迁移学习案例-python代码
大白话
迁移学习就是用不太相同但又有一些联系的A和B数据,训练同一个网络。比如,先用A数据训练一下网络,然后再用B数据训练一下网络,那么就说最后的模型是从A迁移到B的。
迁移学习的具体形式是多种多样的,比如先用A训练好一个网络,然后复制这个网络的某几个层的参数到一个新的网络作为初始化的参数,然后用B数据去训练这个新网络。又或者,面对中文翻译的问题,中文翻译成英文和中文翻译成火星文,前几层在提取特征,可以共享参数层,后面几层由于任务不同就可以各自私有训练。
案例来源:李宏毅课程-机器学习-迁移学习
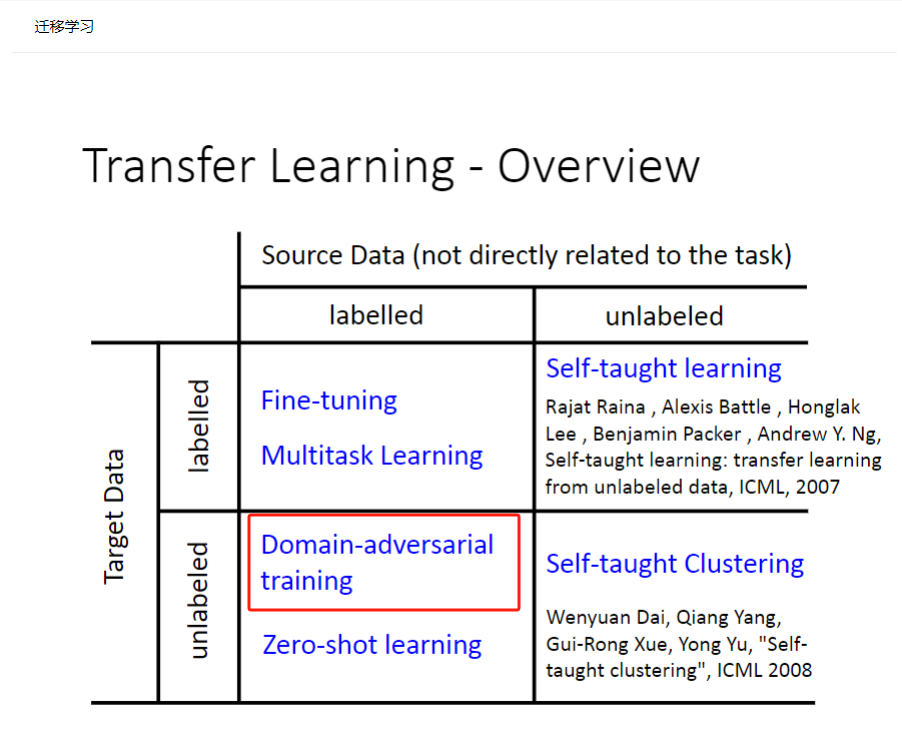
A数据:是源数据,量大效果好,并且有标签。

B数据:量少,没标签。

目的:希望用A数据先训练网络提取到关键特征,然后预测B数据的标签。但是把他们当作两个任务效果不佳,于是以一种迁移的方法解决--域对抗(先用A训练好模型,再直接用B测试,这样效果不佳;而是希望以一种“迁移”的方法,把A数据的知识拿到B上面用)
直接上代码
import matplotlib.pyplot as pltdef no_axis_show(img, title='', cmap=None):# imshow, 缩放模式为nearest。fig = plt.imshow(img, interpolation='nearest', cmap=cmap)# 不要显示axis。fig.axes.get_xaxis().set_visible(False)fig.axes.get_yaxis().set_visible(False)plt.title(title)titles = ['horse', 'bed', 'clock', 'apple', 'cat', 'plane', 'television', 'dog', 'dolphin', 'spider']
plt.figure(figsize=(18, 18))
for i in range(10):plt.subplot(1, 10, i+1)fig = no_axis_show(plt.imread(f'work/real_or_drawing/train_data/{i}/{500*i}.bmp'), title=titles[i])
plt.figure(figsize=(18, 18))
for i in range(10):plt.subplot(1, 10, i+1)fig = no_axis_show(plt.imread(f'work/real_or_drawing/test_data/0/' + str(i).rjust(5, '0') + '.bmp'))
import cv2
import matplotlib.pyplot as plt
titles = ['horse', 'bed', 'clock', 'apple', 'cat', 'plane', 'television', 'dog', 'dolphin', 'spider']
plt.figure(figsize=(18, 18))original_img = plt.imread(f'work/real_or_drawing/train_data/0/0.bmp')
plt.subplot(1, 5, 1)
no_axis_show(original_img, title='original')gray_img = cv2.cvtColor(original_img, cv2.COLOR_RGB2GRAY)
plt.subplot(1, 5, 2)
no_axis_show(gray_img, title='gray scale', cmap='gray')gray_img = cv2.cvtColor(original_img, cv2.COLOR_RGB2GRAY)
plt.subplot(1, 5, 2)
no_axis_show(gray_img, title='gray scale', cmap='gray')canny_50100 = cv2.Canny(gray_img, 50, 100)
plt.subplot(1, 5, 3)
no_axis_show(canny_50100, title='Canny(50, 100)', cmap='gray')canny_150200 = cv2.Canny(gray_img, 150, 200)
plt.subplot(1, 5, 4)
no_axis_show(canny_150200, title='Canny(150, 200)', cmap='gray')canny_250300 = cv2.Canny(gray_img, 250, 300)
plt.subplot(1, 5, 5)
no_axis_show(canny_250300, title='Canny(250, 300)', cmap='gray')
import cv2
import numpy as np
import paddleimport paddle.optimizer as optim
from paddle.io import DataLoader
from paddle.vision.datasets import DatasetFolder
from paddle.nn import Sequential, Conv2D, BatchNorm1D, BatchNorm2D, ReLU, MaxPool2D, Linear
from paddle.vision.transforms import Compose, Grayscale, Transpose, RandomHorizontalFlip, RandomRotation, Resize, ToTensor
class Canny(paddle.vision.transforms.transforms.BaseTransform):def __init__(self, low, high, keys=None):super(Canny, self).__init__(keys)self.low = lowself.high = highdef _apply_image(self, img):Canny = lambda img: cv2.Canny(np.array(img), self.low, self.high)return Canny(img)
source_transform = Compose([RandomHorizontalFlip(),RandomRotation(15),Grayscale(),Canny(low=170, high=300),# Transpose(),ToTensor()])
target_transform = Compose([Grayscale(),Resize((32, 32)),RandomHorizontalFlip(),RandomRotation(15, fill=(0,)),ToTensor()])source_dataset = DatasetFolder('work/real_or_drawing/train_data', transform=source_transform)
target_dataset = DatasetFolder('work/real_or_drawing/test_data', transform=target_transform)source_dataloader = DataLoader(source_dataset, batch_size=32, shuffle=True)
target_dataloader = DataLoader(target_dataset, batch_size=32, shuffle=True)
test_dataloader = DataLoader(target_dataset, batch_size=128, shuffle=False)
class FeatureExtractor(paddle.nn.Layer):def __init__(self):super(FeatureExtractor, self).__init__()self.conv = Sequential(Conv2D(1, 64, 3, 1, 1),BatchNorm2D(64),ReLU(),MaxPool2D(2),Conv2D(64, 128, 3, 1, 1),BatchNorm2D(128),ReLU(),MaxPool2D(2),Conv2D(128, 256, 3, 1, 1),BatchNorm2D(256),ReLU(),MaxPool2D(2),Conv2D(256, 256, 3, 1, 1),BatchNorm2D(256),ReLU(),MaxPool2D(2),Conv2D(256, 512, 3, 1, 1),BatchNorm2D(512),ReLU(),MaxPool2D(2))def forward(self, x):x = self.conv(x).squeeze()return xclass LabelPredictor(paddle.nn.Layer):def __init__(self):super(LabelPredictor, self).__init__()self.layer = Sequential(Linear(512, 512),ReLU(),Linear(512, 512),ReLU(),Linear(512, 10),)def forward(self, h):c = self.layer(h)return cclass DomainClassifier(paddle.nn.Layer):def __init__(self):super(DomainClassifier, self).__init__()self.layer = Sequential(Linear(512, 512),BatchNorm1D(512),ReLU(),Linear(512, 512),BatchNorm1D(512),ReLU(),Linear(512, 512),BatchNorm1D(512),ReLU(),Linear(512, 512),BatchNorm1D(512),ReLU(),Linear(512, 1),)def forward(self, h):y = self.layer(h)return y
feature_extractor = FeatureExtractor()
label_predictor = LabelPredictor()
domain_classifier = DomainClassifier()class_criterion = paddle.nn.loss.CrossEntropyLoss()
domain_criterion = paddle.nn.BCEWithLogitsLoss()optimizer_F = optim.Adam(parameters=feature_extractor.parameters())
optimizer_C = optim.Adam(parameters=label_predictor.parameters())
optimizer_D = optim.Adam(parameters=domain_classifier.parameters())
def train_epoch(source_dataloader, target_dataloader, lamb):'''Args:source_dataloader: source data的dataloadertarget_dataloader: target data的dataloaderlamb: 调控adversarial的loss系数。'''# D loss: Domain Classifier的loss# F loss: Feature Extrator & Label Predictor的loss# total_hit: 计算目前对了几笔 total_num: 目前经过了几笔running_D_loss, running_F_loss = 0.0, 0.0total_hit, total_num = 0.0, 0.0for i, ((source_data, source_label), (target_data, _)) in enumerate(zip(source_dataloader, target_dataloader)):# source_data = source_data.cuda()# source_label = source_label.cuda()# target_data = target_data.cuda()# 我们把source data和target data混在一起,否则batch_norm可能会算错 (两边的data的mean/var不太一样)mixed_data = paddle.concat([source_data, target_data], axis=0)domain_label = paddle.zeros([source_data.shape[0] + target_data.shape[0], 1])# 设定source data的label为1domain_label[:source_data.shape[0]] = 1# Step 1 : 训练Domain Classifierfeature = feature_extractor(mixed_data)# 因为我们在Step 1不需要训练Feature Extractor,所以把feature detach避免loss backprop上去。domain_logits = domain_classifier(feature.detach())# print('domain_logits.shape:', domain_logits.shape, 'domain_label.shape:', domain_label.shape)loss = domain_criterion(domain_logits, domain_label)# running_D_loss+= loss.numpy()[0]running_D_loss+= loss.numpy()# print('loss:', loss)loss.backward()optimizer_D.step()# Step 2 : 训练Feature Extractor和Domain Classifierclass_logits = label_predictor(feature[:source_data.shape[0]])domain_logits = domain_classifier(feature)# loss为原本的class CE - lamb * domain BCE,相减的原因同GAN中的Discriminator中的G loss。loss = class_criterion(class_logits, source_label) - lamb * domain_criterion(domain_logits, domain_label)# running_F_loss+= loss.numpy()[0]running_F_loss+= loss.numpy()loss.backward()optimizer_F.step()optimizer_C.step()optimizer_D.clear_grad()optimizer_F.clear_grad()optimizer_C.clear_grad()# print('class_logits.shape:', class_logits.shape, 'source_label.shape:', source_label.shape)# print('class_logits[0]:', class_logits[0], 'source_label[0]:', source_label[0])total_hit += np.sum((paddle.argmax(class_logits, axis=1) == source_label).numpy())total_num += source_data.shape[0]print(i, end='\r')return running_D_loss / (i+1), running_F_loss / (i+1), total_hit / total_num# 训练200 epochs
for epoch in range(200):train_D_loss, train_F_loss, train_acc = train_epoch(source_dataloader, target_dataloader, lamb=0.1)paddle.save(feature_extractor.state_dict(), f'extractor_model.pdparams')paddle.save(label_predictor.state_dict(), f'predictor_model.pdparams')print('epoch {:>3d}: train D loss: {:6.4f}, train F loss: {:6.4f}, acc {:6.4f}'.format(epoch, train_D_loss, train_F_loss, train_acc))训练结束,预测一波
result = []
label_predictor.eval()
feature_extractor.eval()
for i, (test_data, _) in enumerate(test_dataloader):test_data = test_dataclass_logits = label_predictor(feature_extractor(test_data))x = paddle.argmax(class_logits, axis=1).detach().numpy()result.append(x)import pandas as pd
result = np.concatenate(result)# Generate your submission
df = pd.DataFrame({'id': np.arange(0,len(result)), 'label': result})
df.to_csv('work/DaNN_submission.csv',index=False)
训练比较慢,还得是把代码转到cuda上才行,demo可以把epoch减小一点。
相关文章:
迁移学习案例-python代码
大白话 迁移学习就是用不太相同但又有一些联系的A和B数据,训练同一个网络。比如,先用A数据训练一下网络,然后再用B数据训练一下网络,那么就说最后的模型是从A迁移到B的。 迁移学习的具体形式是多种多样的,比如先用A训练…...

MCUboot 和 U-Boot区别
MCUboot 和 U-Boot 都是用于嵌入式系统的引导加载程序,但它们在一些方面存在区别: 功能特性 安全特性侧重不同 MCUboot :更专注于安全引导方面,强调安全启动、固件完整性验证和加密等安全功能。它提供了强大的安全机制来防止恶意…...

Apache OFBiz SSRF漏洞CVE-2024-45507分析
Apache OFBiz介绍 Apache OFBiz 是一个功能丰富的开源电子商务平台,包含完整的商业解决方案,适用于多种行业。它提供了一套全面的服务,包括客户关系管理(CRM)、企业资源规划(ERP)、订单管理、产…...

计算机毕业设计 饮食营养管理信息系统的设计与实现 Java实战项目 附源码+文档+视频讲解
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...

828华为云征文|华为云Flexus云服务器X实例部署——盲盒抽奖商城系统以及编译发布小程序
盲盒抽奖商城系统使用 thinkphp6.0 uniapp 开发,做到了全移动端兼容。一个系统不仅可以打包 小程序 还可以 打包APP ,H5 华为云Flexus云服务器X实例在安装搭建盲盒商城小程序方面具有显著优势,这些优势主要体现在以下几个方面: …...

优化理论及应用精解【12】
文章目录 最优化基础基本概念一、目标函数二、约束条件三、约束函数 可行域与可行点可行点可行域可行点与可行域的关系示例 最优值与可行域的关系1. 最优值一定在可行域内取得2. 可行域定义了最优解的搜索空间3. 最优值的存在性与可行域的性质有关4. 最优值与可行域的边界关系示…...

excel 填充内容的公式
多行填充快捷方式: 使用“CtrlEnter”键,这样所有选中的空单元格前就会自动添加上相同的字符。 对于多行填充,Excel提供了几个快捷键来提高工作效率: “CtrlR”用于向右填充数据。如果你在表格的某一列输入了数据,选…...

这款工具在手,前端开发轻松搞定!
这款工具在手,前端开发轻松搞定! 引言 在之前的一篇文章中,已经给大家分享了一款AI助手。尽管该助手能够生成前端代码,但遗憾的是缺少了实时预览的功能。而现在,这一缺憾已经被弥补——你只需要描述你的设计想法&…...

Hadoop三大组件之HDFS(一)
HDFS 简介 HDFS (Hadoop Distributed File System) 是一个分布式文件系统,用于存储文件,采用目录树结构来定位文件。它由多个服务器组成,每个服务器在集群中扮演不同的角色。 适合一次写入,多次读取的场景。文件创建、写入和关闭…...

基于Hadoop的NBA球员大数据分析及可视化系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、Vue项目源码、SSM项目源码 精品专栏:Java精选实战项目…...

docker容器安装nginx
docker安装nginx部署前端项目 拉取镜像 docker pull nginx:1.24.0运行容器 docker run --name nginx -p 80:80 -d nginx:1.24.0创建本地挂载的目录 mkdir -p /docker/nginx/conf mkdir -p /docker/nginx/log mkdir -p /docker/nginx/html复制运行的nginx配置到宿主机上 将…...

LC记录一:寻找旋转数组最小值、判断旋转数组是否存在给定元素
文章目录 33.搜索旋转排序数组81.搜索旋转排序数组||153.寻找旋转排序数组中的最小值154.寻找旋转排序数组中的最小值||参考链接 33.搜索旋转排序数组 https://leetcode.cn/problems/search-in-rotated-sorted-array/description/ 下面这张图片是LC154题官方题解提供的一个图…...

关于 JVM 个人 NOTE
目录 1、JVM 的体系结构 2、双亲委派机制 3、堆内存调优 4、关于GC垃圾回收机制 4.1 GC中的复制算法 4.2 GC中的标记清除算法 1、JVM 的体系结构 "堆"中存在垃圾而"栈"中不存在垃圾的原因: 堆(Heap) 用途ÿ…...

网络工程和信息安全专业应该考哪些证书?
网络工程和信息安全专业在校大学生可以考的网络信息安全方向证书有NISP一级、NISP二级、CISP-DSG、CISP-PTE! 一、NISP一级 NISP一级是网络安全行业入门证书! NISP一级报名条件:年满16周岁即可 NISP一级报名时间:随时可报 NI…...

ASP.NET Core 创建使用异步队列
示例图 在 ASP.NET Core 应用程序中,执行耗时任务而不阻塞线程的一种有效方法是使用异步队列。在本文中,我们将探讨如何使用 .NET Core 和 C# 创建队列结构以及如何使用此队列异步执行操作。 步骤 1:创建 EmailMessage 类 首先,…...

从Linux系统的角度看待文件-基础IO
目录 从Linux系统的角度看待文件 系统文件I/O open write read 文件操作的本质 vim中批量注释的方法 从Linux系统的角度看待文件 关于文件的共识: 1.空文件也要占用磁盘空间 2.文件内容属性 3.文件操作包括文件内容/文件属性/文件内容属性 4.文件路径文…...

总结之Coze 是一站式 AI Bot 开发平台——工作流使用及coze总结(三)
工作流介绍 工作流支持通过可视化的方式,对插件、大语言模型、代码块等功能进行组合,从而实现复杂、稳定的业务流程编排,例如旅行规划、报告分析等。 当目标任务场景包含较多的步骤,且对输出结果的准确性、格式有严格要求时&…...

汽车线束之故障诊断方案-TDR测试
当前,在汽车布局中的线束的性能要求越来越高。无法通过简单的通断测试就能满足性能传输要求。早起对智能化要求不高,比如没有激动雷达、高清摄像、中央CPU等。 近几年的智能驾驶对网络传输要求越来越高,不但是高速率,还需要高稳定…...

自己做个国庆75周年头像生成器
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的。 下载相关代码:【免费】《自己做个国庆75周年头像生成器》代码资源-CSDN文库 又是一年国庆节,今年使用国旗做…...

2k1000LA loongnix 安装java
问题: 客户 需要在 loongnix 上 使用 java 的程序。 情况说明: 使用 apt get 是无法 安装java 的。 按照的资料就行。 首先是 下载 loongarch64 的 java 的压缩包。这个我已经下载下来了。 社区下载地址: http://www.loongnix.cn/zh/api/…...

AI智能体架构设计:从成本黑洞到价值引擎的解耦之道
1. 从成本黑洞到价值引擎:为什么你的AI智能体架构正在吞噬预算又到了季度技术复盘会,财务那边递过来的云账单和工程人力成本,是不是又让你倒吸一口凉气?你看着报表上那个名为“AI智能体平台”的项目,它的资源消耗曲线几…...

量子软件测试的挑战与优化策略
1. 量子软件测试的挑战与机遇量子计算正在从实验室走向实际应用,随之而来的是对可靠量子软件的需求激增。与传统软件不同,量子程序面临三大独特挑战:首先,量子态的叠加性和纠缠性使得测试变得异常复杂。一个n量子比特系统可以同时…...

终极鼠标连点器使用指南:3分钟掌握高效自动化技巧
终极鼠标连点器使用指南:3分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,操作…...

基于MAX78000的离线鸟类声音识别:边缘AI从数据到部署全流程解析
1. 项目概述:当边缘AI“听懂”鸟鸣在野外生态监测或自家后院观鸟时,你是否有过这样的经历:听到一阵清脆或婉转的鸟鸣,却完全不知道是哪位“歌唱家”在表演?传统的鸟类识别依赖专家经验和图鉴比对,不仅门槛高…...

巨量投放总结
巨量商务管理平台 : https://business.oceanengine.com 巨量广告投放平台: https://ad.oceanengine.com 商务管理平台 账户 广告组 计划 广告投放平台 层级关系: 广告组 -> 计划 -> 创意 对应FB: 系列 - > 广告组 -> 广告...

交流电机驱动器的三种控制模式:前沿切相、后沿切相与同步模式详解
1. 项目概述:一个能玩出花的交流电机驱动器在汽车改装、工业控制或者一些创客项目里,驱动一个交流电机听起来简单,但想让它听话地变速、正反转,甚至实现软启动和精确同步,往往就得搬出笨重又昂贵的工业变频器。今天分享…...

sngan_projection论文解读:ICLR2018两大GAN技术的完美结合
sngan_projection论文解读:ICLR2018两大GAN技术的完美结合 【免费下载链接】sngan_projection GANs with spectral normalization and projection discriminator 项目地址: https://gitcode.com/gh_mirrors/sn/sngan_projection sngan_projection是一个实现了…...

Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例
Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例 想象一下,医生通过CT扫描将人体内部结构分层呈现,而GIS中的"渔网"工具同样能对城市路网进行"切片式"分析。这种空间离散化技术&…...

OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权
OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权 【免费下载链接】firmware Alternative IP Camera firmware from an open community 项目地址: https://gitcode.com/gh_mirrors/fir/firmware 还在为网络摄像头的封闭系统而烦恼吗?想要完全掌控…...

ZMJS,把 JavaScript 解释器放进 SAP ABAP 应用服务器之后,很多扩展思路会变得不一样
我今天看这个 oisee/zmjs 仓库时,最吸引人的不是它把 JavaScript 语法做进了 ABAP,而是它选择了一条非常 SAP 的路线,纯 ABAP、无外部依赖、无 Kernel Module、以类和接口的形式运行在 SAP 应用服务器内部。仓库自己的定位很直接,ZMJS 是一个面向 SAP ABAP 的 Mini JavaScr…...