【力扣 | SQL题 | 每日四题】力扣1783,1757,1747,1623,1468,1661
昨天晚上睡着了,今天把昨天的每日一题给补上。
1. 力扣1783:大满贯数量
1.1 题目:
表:Players
+----------------+---------+ | Column Name | Type | +----------------+---------+ | player_id | int | | player_name | varchar | +----------------+---------+ player_id 是这个表的主键(具有唯一值的列) 这个表的每一行给出一个网球运动员的 ID 和 姓名
表:Championships
+---------------+---------+ | Column Name | Type | +---------------+---------+ | year | int | | Wimbledon | int | | Fr_open | int | | US_open | int | | Au_open | int | +---------------+---------+ year 是这个表的主键(具有唯一值的列) 该表的每一行都包含在每场大满贯网球比赛中赢得比赛的球员的 ID
编写解决方案,找出每一个球员赢得大满贯比赛的次数。结果不包含没有赢得比赛的球员的ID 。
结果集 无顺序要求 。
结果的格式,如下所示。
示例 1:
输入: Players 表: +-----------+-------------+ | player_id | player_name | +-----------+-------------+ | 1 | Nadal | | 2 | Federer | | 3 | Novak | +-----------+-------------+ Championships 表: +------+-----------+---------+---------+---------+ | year | Wimbledon | Fr_open | US_open | Au_open | +------+-----------+---------+---------+---------+ | 2018 | 1 | 1 | 1 | 1 | | 2019 | 1 | 1 | 2 | 2 | | 2020 | 2 | 1 | 2 | 2 | +------+-----------+---------+---------+---------+ 输出: +-----------+-------------+-------------------+ | player_id | player_name | grand_slams_count | +-----------+-------------+-------------------+ | 2 | Federer | 5 | | 1 | Nadal | 7 | +-----------+-------------+-------------------+ 解释: Player 1 (Nadal) 获得了 7 次大满贯:其中温网 2 次(2018, 2019), 法国公开赛 3 次 (2018, 2019, 2020), 美国公开赛 1 次 (2018)以及澳网公开赛 1 次 (2018) 。 Player 2 (Federer) 获得了 5 次大满贯:其中温网 1 次 (2020), 美国公开赛 2 次 (2019, 2020) 以及澳网公开赛 2 次 (2019, 2020) 。 Player 3 (Novak) 没有赢得,因此不包含在结果集中。
1.2 思路:
union all炸裂,然后再查询。
1.3 题解:
-- union all 大法
with tep as (select Wimbledon grand_slamsfrom Championshipsunion all select Fr_open grand_slamsfrom Championshipsunion all select US_open grand_slamsfrom Championshipsunion all select Au_open grand_slamsfrom Championships
)
-- 然后在炸裂完的表中查询
select player_id, player_name, (select count(*)from tepwhere grand_slams = player_id
) grand_slams_count
from Players
where (select count(*)from tepwhere grand_slams = player_id
) > 02. 力扣1757:可回收且低脂的产品
2.1 题目:
表:Products
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| product_id | int |
| low_fats | enum |
| recyclable | enum |
+-------------+---------+
product_id 是该表的主键(具有唯一值的列)。
low_fats 是枚举类型,取值为以下两种 ('Y', 'N'),其中 'Y' 表示该产品是低脂产品,'N' 表示不是低脂产品。
recyclable 是枚举类型,取值为以下两种 ('Y', 'N'),其中 'Y' 表示该产品可回收,而 'N' 表示不可回收。
编写解决方案找出既是低脂又是可回收的产品编号。
返回结果 无顺序要求 。
返回结果格式如下例所示:
示例 1:
输入: Products 表: +-------------+----------+------------+ | product_id | low_fats | recyclable | +-------------+----------+------------+ | 0 | Y | N | | 1 | Y | Y | | 2 | N | Y | | 3 | Y | Y | | 4 | N | N | +-------------+----------+------------+ 输出: +-------------+ | product_id | +-------------+ | 1 | | 3 | +-------------+ 解释: 只有产品 id 为 1 和 3 的产品,既是低脂又是可回收的产品。
2.2 思路:
感谢力扣能赏些简单题给我们提升信息。
2.3 题解:
select distinct product_id
from Products
where low_fats = 'Y' and recyclable = 'Y'3. 力扣1747:应该被禁止的Leetflex账户
3.1 题目:
表: LogInfo
+-------------+----------+ | Column Name | Type | +-------------+----------+ | account_id | int | | ip_address | int | | login | datetime | | logout | datetime | +-------------+----------+ 该表可能包含重复项。 该表包含有关Leetflex帐户的登录和注销日期的信息。 它还包含了该账户用于登录和注销的网络地址的信息。 题目确保每一个注销时间都在登录时间之后。
编写解决方案,查找那些应该被禁止的Leetflex帐户编号 account_id 。 如果某个帐户在某一时刻从两个不同的网络地址登录了,则这个帐户应该被禁止。
可以以 任何顺序 返回结果。
查询结果格式如下例所示。
示例 1:
输入: LogInfo table: +------------+------------+---------------------+---------------------+ | account_id | ip_address | login | logout | +------------+------------+---------------------+---------------------+ | 1 | 1 | 2021-02-01 09:00:00 | 2021-02-01 09:30:00 | | 1 | 2 | 2021-02-01 08:00:00 | 2021-02-01 11:30:00 | | 2 | 6 | 2021-02-01 20:30:00 | 2021-02-01 22:00:00 | | 2 | 7 | 2021-02-02 20:30:00 | 2021-02-02 22:00:00 | | 3 | 9 | 2021-02-01 16:00:00 | 2021-02-01 16:59:59 | | 3 | 13 | 2021-02-01 17:00:00 | 2021-02-01 17:59:59 | | 4 | 10 | 2021-02-01 16:00:00 | 2021-02-01 17:00:00 | | 4 | 11 | 2021-02-01 17:00:00 | 2021-02-01 17:59:59 | +------------+------------+---------------------+---------------------+ 输出: +------------+ | account_id | +------------+ | 1 | | 4 | +------------+ 解释: Account ID 1 --> 该账户从 "2021-02-01 09:00:00" 到 "2021-02-01 09:30:00" 在两个不同的网络地址(1 and 2)上激活了。它应该被禁止. Account ID 2 --> 该账户在两个不同的网络地址 (6, 7) 激活了,但在不同的时间上. Account ID 3 --> 该账户在两个不同的网络地址 (9, 13) 激活了,虽然是同一天,但时间上没有交集. Account ID 4 --> 该账户从 "2021-02-01 17:00:00" 到 "2021-02-01 17:00:00" 在两个不同的网络地址 (10 and 11)上激活了。它应该被禁止.
3.2 思路:
自连接。
3.3 题解:
-- 自连接,连接条件是:账户相同,但ip地址不一样-- 如果该条记录的这个登录时间在另一个ip地址出现了,就留下来。
select distinct l2.account_id
from LogInfo l1
join LogInfo l2
on l1.account_id = l2.account_id and l1.ip_address <> l2.ip_address
where (l1.login between l2.login and l2.logout) or (l1.login between l2.login and l2.logout)4. 力扣1623:三人国家代表队
4.1 题目:
表: SchoolA
+---------------+---------+ | Column Name | Type | +---------------+---------+ | student_id | int | | student_name | varchar | +---------------+---------+ student_id 是该表具有唯一值的列 表中的每一行包含了学校 A 中每一个学生的名字和 ID 所有 student_name 在表中都是独一无二的
表: SchoolB
+---------------+---------+ | Column Name | Type | +---------------+---------+ | student_id | int | | student_name | varchar | +---------------+---------+ student_id 是该表具有唯一值的列 表中的每一行包含了学校 B 中每一个学生的名字和 ID 所有 student_name 在表中都是独一无二的
表: SchoolC
+---------------+---------+ | Column Name | Type | +---------------+---------+ | student_id | int | | student_name | varchar | +---------------+---------+ student_id 是该表具有唯一值的列 表中的每一行包含了学校 C 中每一个学生的名字和 ID 所有 student_name 在表中都是独一无二的
有一个国家只有三所学校,这个国家的每一个学生只会注册 一所学校。
这个国家正在参加一个竞赛,他们希望从这三所学校中各选出一个学生来组建一支三人的代表队。例如:
member_A是从SchoolA中选出的member_B是从SchoolB中选出的member_C是从SchoolC中选出的- 被选中的学生具有不同的名字和 ID(没有任何两个学生拥有相同的名字、没有任何两个学生拥有相同的 ID)
使用上述条件,编写一个解决方案来找到所有可能的三人国家代表队组合。
返回结果 无顺序要求。
结果格式如下示例所示。
示例 1:
输入:SchoolAtable: +------------+--------------+ | student_id | student_name | +------------+--------------+ | 1 | Alice | | 2 | Bob | +------------+--------------+SchoolBtable: +------------+--------------+ | student_id | student_name | +------------+--------------+ | 3 | Tom | +------------+--------------+SchoolCtable: +------------+--------------+ | student_id | student_name | +------------+--------------+ | 3 | Tom | | 2 | Jerry | | 10 | Alice | +------------+--------------+ 输出: +----------+----------+----------+ | member_A | member_B | member_C | +----------+----------+----------+ | Alice | Tom | Jerry | | Bob | Tom | Alice | +----------+----------+----------+ 解释: 让我们看看有哪些可能的组合: - (Alice, Tom, Tom) --> 不适用,因为member_B(Tom)和member_C(Tom)有相同的名字和ID - (Alice, Tom, Jerry) --> 可能的组合 - (Alice, Tom, Alice) --> 不适用,因为member_A和member_C有相同的名字 - (Bob, Tom, Tom) --> 不适用,因为member_B和member_C有相同的名字和ID - (Bob, Tom, Jerry) --> 不适用,因为member_A和member_C有相同的ID - (Bob, Tom, Alice) --> 可能的组合.
4.2 思路:
多表连接,需要满足字段之间的ID不同,且名字也不同。
4.3 题解:
-- 满足了ID唯一,名字唯一
with tep1 as (select a.student_name a_student_name, b.student_name b_student_name, a.student_id a_student_id, b.student_id b_student_idfrom SchoolA a join SchoolB b on a.student_name <> b.student_nameand a.student_id <> b.student_id
)select a_student_name member_A, b_student_name member_B, student_name member_C
from tep1 t
join SchoolC c
on student_name <> a_student_name and student_name <> t.b_student_name
and t.a_student_id <> c.student_id and t.b_student_id <> c.student_id5. 力扣1468:计算税后工资
5.1 题目:
Salaries 表:
+---------------+---------+ | Column Name | Type | +---------------+---------+ | company_id | int | | employee_id | int | | employee_name | varchar | | salary | int | +---------------+---------+ 在 SQL 中,(company_id, employee_id) 是这个表的主键 这个表包括员工的company id, id, name 和 salary
查找出每个员工的税后工资
每个公司的税率计算依照以下规则
- 如果这个公司员工最高工资不到
$1000,税率为0% - 如果这个公司员工最高工资在
[1000, 10000]之间,税率为24% - 如果这个公司员工最高工资大于
$10000,税率为49%
按 任意顺序 返回结果。
返回结果的格式如下例所示。
示例 1:
输入: Salaries 表: +------------+-------------+---------------+--------+ | company_id | employee_id | employee_name | salary | +------------+-------------+---------------+--------+ | 1 | 1 | Tony | 2000 | | 1 | 2 | Pronub | 21300 | | 1 | 3 | Tyrrox | 10800 | | 2 | 1 | Pam | 300 | | 2 | 7 | Bassem | 450 | | 2 | 9 | Hermione | 700 | | 3 | 7 | Bocaben | 100 | | 3 | 2 | Ognjen | 2200 | | 3 | 13 | Nyancat | 3300 | | 3 | 15 | Morninngcat | 7777 | +------------+-------------+---------------+--------+ 输出: +------------+-------------+---------------+--------+ | company_id | employee_id | employee_name | salary | +------------+-------------+---------------+--------+ | 1 | 1 | Tony | 1020 | | 1 | 2 | Pronub | 10863 | | 1 | 3 | Tyrrox | 5508 | | 2 | 1 | Pam | 300 | | 2 | 7 | Bassem | 450 | | 2 | 9 | Hermione | 700 | | 3 | 7 | Bocaben | 76 | | 3 | 2 | Ognjen | 1672 | | 3 | 13 | Nyancat | 2508 | | 3 | 15 | Morninngcat | 5911 | +------------+-------------+---------------+--------+ 解释: 对于公司 1,最高薪资为 21300。公司 1 的员工税率为 49%。 对于公司 2,最高薪资为 700。公司 2 的员工税率为 0%。 对于公司 3,最高薪资为 7777。公司 3 的员工税率为 24%。 薪资扣除税后的金额计算公式为:薪资 - (税率百分比 / 100) * 薪资 例如,Morninngcat(员工号 3,薪资为 7777)扣除税后的薪资为:7777 - 7777 * (24 / 100) = 7777 - 1866.48 = 5910.52,四舍五入为 5911。
5.2 思路:
case when语句,如果这个分组里面的最高工资怎么怎么样,就计算税后工资。记得要round
四舍五入。
5.3 题解:
select company_id, employee_id, employee_name,
case when (select max(salary)
from Salaries s1
where s.company_id = s1.company_id) <= 1000 then salarywhen (select max(salary)
from Salaries s1
where s.company_id = s1.company_id) <= 10000 then round(salary*0.76)else round(salary*0.51)
end salaryfrom Salaries s6. 力扣1661:每台机器的进程平均运行时间
6.1 题目:
表: Activity
+----------------+---------+
| Column Name | Type |
+----------------+---------+
| machine_id | int |
| process_id | int |
| activity_type | enum |
| timestamp | float |
+----------------+---------+
该表展示了一家工厂网站的用户活动。
(machine_id, process_id, activity_type) 是当前表的主键(具有唯一值的列的组合)。
machine_id 是一台机器的ID号。
process_id 是运行在各机器上的进程ID号。
activity_type 是枚举类型 ('start', 'end')。
timestamp 是浮点类型,代表当前时间(以秒为单位)。
'start' 代表该进程在这台机器上的开始运行时间戳 , 'end' 代表该进程在这台机器上的终止运行时间戳。
同一台机器,同一个进程都有一对开始时间戳和结束时间戳,而且开始时间戳永远在结束时间戳前面。
现在有一个工厂网站由几台机器运行,每台机器上运行着 相同数量的进程 。编写解决方案,计算每台机器各自完成一个进程任务的平均耗时。
完成一个进程任务的时间指进程的'end' 时间戳 减去 'start' 时间戳。平均耗时通过计算每台机器上所有进程任务的总耗费时间除以机器上的总进程数量获得。
结果表必须包含machine_id(机器ID) 和对应的 average time(平均耗时) 别名 processing_time,且四舍五入保留3位小数。
以 任意顺序 返回表。
具体参考例子如下。
示例 1:
输入: Activity table: +------------+------------+---------------+-----------+ | machine_id | process_id | activity_type | timestamp | +------------+------------+---------------+-----------+ | 0 | 0 | start | 0.712 | | 0 | 0 | end | 1.520 | | 0 | 1 | start | 3.140 | | 0 | 1 | end | 4.120 | | 1 | 0 | start | 0.550 | | 1 | 0 | end | 1.550 | | 1 | 1 | start | 0.430 | | 1 | 1 | end | 1.420 | | 2 | 0 | start | 4.100 | | 2 | 0 | end | 4.512 | | 2 | 1 | start | 2.500 | | 2 | 1 | end | 5.000 | +------------+------------+---------------+-----------+ 输出: +------------+-----------------+ | machine_id | processing_time | +------------+-----------------+ | 0 | 0.894 | | 1 | 0.995 | | 2 | 1.456 | +------------+-----------------+ 解释: 一共有3台机器,每台机器运行着两个进程. 机器 0 的平均耗时: ((1.520 - 0.712) + (4.120 - 3.140)) / 2 = 0.894 机器 1 的平均耗时: ((1.550 - 0.550) + (1.420 - 0.430)) / 2 = 0.995 机器 2 的平均耗时: ((4.512 - 4.100) + (5.000 - 2.500)) / 2 = 1.456
6.2 思路:
group by分组,然后再将end的平均时间减去start的平均时间。->avg(end) - avg(start) == avg(end - start)是等价的。
6.3 题解:
select machine_id, round((select avg(timestamp)from Activity a1 where a.machine_id = a1.machine_id and activity_type = 'end'
) - (select avg(timestamp)from Activity a2where a.machine_id = a2.machine_id and activity_type = 'start'
), 3
) processing_time
from Activity a
group by machine_id相关文章:

【力扣 | SQL题 | 每日四题】力扣1783,1757,1747,1623,1468,1661
昨天晚上睡着了,今天把昨天的每日一题给补上。 1. 力扣1783:大满贯数量 1.1 题目: 表:Players ------------------------- | Column Name | Type | ------------------------- | player_id | int | | player_na…...

《深入探究 C++中的函数模板特化:开启编程新境界》
在 C的广袤世界中,函数模板特化是一项强大而富有魅力的技术,它为程序员提供了更高的灵活性和效率。本文将带你深入了解 C中函数模板特化是如何实现的,揭开这一神秘面纱,让你在编程之路上更上一层楼。 一、函数模板的基础概念 在…...

RTEMS面试题汇总及参考答案
目录 RTEMS是什么?它在嵌入式系统中扮演什么角色? RTEMS的全称是什么? RTEMS的主要特点有哪些? RTEMS支持哪些处理器架构? RTEMS的可剥夺型内核和不可剥夺型内核有何不同? RTEMS 的微内核设计及其优势 RTEMS 如何实现多任务处理和调度 RTEMS 的任务调度策略有哪…...
)
螺蛳壳里做道场:老破机搭建的私人数据中心---Centos下Docker学习03(网络及IP规划)
3 网络及IP规划 3.1 容器连接网络初步规划 规划所有容器与虚拟机的三张网卡以macvlan的方式进行连接(以后根据应用可以更改),在docker下创建nat、wifi、nei、wai四张网卡,他们和虚拟机及宿主机上NIC的相关连接参数如下表所示&am…...

BLOOM 模型的核心原理、局限与未来发展方向解析
1. 引言 1.1 BLOOM 模型概述 BLOOM(BigScience Large Open-science Open-access Multilingual Language Model)是一款由多个国际研究团队联合开发的大型语言模型。BLOOM 模型旨在通过先进的 Transformer 架构处理复杂的自然语言生成与理解任务。它支持…...

Kubernetes 深度洞察:重新认识 Docker 容器的奇妙世界
《Kubernetes 深度洞察:重新认识 Docker 容器的奇妙世界》 在 Kubernetes 的学习进程中,对 Docker 容器的深入理解至关重要。这一节,我们将重新认识 Docker 容器,探索其在 Kubernetes 生态系统中的关键作用。 一、Docker 容器的基本概念 Docker 容器是一种轻量级的虚拟化…...

柔性作业车间调度(FJSP)
1.1 调度问题的研究背景 生产调度是指针对一项可分解的工作(如产品制造),在尽可能满足工艺路线、资源情况、交货期等约束条件的前提下,通过下达生产指令,安排其组成部分(操作)所使用的资源、加工时间及加工的先后顺序,以获得产品制造时间或成本最优化的一项工作。 一般研究车间…...

速盾:游戏用CDN可以吗?
游戏用CDN是一种常见的解决方案,可以提高游戏的网络性能和加载速度。CDN(Content Delivery Network,内容分发网络)能够将游戏的静态资源分布到全球各地的边缘节点上,使用户可以从离他们最近的节点获取游戏资源…...

《重生到现代之从零开始的C语言生活》—— 字符函数和字符串函数
字符函数和字符串函数 字符分类函数 大家知道字符是分为很多种类型的 就比如说’a’ ‘1’ A’等等,所以我们需要一种函数来完成字符函数的分类 这就是字符分类函数 函数需要包含头文件<ctype.h> 函数的运行规则是:如果符合下列参数就返回真 …...

双指针:滑动窗口
题目描述 给定两个字符串 S 和 T,求 S 中包含 T 所有字符的最短连续子字符串的长度,同时要求时间复杂度不得超过 O(n)。 输入输出样例 输入是两个字符串 S 和 T,输出是一个 S 字符串的子串。样例如下: 在这个样例中,…...

云原生(四十八) | Nginx软件安装部署
文章目录 Nginx软件安装部署 一、Nginx软件部署步骤 二、安装与配置Nginx Nginx软件安装部署 一、Nginx软件部署步骤 第一步:安装 Nginx 软件 第二步:把 Nginx 服务添加到开机启动项 第三步:配置 Nginx 第四步:启动Nginx …...

【WPF开发】如何设置窗口背景颜色以及背景图片
在WPF中,可以通过设置窗口的 Background 属性来改变窗口的背景。以下是一些设置窗口背景的不同方法: 一、设置纯色背景 1、可以使用 SolidColorBrush 来设置窗口的背景为单一颜色。 <Window x:Class"YourNamespace.MainWindow"xmlns&quo…...
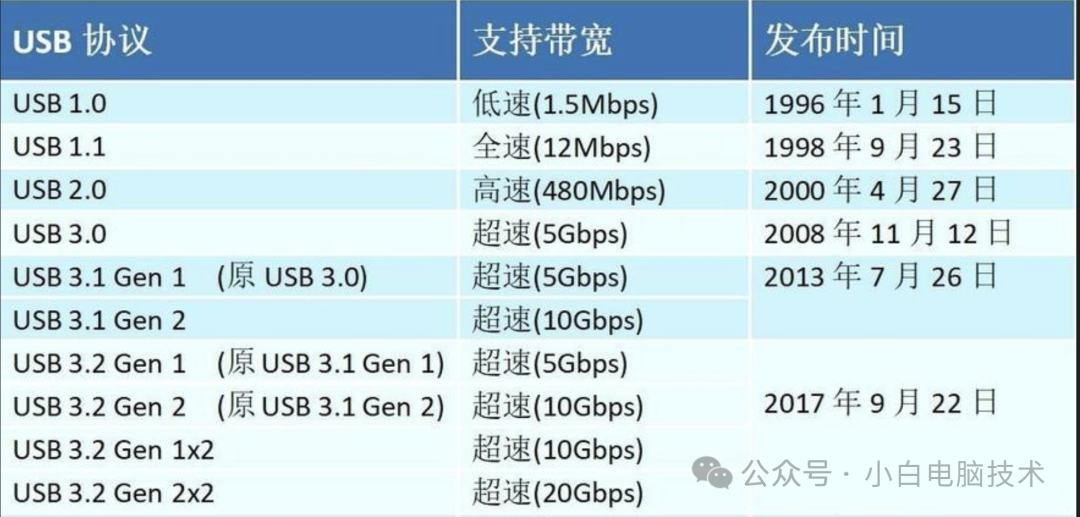
USB 3.0?USB 3.1?USB 3.2?怎么区分?
还记得小白刚接触电脑的时候,电脑普及的USB接口大部分是USB 2.0,还有少部分USB 1.0的(现在基本上找不到了)。 当时的电脑显示器,可能00后的小伙伴都没见过,它们大概长这样: 当时小白以为电脑最…...

Gitlab实战教程:打造企业级代码托管与协作平台!
目录 一、Gitlab概述1、Gitlab简介(1)Gitlab的定义(2)Gitlab与Git的关系(3)Gitlab的主要功能 2、Gitlab与Git的关系(1)Git的基本概念(2)Gitlab与Git的关联&am…...

更新C语言题目
1.以下程序输出结果是() int main() {int a 1, b 2, c 2, t;while (a < b < c) {t a;a b;b t;c--;}printf("%d %d %d", a, b, c); } 解析:a1 b2 c2 a<b 成立 ,等于一个真值1 1<2 执行循环体 t被赋值为1 a被赋值2 b赋值1 c-- c变成1 a<b 不成立…...

struct和C++的类
1.铺垫 1.1想看明白这章节,必须要懂得C语言的struct结构体、C语言深度解剖的static用法、理解声明与定义,C的类和static用法;否则看起来有些吃力 2.引子 2.1struct结构体里面只能存储内置类型;比如:char、short、 i…...

【数据结构与算法】LeetCode:图论
文章目录 LeetCode:图论岛屿数量(Hot 100)岛屿的最大面积腐烂的橘子(Hot 100)课程表(Hot 100) LeetCode:图论 岛屿数量(Hot 100) 岛屿数量 DFS: class So…...

YOLOv8 基于NCNN的安卓部署
YOLOv8 NCNN安卓部署 前两节我们依次介绍了基于YOLOv8的剪枝和蒸馏 本节将上一节得到的蒸馏模型导出NCNN,并部署到安卓。 NCNN 导出 YOLOv8项目中提供了NCNN导出的接口,但是这个模型放到ncnn-android-yolov8项目中你会发现更换模型后app会闪退。原因…...

【Python|接口自动化测试】使用requests发送http请求时添加headers
文章目录 1.前言2.HTTP请求头的作用3.在不添加headers时4.反爬虫是什么?5.在请求时添加headers 1.前言 本篇文章主要讲解如何使用requests请求时添加headers,为什么要加headers呢?是因为有些接口不添加headers时,请求会失败。 2…...

需求管理工具Jama Connect:与Jira/Slack/GitHub无缝集成,一站式解决复杂产品开发中的协作难题
在产品和软件开发的动态世界中,有效协作是成功的关键。然而,团队往往面临着阻碍进步和创新的重大挑战。了解这些挑战并找到强有力的解决方案,对于实现无缝、高效的团队协作至关重要。Jama Connect就是这样一种解决方案,它是一个功…...

LLMs 的新前沿:挑战、解决方案与工具
原文:towardsdatascience.com/the-new-frontiers-of-llms-challenges-solutions-and-tools-b1d48c34cf8e?sourcecollection_archive---------2-----------------------#2024-01-25 https://towardsdatascience.medium.com/?sourcepost_page---byline--b1d48c34cf8…...

Python股票数据查询工具:适配器模式与缓存策略实战
1. 项目概述:一个股票价格查询工具的核心价值最近在GitHub上看到一个挺有意思的项目,叫tjefferson/stock-price-query。光看名字,你可能会觉得这不就是个简单的数据抓取脚本吗?市面上类似的工具一抓一大把。但作为一个在金融数据和…...

GBFR Logs:游戏数据采集与实时分析引擎的架构深度解析
GBFR Logs:游戏数据采集与实时分析引擎的架构深度解析 【免费下载链接】gbfr-logs GBFR Logs lets you track damage statistics with a nice overlay DPS meter for Granblue Fantasy: Relink. 项目地址: https://gitcode.com/gh_mirrors/gb/gbfr-logs 在游…...

5分钟掌握MAA:解放双手的明日方舟智能助手终极指南
5分钟掌握MAA:解放双手的明日方舟智能助手终极指南 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https://gitcod…...

对比直接使用厂商API与通过Taotoken聚合调用的费用观感
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商API与通过Taotoken聚合调用的费用观感 1. 引言:成本感知的演变 在构建基于大模型的应用时࿰…...

Artisan烘焙软件:基于Python的开源咖啡烘焙控制与数据分析平台
Artisan烘焙软件:基于Python的开源咖啡烘焙控制与数据分析平台 【免费下载链接】artisan artisan: the worlds most trusted roasting software 项目地址: https://gitcode.com/gh_mirrors/ar/artisan Artisan是一款采用Python技术栈构建的开源咖啡烘焙控制软…...
TranslucentTB完全指南:轻松实现Windows任务栏透明化的终极方案
TranslucentTB完全指南:轻松实现Windows任务栏透明化的终极方案 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 想要让Window…...

27考研er必备的那些学习工具!
对2027考研人来说,备考不是简单地“埋头刷题”,而是一场关于信息筛选、资源整合、时间管理和学习效率的长期战役。面对公共课、专业课、院校信息、经验帖、课程资源等海量内容,选对工具往往能让复习少走弯路。 以下这些平台和网站,…...

点云配准避坑指南:从理论到代码,详解点到面ICP中法线计算的‘坑’与线性近似的前提
点云配准实战:深入解析点到面ICP算法中的法线计算与线性近似陷阱 在三维重建和机器人定位领域,点云配准技术扮演着关键角色。当我们面对两个部分重叠的点云数据集时,如何精确地将它们对齐成为一个统一坐标系下的完整模型?迭代最近…...

IC设计五大典型Bug剖析:从CDC到软硬件协同的防御性设计
1. 项目概述:IC设计中的那些“老朋友”在芯片设计的江湖里混迹多年,我越来越觉得,我们这些IC工程师(ICer)的日常,与其说是在创造,不如说是在与各种层出不穷的“老朋友”——也就是bug——斗智斗…...