基于 Seq2Seq 的中英文翻译项目(pytorch)
项目简介
本项目旨在使用 PyTorch 构建一个基于 Seq2Seq(编码器-解码器架构)的中英文翻译模型。我们将使用双语句子对的数据进行训练,最终实现一个能够将英文句子翻译为中文的模型。项目的主要步骤包括:
- 数据预处理:从数据集中提取英文和中文句子,并进行初步清洗和保存。
- 数据加载与分词:将预处理后的数据加载进内存,进行分词处理,并构建词汇表。
- 模型构建:实现 Seq2Seq 模型的编码器和解码器部分。
- 模型训练与验证:使用训练集对模型进行训练,并使用验证集评估模型性能。
- 测试与推理:使用训练好的模型进行实际的翻译测试。
Step 1: 数据预处理
目的
从原始数据集中提取英文和中文句子,并将其转换为模型能够使用的格式。
流程
- 读取文件:从给定的文本文件中读取每一行数据。
- 提取句子:每一行数据包含英文和中文句子,我们将其分割并提取出这两部分。
- 保存处理后的数据:将处理后的句子保存为两个单独的文件,一个保存英文句子,另一个保存中文句子。
代码
import pandas as pd# 加载数据文件并进行预处理
file_path = 'data/cmn.txt' # 请确保数据文件位于该路径下# 读取文件并处理每一行,提取英文和中文句子
data = []
with open(file_path, 'r', encoding='utf-8') as file:for line in file:# 每行数据使用制表符分割,提取英文和中文部分parts = line.strip().split('\t')if len(parts) >= 2:english_sentence = parts[0].strip()chinese_sentence = parts[1].strip()data.append([english_sentence, chinese_sentence])# 创建 DataFrame 保存提取的句子
df = pd.DataFrame(data, columns=['English', 'Chinese'])# 将处理后的英文和中文句子分别保存为两个文件
df['English'].to_csv('data/english_sentences.txt', index=False, header=False)
df['Chinese'].to_csv('data/chinese_sentences.txt', index=False, header=False)# 显示前几行以验证处理是否正确
print(df.head())
输出示例
English Chinese
0 Hi. 嗨。
1 Hi. 你好。
2 Run! 你跑吧!
3 Run! 你快跑!
4 Who? 是谁?
Step 2: 数据加载与分词
目的
将预处理后的数据加载进内存,对每个句子进行分词处理,并构建英文和中文的词汇表。
流程
- 定义分词器:英文使用基本的英文分词器,中文采用字符级分割。
- 构建词汇表:基于分词后的数据构建词汇表,并添加特殊标记,如
<unk>、<pad>、<bos>、<eos>。 - 将句子转换为索引序列:将分词后的句子转换为词汇表中的索引序列,准备用于模型的输入。
- 创建数据集和数据加载器:将处理后的数据封装成可用于模型训练的数据集和数据加载器。
代码
import torch
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator# 定义英文和中文的分词器
tokenizer_en = get_tokenizer('basic_english')# 中文分词器:将每个汉字作为一个 token
def tokenizer_zh(text):return list(text)# 构建词汇表函数
def build_vocab(sentences, tokenizer):def yield_tokens(sentences):for sentence in sentences:yield tokenizer(sentence)vocab = build_vocab_from_iterator(yield_tokens(sentences), specials=['<unk>', '<pad>', '<bos>', '<eos>'])vocab.set_default_index(vocab['<unk>'])return vocab# 从文件中加载句子
with open('data/english_sentences.txt', 'r', encoding='utf-8') as f:english_sentences = [line.strip() for line in f]with open('data/chinese_sentences.txt', 'r', encoding='utf-8') as f:chinese_sentences = [line.strip() for line in f]# 构建词汇表
en_vocab = build_vocab(english_sentences, tokenizer_en)
zh_vocab = build_vocab(chinese_sentences, tokenizer_zh)print(f'英文词汇表大小:{len(en_vocab)}')
print(f'中文词汇表大小:{len(zh_vocab)}')# 将句子转换为索引序列,并添加 <bos> 和 <eos>
def process_sentence(sentence, tokenizer, vocab):tokens = tokenizer(sentence)tokens = ['<bos>'] + tokens + ['<eos>']indices = [vocab[token] for token in tokens]return indices# 处理所有句子
en_sequences = [process_sentence(sentence, tokenizer_en, en_vocab) for sentence in english_sentences]
zh_sequences = [process_sentence(sentence, tokenizer_zh, zh_vocab) for sentence in chinese_sentences]# 示例:查看处理后的索引序列
print("示例英文句子索引序列:", en_sequences[0])
print("示例中文句子索引序列:", zh_sequences[0])
创建数据集和数据加载器
from torch.utils.data import Dataset, DataLoader
from torch.nn.utils.rnn import pad_sequenceclass TranslationDataset(Dataset):def __init__(self, src_sequences, trg_sequences):self.src_sequences = src_sequencesself.trg_sequences = trg_sequencesdef __len__(self):return len(self.src_sequences)def __getitem__(self, idx):return torch.tensor(self.src_sequences[idx]), torch.tensor(self.trg_sequences[idx])def collate_fn(batch):src_batch, trg_batch = [], []for src_sample, trg_sample in batch:src_batch.append(src_sample)trg_batch.append(trg_sample)src_batch = pad_sequence(src_batch, padding_value=en_vocab['<pad>'])trg_batch = pad_sequence(trg_batch, padding_value=zh_vocab['<pad>'])return src_batch, trg_batch# 创建数据集
dataset = TranslationDataset(en_sequences, zh_sequences)# 划分训练集和验证集
from sklearn.model_selection import train_test_split
train_data, val_data = train_test_split(dataset, test_size=0.1)# 创建数据加载器
batch_size = 32
train_dataloader = DataLoader(train_data, batch_size=batch_size, shuffle=True, collate_fn=collate_fn)
val_dataloader = DataLoader(val_data, batch_size=batch_size, shuffle=False, collate_fn=collate_fn)
Step 3: Seq2Seq 模型构建
目的
构建一个基于 Seq2Seq 结构的模型,用于序列到序列的翻译任务。Seq2Seq 模型主要包括两个部分:
- 编码器(Encoder):负责接收输入的英文句子,将其编码为上下文向量。
- 解码器(Decoder):根据编码器的输出上下文向量,逐字生成中文翻译。
编码器
import torch.nn as nnclass Encoder(nn.Module):def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):"""初始化编码器:param input_dim: 输入词汇表的大小(英文词汇表大小):param emb_dim: 词嵌入维度:param hid_dim: 隐藏层维度:param n_layers: LSTM 层数:param dropout: Dropout 概率"""相关文章:
)
基于 Seq2Seq 的中英文翻译项目(pytorch)
项目简介 本项目旨在使用 PyTorch 构建一个基于 Seq2Seq(编码器-解码器架构)的中英文翻译模型。我们将使用双语句子对的数据进行训练,最终实现一个能够将英文句子翻译为中文的模型。项目的主要步骤包括: 数据预处理:从数据集中提取英文和中文句子,并进行初步清洗和保存。…...

部标主动安全(ADAS+DMS)对接说明
1.前言 上一篇介绍了部标(JT/T1078)流媒体对接说明,这里说一下如何对接主动安全附件服务器。 流媒体的对接主要牵扯到4个方面: (1)平台端:业务端系统,包含前端呈现界面。 &#x…...
迭代器)
C++ STL(1)迭代器
文章目录 一、迭代器详解1、迭代器的定义与功能2、迭代器类型3、示例4、迭代器失效4.1、vector 迭代器失效分析4.2、list 迭代器失效分析4.3、set 与 map 迭代器失效分析 5、总结 前言: 在C标准模板库(STL)中,迭代器是一个核心概念…...

uview表单校验不生效问题
最近几次使用发现有时候会不生效,具体还没排查出来什么原因,先记录一下解决使用方法 <u--formlabelPosition"top"labelWidth"auto":model"form":rules"rules"ref"uForm" ><view class"…...

前端开发设计模式——单例模式
目录 一、单例模式的定义和特点: 1.定义: 2.特点: 二、单例模式的实现方式: 1.立即执行函数结合闭包实现: 2.ES6类实现: 三、单例模式的应用场景 1.全局状态管理: 2.日志记录器: …...

行情叠加量化,占据市场先机!
A股久违的3000点,最近都没有更新,现在终于对我们的市场又来点信息。相信在座的朋友这几天都是喜笑颜开,对A股又充满信心。当前行情好起来了,很多朋友又开始重回市场,研究股票学习量化,今天我们给大家重温下…...

大厂面试真题-ConcurrentHashMap怎么保证的线程安全?
ConcurrentHashMap是Java中的一个线程安全的哈希表实现,它通过一系列精妙的机制来保证线程安全。以下是ConcurrentHashMap保证线程安全的主要方式: 分段锁(Segment Locking,Java 1.8之前): 在Java 1.8之前的…...

【RabbitMQ】消息堆积、推拉模式
消息堆积 原因 消息堆积是指在消息队列中,待处理的消息数量超过了消费者处理能力,导致消息在队列中不断堆积的现象。通常有以下几种原因: 消息生产过快:在高流量或者高负载的情况下,生产者以极高的速率发送消息&…...
)
MySQL常用SQL语句(持续更新中)
文章目录 数据库相关表相关索引相关添加索引 编码相关系统变量相关 收录一些经常用到的sql 数据库相关 建数据库 CREATE DATABASE [IF NOT EXISTS] <数据库名> [[DEFAULT] CHARACTER SET <字符集名>] [[DEFAULT] COLLATE <校对规则名>];例如: C…...
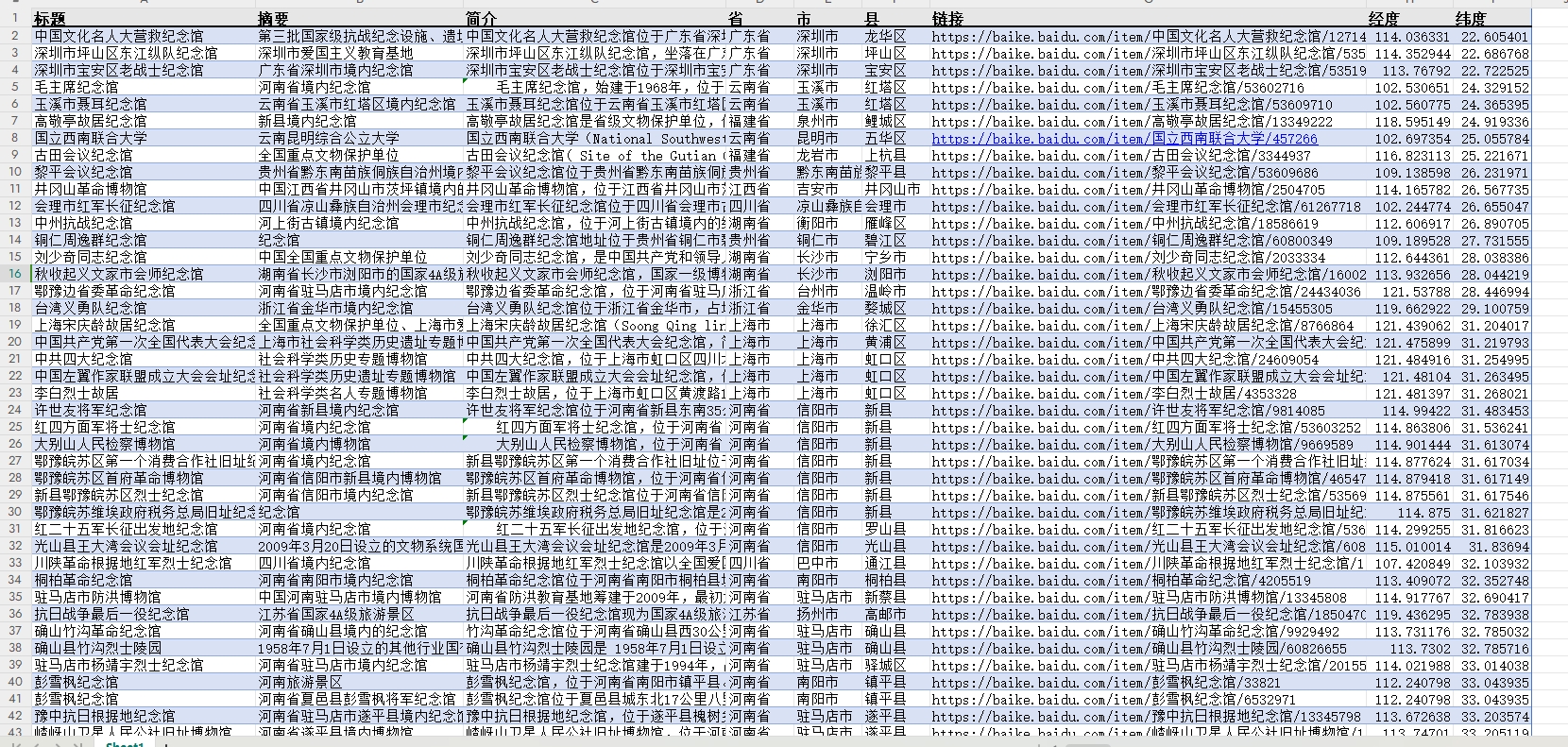
【更新】红色文化之红色博物馆数据集(经纬度+地址)
数据简介:红色博物馆作为国家红色文化传承与爱国主义教育的重要基地,遍布全国各地,承载着丰富的革命历史与文化记忆。本数据说明旨在汇总并分析全国范围内具有代表性的红色博物馆的基本信息,包括其地址、特色及教育意义࿰…...

Python项目Flask框架整合Redis
一、在配置文件中创建Redis连接信息 二、 实现Redis配置类 import redis from config.config import REDIS_HOST, REDIS_PORT, REDIS_PASSWD, REDIS_DB, EXPIRE_TIMEclass RedisDb():def __init__(self, REDIS_HOST, REDIS_PORT, REDIS_DB, EXPIRE_TIME, REDIS_PASSWD):# 建立…...

完整网络模型训练(一)
文章目录 一、网络模型的搭建二、网络模型正确性检验三、创建网络函数 一、网络模型的搭建 以CIFAR10数据集作为训练例子 准备数据集: #因为CIFAR10是属于PRL的数据集,所以需要转化成tensor数据集 train_data torchvision.datasets.CIFAR10(root&quo…...

高效便捷,体验不一样的韩语翻译神器
嘿,大家好啊!今天想跟大家聊聊我用过的几款翻译神器,特别是它们在翻译韩语时的那些小感受。作为一个偶尔需要啃啃韩语资料或者跟韩国朋友聊天的普通人,我真心觉得这些翻译工具简直就是我的救星! 一、福昕在线翻译 网址…...
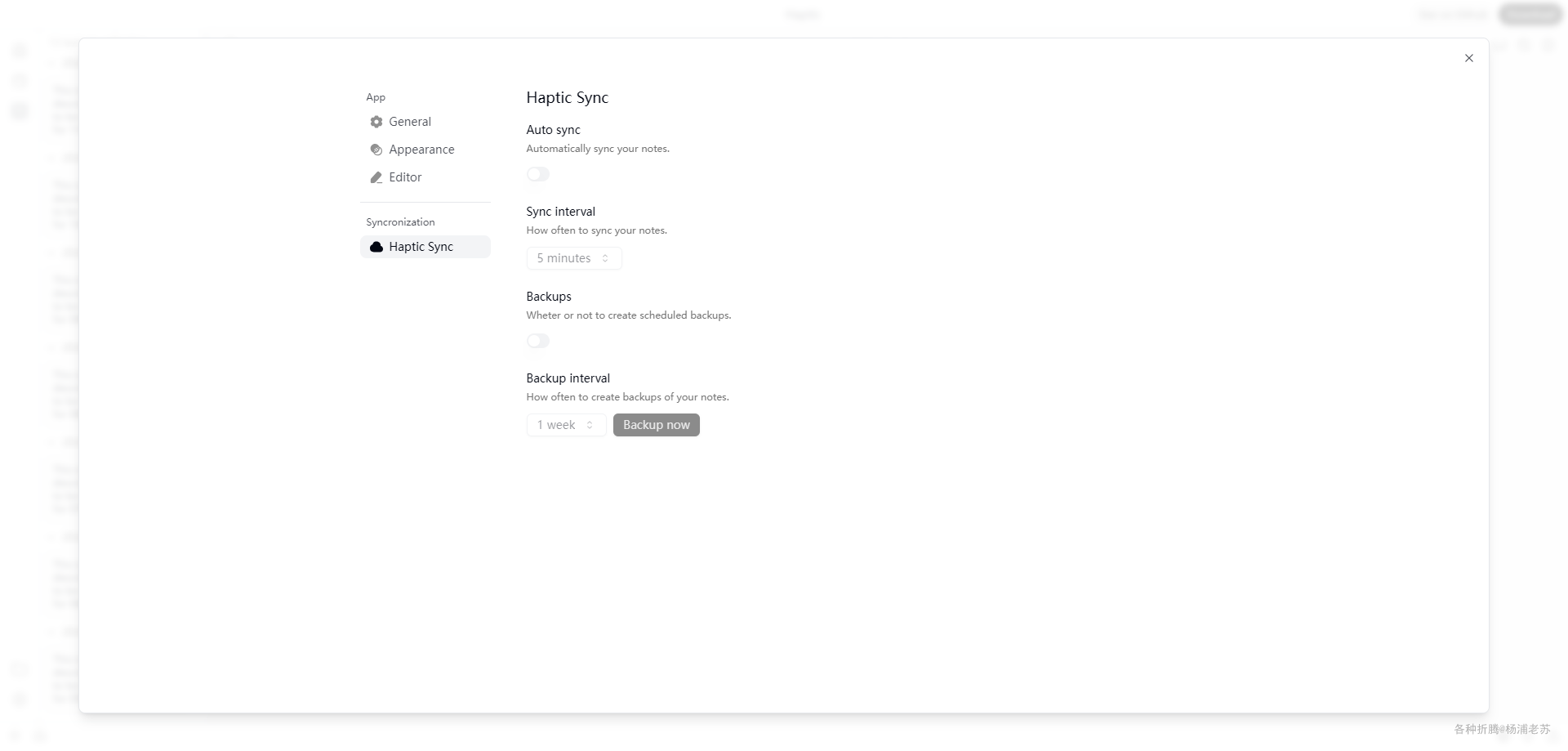
Markdown笔记管理工具Haptic
什么是 Haptic ? Haptic 是一个新的本地优先、注重隐私的开源 Markdown 笔记管理工具。它简约、轻量、高效,旨在提供您所需的一切,而不包含多余的功能。 目前官方提供了 docker 和 Mac 客户端。 Haptic 仍在积极开发中。以下是未来计划的一些…...

网络原理-传输层UDP
上集回顾: 上一篇博客中讲述了应用层如何自定义协议:确定传输信息,确定数据格式 应用层也有一些现成的协议:HTTP协议 这一篇博客中来讲述传输层协议 传输层 socket api都是传输层协议提供的(操作系统内核实现的了…...

C++中,如何使你设计的迭代器被标准算法库所支持。
iterator(读写迭代器) const_iterator(只读迭代器) reverse_iterator(反向读写迭代器) const_reverse_iterator(反向只读迭代器) 以经常介绍的_DList类为例,它的迭代…...

Java NIO 全面详解:掌握 `Path` 和 `Files` 的一切
在 Java 7 中引入的 NIO (New I/O) 为文件系统和流的操作带来了强大的能力,其中 Path 和 Files 是核心部分。Path 作为对文件路径的抽象,提供了灵活的方式处理文件系统中的路径;Files 则通过一系列静态方法,使得文件的读写、复制、…...

bluez免提协议hands-free介绍,全到无法想象,bluez hfp ag介绍
零. 前言 由于Bluez的介绍文档有限,以及对Linux 系统/驱动概念、D-Bus 通信和蓝牙协议都有要求,加上网络上其实没有一个完整的介绍Bluez系列的文档,所以不管是蓝牙初学者还是蓝牙从业人员,都有不小的难度,学习曲线也相对较陡,所以我有了这个想法,专门对Bluez做一个系统…...
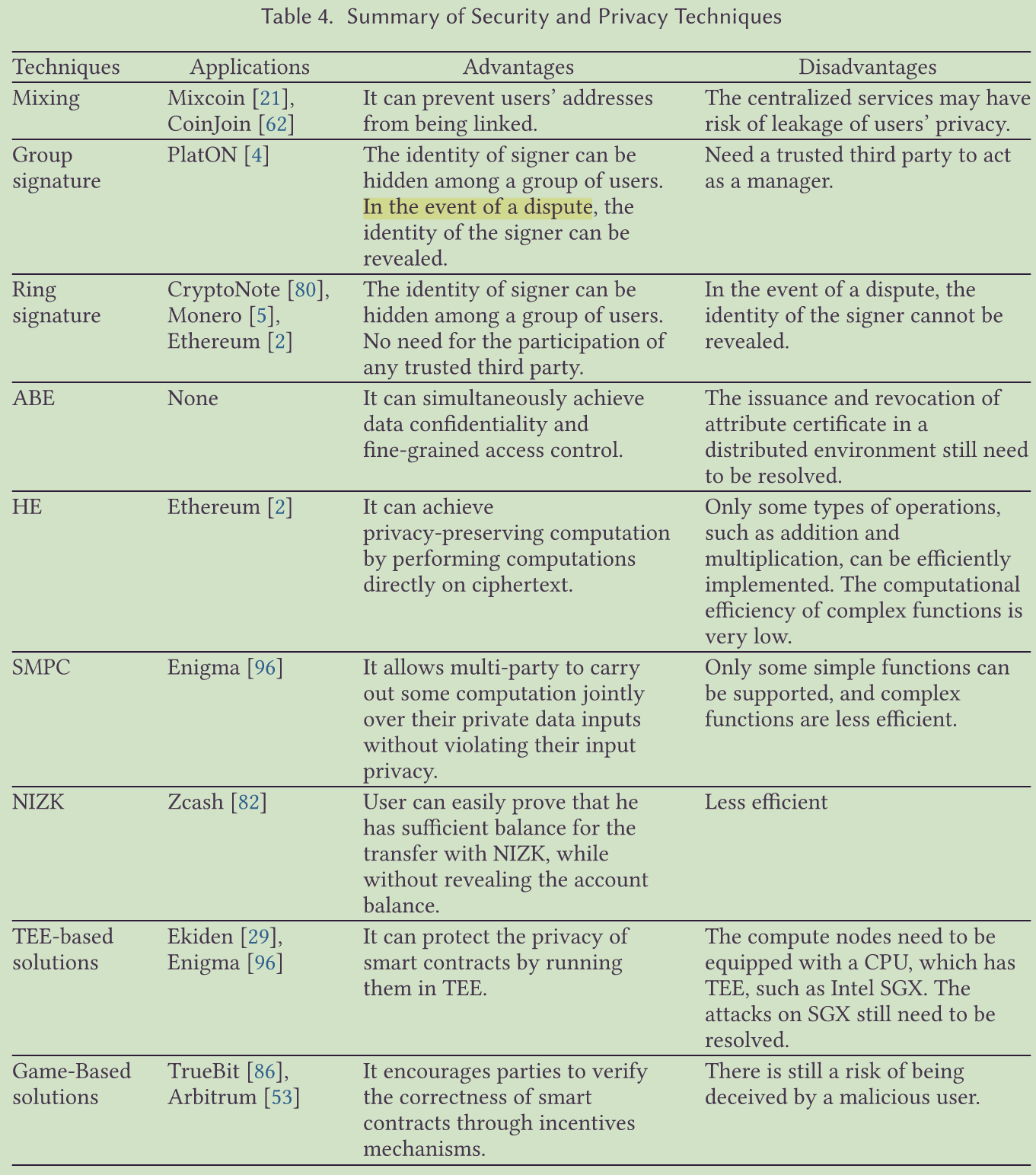
关于区块链的安全和隐私
背景 区块链技术在近年来发展迅速,被认为是安全计算的突破,但其安全和隐私问题在不同应用中的部署仍处于争论焦点。 目的 对区块链的安全和隐私进行全面综述,帮助读者深入了解区块链的相关概念、属性、技术和系统。 结构 首先介绍区块链…...

特征工程——一门提高机器学习性能的艺术
当前围绕人工智能(AI)和机器学习(ML)展开的许多讨论以模型为中心,聚焦于 ML和深度学习(DL)的最新进展。这种模型优先的方法往往对用于训练这些模型的数据关注不足,甚至完全忽视。类似MLOps的领域正迅速发展,通过系统性地训练和利用ML模型&…...

ROS2 核心概念与实战应用指南
1. ROS2核心概念解析:从零开始理解机器人开发框架 第一次接触ROS2时,我被它复杂的术语体系搞得晕头转向。直到把机器人项目比作一个餐厅,才突然开窍——节点就像厨师和服务员,话题是传菜窗口,服务是点单对讲机…...

OpenClaw团队协作版:ollama-QwQ-32B支持多人任务队列的改造
OpenClaw团队协作版:ollama-QwQ-32B支持多人任务队列的改造 1. 为什么我们需要团队协作版的OpenClaw 上周我们小组遇到了一个典型问题:三个人同时使用同一台机器上的OpenClaw实例时,任务开始互相干扰。最严重的一次,A同事的自动…...

OpenClaw多任务测试:nanobot镜像并行处理能力评估
OpenClaw多任务测试:nanobot镜像并行处理能力评估 1. 测试背景与目标 最近在探索OpenClaw的自动化能力边界时,我遇到了一个实际需求:能否让这个智能体框架同时处理多个不同类型的任务?比如一边整理本地文件,一边抓取…...

ContextMenuManager:高效管理Windows右键菜单的全方案
ContextMenuManager:高效管理Windows右键菜单的全方案 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager Windows右键菜单是我们日常操作电脑时最常用的…...

FPGA分频器避坑指南:为什么你的奇数倍分频时钟占空比总不对?
FPGA奇数倍分频器设计避坑实战:从原理到调试的完整解决方案 在FPGA开发中,时钟分频是最基础却又最容易出问题的环节之一。特别是当我们需要奇数倍分频时,很多工程师都会遇到一个共同的困扰——为什么仿真通过的代码,烧写到FPGA后输…...

如何快速上手MOOTDX:Python量化分析者的通达信数据完整实战手册
如何快速上手MOOTDX:Python量化分析者的通达信数据完整实战手册 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx MOOTDX是一个专门为Python开发者设计的通达信数据接口封装库࿰…...

ESP32低功耗项目实战:用Light Sleep和Deep Sleep保持LED亮度的完整代码与避坑指南
ESP32低功耗项目实战:用Light Sleep和Deep Sleep保持LED亮度的完整代码与避坑指南 在物联网设备开发中,电池续航往往是决定产品成败的关键因素。想象一下,你设计的智能门锁因为频繁更换电池而被用户抱怨,或者环境监测传感器因为电…...
在目标检测中的关键作用与高效实现)
深入解析IoU(Jaccard系数)在目标检测中的关键作用与高效实现
1. IoU究竟是什么?从基础概念到视觉理解 第一次接触目标检测时,我对着论文里满屏的"IoU"缩写发懵——这到底是个什么魔法指标?后来在调试YOLO模型时才发现,这个看似简单的比值,实际上是整个检测任务的基石性…...

从标准到实战:网络变压器在POE应用中的AF/AT/BF/BT详解与电路设计指南
1. 网络变压器在POE系统中的核心作用 第一次接触POE供电系统时,我对着电路板上那个带铁壳的方形元件研究了半天——这就是网络变压器。它看起来平平无奇,却是整个POE系统的"心脏"。简单来说,网络变压器在POE系统中要同时干两件事&a…...

从4.69万亿Token看中国AI大模型:调用量超越美国的背后逻辑
前言最近看到一组数据:截至2026年3月15日,中国AI大模型的周调用量达到4.69万亿Token,连续第二周超越美国,全球前三全部被中国模型包揽。作为一个长期关注AI行业的技术人,这个消息让我想深入挖一挖背后的逻辑࿱…...