【Linux系统编程】第二十七弹---文件描述符与重定向:fd奥秘、dup2应用与Shell重定向实战
✨个人主页: 熬夜学编程的小林
💗系列专栏: 【C语言详解】 【数据结构详解】【C++详解】【Linux系统编程】
目录
1、文件描述符fd
1.1、0 & 1 & 2
1.2、文件描述符的分配规则
2、重定向
3、使用 dup2 系统调用
3.1、> 输出重定向
3.2、>> 追加重定向
3.3、< 输入重定向
3.4、shell模拟实现> >> <
4、缓冲区
1、文件描述符fd
- 通过对open函数的学习,我们知道了文件描述符就是一个小整数
查看open的返回值fd。
会用到的头文件
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>代码演示
int main()
{// 查看open返回值是什么int fda = open("loga.txt",O_WRONLY | O_CREAT | O_TRUNC,0666);printf("fda : %d\n",fda);int fdb = open("logb.txt",O_WRONLY | O_CREAT | O_TRUNC,0666);printf("fdb : %d\n",fdb);int fdc = open("logc.txt",O_WRONLY | O_CREAT | O_TRUNC,066);printf("fdc : %d\n",fdc);int fdd = open("logd.txt",O_WRONLY | O_CREAT | O_TRUNC,0666);printf("fdd : %d\n",fdd);return 0;
}
运行结果
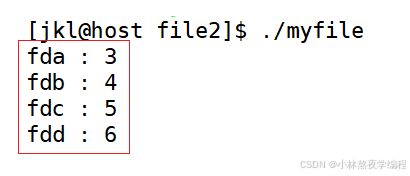
结果是从3开始,且是依次递增的。
1.1、0 & 1 & 2
fd为什么从3开始呢?0 1 2分别代表什么呢?
- Linux进程默认情况下会有3个缺省打开的文件描述符,分别是标准输入0, 标准输出1, 标准错误2,根据文件描述符分配规则(后序一个标题详细讲解),找到当前没有被使用的最小的一个下标,作为新的文件描述符。
- 0,1,2对应的物理设备一般是:键盘,显示器,显示器。
补充(使用系统调用读文件):
#include <unistd.h>ssize_t read(int fd, void *buf, size_t count);尝试从文件描述符 fd 读取最多 count 个字节到从 buf 开始的缓冲区。
验证一
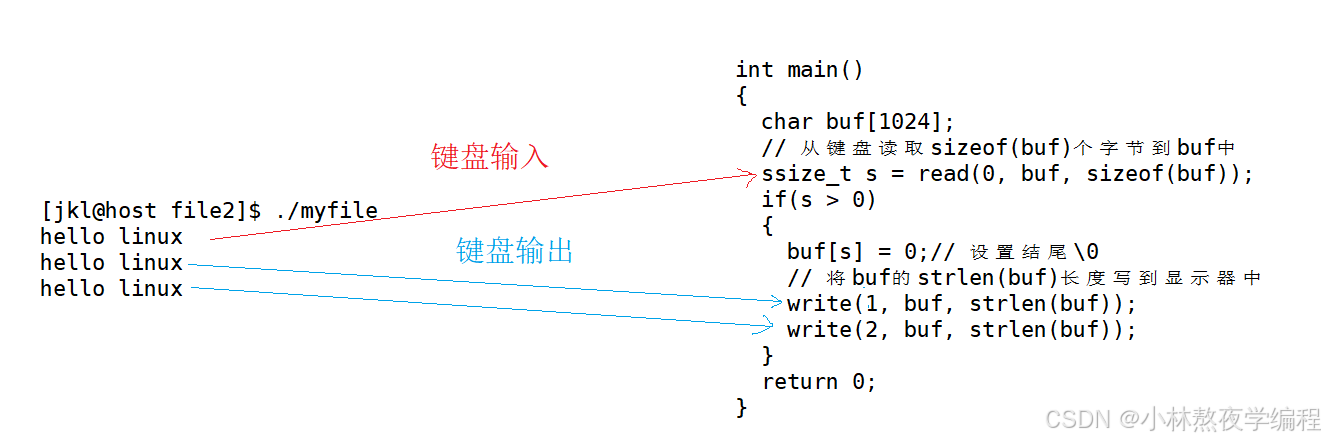
int main()
{char buf[1024];// 从键盘读取sizeof(buf)个字节到buf中ssize_t s = read(0, buf, sizeof(buf));if(s > 0){buf[s] = 0;// 设置结尾\0// 将buf的strlen(buf)长度写到显示器中write(1, buf, strlen(buf));write(2, buf, strlen(buf));}return 0;
}运行结果
内核结构
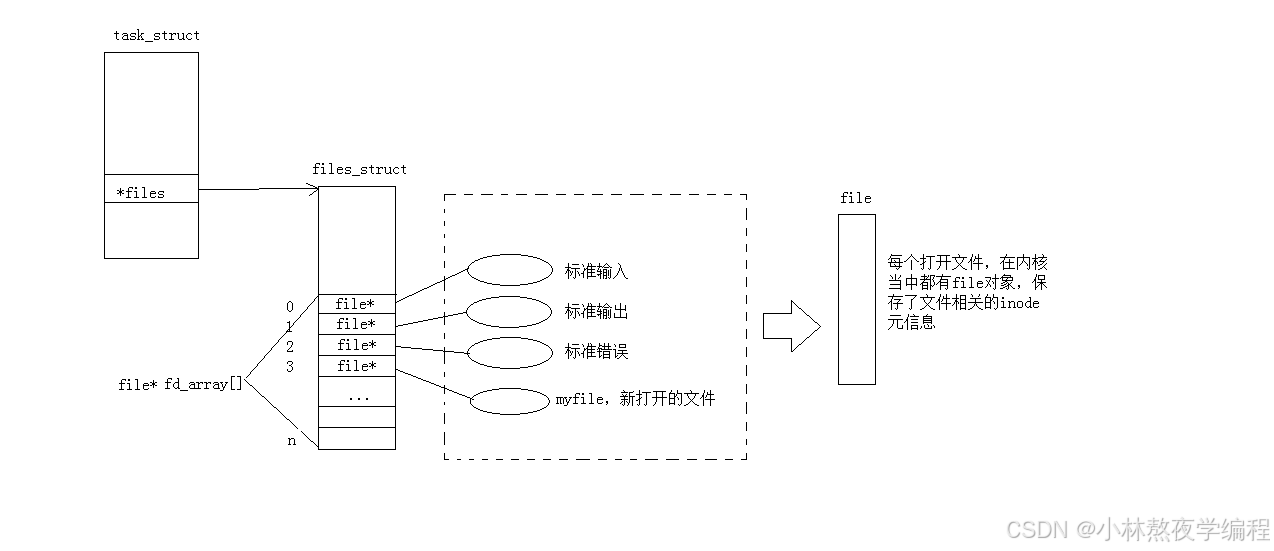
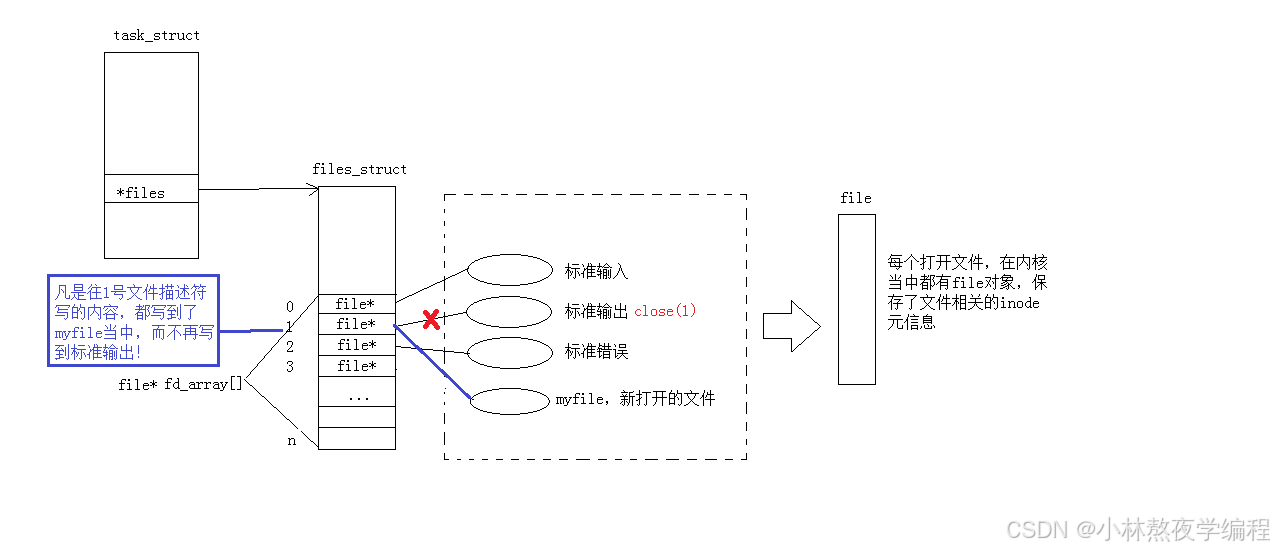
而现在知道,文件描述符就是从0开始的小整数。当我们打开文件时,操作系统在内存中要创建相应的数据结构来描述目标文件。于是就有了file结构体。表示一个已经打开的文件对象。而进程执行open系统调用,所以必须让进程和文件关联起来。每个进程都有一个指针*files, 指向一张表files_struct,该表最重要的部分就是包涵一个指针数组,每个元素都是一个指向打开文件的指针!所以,本质上,文件描述符就是该数组的下标。所以,只要拿着文件描述符,就可以找到对应的文件。
进一步验证
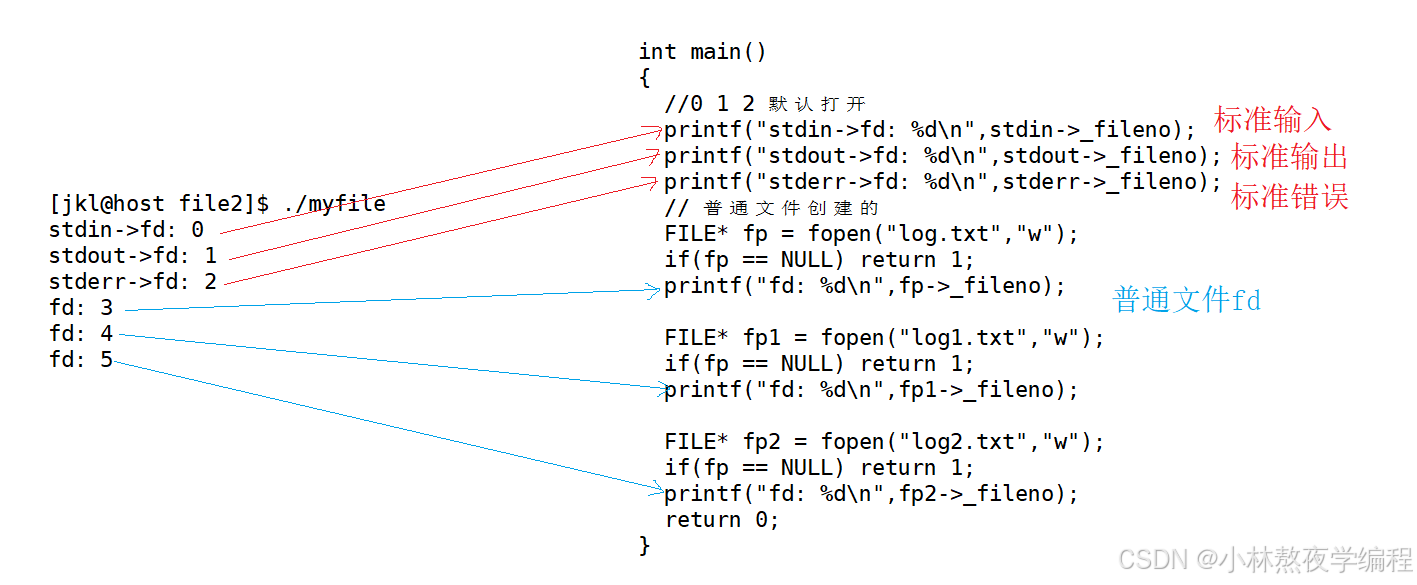
fd在C语言层面其实是FILE结构体中的一个 _fileno 成员,我们可以打印这个成员的结果来验证0,1,2。
代码演示
int main()
{//0 1 2 默认打开 printf("stdin->fd: %d\n",stdin->_fileno);printf("stdout->fd: %d\n",stdout->_fileno);printf("stderr->fd: %d\n",stderr->_fileno);// 普通文件创建的FILE* fp = fopen("log.txt","w");if(fp == NULL) return 1;printf("fd: %d\n",fp->_fileno);FILE* fp1 = fopen("log1.txt","w");if(fp == NULL) return 1;printf("fd: %d\n",fp1->_fileno);FILE* fp2 = fopen("log2.txt","w");if(fp == NULL) return 1;printf("fd: %d\n",fp2->_fileno);return 0;
}运行结果
1.2、文件描述符的分配规则
关闭0或者2
int main()
{close(2);//close(0);int fd = open("log.txt",O_WRONLY | O_CREAT | O_TRUNC,0666);if(fd < 0) {perror("open");return 1;}printf("fd: %d\n",fd);return 0;
}运行结果

从关闭0号和2号文件描述符我们可以看到,关闭几号创建新文件的fd就是几号。
文件描述符的分配规则:在files_struct数组当中,找到当前没有被使用的最小的一个下标,作为新的文件描述符。
2、重定向
代码演示
int main()
{close(1);int fd = open("log.txt",O_WRONLY | O_CREAT | O_TRUNC,0666);if(fd < 0){perror("open");return 1;}printf("fd: %d\n",fd);fflush(stdout);close(fd);return 0;
}运行结果

此时,我们发现,本来应该输出到显示器上的内容,输出到了文件 myfile 当中,其中,fd=1。这种现象叫做输出重定向。常见的重定向有:>, >>, <。
那重定向的本质是什么呢?
上层用的 fd 不变,在内核中更改 fd 对应的 struct file* 地址。
3、使用 dup2 系统调用
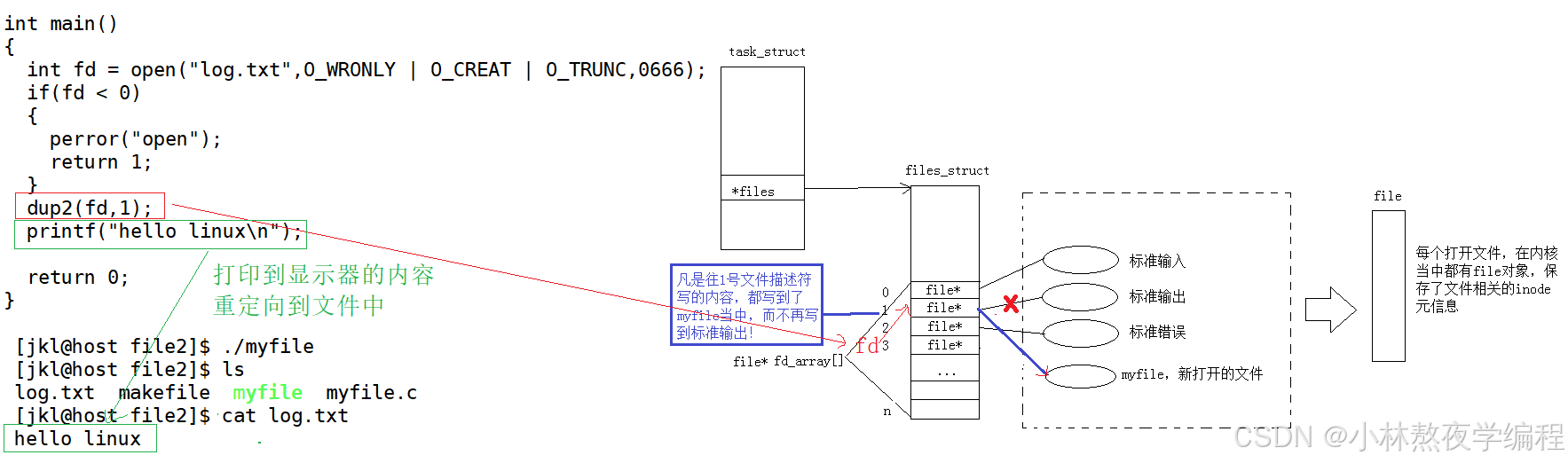
#include <unistd.h>int dup2(int oldfd, int newfd);文件描述符下标内容的拷贝,将oldfd拷贝给newfd。
3.1、> 输出重定向
将新文件描述符下标内容拷贝到显示器上。
代码演示
int main()
{int fd = open("log.txt",O_WRONLY | O_CREAT | O_TRUNC,0666);if(fd < 0){perror("open");return 1;}dup2(fd,1);printf("hello linux\n");return 0;
}运行结果
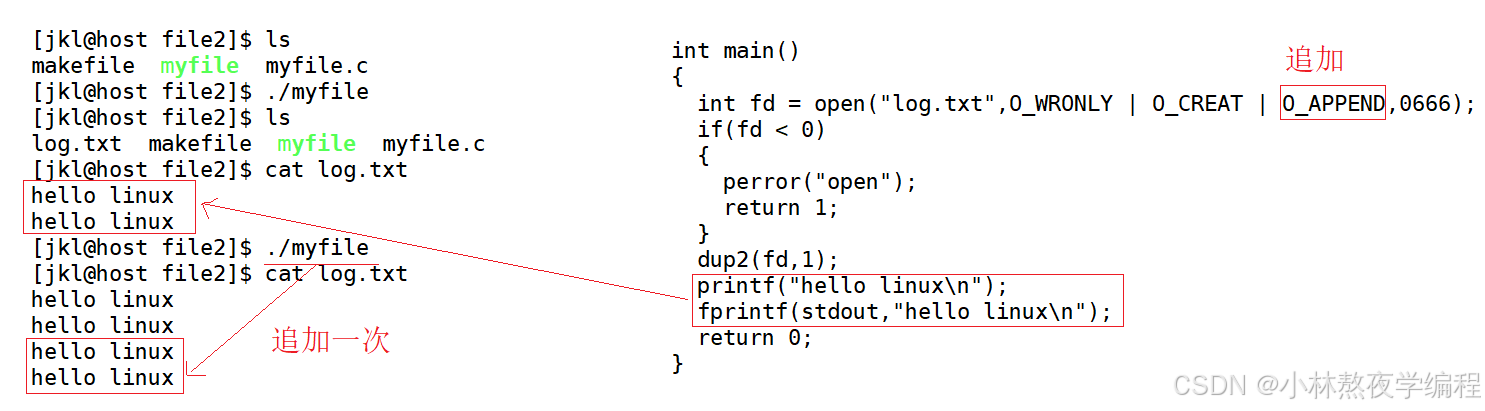
3.2、>> 追加重定向
将新文件描述符下标内容追加拷贝到显示器上。
代码演示
int main()
{int fd = open("log.txt",O_WRONLY | O_CREAT | O_APPEND,0666);if(fd < 0){perror("open");return 1;}dup2(fd,1);printf("hello linux\n");fprintf(stdout,"hello linux\n"); return 0;
}运行结果
3.3、< 输入重定向
将新文件描述符下标内容拷贝到键盘上。
代码演示
int main()
{int fd=open("log.txt",O_RDONLY);if(fd == -1){perror("open");return 1;}//输入重定向dup2(fd,0);char outbuffer[64];while(1){// 获取fd = 0中数据,即文件if(fgets(outbuffer,sizeof(outbuffer),stdin) == NULL) break;printf("<%s",outbuffer);}return 0;
}运行结果

3.4、shell模拟实现> >> <
头文件、宏、全局变量
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<string.h>
#include<ctype.h>
#include<sys/types.h>
#include<sys/wait.h>
#include<errno.h>#define SIZE 512
#define ZERO '\0'
#define SEP " "
#define NUM 32
// 找最后一个/ ,宏是替换可以不用传二级指针,do while 不加分号,为了后面加分号
#define SkipPath(p) do{ p += (strlen(p)-1); while(*p != '/') p--; }while(0)
#define SkipSpace(cmd, pos) do{\while(1){\if(isspace(cmd[pos]))\pos++;\else break;\}\
}while(0)char* gArgv[NUM];
int lastcode = 0;
char cwd[SIZE*2];// "ls -a -l -n > myfile.txt"
#define None_Redir 0
#define In_Redir 1
#define Out_Redir 2
#define App_Redir 3int redir_type = None_Redir;
char *filename = NULL;
1.CheckRedir
在获取字符串之后检查是否有重定向符号,通过全局变量redir_type赋予不同的值,默认没有重定向符号。
代码演示
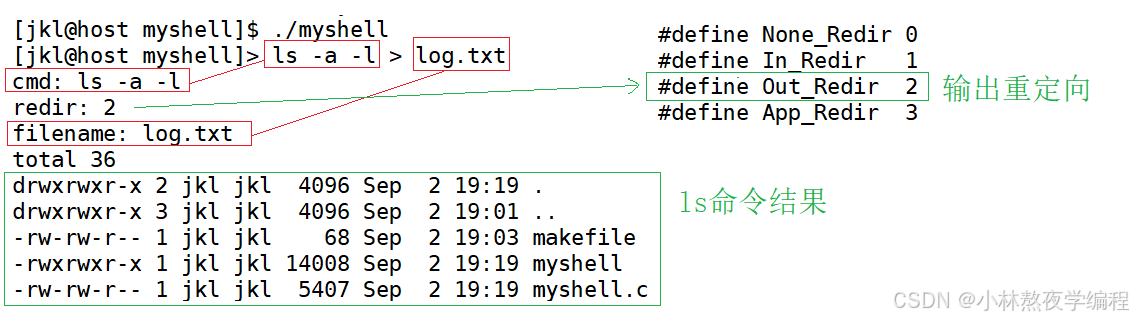
void CheckRedir(char cmd[])
{// > >> <// "ls -a -l > myfile.txt"int pos = 0;int end = strlen(cmd);while(pos < end){if(cmd[pos] == '>'){if(cmd[pos + 1] == '>'){cmd[pos++] = 0;pos++;redir_type = App_Redir;SkipSpace(cmd,pos);filename = cmd + pos;}else {cmd[pos++] = 0;redir_type = Out_Redir;SkipSpace(cmd,pos);filename = cmd + pos;}}else if(cmd[pos] == '<'){cmd[pos++] = 0;redir_type = In_Redir;SkipSpace(cmd,pos);filename = cmd + pos;}else {pos++;}}
}2.测试CheckRedir
打印出对应的变量值即可。
printf("cmd: %s\n",usercommand);printf("redir: %d\n",redir_type);printf("filename: %s\n",filename);
运行结果
4、缓冲区
缓冲区是什么?
缓冲区是一段内存空间。
为什么要有缓冲区?
给上层提供高效的IO体验,间接提高整体的效率。
缓冲区的刷新策略
正常情况
1、立即刷新。fflush(stdout) int fsync(int fd); synchronize a file's in-core state with storage device。
2、行刷新。显示器刷新,为了照顾用户的体验。
3、全缓冲。缓冲区写满才刷新(普通文件)。
特殊情况
1、进程退出,系统自动刷新
2、强制刷新
缓冲器包括?
用户级缓冲区 内核级缓冲区
缓冲区的意义:
1、解耦
2、提高效率,提高用户使用的效率,提高刷新IO的效率
代码演示
int main()
{printf("hello printf\n");fprintf(stdout,"hello fprintf\n");const char* msg = "hello write\n";write(1,msg,strlen(msg));return 0;
}
运行结果

奇怪的代码
int main()
{printf("hello printf\n");fprintf(stdout,"hello fprintf\n");const char* msg = "hello write\n";write(1,msg,strlen(msg));fork();return 0;
}
运行结果
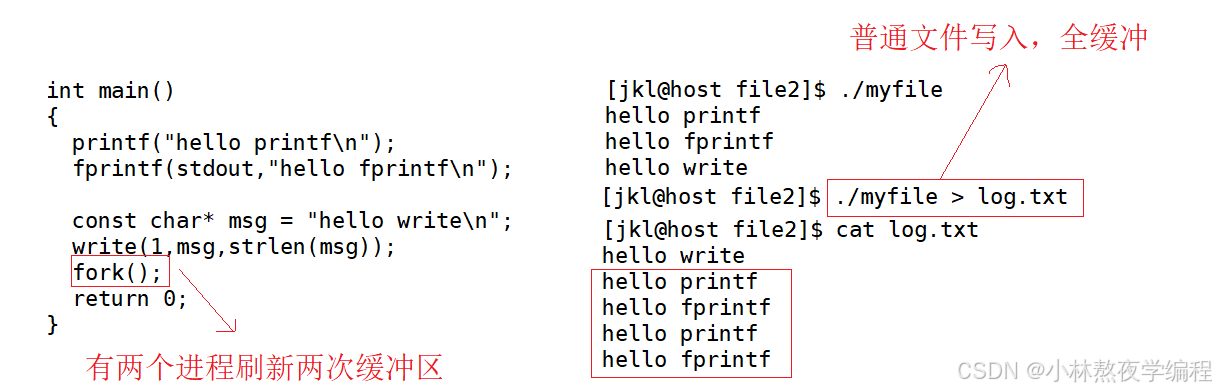
我们发现 printf 和 fprintf (库函数)都输出了2次,而 write 只输出了一次(系统调用)。为什么呢?肯定和fork有关!
- 一般C库函数写入文件时是全缓冲的,而写入显示器是行缓冲。
- printf fwrite 库函数会自带缓冲区(进度条例子就可以说明),当发生重定向到普通文件时,数据的缓冲方式由行缓冲变成了全缓冲。
- 而我们放在缓冲区中的数据,就不会被立即刷新,甚至fork之后
- 但是进程退出之后,会统一刷新,写入文件当中。
- 但是fork的时候,父子数据会发生写时拷贝,所以当你父进程准备刷新的时候,子进程也就有了同样的一份数据,随即产生两份数据。
- write 没有变化,说明没有所谓的缓冲
综上: printf fwrite 库函数会自带缓冲区,而 write 系统调用没有带缓冲区。另外,我们这里所说的缓冲区,都是用户级缓冲区。其实为了提升整机性能,OS也会提供相关内核级缓冲区,不过不再我们讨论范围之内。
那这个缓冲区谁提供呢? printf fwrite 是库函数, write 是系统调用,库函数在系统调用的“上层”, 是对系统调用的“封装”,但是 write 没有缓冲区,而 printf fwrite 有,足以说明,该缓冲区是二次加上的,又因为是C,所以由C标准库提供。
如果有兴趣,可以看看FILE结构体:
typedef struct _IO_FILE FILE; 在/usr/include/stdio.h
在/usr/include/libio.h
struct _IO_FILE {
int _flags; /* High-order word is _IO_MAGIC; rest is flags. */
#define _IO_file_flags _flags
//缓冲区相关
/* The following pointers correspond to the C++ streambuf protocol. */
/* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */
char* _IO_read_ptr; /* Current read pointer */
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
char* _IO_write_base; /* Start of put area. */
char* _IO_write_ptr; /* Current put pointer. */
char* _IO_write_end; /* End of put area. */
char* _IO_buf_base; /* Start of reserve area. */
char* _IO_buf_end; /* End of reserve area. */
/* The following fields are used to support backing up and undo. */
char *_IO_save_base; /* Pointer to start of non-current get area. */
char *_IO_backup_base; /* Pointer to first valid character of backup area */
char *_IO_save_end; /* Pointer to end of non-current get area. */
struct _IO_marker *_markers;
struct _IO_FILE *_chain;
int _fileno; //封装的文件描述符
#if 0
int _blksize;
#else
int _flags2;
#endif
_IO_off_t _old_offset; /* This used to be _offset but it's too small. */
#define __HAVE_COLUMN /* temporary */
/* 1+column number of pbase(); 0 is unknown. */
unsigned short _cur_column;
signed char _vtable_offset;
char _shortbuf[1];
/* char* _save_gptr; char* _save_egptr; */
_IO_lock_t *_lock;
#ifdef _IO_USE_OLD_IO_FILE
};相关文章:
【Linux系统编程】第二十七弹---文件描述符与重定向:fd奥秘、dup2应用与Shell重定向实战
✨个人主页: 熬夜学编程的小林 💗系列专栏: 【C语言详解】 【数据结构详解】【C详解】【Linux系统编程】 目录 1、文件描述符fd 1.1、0 & 1 & 2 1.2、文件描述符的分配规则 2、重定向 3、使用 dup2 系统调用 3.1、> 输出…...

开放式耳机哪个品牌好?好用且高性价比的开放式蓝牙耳机推荐
相信很多经常运动的朋友都不是很喜欢佩戴入耳式耳机,因为入耳式耳机真的有很多缺点。 安全方面:在安全上就很容易存在隐患,戴上后难以听到周围环境声音,像汽车鸣笛、行人呼喊等,容易在运动中发生意外。 健康方面&…...

区间合并——模板题
题目描述 给定 n 个区间 [li, ri],要求合并所有有交集的区间。注意如果在端点处相交,也算有交集。 输出合并完成后的区间个数。 例如:[1, 3] 和 [2, 6] 可以合并为一个区间 [1, 6]。 输入格式 第一行包含整数 n 。 接下来 n 行,…...

Microsoft Edge 五个好用的插件
🐣个人主页 可惜已不在 🐤这篇在这个专栏 插件_可惜已不在的博客-CSDN博客 🐥有用的话就留下一个三连吧😼 目录 Microsoft Edge 一.安装游览器 编辑 二.找到插件商店 1.打开游览器后,点击右上角的设置&#…...

解决 遇到JWT中claims中获取不到数据的问题
1.先介绍一下JWT的常规流程 用户进行登录将token储存到redis,然后进行其他需要验证的操作时进行验证,比如使用拦截器进行验证,那么id存储的到claims,因为可以在拦截器验证时将其存放到ThreadLocal中,这样通过ThreadLo…...
会议平台后端优化方案
会议平台后端优化方案 通过RTC的学习,我了解到了端对端技术,就想着做一个节省服务器资源的会议平台 之前做了这个项目,快手二面被问到卡着不知如何介绍,便有了这篇文章 分析当下机制 相对于传统视频平台(SFUÿ…...
分片插入长数据)
unixODBC编程(十)分片插入长数据
遇到有LONG数据类型的表,要插入一条数据量很大的行,一次插入的缓冲区会不够大,这时需要一部分一部分的插入LONG数据,这就用到了在执行语句时动态提供数据的机制。在ODBC中要动态提供数据需要几个步骤。 1. 在绑定输入参数时&…...

【Java】—— 集合框架:Collection子接口:Set不同实现类的对比及使用(HashSet、LinkedHashSet、TreeSet)
目录 5. Collection子接口2:Set 5.1 Set接口概述 5.2 Set主要实现类:HashSet 5.2.1 HashSet概述 5.2.2 HashSet中添加元素的过程: 5.2.3 重写 hashCode() 方法的基本原则 5.2.4 重写equals()方法的基本原则 5.2.5 练习 5.3 Set实现类…...

android Activity生命周期
android 中一个 activity 在其生命周期中会经历多种状态。 您可以使用一系列回调来处理状态之间的转换。下面我们来介绍这些回调。 onCreate(创建阶段) 初始化组件:在这个阶段,Activity的主要工作是进行初始化操作。这包括为Ac…...

C#的面向对象
1)对象 算法数据结构 2)对象的行为已方法的形式定义的,属性以成员变量的形式定义的 面向对象程序设计的特点 1)封装性 2)继承性 3)多态性 知识点: 封装性面向对象的核心思想,将…...

【区别】三种命令取消已暂存的文件,处理暂存区和文件的跟踪状态
取消已暂存的文件 git restore --staged <文件>、git reset HEAD <文件> 和 git rm --cached <文件> 都可以用于取消已暂存的文件,但它们的作用和使用场景略有不同。下面是它们的区别: 1. git restore --staged <文件> 该命令…...

如何在Spring Boot中有条件地运行CommandLineRunner Bean
PS 使用 Spring Boot 3.1.2 进行测试 1.使用ConditionalOnProperty ConditionalOnProperty仅当特定属性存在或具有特定值时,注释才会创建 Bean 。 在此示例中,仅当或文件中的CommandLineRunner属性db.init.enabled设置为 true时,才会执行。…...
边缘自适应粒子滤波(Edge-Adaptive Particle Filter)的MATLAB函数示例,以及相应的讲解
目录 讲解 初始化 预测步骤 观测模拟 权重更新 重采样 状态估计 总结 下面是一个简单的边缘自适应粒子滤波()的函数示例,以及相应的讲解。 程序源代码: function X_est edgeAdaptiveParticleFilter(numParticles, numS…...

一块1T硬盘怎么有sdb1和sdb2
在一块 1TB 硬盘上看到两个分区 sdb1 和 sdb2 是非常常见的现象。硬盘可以被划分为多个分区,每个分区都可以用作不同的目的,如存储不同类型的数据、安装不同的操作系统或为系统不同的功能提供支持。 1. 分区的概念 硬盘可以被划分为多个分区࿰…...

Python知识点:如何使用Flink与Python进行实时数据处理
开篇,先说一个好消息,截止到2025年1月1日前,翻到文末找到我,赠送定制版的开题报告和任务书,先到先得!过期不候! 如何使用Flink与Python进行实时数据处理 Apache Flink是一个流处理框架…...

Swagger配置且添加小锁(asp.net)(笔记)
此博客是基于 asp.net core web api(.net core3.1)框架进行操作的。 一、安装Swagger包 在 NuGet程序包管理中安装下面的两个包: swagger包:Swashbuckle.AspNetCore swagger包过滤器:Swashbuckle.AspNetCore.Filters 二、swagger注册 在…...

lambda表达式底层实现:反编译LambdaMetafactory + 转储dump + 运行过程 + 反汇编 + 动态指令invokedynamic
一、结论先行 lambda 底层实现机制 1.lambda 表达式的本质:函数式接口的匿名子类的匿名对象 2.lambda表达式是语法糖 语法糖:编码时是lambda简洁的表达式,在字节码期,语法糖会被转换为实际复杂的实现方式,含义不变&am…...

Unity初识+面板介绍
Unity版本使用 小版本号高,出现bug可能性更小;一台电脑可以安装多个版本的Unity,但是需要安装在不同路径;安装Unity时不能有中文路径;Unity项目路径也不要有中文。 Scene面板 相当于拍电影的片场,Unity程…...

【CSS in Depth 2 精译_041】6.4 CSS 中的堆叠上下文与 z-index(上)
当前内容所在位置(可进入专栏查看其他译好的章节内容) 第一章 层叠、优先级与继承(已完结)第二章 相对单位(已完结)第三章 文档流与盒模型(已完结)第四章 Flexbox 布局(已…...

uniapp微信小程序巧用跳转封装鉴权路由
1.这是封装的跳转方法: import store from "../stores/store";function Router(type, url, params) {const NoLoginPage [。。。。。];var queryString Object.keys(params).map((key) > ${key}${params[key]}).join("&");if (!NoLog…...

CANN/pypto isfinite函数文档
pypto.isfinite 【免费下载链接】pypto PyPTO(发音: pai p-t-o):Parallel Tensor/Tile Operation编程范式。 项目地址: https://gitcode.com/cann/pypto 产品支持情况 产品是否支持Ascend 950PR/Ascend 950DT√Atlas A3 训练系列产品…...

如何用智能弹幕助手告别直播中的重复劳动?B站直播效率提升300%的秘密
如何用智能弹幕助手告别直播中的重复劳动?B站直播效率提升300%的秘密 【免费下载链接】MagicalDanmaku 本仓库及所有相关项目已永久停止开发、维护和任何形式的分发。 项目地址: https://gitcode.com/gh_mirrors/bi/MagicalDanmaku 还在为直播时手忙脚乱而烦…...
)
强制启动 Cursor IDE 主程序(不带 Agent 模式)
🔧 终极解决:强制启动 Cursor IDE 主程序(不带 Agent 模式)方法 1:用「命令行」强制启动主程序(最稳)按 WinR 打开运行窗口,输入 cmd 回车,打开命令提示符输入下面这行命…...

SVM实战调参指南:从标准化、核函数到支持向量解读
1. 这不是教科书里的SVM,而是我亲手调过37次参数后才敢写的入门实录Support Vector Machine(SVM)这个词,第一次见是在三年前的某次算法面试里。面试官问:“你说说SVM为什么叫‘支持向量’?”我张了张嘴&…...
)
农业电商服务系统(10078)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

Unity游戏资源提取实战指南:AssetStudio高阶用法与避坑手册
1. 这不是“又一个AssetStudio教程”,而是我拆了27款Unity手游后总结的资源提取生存手册AssetStudio、Unity游戏资源提取、Unity AssetBundle、Unity3D反编译——这几个词,过去三年里我每天至少在技术群、论坛、工单系统里看到50次。但绝大多数人点开Ass…...

通用异步导出服务设计:从业务功能到平台基础能力的抽象
在后台管理系统中,“导出 Excel”几乎是一个绕不开的功能。看似只是点击一个按钮、下载一个文件,背后却经常隐藏着性能、稳定性、安全性和用户体验问题。 当数据量较小时,同步导出通常可以满足需求。但随着业务数据规模增长,导出操…...

【ElevenLabs潮州话语音实战指南】:20年语音AI专家亲授3大落地陷阱与5步合规部署法
更多请点击: https://kaifayun.com 第一章:ElevenLabs潮州话语音技术全景概览 ElevenLabs 作为全球领先的语音合成平台,长期聚焦于高保真、多语言、情感化TTS技术研发。尽管其官方公开支持的语言列表尚未正式纳入潮州话(Teochew&…...

LeetCode 88:合并两个有序数组 | 双指针从后向前求解
LeetCode 88:合并两个有序数组 | 双指针从后向前求解 引言 合并两个有序数组(Merge Sorted Array)是 LeetCode 第 88 题,难度为 Easy,但却是双指针法应用的经典案例。题目要求将两个已排序的数组 nums1 和 nums2 合并…...
)
86、【Agent】【OpenCode】bash 工具提示词(完结)
【声明】本博客所有内容均为个人业余时间创作,所述技术案例均来自公开开源项目(如Github,Apache基金会),不涉及任何企业机密或未公开技术,如有侵权请联系删除 背景 上篇 blog 【Agent】【OpenCode】bash 工…...