完整网络模型训练(一)
文章目录
- 一、网络模型的搭建
- 二、网络模型正确性检验
- 三、创建网络函数
一、网络模型的搭建
以CIFAR10数据集作为训练例子
准备数据集:
#因为CIFAR10是属于PRL的数据集,所以需要转化成tensor数据集
train_data = torchvision.datasets.CIFAR10(root="./data", train=True, transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="./data", train=False, transform=torchvision.transforms.ToTensor(),download=True)
查看数据集的长度:
train_data_size = len(train_data)
test_data_size = len(test_data)
print(f"训练数据集的长度为{train_data_size}")
print(f"测试数据集的长度为{test_data_size}")
运行结果:

利用DataLoader来加载数据集:
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
搭建CIFAR10数据集神经网络:

卷积层【1】代码解释:
#第一个数字3表示inputs(可以看到图中为3),第二个数字32表示outputs(图中为32)
#第三个数字5为卷积核(图中为5),第四个数字1表示步长(stride)
#第五个数字表示padding,需要计算,计算公式:

nn.Conv2d(3, 32, 5, 1, 2)
最大池化代码解释:
#数字2表示kernel卷积核
nn.MaxPool2d(2)
读图
卷积层【1】的Inputs 和 Outputs是下图这两个:

最大池化【1】的Inputs 和 Outputs是下图这两个:

卷积层【2】的Inputs 和 Outputs是下图这两个:

以此类推
展平:

Flatten后它会变成64*4 *4的一个结果
线性输出:

线性输入是64*4 *4,线性输出是64,故如下代码
nn.LInear(64 *4 *4,64)
继续线性输出

nn.LInear(64,10)
搭建网络完整代码:
class Sen(nn.Module):def __init__(self):super(Sen, self).__init__()self.model = nn.Sequential(nn.Conv2d(3, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, 1 ,2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, 1, 2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64*4*4, 64),nn.Linear(64, 10))def forward(self,x):x = self.model(x)return x
二、网络模型正确性检验
if __name__ == '__main__':sen = Sen()input = torch.ones((64, 3, 32, 32))output = sen(input)print(output.shape)
注释:
input = torch.ones((64, 3, 32, 32))
这一行代码的含义是:创建一个大小为 (64, 3, 32, 32) 的全 1 张量,数据类型为 torch.float32。
64:这是批次大小,代表输入有 64 张图片。
3:这是图片的通道数,通常为 RGB 图像的三个通道 (红、绿、蓝)。
32, 32:这是图片的高和宽,表示每张图片的尺寸为 32x32 像素。
torch.ones 函数用于生成一个全 1 的张量,这里的张量形状适合用于输入图像分类或卷积神经网络(CNN)中常见的 CIFAR-10 或类似的 32x32 像素图像数据。
运行结果:

可以得到成功变成了【64, 10】的结果。
三、创建网络函数
创建网络模型:
sen = Sen()
搭建损失函数:
loss_fn = nn.CrossEntropyLoss()
优化器:
learning_rate = 1e-2
optimizer = torch.optim.SGD(sen.parameters(), lr=learning_rate)
优化器注释:
使用随机梯度下降(SGD)优化器
learning_rate = 1e-2 这里的1e-2代表的是:1 x (10)^(-2) = 1/100 = 0.01
记录训练的次数:
total_train_step = 0
记录测试的次数:
total_test_step = 0
训练的轮数:
epoch= 10
进行循环训练:
for i in range(epoch):print(f"第{i+1}轮训练开始")for data in train_dataloader:imgs, targets = dataoutputs = sen(imgs)loss = loss_fn(outputs, targets)optimizer.zero_grad()loss.backward()optimizer.step()total_train_step = total_train_step + 1print(f"训练次数:{total_train_step},Loss:{loss.item()}")
注释:
imgs, targets = data是解包数据,imgs 是输入图像,targets 是目标标签(真实值)
outputs = sen(imgs)将输入图像传入模型 ‘sen’,得到模型的预测输出 outputs
loss = loss_fn(outputs, targets)计算损失值(Loss),loss_fn 是损失函数,它比较outputs的值与targets 是目标标签(真实值)的误差
optimizer.zero_grad()清除优化器中上一次计算的梯度,以免梯度累积
loss.backward()反向传播,计算损失相对于模型参数的梯度
optimizer.step()使用优化器更新模型的参数,以最小化损失
loss.item() 将张量转换为 Python 的数值
loss.item演示:
import torch
a = torch.tensor(5)
print(a)
print(a.item())
运行结果:

因此可以得到:item的作用是将tensor变成真实数字5
本章节完整代码展示:
import torchvision.datasets
from torch import nn
from torch.utils.data import DataLoaderclass Sen(nn.Module):def __init__(self):super(Sen, self).__init__()self.model = nn.Sequential(nn.Conv2d(3, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, 1 ,2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, 1, 2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64*4*4, 64),nn.Linear(64, 10))def forward(self,x):x = self.model(x)return x
#准备数据集
#因为CIFAR10是属于PRL的数据集,所以需要转化成tensor数据集
train_data = torchvision.datasets.CIFAR10(root="./data", train=True, transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="./data", train=False, transform=torchvision.transforms.ToTensor(),download=True)#length长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print(f"训练数据集的长度为{train_data_size}")
print(f"测试数据集的长度为{test_data_size}")train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)sen = Sen()#损失函数
loss_fn = nn.CrossEntropyLoss()#优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(sen.parameters(), lr=learning_rate)#记录训练的次数
total_train_step = 0
#记录测试的次数
total_test_step = 0
#训练的轮数
epoch= 10for i in range(epoch):print(f"第{i+1}轮训练开始")for data in train_dataloader:imgs, targets = dataoutputs = sen(imgs)loss = loss_fn(outputs, targets)optimizer.zero_grad()loss.backward()optimizer.step()total_train_step = total_train_step + 1print(f"训练次数:{total_train_step},Loss:{loss.item()}")
运行结果:

可以看到训练的损失函数在一直进行修正。
相关文章:
完整网络模型训练(一)
文章目录 一、网络模型的搭建二、网络模型正确性检验三、创建网络函数 一、网络模型的搭建 以CIFAR10数据集作为训练例子 准备数据集: #因为CIFAR10是属于PRL的数据集,所以需要转化成tensor数据集 train_data torchvision.datasets.CIFAR10(root&quo…...

高效便捷,体验不一样的韩语翻译神器
嘿,大家好啊!今天想跟大家聊聊我用过的几款翻译神器,特别是它们在翻译韩语时的那些小感受。作为一个偶尔需要啃啃韩语资料或者跟韩国朋友聊天的普通人,我真心觉得这些翻译工具简直就是我的救星! 一、福昕在线翻译 网址…...
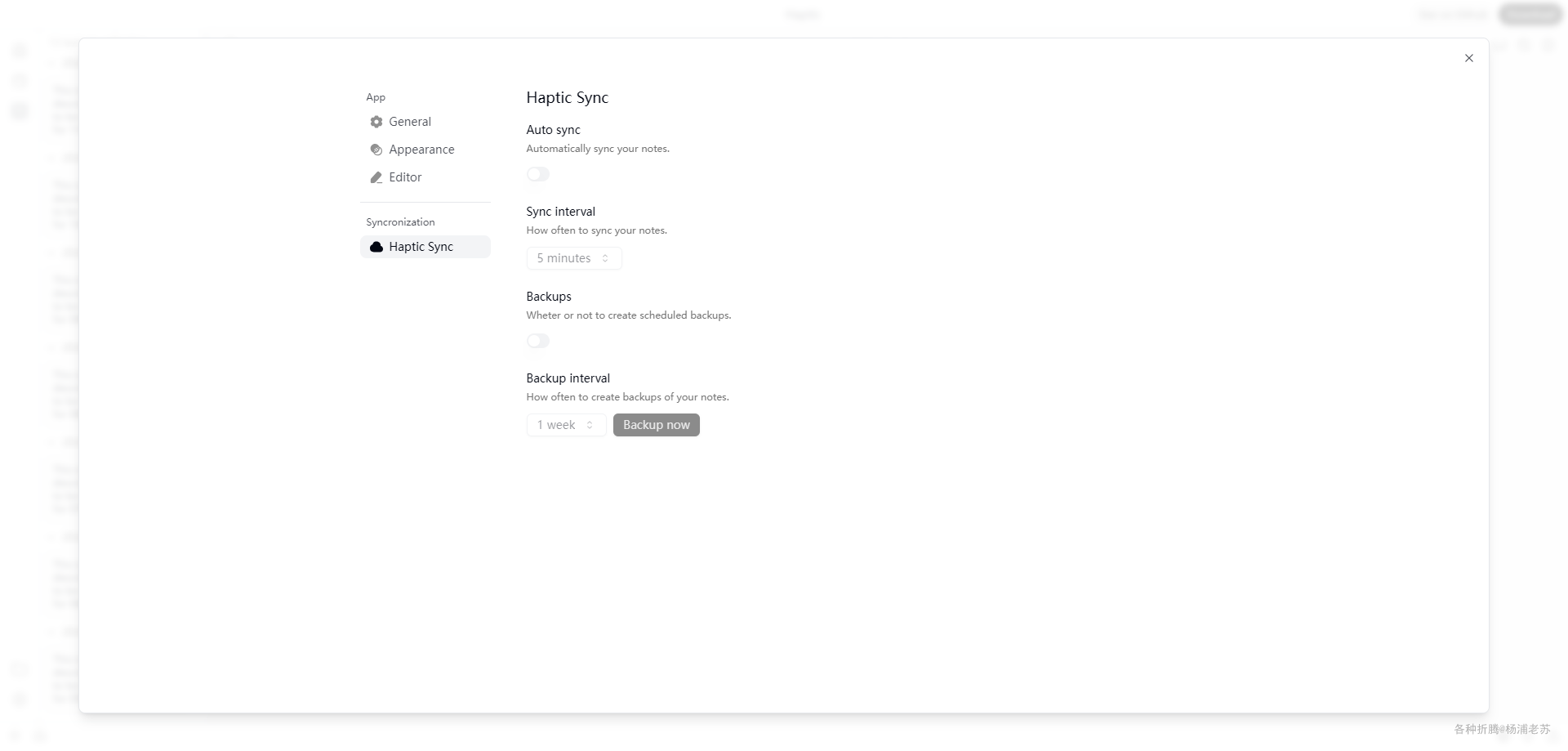
Markdown笔记管理工具Haptic
什么是 Haptic ? Haptic 是一个新的本地优先、注重隐私的开源 Markdown 笔记管理工具。它简约、轻量、高效,旨在提供您所需的一切,而不包含多余的功能。 目前官方提供了 docker 和 Mac 客户端。 Haptic 仍在积极开发中。以下是未来计划的一些…...

网络原理-传输层UDP
上集回顾: 上一篇博客中讲述了应用层如何自定义协议:确定传输信息,确定数据格式 应用层也有一些现成的协议:HTTP协议 这一篇博客中来讲述传输层协议 传输层 socket api都是传输层协议提供的(操作系统内核实现的了…...

C++中,如何使你设计的迭代器被标准算法库所支持。
iterator(读写迭代器) const_iterator(只读迭代器) reverse_iterator(反向读写迭代器) const_reverse_iterator(反向只读迭代器) 以经常介绍的_DList类为例,它的迭代…...

Java NIO 全面详解:掌握 `Path` 和 `Files` 的一切
在 Java 7 中引入的 NIO (New I/O) 为文件系统和流的操作带来了强大的能力,其中 Path 和 Files 是核心部分。Path 作为对文件路径的抽象,提供了灵活的方式处理文件系统中的路径;Files 则通过一系列静态方法,使得文件的读写、复制、…...

bluez免提协议hands-free介绍,全到无法想象,bluez hfp ag介绍
零. 前言 由于Bluez的介绍文档有限,以及对Linux 系统/驱动概念、D-Bus 通信和蓝牙协议都有要求,加上网络上其实没有一个完整的介绍Bluez系列的文档,所以不管是蓝牙初学者还是蓝牙从业人员,都有不小的难度,学习曲线也相对较陡,所以我有了这个想法,专门对Bluez做一个系统…...
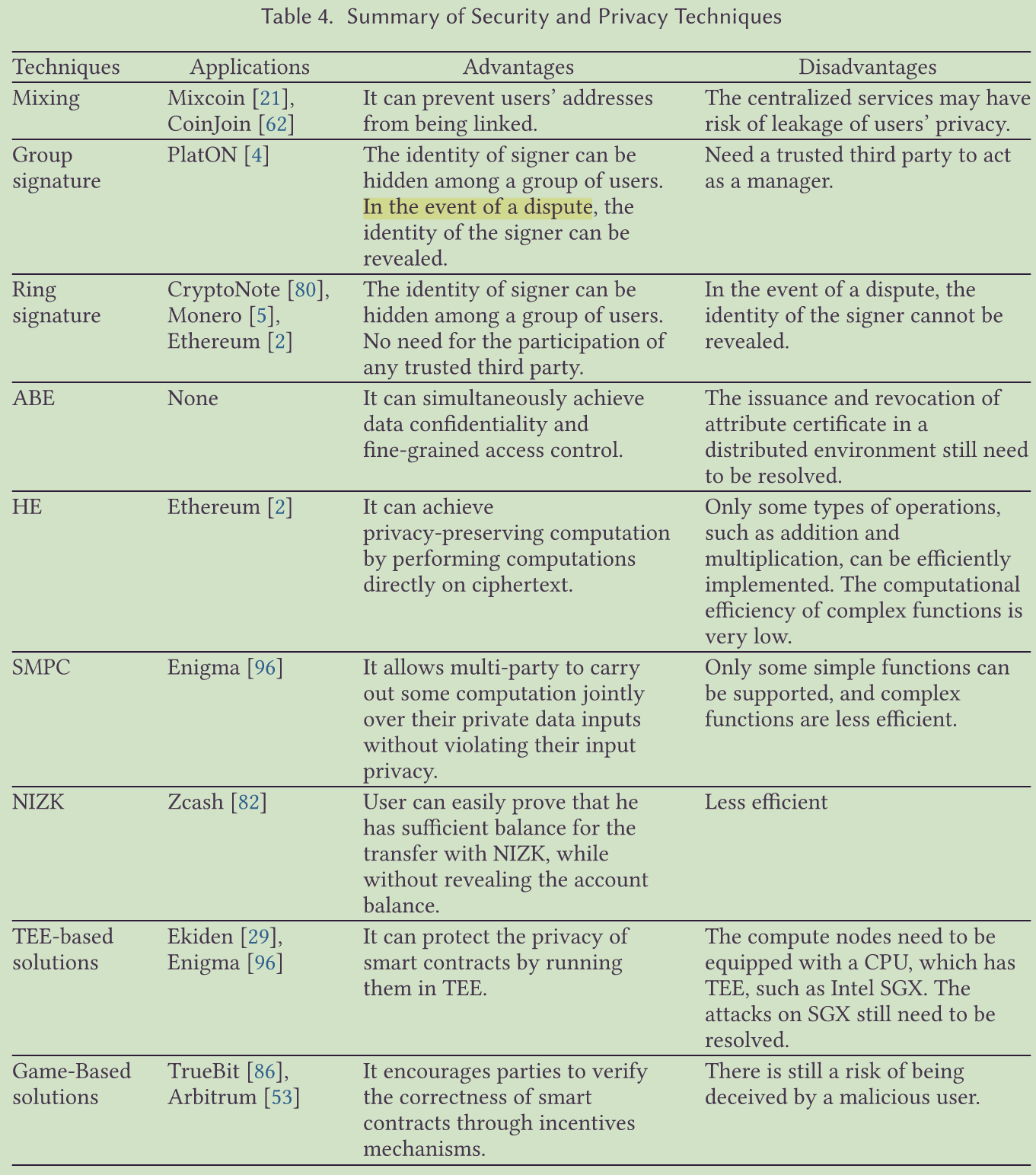
关于区块链的安全和隐私
背景 区块链技术在近年来发展迅速,被认为是安全计算的突破,但其安全和隐私问题在不同应用中的部署仍处于争论焦点。 目的 对区块链的安全和隐私进行全面综述,帮助读者深入了解区块链的相关概念、属性、技术和系统。 结构 首先介绍区块链…...

特征工程——一门提高机器学习性能的艺术
当前围绕人工智能(AI)和机器学习(ML)展开的许多讨论以模型为中心,聚焦于 ML和深度学习(DL)的最新进展。这种模型优先的方法往往对用于训练这些模型的数据关注不足,甚至完全忽视。类似MLOps的领域正迅速发展,通过系统性地训练和利用ML模型&…...
Paper解读:工作场所人机协作的团队形成:促进组织变革的目标编程模型
人工智能(AI)具有降低运营成本、提高效率和改善客户体验的潜力。 因此,在组织中组建项目团队至关重要,这样他们就会在决策过程中欢迎人工智能。 当前的技术革命要求公司快速变革,并增加了对团队在促进创新采用方面的作…...

图文深入理解Oracle Network配置管理(一)
List item 本篇图文深入介绍Oracle Network配置管理。 Oracle Network概述 Oracle Net 服务 Oracle Net 监听程序 <oracle_home>/network/admin/listener.ora <oracle_home>/network/admin/sqlnet.ora建立网络连接 要建立客户机或中间层连接,Oracle…...

leetcode-链表篇3
leetcode-61 给你一个链表的头节点 head ,旋转链表,将链表每个节点向右移动 k 个位置。 示例 1: 输入:head [1,2,3,4,5], k 2 输出:[4,5,1,2,3]示例 2: 输入:head [0,1,2], k 4 输出&#x…...

RAG(Retrieval Augmented Generation)及衍生框架:CRAG、Self-RAG与HyDe的深入探讨
近年来,随着大型语言模型(LLMs)的迅猛发展,我们在寻求更精确、更可靠的语言生成能力上取得了显著进展。其中,检索增强生成(Retrieval-Augmented Generation)作为一种创新方法,极大地…...

C语言介绍
什么是C语言 C programing language 能干什么 Hello world? 如何学C语言 no reading no learning...

损失函数篇 | YOLOv10 更换损失函数之 MPDIoU | 《2023 一种用于高效准确的边界框回归的损失函数》
论文地址:https://arxiv.org/pdf/2307.07662v1.pdf 边界框回归(Bounding Box Regression,BBR)在目标检测和实例分割中得到了广泛应用,是目标定位的重要步骤。然而,对于边界框回归的大多数现有损失函数来说,当预测的边界框与真值边界框具有相同的长宽比,但宽度和高度的…...

WMware安装WMware Tools(Linux~Ubuntu)
1、这里终端里面输入sudo apt upgrade用于更新最新的包 sudo apt upgrade 2、安装 open-vm-tools-desktop 包, Ps:这里是以为我已经安装好了。 udo apt install open-vm-tools-desktop -y3、最后重启就大功告成了 reboot 4、测试是否成功:…...
关键帧跟踪)
SLAM ORB-SLAM2(30)关键帧跟踪
SLAM ORB-SLAM2(30)关键帧跟踪 1. 关键帧跟踪2. TrackReferenceKeyFrame2.1. 将当前普通帧的描述子转化为BoW向量2.2. 通过词袋BoW加速当前帧与参考帧之间的特征点匹配2.3. 将上一帧的位姿态作为当前帧位姿的初始值2.4. 通过优化3D-2D的重投影误差来获得位姿2.5. 剔除优化后的…...

k8s 部署 prometheus
创建namespace prometheus-namespace.yaml apiVersion: v1 kind: Namespace metadata:name: ns-prometheus拉取镜像 docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/quay.io/prometheus/prometheus:v2.54.0prometheus配置文件configmap prometheus-configmap.yaml …...
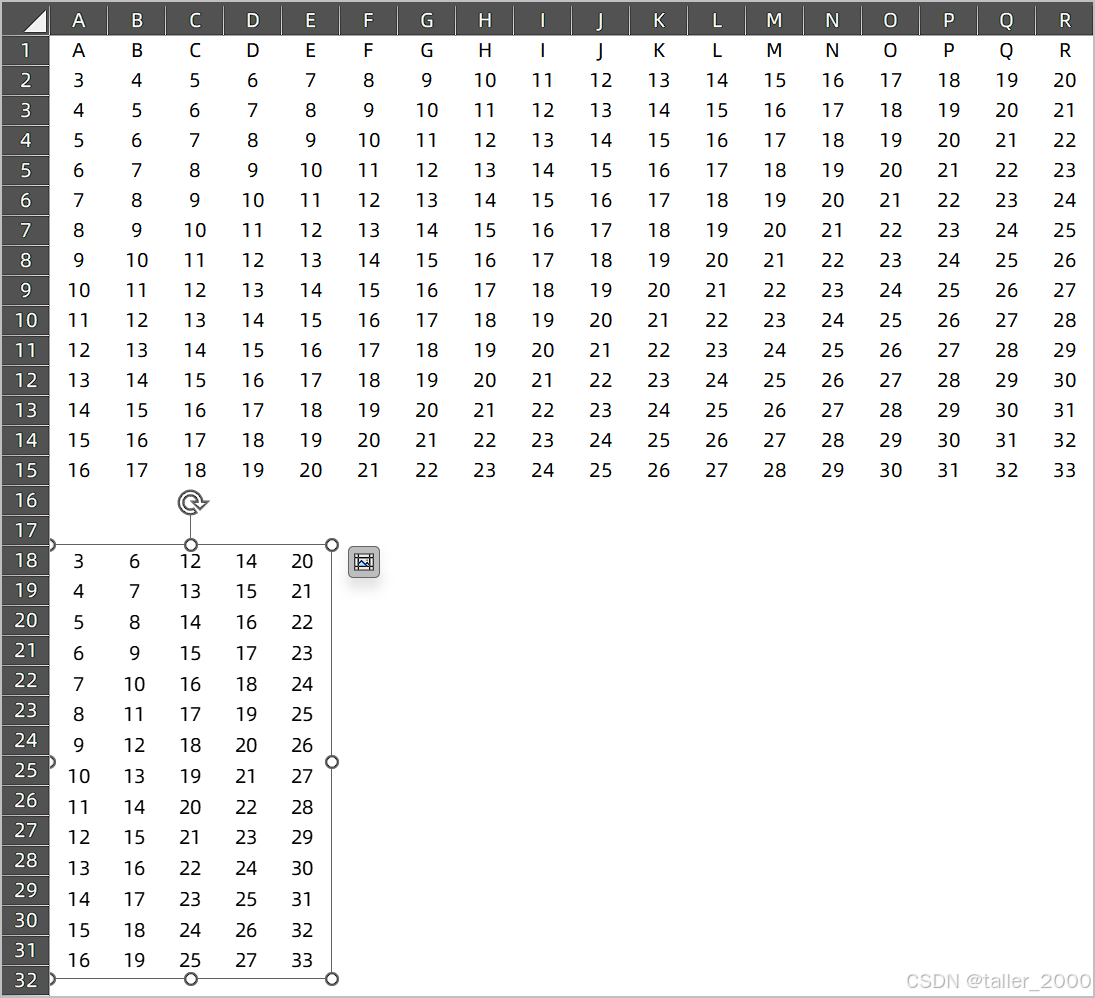
使用VBA快速生成Excel工作表非连续列图片快照
Excel中示例数据如下图所示。 现在需要拷贝A2:A15,D2:D15,J2:J15,L2:L15,R2:R15为图片,然后粘贴到A18单元格,如下图所示。 大家都知道VBA中Range对象有CopyPicture方法可以拷贝为图片,但是如果Range对象为非连续区域,那么将产生10…...

解决GitHub下载速度慢
解决GitHub下载速度慢 方法一:使用git clone 地址 --depth 1来下载 depth 1 表示只科隆最新的一次提交,也就是默认主分支,而不是完整地克隆整个代码仓库,这样可以减少下载地数据,加快克隆操作 可以用git clone 地址 …...
)
别再复制粘贴了!手把手教你用MATLAB/Simulink把低通滤波器写成C代码(附避坑指南)
从MATLAB到嵌入式C:低通滤波器工程化实现全指南 在嵌入式系统开发中,数字滤波器的实现往往成为算法落地的关键瓶颈。许多工程师能够熟练使用MATLAB设计出完美的滤波器模型,却在将其转化为实际可用的C代码时频频碰壁——仿真曲线平滑优美&…...

Taotoken提供的审计日志功能如何满足企业级安全与合规需求
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken提供的审计日志功能如何满足企业级安全与合规需求 1. 企业引入大模型能力后的审计挑战 当企业将大模型API能力整合到内部…...

使用Taotoken后如何清晰观测API用量与成本变化
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken后如何清晰观测API用量与成本变化 对于团队管理者或开发者而言,将大模型能力集成到产品中后,资…...

2026 AI大模型API加速网站推荐
在AI开发领域,一个现实问题始终困扰着开发者:如何接入模型厂商的官方API?在海外,注册、绑卡、调用这三个步骤就能轻松解决。然而,国内开发者面临着跨境网络波动、外币支付门槛、发票合规需求以及多厂商Key碎片化管理等…...

解放双手:D3KeyHelper让暗黑3游戏操作变得前所未有的简单
解放双手:D3KeyHelper让暗黑3游戏操作变得前所未有的简单 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 还在为暗黑3中繁琐的技能循环和…...

Cursor Free VIP:如何一键突破AI编程助手使用限制?
Cursor Free VIP:如何一键突破AI编程助手使用限制? 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached …...

OpenClaw CLI:在终端无缝集成AI智能体的MCP服务器部署指南
1. 项目概述:OpenClaw CLI,一个连接终端与智能体的桥梁 如果你和我一样,日常开发工作大部分时间都泡在终端里,同时又对AI智能体(Agent)的自动化能力垂涎三尺,那么你肯定也遇到过这样的痛点&…...
)
MATLAB roots函数实战:5分钟搞定高阶系统稳定性判断(附完整代码)
MATLAB roots函数实战:高阶系统稳定性分析的黄金法则 在控制工程和自动化领域,系统稳定性分析是每个工程师的必修课。面对复杂的高阶系统特征方程,传统的手工计算方法不仅耗时耗力,还容易出错。而MATLAB的roots函数配合简单的可视…...

从帧结构到数据解析:深入理解CJ/T 188 MBUS水表通信协议
1. MBUS协议与水表通信基础 第一次接触CJ/T 188 MBUS协议时,我完全被那一串串十六进制报文搞懵了。FE FE FE 68开头的报文到底在说什么?为什么水表厂商给的文档读起来像天书?经过几个项目的实战,我发现只要掌握几个关键点…...
)
基于SpringBoot的企业客户管理系统(附源码)
项目编号050 项目获取:合集 想学习Java开发却找不到合适的项目练手?这套基于Spring Boot的企业客户管理系统就是你的最佳选择!代码简单清晰,功能实用完整,非常适合初学者学习和二次开发。 这是什么项目? …...