OpenCV第十二章——人脸识别
1.人脸跟踪
1.1 级联分类器
OpenCV中的级联分类器是一种基于AdaBoost算法的多级分类器,主要用于在图像中检测目标对象。以下是对其简单而全面的解释:
一、基本概念
级联分类器:是一种由多个简单分类器(弱分类器)级联组成的强分类器。每个弱分类器逐步过滤掉非目标区域,减少误检率,同时尽可能保持高召回率。这种结构使得级联分类器在检测过程中能够高效且准确地识别目标对象。
AdaBoost算法:Adaptive Boosting(自适应增强)的缩写,是一种集成学习算法。它通过构建一系列弱分类器,并根据每个弱分类器的表现(即分类错误率)来调整其在最终强分类器中的权重,从而组合成一个强分类器。
二、工作原理
特征提取:级联分类器使用特征提取器(如Haar-like特征、Local Binary Patterns(LBP)等)从图像中提取出用于分类的特征。这些特征通常反映了图像的灰度变化、纹理信息等。
训练过程:
- 准备训练数据:包括大量的正样本(包含目标对象的图像)和负样本(不包含目标对象的图像)。
- 使用AdaBoost算法训练每一级分类器:在每一级中,算法会选择一些特征来训练一个弱分类器,并通过调整样本权重来优化分类器的性能。随着训练的进行,后续级别的分类器会专注于更难以区分的样本。
- 重复上述过程,直到满足预定的训练精度要求或达到预设的级数。
检测过程:
- 输入待检测的图像,并将其转换为灰度图像。
- 使用训练好的级联分类器对图像进行扫描,通过不断缩小图像(制作图像金字塔)和滑动检测窗口来寻找目标对象。
- 每一级分类器都会对当前检测窗口内的图像区域进行分类,如果认为是目标对象的一部分,则将该区域传递给下一级分类器进行更细粒度的检测。
- 最终,当某个检测窗口通过所有级别的分类器时,就认为该窗口内存在目标对象,并输出其位置和大小。
三、优缺点
优点:
- 简单、易于理解和实现。
- 易于并行化,适合处理大量数据。
- 在许多目标检测任务中表现出色,特别是在面部检测和其他特征点检测方面。
缺点:
- 对异常值敏感,容易受到噪声和光照变化的影响。
- 需要大量的训练数据和计算资源来训练级联分类器。
- 对复杂形状和纹理的描述能力有限,可能无法准确检测某些类型的目标对象。
四、应用场景
OpenCV中的级联分类器广泛应用于各种目标检测任务中,包括但不限于面部检测、眼睛检测、车辆检测等。这些分类器通常以XML文件的形式提供,包含了训练好的特征和分类器参数,用户可以直接加载这些文件来进行目标检测。
综上所述,OpenCV中的级联分类器是一种高效且强大的目标检测工具,通过结合AdaBoost算法和特征提取技术,能够在复杂的图像中准确地识别出目标对象。


1.2 方法
OpenCV通过CascadeClassifier()方法创建了级联分类器对象,其语法结构如下:
<CascadeClassifier object> = cv2.CascadeClassifier(filename)
参数说明:
filename:级联分类器的XML文件名。
返回值说明:
object:分类器对象。
之后使用已经创建好的分类器对图像进行识别,此过程需要调用分类器对象的detectMulti-Scale()方法,语法格式如下:
objects = cascsde.detectMultiScale(image, scaleFactor, minNeighbors, flags,minSize,maxSize)
对象说明:
cascade:已有的分类器对象。
参数说明:
image:待分析的图像。
scaleFactor:可选参数,扫描图像时的缩放比例。
minNeighbors:可选参数,每个候选区域至少保留多少个检测结果才可以判定为人脸。该值越大分析的误差越小。
flags:可选参数,建议使用默认值。
minSize:可选参数,最小的目标尺寸。
maxSize:可选参数,最大的目标尺寸。
返回值说明:
objects:捕捉到的目标区域数组,数组中每一个元都是一个目标区域,每一个目标区域都包含四个值,分别是:左上角点横坐标,左上角点纵坐标,区域宽,区域高。
1.3分析人脸位置
haarcascade_frontalface_default.xml是就按测正面人脸的级联分类器文件,加载该文件就可以创建出追踪正面人脸的分类器,调用分类器对象的detectMultiScale()方法,就可以得到人脸区域的坐标的和宽高。
1.3.1 在图像的人脸位置绘制红框
操作代码示例:
import cv2img = cv2.imread(r"C:\Users\cgs\Desktop\pictures\1 (37).jpg") # 读取人脸图像
# 加载识别人脸的级联分类器
faceCascade = cv2.CascadeClassifier(r"B:\Python_opencv_book\12\01\cascades\haarcascade_frontalface_default.xml")
faces = faceCascade.detectMultiScale(img, 1.3) # 识别出所有人脸
for (x, y, w, h) in faces: # 遍历所有人脸的区域cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 255), 5) # 在图像中人脸的位置绘制方框
cv2.imshow("img", img) # 显示最终处理的效果
cv2.waitKey()
cv2.destroyAllWindows() 操作效果图像:

1.3.2 实现特效、
操作代码示例:
import cv2# 覆盖图像
def overlay_img(img, img_over, img_over_x, img_over_y):"""覆盖图像:param img: 背景图像:param img_over: 覆盖的图像:param img_over_x: 覆盖图像在背景图像上的横坐标:param img_over_y: 覆盖图像在背景图像上的纵坐标:return: 两张图像合并之后的图像"""img_h, img_w, img_p = img.shape # 背景图像宽、高、通道数img_over_h, img_over_w, img_over_c = img_over.shape # 覆盖图像高、宽、通道数if img_over_c == 3: # 通道数小于等于3img_over = cv2.cvtColor(img_over, cv2.COLOR_BGR2BGRA) # 转换成4通道图像for w in range(0, img_over_w): # 遍历列for h in range(0, img_over_h): # 遍历行if img_over[h, w, 3] != 0: # 如果不是全透明的像素for c in range(0, 3): # 遍历三个通道x = img_over_x + w # 覆盖像素的横坐标y = img_over_y + h # 覆盖像素的纵坐标if x >= img_w or y >= img_h: # 如果坐标超出最大宽高break # 不做操作img[y, x, c] = img_over[h, w, c] # 覆盖像素return img # 完成覆盖的图像face_img = cv2.imread(r"C:\Users\cgs\Desktop\pictures\1_37.jpg") # 读取人脸图像
face_img = cv2.resize(face_img, (800, 800))
glass_img = cv2.imread(r"B:\Python_opencv_book\12\02\glass.png", cv2.IMREAD_UNCHANGED) # 读取眼镜图像,保留图像类型
height, width, channel = glass_img.shape # 获取眼镜图像高、宽、通道数
# 加载级联分类器
face_cascade = cv2.CascadeClassifier(r"B:\Python_opencv_book\12\02\cascades\haarcascade_frontalface_default.xml")
garyframe = cv2.cvtColor(face_img, cv2.COLOR_BGR2GRAY) # 转为黑白图像
faces = face_cascade.detectMultiScale(garyframe, 1.3, 5) # 识别人脸
for (x, y, w, h) in faces: # 遍历所有人脸的区域gw = w # 眼镜缩放之后的宽度gh = int(height * w / width) # 眼镜缩放之后的高度度glass_img = cv2.resize(glass_img, (gw, gh)) # 按照人脸大小缩放眼镜overlay_img(face_img, glass_img, x, y + int(h * 1 / 3)) # 将眼镜绘制到人脸上
cv2.imshow("screen", face_img) # 显示最终处理的效果
cv2.waitKey() # 按下任何键盘按键后
cv2.destroyAllWindows() # 释放所有窗体
操作效果图像:

2.检测其他内容
2.1 眼睛跟踪
操作代码示例:
import cv2img = cv2.imread(r"C:\Users\cgs\Desktop\pictures\12-3.jpg") # 读取人脸图像
# img = cv2.resize(img, (800, 800))
# 加载识别眼睛的级联分类器
eyeCascade = cv2.CascadeClassifier(r"B:\Python_opencv_book\12\03\cascades\haarcascade_eye.xml")
eyes = eyeCascade.detectMultiScale(img, 1.15) # 识别出所有眼睛
for (x, y, w, h) in eyes: # 遍历所有眼睛的区域cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 4) # 在图像中眼睛的位置绘制方框
cv2.imshow("img", img) # 显示最终处理的效果
cv2.waitKey()
cv2.destroyAllWindows()
操作效果图像:

2.2 猫脸跟踪
操作代码示例:
import cv2
img = cv2.imread(r"B:\Python_opencv_book\12\04\cat.jpg") # 读取猫脸图像
# 加载识别猫脸的级联分类器
catFaceCascade = cv2.CascadeClassifier(r"B:\Python_opencv_book\12\04\cascades\haarcascade_frontalcatface_extended.xml")
catFace = catFaceCascade.detectMultiScale(img, 1.15, 4) # 识别出所有猫脸
for (x, y, w, h) in catFace: # 遍历所有猫脸的区域cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 5)# 在图像中猫脸的位置绘制方框
cv2.imshow("A cute cat.", img) # 显示最终处理的效果
cv2.waitKey()
cv2.destroyAllWindows()
操作效果图像:

2.3 行人跟踪
在操作用图像:

操作代码示例:
import cv2
img = cv2.imread(r"B:\Python_opencv_book\12\05\monitoring.jpg") # 读取图像
# 加载识别类人体的级联分类器
bodyCascade = cv2.CascadeClassifier(r"B:\Python_opencv_book\12\05\cascades\haarcascade_fullbody.xml")
bodys = bodyCascade.detectMultiScale(img, 1.15, 4) # 识别出所有人体
for (x, y, w, h) in bodys: # 遍历所有人体区域cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 5)# 在图像中人体的位置绘制方框
cv2.imshow("img", img) # 显示最终处理的效果
cv2.waitKey()
cv2.destroyAllWindows()
操作效果图像:

2.4 车牌跟踪
操作代码示例:
import cv2img = cv2.imread(r"C:\Users\cgs\Desktop\pictures\12_10.jpg") # 读取车的图像
# 加载识别车牌的级联分类器
plateCascade = cv2.CascadeClassifier(r"B:\Python_opencv_book\12\06\cascades\haarcascade_russian_plate_number.xml")
plates = plateCascade.detectMultiScale(img, 1.15, 4) # 识别出所有车牌
for (x, y, w, h) in plates: # 遍历所有车牌区域cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 5) # 在图像中车牌的位置绘制方框
cv2.imshow("img", img) # 显示最终处理的效果
cv2.waitKey()
cv2.destroyAllWindows()
操作效果图像:

3.人脸识别
3.1 Eigenfaces人脸识别器
Eigenfaces人脸识别器是一种基于主成分分析(PCA)技术的人脸识别方法,也常被称为“特征脸”方法。以下是对Eigenfaces人脸识别器的详细简述:
原理
Eigenfaces方法的核心思想是通过PCA将人脸图像从高维空间转换到低维空间,同时保留图像中的主要特征信息。具体来说,PCA被用来计算训练集中所有人脸图像的协方差矩阵,并从中提取出一组特征向量(即主成分),这些特征向量被称为“特征脸”(Eigenfaces)。这些特征脸代表了人脸图像中最具代表性的特征,如眼睛、鼻子和嘴巴的位置和形状等。
步骤
Eigenfaces人脸识别器的实现通常包括以下步骤:
- 数据预处理:将人脸图像转换为灰度图像,并进行大小归一化处理,以确保所有图像具有相同的尺寸和格式。
- 特征提取:对预处理后的人脸图像进行PCA分析,提取出一组特征向量(特征脸)。这些特征向量能够捕捉到人脸图像中的关键特征信息。
- 训练分类器:使用提取出的特征向量和对应的标签(即人脸的身份信息)来训练一个分类器。这个分类器可以是K-近邻分类器、支持向量机(SVM)等,用于将输入的人脸图像映射到其对应的身份标签上。
- 人脸识别:对于一张新的未知身份的人脸图像,首先将其转换为特征向量,然后使用训练好的分类器进行识别。分类器会计算输入图像与训练集中各个身份的特征向量之间的距离或相似度,并返回最相似的身份标签作为识别结果。
优缺点
优点:
- Eigenfaces方法能够有效地降低人脸图像的维度,同时保留关键特征信息,从而提高识别效率。
- 它对光照、表情等变化具有一定的鲁棒性,能够在一定程度上应对这些变化对识别结果的影响。
缺点:
- Eigenfaces方法对姿态变化比较敏感,当人脸图像存在较大的姿态差异时,识别效果可能会下降。
- 它对于图像质量的要求较高,如果输入图像的质量较差(如模糊、遮挡等),可能会影响识别效果。
需要通过三个方法来完成人脸识别操作:
1.通过cv2.face.EigenFaceRecognizer_creat()方法创建人脸识别器
语法格式如下:recognizer = cv2.face.EigenFacecognizer_create(num_components,threshold)
参数说明:
num_components:可选参数,PCA方法中保留的分量个数
thresh:可选参数。人脸识别时使用的阈值
返回值说明:
recognizer:创建完的人脸识别器对象。
2.创建完识别器对象后,需要通过对象的train()方法来训练识别器。建议每个人都给出2张以上的照片作为训练样本。该方法语法结构如下:
recognizer.train(src, labels)
对象说明:
recognizer.train(src, lables)
参数说明:
src:用来训练的人脸图像样本列别,格式为list。样本图像必须宽高一致。
labels:样本对应的标签,格式为数组,元素类型为整数。数组长度必须与样本列表长度相同。样本与标签一一对应,
3.训练完识别器后就可以通过识别器的predict()方法来识别人脸了,该方法hi比对样本的特征,给出最相近的结果和评分。其语法结构如下:
label, confidence = recognizer.predict(src)
对象说明:
recognizer:已有的Eigenfaces人脸识别器对象。
参数说明:
src:需要识别的人脸对象,该图像宽高必须与样本一致。
返回值说明:
label:与样本匹配程度最高的标签值。
confidence:匹配程度最高的信用度评分,小于5000就可以认为匹配程度较高,0分表示两幅图像完全一样。
示例代码如下:其中Elvis1、2、3和summers1、2、3为训练样本,summers4为待识别图像。
import cv2
import numpy as npphotos = list() # 样本图像列表
labels = list() # 标签列表
photos.append(cv2.imread(r"B:\Python_opencv_book\12\07\face\summer1.png", 0)) # 记录第1张人脸图像
labels.append(0) # 第1张图像对应的标签
photos.append(cv2.imread(r"B:\Python_opencv_book\12\07\face\summer2.png", 0)) # 记录第2张人脸图像
labels.append(0) # 第2张图像对应的标签
photos.append(cv2.imread(r"B:\Python_opencv_book\12\07\face\summer3.png", 0)) # 记录第3张人脸图像
labels.append(0) # 第3张图像对应的标签photos.append(cv2.imread(r"B:\Python_opencv_book\12\07\face\Elvis1.png", 0)) # 记录第4张人脸图像
labels.append(1) # 第4张图像对应的标签
photos.append(cv2.imread(r"B:\Python_opencv_book\12\07\face\Elvis2.png", 0)) # 记录第5张人脸图像
labels.append(1) # 第5张图像对应的标签
photos.append(cv2.imread(r"B:\Python_opencv_book\12\07\face\Elvis3.png", 0)) # 记录第6张人脸图像
labels.append(1) # 第6张图像对应的标签names = {"0": "Summer", "1": "Elvis"} # 标签对应的名称字典recognizer = cv2.face.EigenFaceRecognizer_create() # 创建特征脸识别器
recognizer.train(photos, np.array(labels)) # 识别器开始训练i = cv2.imread(r"B:\Python_opencv_book\12\07\face\summer4.png", 0) # 待识别的人脸图像
label, confidence = recognizer.predict(i) # 识别器开始分析人脸图像
print("confidence = " + str(confidence)) # 打印评分
print(names[str(label)]) # 数组字典里标签对应的名字
cv2.waitKey()
cv2.destroyAllWindows()
操作结果:

3.2 Fisherfaces人脸识别器
同样是三个步骤:
1. 创建 FisherFaces 人脸识别器
使用cv2.face.FisherFaceRecognizer_create() 方法创建人脸识别器。
语法格式如下:
recognizer = cv2.face.FisherFaceRecognizer_create(num_components=150, threshold=200.0)2.训练识别器
语法格式如下:
# 假设 images 是包含人脸图像列表的变量,每个图像已调整为相同大小
# labels 是与每个图像对应的标签列表
recognizer.train(images, labels)3.识别人脸
语法格式如下:
# 假设 new_face 是待识别的人脸图像,且已调整为与训练样本相同的尺寸
label, confidence = recognizer.predict(new_face) # 输出识别结果
print(f"Recognized as person with label: {label}, confidence: {confidence}") # 根据置信度判断识别是否成功
if confidence < 5000: print("High confidence in recognition")
else: print("Low confidence in recognition")操作代码示例:
import cv2
import numpy as npphotos = list() # 样本图像列表
lables = list() # 标签列表
photos.append(cv2.imread(r"B:\Python_opencv_book\12\08\face\Mike1.png", 0)) # 记录第1张人脸图像
lables.append(0) # 第1张图像对应的标签
photos.append(cv2.imread(r"B:\Python_opencv_book\12\08\face\Mike2.png", 0)) # 记录第2张人脸图像
lables.append(0) # 第2张图像对应的标签
photos.append(cv2.imread(r"B:\Python_opencv_book\12\08\face\Mike3.png", 0)) # 记录第3张人脸图像
lables.append(0) # 第3张图像对应的标签photos.append(cv2.imread(r"B:\Python_opencv_book\12\08\face\kaikai1.png", 0)) # 记录第4张人脸图像
lables.append(1) # 第4张图像对应的标签
photos.append(cv2.imread(r"B:\Python_opencv_book\12\08\face\kaikai2.png", 0)) # 记录第5张人脸图像
lables.append(1) # 第5张图像对应的标签
photos.append(cv2.imread(r"B:\Python_opencv_book\12\08\face\kaikai3.png", 0)) # 记录第6张人脸图像
lables.append(1) # 第6张图像对应的标签names = {"0": "Mike", "1": "kaikai"} # 标签对应的名称字典recognizer = cv2.face.FisherFaceRecognizer_create() # 创建线性判别分析识别器
recognizer.train(photos, np.array(lables)) # 识别器开始训练i = cv2.imread(r"B:\Python_opencv_book\12\08\face\Mike4.png", 0) # 待识别的人脸图像
label, confidence = recognizer.predict(i) # 识别器开始分析人脸图像
print("confidence = " + str(confidence)) # 打印评分
print(names[str(label)]) # 数组字典里标签对应的名字cv2.waitKey()
cv2.destroyAllWindows()
操作效果:

3.3 Local Binary Pattern Histogram人脸识别器
同样三个步骤
1.创建LBPH人脸识别器
语法格式如下:
import cv2 # 创建LBPH人脸识别器
recognizer = cv2.face.LBPHFaceRecognizer_create()
# 如果需要,可以设置参数,如半径和邻居数等,但这里我们使用默认设置
# recognizer = cv2.face.LBPHFaceRecognizer_create(radius=1, neighbors=8, grid_x=8, grid_y=8)2.训练识别器
语法格式如下:
# 假设images是预处理过(灰度化、大小调整等)的图像列表,labels是对应的标签
images = [...] # 图像列表
labels = [...] # 对应的标签列表 # 训练识别器
recognizer.train(images, labels)3.使用predict()方法来识别人脸
语法结构如下:
# 假设test_image是待识别的图像,且已调整为与训练图像相同的大小
test_image = ... # 待识别的图像 # 预测
label, confidence = recognizer.predict(test_image) # 打印预测结果
print(f"Predicted label: {label}, Confidence: {confidence}") # 置信度评分小于某个阈值(例如5000)时,认为识别成功
if confidence < 5000: print("Recognized with high confidence!")
else: print("Low confidence recognition or unknown face.")操作实例代码:
import cv2
import numpy as npphotos = list() # 样本图像列表
lables = list() # 标签列表
photos.append(cv2.imread(r"B:\Python_opencv_book\12\09\face\lxe1.png", 0)) # 记录第1张人脸图像
lables.append(0) # 第1张图像对应的标签
photos.append(cv2.imread(r"B:\Python_opencv_book\12\09\face\lxe2.png", 0)) # 记录第2张人脸图像
lables.append(0) # 第2张图像对应的标签
photos.append(cv2.imread(r"B:\Python_opencv_book\12\09\face\lxe3.png", 0)) # 记录第3张人脸图像
lables.append(0) # 第3张图像对应的标签photos.append(cv2.imread(r"B:\Python_opencv_book\12\09\face\ruirui1.png", 0)) # 记录第4张人脸图像
lables.append(1) # 第4张图像对应的标签
photos.append(cv2.imread(r"B:\Python_opencv_book\12\09\face\ruirui2.png", 0)) # 记录第5张人脸图像
lables.append(1) # 第5张图像对应的标签
photos.append(cv2.imread(r"B:\Python_opencv_book\12\09\face\ruirui3.png", 0)) # 记录第6张人脸图像
lables.append(1) # 第6张图像对应的标签names = {"0": "LXE", "1": "RuiRui"} # 标签对应的名称字典recognizer = cv2.face.LBPHFaceRecognizer_create() # 创建LBPH识别器
recognizer.train(photos, np.array(lables)) # 识别器开始训练i = cv2.imread(r"B:\Python_opencv_book\12\09\face\ruirui4.png", 0) # 待识别的人脸图像
label, confidence = recognizer.predict(i) # 识别器开始分析人脸图像
print("confidence = " + str(confidence)) # 打印评分
print(names[str(label)]) # 数组字典里标签对应的名字cv2.waitKey()
cv2.destroyAllWindows()
操作效果:

4.总结
LBPH(Local Binary Patterns Histogram,局部二值模式直方图)、Eigenfaces和Fisherfaces是人脸识别中常用的三种算法,它们各自具有不同的优势和劣势。
LBPH人脸识别器
优势:
- 灵活性高:LBPH算法允许模型样本人脸和检测到的人脸在形状、大小上有所不同,这增加了算法的适用范围。
- 鲁棒性强:由于LBP特征对光照变化不敏感,LBPH算法在光照变化较大的环境中也能保持较好的识别效果。
- 计算效率高:LBP特征提取简单,计算速度快,适合实时性要求较高的场景。
劣势:
- 精度依赖样本质量:如果训练样本的质量不高,或者样本之间的差异性较小,可能会影响识别精度。
- 对极端表情和姿态的适应性差:在极端表情或姿态下,人脸特征可能会发生较大变化,影响识别效果。
Eigenfaces人脸识别器
优势:
- 理论基础扎实:Eigenfaces基于PCA(主成分分析)进行特征提取,PCA是计算机视觉中常用的降维技术,理论成熟。
- 计算相对简单:相比于其他复杂的人脸识别算法,Eigenfaces的计算过程相对简单。
劣势:
- 对光照敏感:Eigenfaces算法对光照变化较为敏感,光照条件的变化可能会影响识别效果。
- 识别精度有限:在复杂的人脸图像数据集中,Eigenfaces的识别精度可能不如一些更先进的算法。
Fisherfaces人脸识别器
优势:
- 识别精度高:Fisherfaces从PCA衍生发展而来,逻辑更复杂,计算更密集,通常能够获得比Eigenfaces更高的识别精度。
- 对光照和表情变化有一定适应性:Fisherfaces算法能够推断和插值照明和面部表情的变化,从而提高识别效果。
劣势:
- 计算复杂度高:相比于Eigenfaces和LBPH,Fisherfaces的计算复杂度更高,需要更多的计算资源。
- 训练过程较长:由于算法复杂,Fisherfaces的训练过程可能需要更长的时间。
相关文章:
OpenCV第十二章——人脸识别
1.人脸跟踪 1.1 级联分类器 OpenCV中的级联分类器是一种基于AdaBoost算法的多级分类器,主要用于在图像中检测目标对象。以下是对其简单而全面的解释: 一、基本概念 级联分类器:是一种由多个简单分类器(弱分类器)级联组…...

深入Volatile
深入Volatile 1、变量不可见性: 1.1多线程下变量的不可见性 直接上代码 /*** author yourkin666* date 2024/08/12/16:12* description*/ public class h1 {public static void main(String[] args) {MyClass myClass new MyClass();myClass.start();while (tr…...

数据结构 ——— 顺序表oj题:编写函数,合并两个有序数组
目录 题目要求 代码实现 题目要求 nums1 和 nums2 是两个升序的整型数组,另外有两个整数 m 和 n 分别代表 nums1 和 nums2 中的元素个数 要求合并 nusm2 到nums1 中,使合并后的 nums1 同样按升序顺序排列 最终,合并后的数组不应由函数返…...

Proto文件相关知识
百度Apollo的数据结构常用proto文件来定义, proto文件允许你以类似于C结构体或类的方式定义数据结构。你可以在这个文件中定义简单数据类型、枚举、消息类型等。 基于proto文件,Protocol Buffers编译器(protoc)可以自动生成对应的…...

k8s的控制节点不能访问node节点容器的ip地址
master控制node服务器添加容器后,访问不了该node服务器容器的ip,只能在node服务器访问 排查后发现是k8s的master服务器和node节点的网址网段和k8s初始化时提示的ip网段不一致 我之前是192.168.137.50, 实际上master主机期望的是192.168.1.50 解决方案: 1.删除服务器后重建ma…...

鸿蒙OpenHarmony
开源鸿蒙系统编译指南 Ubuntu编译环境配置第一步:Shell 改 Bash第二步:安装Git和安装pip3工具第三步:远程仓配置第四步:拉取代码第五步:安装编译环境第六步:本地编译源码 Windows开发环境配置第一步&#x…...
把白底照片变蓝色用什么软件免费 批量更换证件照底色怎么弄
作为专业的修图师,有时候也会接手证件照修图和换底色工作,这种情况下,需要换底色的照片也许达到上百张。为了提高工作效率,一般需要批量快速修图,那么使用什么软件工具能够给各式不同的照片批量更换背景色呢࿱…...
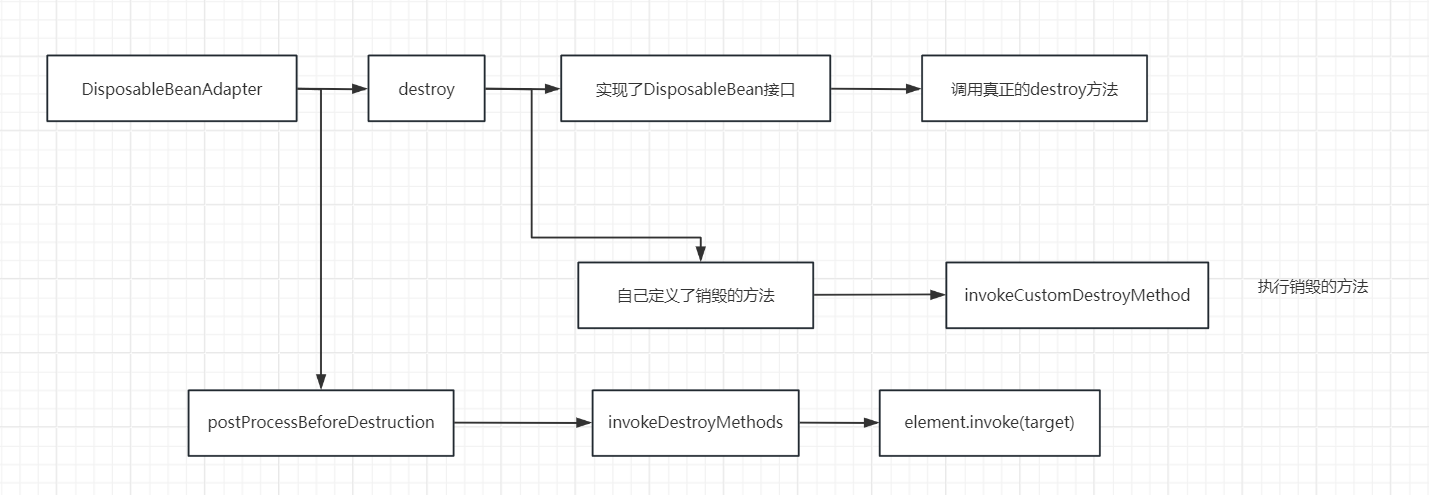
Spring之生成Bean
Bean的生命周期:实例化->属性填充->初始化->销毁 核心入口方法:finishBeanFactoryInitialization-->preInstantiateSingletons DefaultListableBeanFactory#preInstantiateSingletons用于实例化非懒加载的bean。 1.preInstantiateSinglet…...

笔记整理—linux进程部分(6)进程间通信、alarm和pause
两个进程间通信可能是任何两个进程间的通信(IPC)。同一个进程是在同一块地址空间中的,在不同的函数与文件以变量进程传递,也可通过形参传递。2个不同进程处于不同的地址空间,要互相通信有难度(内存隔离的原…...

Java网络通信—UDP
0.小记 1.udp通信不需要建立socket管道,一边只管发,一边只管收 2.客户端:将数据(byte)打包成包裹(DatagramPacket),写上地址(IP端口),通过快递站&…...

k8s架构,从clusterIP到光电半导体,再从clusterIP到企业管理
clusterIP作为k8s中的服务, 也是其他三个服务的基础 ~]$ kubectl create service clusterip externalname loadbalancer nodeport 客户端的流量到service service分发给pod,pod由控制器自动部署,自动维护 那么问题是service的可用…...

vue框架和uniapp框架区别
文章目录 vue框架和uniapp框架区别一、引言二、Vue.js 概述1、Vue.js 简介1.1、特点 2、适用场景 三、Uni-app 概述1、Uni-app 简介1.1、特点 2、适用场景 四、区别与比较1、跨平台能力2、开发体验3、性能优化4、社区和支持 五、总结 vue框架和uniapp框架区别 一、引言 在前端…...

828华为云征文 | 华为云Flexus云服务器X实例搭建Zabbix网络设备监视系统(Ubuntu服务器运维)
前言 Flexus X实例内嵌智能应用调优算法,性能强悍,基础模式GeekBench单核及多核跑分可达同规格独享型实例的1.6倍,性能模式更是超越多系列旗舰型云主机,为企业业务提供强劲动力。 💼 Flexus X Zabbix:打造…...
、多线程(Multi-threaded))
JAVA基础-线程(Thread)、多线程(Multi-threaded)
1、知识铺垫 要想了解什么是线程,首先要搞明白线程与进程的区别,并行与并发的区别 1.1 线程与进程 进程:是指⼀个内存中运⾏的应⽤程序,每个进程都有⼀个独⽴的内存空间,⼀个应⽤程序可以同时运⾏多个进程;…...

hystrix微服务部署
目录 一.启动nacos和redis 1.查看是否有nacos和redis 二.开始项目 1.hystrix1工程(修改一下工程的注册名字) 2.运行登录nacos网站查看运行效果(默认密码nacos,nacos) 3.开启第二个项目 hystrix2工程 4.关闭第二个项目 hyst…...

使用百度文心智能体创建多风格表情包设计助手
文章目录 一、智能定制,个性飞扬二、多元风格,创意无限 百度文心智能体平台为你开启。百度文心智能体平台,创建属于自己的智能体应用。百度文心智能体平台是百度旗下的智能AI平台,集成了先进的自然语言处理技术和人工智能技术&…...

【嵌入式裸机开发】智能家居入门3(MQTT服务器、MQTT协议、微信小程序、STM32)
前面已经写了两篇博客关于智能家居的,服务器全都是使用ONENET中国移动,他最大的优点就是作为数据收发的中转站是免费的。本篇使用专门适配MQTT协议的MQTT服务器,有公用的,也可以自己搭建 前言一、项目总览二、总体流程分析1、了解…...

css的背景background属性
CSS的background属性是一个简写属性,它允许你同时设置元素的多个背景相关的子属性。使用这个属性可以简化代码,使其更加清晰和易于维护。background属性可以设置不同的子属性。 background子属性 定义背景颜色 使用background-color属性 格式&#x…...

Cypress自动化测试实战:构建高效的前端测试体系
在快速迭代的软件开发环境中,前端自动化测试是保证代码质量和用户体验的重要手段。Cypress作为一款功能强大的前端自动化测试工具,凭借其丰富的特性、直观的API和高效的测试执行速度,赢得了众多开发者和测试团队的青睐。本文将深入探讨Cypres…...

【YOLO学习】YOLOv2详解
文章目录 1. 概述2. Better2.1 Batch Normalization(批归一化)2.2 High Resolution Classifier(高分辨率分类器)2.3 Convolutional With Anchor Boxes(带有Anchor Boxes的卷积)2.4 Dimension Clusters&…...

3个技巧彻底改变你的泰坦之旅装备管理体验
3个技巧彻底改变你的泰坦之旅装备管理体验 【免费下载链接】TQVaultAE Extra bank space for Titan Quest Anniversary Edition 项目地址: https://gitcode.com/gh_mirrors/tq/TQVaultAE 你是否曾在泰坦之旅的冒险中,面对满仓库的传奇装备却找不到需要的那一…...

Stryker.NET在CI/CD中的应用:如何在DevOps流水线中集成变异测试
Stryker.NET在CI/CD中的应用:如何在DevOps流水线中集成变异测试 【免费下载链接】stryker-net Mutation testing for .NET core and .NET framework! 项目地址: https://gitcode.com/gh_mirrors/st/stryker-net Stryker.NET是一款强大的.NET变异测试工具&…...

长期项目使用Taotoken按Token计费模式带来的成本优化体感
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期项目使用Taotoken按Token计费模式带来的成本优化体感 1. 项目背景与计费模式选择 我们团队维护着一个中等规模的AI应用项目&a…...

Prometheus监控主机,Grafana成图
全部使用官方 GitHub 源的部署方案,下载链接来自官方,无需镜像。 官方下载地址汇总 组件 官方下载地址 Node Exporter https://github.com/prometheus/node_exporter/releases/download/v1.8.2/node_exporter-1.8.2.linux-amd64.tar.gz Prometheus https…...
:定义第一个类——成员变量与成员函数)
【c++面向对象编程】第2篇:类与对象(一):定义第一个类——成员变量与成员函数
目录 一、从一个日常需求开始 二、定义你的第一个类 三、访问修饰符:public、private、protected 举个例子,看看区别: 四、成员变量怎么声明? 五、成员函数:两种实现方式 方式一:类内实现(…...

番茄小说下载器:打造个人专属离线小说图书馆的完整指南
番茄小说下载器:打造个人专属离线小说图书馆的完整指南 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 你是否曾在通勤路上突然想读小说,却因为网络信号不佳而无法加…...

crawdad-openclaw:构建高韧性智能爬虫的模块化框架实战
1. 项目概述:一个为数据抓取而生的开源“机械爪”如果你和我一样,在数据工程或网络爬虫领域摸爬滚打过几年,那你一定经历过这样的时刻:面对一个结构复杂、反爬机制严密的网站,你精心编写的爬虫脚本在运行了几个小时后&…...

基于Bing搜索的GPT智能体:实现大语言模型实时联网搜索
1. 项目概述:一个基于Bing搜索的GPT智能体 最近在GitHub上闲逛,发现了一个挺有意思的项目,叫 bujnlc8/gptbing 。光看名字,你可能会觉得这又是一个“GPT套壳”应用,无非是把OpenAI的API包装一下。但如果你仔细琢磨一…...

量子计算在供应链风险模拟中的革命性应用
1. 量子计算在供应链风险模拟中的革命性突破零售供应链风险管理正面临前所未有的挑战。2021年全球半导体短缺导致汽车行业损失2100亿美元,而疫情期间超市缺货率超过15%——这些危机暴露了传统风险模型的根本缺陷:它们假设供应链节点故障是独立事件&#…...

书匠策AI到底能帮你搞定毕业论文几步?一个教育博主的拆解实录
你有没有经历过这样的夜晚——凌晨两点,对着空白文档,光标一闪一闪,仿佛在嘲笑你连选题都没定? 别慌,今天我不讲大道理,直接拿一个工具给你做一次"开颅式拆解"。这个工具叫书匠策AI,…...