RAG技术: 如Borgeaud等人在2022年的研究,探讨了通过检索增强预训练语言模型的方法。
- 长尾知识处理: 如Kandpal等人在2023年的研究,讨论了LLMs在长尾知识学习上的挑战。
- METEOR评估: Banerjee和Lavie在2005年提出的评估机器翻译质量的方法,被用于GECE指标中。
如果您对我的博客内容感兴趣,欢迎三连击(点赞,关注和评论),我将持续为您带来计算机人工智能前沿技术(尤其是AI相关的大语言模型,深度学习,计算机视觉相关方向)最新学术论文及工程实践方面的内容分享,助力您更快更准更及时地了解前沿技术的发展现状。
相关文章:
[大语言模型-论文精读] ACL2024-长尾知识在检索增强型大型语言模型中的作用
ACL2024-长尾知识在检索增强型大型语言模型中的作用 On the Role of Long-tail Knowledge in Retrieval Augmented Large Language Models Authors: Dongyang Li, Junbing Yan, Taolin Zhang, Chengyu Wang, Xiaofeng He, Longtao Huang, Hui Xue, Jun Huang 1.概览 问题解决&…...

“迷茫野路子到AI大模型高手:一张图解产品经理晋升之路和能力构建“
前言 在探寻成功之路上,若你向20位业界顶尖的产品经理或运营专家请教,他们可能会向你展示一条条各异的路径,正如那句古老的格言:“条条大路通罗马”。但是,我们必须认识到,这些路径虽多,却并非…...
可看见车辆行人的高清实时视频第2辑
我们在《看见车辆行人的高清实时视频第2辑》分享了10处可看见车辆行人的实时动态高清视频。 现在我们又整理10处为你分享可看见车辆行人的实时动态高清视频,一共有30个摄像头数据,这些视频来自公开的高清摄像头实时直播画面。 我们在文末为你分享了这些…...

基于饥饿游戏搜索优化随机森林的数据回归预测 MATLAB 程序 HGS-RF
1. 引言 随着人工智能和机器学习的飞速发展,回归预测在各个领域得到了广泛应用。回归模型用于预测连续变量的值,如金融市场的价格走势、气象预报中的温度变化等。本文提出了一种基于**饥饿游戏搜索(Hunger Games Search, HGS)优化…...

一天面了8个Java后端,他们竟然还在背5年前的八股文!
今天面了8个Java候选人,在面试中我发现他们还停留在面试背八股文的阶段,5年前面试背八股文没问题,随着市场竞争越来越激烈,再问普通的Java八股文已经没有意义了,因为考察不出来获选人的真实实力! 现在面试…...

python功能测试
文章目录 unnittest1. 基本结构2. 常用断言方法3. 测试生命周期方法4. 跳过测试5. 运行测试 pytest1. 基本测试用法2. 安装 pytest3. 运行测试4. 使用 assert 断言5. 异常测试6. 参数化测试7. 测试前后设置8. 跳过测试和标记失败9. 测试夹具 (Fixtures)10. 生成测试报告11. 插件…...
-三语言题解)
【秋招笔试】09.25华子秋招(已改编)-三语言题解
🍭 大家好这里是 春秋招笔试突围,一起备战大厂笔试 💻 ACM金牌团队🏅️ | 多次AK大厂笔试 | 大厂实习经历 ✨ 本系列打算持续跟新 春秋招笔试题 👏 感谢大家的订阅➕ 和 喜欢💗 和 手里的小花花🌸 ✨ 笔试合集传送们 -> 🧷春秋招笔试合集 🍒 本专栏已收集…...

【中级通信工程师】终端与业务(四):通信产品
【零基础3天通关中级通信工程师】 终端与业务(四):通信产品 本文是中级通信工程师考试《终端与业务》科目第四章《通信产品》的复习资料和真题汇总。终端与业务是通信考试里最简单的科目,有效复习通过率可达90%以上,本文结合了高频考点和近几…...

数据科学 - 字符文本处理
1. 字符串的基本操作 1.1 结构操作 1.1.1 拼接 • 字符串之间拼接 字符串之间的拼接使用进行字符串的拼接 a World b Hello print(b a) • 列表中的字符串拼接 将以分隔符‘,’为例子 str [apple,banana] print(,.join(str)); • 字符串中选择 通过索引进行切片操…...

python之装饰器、迭代器、生成器
装饰器 什么是装饰器? 用来装饰其他函数,即为其他函数添加特定功能的函数。 装饰器的两个基本原则: 装饰器不能修改被装饰函数的源码 装饰器不能修改被装饰函数的调用方式 什么是可迭代对象? 在python的任意对象中ÿ…...

Go语言实现后台管理系统如何根据角色来动态显示栏目
实现要点 根据不同的用户显示不同的栏目是后台管理的重要内容,那么如何实现这些功能呢? 栏目有很多分级这些需要递归查出来新增和删除也要满足层级规则且不影响其他层级各节点之间的关系因该明确,方便添加和删除数据库设置 存储栏目的数据库设计,要明确节点的关系最常用的…...

【深度学习】【TensorRT】【C++】模型转化、环境搭建以及模型部署的详细教程
【深度学习】【TensorRT】【C】模型转化、环境搭建以及模型部署的详细教程 提示:博主取舍了很多大佬的博文并亲测有效,分享笔记邀大家共同学习讨论 文章目录 【深度学习】【TensorRT】【C】模型转化、环境搭建以及模型部署的详细教程前言模型转换--pytorch转engineWindows平台搭…...

LeetCode(Python)-贪心算法
文章目录 买卖股票的最佳时机问题穷举解法贪心解法 物流站的选址(一)穷举算法贪心算法 物流站的选址(二)回合制游戏快速包装 买卖股票的最佳时机问题 给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。如果你…...

【C/C++】【基础数论】33、算数基本定理
算术基本定理,又称正整数的唯一分解定理。 说起来比较复杂,但是看一下案例就非常清楚了 任何一个大于 1 的正整数都可以唯一地分解成有限个质数的乘积形式,且这些质数按照从小到大的顺序排列,其指数也是唯一确定的。 例如&#…...
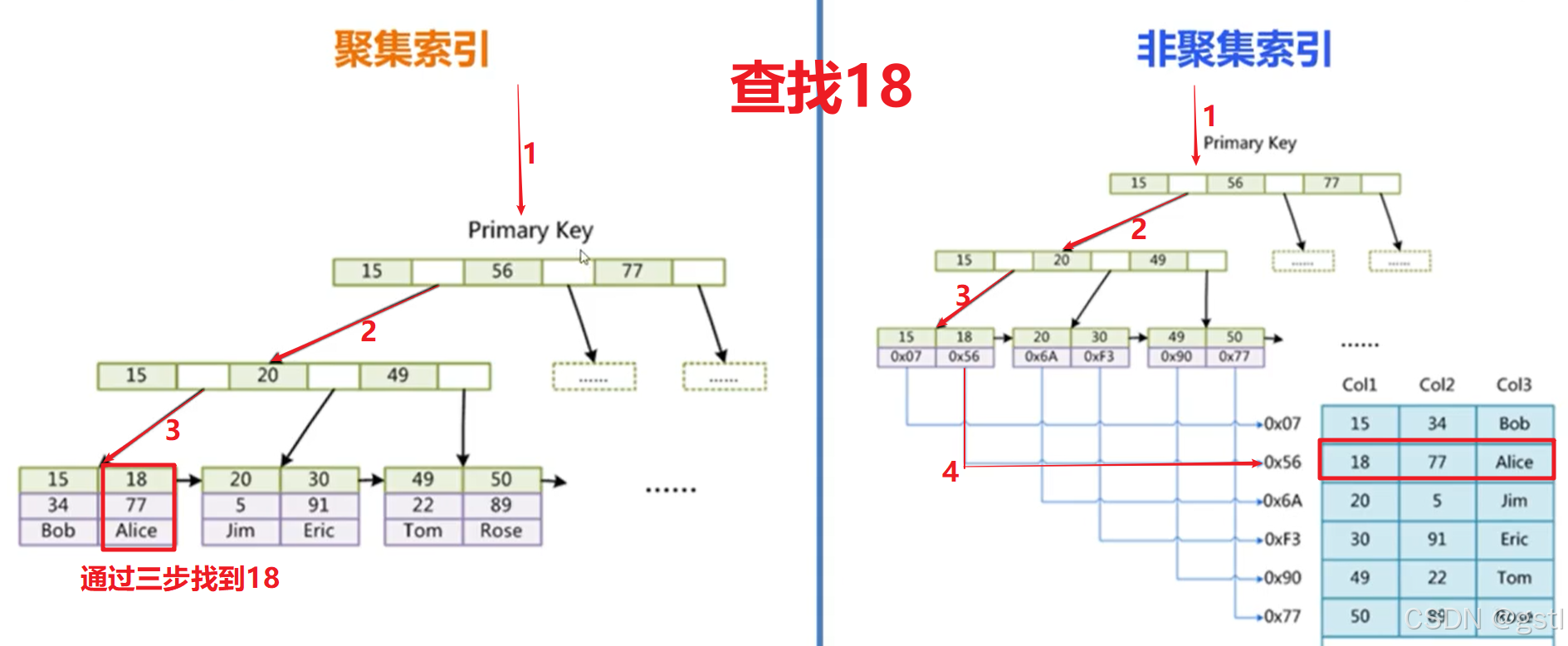
聚簇索引与非聚簇索引
物理存储方式不同: 1. InnoDb默认数据结构是聚簇索引;MyISAM 是非聚簇索引 2. 聚簇索引 中表索引与数据是在一个文件中 .ibd;非聚簇索引中表索引(.MYI)与数据(.MYD)是在两个文件中 3. 聚簇索引中表数据行都存放在索引树…...

“类型名称”在Go语言规范中的演变
Go语言规范(The Go Programming Language Specification)[1]是Go语言的核心文档,定义了该语言的语法、类型系统和运行时行为。Go语言规范的存在使得开发者在实现Go编译器时可以依赖一致的标准,它确保了语言的稳定性和一致性&#…...

c++----继承(初阶)
大家好呀,今天我们也是多久没有更新博客了,今天来讲讲我们c加加中的一个比较重要的知识点继承。首先关于继承呢,大家从字面意思看,是不是像我们平常日常生活中很容易出现的,比如说电视剧里面什么富豪啊,去了…...
常见的四种非关系型数据库(NoSQL))
数据库系列(1)常见的四种非关系型数据库(NoSQL)
非关系型数据库(NoSQL) 非关系型数据库适用于需要灵活数据模型和高可扩展性的场景。常见的非关系型数据库包括: MongoDB:文档数据库,以JSON-like格式存储数据,适合快速开发和迭代。Cassandra:…...

大规模预训练语言模型的参数高效微调
人工智能咨询培训老师叶梓 转载标明出处 大规模预训练语言模型(PLMs)在特定下游任务上的微调和存储成本极高,这限制了它们在实际应用中的可行性。为了解决这一问题,来自清华大学和北京人工智能研究院的研究团队探索了一种优化模型…...

一场大模型面试,三个小时,被撞飞了
去华为面试大模型,一点半去五点半回,已经毫无力气。 1️⃣一轮面试—1小时 因为一面都是各个业务的主管,所以专业性很强,面试官经验很丰富,建议大家还是需要十分熟悉所学内容,我勉强通过一面。 2️⃣二轮…...
)
告别手动复制粘贴!用Matlab脚本一键搞定A2L与ELF文件合并(附完整.m文件)
汽车电控标定工程师的自动化利器:Matlab脚本实现A2L与ELF文件智能合并 在汽车电子控制单元(ECU)开发过程中,标定工作是不可或缺的关键环节。传统的手动操作方式不仅效率低下,还容易引入人为错误。本文将详细介绍如何利…...

Proxmark3GUI图形化工具:5分钟学会RFID卡片分析与数据管理
Proxmark3GUI图形化工具:5分钟学会RFID卡片分析与数据管理 【免费下载链接】Proxmark3GUI A cross-platform GUI for Proxmark3 client | 为PM3设计的跨平台图形界面 项目地址: https://gitcode.com/gh_mirrors/pr/Proxmark3GUI Proxmark3GUI是一款为Proxmar…...

Golang怎么实现HTTP请求取消_Golang如何用context取消正在进行的HTTP请求【实战】
HTTP客户端默认不取消请求是设计选择,需显式通过context.Context传递取消信号;必须用NewRequestWithContext、禁用Client.Timeout、确保Transport组件响应同一ctx。为什么 http.Client 默认不取消请求?Go 的 http.Client 本身不自动响应外部中…...
)
【2026最新】应对维普算法升级,5大降AI工具横测,一次稳降至25%(附手改秘籍)
知网和维普的AIGC检测系统又更新了! 在当下的关口,如何在不牺牲质量的前提下,优化初稿表达,安全地降低AI痕迹,成了所有小伙伴们必须解决的一个问题。网络上各种“降AI神器”铺天盖地,这些工具到底靠不靠谱…...

DLSS Swapper终极指南:一键切换游戏超采样版本,免费提升帧率30%+
DLSS Swapper终极指南:一键切换游戏超采样版本,免费提升帧率30% 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 你是否曾羡慕别人在《赛博朋克2077》里享受丝滑流畅的画面,而你的游戏…...

柔性LED灯丝DIY:从电路原理到创意饰品制作全攻略
1. 项目概述:当生日遇上柔性LED灯丝给孩子的生日派对准备一份独一无二的、会发光的惊喜,是很多家长和手工爱好者的心愿。这次,我们不买现成的塑料灯牌,而是亲手做一个能戴在头上或挂在脖子上的“生日数字灯冠”。这个项目的核心&a…...

智能路由器项目解析:基于策略路由实现多线路流量智能调度
1. 项目概述:一个“聪明”的路由器能做什么?最近在GitHub上看到一个挺有意思的项目,叫smart-router,作者是c0nSpIc0uS7uRk3r。光看名字,你可能会觉得这又是一个关于家庭网络优化的工具,但点进去仔细研究后&…...

LVGUI字体瘦身实战:如何为你的IoT设备定制一个超小的中文字体库
LGVUI字体瘦身实战:为IoT设备定制超小中文字体库的工程化解决方案 在嵌入式物联网设备开发中,每一KB的Flash和RAM都弥足珍贵。当你的智能温控器需要显示"当前温度:25℃"或者电子秤要呈现"净重:0.5kg"时&#…...

Touchpoint:命令行工具集中管理工作上下文,提升开发效率
1. 项目概述:一个被低估的开发者效率工具如果你和我一样,日常开发工作需要在多个代码仓库、项目管理工具(如Jira、Linear)、文档平台(如Confluence、Notion)和沟通软件(如Slack)之间…...

完整实战指南:使用N_m3u8DL-RE高效解决流媒体下载难题
完整实战指南:使用N_m3u8DL-RE高效解决流媒体下载难题 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE …...