Kafka学习笔记(三)Kafka分区和副本机制、自定义分区、消费者指定分区
文章目录
- 前言
- 7 分区和副本机制
- 7.1 生产者分区写入策略
- 7.1.1 轮询分区策略
- 7.1.2 随机分区策略
- 7.1.3 按key分区分配策略
- 7.1.4 自定义分区策略
- 7.1.4.1 实现`Partitioner`接口
- 7.1.4.2 实现分区逻辑
- 7.1.4.3 配置使用自定义分区器
- 7.1.4.4 分区测试
- 7.2 消费者分区分配策略
- 7.2.1 RangeAssignor(范围分配策略)
- 7.2.2 RoundRobinAssignor(轮询分配策略)
- 7.2.3 StickyAssignor(粘性分配策略)
- 7.2.4 消费者组的Reblance机制
- 7.3 副本机制
- 7.3.1 生产者的`acks`参数
- 7.3.2 `acks`参数配置为0
- 7.3.2 `acks`参数配置为1
- 7.3.3 `acks`参数配置为-1或all
- 7.3.4 基准测试
- 7.4 消费指定分区数据
前言
Kafka学习笔记(一)Linux环境基于Zookeeper搭建Kafka集群、Kafka的架构
Kafka学习笔记(二)Kafka基准测试、幂等性和事务、Java编程操作Kafka
7 分区和副本机制
7.1 生产者分区写入策略
生产者写入消息到Topic,Kafka将依据不同的策略将数据分配到不同的分区中,主要有以下策略:
7.1.1 轮询分区策略
默认的策略,也是使用最多的策略,可以最大限度保证所有消息平均分配到一个分区。
7.1.2 随机分区策略
每次都随机地将消息分配到每个分区。在较早的版本,默认的分区策略就是随机策略,也是为了将消息均衡地写入到每个分区,但后续轮询策略表现更佳,所以基本上很少会使用随机策略。
7.1.3 按key分区分配策略
根据key值,通过一定的算法将消费分配到不同分区。按key分配策略,有可能会出现「数据倾斜」,例如某个key包含了大量的数据,因为key值一样,所有所有的数据将都分配到这个分区中,造成该分区的消息数量远大于其他的分区。
7.1.4 自定义分区策略
轮询策略、随机策略都会导致一个问题,生产到Kafka中的数据是乱序存储的。而按key分区可以一定程度上实现数据有序存储(分区内局部有序),但这又可能会导致数据倾斜,所以在实际生产环境中要结合实际情况来做取舍。
7.1.4.1 实现Partitioner接口
在Java中,自定义分区需要实现org.apache.kafka.clients.producer.Partitioner接口,该接口定义了如下方法:

topic:针对特定Topic使用不同的分区规则。key、keyBytes:针对特定key值使用不同的分区规则。value、valueBytes:针对特定的消息内容使用不同的分区规则。cluster:Cluster对象提供了Topic的分区信息,可以据此动态调整分区策略。
7.1.4.2 实现分区逻辑
重写partition()方法,实现分区逻辑。例如:
/*** 自定义分区器*/
public class MyKafkaPartitioner implements Partitioner {@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {if(key != null) {String keyString = (String) key;// key 以 animal 开头时分配到分区 0if(keyString.startsWith("animal")) {return 0;}// key 以 food 开头时分配到分区 1if(keyString.startsWith("food")) {return 1;}}// 默认分配到分区 0return 0;}@Overridepublic void configure(Map<String, ?> configs) {}@Overridepublic void close() {}
}
7.1.4.3 配置使用自定义分区器
在Kafka生产者配置中,使用自定义分区器的类名:
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, MyKafkaPartitioner.class.getName());
7.1.4.4 分区测试
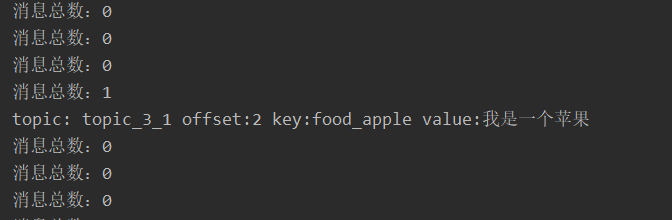
向3分区1副本的Topic[topic_3_1]发送key值为animal_rabbit的消息:

执行结果如下:

将key值修改为food_apple,则分配的分区是1:

7.2 消费者分区分配策略
通过消费者组(Consumer Group),Kafka允许多个消费者共同处理某个Topic的消息,但生产者已经将消息写入了Topic的不同分区,因此首先要解决哪个消费者消费哪个分区的数据的问题,即消费者分区分配策略问题。
在Java中,ConsumerPartitionAssignor接口用来定制消费者的分区分配策略,该接口的3个子类实现分别对应3种消费者分区分配策略。

7.2.1 RangeAssignor(范围分配策略)
范围分配策略是Kafka默认的分配策略,它可以确保每个消费者消费的分区数量是均衡的。
注意:范围分配策略是针对每个Topic的。
范围分配策略有两个算法公式:
- n = 分区数量 / 消费者数量
- m = 分区数量 % 消费者数量
策略结果是:前m个消费者消费n+1个分区,剩余消费者消费n个分区。如图:


7.2.2 RoundRobinAssignor(轮询分配策略)
轮询分配策略是将消费者组内所有消费者以及消费者所订阅的所有Topic的分区按照字典序排序(Topic和分区的hashcode进行排序),然后通过轮询方式逐个将分区分配给每个消费者。
注意:轮询分配策略不局限于单个Topic。

如上图所示,3个消费者共订阅了2个Topic,共8个分区,将8个分区按照字典序排序后,开始轮询:
- TopicA p0 → consumer0
- TopicA p1 → consumer1
- TopicA p2 → consumer2
- TopicA p3 → consumer0
- TopicB p0 → consumer1
- TopicB p1 → consumer2
- TopicB p2 → consumer0
- TopicB p3 → consumer1
- Topica p0 → consumer2
- …
7.2.3 StickyAssignor(粘性分配策略)
从Kafka 0.11.x版本开始,引入此类分配策略。其主要目的在于使分区分配尽可能均匀,同时在Topic或消费者发送变动需要重新分配时,分区的分配尽可能与上一次分配保持相同。
粘性分配策略主要作用在需要重新分配的情况,而不需要重新分配时和轮询分配策略类似。如图:

如果consumer2崩溃了,此时需要进行重新分配。而粘性分配策略会保留重新分配之前的分配结果,只是将原先consumer2负责的两个分区再均匀分配给consumer0、consumer1。

例如:之前consumer0、consumer1正在消费某几个分区,但由于需要重新分配,导致consumer0、consumer1需要取消处理,之后重新消费之前正在处理的分区,导致不必要的系统开销。而粘性分配策略可以明显减少这样的系统资源浪费。
7.2.4 消费者组的Reblance机制
上面提到了消费者的分区重新分配,其实就是Kafka中的Rebalance机制,称之为再均衡。
Reblance机制是Kafka中确保消费者组下所有的consumer如何达成一致,分配订阅的Topic的每个分区的机制。
Rebalance触发的时机有:
-
1)消费者组中consumer的个数发生变化。例如:有新的consumer加入到消费者组,或者是某个consumer停止了。
-
2)订阅的Topic个数发生变化。消费者可以订阅多个主题,假设当前消费者组订阅了三个主题,但有一个主题突然被删除了,此时也需要发生再均衡。
-
3)订阅的Topic分区数发生变化。
当然,Reblance机制的不良影响也挺大的。发生Rebalance时,消费者组下的所有consumer都将停止工作,直到Rebalance完成。
7.3 副本机制
副本的目的就是冗余备份,当某个Broker上的分区数据丢失时,依然可以从其他备份上读取,保障数据可用。
7.3.1 生产者的acks参数
生产者配置的acks参数,表示当生产者生产消息时,写入到副本的要求严格程度。它决定了生产者如何在性能和可靠性之间做取舍。
例如,在之前的测试代码中有如下配置:
props.put("acks", "all");
7.3.2 acks参数配置为0

acks参数配置为0,生产者不会等到Broker确认,而直接发送下一条数据。因此它的性能最高,但有可能会丢失数据。
7.3.2 acks参数配置为1

acks参数配置为1,生产者会等待leader副本确认接收后,才会发送下一条数据,性能中等。
7.3.3 acks参数配置为-1或all

acks参数配置为1,生产者会等待所有副本同步完成并确认接收后,才会发送下一条数据,性能最低。
7.3.4 基准测试
分别对不同的acks参数进行基准测试,acks参数为0时的命令如下,其余类推:
bin/kafka-producer-perf-test.sh --topic topic_1_1 --num-records 5000000 --throughput -1 --record-size 1000 --producer-props bootstrap.servers=192.168.245.130:9092,192.168.245.131:9092,192.168.245.132:9092 acks=0
基准测试结果如下:
| 指标(1分区1副本) | ack=0 | ack=1 | ack=-1/all |
|---|---|---|---|
| 吞吐量 | 18299.132255 records/sec | 19160.979049 records/sec | 13137.876761 records/sec |
| 吞吐速率 | 17.45 MB/sec | 18.27 MB/sec | 12.53 MB/sec |
| 平均延迟时间 | 1769.71 ms | 1692.25 ms | 2473.96 ms |
| 最大延迟时间 | 5490.00 ms | 4455.00 ms | 10434.00 ms |
由此可见,acks参数为0和1时性能相当,为-1/all时性能大幅下降。
7.4 消费指定分区数据

如上图所示的Kafka消费者代码,只需要指定Topic,就可以直接读取消息,而不需要管理分区、副本、offset等元数据,实现方便。
这是因为,Kafka的偏移量offset是由Zookeeper管理的,消费者会自动根据上一次在Zookeeper中保存的offset去接着获取数据。不同的消费者组,在Zookeeper中保存了不同的offset,这样不同消费者组读取同一个Topic就不会有任何影响。
但以上代码也有缺点,就是不能细化控制分区、副本、offset等,从而无法从指定位置读取数据。
如果想要手动指定消费分区,则不能再使用之前的subscribe()方法订阅主题,而是要用assign()方法:
// 3. 订阅要消费的主题
// 指定消费者从哪个topic中拉取数据
// kafkaConsumer.subscribe(Arrays.asList("my_topic"));String topic = "topic_3_1";
TopicPartition partition0 = new TopicPartition(topic, 0);
TopicPartition partition1 = new TopicPartition(topic, 1);
TopicPartition partition2 = new TopicPartition(topic, 2);
// 手动指定只消费分区1的数据
kafkaConsumer.assign(Arrays.asList(partition1));
利用自定义分区策略(详见7.1.4节),向Topic[topic_3_1]的分区0、分区1分别写入数据:

但消费者只消费了分区1的数据:
…
本节完,更多内容请查阅分类专栏:微服务学习笔记
感兴趣的读者还可以查阅我的另外几个专栏:
- SpringBoot源码解读与原理分析
- MyBatis3源码深度解析
- Redis从入门到精通
- MyBatisPlus详解
- SpringCloud学习笔记
相关文章:
Kafka学习笔记(三)Kafka分区和副本机制、自定义分区、消费者指定分区
文章目录 前言7 分区和副本机制7.1 生产者分区写入策略7.1.1 轮询分区策略7.1.2 随机分区策略7.1.3 按key分区分配策略7.1.4 自定义分区策略7.1.4.1 实现Partitioner接口7.1.4.2 实现分区逻辑7.1.4.3 配置使用自定义分区器7.1.4.4 分区测试 7.2 消费者分区分配策略7.2.1 RangeA…...

华为 HCIP-Datacom H12-821 题库 (31)
🐣博客最下方微信公众号回复题库,领取题库和教学资源 🐤诚挚欢迎IT交流有兴趣的公众号回复交流群 🦘公众号会持续更新网络小知识😼 1. 默认情况下,IS-IS Level-1-2 路由器会将 Level-2 区域的明细路由信息发布到Lev…...

占位,凑满减
占位,凑满减...

SpringBoot校园资料平台:从零到一的构建过程
1系统概述 1.1 研究背景 如今互联网高速发展,网络遍布全球,通过互联网发布的消息能快而方便的传播到世界每个角落,并且互联网上能传播的信息也很广,比如文字、图片、声音、视频等。从而,这种种好处使得互联网成了信息传…...

czx前端
一、盒模型 标准盒模型:box-sizing: content-box。 外边距边框内边距内容区。 IE盒模型,怪异盒模型:box-sizing: border-box。 外边距内容区(边框内边距内容区)。 二、CSS特性 继承性: 父元素的字体大小…...

Perforce演讲回顾(上):从UE项目Project Titan,看Helix Core在大型游戏开发中的版本控制与集成使用策略
日前,Perforce携手合作伙伴龙智一同亮相Unreal Fest 2024上海站,分享Helix Core版本控制系统及其协作套件的强大功能与最新动态,助力游戏创意产业加速前行。 Perforce解决方案工程师Kory Luo在活动主会场,带来《Perforce Helix C…...

【含文档】基于Springboot+Andriod的成人教育APP(含源码+数据库+lw)
1.开发环境 开发系统:Windows10/11 架构模式:MVC/前后端分离 JDK版本: Java JDK1.8 开发工具:IDEA 数据库版本: mysql5.7或8.0 数据库可视化工具: navicat 服务器: SpringBoot自带 apache tomcat 主要技术: Java,Springboot,mybatis,mysql,vue 2.视频演示地址 3.功能 系统定…...

CentOS7系统配置Yum环境
新安装完系统的服务器往往缺少我们常用的依赖包,故需要设置好yum源,方便软件安装,以下是CentOS7为例,系统安装后yum默认安装。 //备份之前的配置文件 mv /etc/yum.repos.d /etc/yum.repos.d.bak mkdir -p /etc/yum.repos.d 1…...

pyqt打包成exe相关流程
1、首先是安装pyinstaller, 在cmd中输入以下安装命令: pip3 install pyinstaller -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple/ 2、安装完毕之后,下一步就是找到你要打包的工程,打包的logo放置如下位置: 3、将log…...

设计模式、系统设计 record part02
软件设计模式: 1.应对重复发生的问题 2.解决方案 3.可以反复使用 1.本质是面向对象 2.优点很多 1.创建型-创建和使用分离 2.结构型-组合 3.行为型-协作 571123种模式 UML-统一建模语言-Unified Modeling Language 1.可视化,图形化 2.各种图(9…...

github双重验证(2FA)启用方法
一、双重验证-2FA 在去年看到过说github启用双重验证的通知,觉得做为一个普通开发者,可能没有这么快会要求启用。结果,今天早晨一来就收到了邮件,要求说在11月底完成2FA的认证,否则权限受限。真是无了语。所谓2FA好理…...

《Linux从小白到高手》理论篇:Linux的系统服务管理
值此国庆佳节,深宅家中,闲来无事,就多写几篇博文。本篇详细深入介绍Linux的系统服务管理。 系统服务通常在系统启动时自动启动,并在后台持续运行,为系统和用户提供特定的功能。例如,网络服务、打印服务、数…...

SQL中如何进行 ‘’撤销‘’ 操作-详解
在 SQL 中,撤销已经执行的操作通常涉及两个主要的概念:事务控制和回滚操作。 ### 1. 事务控制 在支持事务的数据库管理系统(如 MySQL 的 InnoDB 引擎)中,您可以使用事务来确保数据的完整性。事务可以确保一系列的操作…...

Hadoop之WordCount测试
1、Hadoop简介: Hadoop是Apache旗下的一个用Java语言实现的开源软件框架,是一个开发和运行处理大规模数据的软件平台。 Hadoop的核心组件包括Hadoop分布式文件系统(HDFS)和MapReduce编程模型。HDFS是一个高度容错的系统…...

Vue和axios零基础学习
Vue的配置与项目创建 在这之前要先安装nodejs 安装脚手架 官网 Home | Vue CLI (vuejs.org) 先运行,切换成淘宝镜像源,安装速度更快 npm config set registry http://registry.npm.taobao.org 创建项目 用编译器打开一个空文件,在终端输入…...

STM32新建工程-基于库函数
目录 一、创建一个新工程 二、为工程添加文件和路径 三、创建一个main.c文件,并调试 四、修改一些配置 五、用库函数进行写程序 1、首先加入一些库函数和头文件 2、编写库函数程序 一、创建一个新工程 我这里选择STM32F103C8的型号,然后点击OK。 …...
矩阵、字符串、基本语句、函数)
matlab入门学习(二)矩阵、字符串、基本语句、函数
一、矩阵 1、矩阵生成 %矩阵生成%直接法 A[1,2,3; 4,5,6; 7,8,9]%冒号一维矩阵:开始,步长,结束(步长为1时可以省略) B1:1:10 B1:10 %函数法%linspace(开始,结束,元素个数),等差生成…...

PC端微信小程序如何调试?
向往常一样运行开微信小程序开发者工具 如果只弹出pc端小程序,没有出现调试的界面:点击胶囊按钮的三个…选择重新进入小程序 即可依次展开相应的功能调试,改完代码没反应再刷新看看,再没反应就再次重新点击编译并自动调试。...

点击按钮提示气泡信息(Toast)
演示效果: 目录结构: activity_main.xml(布局文件)代码: <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas.android.com/apk/res/android"xmlns:app"http:…...
【易社保-注册安全分析报告】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 1. 暴力破解密码,造成用户信息泄露 2. 短信盗刷的安全问题,影响业务及导致用户投诉 3. 带来经济损失,尤其是后付费客户,风险巨大,造…...

Taotoken用量看板与账单追溯为团队开发带来的成本管控体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板与账单追溯为团队开发带来的成本管控体验 对于依赖大模型API进行开发的团队而言,成本的可观测与可控性…...

从游戏画面Bug到图形学原理:一次深度测试失败的排查与透视矫正插值的深度理解
从游戏画面Bug到图形学原理:深度测试失败的排查与透视矫正插值解析 深夜调试游戏引擎时,屏幕上的三角形边缘突然出现诡异的闪烁——这种被称为"深度冲突"的现象,往往让开发者陷入漫长的调试循环。本文将以一个实际开发中的深度测试…...

思源宋体TTF格式终极指南:免费商用中文字体的完整使用教程
思源宋体TTF格式终极指南:免费商用中文字体的完整使用教程 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为商业项目寻找既专业又免费的中文字体而烦恼吗?…...

树莓派网页编辑器:云端开发环境革新与实战指南
1. 项目概述:一次开发体验的“降维”革新最近,树莓派基金会悄无声息地放出了一个重磅工具:一个可以直接在网页浏览器里运行的代码编辑器。这个消息乍一听,可能不如发布一块新的、性能翻倍的树莓派单板计算机那么激动人心ÿ…...

法律文书分析系统接入 A-MEM 长程记忆
项目实训 | Vue3 FastAPI | NeurIPS 2025 A-MEM 复现与工程落地一、背景与动机 在法律文书智能分析系统的开发过程中,我们发现了一个核心痛点:AI助手没有"记忆"。 用户在第一轮对话里详细描述了案件事实——“我是原告张三,2024年…...

告别命令行!用这个免费软件5分钟搞定Abaqus三维Voronoi泡沫模型
五分钟可视化构建Abaqus三维Voronoi泡沫模型:零代码解决方案全指南 在材料科学与工程仿真领域,三维Voronoi泡沫结构的建模一直是学术研究和工业应用的热点。这种仿生多孔结构因其优异的力学性能和轻量化特性,被广泛应用于缓冲材料、骨科植入物…...

别再死记硬背了!用Python/JavaScript/C++对比理解‘整型变布尔’的底层逻辑
别再死记硬背了!用Python/JavaScript/C对比理解‘整型变布尔’的底层逻辑 在编程语言的学习过程中,类型系统是最基础也最容易被忽视的部分。特别是当开发者从一门动态类型语言转向静态类型语言时,经常会遇到一些"反直觉"的类型转换…...
ESP32 阿里云身份认证 超简版教程)
硬件入门 + 单片机基础(第16天)ESP32 阿里云身份认证 超简版教程
一、准备工作阿里云物联网平台创建产品 设备,拿到三元组ProductKeyDeviceNameDeviceSecretArduino 安装库:AliyunIoTSDK(阿里云官方 MQTT)WiFiPubSubClient二、直接可用代码(只需要改 4 处信息)#include &…...
)
告别串口打印!用STM32+DS18B20做个OLED温湿度计(HAL库+SSD1306)
STM32实战:打造OLED温湿度监测系统(DS18B20SSD1306) 每次调试嵌入式项目时,盯着串口助手看数据总有种隔靴搔痒的感觉。最近在工作室整理零件时,发现抽屉里还躺着几片0.96寸OLED和DS18B20温度传感器,突然萌生…...
)
告别Keil4!手把手教你用Keil C51 V9.61编译51单片机代码(附最新激活方法)
51单片机开发效率革命:Keil C51 V9.61全栈升级指南 当你的51单片机项目编译进度条像蜗牛爬行时,当老旧开发环境频繁卡顿崩溃时,开发者们都在期待一场彻底的效率革命。Keil C51 V9.61的发布,正是针对这些痛点的技术回应——它不仅将…...