什么猫猫最受欢迎?Python采集猫咪交易数据
前言
在日常生活中,我们看到可爱的猫咪表情包,总是会忍不住收藏

认识的一些朋友也养了猫,比如橘猫、英短、加菲猫之类的

看他们发朋友圈撸猫,老羡慕了,猫咪真的太可爱啦。

你是不是也动过养猫猫的小心思呢~反正我是动过了
于是,网上闲逛的时候发现一个专门交易猫猫的网站—猫猫交易网
这不得采集20W+ 条猫猫数据,以此来了解一下可爱的猫咪。

python源码、教程、资料、解答: 点击此处跳转文末名片获取
数据获取
打开猫猫交易网,先采集猫咪品种数据,首页点击猫咪品种
这里打开页面可以看到猫猫品种列表:
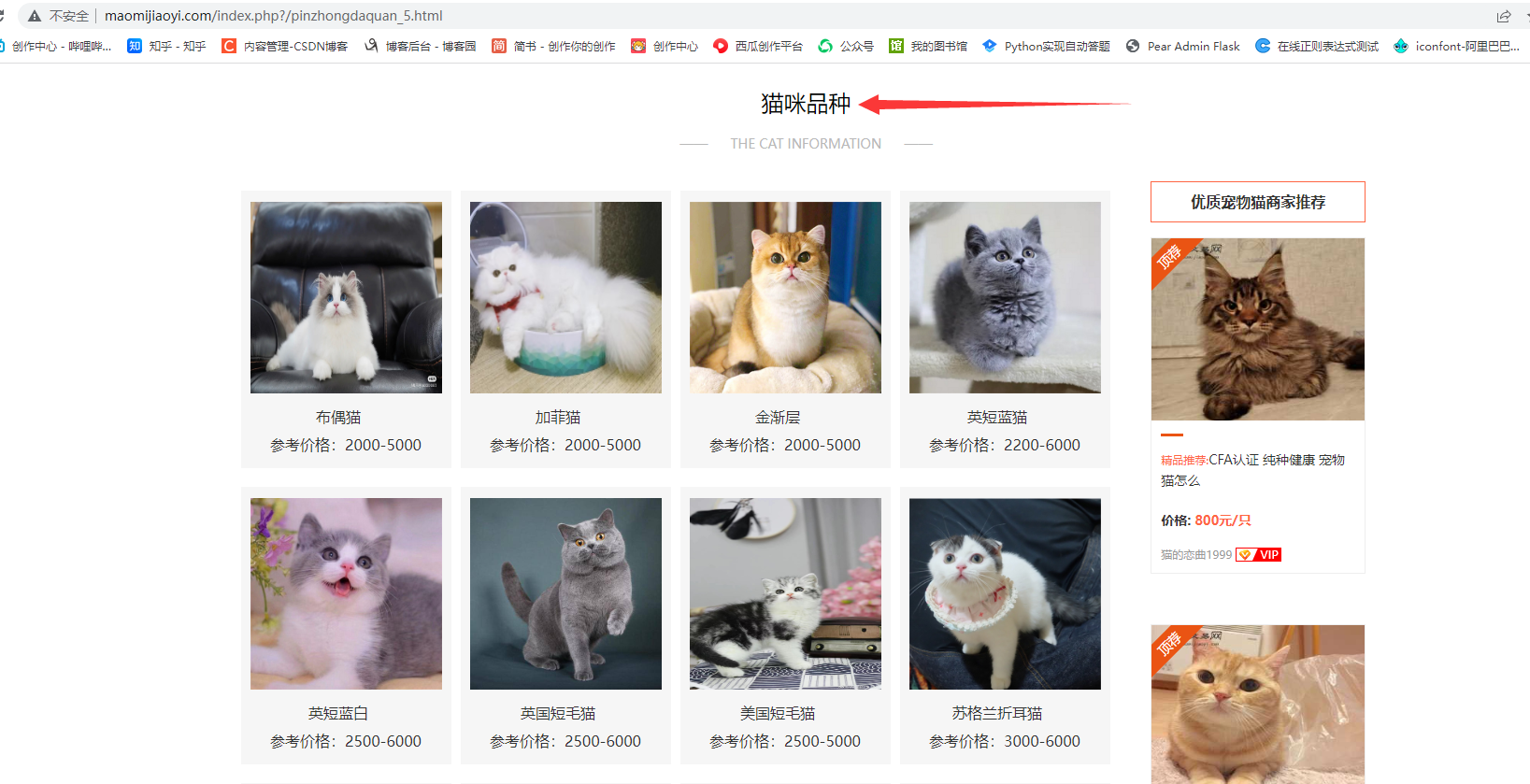
但只显示了每种猫猫的品种名,参考价格,我们点进详情页,可以看到更加详细的数据:
品种名、参考价格、中文学名、基本信息、性格特点、生活习性、优缺点、喂养方法等。
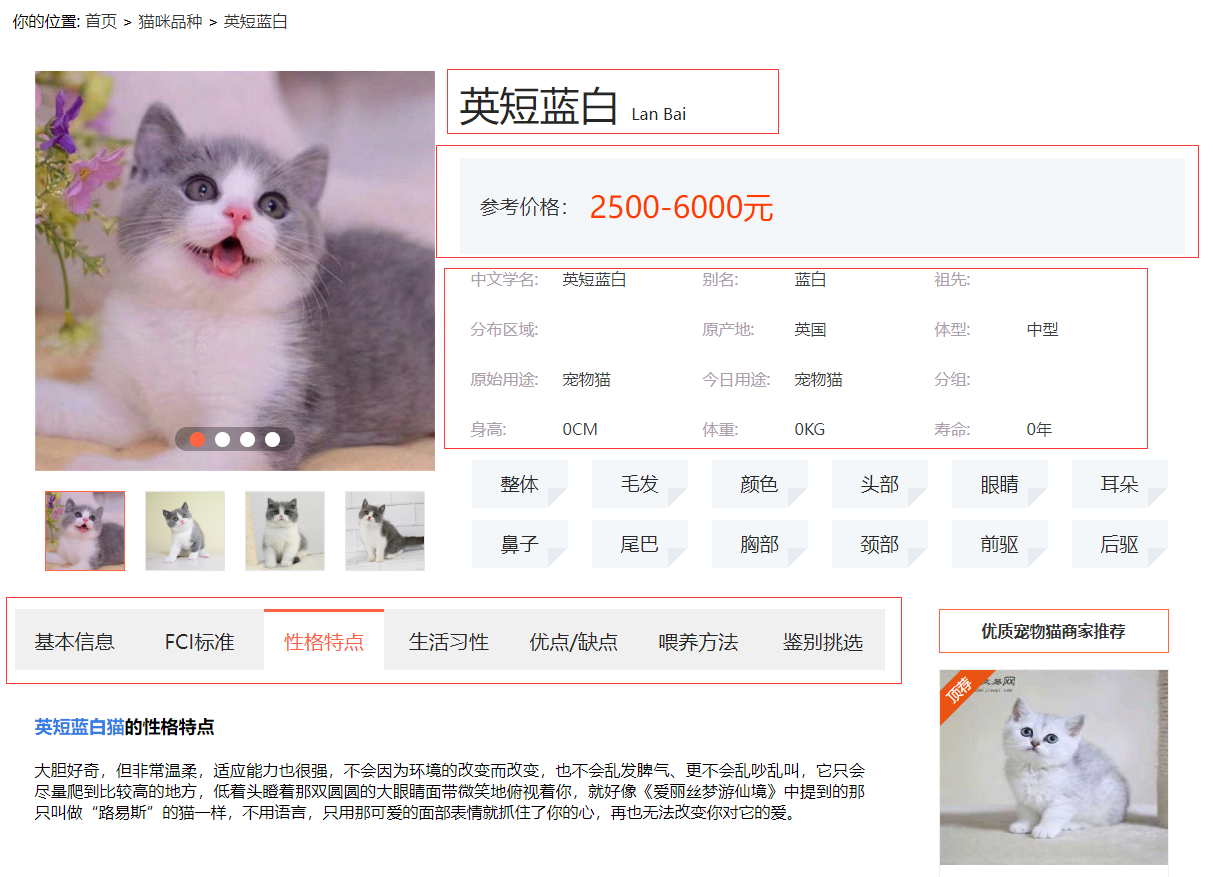
检查网页,可以发现网页结构简单,容易解析和提取数据。
代码如下:
import requests
import re
import csv
from lxml import etree
from tqdm import tqdm
from fake_useragent import UserAgent
随机产生请求头
ua = UserAgent(verify_ssl=False, path='fake_useragent.json')def random_ua(): # 用于随机切换请求头headers = {"Accept-Encoding": "gzip","Accept-Language": "zh-CN","Connection": "keep-alive","Host": "www.maomijiaoyi.com","User-Agent": ua.random}return headers
创建保存数据的csv
def create_csv(): with open('./data/cat_kind.csv', 'w', newline='', encoding='utf-8') as f:wr = csv.writer(f)wr.writerow(['品种', '参考价格', '中文学名', '别名', '祖先', '分布区域','原产地', '体型', '原始用途', '今日用途', '分组', '身高','体重', '寿命', '整体', '毛发', '颜色', '头部', '眼睛','耳朵', '鼻子', '尾巴', '胸部', '颈部', '前驱', '后驱','基本信息', 'FCI标准', '性格特点', '生活习性', '优点/缺点','喂养方法', '鉴别挑选'])
获取HTML网页源代码 返回文本
def scrape_page(url1): response = requests.get(url1, headers=random_ua())# print(response.status_code)response.encoding = 'utf-8'return response.text
获取每个品种猫咪详情页url
def get_cat_urls(html1): dom = etree.HTML(html1)lis = dom.xpath('//div[@class="pinzhong_left"]/a')cat_urls = []for li in lis:cat_url = li.xpath('./@href')[0]cat_url = 'http://*****' + cat_urlcat_urls.append(cat_url)return cat_urls
采集每个品种猫咪详情页里的有关信息
def get_info(html2): # 品种kind = re.findall('div class="line1">.*?<div class="name">(.*?)<span>', html2, re.S)[0]kind = kind.replace('\r','').replace('\n','').replace('\t','')# 参考价格price = re.findall('<div>参考价格:</div>.*?<div>(.*?)</div>', html2, re.S)[0]price = price.replace('\r', '').replace('\n', '').replace('\t', '')# 中文学名chinese_name = re.findall('<div>中文学名:</div>.*?<div>(.*?)</div>', html2, re.S)[0]chinese_name = chinese_name.replace('\r', '').replace('\n', '').replace('\t', '')# 别名other_name = re.findall('<div>别名:</div>.*?<div>(.*?)</div>', html2, re.S)[0]other_name = other_name.replace('\r', '').replace('\n', '').replace('\t', '')# 祖先ancestor = re.findall('<div>祖先:</div>.*?<div>(.*?)</div>', html2, re.S)[0]ancestor = ancestor.replace('\r', '').replace('\n', '').replace('\t', '')# 分布区域area = re.findall('<div>分布区域:</div>.*?<div>(.*?)</div>', html2, re.S)[0]area = area.replace('\r', '').replace('\n', '').replace('\t', '')# 原产地source_area = re.findall('<div>原产地:</div>.*?<div>(.*?)</div>', html2, re.S)[0]source_area = source_area.replace('\r', '').replace('\n', '').replace('\t', '')# 体型body_size = re.findall('<div>体型:</div>.*?<div>(.*?)</div>', html2, re.S)[0]body_size = body_size.replace('\r', '').replace('\n', '').replace('\t', '').strip()# 原始用途source_use = re.findall('<div>原始用途:</div>.*?<div>(.*?)</div>', html2, re.S)[0]source_use = source_use.replace('\r', '').replace('\n', '').replace('\t', '')# 今日用途today_use = re.findall('<div>今日用途:</div>.*?<div>(.*?)</div>', html2, re.S)[0]today_use = today_use.replace('\r', '').replace('\n', '').replace('\t', '')# 分组group = re.findall('<div>分组:</div>.*?<div>(.*?)</div>', html2, re.S)[0]group = group.replace('\r', '').replace('\n', '').replace('\t', '')# 身高height = re.findall('<div>身高:</div>.*?<div>(.*?)</div>', html2, re.S)[0]height = height.replace('\r', '').replace('\n', '').replace('\t', '')# 体重weight = re.findall('<div>体重:</div>.*?<div>(.*?)</div>', html2, re.S)[0]weight = weight.replace('\r', '').replace('\n', '').replace('\t', '')# 寿命lifetime = re.findall('<div>寿命:</div>.*?<div>(.*?)</div>', html2, re.S)[0]lifetime = lifetime.replace('\r', '').replace('\n', '').replace('\t', '')# 整体entirety = re.findall('<div>整体</div>.*?<!-- 页面小折角 -->.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]entirety = entirety.replace('\r', '').replace('\n', '').replace('\t', '').strip()# 毛发hair = re.findall('<div>毛发</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]hair = hair.replace('\r', '').replace('\n', '').replace('\t', '').strip()# 颜色color = re.findall('<div>颜色</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]color = color.replace('\r', '').replace('\n', '').replace('\t', '').strip()# 头部head = re.findall('<div>头部</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]head = head.replace('\r', '').replace('\n', '').replace('\t', '').strip()# 眼睛eye = re.findall('<div>眼睛</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]eye = eye.replace('\r', '').replace('\n', '').replace('\t', '').strip()# 耳朵ear = re.findall('<div>耳朵</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]ear = ear.replace('\r', '').replace('\n', '').replace('\t', '').strip()# 鼻子nose = re.findall('<div>鼻子</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]nose = nose.replace('\r', '').replace('\n', '').replace('\t', '').strip()# 尾巴tail = re.findall('<div>尾巴</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]tail = tail.replace('\r', '').replace('\n', '').replace('\t', '').strip()# 胸部chest = re.findall('<div>胸部</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]chest = chest.replace('\r', '').replace('\n', '').replace('\t', '').strip()# 颈部neck = re.findall('<div>颈部</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]neck = neck.replace('\r', '').replace('\n', '').replace('\t', '').strip()# 前驱font_foot = re.findall('<div>前驱</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]font_foot = font_foot.replace('\r', '').replace('\n', '').replace('\t', '').strip()# 后驱rear_foot = re.findall('<div>前驱</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]rear_foot = rear_foot.replace('\r', '').replace('\n', '').replace('\t', '').strip()
保存前面猫猫的各种有关信息
cat = [kind, price, chinese_name, other_name, ancestor, area, source_area,body_size, source_use, today_use, group, height, weight, lifetime,entirety, hair, color, head, eye, ear, nose, tail, chest, neck, font_foot, rear_foot]
提取标签栏信息(基本信息-FCI标准-性格特点-生活习性-优缺点-喂养方法-鉴别挑选)
html2 = etree.HTML(html2)labs = html2.xpath('//div[@class="property_list"]/div')for lab in labs:text1 = lab.xpath('string(.)')text1 = text1.replace('\n','').replace('\t','').replace('\r','').replace(' ','')cat.append(text1)return cat
保存数据 追加写入
def write_to_csv(data): with open('./data/cat_kind.csv', 'a+', newline='', encoding='utf-8') as fn:wr = csv.writer(fn)wr.writerow(data)
创建保存数据的csv
if __name__ == '__main__':create_csv()# 猫咪品种页面urlbase_url = 'http://*****/index.php?/pinzhongdaquan_5.html'# 获取品种页面中的所有urlhtml = scrape_page(base_url)urls = get_cat_urls(html)# 进度条可视化运行情况 就不打印东西来看了pbar = tqdm(urls)
开始采集
for url in pbar:text = scrape_page(url)info = get_info(text)write_to_csv(info)
成功采集了猫咪品种数据保存到csv,接下来采集猫猫交易数据

进入到买猫卖猫页面:

爬取更详细的数据需要进入详情页,包含商家信息、猫咪品种、猫龄、价格、标题、在售只数、预防等信息。
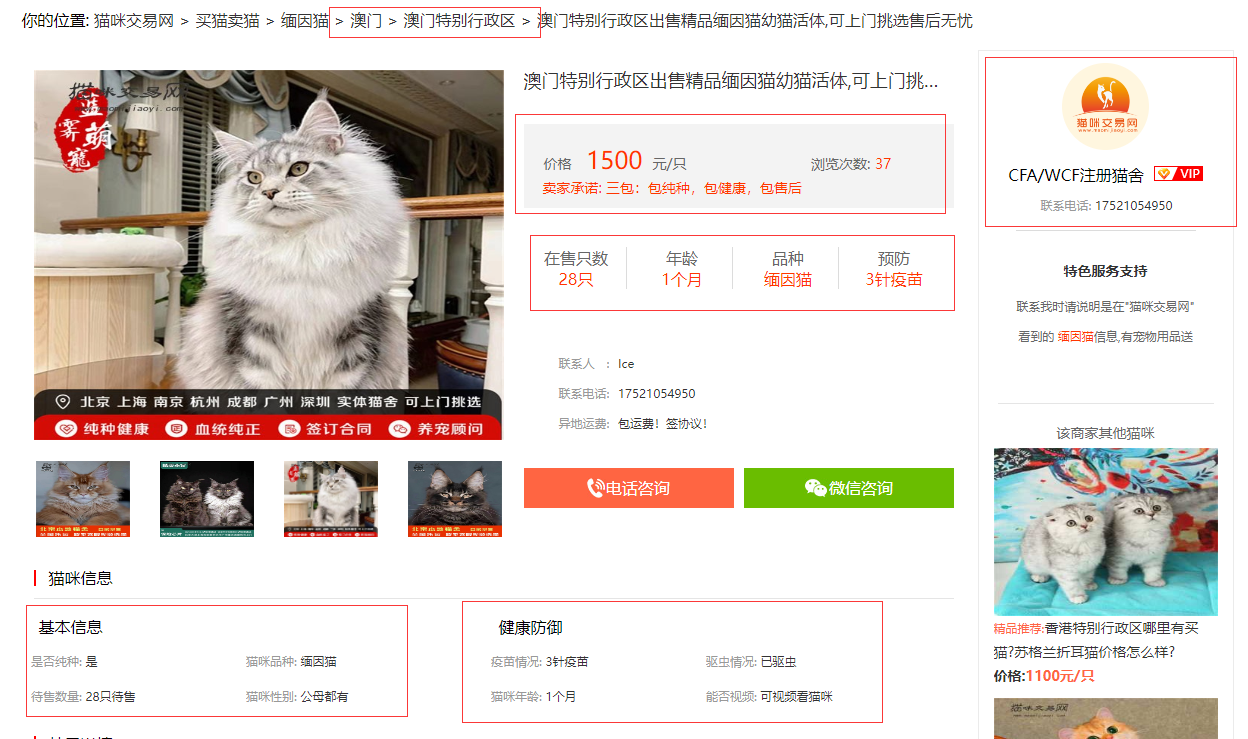
由于数据量较大,可以分开爬取,先获取到每一页中的所有猫猫详情交易链接的 url 保存到csv,再
读取 csv 中的 url 来请求,爬取每条交易数据,爬虫思路跟前面类似,为了加快爬取效率,可以使用多线程或者异步爬虫。
最终获取了 20W+ 条数据。
尾语 💝
要成功,先发疯,下定决心往前冲!
学习是需要长期坚持的,一步一个脚印地走向未来!
未来的你一定会感谢今天学习的你。
—— 心灵鸡汤
本文章到这里就结束啦~感兴趣的小伙伴可以复制代码去试试哦 😝

相关文章:
什么猫猫最受欢迎?Python采集猫咪交易数据
前言 在日常生活中,我们看到可爱的猫咪表情包,总是会忍不住收藏 认识的一些朋友也养了猫,比如橘猫、英短、加菲猫之类的 看他们发朋友圈撸猫,老羡慕了,猫咪真的太可爱啦。 你是不是也动过养猫猫的小心思呢~反正我是动…...
使用Nextcloud搭建私人云盘,并内网穿透实现公网远程访问
文章目录摘要视频教程1. 环境搭建2. 测试局域网访问3. 内网穿透3.1 ubuntu本地安装cpolar3.2 创建隧道3.3 测试公网访问4 配置固定http公网地址4.1 保留一个二级子域名4.1 配置固定二级子域名4.3 测试访问公网固定二级子域名摘要 Nextcloud,它是ownCloud的一个分支,是一个文件…...
国际测量控制及仪器仪表展览会)
行业盛会|2023中国(东莞)国际测量控制及仪器仪表展览会
时间:2023年11月16-18日 地点:广东现代国际展览中心 ◆展会背景background: 众所周知,当今世界已经进入信息时代,信息技术成为推动科学技术高速发展的关键技术。…...

redis集群 服务器重启测试
redis集群 服务器重启测试1、集群规划:2台服务器 每台服务器运行3个redis实例2、重启2台服务器后redis实例没有自动重启最后一对主从节点比较 重启实例后和之前的主从分配3、再次重启2台服务器4、主从同步测试1、集群规划:2台服务器 每台服务器运行3个re…...

Diffusion的unet中用到的AttentionBlock详解
AttentionBlocktorch.splittorch中的permute的用法torch.transpose()view()torch.bmmsoftmax(x, dim-1)Diffusion的unet中用到的AttentionBlock详解class AttentionBlock(nn.Module):__doc__ r"""Applies QKV self-attention with a residual connection.Input…...
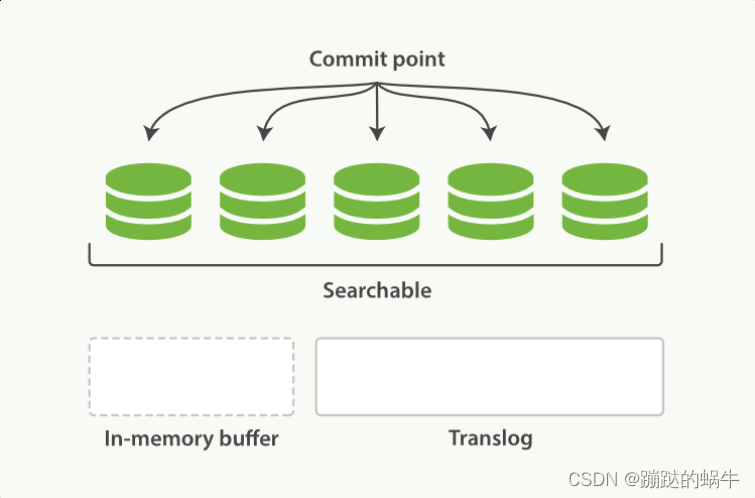
ElasticSearch索引文档写入和近实时搜索
一、基本概念 1.Segments In Lucene 众所周知,ElasticSearch存储的基本单元Shard,ES中一个Index可能分为多个Shard,事实上每个Shard都是一个Lucence的Index,并且每个Lucene Index由多个Segment组成,每个Segment事实上…...

【C语言蓝桥杯每日一题】——等差数列
【C语言蓝桥杯每日一题】——等差数列😎前言🙌等差数列🙌解题思路分析:😍解题源代码分享:😍总结撒花💞😎博客昵称:博客小梦 😊最喜欢的座右铭&…...

EM7电磁铁的技术参数
电磁铁可以通过更换电磁铁极头在一定范围内改善磁场的大小和磁场的均匀度 ,并且可以通过调整极头间距改变磁场的大小。主要用于磁滞现象研究、磁化系数测量、霍尔效应研究、磁光实验、磁场退火、核磁共振、电子顺磁共振、生物学研究、磁性测量、磁性材料取向、磁性产…...

选择很重要,骑友,怎么挑选骑行装备?
骑行装备的重要性,已经不用多说了,大家也都知道。但是如何挑选,如何选择适合自己的骑行装备呢?今天我来和大家聊一聊这个问题。首先我们需要了解一个概念:骑行装备分为两大类:骑行服和骑行鞋。对于公路车来…...

【JUC面试题】Java并发编程面试题
Java并发编程 基础知识 1. 为什么要使用并发编程? 提升多核系统的CPU利用率一般来说一台主机上的会有多个CPU核心,我们可以创建多个线程,理论 上讲操作系统可以将多个线程分配给不同的CPU去执行,每个CPU执行一个线程,…...

spark笔记
spark笔记 1. 概述 Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎;Spark提供内存计算,将计算结果直接放在内存中,减少了迭代计算的IO开销,有更高效的运算效率。 1.1 Spark核心模块 Spark Core:提供S…...
丢失了packet.dll原因和解决方法全面指南
packet.dll是Windows操作系统中的一个重要文件,它主要用于网络通信,如果丢失了这个文件,可能会导致网络连接问题。本文将探讨packet.dll文件丢失的原因,并提供相应的解决方法。 一、丢失packet.dll文件的原因 1. 病毒感染&#x…...
算法练习随记(三)
1.全排列 给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。 示例 1: 输入:nums [1,2,3] 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]示例 2: 输入&#x…...
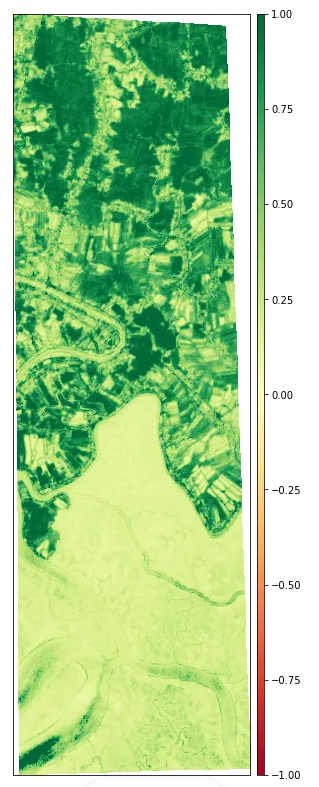
基于Python 进行卫星图像多种指数分析
一、前言本文帮助读者更好地了解卫星数据以及使用 Python 探索和分析哨兵2卫星数号数据在Sundarbans地区的不同方法。二、Sundarbans研究区孙德尔本斯(Sundarbans)是恒河、雅鲁藏布江和梅克纳河在孟加拉湾汇合形成的三角洲中最大的红树林区之一。 孙德尔…...
综合复习(C++,字符串,数学))
(Week 15)综合复习(C++,字符串,数学)
文章目录T1 [Daimayuan]删删(C,字符串)输入格式输出格式样例输入样例输出数据规模解题思路T2 [Daimayuan]快快变大(C,区间DP)输入格式输出格式样例输入样例输出数据规模解题思路T3 [Daimayuan]饿饿 饭饭2&a…...

迪赛智慧数——柱状图(正负条形图):“光棍”排行榜TOP10省份
效果图 中国单身男女最多的省份是广东,广东的人口是全国最多的。人口多了,单身的人也会多,单身女性324万,男性498万。全国第二的省份是四川省,单身女性256万,单身男性296万。 数据源:静态数据…...

IDEA集成chatGTP让你编码如虎添翼
第一步,打开您的IDEA, 打开首选项(Preference) -> 插件(Plugin) 在插件市场搜索 chatGPT, 点击安装 安装完毕后会提示您重启IDE, 重启IDEA. 重启后您会发现窗口,右边条上 竖着挂着个chatGPT按钮了。 第二步、配置APIkey或accessToken(二选一,推荐accessToken无费用…...
 方法、Python3 File readline() 方法)
Python3 os.close() 方法、Python3 File readline() 方法
Python3 os.close() 方法 概述 os.close() 方法用于关闭指定的文件描述符 fd。 语法 close()方法语法格式如下: os.close(fd);参数 fd -- 文件描述符。 返回值 该方法没有返回值。 实例 以下实例演示了 close() 方法的使用: #!/usr/bin/python3…...
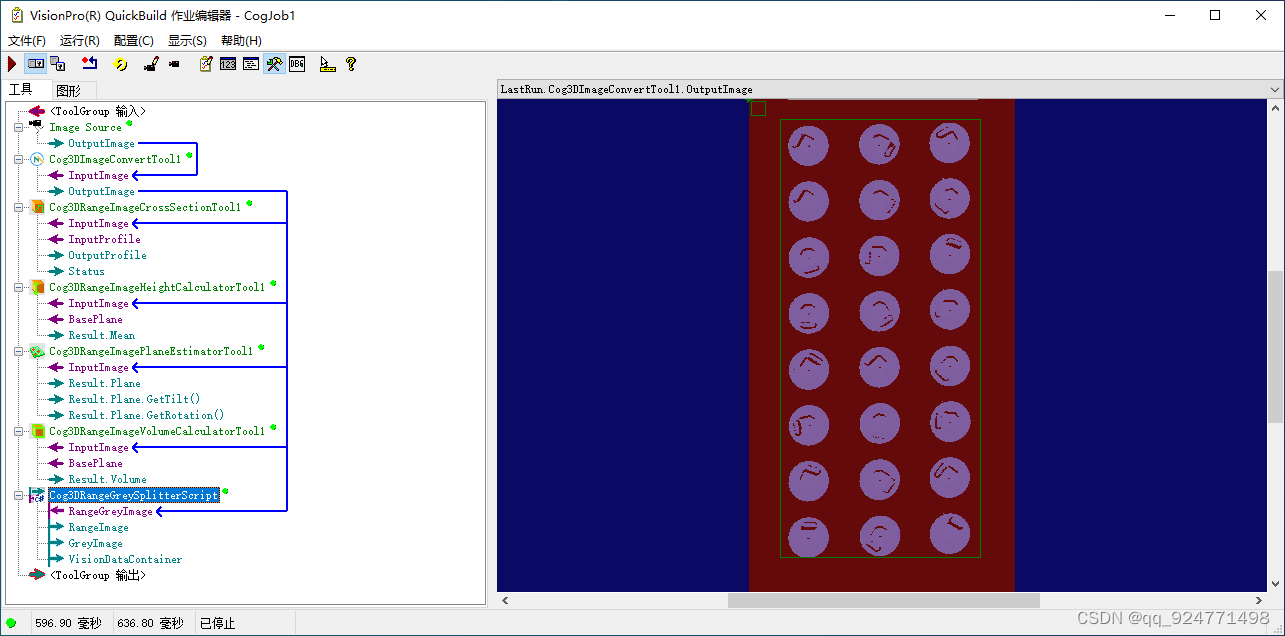
Vision Pro 自己写的一些自定义工具(c#)
目录前言一、保存图片工具1、展示2、源码下载地址二、3D图片格式转化1、展示2、源码下载地址三、所有工具汇总下载地址前言 自己用c#写的一些visionPro自定义工具,便于使用的时候直接拿出来,后续会不断添加新的工具。 想看怎么使用c#写visionPro自定义…...

ARM/FPGA/DSP板卡选型大全,总有一款适合您
创龙科技ARM/FPGA/DSP嵌入式板卡选型大全2023.2版本正式发布!接下来,跟着我们一起看看有哪些亮点吧! 6大主流工业处理器原厂 创龙科技现有30多条产品线,覆盖工业自动化、能源电力、仪器仪表、通信、医疗、安防等工业领域,与6大主流工业处理器原厂强强联合,包括德州仪器…...

物联网设备网络无缝切换与多网融合:exnetif模块实战指南
1. 项目概述:为什么我们需要exnetif? 在物联网项目的实际开发中,我遇到过太多因为网络环境不稳定而导致的“玄学”问题。比如,一个部署在工厂车间的智能网关,原本通过稳定的有线以太网连接云端,一旦生产线调…...

在多轮对话中感受Taotoken路由策略的稳定性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话中感受Taotoken路由策略的稳定性 1. 引言:多轮对话的稳定性挑战 在构建依赖大语言模型的对话应用时&#x…...

LizzieYzy深度解析:专业围棋AI分析平台的实战进阶手册
LizzieYzy深度解析:专业围棋AI分析平台的实战进阶手册 【免费下载链接】lizzieyzy LizzieYzy - GUI for Game of Go 项目地址: https://gitcode.com/gh_mirrors/li/lizzieyzy 在围棋AI技术日新月异的今天,如何将强大的计算能力转化为实用的分析工…...

HPM6750 CAN FD实战:从波特率配置到高效收发,避坑指南
1. 项目概述:从经典CAN到CAN FD的实战入门作为一名长期在嵌入式领域摸爬滚打的开发者,我深知现场总线技术,尤其是CAN总线,在工业控制、汽车电子等领域的核心地位。随着数据吞吐量需求的激增,经典CAN的1Mbps带宽逐渐捉襟…...

3D打印操作辅助工具:自制安全高效的“过来放大器”
1. 项目概述:当3D打印遇上“过来”放大器在3D打印这个行当里折腾了这么多年,我见过各种稀奇古怪的“魔改”和“土法炼钢”,但最近一个朋友工作室里出现的一个小玩意儿,还是让我眼前一亮。他管它叫“3D打印设备专用过来放大器”。初…...
)
别再乱装CUDA了!用Anaconda为你的3060 Ti一键搞定PyTorch GPU环境(含CUDA 11.3实战)
3060 Ti显卡玩家的PyTorch环境配置指南:用Anaconda避开CUDA版本地狱 在深度学习领域,GPU加速已经成为提升模型训练效率的标配。然而,对于许多刚入门的开发者来说,配置PyTorch的GPU支持往往成为第一道门槛——尤其是当涉及到CUDA版…...

通过taotoken审计日志追溯api调用详情与安全分析
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken审计日志追溯API调用详情与安全分析 对于将大模型API集成到业务流程中的团队而言,API调用的可见性与可控性…...

保姆级教程:用CH34xSerCfg修改USB转串口芯片的VID/PID,解决驱动冲突和串口号固定问题
嵌入式开发实战:用CH34xSerCfg定制USB转串口设备标识与驱动管理 当你的工作台上同时连接着五个相同型号的USB转TTL模块,Windows设备管理器里COM端口像走马灯一样随机变换编号时;当团队协作开发中,每个成员需要固定识别自己的调试设…...

西门子PLC通信必备:手把手教你用SCL编写Modbus RTU CRC校验功能块
西门子PLC通信实战:SCL实现Modbus RTU CRC校验的工程化解决方案 在工业自动化领域,可靠的数据通信如同设备的神经系统。当两台PLC需要通过RS485接口交换温度传感器读数时,Modbus RTU协议因其简洁高效成为首选。但许多工程师在调试阶段都会遇到…...

3DS游戏格式转换神器:5分钟让.3ds文件变身为可安装的CIA
3DS游戏格式转换神器:5分钟让.3ds文件变身为可安装的CIA 【免费下载链接】3dsconv Python script to convert Nintendo 3DS CCI (".cci", ".3ds") files to the CIA format 项目地址: https://gitcode.com/gh_mirrors/3d/3dsconv 还在为…...