大数据-151 Apache Druid 集群模式 配置启动【上篇】 超详细!
点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(已更完)
- ClickHouse(已更完)
- Kudu(已更完)
- Druid(正在更新…)
章节内容
上节我们完成了如下的内容:
- Apache Druid 系统架构 核心组件介绍
- Druid 单机模式配置启动

整体介绍
Apache Druid 是一种高性能、分布式的列式存储数据库,专门用于实时分析和查询大规模数据集。它适用于 OLAP(在线分析处理)场景,尤其在处理大数据实时流时表现优异。Druid 的架构由多个组件组成,主要包括数据摄取、存储、查询和管理。
在集群配置方面,Druid 通常由以下节点构成:
- 数据摄取层:使用 MiddleManager 节点来处理数据的实时摄取,负责从不同数据源(如 Kafka、HDFS 等)读取数据并进行实时处理。
- 存储层:数据存储在 Historical 节点上,这些节点负责存储和管理较老的数据,支持高效的查询。数据被以列式格式存储,优化了查询性能。
- 查询层:Broker 节点充当查询路由器,接受用户的查询请求并将其分发到相应的 Historical 或 Real-time 节点,然后将结果汇总返回给用户。
- 协调层:Coordinator 节点负责集群的状态管理和数据分配,确保数据均匀分布并自动处理节点故障。
Druid 的配置文件允许用户自定义参数,如 JVM 设置、内存分配和数据分片策略,以便根据不同的工作负载和性能需求进行优化。此外,Druid 还支持多种查询语言,包括 SQL,便于用户进行灵活的数据分析。整体上,Druid 提供了一种高效、可扩展的解决方案,适合需要快速实时分析的大数据应用场景。
集群规划
集群部署采用的分配如下:
- 主节点部署 Coordinator 和 Overlord 进程
- 数据节点运行 Historical 和 MiddleManager 进程
- 查询节点 部署Broker 和 Router 进程

我的实机部署情况:
- h121.wzk.icu 2C4G ZooKeeper、Kafka、Druid
- h122.wzk.icu 2C4G ZooKeeper、Kafka、Druid、MySQL(之前Hive时搭建)
- h123.wzk.icu 2C2G ZooKeeper、Druid
环境变量
vim /etc/profile
写入的内容如下:
# druid
export DRUID_HOME=/opt/servers/apache-druid-30.0.0
export PATH=$PATH:$DRUID_HOME/bin

配置文件
将 Hadoop 配置文件:
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
上述文件链接到 conf/druid/cluster/_common 下
执行下面的Shell:
cd $DRUID_HOME/conf/druid/cluster/_common
ln -s $HADOOP_HOME/etc/hadoop/core-site.xml core-site.xml
ln -s $HADOOP_HOME/etc/hadoop/hdfs-site.xml hdfs-site.xml
ln -s $HADOOP_HOME/etc/hadoop/yarn-site.xml yarn-site.xml
ln -s $HADOOP_HOME/etc/hadoop/mapred-site.xml mapred-site.xml
ls
执行结果如下图所示:

MySQL
将MySQL驱动链接到:$DRUID_HOME/extensions/mysql-metadata-storage 中
cd $DRUID_HOME/extensions/mysql-metadata-storage
cp $HIVE_HOME/lib/mysql-connector-java-8.0.19.jar mysql-connector-java-8.0.19.jar
ls
执行结果如下图所示:

修改配置
vim $DRUID_HOME/conf/druid/cluster/_common/common.runtime.properties
我们要修改如下的内容:
# 增加"mysql-metadata-storage"
druid.extensions.loadList=["mysql-metadata-storage", "druid-hdfs-storage", "druid-kafka-indexing-service", "druid-datasketches", "druid-multi-stage-query"]# 每台机器写自己的ip或hostname
# 我这里是h121节点
druid.host=h121.wzk.icu
# 填写zk地址
druid.zk.service.host=h121.wzk.icu:2181,h122.wzk.icu:2181,h123.wzk.icu:2181
druid.zk.paths.base=/druid# 注释掉前面 derby 的配置
# 增加 mysql 的配置
druid.metadata.storage.type=mysql
druid.metadata.storage.connector.connectURI=jdbc:mysql://h122.wzk.icu:3306/druid
druid.metadata.storage.connector.user=hive
druid.metadata.storage.connector.password=hive@wzk.icu# 注释掉local的配置
# 增加HDFS的配置,即使用HDFS作为深度存储
druid.storage.type=hdfs
druid.storage.storageDirectory=/druid/segments# 注释掉 indexer.logs For local disk的配置
# 增加 indexer.logs For HDFS 的配置
druid.indexer.logs.type=hdfs
druid.indexer.logs.directory=/druid/indexing-logs
修改截图如下:

修改截图如下所示:

coordinator-overlord
参数大小根据实际情况调整
vim $DRUID_HOME/conf/druid/cluster/master/coordinator-overlord/jvm.config
原来的配置如下图所示:
-server
-Xms15g
-Xmx15g
-XX:+ExitOnOutOfMemoryError
-XX:+UseG1GC
-Duser.timezone=UTC
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
-Dderby.stream.error.file=var/druid/derby.log
修改内容如下所示:
-server
-Xms512m
-Xmx512m
-XX:+ExitOnOutOfMemoryError
-XX:+UseG1GC
-Duser.timezone=UTC+8
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
对应的截图如下所示:

historical
参数大小根据实际情况调整
vim $DRUID_HOME/conf/druid/cluster/data/historical/jvm.config
原配置内容如下所示:
-server
-Xms8g
-Xmx8g
-XX:MaxDirectMemorySize=13g
-XX:+ExitOnOutOfMemoryError
-Duser.timezone=UTC
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
修改内容如下:
-server
-Xms512m
-Xmx512m
-XX:MaxDirectMemorySize=1g
-XX:+ExitOnOutOfMemoryError
-Duser.timezone=UTC+8
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
修改结果如下图:

此外还有一个参数:
vim $DRUID_HOME/conf/druid/cluster/data/historical/runtime.properties
原配置内容如下:
druid.processing.buffer.sizeBytes=500MiB
修改为如下内容:
# 相当于 50MiB
druid.processing.buffer.sizeBytes=50000000
修改的截图如下:

备注:
- druid.processing.buffer.sizeBytes 每个查询用于聚合的对外哈希表的大小
- maxDirectMemory = druid.processing.buffer.sizeBytes * (durid.processing.numMergeBuffers + druid.processing.numThreads + 1)
- 如果 druid.processing.buffer.sizeBytes太大的话,需要加大 maxDirectMemory,否则 historical服务无法启动
middleManager
vim $DRUID_HOME/conf/druid/cluster/data/middleManager/jvm.config
原配置:
-server
-Xms128m
-Xmx128m
-XX:+ExitOnOutOfMemoryError
-Duser.timezone=UTC
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
配置如下(没有修改):
-server
-Xms128m
-Xmx128m
-XX:+ExitOnOutOfMemoryError
-Duser.timezone=UTC+8
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
修改的截图如下:

【续接下篇!】
相关文章:
大数据-151 Apache Druid 集群模式 配置启动【上篇】 超详细!
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完&am…...

CentOS8.5.2111(3)实验之DHCP服务器架设
一、实验目标 1.掌握DHCP服务器的主配置文件各项申明参数及操作及其含义 2. 具备DHCP 服务器、中继服务器的配置能力 3. 具备测试客户端正常获取服务器分配地址的能力 4. 具备DHCP服务器故障排除能力 二、实训原理/流程 (一)项目背景 …...
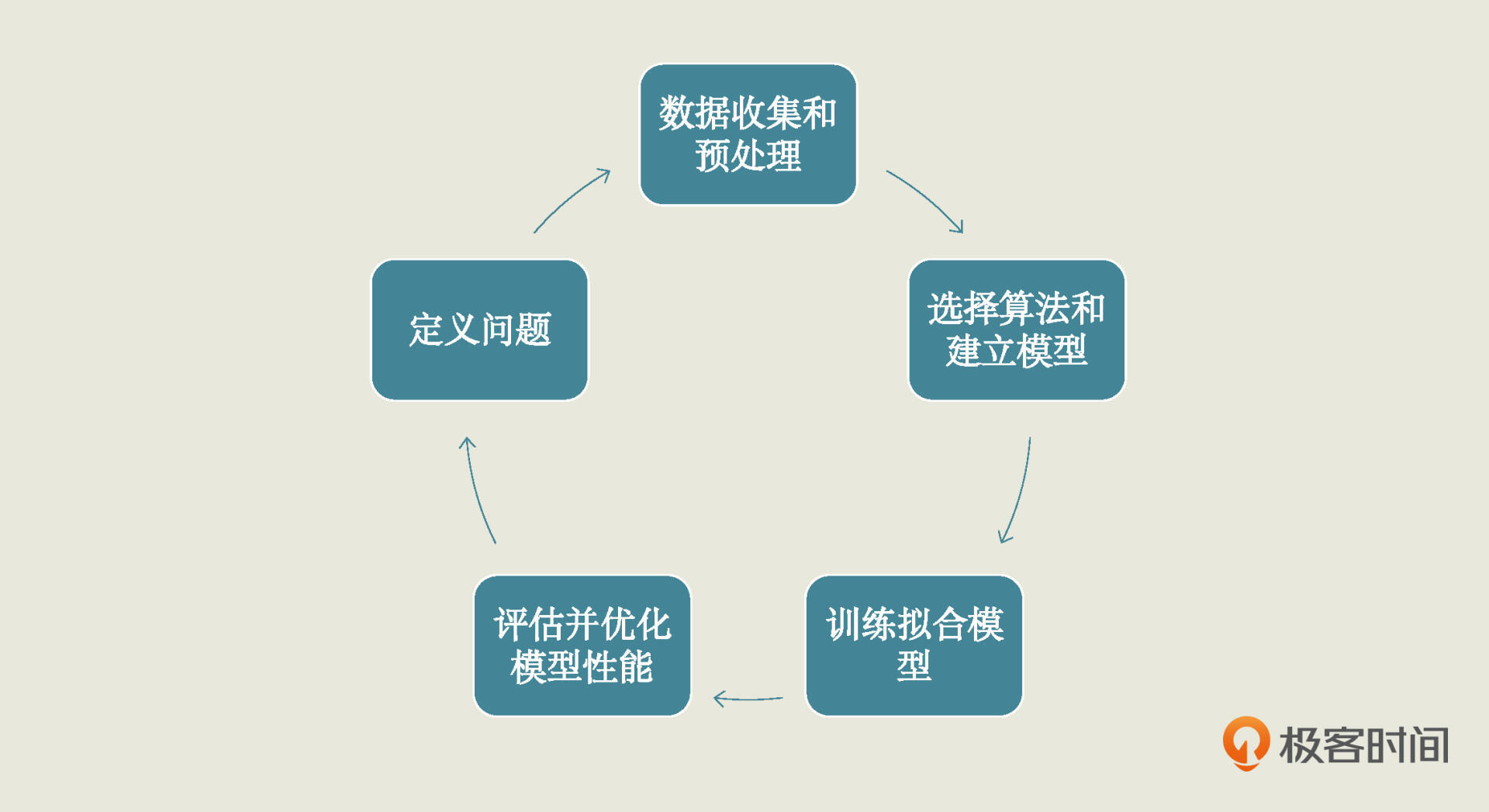
机器学习(4):机器学习项目步骤(一)——定义问题
1. 机器学习项目的五大步骤 定义问题 收集数据和预处理 选择算法和确定模型 训练拟合模型 评估优化模型性能 2. 定义问题的主要任务 刨析业务场景,设定清晰目标,同时还要确定当前问题属于哪一种机器学习类型。 3. “易速鲜花”项目案例 项目任务&a…...

C#中Socket通信常用的方法
创建Socket 在C#中创建一个Socket对象的基本步骤如下: 引入命名空间: 首先,确保你的文件顶部包含了以下命名空间的引用: using System.Net; using System.Net.Sockets; 创建Socket实例: 你可以创建一个Socket实例&am…...

【JavaEE】——单例模式引起的多线程安全问题:“饿汉/懒汉”模式,及解决思路和方法(面试高频)
阿华代码,不是逆风,就是我疯,你们的点赞收藏是我前进最大的动力!!希望本文内容能够帮助到你! 目录 一:单例模式(singleton) 1:概念 二:“饿汉模…...

huggingface实现中文文本分类
目录 1 自定义数据集 2 分词 2.1 重写collate_fn方法 3 用BertModel加载预训练模型 4 模型试算 5 定义下游任务 6 训练 7 测试 #导包 import torch from datasets import load_from_disk #用于加载本地磁盘的datasets文件 1 自定义数据集 #自定义数据集 #…...
基于python+控制台+txt文档实现学生成绩管理系统(含课程实训报告)
目录 第一章 需求分析 第二章 系统设计 2.1 系统功能结构 2.1.1 学生信息管理系统的七大模块 2.1.2 系统业务流程 2.2 系统开发必备环境 第三章 主函数设计 3.1 主函数界面运行效果图 3.2 主函数的业务流程 3.3 函数设计 第四章 详细设计及实现 4.1 学生信息录入模块的设计与实…...

Spring Boot 整合MyBatis-Plus 实现多层次树结构的异步加载功能
文章目录 1,前言2,什么是多层次树结构?3,异步加载的意义4,技术选型与实现思路5,具体案例5.1,项目结构5.2,项目配置(pom.xml)5.3,配置文件…...

网络工程师指南:防火墙配置与管理命令大全,零基础入门到精通,收藏这一篇就够了
本指南详细介绍了防火墙的配置与管理命令,涵盖了防火墙的工作原理、常见配置命令、安全策略与访问控制、日志管理与故障排查,并通过实战案例展示了如何有效防御网络攻击。通过学习本指南,网络工程师能够系统掌握防火墙的配置与管理技能&#…...

英特尔终于找到了Raptor Lake处理器崩溃与不稳定问题的根源
技术背景 在过去的几个月里,一些用户报告称他们的第13代和第14代Intel Core“Raptor Lake”处理器遇到了系统崩溃和不稳定的情况。这些问题最初在2024年7月底被英特尔识别出来,并且初步的诊断显示,这些问题与微码有关,该微码使CP…...

Shp2pb:Shapefile转Protocol Buffers的高效工具
Shp2pb是一个实用工具,专门用于将Shapefile(shp)格式转换为Protocol Buffers(protobuf)文件。这对于以更高效、更紧凑的方式处理地理数据特别有用。以下是关于如何安装和使用Shp2pb工具的详细说明,以及一个…...

Elasticsearch使用Easy-Es + RestHighLevelClient实现深度分页跳页
注意!!!博主只在测试环境试了一下,没有发到生产环境跑。因为代码还没写完客户说不用弄了( •̩̩̩̩_•̩̩̩̩ ) 也好,少个功能少点BUG 使用from size的时候发现存在max_result_window10000的限制&…...

基于ASRPRO的语音应答
做这个的起因是为了送女朋友,而且这东西本身很简单,所以在闲暇之余尝试了一下。 这个工程很简单,只通过对ASRPRO进行编程即可。 先看效果。(没有展示所有效果,后续会列出来所有对话触发) 语音助手示例1 语音助手示例2 代码部分使用天文Block编辑,找了一圈好像只…...

3D看车汽车案例,车模一键换皮肤,开关车门,轴距,电池功能
3D 汽车案例 网址: http://car.douchuanwei.com/...

数据结构-4.栈与队列
本篇博客给大家带来的是栈和队列的知识点, 其中包括两道面试OJ题 用队列实现栈 和 用栈实现队列. 文章专栏: Java-数据结构 若有问题 评论区见 欢迎大家点赞 评论 收藏 分享 如果你不知道分享给谁,那就分享给薯条, 如果分享不成功, 那我就会回你一下,那样你就分享成功啦. 你们的…...

芝士AI写作有什么特色? 大模型支撑,智能改写续写,让写作更轻松
又到了一年的毕业季,大学四年眨眼间匆匆就过去了,毕业,求职,考研,工作,升学,但是在这之前,我们必须要完成论文的写作,这也是每一位大学生都必须要面对~ 芝士AI官网&…...

【计网】从零开始学习http协议 --- http的请求与应答
如果你不能飞,那就跑; 如果跑不动,那就走; 实在走不了,那就爬。 无论做什么,你都要勇往直前。 --- 马丁路德金 --- 从零开始学习http协议 1 什么是http协议2 认识URL3 http的请求和应答3.1 服务端设计…...

记录linux环境下搭建本地MQTT服务器实现mqtt的ssl加密通讯
1、ubuntu安装mosquitto sudo apt-get update//安装服务端 sudo apt-get install mosquitto//安装客户端 sudo apt-get install mosquitto-clients 2、安装openssl 3、mqtts/tls加密传输 mosquitto原生支持了TLS加密,TLS(传输层安全)是SSL&…...

基于python+django+vue的电影数据分析及可视化系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、Vue项目源码、SSM项目源码 精品专栏:Java精选实战项目…...

HJ50-四则运算:栈的运用、中缀表达式转后缀表达式并计算结果
文章目录 题目一、分析1.1表达式预处理1.2中缀表达式转后缀1.3 后缀表达式计算结果 二、答案 题目 一、分析 通过利用栈将中缀表达式转换为后缀表达式,在根据后缀表达式计算运算结果。由于包含负数操作数的情况,并且操作数位数不固定为1,因此…...

RWKV7-1.5B-G1A快速上手:5分钟部署你的轻量级文本生成助手
RWKV7-1.5B-G1A快速上手:5分钟部署你的轻量级文本生成助手 1. 为什么选择RWKV7-1.5B-G1A 如果你正在寻找一个轻量级但功能强大的文本生成模型,RWKV7-1.5B-G1A绝对值得考虑。这个基于RWKV-7架构的模型在1.5B参数规模下展现了出色的性能,特别…...
)
保姆级教程:YOLOv8轻量化模型从训练到安卓部署全流程(附避坑指南)
保姆级教程:YOLOv8轻量化模型从训练到安卓部署全流程(附避坑指南) 在移动端实现实时目标检测一直是计算机视觉领域的热门方向。YOLOv8作为当前最先进的检测模型之一,其轻量化版本在安卓设备上的部署需求日益增长。本文将手把手带…...

Enhancing LLM Reasoning with Knowledge Graphs: A Faithful and Interpretable Approach
1. 为什么需要知识图谱增强LLM推理 最近两年,大型语言模型(LLM)的表现确实让人惊艳。我测试过GPT-4在代码生成、文案创作等场景的表现,效果确实超出预期。但当我尝试用LLM做知识密集型任务时,比如回答"贾斯汀比伯…...

2026实测不踩坑!6款成品PPT网站客观测评
2026实测不踩坑!6款成品PPT网站客观测评作为常年深耕AI工具测评的博主,日常需应对各类PPT创作需求,也经常收到粉丝咨询相关工具选择。经过实测多款成品PPT网站后,整理出6款适配性较强的平台,涵盖不同需求场景ÿ…...

Graphormer实战教程:基于ogb库加载PCQM4M数据微调模型示例
Graphormer实战教程:基于ogb库加载PCQM4M数据微调模型示例 1. 引言 Graphormer是一种创新的分子属性预测模型,采用纯Transformer架构的图神经网络设计。它专门针对分子图(原子-键结构)的全局结构建模与属性预测任务,…...

3步掌控《缺氧》存档:用Oni-Duplicity打造理想殖民地
3步掌控《缺氧》存档:用Oni-Duplicity打造理想殖民地 【免费下载链接】oni-duplicity A web-hosted, locally-running save editor for Oxygen Not Included. 项目地址: https://gitcode.com/gh_mirrors/on/oni-duplicity 你是否曾因《缺氧》中复制人负面特质…...
)
别再只盯着EMD了!滚动轴承故障诊断,试试VMD和MCKD这些新方法(附Python代码对比)
滚动轴承故障诊断:VMD与MCKD的实战对比与Python实现 滚动轴承作为旋转机械的核心部件,其健康状态直接影响设备运行安全。传统经验模态分解(EMD)虽广泛应用,但在处理强噪声和非平稳信号时存在明显局限。本文将深入解析变…...

UEFI SCT编译调试踩坑记:我的AARCH64环境搭建与问题解决实录
UEFI SCT编译调试实战:AARCH64环境搭建与疑难问题全解析 当你在深夜的办公室里盯着屏幕上闪烁的光标,第N次尝试编译UEFI SCT测试套件时,那种既熟悉又陌生的挫败感再次袭来。作为UEFI开发者,我们都经历过这样的时刻——官方文档看似…...

把openEuler当微服务跑:Docker Compose编排实战,管理Nginx+MySQL多容器应用
微服务架构下的openEuler容器化实践:NginxMySQL多容器编排指南 1. 云原生时代的轻量级操作系统选择 在容器化技术席卷全球的今天,开发者们越来越倾向于将操作系统本身也视为可编排的服务单元。openEuler作为一款专为云原生场景优化的Linux发行版…...

货车行车记录仪被破坏手工修复成功
由于视频记录了打架过程,很重要, 客户在第一次查看时没问题,再次想拷贝,发现内容都没有了只有USC文件,使用容量也有,如图 好在客户没有再次破坏,TS视频文件,同行通过恢复软件恢复&am…...