LeetCode(Python)-贪心算法
文章目录
- 买卖股票的最佳时机问题
- 穷举解法
- 贪心解法
- 物流站的选址(一)
- 穷举算法
- 贪心算法
- 物流站的选址(二)
- 回合制游戏
- 快速包装
买卖股票的最佳时机问题
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。如果你最多只允许完成一笔交易(即买入和卖出一支股票),设计一个算法来计算你所能获取的最大利润。
注意你不能在买入股票前卖出股票。
示例 1:
输入 : [7, 1, 5, 3, 6, 4]
输出 : 5
解释 : 在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,
最大利润 = 6 - 1 = 5 。
注意利润不能是 7 - 1 = 6, 因为卖出价格需要大于买入价格。
示例 2 :
输入 : [7, 6, 4, 3, 1]
输出 : 0
穷举解法
对所有可能的买入和卖出时机进行遍历,并记录最大差值。
prices = [7, 1, 5, 3, 6, 4]
def find_max(prices):if len(prices) <2:return "长度不够"max_profit = 0for i in range(len(prices)):for j in range(i+1,len(prices)):if (prices[j]-prices[i])>max_profit:max_profit=prices[j]-prices[i]return max_profit
print(find_max(prices))
贪心解法
最贪心的投资方案显然是在低价时买人,高价时卖出。是找到一个波峰和一个波谷,且波峰在波谷之后出现,使波峰和波谷在竖功方向上的差别最大,这样一来,在波谷处买人,在波峰处卖出,赚取的差价最大。
假设我们要在第i天卖出,那么就要在前-1天中的某一天买人,贪心地考虑,当我们在前i-1天中以最低价买人时,赚的钱最多,这正是当前最好的方案。所以可以只遍历卖出的时间,买入的价格就是卖出前的最低价。与“暴力的穷举算法相比,这样的贪心算法把时间复杂度从0(n*2)了降低到了0(n)。
prices = [7, 1, 5, 3, 6, 4]
def find_max(prices):if len(prices) <2:return "长度不够"max_profit = 0min_price=prices[0]for i in range(len(prices)):if prices[i]-min_price>max_profit:max_profit=prices[i]-min_priceif prices[i]<min_price:min_price=prices[i]#维护一个最小值return max_profit
print(find_max(prices))
物流站的选址(一)
小余的家乡共有n个地方可以建设物流站。每一个物流站都只能对附近直线距离为ai的区域(包括边界)中的居民点进行配送,另外,小余的家乡有m个居民点需要提供物流配送服务。
小余作为一个关心家乡的老板,既要满足所有居民的需求(即每个居民点至少有一个可以提供服务的物流站),又要保障公司的利益(即建立较少的物流站),小余必须担任物流站选址规划的重任,要计算最小需要建设多少物流站才能服务到每一个居民点。
为了简化问题,物流站和居民点都可以看作二维平面上的点,物流站和居民点之间的距离就是两点之间的直线距离。
数据 n=4,表示物流站选址的个数。m=9附近居民点的个数。
接下来表示每个物流站选址的坐标和配送范围
2,1,2;-3,0,3;-1,0,2;2,-1,3。
每个居民点的坐标
1,2;-4,1;-1,1;1,1;-2,0;2,0;3,0;-1,-1;-3,-2。
穷举算法
一共有4个地址,每个地址要么被选择作为物流站,要么否。一共只有16种方案,可穷举。(用二进制表示方案)
import numpy as np
import math
n=4#物流站地址个数
m=9#居民点个数
X=[2,-3,-1,2] #物流站地址横坐标
Y=[1,0,0,-1]#物流站地址纵坐标
a=[2,3,2,3]#物流站地址配送距离
u=[1,-4,-1,1,-2,2,3,-1,-3]#居民点横坐标
v=[2,1,1,1,0,0,0,-1,-2]#居民点纵坐标flag=[False for i in range(m)] #标记每个居民点是否被覆盖
#判断物流站i能否服务居民点j
def can_serve(i,j):return (X[i]-u[j])*((X[i]-u[j]))+(Y[i]-v[j])*(Y[i]-v[j])<=a[i]*a[i]max_s=np.power(2,n)#总方案数 ,2的n次方 用二进制表示方案[0,0,0,0]=0 [0,0,0,1]=1,1表示可选def ten_two(max_s,num):"""将num转换为二进制:param max_s: 方案总数:param num: 当前方案代码 且num<max_s:return:"""result = [0 for i in range(int(math.log(max_s,2)))] #二进制初始化num_two = bin(num) # 将num转换为二进制 如5结果为0b101num_two = str(num_two[2:]) # 去除0b 格式为字符geshu = int(len(result)) - int(len(num_two))result1 = [0 for i in range(geshu)]result1.extend([int(i) for i in num_two])return result1def solve():ans=n#初始化结果为nbests=0 #最优方案for s in range(max_s):#遍历每个方案station=0 #当前方案的物流站个数for j in range(m):#遍历每个居民点flag[j]=Falsetemp=ten_two(max_s,s) #当前方案二进制for i in range(len(temp)): # 遍历每个方案选址if temp[i]==1:station += 1# 将物流站i服务范围内的每个居民点打上标志for j1 in range(m):if can_serve(i,j1):flag[j1]=True# 判断当前方案能否覆盖每个居名点,并更新答案num = 0for j2 in range(m):if flag[j2]:num += 1if num == m:if station<ans:ans=stationbests=sreturn ans,ten_two(max_s,bests) # 最优选址个数,最优选址方案ans,best=solve()
print("最优选址个数:",ans)
print("最优选址方案:",best)

贪心算法
既然要覆盖每一个居民点,那么每次都要尽可能多地覆盖几个居民点,这正是贪心算法的核心思想。
步骤如下:
(1)选一个包含最多未覆盖的居民点的物流站站址,在此处新建物流站。
(2)重复步骤(1),直到所有居民点都被覆盖。
贪心算法在这个样例中恰好得到了最优解,但正如前面提到的,根本不存在解决这个问题的快速解法,贪心算法计算出的结果不一定是最优解,但这个解不会太差。
n=4#物流站地址个数
m=9#居民点个数
X=[2,-3,-1,2] #物流站地址横坐标
Y=[1,0,0,-1]#物流站地址纵坐标
a=[2,3,2,3]#物流站地址配送距离
u=[1,-4,-1,1,-2,2,3,-1,-3]#居民点横坐标
v=[2,1,1,1,0,0,0,-1,-2]#居民点纵坐标flag=[False for i in range(m)] #标记每个居民点是否被覆盖
#判断物流站i能否服务居民点j
def can_serve(i,j):return (X[i]-u[j])*((X[i]-u[j]))+(Y[i]-v[j])*(Y[i]-v[j])<=a[i]*a[i]new_num=[0 for i in range(n)]#每个选址覆盖的居民点数初始化为0best=[0 for i in range(n)] #初始化最优选址
def solve():num=0 #当前覆盖的居民点个数station=0#需要建造的物流站个数while(num<m):#遍历每一个居民#选一个包含最多未被覆盖的居名点的物流站,将它作为一个修建点new_station=0for i in range(n):#遍历每一个选址new_num[i]=0#i选址覆盖的居民点数初始化为0for j in range(m):#遍历每一个居民点if flag[j]==False and can_serve(i,j):new_num[i]+=1if new_num[i]>new_num[new_station]:new_station=ibest[new_station]=1 #当前的选址索引#在该处新建物流站,更新相关变量for j in range(m):##遍历每一个居民点if flag[j]==False and can_serve(new_station,j):flag[j]==Truenum+=1station+=1return station,best #个数 、方案
station,best=solve()
print("最优选址个数:",station)
print("最优方案:",best)

物流站的选址(二)
小算为了扩大物流运输服务的范围,打算开辟一条新的物流运输线路,这条线路可以认为是数轴上长度为L的线段,在坐标0,1,工上有L+1个居民点,需要在其中若干个居民点建设物流站,每一个物流站都只能对线路上直线距离a以内的区域(含边界)提供服务。这条物流运输线路很长,并非每个居民点都可以建设物流站,但为了满足长距离运输的需求,线路上每一个居民点都必须在服务范围内,现在小算需要重新考虑物流站选址的问题,如图所示。

数据格式
n=4,表示物流站选址的个数
L=8表示物流运输线路的长度
接下来的n行,每行有2个整数Xi,ai。表示第i个物流站选址的坐标和服务距离
4,3;
1,1;
6,2;
2,2;
以样例为例,如果按照前一个问题中的贪心的思路,每次尽可能增加服务范围,结果如图。

但是,最优解显然不需要三个物流站,两个就够了。

这个例子再次说明了用贪心算法的思想解决问题时只考虑眼前利益并不一定能得到最优解。现在换一种贪心算法的思路,从最左侧开始,每次在左侧尽可能增加服务范围,这样的思路恰好得到了最优解。同样是贪心算法,为什么这个思路就可以得到最优解呢?下面来分析原因。
首先要注意的是,物流站的选址规划与顺序无关,所以从左侧开始和从右侧
开始建设物流站都可以。
考虑最左侧的居民点0,能覆盖到这个点的物流站有两个,分别位于位置1和位置2,这两个物流站至少要建一个,当前看来,位于位置2的物流站更优,因为它可以覆盖更多居民点。对于整个方案来说,如果选择在位置1建设物流站,那么还需要覆盖{3,4,5,6,7,8}居民点,如果选择在位置2建设物流站,那么还需要覆盖{5,6,7,8}居民点,是前者的子集。所以选择在位置2建设物流站对于整个方案来说是最优的选择。
未被覆盖的居民点5,也用类似的思路分析,在位置4和位置6中选择,左侧增加的服务范围越大,剩余需要覆盖的居民点越少,这种贪心的思路可以保证每一步决策都是全局最优的。
n=4#物流站地址个数
L=8#物流运输线路的长度
X=[4,1,6,2]#Xi表示第i个物流站选址的坐标
a=[3,1,2,2]#ai。表示第i个物流站选址的服务距离
best=[]#存放最优物流站选址的坐标索引
def Solve():r=0#当前未覆盖的最左侧的居民点num=0#物流站数量while(r<=L):# 寻找下一个物流站选址nex=-1for i in range(n):if (X[i]-a[i]<=r) and (r<=X[i]+a[i]):if nex==-1 or X[nex]+a[nex]<X[i]+a[i]: #居民点i比nex更优nex=ibest.append(nex)#如果没有任何物流站可以覆盖坐标r的居民点,返回--1if nex==-1:return -1#更新r和numr=X[nex]+a[nex]+1num+=1return num,bestprint(Solve())
既然这种贪心算法的思路可以得到全局最优解,那么为什么在前面的二维平面建物流站时,不能用贪心算法得到最优解呢?因为二维比一维要复杂得多,比较两个物流站选址的优劣时,关键是要比较决策后仍需解决的问题,这在二维平面中是很困难的。
例如在图中,要比较物流站选址1和物流站选址3,在物流站选址1及建立物流站后,还需要再覆盖居民点{(1,2),(1,1),(2,0),(3,0)},在物流站选址3处建立物流站后,还需要再覆盖居民点{(1,2),(-4,1),(-1,1),(-2,0),(-3,-2)},这两个集之间没有包含或被包含的关系,也就没办法直接判断两种决策的优劣。

回合制游戏
小余回到家里,打开计算机,开始玩一个回合制游戏。在该回合制游戏中,小余扮演勇者,在前往拯救公主的路上,魔王派出了n只怪物阻挡勇者的前进,每个怪物都有一定的血量(游戏人物的生命值)hi和攻击力ai。
每个回合中,首先所有未被打败的怪物会一哄而上攻击小余扮演的勇者,第i只怪物会造成ai点的伤害,勇者受到的伤害等于每个怪物造成的伤害总和。
当然,勇者也会攻击,勇者一次只能选择其中一只怪物进行攻击,第i个怪物需要攻击hi次才能被打败。
勇者不能逃避,必须选择攻击,现在用算法采取最优决策,规划攻击每个怪物的顺序,计算出勇者打败所有怪物时受到的最小伤害。
数据格式
n=5表示5个怪物。
a=[1,3,2,6,3],ai表示第i个怪物每回合可造成ai的伤害。
h=[9,4,2,3,3],hi表示第i个怪物需要hi回合才能被打败。
思路:
如果只有一只怪物,打败它需要h0回合,每回合受到a0的伤害,总共受到的伤害就是a0*h0。
如果有两只怪物,其中一只a0=2,h0=2,另一只a1=3,h1=4。
- 从怪物攻击力的角度考虑,第2只怪物的攻击力更大,每回合对勇者的伤害更大,所以要优先打败第2只怪物。
- 从回合数的角度考虑,打败第2只怪物需要的回合数更多,这意味着,如果先打败第2只怪物,则第1只怪物对勇者造成伤害的回合数会更多,所以优先打败第1只怪物。
两只怪物判断函数如下
n=5 #怪物数量
a=[1,3,2,6,3]#ai表示第i个怪物每回合可造成ai的伤害。
h=[9,4,2,3,3]#hi表示第i个怪物需要hi回合才能被打败。def compare(num1,num2):"""判断怪物num1,num2应该优先打败谁:param num1: 怪物1位置索引:param num2: 怪物2位置索引:return:"""#计算先打败怪物num1时受到的伤害damage1=(a[num1]+a[num2])*h[num1]+a[num2]*h[num2]# 计算先打败怪物num2时受到的伤害damage2 = (a[num1] + a[num2]) * h[num2] + a[num1] * h[num1]#比较两个伤害,决定先打败那一只怪物if damage1<damage2:print("damage1:",damage1)print("damage2:",damage2)return Trueelse:print("damage1:", damage1)print("damage2:", damage2)return False
print(compare(0,1))

有两只怪物时应该如何攻击的问题解决了,那么有n只怪物呢?此时需要一个排序算法。本题的解法本质就是一个自定义排序(只是传统的直接比较数字大小变成了用compare(num1,num2)比较)
n=5 #怪物数量
a=[1,3,2,6,3]#ai表示第i个怪物每回合可造成ai的伤害。
h=[9,4,2,3,3]#hi表示第i个怪物需要hi回合才能被打败。def compare(num1,num2):"""判断怪物num1,num2应该优先打败谁:param num1: 怪物1位置索引:param num2: 怪物2位置索引:return:"""#计算先打败怪物num1时受到的伤害damage1=(a[num1]+a[num2])*h[num1]+a[num2]*h[num2]# 计算先打败怪物num2时受到的伤害damage2 = (a[num1] + a[num2]) * h[num2] + a[num1] * h[num1]#比较两个伤害,决定先打败那一只怪物if damage1<damage2:return Trueelse:return False
#print(compare(1,2)) #False#====排序===
def sortArray(n,a,h):"""快速排序:param n:n=5 #怪物数量:param a: a=[1,3,2,6,3]#ai表示第i个怪物每回合可造成ai的伤害。:param h: h=[9,4,2,3,3]#hi表示第i个怪物需要hi回合才能被打败。:return:"""# selection sortnums=[i for i in range(n)] #怪物位置索引for i in range(n):for j in range(i,n):if compare(i,j):#如果应该优先打败怪物ipasselse:#如果应该优先打败怪物j。则j和i位置变换nums[i],nums[j] = nums[j],nums[i]a[i], a[j] = a[j], a[i]#攻击交换h[i], h[j] = h[j], h[i] # 回合交换return numsnums=sortArray(n,a,h)
print("排序结果:",nums)#[3, 4, 2, 1, 0]
#计算勇者受到的总伤害
damage=0
round=0
for i in range(n):round+=nums[i]*h[i]#回合数增加damage+=round*a[i]print("总伤害:",damage)

快速包装
小余在物流站建立一套自动化快递打包系统。只需要把快递摆放在传送带上,传送带就会自动将货物运输到打包机械臂下方,打包机械臂会根据货物调整到合适的大小,只需要1min就可以完成一件快递的打包工作。等机械臂打包完成后,传送带才会慢慢移动,送来下一件货物。
每件快递大小不一,并已知每件快递的高度和长度。打包台会依次对传送带上的每件快递进行打包,特别地,如果后一件快递的高度和长度分别都不大于当前快递的高度和长度,那么机械臂打包完当前的快递后不需要调整即可立即对后一件快递进行打包,否则需要1min来做调整,此外,第1件快递打包时也需要花时间调整。小余想要尽可能提高打包效率,请你计算最少需要多久才能完成打包。

输入格式
n=6 表示快递的数量
L=[8,5,7,4,5,3] 。Li表示第 i件快递的高度。
W=[8,7,6,4,7,7]。Wi表示第i件快递的长度。
思路:每件快递打包需要的时间都是1min,所以需要缩短打包做调整的时间,可以再进一步,把这些快递分到若干个队列中,再对每个队列中的快递打包时,打包只需在队首做一次调整,需要用最少的队列容纳所有的快递。
1 在每个队列中,队首的高度和长度最大,后续每个货物都比前一个相等或者小。
2 用最少的队列。

方案如下
先把货物排序,然后进行如下
(1)如果没有任何队列可以容纳某快递,那么就新建一个队列容纳它。
(2)如果有队列都能容纳该快递,那么一定不要新建队列。
(3)如果有多个队列可以容纳这件快递,那么把它放在最早出现的队列末尾。
#快递结构体
class kuaidi:def __init__(self,Li,Wi):self.L=Li #快递高度self.W=Wi#快递长度n=6 #表示快递的数量
L=[8,5,7,4,5,3] #Li表示第 i件快递的高度。
W=[8,7,6,4,7,7]#Wi表示第i件快递的长度
lis=[] #快递结构题数组
for i in range(n):lis.append(kuaidi(L[i],W[i]))def compare_parkage(a,b):"""比较两个快递 。先比较高度再比较长度:param a:快递1:param b:快递2:return:"""if a.L!=b.L:#快递1高度是否大于快递2return a.L>b.Lelse: #否则比较长度return a.W > b.W# ====排序===def sortArray(n, lis):"""根据问题自定义快速排序:param n: 表示快递的数量:param lis: #快递结构题数组:return:"""for i in range(n):for j in range(i, n):if compare_parkage(lis[i], lis[j]): # 如果快递i 快递j 比较passelse:# 则j和i位置变换lis[i], lis[j]=lis[j], lis[i]return lis
lis1=sortArray(n,lis) #排序后的快递组
for i in range(n):print("第%d个快递,高度为%d,长度为%d"%(i,lis[i].L,lis[i].W))#==============构建队列=============
queue_num=0 #队列数量初始化为0
tail=[] #初始化每个队列的队尾,最多n个队尾
for i in range(n):tail.append(kuaidi(Li=0,Wi=0))for i in range(n):#遍历每个快递flag=Truefor j in range(queue_num):#遍历每个队列#找到最早出现的能容纳这件快递的队列if (tail[j].L>=lis1[i].L) & (tail[j].W>=lis1[i].W):tail[j]=lis1[i]flag=Falsebreak#如果没有找到能容纳这件快递的队列,则新建一个队列if flag:tail[queue_num]=lis1[i]queue_num+=1
print("--------------结果-----------------")
print("队列数量:%d,快递数量:%d"%(queue_num,n))


相关文章:
LeetCode(Python)-贪心算法
文章目录 买卖股票的最佳时机问题穷举解法贪心解法 物流站的选址(一)穷举算法贪心算法 物流站的选址(二)回合制游戏快速包装 买卖股票的最佳时机问题 给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。如果你…...

【C/C++】【基础数论】33、算数基本定理
算术基本定理,又称正整数的唯一分解定理。 说起来比较复杂,但是看一下案例就非常清楚了 任何一个大于 1 的正整数都可以唯一地分解成有限个质数的乘积形式,且这些质数按照从小到大的顺序排列,其指数也是唯一确定的。 例如&#…...
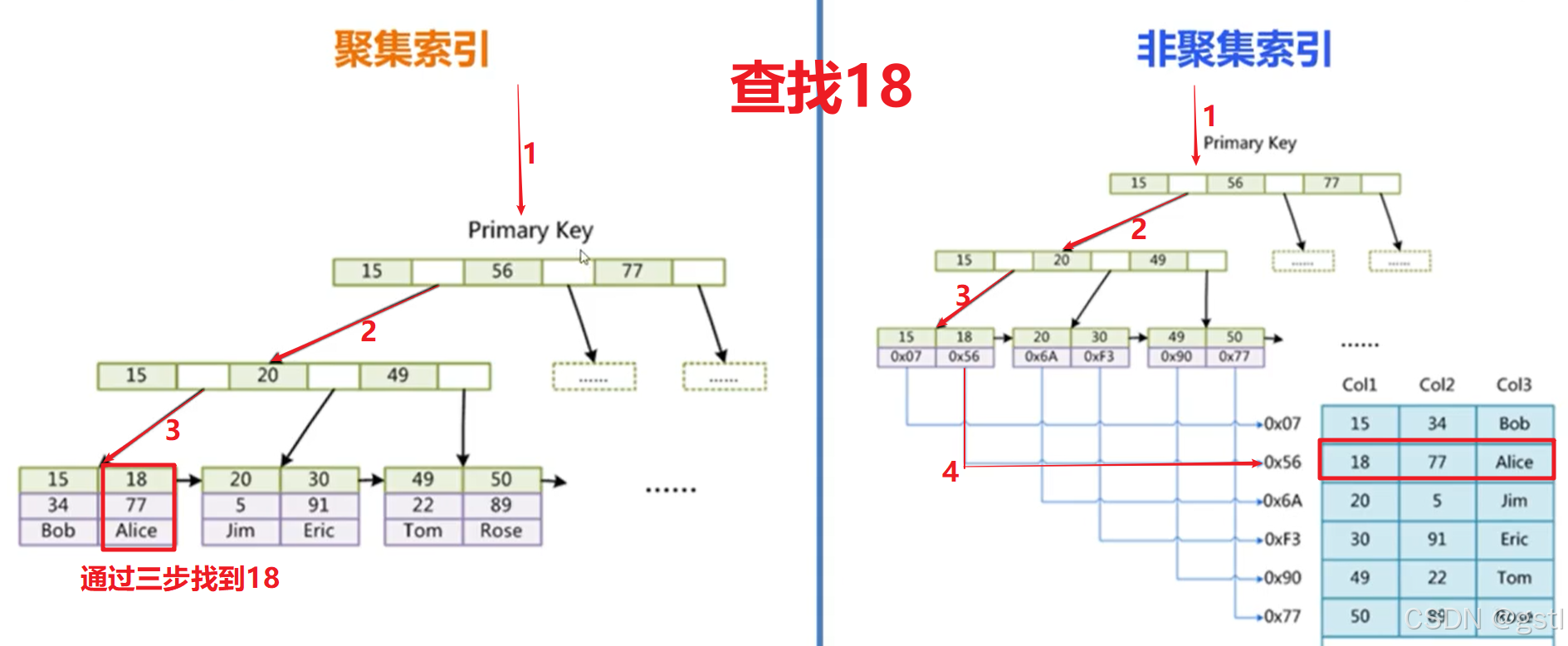
聚簇索引与非聚簇索引
物理存储方式不同: 1. InnoDb默认数据结构是聚簇索引;MyISAM 是非聚簇索引 2. 聚簇索引 中表索引与数据是在一个文件中 .ibd;非聚簇索引中表索引(.MYI)与数据(.MYD)是在两个文件中 3. 聚簇索引中表数据行都存放在索引树…...

“类型名称”在Go语言规范中的演变
Go语言规范(The Go Programming Language Specification)[1]是Go语言的核心文档,定义了该语言的语法、类型系统和运行时行为。Go语言规范的存在使得开发者在实现Go编译器时可以依赖一致的标准,它确保了语言的稳定性和一致性&#…...

c++----继承(初阶)
大家好呀,今天我们也是多久没有更新博客了,今天来讲讲我们c加加中的一个比较重要的知识点继承。首先关于继承呢,大家从字面意思看,是不是像我们平常日常生活中很容易出现的,比如说电视剧里面什么富豪啊,去了…...
常见的四种非关系型数据库(NoSQL))
数据库系列(1)常见的四种非关系型数据库(NoSQL)
非关系型数据库(NoSQL) 非关系型数据库适用于需要灵活数据模型和高可扩展性的场景。常见的非关系型数据库包括: MongoDB:文档数据库,以JSON-like格式存储数据,适合快速开发和迭代。Cassandra:…...

大规模预训练语言模型的参数高效微调
人工智能咨询培训老师叶梓 转载标明出处 大规模预训练语言模型(PLMs)在特定下游任务上的微调和存储成本极高,这限制了它们在实际应用中的可行性。为了解决这一问题,来自清华大学和北京人工智能研究院的研究团队探索了一种优化模型…...

一场大模型面试,三个小时,被撞飞了
去华为面试大模型,一点半去五点半回,已经毫无力气。 1️⃣一轮面试—1小时 因为一面都是各个业务的主管,所以专业性很强,面试官经验很丰富,建议大家还是需要十分熟悉所学内容,我勉强通过一面。 2️⃣二轮…...

Python每次for循环向list中添加多个元素
Python中,我每次for loop要产生几个结果。要将这些结果加到一个list中。怎么最高效? 答: list extend 方法 在Python中,如果你想在循环中将多个元素添加到列表中,最直接和最高效的方式是使用列表的 append() 方法。每次循环时&a…...

Java爬虫抓取数据的艺术
在信息时代,数据的重要性不言而喻。对于Java开发者来说,掌握如何使用Java进行数据抓取是一项宝贵的技能。通过编写爬虫程序,我们可以从互联网的海量信息中提取有价值的数据,用于市场分析、客户洞察、内容监控等多种场景。本文将介…...

Unity场景内画车道线(根据五阶曲线系数)
之前做过使用Dreamteck Splines插件构建车道线之前需求是给定车道线的点位,根据点位来进行构建。 由于AI识别出来的点位不线性,画出来的车道线经常是歪七扭八,所以使用五阶曲线系数进行构建。 使用在线图形计算器进行测试构建,公式…...

IPLOOK百万级用户容量核心网惊艳亮相北京PT展
2024年9月25日,以“推动数实深度融合,共筑新质生产力”为主题,本届中国国际信息通信展(PT展)在北京国家会议中心正式拉开帷幕。 广州爱浦路网络技术有限公司(简称:IPLOOK)ÿ…...

家庭网络的ip安全性高吗
家庭网络的IP安全性是一个重要的话题,涉及到如何保护家庭设备和用户的隐私。家庭网络的安全性既有其优势,也存在一些潜在的风险。以下是关于家庭网络IP安全性的几个关键点: 1. 家庭网络的优势 私有IP地址的使用 家庭网络中的设备通常使用私…...

LLM阅读推荐
(按名称排序) 【徹底解説】これからのエンジニアの必携スキル、プロンプトエンジニアリングの手引「Prompt Engineering Guide」を読んでまとめてみた(opens in a new tab)3 Principles for prompt engineering with GPT-3(opens in a new tab)A beginn…...

计算机网络笔记001
讲义 1.计算机网络的定义 定义: 一批独立自治的计算机系统的互连集合体 说明: 独立自治的计算机系统, 互连的手段是各种各样的, 依据协议进行 工作 2.计算机网络和通信网络 通信网络: 重点研究通…...

如何用IDEA连接HBase
编写java代码,远程连接HBase进行相关的操作 一、先导依赖 代码如下: 二、连接成功...

【JS代码规范】如何优化if-else代码规范
1. 快速结束,减少没必要的else 案例一:2种互斥的条件判断 function test(data) {let result ;if (data < 0) {result 负数;} else {result 非负数;}return result; }优化一: function test(data) {if (data < 0) {return 负数;} …...

MovieLife 电影生活
MovieLife 电影生活 今天看到一个很有意思的项目:https://www.lampysecurity.com/post/the-infinite-audio-book “我有一个看似愚蠢的想法。通常,这类想法只是一闪而过,很少会付诸实践。但这次有所不同。假如你的生活是一部电影,…...

网工内推 | 中级云运维工程师,双休,五险一金
01 博达人才 🔷招聘岗位:中级云运维工程师 🔷岗位职责 1、受理数据中心、云租户投诉、受理故障工单,并在时限内完成。 2、协助客户开通云产品,解答客户使用过程中的疑问。 3、处理云产品故障,协助进行故…...

Thingsboard规则链:Related Entity Data节点详解
引言 在复杂的物联网(IoT)生态系统中,数据的集成与分析是实现高效管理和智能决策的基础。Thingsboard作为一个强大的开源物联网平台,其规则链(Rule Chains)机制允许用户构建自定义的数据处理流程。其中&am…...

狼来了?如果我们正处于AI泡沫中会怎样?
AI 热潮真正的风险,不在模型神话,而在算力账单和 ROI 清算。 原文链接:AI 小老六 每天,我们都能在网络上看到各种关于 AI 未来 的离谱预测。 有人说:“GPT-7 马上就要出来了,它会吞噬所有的软件࿰…...

终极AI分层工具:3分钟让单张图片变专业PSD文件
终极AI分层工具:3分钟让单张图片变专业PSD文件 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 还在为复杂的插画分层工作头疼吗?L…...

G-Helper终极指南:如何彻底解决华硕笔记本散热与性能管理难题
G-Helper终极指南:如何彻底解决华硕笔记本散热与性能管理难题 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenb…...

《风险背后的数学 — 第二部分》
原文:towardsdatascience.com/the-math-behind-risk-part-2-4a3ac74eedec?sourcecollection_archive---------4-----------------------#2024-07-03 攻击方在世界征服游戏中真的占有优势吗? https://medium.com/menachemrose1?sourcepost_page---byli…...
核心原理、MATLAB/Python实现与工程应用全解析)
离散时间傅里叶变换(DTFT)核心原理、MATLAB/Python实现与工程应用全解析
1. 项目概述:从连续到离散的信号分析桥梁信号处理领域里,我们常常需要分析一个信号的频率成分。对于连续时间信号,我们有强大的工具——连续时间傅里叶变换。但现实世界中的计算机和数字系统处理的都是离散的、一串串的数字序列,比…...

告别Python依赖!手把手教你用C++复现Librosa的Mel频谱和MFCC特征提取
高性能C音频特征提取实战:从Librosa原理到嵌入式部署优化 在语音识别和音频分析领域,Mel频谱和MFCC特征提取是基础但关键的技术环节。许多开发者习惯使用Python的Librosa库快速实现原型,但当需要部署到生产环境时,Python的解释器性…...
)
告别Demo!用EMQX和Java模拟真实物联网设备上报数据流(Windows本地开发环境)
告别Demo!用EMQX和Java构建真实物联网数据流模拟方案 在物联网开发中,最令人头疼的莫过于缺乏真实设备进行测试。想象一下,当你精心设计的平台等待设备接入时,硬件团队却告诉你"下周才能交付原型机"。这种等待不仅拖延进…...

攻克R与Python的壁垒:Giotto空间转录组分析环境一站式搭建指南
1. 为什么你的Giotto安装总是失败? 每次看到空间转录组数据就手痒想用Giotto分析,结果安装环节就被劝退?这可能是大多数生物信息学新手都会遇到的尴尬。作为一个在生信领域摸爬滚打多年的"环境配置工程师",我太理解这种…...

Steam成就管理器终极指南:3步修复错失的游戏成就
Steam成就管理器终极指南:3步修复错失的游戏成就 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager Steam Achievement Manager(SAM&a…...

终极qmcdump指南:5分钟掌握QQ音乐加密格式解密技巧
终极qmcdump指南:5分钟掌握QQ音乐加密格式解密技巧 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump qmcdump是…...