【图神经网络】从0到1使用PyG手把手创建异构图
从0到1用PyG创建异构图
- 异构图
- 创建异构图
- 电影评分数据集MovieLens
- 建立二分图数据集
- 转换为可训练的数据集
- 建立异构图神经网络
- 以OGB数据集为例
- HeteroData中常用的函数
- 将简单图神经网络转换为异质图神经网络
- GraphGym的使用
- PyG中常用的卷积层
- 参考资料
在现实中需要对 多种类型的节点以及这些 节点之间多种类型的边进行处理,这就需要
异构图的概念,在异构图中,
不同类型的边描述不同类型节点之间
不同的关系,
异构图神经网络的任务就是在这种图结构上学习出节点或者整个异构图的特征表示。
异构图
异构图的准确定义如下:异构图(Heterogeneous Graphs):一个异构图GGG有一组节点V=v1,v2,...,vnV=v_1,v_2,...,v_nV=v1,v2,...,vn和一组边E=e1,e2,...,emE=e_1,e_2,...,e_mE=e1,e2,...,em组成,其中每个节点和每条边都对应着一种类型,用TvT_vTv表示节点类型的集合,TeT_eTe表示边类型的集合,一个异构图有两个映射函数,分别将每个节点映射到其对应的类型ϕv:V→Tv\phi_v:V\rightarrow T_vϕv:V→Tv,每条边映射到其对应的类型:ϕe:E→Te\phi_e:E\rightarrow T_eϕe:E→Te。
创建异构图
电影评分数据集MovieLens
这里以一个电影评分数据集MovieLens为例,逐行示例如何创建异构图。MovieLens包含了600个用户对于电影的评分,利用这个数据集构建一个二分图,包含电影、用户两种类型的节点,一种类型的边(含有多种类型节点,所以可以看作一个异质图)。
- MovieLens中的
movies.csv文件描述了电影的信息,包括电影在数据集中唯一的ID,电影名,电影所属的类型:
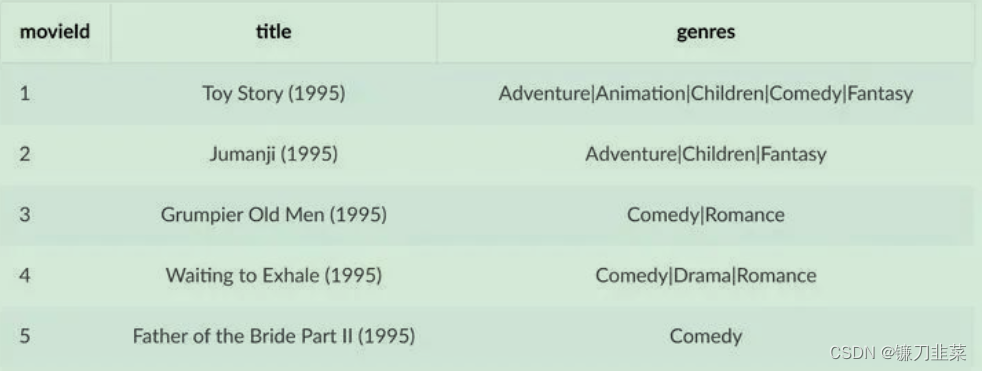
- MovieLens中的ratings.csv包含了用户对于电影的评分:

建立二分图数据集
首先下载一个Python库:sentence_transformers。SentenceTransformers 是一个可以用于句子、文本和图像嵌入的Python库。 可以为 100 多种语言计算文本的嵌入并且可以轻松地将它们用于语义文本相似性、语义搜索和同义词挖掘等常见任务。该框架基于 PyTorch 和 Transformers,并提供了大量针对各种任务的预训练模型。 还可以很容易根据自己的模型进行微调。
pip install -U sentence-transformers
首先,导入依赖库:
import os.path as ospimport torch
import pandas as pd
from sentence_transformers import SentenceTransformerfrom torch_geometric.data import HeteroData, download_url, extract_zip
from torch_geometric.transforms import ToUndirected, RandomLinkSplit
然后,设定数据集:
利用Pandas查看数据集
(1)利用嵌入模型将每个电影名用向量表示(Embedding)
# 将电影名那列用嵌入模型将每个电影名用向量表示(Embedding)
class SequenceEncoder(object):# 初始化,指定使用的embedding module和设备def __init__(self, model_name='all-MiniLM-L6-v2', device=None):# 使用的设备self.device = device# 使用的嵌入模型名self.model = SentenceTransformer(model_name, device=device)# 嵌入模型不参与后续图神经网络的训练@torch.no_grad()def __call__(self, df):x = self.model.encode(# 要进行嵌入的值df.values,# 显示处理进度show_progress_bar=True,# 转换为Pytorch的张量convert_to_tensor=True,# 使用的设备device=self.device)return x.cpu()
(2)将电影类型也进行嵌入表示
# 将电影类型那列也进行嵌入表示
class GenresEncoder(object):# 默认分隔符为"|"def __init__(self, sep="|"):self.sep = sepdef __call__(self, df):genres = set(g for col in df.values for g in col.split(self.sep))# 将电影类型用数字表示mapping = {genre: i for i, genre in enumerate(genres)}# 用multi-hot形式表示电影的类型x = torch.zeros(len(df), len(mapping))for i, col in enumerate(df.values):for genre in col.split(self.sep):x[i, mapping[genre]]=1return x
(3)从CSV文件中读取信息,建立二分图中的节点信息
# 从csv中读取信息,建立二分图中节点的信息
def load_node_csv(path, index_col, encoders=None, **kwargs):""":param path: CSV文件路径:param index_col: 文件中的索引列,也就是节点所在的列:param encoders: 节点嵌入器:param kwargs:return:"""df = pd.read_csv(path, index_col=index_col, **kwargs)# 将索引用数字表示mapping = {index: i for i, index in enumerate(df.index.unique())}# 节点属性向量矩阵x = None# 如果嵌入器非空if encoders is not None:# 对相应的列进行嵌入,获取嵌入向量表示xs = [encoder(df[col]) for col, encoder in encoders.items()]x = torch.cat(xs, dim=-1)return x, mapping
(4)获取节点信息
# 处理movies.csv表,将"电影名","电影类型"列转换为嵌入向量的表示形式
movie_x, movie_mapping = load_node_csv(movie_path, index_col = 'movieId', encoders = {'title':SequenceEncoder(),'genres':GenresEncoder()})
# 处理rating.csv表,将用户ID用PyTorch中的张量表示
user_x, user_mapping = load_node_csv(rating_path, index_col='userId')
# 建立异质图,这里是一个二分图
data = HeteroData() # HeteroData()是PyG中内置的一个表示异质图的数据结构
# 加入不同类型节点的信息
# 加入用户信息,用户没有属性信息, 只需要告诉PyG有多少个用户节点就可以
data['user'].num_nodes = len(user_mapping)
# 告诉PyG 电影的属性向量矩阵,PyG会根据x推断出电影节点的个数
data['movie'].x = movie_x
print(data)

(5)建立用户和电影之间的边的信息
# 将用户对电影的评分转换为PyTorch的张量
class IdentityEncoder(object):def __init__(self, dtype=None):self.dtype = dtypedef __call__(self, df):return torch.from_numpy(df.values).view(-1, 1).to(self.dtype)
(6)建立二分图边的连接信息
# 建立二分图边的链接信息
def load_edge_csv(path, src_index_col, src_mapping, dst_index_col, dst_mapping, encoders=None, **kwargs):""":param path: CSV表的路径:param src_index_col: 二分图左边节点来源于CSV表的哪一列,比如'user_id'这列:param src_mapping:将user_id映射为节点编号,我们前面定义的user_mapping:param dst_index_col:同理,二分图右边电影节点:param dst_mapping::param encoders:边的嵌入器:param kwargs::return:"""df = pd.read_csv(path, **kwargs)# 建立连接信息src = [src_mapping[index] for index in df[src_index_col]]dst = [dst_mapping[index] for index in df[dst_index_col]]# 注意这里edge_index维度为[2, 边数]edge_index = torch.tensor([src, dst])# 边的属性信息edge_attr = None# 如果嵌入器非空if encoders is not None:edge_attrs = [encoder(df[col]) for col, encoder in encoders.items()]edge_attr = torch.cat(edge_attrs, dim=-1)return edge_index, edge_attr
(7)获取二分图边的信息
# 获取二分图边的信息
edge_index, edge_label = load_edge_csv(rating_path,# 二分图左边是用户src_index_col='userId',src_mapping=user_mapping,# 右边是电影dst_index_col='movieId',dst_mapping=movie_mapping,encoders={'rating': IdentityEncoder(dtype=torch.long)})
(8)将二分图中的边命名为(‘user’, ‘rates’, ‘movie’)

到此,我们的异构图数据集,实际上是一个二分图,就构建完毕了。下面还要将其转换为一个可以进行训练的数据集
转换为可训练的数据集
这里,我们将构建的异构图数据集转换为一个可训练的无向图数据集。
(1)转换为无向图,同时删除相反方向边的属性信息
data = ToUndirected()(data)
# 删除相反方向边的属性信息,因为没有电影对用户的评分数据
del data['movie', 'rev_rates', 'user'].edge_label
(2)按照比例分割数据集为训练集、测试集、验证集
# 按照一定比例分割数据集为训练集、测试集和验证集
transform = RandomLinkSplit(num_val=0.05, num_test=0.1,# 负采样比率# 不用负采样,全部输入进行训练neg_sampling_ratio = 0.0,# 告诉PyG边的连接关系edge_types=[('user', 'rates', 'movie')],rev_edge_types=[('movie', 'rev_rates', 'user')],)
# 分割数据集
train_data, val_data, test_data = transform(data)
print(train_data)
print(val_data)
print(test_data)

至此,一个可训练的数据集已经构建完毕。
建立异构图神经网络
以OGB数据集为例
在OGB数据集中包含4种类型的节点:author、paper、institution、field of study;4种类型的边:
- writes:author和paper之间的连接关系
- affiliated with:author和institution之间的连接关系
- cites:paper和paper之间的关系
- has topic:paper和field of study之间的关系
OGB数据集上的任务是预测论文在整个关系网中所属的位置。下面代码示例如何表示这个异质图:
from torch_geometric.data import HeteroData# HeteroData是PyG自带的一个异质图数据结构
data = HeteroData()# 添加节点的信息
data['paper'].x = ... # [num_papers, num_features_paper]
data['author'].x = ... # [num_authors, num_features_author]
data['institution'].x = ... # [num_institutions, num_features_institution]
data['field_of_study'].x = ... # [num_field, num_features_field]# 添加边的连接信息
data['paper', 'cites', 'paper'].edge_index = ... # [2, num_edges_cites]
data['author', 'writes', 'paper'].edge_index = ... # [2, num_edges_writes]
data['author', 'affiliated_with', 'institution'].edge_index = ... # [2, num_edges_affiliated]
data['paper', 'has_topic', 'field_of_study'].edge_index = ... # [2, num_edges_topic]# 添加边的属性信息
data['paper', 'cites', 'paper'].edge_attr = ... # [num_edges_cites, num_features_cites]
data['author', 'writes', 'paper'].edge_attr = ... # [num_edges_writes, num_features_writes]
data['author', 'affiliated_with', 'institution'].edge_attr = ... # [num_edges_affiliated, num_features_affiliated]
data['paper', 'has_topic', 'field_of_study'].edge_attr = ... # [num_edges_topic, num_features_topic]
这样上面的异质图就建立完成了,我们可以将它输入到一个异质图神经网络中:
# 异质图神经网络
model = HeteroGNN(...)
# 获取异构图神经网络的输出
# 注意异质图神经网络的输入是 ..._dict
output = model(data.x_dict, data.edge_index_dict, data.edge_attr_dict)
如果PyG中包含你想用的异质图,可以直接这样导入:
from torch_geometric.datasets import OGB_MAG# 导入数据集
dataset = OGB_MAG(root='./data', preprocess='metapath2vec')
data = dataset[0]
这样上面的异质图就建立完成了,我们可以将它输入到一个异质图神经网络中
HeteroData中常用的函数
下面介绍一下HeteroData中常用的函数:
- 获取异质图中的某种节点或边
paper_node_data=data['paper']
cites_edge_data=data['paper','cites','paper']
- 如果边的连接节点集合或者边的命名是唯一的,还可以这样写
#使用连接端点获取边
cites_edge_data=data['paper','paper']
#使用边的名字获取
cites_edge_data=data['cites']
- 给节点添加新属性
data['paper'].year=...
- 删除节点的某些属性
def data['field_of_study']
- 通过metadata获取异质图中所有类型的信息
node_types,edge_types=data.metadata()
- 所有类型的节点
print(node_types)
- 所有类型的边
print(edge_types)
- 判断异质图自身的一些属性
print(data.has_isolated_nodes())
- 如果不同类型信息之间维度匹配,还可以将异质图融合为一个简单图
homogeneous_data=data.to_homogeneous()
- 对异质图进行变换
import torch_geometric.transforms as T#变为无向图
data=T.ToUndirected()(data)
#添加到自身的环
data=T.AddSelfLoops()(data)
将简单图神经网络转换为异质图神经网络
PyG可以通过torch_geometric.nn.to_hetero(),或者torch_geometric.nn.to_hetero_with_bases()将一个简单图神经网络转换成异质图的形式。
import torch_geometric.transforms as T
from torch_geometric.datasets import OGB_MAG
from torch_geometric.nn import SAGEConv, to_hetero# 导入数据集
dataset = OGB_MAG(root='./data', preprocess='metapath2vec', transform=T.ToUndirected())
data = dataset[0]# 定义一个普通的图神经网络
class GNN(torch.nn.Module):def __init__(self, hidden_channels, out_channels):super().__init__()self.conv1 = SAGEConv((-1, -1), hidden_channels)self.conv2 = SAGEConv((-1, -1), out_channels)def forward(self, x, edge_index):x = self.conv1(x, edge_index).relu()x = self.conv2(x, edge_index)return x# 实例化我们定义的图神经网络
model = GNN(hidden_channels=64, out_channels=dataset.num_classes)
# 将其转换为异质图形式
model = to_hetero(model, data.metadata(), aggr='sum')
PyG的to_hetero具体工作方式是这样的:
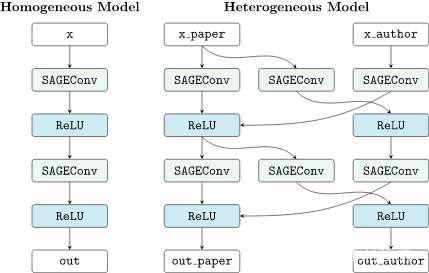
它根据我们的异质图数据结构,自动将我们定义的简单图神经网络结构中的层结构进行了复制,并添加了信息传递路径。
然后,创建的模型可以像往常一样进行训练:
def train():model.train()optimizer.zero_grad()out = model(data.x_dict, data.edge_index_dict)mask = data['paper'].train_maskloss = F.cross_entropy(out['paper'][mask], data['paper'].y[mask])loss.backward()optimizer.step()return float(loss)
异构卷积包装器torch_geometry.nn.conv.HeteroConv允许定义自定义异构消息和更新函数,以从头开始为异构图构建任意MP-GNN。虽然to_hetero()的自动转换器对所有边类型使用相同的运算符,但包装器允许为不同的边类型定义不同的运算符。在这里,HeteroConv将子模块的字典作为输入,图数据中的每个边缘类型都有一个子模块。以下示例显示了如何应用它。
import torch_geometric.transforms as T
from torch_geometric.datasets import OGB_MAG
from torch_geometric.nn import HeteroConv, GCNConv, SAGEConv, GATConv, Lineardataset = OGB_MAG(root='./data', preprocess='metapath2vec', transform=T.ToUndirected())
data = dataset[0]class HeteroGNN(torch.nn.Module):def __init__(self, hidden_channels, out_channels, num_layers):super().__init__()self.convs = torch.nn.ModuleList()for _ in range(num_layers):conv = HeteroConv({('paper', 'cites', 'paper'): GCNConv(-1, hidden_channels),('author', 'writes', 'paper'): SAGEConv((-1, -1), hidden_channels),('paper', 'rev_writes', 'author'): GATConv((-1, -1), hidden_channels,add_self_loops=False),}, aggr='sum')self.convs.append(conv)self.lin = Linear(hidden_channels, out_channels)def forward(self, x_dict, edge_index_dict):for conv in self.convs:x_dict = conv(x_dict, edge_index_dict)x_dict = {key: x.relu() for key, x in x_dict.items()}return self.lin(x_dict['author'])model = HeteroGNN(hidden_channels=64, out_channels=dataset.num_classes,num_layers=2)
我们可以通过调用一次来初始化模型(有关延迟初始化的更多详细信息,请参阅此处)
with torch.no_grad(): # Initialize lazy modules.out = model(data.x_dict, data.edge_index_dict)
GraphGym的使用
PyG 2.0 现在通过 torch_geometric.graphgym 正式支持 GraphGym。总的来说,GraphGym 是一个平台,用于通过高度模块化的 pipeline 从配置文件中设计和评估图神经网络:
- GraphGym 是开始学习标准化 GNN 实现和评估的最佳平台;
- GraphGym 提供了一个简单的接口来并行尝试数千个 GNN 架构,以找到适合特定任务的最佳设计;
- GraphGym 可轻松进行超参数搜索并可视化哪些设计选择更好。

对于GraphGym更多资料,参考https://pytorch-geometric.readthedocs.io/en/latest/modules/graphgym.html
PyG中常用的卷积层
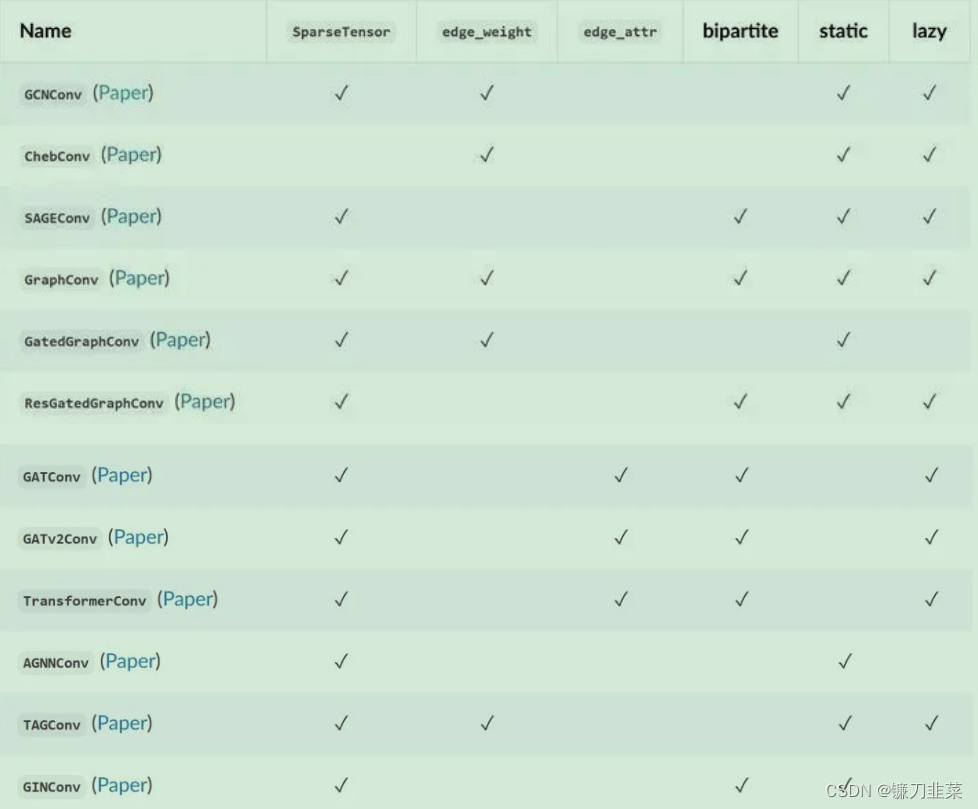
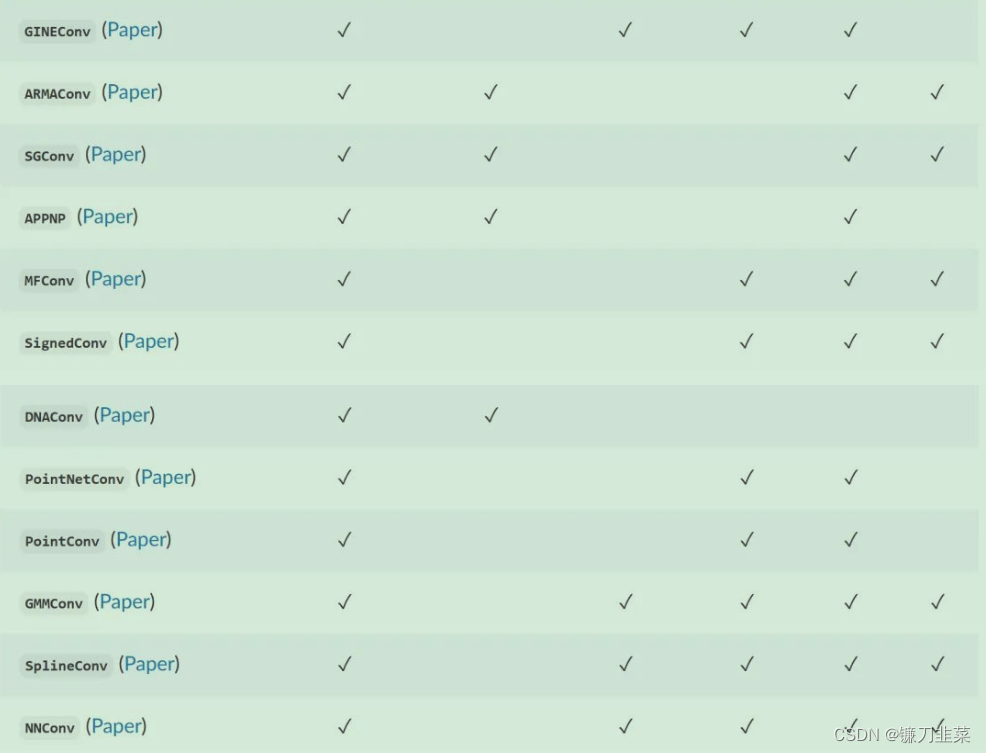
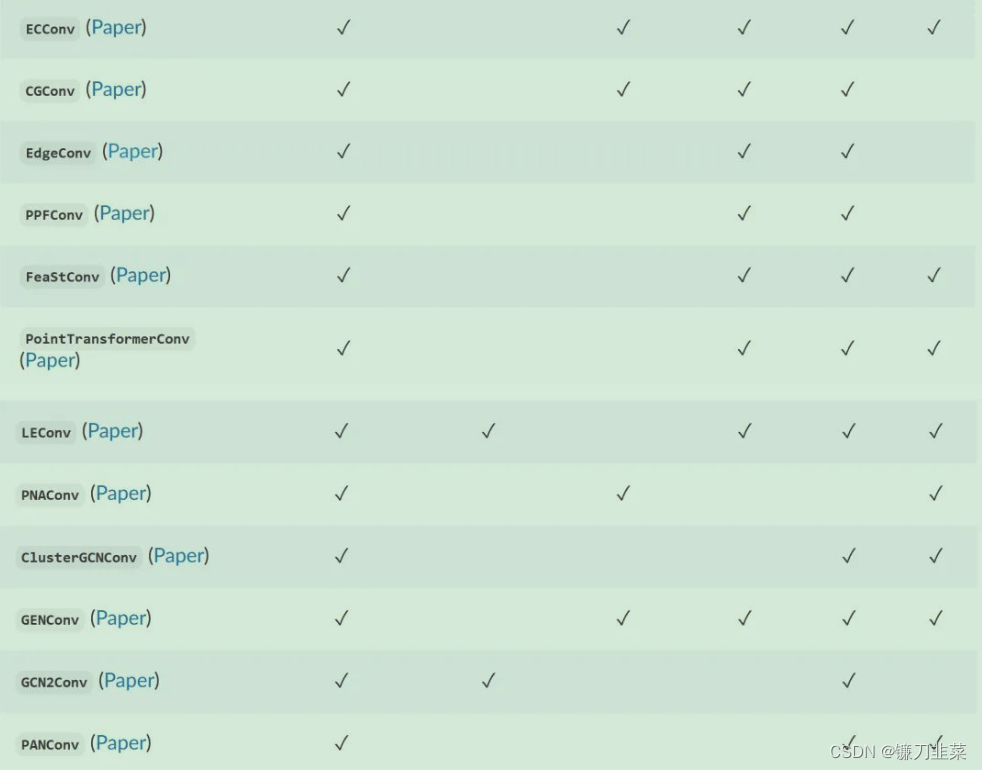
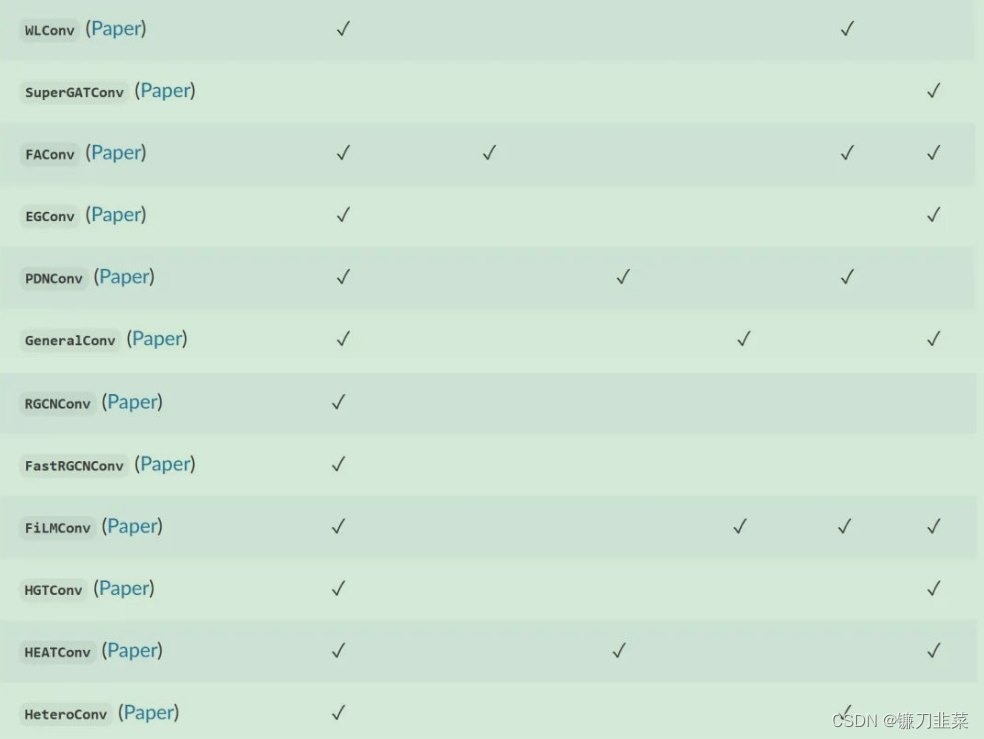

参考资料
- PyG创建自定义异构图Heterogeneous Graphs数据集
- Pytorch图神经网络库——PyG创建自己的数据集
- Pytorch图神经网络库——PyG异构图学习
- 异质图的建立
- 《图深度学习》 马耀、汤继良著
- SentenceTransformers 库介绍
- GraphGym
相关文章:
【图神经网络】从0到1使用PyG手把手创建异构图
从0到1用PyG创建异构图异构图创建异构图电影评分数据集MovieLens建立二分图数据集转换为可训练的数据集建立异构图神经网络以OGB数据集为例HeteroData中常用的函数将简单图神经网络转换为异质图神经网络GraphGym的使用PyG中常用的卷积层参考资料在现实中需要对 多种类型的节点以…...
2023美赛春季赛思路分析汇总
将在本帖更新汇总2023美赛春季赛两个赛题思路,大家可以点赞收藏! 2023美赛春季赛各赛题全部解题参考思路资料模型代码等全部实时更新!第一时间获取全部美赛春季赛相关资料! 目前思路整理仅为部分,请大家耐心等待&…...
GPT4国内镜像站
GPT-4介绍GPT-4是OpenAI发布的最先进的大型语言模型,是ChatGPT模型的超级进化版本。与ChatGPT相比,GPT-4的推理能力、复杂问题的理解能力、写代码能力得到了极大的强化,是当前人工智能领域,最有希望实现通用人工智能的大模型。但G…...

代码随想录算法训练营第四十八天| 198 打家劫舍 213 打家劫舍II 337 打家劫舍III
代码随想录算法训练营第四十八天| 198 打家劫舍 213 打家劫舍II 337 打家劫舍III LeetCode 198 打家劫舍 题目: 198.打家劫舍 动规五部曲: 确定dp数组以及下标的含义 dp[i]:考虑下标i(包括i)以内的房屋,最多可以偷…...
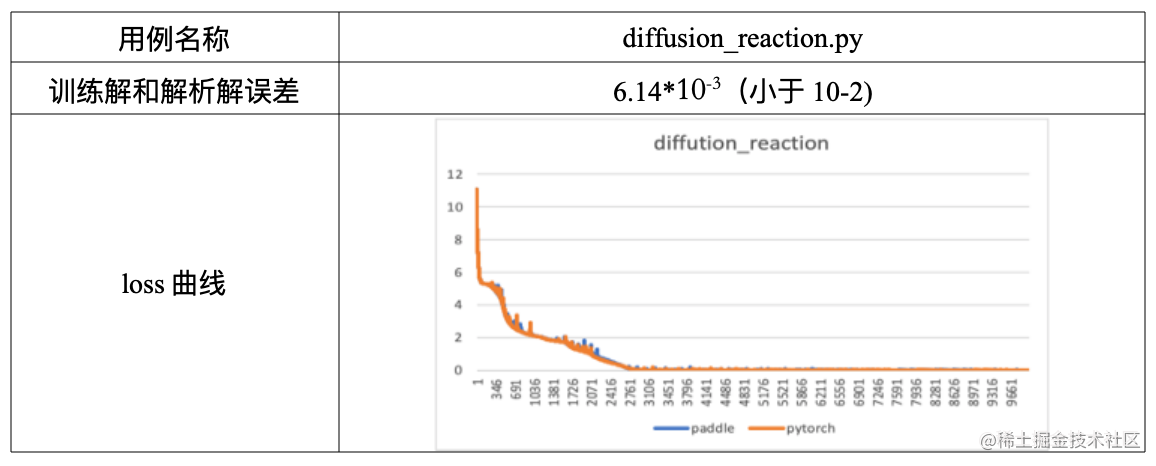
飞桨DeepXDE用例验证及评估
在之前发布的文章中,我们介绍了飞桨全量支持业内优秀科学计算深度学习工具 DeepXDE。本期主要介绍基于飞桨动态图模式对 DeepXDE 中 PINN 方法用例实现、验证及评估的具体流程,同时提供典型环节的代码,旨在帮助大家更加高效地基于飞桨框架进行…...

telegram连接本地Proxy连接不上
1.ClashX开启允许局域网连接。 2.重启ClashX和Telegram...
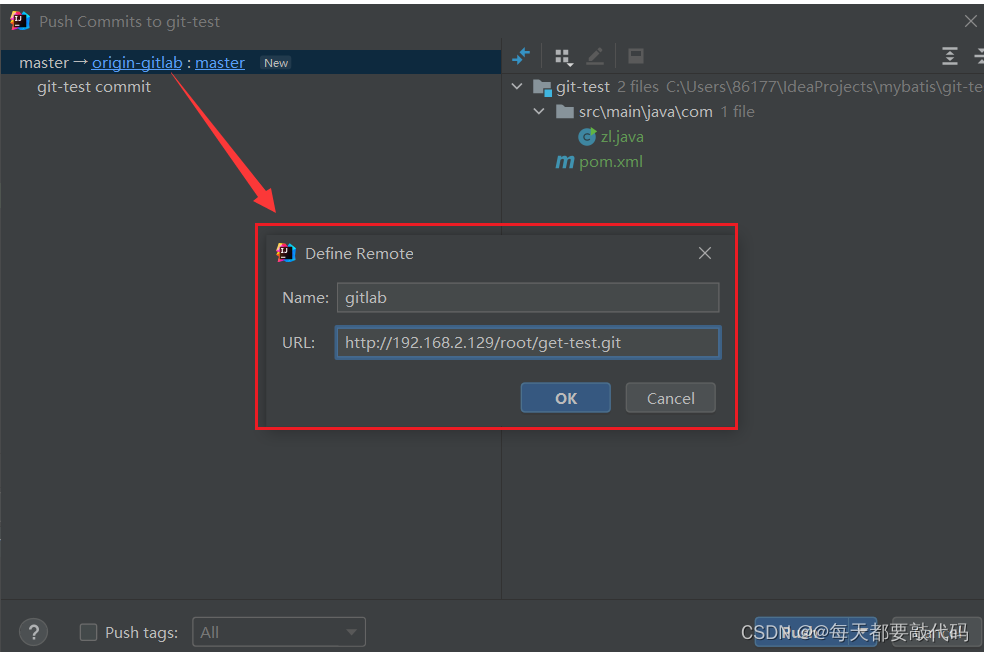
【分布式版本控制系统Git】| 国内代码托管中心-Gitee、自建代码托管平台-GitLab
目录 一:国内代码托管中心-码云 1. 码云创建远程库 2. IDEA 集成码云 3. 码云复制 GitHub 项目 二:自建代码托管平台-GitLab 1. GitLab 安装 2. IDEA 集成 GitLab 一:国内代码托管中心-码云 众所周知,GitHub 服务器在国外&…...
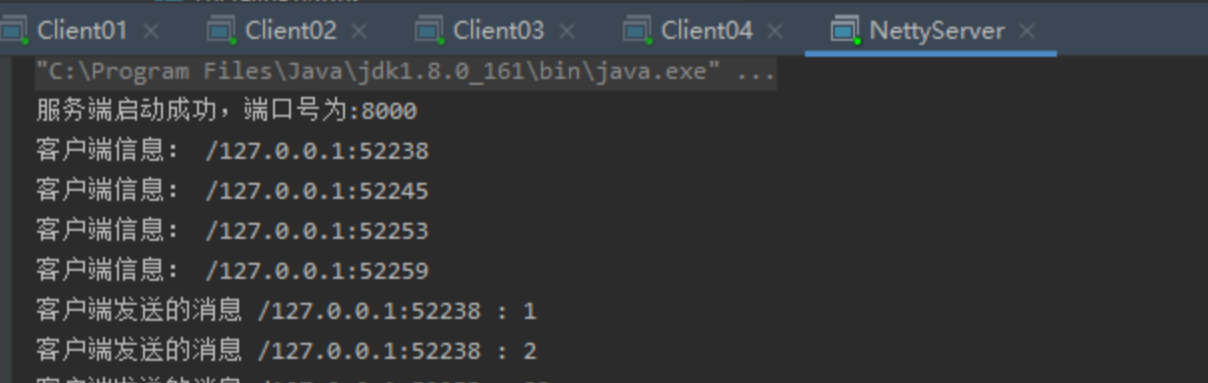
【面试】BIO、NIO、AIO面试题
文章目录什么是IO在了解不同的IO之前先了解:同步与异步,阻塞与非阻塞的区别什么是BIO什么是NIO什么是AIO什么NettyBIO和NIO、AIO的区别IO流的分类按照读写的单位大小来分:按照实际IO操作来分:按照读写时是否直接与硬盘,…...

C语言实现拼图求解
题目: 有如下的八种拼图块,每块都是由八块小正方块构成, 这些拼图块刚好可以某种方式拼合放入给定的目标形状, 请以C或C++编程,自动求解 一种拼图方式 目标拼图: 本栏目适合想要深入了解无向图、深度优先算法、编程语句如何实现算法、想要去接拼图算法的小伙伴。...

python --获取本机屏幕分辨率
pywin32 方法一 使用 win32api.GetDeviceCaps() 方法来获取显示器的分辨率。 使用 win32api.GetDC() 方法获取整个屏幕的设备上下文句柄,然后使用 win32api.GetDeviceCaps() 方法获取水平和垂直方向的分辨率。最后需要调用 win32api.ReleaseDC() 方法释放设备上下…...
Java多态
目录 1.多态是什么? 2.多态的条件 3.重写 3.1重写的概念 3.2重写的作用 3.3重写的规则 4.向上转型与向下转型 4.1向上转型 4.2向下转型 5.多态的优缺点 5.1 优点 5.2 缺点 面向对象程序三大特性:封装、继承、多态。 1.多态是什么࿱…...

绝对路径和相对路径
1.绝对路径:从根目录为起点到某一个目录的路径 使用计算机时要找到需要的文件就必须知道文件的位置,表示文件的位置的方式就是路径,例如只要看到这个路径:c:/website/img/photo.jpg我们就知道photo.jpg文件是在c盘的website目录下…...

Linux第二次总结
Linux阶段总结 OSI模型:应用层、表示层、会话层、传输层、网络层、数据链路层、物理层 路由器的工作原理:最佳路径选择 三次握手四次挥手:... shell是翻译官把人类语言翻译成二进制语言 Tab作用:自动补齐、确认输入是否有误 …...
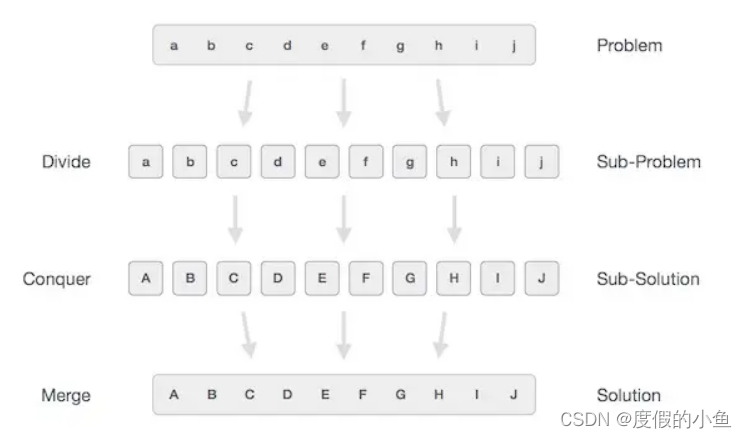
算法:贪婪算法、分而治之
算法:贪婪算法、分而治之 文章目录1.贪婪算法计数硬币实例12.分而治之分割/歇征服/解决合并/合并实例23.动态规划对照实例34.基本概念算法数据定义数据对象内置数据类型派生数据类型基本操作1.贪婪算法 设计算法以实现给定问题的最佳解决方案。在贪婪算法方法中&am…...

462. 最小操作次数使数组元素相等 II——【Leetcode每日一题】
462. 最小操作次数使数组元素相等 II 给你一个长度为 n 的整数数组 nums ,返回使所有数组元素相等需要的最小操作数。 在一次操作中,你可以使数组中的一个元素加 1 或者减 1 。 示例 1: 输入:nums [1,2,3] 输出:2 …...

对数据库的库及表的操作
全篇在MySQL操作下完成 在此之前,先介绍一下,字段、列类型及属性。 一、什么是字段、列类型、属性 (1)字段,一张表中列的名称;列类型,该列存储数据的类型;属性,描述列类型的特征。 …...

final类又没实现接口应该用哪一种代理, jdk动态代理还是cglib代理
jdk动态代理还是cglib代理🧙jdk动态代理和cglib代理的示例JDK动态代理原理CGLIB代理final类又没实现接口应该用哪一种代理, jdk动态代理还是cglib代理滚滚长江东逝水,浪花淘尽英雄。——唐代杨炯《临江仙》 jdk动态代理和cglib代理的示例 以下是一个使用…...

使用StaMPS_Visualizer
0 前言 StaMPS-Visualizer :由thho开发的用于可视化由StaMPS / MTI处理的DInSAR结果。 github地址:StaMPS-Visualizer 使用StaMPS_Visualizer需要配置好StaMPS,并安装好R和Rstudio Ubuntu中安装StaMPS StaMPS-Visualizer 安装步骤–在linux…...

高并发-高性能-高可用-结论版
文章目录上万的并发需要多少台web服务器一般单机能处理200请求,为何redis单机却能处理上万请求单线程每秒能处理(发送/响应)的http请求数三高的定义高并发的解决方案高性能的解决方案高可用的解决方案参考文章上万的并发需要多少台web服务器 …...

数智转型助力建筑业全产业链升级,你了解多少?
关于数智转型,指的是基于数字化技术和数据驱动的思维方式,将企业的管理、业务和服务进行全面的升级和改造,从而帮助实现企业的数字化转型和升级。通过数字技术和数据分析来提高企业的效率、创新能力和竞争力,进一步提高企业的市场…...

猫抓扩展完整指南:三步掌握浏览器视频嗅探与下载技巧
猫抓扩展完整指南:三步掌握浏览器视频嗅探与下载技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch&#…...

AI模型部署实战:基于FastAPI与Tauri构建OpenClaw模型GUI应用
1. 项目概述与核心价值最近在AI应用开发圈里,一个名为“GrahamMiranda-AI/openclaw-model-gui”的项目引起了我的注意。乍一看这个标题,它融合了“openclaw-model”和“gui”两个关键部分,这让我立刻联想到一个典型的场景:一个已经…...

Redis高效开发工具集:从SCAN迭代到数据迁移的Python实践
1. 项目概述:一个Redis开发者的“瑞士军刀”如果你和我一样,日常开发中重度依赖Redis,那你一定遇到过这些场景:想快速查看某个大Key的内存占用,得写脚本遍历;想分析某个Pattern下的所有键,得手动…...

基于Helm Chart的JupyterHub生产级部署与运维实战指南
1. 项目概述:为什么我们需要一个可扩展的JupyterHub部署方案?如果你在团队里负责过数据科学或机器学习平台的搭建,大概率会为Jupyter Notebook的部署和管理头疼过。单个Jupyter Notebook服务给一两个人用还行,一旦团队规模扩大到十…...

AI量化交易实战:从机器学习模型到加密货币对冲基金系统构建
1. 项目概述:一个面向加密货币的AI对冲基金框架最近几年,AI在量化交易领域的应用已经从实验室走向了实战,尤其是在波动性极高的加密货币市场。如果你对量化交易和机器学习感兴趣,并且想找一个能直接上手、结构清晰的实战项目来学习…...

基于Kubernetes Lease构建分布式部署锁:解决CI/CD环境下的资源竞争
1. 项目概述:从“clawfight”看一场被遗忘的社区技术博弈看到“2019-02-18/clawfight”这个标题,很多人的第一反应可能是困惑。它不像一个标准的软件项目名,没有清晰的版本号,也没有指明具体的技术栈。但恰恰是这种看似随意的命名…...
NeoPixel光剑制作全攻略:从WS2812B原理到实战装配
1. 项目概述:从零件到光剑的旅程如果你和我一样,是个对《星球大战》里的光剑毫无抵抗力,同时又喜欢动手折腾电子玩意儿的人,那么用NeoPixel灯带自制一把会发光、能变色的光剑,绝对是件充满成就感的事。这不仅仅是把灯塞…...

从零打造开源机械爪:低成本机器人抓取方案全解析
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“OpenClawTuto”。光看这个名字,你可能会有点摸不着头脑,它不像“XX管理系统”或者“XX深度学习框架”那样一目了然。但作为一个在开源社区和自动化领域摸爬滚打了十来年的老手…...

动态提示词工程:让AI提示词具备上下文学习能力的实践指南
1. 项目概述:当提示词遇上上下文学习最近在折腾大语言模型应用时,我反复遇到一个痛点:精心设计的提示词(Prompt)在特定任务上效果拔群,但换个场景或数据,效果就大打折扣。每次都得重新调整、测试…...

基于Claude的AI招聘系统:从简历解析到智能评估全流程实践
1. 项目概述:当Claude成为你的招聘官最近在GitHub上看到一个挺有意思的项目,叫“hire-from-claude”。光看名字,你可能会觉得有点玄乎,难道是要让AI来面试和招聘人类?其实,这个项目的核心思路,是…...