Redis: 集群测试和集群原理
集群测试
1 ) SET/GET 命令
- 测试 set 和 get 因为其他命令也基本相似,
- 我们在 101 节点上尝试连接 103 $
/usr/local/redis/bin/redis-cli -c -a 123456 -h 192.168.10.103 -p 6376 - 我们在插入或读取一个 key的时候,会对这个key做一个hash运算,运算完以后会得到对应槽的索引值
- 之后,就会把key插入槽里,当执行 $
set username zhangsan,username 这个key就会被hash运算- > Reddirecte to slot [14315] located at 192.168.10.103:6375 - 可见 username 的 槽是 14315,在 103:6375 这个实例上
- 并且,我现在如果执行 set 的时候主机是 6376,命令行会重定向到 6375,这是内部的一个转向

- 这是它内部在做的一个转向操作,之后,执行 $
set age 18这个 age 运算完后插入 741槽 - 这里又有了一个转向,741 这个槽在 6371的实例范围之内, 这些范围在 $
cluster nodes返回可见

- 执行 $
set address sh发现并没有做转向,原因肯定是 address 运算之后,在 6371 实例槽的范围之内

- 注意,get 也一样,会转向, 不再演示
2 ) 开启从节点只读模式
- 关于从节点的只读模式,通过上面的例子,可以看出,所有的操作都是转发到主节点上去的
- 目前从节点只起到备份容灾的角色,而非读的角色分担压力,目前还没有开启从节点的读功能
- 我现在要释放压力,把读的压力给从节点,我只需要在从节点中执行一个 $
READONLY命令即可 - 注意,这个 $
READONLY命令只支持自己主节点的key的范围- 就是如果获取的 key 不在这个从节点复制的主节点中
- 它是没有办法给你直接返回的,它还是会去做转发,这是必然的
单节点和集群模式的性能测试
- 我们对性能进行一个测试,通过 Redis 自带的 redis-benchmark 命令
- Redis 是通过同时执行多个命令实现的
- 把集群和单机分别执行一百万的get和set,看一下谁的性能更高,其实单机的性能是比较高的
- 在集群环境测试的时候,get/set 它内部会去做一个转向的处理, 单机没有这个过程
1 )语法
-
$
redis-benchmark [option] [option value] -
参数
选项 描述 -h 指定服务器主机名 -p 指定服务器端口 -s 指定服务器 socket 方式连接 -c 指定并发连接数 -n 指定请求数 -d 以字节的形式指定SET/GET值的数据大小 -k 1=keep alive 0=reconnect -r SET/GET/INCR 使用随机 Key -P 通过管道传输请求 -q 指定强制退出 Redis –csv 以CsV格式输出 -l 生成循环,永久执行测试 -t 仅运行以逗号分隔的测试命令列表
2 ) 单机测试
# 随机set/get1000000条命令1000个并发
bin/redis-benchmark -a 123456 -h 192.168.10.101 -p 6379 -t set,get -r 1000000 -n 1000000 -c 1000
3 ) 集群测试
# 随机set/get1000000条命令1000个并发
bin/redis-benchmark -a 123456 -h 192.168.10.101 -p 6371 -t set, get -r 1000000 -n 1000000 -c 1000
4 ) 对比结果
- 综合上述单机和集群跑出来的数据结果,单机要更快!
集群原理
- 我们之前用到的单机,主从,哨兵这几种模式数据都是存在单个节点上
- 如果说是主从的话,会有从节点,从节点也只是对主节点的数据进行复制
- 而我们单个节点它存储是有上限的,而且我们说它还有写压力等
- 集群其实就是把请求包括数据的存储都分在了不同的节点上,就是把数据进行了分片存储
- 当一个分片的数量达到上限的时候,还可以给它分成多个分片
1 ) 哈希槽
- 集群的原理是什么? 它的本质是哈希槽
- Redis 集群,它并没有选用一致性哈希,一致性哈希它是一个圆环,它的节点是分配在这个圆环上
- 当我们插入和删除节点的时候,它是会影响响临近的节点,对其他的节点没有影响,这是它的优点
- 但是缺点就是在节点比较少的情况下,当你插入一个新的节点的时候,它影响到数据会比较多
- 因为我们要做数据迁移,除非你有上千个节点,这个时候添加一个节点影响的就微乎其微了
- 所以说它不太适合那种节点比较少的分布式的缓存
- 一般我们公司里的集群不可能达到上千个节点,因为它性能本身就很高
- 所以说 Redis 的集群它并没有选择一致性哈希算法
- 它采用的是哈希槽的这种概念,主要原因就是一致性哈希它对于数据的分布
- 节点的位置的控制并不是很友好
- 哈希槽其实是两个概念
- 第一个概念就是哈希算法,Redis Cluster 的 hash算法,它不是简单的 hash()
- 而是内部的一个crc16的算法, 是一种校验算法
- 第二个就是槽位的一个概念,就是空间分配的规则
- 其实哈希槽的本质和一致性哈希算法是非常相似的
- 不同点就是对于哈希空间的定义
- 一致性哈希的空间是一个圆环,节点分布是基于圆环的
- 没有办法很好的就是控制数据的分布
- 圆环节点分布在圆环上,你节点比较少的时候,插入一个节点
- 对临近的节点有影响,数据迁移就会比较多
- 除非现在这个环上有上千个节点,在添加一个节点的时候,它的影响就非常非常小了
- 所以它不适合少量数据节点的分布式方案
- 而 Redis Cluster 槽位空间,它是可以自定义分配的
- 就类似于像windows 盘符分区, 这种分区可以自定义大小,自定义位置
- 就很好的可以去方便的管理,比如说我现在在D盘上右键扩展卷
- 我就把D盘的一部分分出去变成一个E盘,对E盘还可以合并其他盘或删除E盘
- 这样来回操作都没有什么问题,非常方便管理
- 一致性哈希的空间是一个圆环,节点分布是基于圆环的
- 第一个概念就是哈希算法,Redis Cluster 的 hash算法,它不是简单的 hash()
- 注意,对于槽位的转移和分派,Redis集群是不会自动进行的,而是需要人工配置的
- 所以,Redis集群的高可用是依赖于节点的主从复制和主从间的故障转移。
- Redis Cluster 它内部的哈希槽是 16384 个,通过 之前 check 检查的命令可以看出
- 对于主节点的槽位的分配还是非常平均的
- 这默认是Redis Cluster 自己去做的,当然我们人为的也可以去做这样的分配
- 每个key 通过计算都会落在一个具体的槽位上,这个槽位,比如说属于哪个节点的
- 然后这个我们自己在添加槽的时候,就可以自己来定义了
- 比如说你的这个机器硬盘比较小,我们给它分配少一点
- 哈希槽的这种概念就很好的解决了一致性哈希的一个缺点,而且它在容错和扩展上也非常的方便
- 虽然说它表象跟一致性哈希一样,都是对受影响的数据进行转移
- 但哈希槽本质其实是对槽位的转移
- 就是它会把故障的节点负责的这个槽位转到其他正常的节点上
- 扩展节点也是一样的, 比如说我现在新加了一个节点
- 我可以把其他节点上的槽再转移到这个新的节点上,就非常的方便,影响很低的
- 因为它固定了聚集在这些槽的某一个节点
2 ) 16384 个 slots (槽位)
-
Redis Cluster 没有单机那种 16个数据库 (0 - 15) 数据库的概念了,就是我们已经看不到数据库了
-
而是分成了 16384 个 slots (槽位) ,每个节点负责其中一部分槽位,槽位的信息存储于每个节点中
-
那我们客户端这边是怎么来操作集群的呢?
- 当客户端连接集群的时候,首先它会得到一份集群的槽位配置信息
- 然后把它缓存到客户端本地,这样客户端要查找某个key的时候,就可以直接定位到目标节点
- 同时因为槽位的信息可能会存在客户端服务器不一致的情况
- 那这个里边还会有纠错机制来实现槽位信息的一个调整
- 客户端,随便找一台都能连上,对吧?都能连上,然后连上之后看到的效果都是一样的
3 )槽位定位算法
- Redis Cluster 默认会对key值使用CRC16算法进行hash得到一个整数值
- 再把这个整数对 16384 取余,取完余以后会得到一个具体的槽位
- 这个就是槽位的计算公式: HASH_SLOT = CRC16(key) mod 16384
- 不管是 SET/GET 都是用这个方式
- 基于此,Redis Cluster 它提供了灵活的节点的扩容和缩容的方案
- 而且可以在不影响集群对外提供服务的情况下,为我们的集群添加节点进行扩容
- 也可以下线部分节点进行缩容
- 这里的槽其实就是 Redis Cluster 管理数据的基本单位
- 集群的伸缩,其实就是咱们的槽和对应的数据在节点之间的移动
- 对于这个槽位算法,简单的理解就扩容缩容之后槽需要重新分配,数据也需要重新迁移
- 但是服务不需要下线,而且他对于数据和节点的影响非常的小
- 为什么是 16834 个槽,而不是别的数字呢?
- https://github.com/redis/redis/issues/2576
- 这里考虑心跳消息头的一个大小, 会达到 8k,过于庞大,比较占带宽
- 还有就是关于节点,数量不可能到达1000的,16834 足够
- 第三个就是就是槽位越小节点少的情况下压缩率越高
- 哈希槽的存储是通过 bitmap 形式来进行保存的
- 传输的过程中会对 bitmap 进行压缩
- 如果哈希槽越多,压缩率就会很低,而 16834 / 8 约等于 2kb 这个压缩率会很高
相关文章:
Redis: 集群测试和集群原理
集群测试 1 ) SET/GET 命令 测试 set 和 get 因为其他命令也基本相似,我们在 101 节点上尝试连接 103 $ /usr/local/redis/bin/redis-cli -c -a 123456 -h 192.168.10.103 -p 6376我们在插入或读取一个 key的时候,会对这个key做一个hash运算,…...

问题解决实录 | bash 中 tmux 颜色显示不全
点我进入博客 如下图,tmux 中颜色显示不全: echo $TERM输出的是 screen 但在 bash 里面输出的是 xterm-256 color 在 bash 里面输入: touch ~/.tmux.conf vim ~/.tmux.conf set -g default-terminal "xterm-256color"使之生效 source …...

古典舞在线交流平台:SpringBoot设计与实现详解
摘 要 随着互联网技术的发展,各类网站应运而生,网站具有新颖、展现全面的特点。因此,为了满足用户古典舞在线交流的需求,特开发了本古典舞在线交流平台。 本古典舞在线交流平台应用Java技术,MYSQL数据库存储数据&#…...

五子棋双人对战项目(6)——对战模块(解读代码)
目录 一、约定前后端交互接口的参数 1、房间准备就绪 (1)配置 websocket 连接路径 (2)构造 游戏就绪 的 响应对象 2、“落子” 的请求和响应 (1)“落子” 请求对象 (2)“落子…...

查缺补漏----I/O中断处理过程
中断优先级包括响应优先级和处理优先级,响应优先级由硬件线路或查询程序的查询顺序决定,不可动态改变。处理优先级可利用中断屏蔽技术动态调整,以实现多重中断。下面来看他们如何运用在中断处理过程中: 中断控制器位于CPU和外设之…...

Java API接口开发规范
文章目录 一、命名规范1.1 接口命名1.2 变量命名 二、接收参数规范2.1 请求体(Body)2.2 查询参数(Query Parameters) 三、参数检验四、接收方式规范五、异常类处理六、统一返回格式的定义七、API接口的幂等性(Idempote…...

Go语言实现长连接并发框架 - 任务管理器
文章目录 前言接口结构体接口实现项目地址最后 前言 你好,我是醉墨居士,我们上篇博客实现了路由分组的功能,接下来这篇博客我们将要实现任务管理模块 接口 trait/task_mgr.go type TaskMgr interface {RouterGroupStart()StartWorker(tas…...

【大数据】深入解析分布式数据库:架构、技术与未来
目录 1. 分布式数据库的定义2. 架构类型2.1 主从架构2.2 同步与异步复制2.3 分片架构 3. 技术实现3.1 一致性模型3.2 CAP理论3.3 数据存储引擎 4. 应用场景5. 选择分布式数据库的因素5.1 数据一致性需求5.2 读写负载5.3 成本5.4 技术栈兼容性 6. 未来发展趋势总结 分布式数据库…...

uniapp框架中实现文件选择上传组件,可以选择图片、视频等任意文件并上传到当前绑定的服务空间
前言 uni-file-picker是uniapp中的一个文件选择器组件,用于选择本地文件并返回选择的文件路径或文件信息。该组件支持选择单个文件或多个文件,可以设置文件的类型、大小限制,并且可以进行文件预览。 提示:以下是本篇文章正文内容,下面案例可供参考 uni-file-picker组件具…...

GEE教程:NASA/GRACE/MASS_GRIDS/LAND数据的查看不同时期液态水数据的变化情况
目录 简介 NASA/GRACE/MASS_GRIDS/LAND 函数 first() Arguments: Returns: Image 代码 结果 简介 利用NASA/GRACE/MASS_GRIDS/LAND数据的查看不同时期液态水数据的变化情况。 NASA/GRACE/MASS_GRIDS/LAND NASA/GRACE/MASS_GRIDS/LAND数据是由NASA的重力恒星MASS数据…...

世邦通信股份有限公司IP网络对讲广播系统RCE
漏洞描述 SPON世邦IP网络广播系统采用的IPAudio™技术, 将音频信号以数据包形式在局域网和广域网上进行传送,是一套纯数字传输的双向音频扩声系统。传统广播系统存在的音质不佳,传输距离有限,缺乏互动等问题。该系统设备使用简便,…...

爬虫——爬取小音乐网站
爬虫有几部分功能??? 1.发请求,获得网页源码 #1.和2是在一步的 发请求成功了之后就能直接获得网页源码 2.解析我们想要的数据 3.按照需求保存 注意:开始爬虫前,需要给其封装 headers {User-…...

5G NR SSB简介
文章目录 SSB介绍SSB波束扫描 SSB介绍 5G NR 引入了SSB 这个概念,同步信号和PBCH块(Synchronization Signal and PBCH block, 简称SSB) 它由主同步信号(Primary Synchronization Signals, 简称PSS)、辅同步信号(Secondary Synchronization Signals, 简称SSS)、PBCH…...

java将mysql表结构写入到word表格中
文章目录 需要的依赖 需要的依赖 <dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>3.9</version> </dependency> <!--07版本的,行数不受限制--> <dependency>&l…...

SpringBoot教程(安装篇) | Docker Desktop的安装(Windows下的Docker环境)
SpringBoot教程(安装篇) | Docker Desktop的安装(Windows下的Docker环境) 前言如何安装Docker Desktop资源下载安装启动(重点)1. 检查 bcdedit的hypervisorlaunchtype是否为Auto2. 检查CPU是否开启虚拟化3.…...

day2网络编程项目的框架
基于终端的 UDP云聊天系统 开发环境 Linux 系统GCCUDPmakefilesqlite3 功能描述 通过 UDP 网络使服务器与客户端进行通信吗,从而实现云聊天。 Sqlite数据库 用户在加入聊天室前,需要先进行用户登录或注册操作,并将注册的用户信息…...

C++和OpenGL实现3D游戏编程【连载13】——多重纹理混合详解
🔥C++和OpenGL实现3D游戏编程【目录】 1、本节要实现的内容 前面说过纹理贴图能够大幅提升游戏画面质量,但纹理贴图是没有叠加的。在一些游戏场景中,要求将非常不同的多个纹理(如泥泞的褐色地面、绿草植密布的地面、碎石遍布的地面)叠加(混合)起来显示,实现纹理间能够…...

探索云计算中的 Serverless 架构:未来的计算范式?
目录 引言 一、Serverless架构概览 二、Serverless 架构的优势 三、Serverless架构的挑战 四、Serverless架构的未来展望 五、结论 引言 在当今快速发展的 IT 行业中,云计算无疑占据了举足轻重的地位。随着技术的不断演进,云计算的一个新兴分支——…...
爬虫及数据可视化——运用Hadoop和MongoDB数据进行分析
作品详情 运用Hadoop和MongoDB对得分能力数据进行分析; 运用python进行机器学习的模型调理,利用Pytorch框架对爬取的评论进行情感分析预测; 利用python和MySQL对网站的数据进行爬取、数据清洗及可视化。...
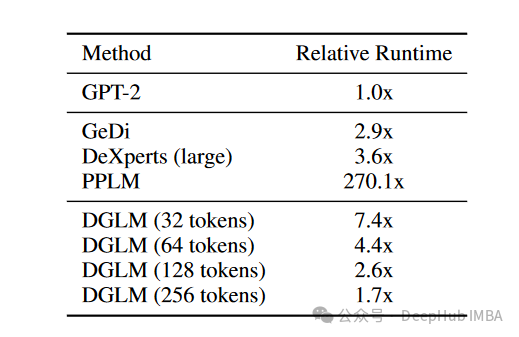
扩散引导语言建模(DGLM):一种可控且高效的AI对齐方法
随着大型语言模型(LLMs)的迅速普及,如何有效地引导它们生成安全、适合特定应用和目标受众的内容成为一个关键挑战。例如,我们可能希望语言模型在与幼儿园孩子互动时使用不同的语言,或在撰写喜剧小品、提供法律支持或总结新闻文章时采用不同的风格。 目前,最成功的LLM范式是训练…...

群晖NAS远程SSH配置全解:从权限控制到独立模式实战
1. 为什么群晖的SSH不是“开个开关”就完事——从权限失控风险说起群晖NAS作为家用与小型办公场景中最普及的存储设备,很多人买来装好硬盘、配好共享文件夹,就觉得万事大吉。直到某天想批量处理照片缩略图、想用rsync做异地备份、想部署一个轻量级服务&a…...

AV1编码背景及现状
AV1(AOMedia Video 1)是一种开放的、免版税的视频编码标准,由开放媒体联盟开发。该标准的最初设计目的是用于互联网上的视频传输,同时提供一个对所有用户开放且无须支付版税的视频压缩解决方案。作为 VP9的下一代视频编码标准&…...
)
超越UNO:手把手教你为ESP8266和AVR单片机配置任意GPIO中断(附端口变化中断PCINT实战)
突破硬件限制:ESP8266与AVR单片机全引脚中断配置实战指南 在嵌入式开发中,中断处理是提升系统响应效率的核心技术。传统Arduino UNO仅提供2个专用外部中断引脚(D2和D3),当项目需要同时监控多个传感器或按钮时ÿ…...

Sunshine游戏串流快速上手:3步搭建你的个人云游戏服务器
Sunshine游戏串流快速上手:3步搭建你的个人云游戏服务器 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想要在任何设备上玩转PC游戏大作吗?Sunshine作为一…...

QiMeng-TensorOp:自动生成高性能张量运算代码的框架
1. 项目概述QiMeng-TensorOp是一个革命性的张量算子自动生成框架,它能够基于硬件原语自动生成高性能的张量运算代码。在现代深度学习和大型语言模型(LLMs)中,张量运算如矩阵乘法(GEMM)和卷积(Conv)占据了90%以上的计算量。传统的手动优化方法需要数月时间…...

嵌入式与复杂系统安全开发实战:从威胁建模到安全编码的十大核心实践
1. 项目概述:为什么安全开发不再是“可选项”?干了十几年软件开发,从早期的桌面应用到后来的Web服务,再到近几年深度参与的嵌入式系统,我最大的感触就是:安全这件事,已经从“锦上添花”变成了“…...

铜钟音乐平台完整指南:三步打造纯净无干扰的听歌体验
铜钟音乐平台完整指南:三步打造纯净无干扰的听歌体验 【免费下载链接】tonzhon-music 铜钟 Tonzhon (tonzhon.whamon.com): 干净纯粹的音乐平台 (铜钟已不再使用 tonzhon.com,现在的 tonzhon.com 不是正版的铜钟) 项目地址: https://gitcode.com/GitHu…...

6. 网络优化方法之 学习率 优化/衰减策略
1. 学习率优化如图:学习率0.01时收敛速度很慢,学习率0.1时收敛速度变快,学习率越大 收敛速度越快; 学习率0.2 即学习率较大是会 来回震荡,学习率0.3 即学习率过大时会发生 梯度爆炸(即远远超出所在范围&…...
:Handle进阶——批量巡检、自动审计与高危操作SOP)
《Sysinternals实战指南》进程和诊断工具学习笔记(8.25):Handle进阶——批量巡检、自动审计与高危操作SOP
🔥个人主页:杨利杰YJlio❄️个人专栏:《Sysinternals实战教程》《Windows PowerShell 实战》《WINDOWS教程》《IOS教程》《微信助手》《锤子助手》 《Python》 《Kali Linux》 《那些年未解决的Windows疑难杂症》🌟 让复杂的事情更…...

最常见的漏洞有哪些?如何发现存在的漏洞呢
常见Web漏洞类型: 1、SQL注入(SQL Injection) 攻击者通过在应用程序的输入中注入恶意的SQL代码,从而绕过程序的验证和过滤机制,执行恶意的SQL查询或命令,通常存在于使用动态SQL查询的Web应用中,…...