Java开发学习(四十六)----MyBatisPlus新增语句之id生成策略控制及其简化配置
在前面有一篇博客:Java开发学习(四十一)----MyBatisPlus标准数据层(增删查改分页)开发,我们在新增的时候留了一个问题,就是新增成功后,主键ID是一个很长串的内容。

我们更想要的是按照数据库表字段进行自增长,在解决这个问题之前,我们先来分析下ID该如何选择:
-
不同的表应用不同的id生成策略
-
日志:自增(1,2,3,4,……)
-
购物订单:特殊规则(FQ23948AK3843)
-
外卖单:关联地区日期等信息(10 04 20200314 34 91)
-
关系表:可省略id
-
……
-
不同的业务采用的ID生成方式应该是不一样的,那么在MyBatisPlus中都提供了哪些主键生成策略,以及我们该如何进行选择?
在这里我们又需要用到MyBatisPlus的一个注解叫@TableId
知识点1:@TableId
| 名称 | @TableId |
|---|---|
| 类型 | 属性注解 |
| 位置 | 模型类中用于表示主键的属性定义上方 |
| 作用 | 设置当前类中主键属性的生成策略 |
| 相关属性 | value(默认):设置数据库表主键名称 type:设置主键属性的生成策略,值查照IdType的枚举值 |
1、环境构建
在构建条件查询之前,我们先来准备下环境
-
创建一个SpringBoot项目
参考Java开发学习(三十五)----SpringBoot快速入门及起步依赖解析
-
pom.xml中添加对应的依赖
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.5.0</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.itheima</groupId><artifactId>mybatisplus_03_dml</artifactId><version>0.0.1-SNAPSHOT</version><properties><java.version>1.8</java.version></properties><dependencies> <dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.4.1</version></dependency> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency> <dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.1.16</version></dependency> <dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><scope>runtime</scope></dependency> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency> <dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.12</version></dependency> </dependencies> <build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build> </project> -
编写UserDao接口
@Mapper public interface UserDao extends BaseMapper<User> { } -
编写模型类
@Data @TableName("tbl_user") public class User {private Long id;private String name;@TableField(value="pwd",select=false)private String password;private Integer age;private String tel;@TableField(exist=false)private Integer online; } -
编写引导类
@SpringBootApplication public class Mybatisplus03DqlApplication { public static void main(String[] args) {SpringApplication.run(Mybatisplus03DqlApplication.class, args);} } -
编写配置文件
# dataSource spring:datasource:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/mybatisplus_db?serverTimezone=UTCusername: rootpassword: root # mp日志 mybatis-plus:configuration:log-impl: org.apache.ibatis.logging.stdout.StdOutImpl -
编写测试类
@SpringBootTest class Mybatisplus02DqlApplicationTests { @Autowiredprivate UserDao userDao;@Testvoid testGetAll(){List<User> userList = userDao.selectList(null);System.out.println(userList);} } -
测试
@SpringBootTest class Mybatisplus03DqlApplicationTests { @Autowiredprivate UserDao userDao;} -
最终创建的项目结构为:
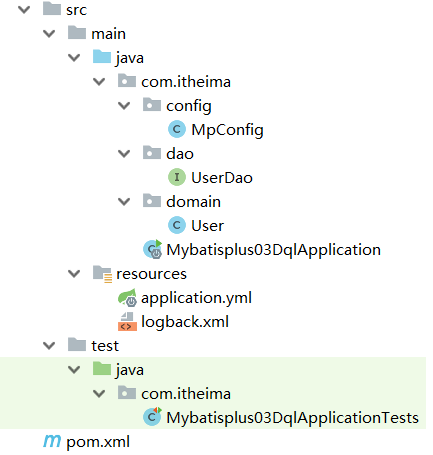
2、代码演示
AUTO策略
@Data
@TableName("tbl_user")
public class User {@TableId(type = IdType.AUTO)private Long id;private String name;@TableField(value="pwd",select=false)private String password;private Integer age;private String tel;@TableField(exist=false)private Integer online;
}会发现,新增成功,并且主键id自动增长
我们会发现AUTO的作用是使用数据库ID自增,在使用该策略的时候一定要确保对应的数据库表设置了ID主键自增,否则无效。
接下来,我们可以进入源码查看下ID的生成策略有哪些?打开源码后,你会发现并没有看到中文注释,这就需要我们点击右上角的Download Sources,会自动帮你把这个类的java文件下载下来,我们就能看到具体的注释内容。因为这个技术是国人制作的,所以他代码中的注释还是比较容易看懂的。
当把源码下载完后,就可以看到如下内容:

从源码中可以看到,除了AUTO这个策略以外,还有如下几种生成策略:
-
NONE: 不设置id生成策略
-
INPUT:用户手工输入id
-
ASSIGN_ID:雪花算法生成id(可兼容数值型与字符串型)
-
ASSIGN_UUID:以UUID生成算法作为id生成策略
-
其他的几个策略均已过时,都将被ASSIGN_ID和ASSIGN_UUID代替掉。
拓展:
分布式ID是什么?
-
当数据量足够大的时候,一台数据库服务器存储不下,这个时候就需要多台数据库服务器进行存储
-
比如订单表就有可能被存储在不同的服务器上
-
如果用数据库表的自增主键,因为在两台服务器上所以会出现冲突
-
这个时候就需要一个全局唯一ID,这个ID就是分布式ID。
INPUT策略
步骤1:设置生成策略为INPUT
@Data
@TableName("tbl_user")
public class User {@TableId(type = IdType.INPUT)private Long id;private String name;@TableField(value="pwd",select=false)private String password;private Integer age;private String tel;@TableField(exist=false)private Integer online;
}注意:这种ID生成策略,需要将表的自增策略删除掉
步骤2:添加数据手动设置ID
@SpringBootTest
class Mybatisplus03DqlApplicationTests {
@Autowiredprivate UserDao userDao;@Testvoid testSave(){User user = new User();//设置主键ID的值user.setId(666L);user.setName("黑马程序员");user.setPassword("itheima");user.setAge(12);user.setTel("4006184000");userDao.insert(user);}
}ASSIGN_ID策略
步骤1:设置生成策略为ASSIGN_ID
@Data
@TableName("tbl_user")
public class User {@TableId(type = IdType.ASSIGN_ID)private Long id;private String name;@TableField(value="pwd",select=false)private String password;private Integer age;private String tel;@TableField(exist=false)private Integer online;
}步骤2:添加数据不设置ID
@SpringBootTest
class Mybatisplus03DqlApplicationTests {
@Autowiredprivate UserDao userDao;@Testvoid testSave(){User user = new User();user.setName("黑马程序员");user.setPassword("itheima");user.setAge(12);user.setTel("4006184000");userDao.insert(user);}
}注意:这种生成策略,不需要手动设置ID,如果手动设置ID,则会使用自己设置的值。
生成的ID就是一个Long类型的数据。
ASSIGN_UUID策略
步骤1:设置生成策略为ASSIGN_UUID
使用uuid需要注意的是,主键的类型不能是Long,而应该改成String类型
@Data
@TableName("tbl_user")
public class User {@TableId(type = IdType.ASSIGN_UUID)private String id;private String name;@TableField(value="pwd",select=false)private String password;private Integer age;private String tel;@TableField(exist=false)private Integer online;
}步骤2:修改表的主键类型
主键类型设置为varchar,长度要大于32,因为UUID生成的主键为32位,如果长度小的话就会导致插入失败。
步骤3:添加数据不设置ID
@SpringBootTest
class Mybatisplus03DqlApplicationTests {
@Autowiredprivate UserDao userDao;@Testvoid testSave(){User user = new User();user.setName("黑马程序员");user.setPassword("itheima");user.setAge(12);user.setTel("4006184000");userDao.insert(user);}
}接下来我们来聊一聊雪花算法:
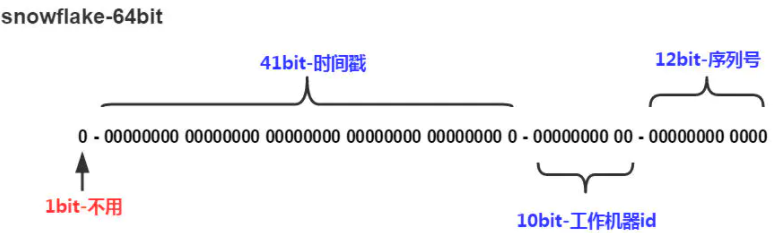
雪花算法(SnowFlake),是Twitter官方给出的算法实现 是用Scala写的。其生成的结果是一个64bit大小整数,它的结构如下图:
-
1bit,不用,因为二进制中最高位是符号位,1表示负数,0表示正数。生成的id一般都是用整数,所以最高位固定为0。
-
41bit-时间戳,用来记录时间戳,毫秒级
-
10bit-工作机器id,用来记录工作机器id,其中高位5bit是数据中心ID其取值范围0-31,低位5bit是工作节点ID其取值范围0-31,两个组合起来最多可以容纳1024个节点
-
序列号占用12bit,每个节点每毫秒0开始不断累加,最多可以累加到4095,一共可以产生4096个ID
3、ID生成策略对比
介绍了这些主键ID的生成策略,我们以后该用哪个呢?
-
NONE: 不设置id生成策略,MyBatisPlus不自动生成,约等于INPUT,所以这两种方式都需要用户手动设置,但是手动设置第一个问题是容易出现相同的ID造成主键冲突,为了保证主键不冲突就需要做很多判定,实现起来比较复杂
-
AUTO:数据库ID自增,这种策略适合在数据库服务器只有1台的情况下使用,不可作为分布式ID使用
-
ASSIGN_UUID:可以在分布式的情况下使用,而且能够保证唯一,但是生成的主键是32位的字符串,长度过长占用空间而且还不能排序,查询性能也慢
-
ASSIGN_ID:可以在分布式的情况下使用,生成的是Long类型的数字,可以排序性能也高,但是生成的策略和服务器时间有关,如果修改了系统时间就有可能导致出现重复主键
-
综上所述,每一种主键策略都有自己的优缺点,根据自己项目业务的实际情况来选择使用才是最明智的选择。
4、简化配置
模型类主键策略设置
对于主键ID的策略已经介绍完,但是如果要在项目中的每一个模型类上都需要使用相同的生成策略,如:

确实是稍微有点繁琐,我们能不能在某一处进行配置,就能让所有的模型类都可以使用该主键ID策略呢?
答案是肯定有,我们只需要在配置文件中添加如下内容:
mybatis-plus:global-config:db-config:id-type: assign_id配置完成后,每个模型类的主键ID策略都将成为assign_id.
数据库表与模型类的映射关系
MyBatisPlus会默认将模型类的类名名首字母小写作为表名使用,假如数据库表的名称都以tbl_开头,那么我们就需要将所有的模型类上添加@TableName,如:

配置起来还是比较繁琐,简化方式为在配置文件中配置如下内容:
mybatis-plus:global-config:db-config:table-prefix: tbl_设置表的前缀内容,这样MyBatisPlus就会拿 tbl_加上模型类的首字母小写,就刚好组装成数据库的表名。
相关文章:
Java开发学习(四十六)----MyBatisPlus新增语句之id生成策略控制及其简化配置
在前面有一篇博客:Java开发学习(四十一)----MyBatisPlus标准数据层(增删查改分页)开发,我们在新增的时候留了一个问题,就是新增成功后,主键ID是一个很长串的内容。 我们更想要的是按照数据库表字段进行自增…...
章鱼哥听歌
uboot环境变量 以下所有的命令,都在串口工具进行执行 ubifsmount- mount UBIFS volume ubifsumount- unmount UBIFS volume ums - Use the UMS [USB Mass Storage] usb - USB sub-system usbboot - boot from USB device version - print monit…...
软件测试电商项目实战(写进简历没问题)
前言 说实话,在找项目的过程中,我下载过(甚至付费下载过)N多个项目、联系过很多项目的作者,但是绝大部分项目,在我看来,并不适合你拿来练习,它们或多或少都存在着“问题”ÿ…...

算法导论—分治法思想、动态规划思想、贪心思想
算法导论—分治法思想、动态规划思想、贪心思想分治法的思想:动态规划:贪心算法:贪心算法求解问题的条件:设计贪心算法的步骤:分治法的思想: 将原问题分解为几个规模较小但类似于原问题的子问题࿰…...

Spring-Data-Jpa实现继承实体类
写在前面:从2018年底开始学习SpringBoot,也用SpringBoot写过一些项目。现在对学习Springboot的一些知识总结记录一下。如果你也在学习SpringBoot,可以关注我,一起学习,一起进步。 相关文章: 【Springboot系…...

多线程环境下的伪共享
今天和大家聊一聊伪共享 1.什么是伪共享? 缓存一致性协议在计算机中针对的最小单元:缓存行,每个缓存行的大小是64字节,一串连续的64字节数据都会存储到缓存行中。 假设数据A和数据B在同一缓存行中,CPU1修改了数据A&am…...

【Taylor and Francis】1/2区云计算、物联网、机器学习类,SCIEEI双检,审稿友好
机器学习类 【期刊简介】IF:6.5-7.0,JCR1/2区,中科院3区 【检索情况】SCIE&EI双检 【参考周期】2-3个月左右录用 【征稿领域】面向制造业云计算物联网应用的机器学习方法 【截稿日期】10篇版面 毕业必看-快刊 计算机科学类…...

CleanMyMac X4.12新版本下载及功能介绍
CleanMyMac X2023最新版终于迎来了又4.12,重新设计了 UI 元素,华丽的现代化风格显露无余。如今的CleanMyMac,早已不是单纯的系统清理工具。在逐渐融入系统优化、软件管理、文件管理等功能后,逐渐趋近于macOS的系统管家,…...
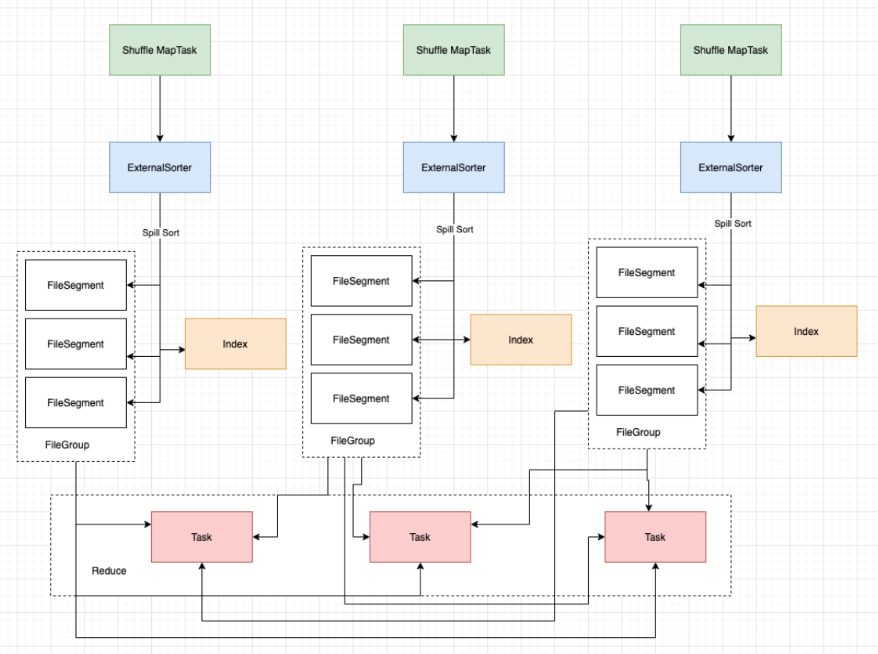
大数据技术架构(组件)26——Spark:Shuffle
2.1.6、Shuffle2.1.6.0 Shuffle Read And WriteMR框架中涉及到一个重要的流程就是shuffle,由于shuffle涉及到磁盘IO和网络IO,所以shuffle的性能直接影响着整个作业的性能。Spark其本质也是一种MR框架,所以也有自己的shuffle实现。但是和MR中的shuffle流程…...

关于Zebec生态的改进提案,即将上线的 Nautilus 链
概括 在最初作为 Solana 原生应用程序推出一年后,Zebec 团队已经能够通过在 BNB和NEAR区块链上成功部署来扩大其产品的范围。 凭借继续向尽可能多的公司/协议/基金提供薪资工具和基础设施的雄心勃勃的计划,我们决定采用最终将使 Zebec生态系统及其核心…...

Python数据可视化(三)(pyecharts)
分享一些python-pyecharts作图小技巧,用于展示汇报。 一、特点 任何元素皆可配置pyecharts只支持python原生的数据类型,包括int,float,str,bool,dict,list动态展示,炫酷的效果,给人视觉冲击力 # 安装 pip install pyecharts fr…...

【Redis面试指南】
Redis面试指南 Redis是一个开源的、基于内存的、高性能的键值对存储系统,它可以用于存储非常大量的数据,并且可以在短时间内获取数据。Redis的性能被广泛用于Web应用程序的缓存层,以提高应用程序的性能和可用性。Redis的面试是一个比较复杂的…...

大数据技术之Hadoop(生产调优手册)
第1章 HDFS—核心参数 1.1 NameNode内存生产配置 1)NameNode内存计算 每个文件块大概占用150byte,一台服务器128G内存为例,能存储多少文件块呢? 128 * 1024 * 1024 * 1024 / 150Byte ≈ 9.1亿 G MB KB Byte 2)Hadoop…...

「Vue源码学习」常见的 Vue 源码面试题,看完可以说 “精通Vue” 了吗?
Vue源码面试题一、行时(Runtime) 编译器(Compiler) vs. 只包含运行时(Runtime-only)webpackRollupBrowserify二、Vue 的初始化过程(面试关问:new Vue(options) 发生了什么࿱…...

FreeModbus RTU 移植指南
FreeModbus 简介 FreeModbus 是一个免费的软件协议栈,实现了 Modbus 从机功能: 纯 C 语言支持 Modbus RTU/ASCII支持 Modbus TCP 本文介绍 Modbus RTU 移植。 移植环境: 裸机Keil MDK 编译器Cortex-M3 内核芯片(LPC1778/88&…...
《唐诗三百首》数据源网络下载
2023年的 元宵之夜,这场以“长安”为主题的音乐会火了!在抖音,超过2300万人次观看了直播,在线同赏唐诗与交响乐的融合。许多网友惊呼,上学时那些害怕背诵的诗句,原来还可以有这么美的表达这场近80分钟的音乐…...

(深度学习快速入门)第五章第一节2:GAN经典案例之MNIST手写数字生成
获取pdf:密码7281 文章目录一:数据集介绍二:GAN简介(1)简介(2)损失函数三:代码编写(1)参数及数据预处理(2)生成器与判别器模型&#x…...
雁过留痕,竟是病毒的痕迹?
凌恩生物全新升级宏病毒组分析流程;聚焦DNA,RNA病毒组研究热点;高灵敏度检测vOTUs;多软件整合,精准鉴定病毒序列;直击地化循环关键环节,助力宏病毒组科研成功!期刊:Micro…...

Linux基本功系列之sort命令实战
文章目录前言一. sort命令介绍二. 语法格式及常用选项三. 参考案例3.1 按照文本默认排序3.2 忽略相同的行3.3 按数字大小进行排序3.4 检查文件是否已经按照顺序排序3.5 将第3列按照数字大小进行排序3.6 将排序结果输出到文件四. 探讨 -k的高级用法总结前言 大家好,…...
【笔记】移动端自动化:adb调试工具+appium+UIAutomatorViewer
学习源: https://www.bilibili.com/video/BV11p4y197HQ https://blog.csdn.net/weixin_47498728/category_11818905.html 一、移动端测试环境搭建 学习目标 1.能够搭建java 环境 2.能够搭建android 环境 (一)整体思路 我们的目标是Andr…...

java+uniapp集成unipush2实现消息推送
一、开通uniPush2.0 1.实名认证 登录DCloud开发者中心,通过实名认证 2.进入UniPush控制台 HBuilderX中打开项目的manifest.json文件 导航在“App模块配置” → 项的“Push(消息推送)” → “UniPush”下点击配置 或者申请开通。 3.配置应用信息 在UniPush开通界面…...

别再乱接电源了!STM32的VDDA、VSSA、VBAT引脚,一个没接对,ADC采样全是噪声
STM32电源设计实战:VDDA、VSSA与VBAT的噪声抑制艺术 当你的STM32项目遇到ADC采样值跳变、RTC计时不准或程序下载失败时,电源引脚的设计往往是罪魁祸首。许多工程师在PCB布局时,对这些看似简单的电源引脚处理过于随意,结果在调试阶…...

云原生 Kubernetes 核心概念与组件详解
目录 一、Kubernetes 是什么? 核心功能概览 二、部署演进:从物理机到容器 1. 传统部署时代 2. 虚拟化部署时代 3. 容器部署时代 三、Kubernetes 集群架构 1. 控制平面组件(集群大脑) (1)kube-apise…...

Go语言匿名函数如何写_Go语言匿名函数和闭包教程【对比】
Go匿名函数写作func(参数)返回类型{函数体},需完整声明;闭包是匿名函数引用外层局部变量并逃逸出作用域时形成的行为结果,捕获变量引用而非值。Go 里匿名函数怎么写,直接上手就用Go 的匿名函数就是没名字的函数字面量,…...

Flutter 自定义动画完全指南
Flutter 自定义动画完全指南 引言 动画是现代移动应用的重要组成部分,它能够提升用户体验,使界面更加生动。Flutter 提供了强大的动画系统,本文将深入探讨如何创建自定义动画效果。 动画基础回顾 动画类型 补间动画 (Tween Animation) - 最常…...

Linux桌面便签终极方案:Sticky让你的灵感永不丢失
Linux桌面便签终极方案:Sticky让你的灵感永不丢失 【免费下载链接】sticky A sticky notes app for the linux desktop 项目地址: https://gitcode.com/gh_mirrors/stic/sticky 在Linux桌面上高效管理零散信息一直是许多用户的痛点。Sticky作为一款专为Linux…...

Honey Select 2终极优化补丁:200+插件一键安装,打造完美游戏体验
Honey Select 2终极优化补丁:200插件一键安装,打造完美游戏体验 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 还在为《Honey Select 2…...

告别手动拼报文!用MQTT.fx和OneNet平台快速调试你的ESP8266物联网设备
用MQTT.fx与OneNet构建高效物联网调试工作流 调试物联网设备时,你是否厌倦了反复修改代码、烧录固件、查看串口日志的循环?当ESP8266与OneNet平台通信异常时,传统调试方式往往让我们陷入二进制报文的泥潭。本文将介绍如何通过MQTT.fx这款图形…...

【技术解析】方差分析:从统计表解读到业务决策的实战指南
1. 方差分析:从统计表到业务决策的实战指南 第一次接触方差分析时,我也被那些统计术语和公式搞得晕头转向。直到有一次,产品经理拿着A/B测试数据问我:"新版页面真的比旧版好吗?好多少?"我才意识到…...
)
可口可乐AI印相私密工作流首次公开(含内部CMYK预置包、罐体反光建模提示词库与印刷出血校准表)
更多请点击: https://intelliparadigm.com 第一章:可口可乐AI印相私密工作流的起源与战略价值 可口可乐AI印相私密工作流并非源于通用大模型的简单套用,而是其全球数字创新实验室在2022年启动的“Project Chroma”中孵化出的端到端隐私增强…...