spark笔记
spark笔记
1. 概述
Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎;Spark提供内存计算,将计算结果直接放在内存中,减少了迭代计算的IO开销,有更高效的运算效率。
-
1.1 Spark核心模块
- Spark Core:提供Spark最基础与最核心的功能
- Spark SQL:是Spark用来操作结构化数据的组件。通过Spark SQL,用户可以使用SQL或者Apache Hive 版本的SQL 方言(HQL)来查询数据
- Spark Streaming:是Spark平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API
-
1.2 基本概念
-
RDD:弹性分布式数据集的简称,分布式内存的一个抽象概念,提供了一种高度受限的共享内存模 (可以看作一个不可变的分布式对象集合)
-
DAG:有向无环图的简称, 反映RDD之间的依赖关系
-
Executor:是运行在工作节点(WorkerNode)的一个进程,负责运行Task
-
应用(Application):用户编写的Spark应用程序
-
任务( Task ):运行在Executor上的工作单元
-
作业( Job ):一个作业包含多个RDD及作用于相应RDD上的各种操作
-
阶段( Stage ):是作业的基本调度单位,一个作业会分为多组任务,每组任务被称为阶段,或者也被称为任务集合,代表了一组关联的、相互之间没有Shuffle依赖关系的任务组成的任务集
-
2. spark工作架构

- Cluster Manager:集群资源管理器
- Worker Node:运行作业任务的工作节点,运行在集群中的一台服务器上
- Cluster Manager:每个应用的任务控制节点
- Driver:每个应用的任务控制节点
- Executor:每个工作节点上负责具体任务的执行进程
一个应用由一个Driver和若干个作业构成,一个作业由多个阶段构成,一个阶段由多个没有Shuffle关系的任务组成;
当执行一个应用时,Driver会向集群管理器申请资源(即由Driver创建一个SparkContext,进行资源的申请、任务的分配和监控) ,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行任务,运行结束后,执行结果会返回给Driver或者写到HDFS或者其他数据库中。
3. RDD
弹性分布式数据集,spark最基本的数据处理模型,代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
-
3.1 特性
弹性: 内存与磁盘的自动切换、数据丢失可以自动恢复、计算出错重试机制、可根据需要重新分片
分布式: 数据存储在大数据集群不同节点上
数据集: RDD封装计算逻辑,不保存数据
不可变: RDD封装计算逻辑,是不可以改变的,想要改变只能产生新的RDD,在新的RDD里面封装计算逻辑
可分区: 并行计算 -
3.2 RDD 创建
RDD的创建可以从从文件系统中加载数据创建得到,或者通过并行集合(数组)创建RDD。
- 从文件系统中加载数据:
val lines = sc.textFile("C:\Users\26414\Downloads\word.txt")- 从HDFS中加载数据:
val lines = sc.textFile("hdfs://localhost:9000/user/hadoop/word.txt")- 从已经存在的集合(数组)上创建:
val list = List(1,2,3,4,5)val rdd = sc.parallelize(list) -
3.3 RDD 操作
-
3.3.1 转换算子(产生新的RDD算子,不触发计算,返回新的RDD)
单值类型方法 描述 map() 一对一的转换操作,对每一条数据计算,默认分区数不变 mapPartitions() 以分区为单位进行计算,一次性获取分区的所有数据,参数为迭代器,返回也是迭代器 mapPartitionsWithIndex() 参数为分区号和迭代器,返回值是迭代器 flatMap() 将map结果扁平化 glom() 将分区内数据转为数组Array groupBy(函数) 用于执行分组操作,返回值为元组,第一个元素为分组的key,第二个元素为相同key的可迭代集合,将数据进行分组操作,但是分区是不会改变的,也可以传入参数改变分区数(shuffle) filter(函数) 过滤,参数为返回值类型为Boolean的函数,将数据根据指定的规则进行筛选 sample() 抽取样本,也可以给定种子 distinct() 去重,也可以传入参数num,改变分区数(shuffle) coalesce(num) 缩减分区,默认shuffle repartition(num) 扩大分区,底层是coalesce(num, true) sortBy() 排序之前可以使用函数进行处理,默认升序,可以传入false降序 map和mapPartitions区别: map每次处理一条数据,mapPartitions每次将一个分区当成一个整体进行处理,如果一个分区没有处理完,那么所有的数据都不会释放,容易出现内存溢出
双值类型
方法 描述 union(rdd) 并集(分区合并) intersection(rdd) 交集(保留最大分区,shuffle) substring(rdd) 差集(分区数为前面的,shuffle) key-value类型
方法 描述 groupByKey() 根据key进行分组,将value合并为一个迭代器(列表) reduceByKey() 根据key进行分组,将value合并为一个迭代器(列表),然后根据传入的自定义函数,对每组中value数据进行聚合处理。 sortByKey() 根据key进行排序操作。默认升序,若想倒序排列,设置参数ascending = False(可直接写False,省略 ascending =) countByValue() 对value进行count的数量统计 combineByKey() 对 key-value 型 rdd 进行聚集操作的聚集函数(aggregation function)。类似于aggregate(),combineByKey()允许用户返回值的类型与输入不一致 reduceByKey和 groupByKey的区别:
从 shuffle 的角度: reduceByKey 和 groupByKey 都存在 shuffle 的操作,但是 reduceByKey可以在 shuffle 前对分区内相同 key 的数据进行预聚合(combine)功能,这样会减少落盘的数据量,而 groupByKey 只是进行分组,不存在数据量减少的问题,reduceByKey 性能比较高。
从功能的角度: reduceByKey 其实包含分组和聚合的功能。GroupByKey 只能分组,不能聚合,所以在分组聚合的场合下,推荐使用 reduceByKey,如果仅仅是分组而不需要聚合。那么还是只能使用 groupByKey -
3.3.2 行动算子(不产生新的RDD算子,触发计算,返回具体值)
方法 描述 reduce() 聚集 RDD 中的所有元素,先聚合分区内数据,再聚合分区间数据 collect() 以数组 Array 的形式返回数据集的所有元素 count() 返回 RDD 中元素的个数 take() 返回一个由 RDD 的前 n 个元素组成的数组 aggregate() 分区的数据通过初始值和分区内的数据进行聚合,然后再和初始值进行分区间的数据聚合 fold() 折叠操作,aggregate 的简化版操作 countByKey() 统计每种 key 的个数 save相关算子 saveAsTextFile()、saveAsObjectFile()、saveAsSequenceFile() foreach() 分布式遍历 RDD 中的每一个元素,调用指定函数
-
-
3.4 Shuffle与依赖
Shuffle:数据混洗
Spark中的两种依赖:
- 宽依赖:一个父RDD的一个分区对应一个子RDD的多个分区,会引起Shuffle
- 窄依赖:一个父RDD的分区对应于一个子RDD的分区,或多个父RDD的分区对应于一个子RDD的分区。
宽窄依赖通俗理解参考:https://www.likecs.com/show-203912211.html
阶段的划分(作业分成几段,落盘完才能进行下一阶段):取决于Shuffle的个数,阶段的个数 = Shuffle的个数 + 1,Shuffle将阶段一分为二
-
3.5 RDD 持久化
RDD是不保存数据的,所以如果多个RDD需要共享其中一个RDD的数据,必须重头执行,效率非常低,所以需要将一些重复性比较高,比较耗时的操作的结果缓存起来,提高效率。
- cache(),缓存RDD数据,在执行行动算子之后,会在血缘关系中添加缓存相关的依赖,一旦发生错误,可以重新执行
- persist(),可以设置不同的级别,存储在磁盘内存,cache默认只在内存中缓存
- checkpoint(),执行前需要设置检查点目录;为了保证数据的准确性,执行时会启动新的job,所以一般与cache结合使用,这样checkpoint的job就可以从cache缓存中读数据;checkpoint()会切断血缘关系,因为它将数据保存在分布式文件系统中,当成了一个数据源,数据相对安全。
血缘关系: A的操作行为依赖于B,B的操作行为依赖于C,然而A的操作行为间接依赖于C,推导于:相邻的两个RDD的关系称之为依赖关系,新的RDD依赖于旧的RDD,多个连续的RDD的依赖关系,称之为血缘关系。每个RDD会保存血缘关系,但每个RDD不会保存数据,如果在reduceByKey过程中出现错误时,由于RDD不会保存数据,但可以根据血缘关系将数据源重新读取进行计算。
参考:https://www.likecs.com/show-203912211.html
4. Spark 共享变量
-
4.1 累加器
使用场景
主要用于多个节点对一个变量进行共享性的操作,在分布式运行时每个task运行的只是原始变量的一个副本,并不能改变原始变量的值,但是当这个变量被声明为累加器后,该变量就会有分布式计数的功能。object Accumulator_scala {def main(args: Array[String]): Unit = {val conf = new SparkConf().setAppName("Accumulator_scala").setMaster("local")val sc = new SparkContext(conf)val sum = sc.accumulator(0);val numberArray = Array(1,2,3,4,5)val numbers = sc.parallelize(numberArray)numbers.foreach( num => sum += num)println(sum)} }注: 累加器在Driver端定义赋初始值,累加器只能在Driver端读取最后的值,在Excutor端更新。
-
4.2 广播变量
使用场景
假如在spark程序里需要用到大对象,比如:字典,黑白名单等,这个都会由Driver端进行分发,一般来讲,如果这个变量不是广播变量,那么每个task就会分发一份,这在task数目十分多的情况下Driver的带宽会成为系统的瓶颈,而且会大量消耗Executor服务器上的资源,如果将这个变量声明为广播变量,那么只是每个Executor拥有一份,这个Executor启动的task会共享这个变量,节省了通信的成本和服务器的资源。object BroadcastVariable_scala {def main(args: Array[String]): Unit = {val conf = new SparkConf().setAppName("BroadcastVariable_scala").setMaster("local")val sc = new SparkContext(conf)val factor = 3val factorBroadcast = sc.broadcast(factor)val numberArray = Array(1,2,3,4,5)val numbers = sc.parallelize(numberArray,1)val multipleNumber = numbers.map{num => num * factorBroadcast.value}multipleNumber.foreach(num => println(num))} }注:
- 因为RDD是不存储数据的。可以将RDD的结果广播出去。
- 广播变量只能在Driver端定义,不能在Executor端定义。
- 在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
-> 如果executor端用到了Driver的变量,如果不使用广播变量在Executor有多少task就有多少Driver端的变量副本。 - 如果Executor端用到了Driver的变量,如果使用广播变量在每个Executor中只有一份Driver端的变量副本
参考:https://blog.csdn.net/chanyue123/article/details/123175776(累加器介绍)
https://zhuanlan.zhihu.com/p/158894710(广播变量原理)5. Spark SQL
Spark SQL 是Spark 用于结构化数据(structured data)处理的Spark 模块,兼容Hive,数据既可以来自RDD,也可以是Hive、HDFS、Cassandra等外部数据源,还可以是JSON格式的数据,提高开发效率,提供两个编程抽象,DataFrame,DataSet。
RDD是数据,DF是结构,DS是类型,RDD只包含数据,没有结构,DataFrame添加了结构,DataSet添加了类型;(DataFrame就是在RDD基础上加入了列,处理数据就像处理二维表一样)

-
5.1 DataFrame
-
5.1.1 DataFrame的组成
在结构层面:
StructType对象描述整个DataFrame的表结构
StructField对象描述一个列的信息
在数据层面
Row对象记录一行数据
Column对象记录一列数据并包含列的信息 -
5.1.2 DataFrame之DSL
- agg: 它是GroupedData对象的API, 作用是 在里面可以写多个聚合
- alias: 它是Column对象的API, 可以针对一个列 进行改名
- withColumnRenamed: 它是DataFrame的API, 可以对DF中的列进行改名, 一次改一个列, 改多个列 可以链式调用
- orderBy: DataFrame的API, 进行排序, 参数1是被排序的列, 参数2是 升序(True) 或 降序 False
- first: DataFrame的API, 取出DF的第一行数据, 返回值结果是Row对象.(Row对象 就是一个数组, 你可以通过row[‘列名’] 来取出当前行中, 某一列的具体数值. 返回值不再是DF 或者GroupedData 或者Column而是具体的值(字符串, 数字等))
常用方法
- show方法
功能:展示DataFrame中的数据, 默认展示20条 - printSchema方法
功能:打印输出df的schema信息
DSL语法
df.select("username").show(),查看某一列数据df.select($"username",$"age" + 1).show,列数据进行运算df.select('username, 'age + 1).show()df.select('username, 'age + 1 as "newage").show(),起别名df.filter($"age">30).show(),过滤数据df.groupBy("age").count.show(),分组- 5.1.2 DataFrame之SQL
SQL语法
df.createOrReplaceTempView("people"),创建一个临时表val sqlDF = spark.sql("SELECT * FROM people"),查询sqlDF.show(),显示结果df.createGlobalTempView("people"),创建一个全局表spark.sql("SELECT * FROM global_temp.people").show(),查询全局表必须加global_tempspark.newSession().sql("SELECT * FROM global_temp.people").show(),在新的Session里可以查询全局表- 5.1.3 DataFrame转换
-
RDD转为DF
RDD没有结构,指定结构:idRDD.toDF(“id”).show,使用toDF(“列名”)
通过样例类,将数据转换成样例类的对象,使用idRDD.toDF,使用样例类中的列名,也可以重命名.toDF(“id”,“name”) -
DF转为RDD
df.rdd,返回的是Row对象
-
注:DataFrame创建参考:https://blog.csdn.net/feizuiku0116/article/details/121523791
-
-
5.2 DataSet
是具有强类型的数据集合,需要提供对应的类型信息,查询之后使用方便,可以看做DataFrame的拓展- DataFrame 一行记录中没有指定特定的数据类型
- Dataset 一行记录中每个对象有明确类型
6. Spark Streaming
SparkStreaming是一套框架。
SparkStreaming是Spark核心API的一个扩展,可以实现高吞吐量的,具备容错机制的实时流数据处理。
实时: 数据处理的时延在毫秒内响应
离线: 数据处理的时延在小时、天
数据处理的方式 :批处理(多条处理),流式(一条一条处理)
微批次,准实时的数据处理引擎
支持多种数据源获取数据:

Spark Streaming接收Kafka、Flume、HDFS等各种来源的实时输入数据,进行处理后,处理结构保存在HDFS、DataBase等各种地方。
*使用的最多的是kafka+Spark Streaming
内部工作原理: Spark Streaming从实时数据流接入数据,再将其划分为一个个小批量供后续Spark engine处理,所以实际上,Spark Streaming是按一个个小批量来处理数据流的。

Spark Streaming为这种持续的数据流提供了的一个高级抽象,即:discretized[dɪˈskriːtaizd] stream(离散数据流)或者叫DStream。DStream既可以从输入数据源创建得来,如:Kafka、Flume或者Kinesis,也可以从其他DStream经一些算子操作得到。其实在内部,一个DStream就是包含了一系列RDDs。
-
6.1 StreamingContext
- StreamingContext定义之后做的操作如下
- 通过创建输入DStream来创建输入数据源。
- 通过对DStream定义transformation和output算子操作,来定义实时计算逻辑。
- 调用StreamingContext的start()方法,来开始实时处理数据。
- 调用StreamingContext的awaitTermination()方法,来等待应用程序的终止。可以使 用CTRL+C手动停止,或者就是让它持续不断的运行进行计算。
- 也可以通过调用StreamingContext的stop()方法,来停止应用程序。
-
StreamingContext创建方式
- SparkConf创建:
val conf = new SparkConf().setAppName(appName).setMaster(master); val ssc = new StreamingContext(conf, Seconds(1));appName是用来在Spark UI上显示的应用名称。master是Spark、Mesos或Yarn集群的URL,或者是local[*]。batch interval可以根据应用程序的延迟要求以及可用的集群资源情况来设置。- SparkContext创建:
val sc = new SparkContext(conf) val ssc = new StreamingContext(sc, Seconds(1))
-
6.2 DStream 简介
Spark Streaming提供了表示连续数据流的、高度抽象的被称为离散流的DStream假如外部数据不断涌入,按照一分钟切片,每个一分钟内部的数据是连续的(连续数据流),而一分钟与一分钟的切片却是相互独立的(离散流)。
DStream是Spark Streaming特有的数据类型。Dstream可以看做一组RDDs,即RDD的一个序列:

Spark的RDD可以理解为空间维度,Dstream的RDD理解为在空间维度上又加了个时间维度。
将连续的数据持久化,离散化,然后进行批量处理。
持久化:接收到的数据暂存(持久化原因:做容错的,当数据流出错了,因为没有得到计算,需要把数据从源头进行回溯,暂存的数据可以进行恢复。)
离散化:按时间分片,形成处理单元。
分片处理:分批处理。 -
6.3 DStream 转换操作
方法 描述 Scala示例 map() 对DStream中的每个元素应用指定函数并返回各元素输出元素组成的DStream ds.map(x=>x+1) flatMap() 对DStream中的每个元素应用指定函数并返回各元素输出迭代器组成的DStream ds.flatMap(x=>x.split(" ")) filter() 筛选过滤 ds.filter(x=>x != 1) repartition() 改变DStream分区数 ds.repartition(10) reduceByKey() 将每个批次中键相同的记录归约 ds.reduceByKey((x,y)=>x+y) groupByKey() 将每个批次中的记录按键分组 ds.groupByKey() -
6.4 DStream 输出操作
方法 描述 print() 在Driver中打印前10个元素 saveAsTextFiles(prefix, [suffix]) 以文本形式保存为文件。其中每次批处理产生文件以prefix-TIME_IN_MS[.suffix]命名 saveAsObjectFiles(prefix, [suffix]) 将DStream中内容按对象序列化并以SequenceFile格式保存。其中每次批处理产生文件以prefix-TIME_IN_MS[.suffix]命名 saveAsHadoopFiles(prefix, [suffix]) 以文本形式保存为hadoop文件。其中每次批处理产生文件以prefix-TIME_IN_MS[.suffix]命名 foreachRDD(func) 最基本输出操作,将func函数应用于DStream中的RDD上,这个操作会输出数据到外部系统 -
6.5 Spark Streaming 窗口操作
-
Spark提供了一组窗口操作,通过滑动窗口技术对大规模数据的增量更新进行统计分析
-
Window Operation:定时进行一定时间段内的数据处理

-
任何基于窗口操作需要指定两个参数:
- 窗口总长度:你想计算多长时间的数据
- 滑动时间间隔:你每多长时间去更新一次
参考文档:
https://www.cnblogs.com/fishperson/p/10447033.html
https://blog.csdn.net/u012369535/article/details/93042905 -
7. Spark 调优
-
7.1 常规性能调优
- 常规性能调优
增加executor个数
增加每个executor的cpu个数
增加每个executor的内存,1缓存更多的数据,减少磁盘IO,2为shuffle提供更多内存,减少写入磁盘数据,3内存较小会频繁GC,增加内存可以避免频繁GC,提升整体性能 - RDD优化
避免在相同的算子和计算逻辑下对RDD进行重复的计算
对多次使用的RDD进行持久化(可以序列化的,对于可靠性要求高的数据可以使用副本)
RDD尽可能早的过滤操作,减少内存占用 - 并行度调节
在资源允许的情况下,应尽可能让并行度与资源匹配,官方推荐task数量应该是总cpu核心数的2-3倍(因为有的任务执行的快,执行完毕后可以立马执行下一个task) - 广播大的变量
如果task算子中使用了外部的变量,每个task会有一个变量的副本,这就造成了内存的极大消耗,如果使用广播变量的话每个executor保存一个副本,可以很大程度上减少内存的使用
序列化:使用Kryo序列化,java的序列化太重(慢,字节多),效率不高
调整本地化等待时长
- 常规性能调优
-
7.2 算子调优
- 使用mapPartitions,map对分区中每一个元素操作,mapPartitions对真个分区操作,如果使用jdbc写入数据,那么每条数据都要建立一个连接,资源消耗大,如果使用mapPartitions,只需要建立一个连接
缺点:如果数据量很大的话,使用mapPartitions容易OOM,如果资源允许可以考虑使用mapPartitions代替map - 使用foreachPartition优化数据库操作,与mapPartitions类似,foreachPartition将RDD的每个分区作为遍历对象
- filter与coalesce的配合使用,过滤后数据量变小,再用原来的去执行浪费资源,有可能导致数据倾斜,可以进行合并分区或者扩大分区(宽依赖,需要设置为true,即开启shuffle,否则不起作用)
- 使用repartition提高SparkSQL的并行度,默认是hive表的文件的切片个数,spark SQL的并行度没法手动更改,可以读取到数据后立马进行扩大分区数,提高并行度
- 使用reduceByKey预聚合,groupByKey 不会进行map 端的聚合,减少磁盘IO,减少对磁盘空间的占用,reduce端的数据也变少
- 使用mapPartitions,map对分区中每一个元素操作,mapPartitions对真个分区操作,如果使用jdbc写入数据,那么每条数据都要建立一个连接,资源消耗大,如果使用mapPartitions,只需要建立一个连接
-
7.3 Shuffle 调优
- 增加map端缓冲区的大小,避免频繁溢写到磁盘
- 增加reduce端拉取数据缓冲区大小,减少拉取次数,减少网络传输
- 增加reduce端拉取数据的重试次数,避免因为JVM的full GC或者网络原因导致数据拉取失败进而导致作业执行失败
- 增加reduce端拉取数据等待间隔,拉取失败会等一段时间后重试,以增加shuffle - 操作的稳定性
- 增加SortShuffle 排序操作阈值,
-
7.4 JVM调优
- 降低cache 操作的内存占比,1静态内存管理机制,需要调节,2统一内存管理机制,堆内存被划分为了两块,Storage 和Execution
- 增大Executor 堆外内存,有时去拉取Executor数据时,Executor可能已经由于内存溢出挂掉了
- 增大连接等待时长,Executor优先从本地关联的BlockManager获取数据,获取不到会去其他节点上获取数据,反复拉取不到会导致DAGScheduler反复提交几次stage,TaskScheduler反复提交几次Task,大大延长作业运行时间
参考文档:
https://zhuanlan.zhihu.com/p/463537198
https://www.bbsmax.com/A/q4zVE2aWdK/
https://www.cnblogs.com/kdy11/p/10943547.html
《spark官方文档》
《Spark快速大数据分析》
《Apache Spark 2.0.2 中文文档》
相关文章:
spark笔记
spark笔记 1. 概述 Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎;Spark提供内存计算,将计算结果直接放在内存中,减少了迭代计算的IO开销,有更高效的运算效率。 1.1 Spark核心模块 Spark Core:提供S…...
丢失了packet.dll原因和解决方法全面指南
packet.dll是Windows操作系统中的一个重要文件,它主要用于网络通信,如果丢失了这个文件,可能会导致网络连接问题。本文将探讨packet.dll文件丢失的原因,并提供相应的解决方法。 一、丢失packet.dll文件的原因 1. 病毒感染&#x…...
算法练习随记(三)
1.全排列 给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。 示例 1: 输入:nums [1,2,3] 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]示例 2: 输入&#x…...
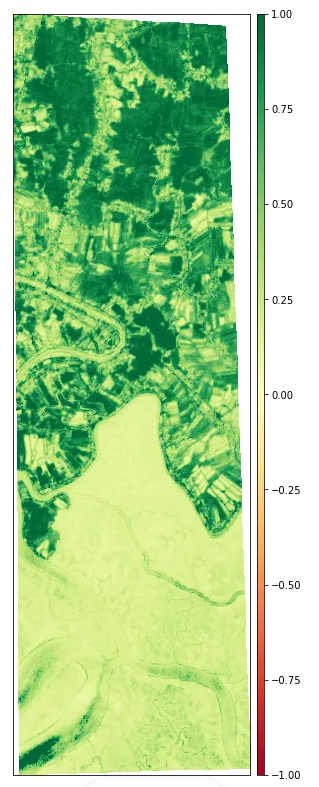
基于Python 进行卫星图像多种指数分析
一、前言本文帮助读者更好地了解卫星数据以及使用 Python 探索和分析哨兵2卫星数号数据在Sundarbans地区的不同方法。二、Sundarbans研究区孙德尔本斯(Sundarbans)是恒河、雅鲁藏布江和梅克纳河在孟加拉湾汇合形成的三角洲中最大的红树林区之一。 孙德尔…...
综合复习(C++,字符串,数学))
(Week 15)综合复习(C++,字符串,数学)
文章目录T1 [Daimayuan]删删(C,字符串)输入格式输出格式样例输入样例输出数据规模解题思路T2 [Daimayuan]快快变大(C,区间DP)输入格式输出格式样例输入样例输出数据规模解题思路T3 [Daimayuan]饿饿 饭饭2&a…...

迪赛智慧数——柱状图(正负条形图):“光棍”排行榜TOP10省份
效果图 中国单身男女最多的省份是广东,广东的人口是全国最多的。人口多了,单身的人也会多,单身女性324万,男性498万。全国第二的省份是四川省,单身女性256万,单身男性296万。 数据源:静态数据…...

IDEA集成chatGTP让你编码如虎添翼
第一步,打开您的IDEA, 打开首选项(Preference) -> 插件(Plugin) 在插件市场搜索 chatGPT, 点击安装 安装完毕后会提示您重启IDE, 重启IDEA. 重启后您会发现窗口,右边条上 竖着挂着个chatGPT按钮了。 第二步、配置APIkey或accessToken(二选一,推荐accessToken无费用…...
 方法、Python3 File readline() 方法)
Python3 os.close() 方法、Python3 File readline() 方法
Python3 os.close() 方法 概述 os.close() 方法用于关闭指定的文件描述符 fd。 语法 close()方法语法格式如下: os.close(fd);参数 fd -- 文件描述符。 返回值 该方法没有返回值。 实例 以下实例演示了 close() 方法的使用: #!/usr/bin/python3…...
Vision Pro 自己写的一些自定义工具(c#)
目录前言一、保存图片工具1、展示2、源码下载地址二、3D图片格式转化1、展示2、源码下载地址三、所有工具汇总下载地址前言 自己用c#写的一些visionPro自定义工具,便于使用的时候直接拿出来,后续会不断添加新的工具。 想看怎么使用c#写visionPro自定义…...

ARM/FPGA/DSP板卡选型大全,总有一款适合您
创龙科技ARM/FPGA/DSP嵌入式板卡选型大全2023.2版本正式发布!接下来,跟着我们一起看看有哪些亮点吧! 6大主流工业处理器原厂 创龙科技现有30多条产品线,覆盖工业自动化、能源电力、仪器仪表、通信、医疗、安防等工业领域,与6大主流工业处理器原厂强强联合,包括德州仪器…...

【C语言蓝桥杯每日一题】—— 既约分数
【C语言蓝桥杯每日一题】—— 既约分数😎前言🙌既约分数🙌递归版解题代码:😍非递归版解题代码:😍总结撒花💞既约分数😎)😎博客昵称:博客小梦 &…...
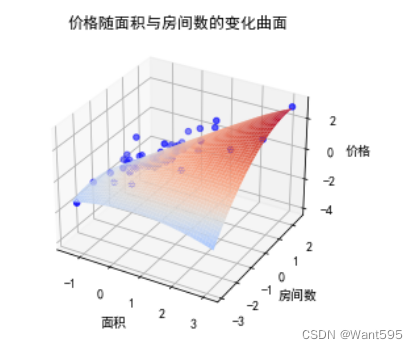
【机器学习】线性回归
文章目录前言一、单变量线性回归1.导入必要的库2.读取数据3.绘制散点图4.划分数据5.定义模型函数6.定义损失函数7.求权重向量w7.1 梯度下降函数7.2 最小二乘法8.训练模型9.绘制预测曲线10.试试正则化11.绘制预测曲线12.试试sklearn库二、多变量线性回归1.导入库2.读取数据3.划分…...

用ChatGPT学习多传感器融合中的基础知识
困惑与解答: 问题:匈牙利算法中的增广矩阵路径是什么意思 解答: 匈牙利算法是解决二分图最大匹配的经典算法之一。其中的增广矩阵路径指的是在当前匹配下,从一个未匹配节点开始,沿着交替路(交替路是指依次…...

PyCharm2020介绍
PyCharm2020PyCharm2020安装过程PyCharm2020安装包1、PyCharm2020介绍2、PyCharm2020特点3、PyCharm2020特点4、PyCharm2020PyCharm2020安装过程 PyCharm2020安装过程安装步骤点击此链接。 PyCharm2020安装包 链接:https://pan.baidu.com/s/19R3nJx6wMyNBU9oY4N4n…...
Le Potato + Jumbospot MMDVM热点盒子
最近才留意到,树莓派受到编程圈一定瞩目之后,智慧的同胞早已悄咪咪的搞了一堆xx派出来,本来对于香橙派,苹果派,土豆派和香蕉派是不感冒的,但是因为最近树莓派夸张的二级市场价格和断供,终于还是…...
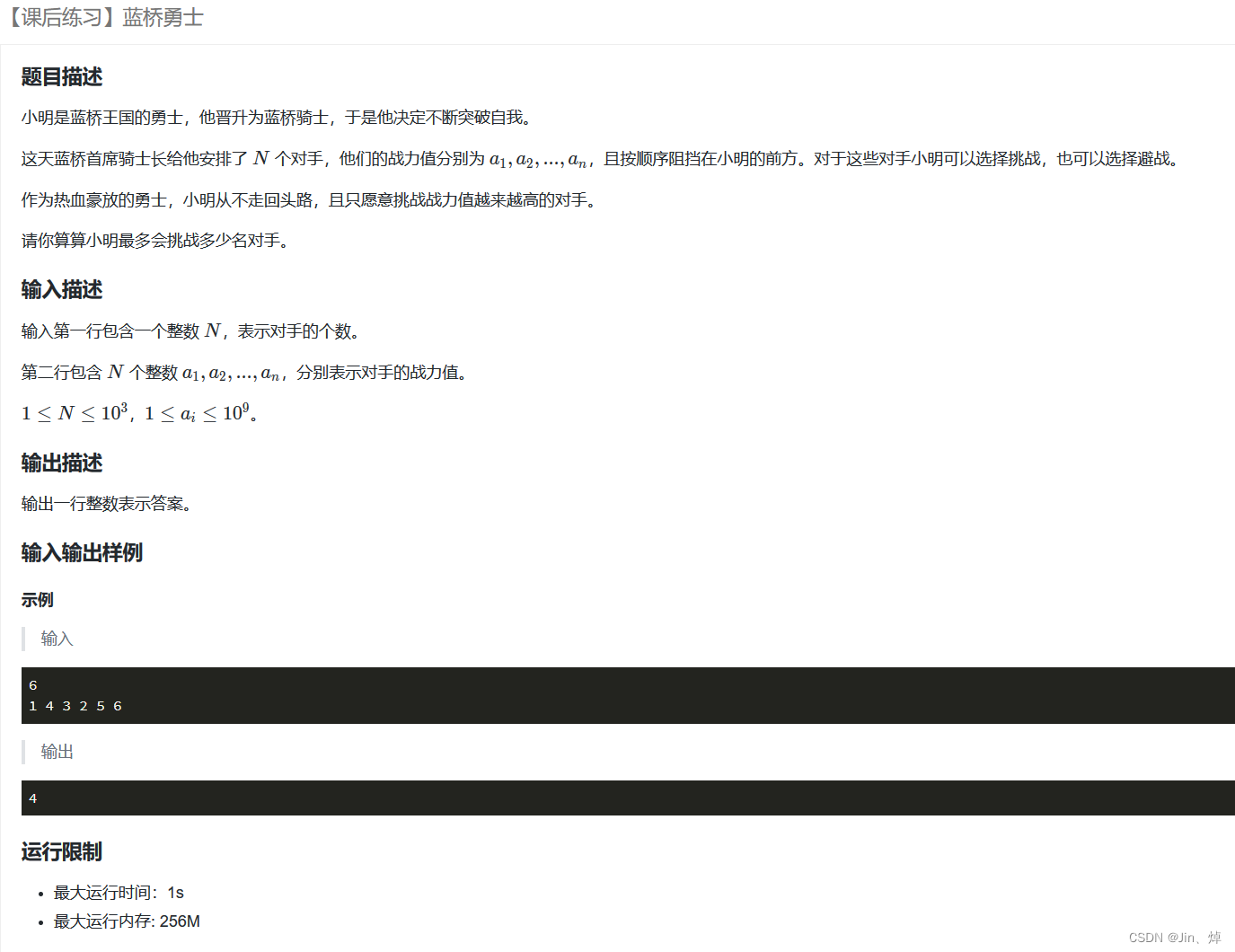
蓝桥杯第19天(Python)(疯狂刷题第2天)
题型: 1.思维题/杂题:数学公式,分析题意,找规律 2.BFS/DFS:广搜(递归实现),深搜(deque实现) 3.简单数论:模,素数(只需要…...
(五)手把手带你搭建精美简洁的个人时间管理网站—基于Axure的首页原型设计
🌟所属专栏:献给榕榕🐔作者简介:rchjr——五带信管菜只因一枚 😮前言:该专栏系为女友准备的,里面会不定时发一些讨好她的技术作品,感兴趣的小伙伴可以关注一下~👉文章简介…...

阿里面试:为什么MySQL不建议使用delete删除数据?
MySQL是一种关系型数据库管理系统,它的数据存储是基于磁盘上的文件系统实现的。MySQL将数据存储在表中,每个表由一系列的行和列组成。每一行表示一个记录,每一列表示一个字段。表的结构由其列名、数据类型、索引等信息组成。 MySQL的数据存储…...

低代码开发公司:用科技强力开启产业分工新时代!
实现办公自动化,是不少企业的共同追求。低代码开发公司会遵循时代发展规律,注入强劲的科技新生力量,在低代码开发市场厚积爆发、努力奋斗,推动企业数字化转型升级,为每一个企业的办公自动化升级创新贡献应有的力量。 一…...
)
参考mfa官方文档实践笔记(亲测)
按顺序执行以下指令: conda create -n aligner -c conda-forge montreal-forced-alignerconda config --add channels conda-forgeconda activate alignerconda install pytorch torchvision torchaudio pytorch-cuda11.7 -c pytorch -c nvidia 如果报错࿱…...

Obsidian笔记AI化:AnythingLLM带来的知识管理革新
Obsidian笔记AI化:AnythingLLM带来的知识管理革新 【免费下载链接】anything-llm The all-in-one AI productivity accelerator. On device and privacy first with no annoying setup or configuration. 项目地址: https://gitcode.com/GitHub_Trending/an/anyth…...

代码编辑器世纪大战:VS Code vs JetBrains IDE vs Zed全面对比
Visual Studio Code、IntelliJ IDEA/PhpStorm/WebStorm、Zed——这三种编辑器代表了三代程序员的生产力哲学。本文从响应速度、生态成熟度、AI赋能、协作能力四个维度进行深度横评。 一、三种编辑器的基因差异 VS Code:开放生态的胜利 VS Code的核心优势不是功能&am…...

STM32H743实战笔记:用SN65HVD230驱动14个伺服电机,1M波特率稳不稳?
STM32H743工业级CAN总线实战:14伺服电机集群控制与SN65HVD230极限测试 在工业机器人关节控制领域,多电机协同作业对总线通讯的实时性和稳定性提出严苛要求。最近完成的一个AGV底盘项目让我对STM32H743的CANopen主站性能有了全新认识——当需要同时驱动14…...

红外敏感薄膜
简 介: 【实验记录】测试废弃红外发光薄膜的光敏特性。使用紫外和红外发光二极管分别照射不同颜色的红外敏感薄膜,观察其发光反应。结果显示:紫外线照射未引发明显发光;红外线照射仅产生微弱亮光(可能是摄像头感应所致…...

在多轮对话中感受Taotoken路由策略的稳定性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话中感受Taotoken路由策略的稳定性 1. 引言:多轮对话的稳定性挑战 在构建依赖大语言模型的对话应用时&#x…...

告别盲选!Space Thumbnails让3D模型文件在Windows资源管理器中“活“起来
告别盲选!Space Thumbnails让3D模型文件在Windows资源管理器中"活"起来 【免费下载链接】space-thumbnails Generates preview thumbnails for 3D model files. Provide a Windows Explorer extensions that adds preview thumbnails for 3D model files.…...

后端架构师转型AI智能体落地:收藏这份3个月进阶指南,轻松玩转不确定性系统
本文为后端/全栈/架构师提供了一条从零到一掌握AI智能体落地的技术路径。文章首先分析了架构师在AI智能体落地中的核心优势,如分布式系统设计、数据库设计、API封装等;接着,提出了一个分四阶段的三个月进阶计划,包括掌握核心范式、…...

编程统计公司内部资料查阅使用数据,优化资料分类存储方式。提升职场员工工作查阅办事效率。
构建一个公司内部资料查阅使用统计与资料分类存储优化的商务智能示例项目,去营销化、中立化,仅用于学习与工程实践参考。一、实际应用场景描述在中大型企业中,内部资料(制度、流程文档、技术手册、项目档案)数量庞大&a…...

Flutter GetX实战:从Provider迁移到GetX,我的开发效率提升了多少?
Flutter GetX实战:从Provider迁移到GetX的效率革命 当Flutter开发团队面临状态管理方案的选择时,往往会陷入一种甜蜜的烦恼——官方推荐的Provider虽然稳定可靠,但第三方库GetX却以"全家桶"式的解决方案不断吸引开发者的目光。作为…...

3步解锁鸣潮120帧:你的终极游戏体验优化指南
3步解锁鸣潮120帧:你的终极游戏体验优化指南 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 还在为《鸣潮》游戏中的60帧限制而烦恼吗?明明拥有强大的硬件配置,却无法充…...