BLOOM 模型的核心原理、局限与未来发展方向解析
1. 引言
1.1 BLOOM 模型概述
BLOOM(BigScience Large Open-science Open-access Multilingual Language Model)是一款由多个国际研究团队联合开发的大型语言模型。BLOOM 模型旨在通过先进的 Transformer 架构处理复杂的自然语言生成与理解任务。它支持多语言生成,能够处理多种文本任务,如文本生成、机器翻译、文本摘要等。BLOOM 的设计使其能够在各类任务中实现高效、自然的文本生成,并展现出卓越的性能。
BLOOM 是目前少数几款完全开源的大型语言模型之一,拥有超过 1760 亿个参数。这使得 BLOOM 成为开源社区重要的基础模型,广泛应用于研究和实际生产中。其支持包括英语、法语、西班牙语、阿拉伯语等 46 种语言,展现了极强的多语言处理能力。
1.2 BLOOM 系列模型的发展背景
随着深度学习和 Transformer 架构的不断进步,语言模型的规模和性能呈现指数级增长。大型语言模型(如 GPT-3、BERT 等)的出现标志着自然语言处理(NLP)技术进入了新的高度。BLOOM 系列模型在此背景下诞生,其目标是在保证高性能的同时,支持多语言任务,并通过开源和透明化为研究人员提供强大的研究工具。
BLOOM 的开发由 BigScience 项目发起,这一项目致力于在全球范围内推动开源科学,汇集了数千名研究人员的智慧,专注于大规模语言模型的开发。BLOOM 不仅继承了 Transformer 架构的核心优势,还在多语言处理、多模态任务等领域进行了创新,是目前 NLP 领域的重要开创性工作之一。
1.3 博客目的:解析 BLOOM 模型的核心原理
本博客的目的是详细解析 BLOOM 系列模型的核心原理,帮助读者理解其架构设计、关键技术以及训练方法。我们将深入探讨 BLOOM 模型在自然语言生成、理解任务中的优势,揭示其在多语言处理、多模态任务中的应用潜力。此外,博客还将讨论 BLOOM 的局限性和未来发展方向,为研究人员和开发者提供有价值的参考。
通过这篇博客,读者将能够更好地理解 BLOOM 模型的技术细节,掌握其在实际任务中的应用场景,并深入了解其未来的发展潜力。
2. BLOOM 模型架构概览
2.1 Transformer 架构在 BLOOM 模型中的应用
BLOOM 模型的核心架构基于 Transformer,这是目前大多数大型语言模型的基础。Transformer 架构以其高效的 自注意力机制(Self-Attention Mechanism) 和 并行处理能力 而著称,能够处理复杂的自然语言生成与理解任务。Transformer 通过并行处理整个输入序列,并使用自注意力机制捕捉输入中每个词与其他词之间的关系,无论它们在序列中的距离有多远。
在 BLOOM 模型中,Transformer 的多头自注意力机制用于生成每个词的上下文表示。模型通过多层堆叠的 Transformer 层,从输入序列中提取特征,并利用这些特征进行高质量的文本生成。BLOOM 还对 Transformer 架构进行了优化,使其能够处理多语言任务,在不同语言的语料上展现出极强的泛化能力。
2.2 BLOOM 模型与 GPT、BERT 等主流模型的对比
BLOOM 模型与其他流行的 Transformer-based 模型(如 GPT 和 BERT)在结构和设计理念上有一些相似性,但在处理任务和目标上存在显著区别。
-
自回归 vs. 自编码模型:
- BLOOM 与 GPT:与 GPT 类似,BLOOM 是一种 自回归语言模型(Auto-regressive Language Model),这意味着它通过条件生成下一个词的方式来逐步构建整个文本。BLOOM 模型擅长生成任务,包括文本生成、对话生成等。两者都使用了 Transformer 的解码器部分作为核心架构。
- BLOOM 与 BERT:BERT 是一种 自编码模型(Autoencoding Model),主要用于文本理解任务。BERT 使用双向 Transformer 架构,通过掩蔽部分输入来学习上下文语义,适合分类、问答、填空等任务。而 BLOOM 更专注于生成任务,采用的是自回归生成方式,不同于 BERT 的掩码语言建模。
-
任务多样性与多语言支持:
- 相比于 GPT 和 BERT,BLOOM 的独特优势在于其对多语言的广泛支持。BLOOM 被设计为处理 46 种语言,能够进行跨语言文本生成和理解,这使得它在全球化应用和多语言任务中有显著的优势。
- 另外,BLOOM 针对多模态任务和跨语言应用场景进行了优化,这使得它比 GPT 和 BERT 在语言生成任务上具备更多的定制化潜力,特别是在多语言生成和跨文化文本生成中。
-
模型规模与开放性:
- BLOOM 是一个开源的超大规模模型,具有与 GPT-3 类似的模型规模。相比 GPT 和 BERT 等闭源或部分开放的模型,BLOOM 提供了完整的开源代码和模型权重,允许研究人员和开发者深入研究其工作原理并进行微调。
- BLOOM 的参数规模接近 GPT-3,拥有 1760 亿个参数,足以支持复杂的语言生成任务。其开源特性为学术界和工业界提供了一个高度可扩展且透明的研究平台,区别于 GPT-3 的商业化限制。
2.3 BLOOM 模型的参数规模与设计理念
BLOOM 的设计理念不仅体现在其庞大的参数规模上,还包括其在多语言支持和透明性上的独特定位。BLOOM 通过其精心设计的架构和开放的训练方式,成为多语言自然语言生成领域的一个重要突破。
-
参数规模:
- BLOOM 具有超过 1760 亿个参数,与 GPT-3 属于同级别的超大规模语言模型。这一庞大的参数规模使得 BLOOM 能够捕捉到复杂的语言模式,并生成高质量的长文本。通过使用大规模并行训练和分布式计算,BLOOM 在多语言任务上的表现尤为突出。
- 为了适应不同的应用场景,BLOOM 还提供了多个版本的模型,从小型模型到超大规模模型,以便开发者根据具体的计算资源选择适合的版本进行使用。
-
多语言支持:
- BLOOM 的设计目标之一是提供对多种语言的强大支持。BLOOM 使用了覆盖广泛语言种类的多语言语料进行训练,旨在让模型在英语之外的其他语言(如法语、西班牙语、阿拉伯语、中文等)上也能保持出色的生成和理解能力。
- BLOOM 的训练数据来自多种语言和文化背景,确保了模型对多语言任务的适应性。这一点与 GPT-3 等主要在英语语料上训练的模型不同,使得 BLOOM 能够在跨文化和多语言生成任务中具备更高的泛化能力。
-
开放性与透明性:
- BLOOM 模型是完全开源的。开发者不仅可以获取模型的所有权重,还可以查看其训练代码和数据。这种透明性使得 BLOOM 成为研究者和开发人员的重要工具,可以用来研究大规模语言模型的行为和优化策略。
- 此外,BLOOM 的开发过程采用了协作式的全球化模式,由 BigScience 社区组织参与。这样的开放性设计促进了全球研究人员的参与,推动了开源语言模型的普及与发展。
BLOOM 模型基于 Transformer 架构,专注于自然语言生成任务。与 GPT 和 BERT 等主流模型相比,BLOOM 不仅拥有庞大的参数规模,还特别针对多语言和多模态任务进行了优化。其开源和透明的设计理念使其成为一个强大的研究工具和生产级应用平台,具备在全球化、多语言环境中的广泛应用潜力。通过在多语言支持、生成能力和开放性方面的突破,BLOOM 为大规模语言模型的研究与应用带来了新的可能。
3. BLOOM 模型的核心技术原理
BLOOM 模型是基于 Transformer 架构的大型语言模型,依托自回归生成、多头自注意力机制、前馈神经网络(FFN)与残差连接、以及位置编码与输入嵌入等技术,展现了强大的自然语言生成与理解能力。以下是这些核心技术原理的详细解析:
3.1 自回归生成机制
自回归生成机制 是 BLOOM 模型生成文本的核心原理。自回归模型通过逐步预测序列中的每个词,以生成完整的文本。具体来说,模型通过条件概率 ( P(x_t | x_1, x_2, …, x_{t-1}) ) 依次生成序列中的每个词,直到完成整个文本生成。
-
工作机制:
- BLOOM 模型从给定的输入(如起始词或句子)开始,通过预测下一个词来逐步构建序列。在每一步,模型根据前面的上下文(已生成的词)来生成当前词,直到生成出符合条件的文本或达到预设的文本长度。
- 这种生成方式使得模型能够基于上下文生成连贯的文本,适用于对话生成、文本续写等任务。
-
优势:
- 自回归生成允许 BLOOM 模型处理复杂的文本生成任务,并在生成过程中根据上下文逐步调整输出,提高生成文本的连贯性和语义一致性。
- 该机制特别适用于生成类任务,如文章撰写、对话生成和机器翻译。
3.2 多头自注意力机制详解
多头自注意力机制(Multi-Head Self-Attention) 是 Transformer 架构中的核心技术,BLOOM 模型通过这一机制来高效捕捉输入序列中的长距离依赖关系和语义关联。
-
自注意力机制原理:
- 自注意力机制通过为每个输入词生成查询(Query)、键(Key)和值(Value)向量,计算每个词与序列中其他词之间的相似度(相关性)。这些相似度通过加权求和生成新的词表示,从而捕捉句子中词与词之间的语义关系。
- 自注意力计算公式:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V \ Attention(Q, K, V) = softmax\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
其中 ( Q )、( K ) 和 ( V ) 分别代表查询、键和值向量,( d_k ) 是向量的维度。
-
多头自注意力:
- 在 BLOOM 模型中,多头自注意力 机制通过将注意力计算分为多个独立的头,每个头可以关注不同的语义模式或特征。通过这种方式,模型能够更全面地理解输入中的多层次信息。
- 多个注意力头的输出被拼接在一起,经过线性变换后形成最终的表示。这种多头机制极大增强了模型捕捉复杂语义结构的能力。
-
在 BLOOM 中的优化:
- BLOOM 模型在多头自注意力的实现中,通过高效的矩阵运算和并行计算优化了训练速度,使其能够处理更大规模的输入序列。此外,通过调整注意力头的数量和维度,BLOOM 模型能够灵活应对不同任务,保证生成质量。
3.3 前馈神经网络(FFN)与残差连接
前馈神经网络(Feed-Forward Neural Network, FFN) 和 残差连接(Residual Connections) 是 Transformer 中的另一个关键组件,负责非线性变换和深层网络的稳定训练。
-
前馈神经网络(FFN):
- BLOOM 模型中的每个 Transformer 层都包含一个前馈神经网络(FFN)。FFN 是一个逐词处理的全连接网络,用于对每个词的表示进行非线性变换,进一步提升模型的表达能力。FFN 结构为两层线性变换,中间通过非线性激活函数(如 ReLU)连接:
F F N ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 \ FFN(x) = max(0, xW_1 + b_1)W_2 + b_2 FFN(x)=max(0,xW1+b1)W2+b2 - 该机制能够为每个词生成更具表现力的语义表示,从而提升模型的生成质量。
- BLOOM 模型中的每个 Transformer 层都包含一个前馈神经网络(FFN)。FFN 是一个逐词处理的全连接网络,用于对每个词的表示进行非线性变换,进一步提升模型的表达能力。FFN 结构为两层线性变换,中间通过非线性激活函数(如 ReLU)连接:
-
残差连接与层归一化(Layer Normalization):
- 残差连接 通过将输入直接加入到输出,避免了深度网络中的梯度消失问题,确保模型能够稳定训练。这使得 BLOOM 模型即便在使用多层堆叠的 Transformer 时,依然能够保持梯度的有效传播。
- 层归一化 则用于在每层中规范输入和输出的分布,使得模型训练更加稳定。结合残差连接与层归一化,BLOOM 能够高效地进行大规模模型训练,并显著提升模型的生成性能。
3.4 位置编码与输入嵌入的实现
由于 Transformer 架构本质上没有内在的序列顺序信息,位置编码(Positional Encoding) 是 BLOOM 模型用来处理序列顺序的关键技术。通过位置编码,BLOOM 能够理解序列中各个词的位置关系,从而更好地处理自然语言的语法和语义结构。
-
位置编码的原理:
- 位置编码通过将位置信息(如词在句子中的顺序)注入到词的表示中,使得模型能够感知序列的顺序。BLOOM 使用类似正弦和余弦函数的周期性编码方式,为每个词的位置生成一个唯一的向量:
P E ( p o s , 2 i ) = s i n ( p o s 1000 0 2 i / d ) , P E ( p o s , 2 i + 1 ) = c o s ( p o s 1000 0 2 i / d ) \ PE_{(pos, 2i)} = sin\left(\frac{pos}{10000^{2i/d}}\right), \quad PE_{(pos, 2i+1)} = cos\left(\frac{pos}{10000^{2i/d}}\right) PE(pos,2i)=sin(100002i/dpos),PE(pos,2i+1)=cos(100002i/dpos) - 这种编码方式确保了词汇的相对位置信息得以保留,从而帮助模型在生成文本时,处理好顺序和结构的复杂性。
- 位置编码通过将位置信息(如词在句子中的顺序)注入到词的表示中,使得模型能够感知序列的顺序。BLOOM 使用类似正弦和余弦函数的周期性编码方式,为每个词的位置生成一个唯一的向量:
-
输入嵌入的实现:
- 输入嵌入(Embedding Layer) 是将输入的离散词汇映射到连续的高维空间中,生成词向量表示。BLOOM 通过嵌入层学习词汇的语义表示,这些词嵌入被输入到 Transformer 层中进行进一步的处理。
- 位置编码与输入嵌入的结合,帮助 BLOOM 在生成和理解自然语言时,不仅能够处理词汇的语义,还能准确掌握句子结构和词序信息。
BLOOM 模型通过自回归生成、多头自注意力、前馈神经网络与残差连接、以及位置编码与输入嵌入等关键技术,构建了一个强大的自然语言处理系统。自回归生成机制赋予了模型强大的文本生成能力,多头自注意力增强了对复杂语义的捕捉能力,而前馈神经网络和残差连接确保了模型的深度训练稳定性。位置编码则让模型能够处理序列中的位置关系,确保文本生成的连贯性和逻辑性。这些技术共同构成了 BLOOM 的核心,支持其在多语言和多任务场景中取得卓越的表现。
4. BLOOM 模型的训练过程
BLOOM 模型的训练过程分为两个主要阶段:预训练阶段 和 微调阶段。在预训练阶段,BLOOM 通过大规模语料库进行无监督学习,掌握广泛的语言模式;而在微调阶段,模型根据具体任务进行精细调优,以提高特定领域的表现。以下详细介绍这两个关键训练阶段及其在不同任务中的应用效果。
4.1 预训练阶段:大规模语料学习
预训练阶段 是 BLOOM 模型建立其基础语言理解能力的关键。在这一阶段,模型通过大规模的无监督数据进行训练,学习语言的语法、语义结构及其广泛的上下文关系。
-
数据集的选择与多语言学习:
- BLOOM 模型的预训练依赖于覆盖广泛语言的语料库,涵盖 46 种语言,包括英语、法语、西班牙语、阿拉伯语、中文等。这些语料库来源多样,如新闻文章、书籍、社交媒体内容、维基百科等,确保模型能处理多种语言和语境下的文本生成任务。
- 多语言语料的使用,使得 BLOOM 在语言生成任务中不仅擅长处理英语,还能有效地处理其他语言,尤其在全球化任务中具有独特优势。
-
自回归语言模型训练目标:
- 与 GPT 模型类似,BLOOM 采用了自回归语言模型(Auto-regressive Language Model)的训练目标。该目标通过最大化每个词出现的条件概率来进行训练,即基于序列中前面的词来预测下一个词。通过这种方式,BLOOM 学习到如何根据上下文生成连贯的文本。
- 这一过程让模型能够掌握复杂的语言模式,无需人工标注,通过无监督学习获取广泛的语言知识。
-
训练过程中的技术优化:
- 在预训练阶段,BLOOM 采用了 混合精度训练(如使用 FP16),显著加快了模型的训练速度并减少了显存占用。
- 为了加速训练,BLOOM 使用了大规模并行计算和分布式训练策略,多个 GPU 或 TPU 节点共同参与模型的训练过程。这种技术确保了模型能够处理超大规模的数据集并显著缩短训练时间。
4.2 微调阶段:任务适应与模型精调
微调阶段(Fine-tuning) 是 BLOOM 模型从通用语言模型转化为任务特定模型的关键步骤。在这一阶段,模型会根据特定任务或领域的数据进行训练,使其能够更好地适应具体的任务需求,如情感分析、问答系统、文本分类等。
-
微调数据集与有监督训练目标:
- 微调阶段通常使用有监督数据集,数据集中包含特定任务的输入输出对。对于每个任务,BLOOM 模型在微调过程中会根据任务目标调整权重,例如对于文本分类任务,目标是根据输入文本预测正确的类别;对于问答系统,目标是根据问题生成合适的答案。
- 微调数据集可以是领域特定的,如金融报告、医学文献、法律文档等,通过这些专业数据集,BLOOM 能够学习到行业特定的语言模式,并在专业领域内生成高质量的文本。
-
微调技术的应用:
- 冻结层技术(Layer Freezing):为了加快微调过程并防止模型过拟合,BLOOM 允许冻结部分 Transformer 层,只对模型的部分参数进行调整。这样可以保持模型的通用语言知识,专注于任务特定的部分。
- 少样本微调(Few-shot Learning):BLOOM 还可以通过少量标注数据进行微调,尤其在任务数据有限的情况下,少样本学习能帮助模型快速适应新任务,节省了大量数据标注成本。
-
微调后的性能优化:
- 微调阶段通过调整模型权重,使其在特定任务上表现更好。对于生成任务,BLOOM 通过调节生成策略(如 Beam Search、贪婪搜索等),能够提高生成文本的连贯性和准确度。
4.3 BLOOM 模型在不同领域任务中的应用效果
通过预训练与微调相结合,BLOOM 模型能够适应广泛的应用场景,特别是在文本生成和理解类任务中展现了优异的性能。以下是 BLOOM 模型在不同领域中的典型应用:
-
自然语言生成任务:
- 对话生成:BLOOM 模型在开放域对话系统中表现出色,能够生成流畅、连贯的对话回复。通过微调对话数据集,BLOOM 能够根据上下文生成个性化、符合语境的回答,适合智能客服和聊天机器人等应用场景。
- 文本创作:在文本生成任务中,BLOOM 模型能够根据提示生成长篇文章、技术文档、新闻稿等。它的自回归生成机制让模型可以逐字逐句地生成符合上下文逻辑的文本,应用于自动化内容创作和报告撰写等任务。
-
跨语言生成与翻译:
- 由于 BLOOM 模型的多语言预训练能力,它在多语言文本生成和机器翻译任务中也表现优异。BLOOM 能够处理跨语言任务,例如将一段文本从一种语言翻译成另一种语言,并且能够生成符合目标语言语法和表达习惯的自然语言文本。
- 此外,BLOOM 还可以在多语言任务中生成双语内容,适用于多语言对话系统、跨语言文章生成等应用场景。
-
专业领域的定制化应用:
- 医疗领域:通过微调医学文献和诊断报告,BLOOM 模型可以生成符合医学标准的诊断建议和报告。这使得模型在医疗智能助手、电子病历自动生成等场景中具有广泛应用。
- 法律领域:BLOOM 模型能够生成法律意见书、合同文本等法律文档,通过定制化的微调,模型能够处理复杂的法律术语,并生成符合法律逻辑的文本。这在法律文档自动生成、合同撰写辅助等场景中发挥重要作用。
- 金融领域:BLOOM 通过微调财务报表、市场分析数据等金融领域数据,能够生成精准的财务分析报告、投资建议,帮助金融从业者提高工作效率。
BLOOM 模型的训练过程通过大规模预训练阶段和针对特定任务的微调阶段相结合,展示了其在多语言文本生成、跨语言任务、以及专业领域中的广泛适应性。预训练阶段赋予了模型强大的语言理解能力,而微调阶段则使其能够快速适应具体任务需求,并生成高质量的文本。BLOOM 的多语言支持和灵活的微调机制,使其在多个行业中的应用效果显著,推动了自然语言处理的进步。
5. BLOOM 的优化技术
为了使 BLOOM 模型在保持高性能的同时,能够更高效地利用计算资源和适应不同场景需求,BLOOM 模型采用了多种优化技术。这些技术包括 模型压缩与参数共享、混合精度训练与高效推理、以及 并行计算与分布式训练优化。这些技术在大规模模型中发挥了关键作用,使得 BLOOM 能够高效处理多语言任务,并减少计算资源消耗。
5.1 模型压缩与参数共享技术
模型压缩 和 参数共享 技术是为了减少模型的存储需求、加快推理速度,同时保证模型的性能不会显著下降。这些技术使得 BLOOM 模型能够在资源有限的环境中进行更高效的推理与部署。
-
权重剪枝(Weight Pruning):
- 权重剪枝 是一种通过去除模型中对最终输出影响较小的参数(权重)来减少模型体积的技术。在 BLOOM 中,剪枝技术移除了冗余的连接和参数,从而减少了模型的计算量和存储需求。剪枝后的模型能够以更少的计算资源实现与原始模型相近的性能。
- 这种技术在训练后应用,通过分析哪些权重对模型输出贡献较小来进行剪枝。
-
量化(Quantization):
- 量化 技术将模型的权重从高精度(如 32 位浮点数,FP32)降低到低精度(如 16 位或 8 位),从而减少内存占用并加快推理速度。BLOOM 通过使用动态量化和静态量化,在推理阶段显著减少了计算复杂度。
- 通过量化,BLOOM 在不显著降低生成质量的情况下,能够以更高效的方式运行,适合低计算能力的设备或移动端部署。
-
参数共享:
- 在 BLOOM 模型的不同层之间,部分参数得到了共享,这大大减少了模型的整体参数规模。通过共享部分层的权重,模型能够在保证生成质量的前提下,减少存储和计算资源需求。这种技术不仅提高了推理效率,还增强了模型的泛化能力。
-
知识蒸馏(Knowledge Distillation):
- 知识蒸馏 是通过将大模型(教师模型)中的知识传递给小模型(学生模型),使小模型在保持高效推理的同时也能具备较高性能。BLOOM 的蒸馏过程生成了较小的版本,使得在资源有限的场景中也能部署具备较好性能的模型。
5.2 混合精度训练与高效推理
混合精度训练 和 高效推理 是加速模型训练过程以及提高推理效率的重要手段,特别是在大规模模型中,它们显著提升了模型的资源利用率和运行效率。
-
混合精度训练(Mixed Precision Training):
- 在 BLOOM 的训练过程中,使用了 混合精度训练 技术,即通过使用 16 位浮点数(FP16)与 32 位浮点数(FP32)进行混合计算。具体来说,前向传播和反向传播中的大部分计算使用 FP16 来减少显存占用,而梯度计算和参数更新使用 FP32 确保数值稳定性。
- 这种方式显著提升了模型训练速度,并减少了显存需求。混合精度训练尤其适合大规模模型,在多个 GPU 上并行处理时能够最大化硬件利用率。
# 使用 PyTorch 实现混合精度训练 scaler = torch.cuda.amp.GradScaler()for input, target in dataloader:optimizer.zero_grad()with torch.cuda.amp.autocast():output = model(input)loss = loss_fn(output, target)scaler.scale(loss).backward()scaler.step(optimizer)scaler.update() -
FP16 推理:
- 在推理阶段,BLOOM 通过使用 16 位浮点数(FP16)推理,大大加快了推理速度并减少了显存占用。FP16 推理对推理性能提升显著,尤其是在实时性要求较高的任务中(如对话生成和在线文本生成),能够提供快速的响应。
-
批处理推理(Batch Inference):
- BLOOM 支持批处理推理,通过同时处理多个输入数据,充分利用 GPU 或 TPU 的计算资源。这种方式适用于大规模文本生成、机器翻译等需要同时处理大量请求的应用场景,能够显著提高处理吞吐量。
5.3 并行计算与分布式训练优化
随着模型规模的增加,单个设备无法满足模型的计算和存储需求。因此,并行计算 和 分布式训练 技术被广泛应用于 BLOOM 模型的训练与推理过程中,使其能够在多个设备上高效运行。
-
数据并行(Data Parallelism):
- 在数据并行模式下,BLOOM 的训练数据被分割成多个小批次,由不同的 GPU 或 TPU 并行处理。每个设备独立计算一个小批次的数据,并在每一轮后同步更新全局模型的梯度。这种方式能够充分利用多个计算设备的计算资源,加速模型的训练过程。
# 使用 PyTorch 数据并行 model = torch.nn.DataParallel(model) output = model(input_data) -
模型并行(Model Parallelism):
- 对于超大规模模型,单个 GPU 无法存储整个模型的参数。BLOOM 通过 模型并行,将模型的不同部分(如不同的 Transformer 层或注意力头)分配到不同的 GPU 上进行计算。这种方式允许模型的每一部分在不同设备上并行处理,从而分担存储和计算负担。
-
分布式数据并行(Distributed Data Parallel, DDP):
- 分布式数据并行(DDP) 是数据并行的扩展,适用于多台机器协同工作的场景。在 DDP 模式下,BLOOM 模型的多个副本分布在不同的计算节点上,每个节点独立计算一部分数据,并通过高效的通信机制同步梯度。
- DDP 是大规模集群训练 BLOOM 的核心技术,能够显著加快训练速度,尤其适合数百亿甚至数千亿参数规模的模型。
-
张量并行(Tensor Parallelism):
- 张量并行 是将模型中的大张量(如注意力矩阵)划分到不同的 GPU 上进行并行计算的技术。这种技术在处理大规模 Transformer 模型时非常有效,能够显著减少单个设备的内存压力,并提高并行处理效率。
-
分层并行(Pipeline Parallelism):
- 分层并行 是将模型的不同层分配到不同的设备上,以并行处理不同层的计算任务。在 BLOOM 模型中,这种技术可以帮助更好地分配计算资源,特别是在处理极大规模的多层 Transformer 时,有助于减少层与层之间的计算瓶颈。
BLOOM 模型通过采用 模型压缩与参数共享、混合精度训练与高效推理、并行计算与分布式训练优化 等技术,极大提高了模型的训练和推理效率。这些优化技术帮助 BLOOM 在处理大规模多语言任务时,能够在性能与资源消耗之间取得平衡。通过这些技术,BLOOM 不仅能够应对超大规模计算任务,还能够适应资源受限的环境,并在实际应用中展现出极高的扩展性和灵活性。
6. BLOOM 模型的应用场景
BLOOM 模型因其强大的自然语言生成和理解能力,广泛应用于多种任务,特别是在处理多语言任务、文本生成、专业文档撰写以及行业定制化应用方面具有显著优势。以下是 BLOOM 模型在不同应用场景中的表现和应用实例。
6.1 自然语言处理任务中的表现
BLOOM 模型在自然语言处理(NLP)任务中的表现尤为突出,能够处理复杂的语言生成与理解任务,广泛应用于机器翻译、文本生成、问答系统等任务。
-
文本生成:
- BLOOM 模型利用自回归生成机制能够生成连贯、自然的长文本。无论是博客文章、新闻报道,还是创意写作,BLOOM 都能够基于上下文生成符合语法的文本。在内容创作、自动化写作等任务中,BLOOM 模型展现了极高的文本生成能力,适合自动生成新闻、技术文档、广告文案等任务。
-
机器翻译:
- BLOOM 支持多语言训练,因此在多语言机器翻译任务中具有显著优势。BLOOM 可以实现多语言之间的翻译,生成的翻译内容准确流畅,尤其在处理少见语言和复杂语言结构时表现突出。BLOOM 模型为多语言对话系统、跨语言沟通提供了技术支撑。
-
问答系统:
- 在问答任务中,BLOOM 通过微调,能够高效理解用户的问题并生成合适的答案。基于其强大的上下文理解能力,BLOOM 能够处理复杂的开放域问答,并在实际应用中用于智能客服、虚拟助手等系统中。
-
文本摘要:
- BLOOM 模型通过理解输入文本的语义结构,能够生成简明扼要的摘要。这一功能在自动化报告生成、文献摘要、新闻摘要等任务中广泛应用,帮助用户快速获取关键信息。
6.2 专业文本生成与自动化文档编写
除了常见的自然语言生成任务,BLOOM 模型还被广泛应用于专业文本生成和自动化文档编写,尤其是在需要生成结构化、逻辑清晰的专业文档的场景中具有重要作用。
-
法律文书生成:
- BLOOM 通过微调法律领域的数据集,能够生成法律意见书、合同、判决文书等专业文本。在法律从业者的辅助工作中,BLOOM 通过快速生成法律文档,减少了手工撰写文书的工作量,极大提高了文档撰写效率。
- 在法律助理或合同生成工具中,BLOOM 模型提供了法律条款的自动补全功能,确保生成文档符合法律规范和逻辑结构。
-
财务报告与市场分析生成:
- BLOOM 模型在金融领域的应用体现在财务报告、市场分析报告等文本的生成上。通过微调金融数据,BLOOM 能够自动化生成财务分析报告、投资建议等结构化文档,帮助分析师快速生成市场洞察。
- 自动化文档生成还减少了手动编写报告的时间,尤其在定期报告、预算分析等领域,BLOOM 能够自动填充数据并生成标准化的报告文本。
-
技术文档编写:
- BLOOM 在技术文档生成方面也具有广泛应用。它能够根据输入的技术规范、用户需求生成完整的产品文档、用户手册等。特别是在软件开发、产品开发等领域,BLOOM 的生成能力能够帮助技术团队快速编写符合行业标准的文档,减少了手工编写文档的负担。
-
学术论文与文献综述:
- BLOOM 在学术研究领域可以应用于生成学术论文的初稿、文献综述或研究报告。通过微调学术领域的数据,BLOOM 可以帮助研究人员生成论文框架、补充相关文献内容,使研究人员能够更专注于创新内容的撰写。
6.3 专业领域的定制化应用(如医疗、法律、金融等)
BLOOM 模型的灵活性和定制化能力使其在多个专业领域中展现了巨大的潜力,尤其是在医疗、法律和金融等需要高精度、高专业性的场景中,通过微调实现行业特定的应用。
-
医疗领域的应用:
- 诊断报告生成:在医疗领域,BLOOM 模型通过定制化微调,能够生成病历报告、诊断建议等专业文档。医生可以根据输入的病症描述自动生成详细的诊断报告,帮助医生在日常诊断中减少重复工作,提高工作效率。
- 医学知识问答系统:BLOOM 可以作为医学助手,回答复杂的医疗问题。通过结合医疗文献和病例数据,模型能够提供准确的医学建议,在医疗问答系统、健康顾问等场景中提供支持。
-
法律领域的应用:
- 法律合同生成与分析:BLOOM 在法律领域的应用涵盖了自动化合同生成、法律文本分析等任务。通过法律文献、判例的微调训练,BLOOM 能够生成符合法律规范的合同文本,并进行法律条款的解释与分析,帮助律师快速处理文书工作。
- 法律意见撰写:BLOOM 模型还能够在法律咨询中生成详细的法律意见书,提供法律建议。这在诉讼文件准备和合同审查中尤为重要,帮助法律从业人员提升效率。
-
金融领域的应用:
- 财务分析报告生成:BLOOM 模型通过在金融领域的数据集上微调,可以自动化生成财务分析报告、财务预测、市场分析等内容,帮助金融分析师快速撰写定期报告。
- 投资建议生成:BLOOM 还可以基于市场数据、投资组合生成个性化的投资建议,帮助投资顾问在金融咨询中提升工作效率。
-
科研与教育领域:
- 自动化研究报告生成:BLOOM 能够根据研究数据和背景资料自动生成研究报告和文献综述。这一功能在学术界和科研机构具有重要应用,减少了研究人员的初期写作负担,使其能够专注于核心科研工作。
- 教育内容生成:在教育领域,BLOOM 可以生成个性化的学习资料、考试题目,帮助教师提供针对学生需求的教学内容。
BLOOM 模型凭借其强大的自然语言生成能力和灵活的微调机制,广泛应用于自然语言处理、自动化文本生成以及专业领域的定制化应用。在自然语言处理任务中,BLOOM 具备多语言处理和文本生成的优势;在专业领域中,BLOOM 通过微调数据,能够生成高质量的专业文档,在法律、医疗、金融等领域展现出显著的应用价值。BLOOM 模型的灵活性和扩展性为其在未来的应用场景中提供了巨大的发展潜力。
7. BLOOM 模型的局限性与挑战
尽管 BLOOM 模型在自然语言处理领域展现了出色的能力,但它仍面临一些技术挑战和局限性。随着模型规模的增加和任务复杂度的提升,BLOOM 模型在长序列生成、一致性、计算资源、偏差与伦理等方面存在需要克服的问题。
7.1 长序列生成中的一致性问题
1. 上下文记忆衰减:
- BLOOM 基于自回归生成机制,这意味着每一步的输出依赖于前面生成的词语。然而,当模型生成长序列文本时,随着生成长度的增加,模型对远距离上下文的记忆能力逐渐减弱,导致生成的文本在逻辑性和一致性上可能出现问题。
- 特别是在处理复杂长文本(如小说、长篇文章)或长时间的对话生成时,模型可能会偏离主题或出现重复内容。
2. 文本重复与偏离主题:
- 在长文本生成中,BLOOM 模型有时会生成重复的词语或句子,或者偏离初始的主题。这是因为在长序列中,模型对前文的依赖减弱,无法保持上下文连贯性,生成质量下降。这种现象在开放式对话、文本续写等任务中尤其明显。
3. 解决方案:
- 外部记忆机制:可以引入外部记忆机制(如 Transformer-XL、Retrieval-Augmented Generation)来增强模型对长序列的记忆。外部记忆通过存储和检索前文上下文,帮助模型在生成过程中保持上下文的连贯性。
- 分段生成与回顾机制:另一种方法是将文本分段生成,每生成一段后回顾之前的内容,从而确保整体逻辑一致。这种策略适用于长文本生成和多轮对话系统。
7.2 模型规模与计算资源的权衡
1. 大规模模型的资源消耗:
- BLOOM 模型的参数规模非常庞大(超过 1760 亿个参数),这使得模型的训练和推理需要消耗大量的计算资源。大规模模型在硬件要求、计算速度和内存占用上都面临极大的挑战,尤其是在进行多语言、多任务处理时,对 GPU 和 TPU 的需求非常高。
- 对于中小型企业或资源有限的开发者来说,训练和运行 BLOOM 这样的大规模模型的成本较高,可能难以负担。
2. 训练时间与成本:
- 在超大规模的 BLOOM 模型上,训练时间和计算成本是一个重要的瓶颈。模型的训练需要数周甚至数月的时间,并且需要大量高性能计算设备。即使在完成训练后,推理过程也可能受到模型规模的限制,推理速度较慢,尤其在实时系统中面临挑战。
3. 解决方案:
- 模型压缩与蒸馏:通过知识蒸馏、模型剪枝和量化等技术,BLOOM 模型可以在保证生成质量的同时,减少模型的参数规模,降低计算资源需求。这些技术可以帮助模型在小型设备或移动端部署时依然保持良好的性能。
- 异构计算与分布式训练:分布式训练和异构计算(结合 CPU、GPU、TPU)是处理超大规模模型的有效方式。通过将模型的计算任务分配给多个设备,并在云计算平台上进行训练,能够显著加快训练速度并提高资源利用率。
7.3 模型偏差与伦理问题
1. 数据偏差带来的生成偏差:
- BLOOM 模型的训练依赖于大量的多语言语料库,而这些语料库中可能存在某些社会偏见、刻板印象或不准确的信息。模型通过学习这些数据,可能在生成文本时反映出这些偏差。例如,生成内容中可能出现性别、种族、文化等方面的偏见。
- 这些偏见不仅会影响模型生成的公平性,还可能对实际应用造成不良影响,特别是在医疗、法律等敏感领域使用时,可能带来伦理和法律问题。
2. 生成有害或不道德内容:
- BLOOM 模型具备强大的生成能力,但这种能力也带来了潜在的滥用风险。模型可能会生成虚假信息、仇恨言论、虚假新闻或误导性内容,尤其是在未经过滤的开放性任务中。如果不加以控制,模型可能被恶意使用,传播不道德或违法内容。
3. 隐私与数据安全:
- BLOOM 模型在训练过程中使用的大规模语料可能包含敏感的个人数据,尽管模型生成的文本通常是新颖的,但仍可能在特定场景中生成与训练数据相关的敏感信息,导致隐私泄露问题。
4. 解决方案:
- 数据去偏技术:在数据预处理阶段,采用去偏算法清除训练数据中的偏见信息,并通过多样化数据源增强模型的公平性。同时可以使用策略来检测和过滤生成过程中可能含有偏见的内容。
- 内容审查与道德过滤:在实际应用中,结合内容审查机制和道德过滤器,可以帮助监控和过滤生成的内容,防止有害或不当的文本输出。这对于社交媒体、新闻生成、对话系统等公共应用至关重要。
- 隐私保护技术:为了保护个人隐私,可以通过差分隐私等技术来确保模型在训练和推理过程中不泄露用户的个人信息。此外,使用加密技术可以在模型应用中提高数据安全性。
BLOOM 模型在自然语言处理任务中表现出强大的生成能力,但在长序列生成一致性、计算资源消耗、以及偏见和伦理问题方面面临挑战。通过引入外部记忆机制、模型压缩与蒸馏、数据去偏、内容过滤等技术手段,可以有效改善这些问题,提升模型的实际应用价值。在进一步优化这些挑战的同时,BLOOM 模型有望在未来更多场景中发挥更大的作用。
8. BLOOM 模型的未来发展方向
BLOOM 模型作为一个多语言和多任务的大型语言模型,具备广泛的应用潜力。然而,随着技术的进步和应用需求的增加,BLOOM 模型在模型优化、跨模态任务、多语言扩展以及社区贡献和定制化发展方面仍有广阔的发展空间。
8.1 模型优化与效率提升
尽管 BLOOM 已经采用了一些优化技术(如混合精度训练、并行计算等),但未来在提升模型效率和优化资源使用方面仍有许多可探索的方向。
-
进一步的模型压缩与剪枝:
- 模型压缩与剪枝 将是未来提升模型效率的一个关键领域。通过更智能的剪枝技术,BLOOM 可以去除对生成效果影响较小的冗余参数,显著减少计算资源的需求,降低存储和推理成本。这将使得 BLOOM 模型更适合部署在资源有限的环境中,如移动设备或边缘计算节点。
-
基于领域的知识蒸馏:
- 知识蒸馏 已经是大规模语言模型压缩的主流方法之一,但未来可以探索基于领域的知识蒸馏,针对特定任务领域(如医疗、法律)优化学生模型。通过从 BLOOM 这样的超大规模模型中蒸馏出更小、更轻的领域特定模型,既能保持高效生成能力,又能显著提高推理速度,降低计算成本。
-
自适应推理与实时优化:
- 自适应推理技术可以根据输入文本的复杂度动态调整计算量。未来,BLOOM 模型可以结合自适应推理,实时决定每个推理步骤的计算深度,从而在不影响生成质量的情况下加快推理速度,特别适用于对实时性要求较高的任务(如对话系统、实时翻译等)。
-
异构计算与分布式推理:
- 未来,BLOOM 模型的训练和推理可以进一步借助 异构计算,结合 CPU、GPU、TPU 等不同计算资源,提高计算效率。通过分布式推理架构,可以进一步优化模型在大型集群中的推理性能,适应更大规模的部署需求。
8.2 跨模态任务与多语言扩展
随着自然语言处理(NLP)领域的快速发展,未来的语言模型不仅需要处理文本数据,还需具备处理多模态任务的能力。同时,扩展多语言支持也将是 BLOOM 模型未来的重要方向。
-
跨模态任务的扩展:
- 文本-图像生成与多模态任务:随着跨模态技术的兴起,BLOOM 可以进一步整合其他模态(如图像、语音),处理文本与图像生成、语音识别与生成等任务。未来,BLOOM 模型可以通过结合图像生成模型(如 DALL·E)和语音模型(如 TTS、ASR),为多模态任务(如图文生成、视频字幕生成)提供强大的技术支持。
- 图像描述与生成:BLOOM 可以扩展到图像描述任务中,生成高质量的文本描述;此外,它还可以结合现有的图像生成技术,推动图像与文本之间的双向生成,适用于视觉与语言结合的应用场景。
-
多语言支持的进一步扩展:
- BLOOM 模型已经支持多语言生成,但未来的扩展方向包括更多的小语种支持和跨语言迁移学习。通过进一步增加多语言语料的覆盖面,BLOOM 可以提高对小语种和低资源语言的生成质量,扩大其全球化应用的范围。
- 零样本和少样本学习:未来,BLOOM 可以在低资源语言上进一步提升 零样本学习 和 少样本学习 能力,通过学习更多语言之间的关联,让模型能够在缺乏标注数据的情况下执行高质量的语言生成任务。
-
跨语言迁移学习:
- 跨语言迁移学习能够让模型在高资源语言(如英语)的知识基础上,迁移到低资源语言上。这种迁移学习机制可以帮助 BLOOM 在小语种上取得更好的生成效果,特别是在跨语言任务中(如机器翻译、跨语言文本生成),具有重要的应用前景。
8.3 社区贡献与定制化发展
作为一个完全开源的模型,BLOOM 的未来发展离不开开源社区的支持与贡献。社区的合作和定制化发展将进一步推动 BLOOM 模型的技术进步和广泛应用。
-
开源社区的合作与贡献:
- BLOOM 作为开源项目,其模型权重和训练代码对外开放,吸引了全球开发者和研究人员的参与。未来,BLOOM 模型的发展将进一步依赖社区的贡献,特别是在模型优化、领域定制、和多语言支持方面。
- 开源社区可以通过贡献新的任务数据集、提出改进的算法、分享微调成果等方式,不断推动 BLOOM 模型的技术迭代。此外,社区的开放合作将帮助发现并解决模型在应用中的局限性。
-
领域定制与自动化微调工具:
- BLOOM 模型未来的一个重要方向是为不同行业和领域提供定制化的解决方案。通过提供领域特定的微调工具,用户可以轻松对模型进行定制,以适应特定任务需求(如医疗诊断、法律文本生成、金融分析等)。
- 自动化微调工具:开发自动化的微调工具将是未来的一个重要目标。这些工具可以帮助开发者无缝地对 BLOOM 进行任务定制,即便没有深厚的深度学习知识,用户也能快速应用 BLOOM 模型完成任务。
-
伦理与去偏机制的发展:
- 随着 BLOOM 模型的广泛应用,模型偏见和伦理问题也成为一个重要关注点。未来,BLOOM 模型的发展需要加强去偏机制和伦理审查工具,确保生成内容的公平性和伦理合规性。
- 通过社区合作,开发者可以贡献更多的去偏算法和数据去偏技术,帮助 BLOOM 在各类应用场景中减少偏见和不当内容的生成,推动 AI 技术的社会责任感。
-
隐私保护与安全性增强:
- BLOOM 模型未来的发展还需要更加关注数据隐私和安全性问题。通过引入 差分隐私 和 安全训练机制,BLOOM 模型可以在保护用户隐私的前提下,安全地执行各类生成任务。
- 另外,未来的 BLOOM 版本可以集成更强的内容安全审查机制,确保模型不会被恶意使用来生成虚假信息或违法内容。
BLOOM 模型未来的发展方向涵盖 模型优化与效率提升、跨模态任务与多语言扩展、以及 社区贡献与定制化发展 等方面。通过不断改进压缩技术、提升推理效率、扩展跨模态与多语言能力,以及依托开源社区的力量,BLOOM 模型有望在更广泛的应用场景中发挥重要作用。同时,随着领域定制化、去偏与伦理技术的不断完善,BLOOM 模型将成为一个更加高效、智能、可靠的自然语言处理工具,推动 AI 技术在全球范围内的创新和发展。
相关文章:

BLOOM 模型的核心原理、局限与未来发展方向解析
1. 引言 1.1 BLOOM 模型概述 BLOOM(BigScience Large Open-science Open-access Multilingual Language Model)是一款由多个国际研究团队联合开发的大型语言模型。BLOOM 模型旨在通过先进的 Transformer 架构处理复杂的自然语言生成与理解任务。它支持…...

Kubernetes 深度洞察:重新认识 Docker 容器的奇妙世界
《Kubernetes 深度洞察:重新认识 Docker 容器的奇妙世界》 在 Kubernetes 的学习进程中,对 Docker 容器的深入理解至关重要。这一节,我们将重新认识 Docker 容器,探索其在 Kubernetes 生态系统中的关键作用。 一、Docker 容器的基本概念 Docker 容器是一种轻量级的虚拟化…...

柔性作业车间调度(FJSP)
1.1 调度问题的研究背景 生产调度是指针对一项可分解的工作(如产品制造),在尽可能满足工艺路线、资源情况、交货期等约束条件的前提下,通过下达生产指令,安排其组成部分(操作)所使用的资源、加工时间及加工的先后顺序,以获得产品制造时间或成本最优化的一项工作。 一般研究车间…...

速盾:游戏用CDN可以吗?
游戏用CDN是一种常见的解决方案,可以提高游戏的网络性能和加载速度。CDN(Content Delivery Network,内容分发网络)能够将游戏的静态资源分布到全球各地的边缘节点上,使用户可以从离他们最近的节点获取游戏资源…...

《重生到现代之从零开始的C语言生活》—— 字符函数和字符串函数
字符函数和字符串函数 字符分类函数 大家知道字符是分为很多种类型的 就比如说’a’ ‘1’ A’等等,所以我们需要一种函数来完成字符函数的分类 这就是字符分类函数 函数需要包含头文件<ctype.h> 函数的运行规则是:如果符合下列参数就返回真 …...

双指针:滑动窗口
题目描述 给定两个字符串 S 和 T,求 S 中包含 T 所有字符的最短连续子字符串的长度,同时要求时间复杂度不得超过 O(n)。 输入输出样例 输入是两个字符串 S 和 T,输出是一个 S 字符串的子串。样例如下: 在这个样例中,…...

云原生(四十八) | Nginx软件安装部署
文章目录 Nginx软件安装部署 一、Nginx软件部署步骤 二、安装与配置Nginx Nginx软件安装部署 一、Nginx软件部署步骤 第一步:安装 Nginx 软件 第二步:把 Nginx 服务添加到开机启动项 第三步:配置 Nginx 第四步:启动Nginx …...

【WPF开发】如何设置窗口背景颜色以及背景图片
在WPF中,可以通过设置窗口的 Background 属性来改变窗口的背景。以下是一些设置窗口背景的不同方法: 一、设置纯色背景 1、可以使用 SolidColorBrush 来设置窗口的背景为单一颜色。 <Window x:Class"YourNamespace.MainWindow"xmlns&quo…...
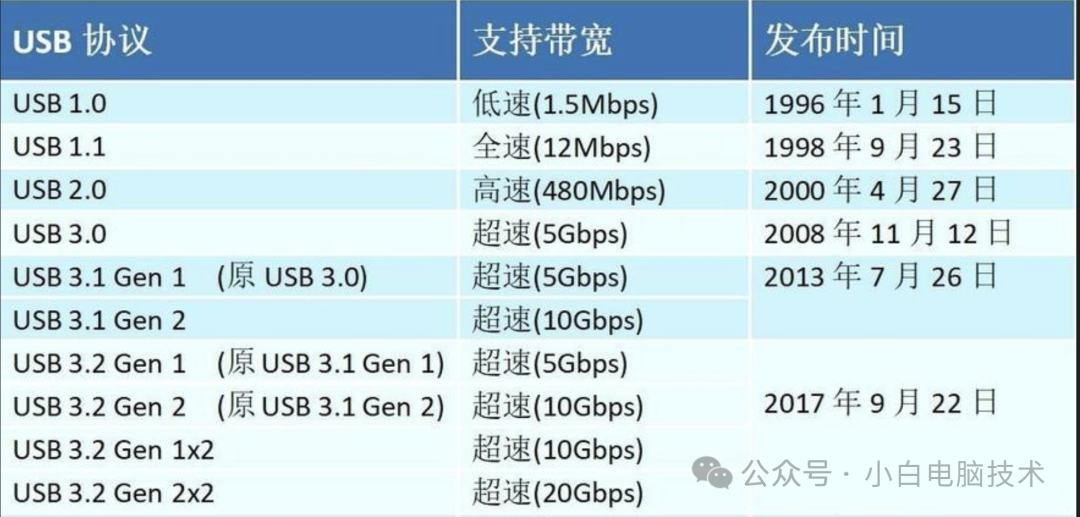
USB 3.0?USB 3.1?USB 3.2?怎么区分?
还记得小白刚接触电脑的时候,电脑普及的USB接口大部分是USB 2.0,还有少部分USB 1.0的(现在基本上找不到了)。 当时的电脑显示器,可能00后的小伙伴都没见过,它们大概长这样: 当时小白以为电脑最…...

Gitlab实战教程:打造企业级代码托管与协作平台!
目录 一、Gitlab概述1、Gitlab简介(1)Gitlab的定义(2)Gitlab与Git的关系(3)Gitlab的主要功能 2、Gitlab与Git的关系(1)Git的基本概念(2)Gitlab与Git的关联&am…...

更新C语言题目
1.以下程序输出结果是() int main() {int a 1, b 2, c 2, t;while (a < b < c) {t a;a b;b t;c--;}printf("%d %d %d", a, b, c); } 解析:a1 b2 c2 a<b 成立 ,等于一个真值1 1<2 执行循环体 t被赋值为1 a被赋值2 b赋值1 c-- c变成1 a<b 不成立…...

struct和C++的类
1.铺垫 1.1想看明白这章节,必须要懂得C语言的struct结构体、C语言深度解剖的static用法、理解声明与定义,C的类和static用法;否则看起来有些吃力 2.引子 2.1struct结构体里面只能存储内置类型;比如:char、short、 i…...

【数据结构与算法】LeetCode:图论
文章目录 LeetCode:图论岛屿数量(Hot 100)岛屿的最大面积腐烂的橘子(Hot 100)课程表(Hot 100) LeetCode:图论 岛屿数量(Hot 100) 岛屿数量 DFS: class So…...

YOLOv8 基于NCNN的安卓部署
YOLOv8 NCNN安卓部署 前两节我们依次介绍了基于YOLOv8的剪枝和蒸馏 本节将上一节得到的蒸馏模型导出NCNN,并部署到安卓。 NCNN 导出 YOLOv8项目中提供了NCNN导出的接口,但是这个模型放到ncnn-android-yolov8项目中你会发现更换模型后app会闪退。原因…...

【Python|接口自动化测试】使用requests发送http请求时添加headers
文章目录 1.前言2.HTTP请求头的作用3.在不添加headers时4.反爬虫是什么?5.在请求时添加headers 1.前言 本篇文章主要讲解如何使用requests请求时添加headers,为什么要加headers呢?是因为有些接口不添加headers时,请求会失败。 2…...

需求管理工具Jama Connect:与Jira/Slack/GitHub无缝集成,一站式解决复杂产品开发中的协作难题
在产品和软件开发的动态世界中,有效协作是成功的关键。然而,团队往往面临着阻碍进步和创新的重大挑战。了解这些挑战并找到强有力的解决方案,对于实现无缝、高效的团队协作至关重要。Jama Connect就是这样一种解决方案,它是一个功…...

CSP-J/S 复赛算法 背包DP
文章目录 前言背包DP的简介问题描述目标解决方法1. **定义状态**2. **状态转移方程**3. **初始化**4. **目标**举个例子动态规划解决背包问题的核心 DP背包问题示例代码问题描述代码实现核心代码讲解:举例:总结: 总结 前言 背包问题是算法竞…...

如何评估和部署 IT 运维系统?
如何才能将如此新兴、流行的技术转化为企业中实用的系统环境呢? 为此,我们采访了一家已经成功部署IT运维体系的大型企业的IT总监龙先生,请他给我们讲一下企业应该如何真正评估和部署自己的IT运维体系。 真理就是价值。 1.评估选择…...

正态分布的极大似然估计一个示例,详细展开的方程求解步骤
此示例是 什么是极大似然估计 中的一个例子,本文的目的是给出更加详细的方程求解步骤,便于数学基础不好的同学理解。 目标 假设我们有一组样本数据 x 1 , x 2 , … , x n x_1, x_2, \dots, x_n x1,x2,…,xn,它们来自一个正态分布 N…...
s7-200SMART编程软件下载
1、官网: STEP 7 Micro/WIN SMART V2.2 完整版http://w2.siemens.com.cn/download/smart/STEP%207%20MicroWIN%20SMART%20V2.2.zip STEP 7 Micro/WIN SMART V2.3 完整版http://w2.siemens.com.cn/download/smart/STEP%207%20MicroWIN%20SMART%20V2.3.iso STEP 7 Mi…...

NCM解密终极指南:3步解锁网易云音乐加密文件
NCM解密终极指南:3步解锁网易云音乐加密文件 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经在网易云音乐下载了心爱的歌曲,却发现只能在官方客户端播放,无法在其他设备或播放器上欣赏&…...

Univer开源项目部署完整指南:从零到生产环境
Univer开源项目部署完整指南:从零到生产环境 【免费下载链接】univer Build AI-native spreadsheets. Univer is a full-stack framework for creating and editing spreadsheets on both web and server. With Univer Platform, Univer Spreadsheets is driven dir…...
)
别再死记ResNet结构了!用PyTorch手把手带你复现ResNet-50(附完整代码与可视化)
从零构建ResNet-50:PyTorch实战与架构解密 当你第一次看到ResNet的残差连接时,是否曾被那个"跳跃"的结构所困惑?为什么简单的跨层连接就能解决深度网络的退化问题?本文将以工程师视角,带你用PyTorch从第一行…...

如何通过QuickLookVideo实现Mac视频预览效率革命:终极工具深度解析
如何通过QuickLookVideo实现Mac视频预览效率革命:终极工具深度解析 【免费下载链接】QuickLookVideo This package allows macOS Finder to display thumbnails, static QuickLook previews, cover art and metadata for most types of video files. 项目地址: ht…...

探索Depth Anything V2:单目深度估计技术的新纪元
探索Depth Anything V2:单目深度估计技术的新纪元 【免费下载链接】Depth-Anything-V2 [NeurIPS 2024] Depth Anything V2. A More Capable Foundation Model for Monocular Depth Estimation 项目地址: https://gitcode.com/gh_mirrors/de/Depth-Anything-V2 …...

从“整蛊脚本”到实战:在虚拟机里安全玩转Windows批处理与VBS的5个实验
从“整蛊脚本”到实战:在虚拟机里安全玩转Windows批处理与VBS的5个实验 当你第一次在网上看到那些号称能让电脑蓝屏、自动关机甚至修改注册表的脚本时,是否既好奇又害怕?这些看似神秘的代码背后,其实隐藏着Windows系统管理的核心…...

3分钟掌握LaTeX公式转换Word的终极指南
3分钟掌握LaTeX公式转换Word的终极指南 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 还在为学术论文中的数学公式复制烦恼吗?LaTeX…...
)
Gemini Nano离线推理部署手册(移动端LLM轻量化部署终极版)
更多请点击: https://codechina.net 第一章:Gemini Nano离线推理部署手册(移动端LLM轻量化部署终极版) Gemini Nano 是 Google 推出的首个专为端侧设备设计的轻量级大语言模型,支持在 Android 14 设备上本地运行&…...

3步搞定Football Manager面部包管理:NewGAN-Manager完全指南
3步搞定Football Manager面部包管理:NewGAN-Manager完全指南 【免费下载链接】NewGAN-Manager A tool to generate and manage xml configs for the Newgen Facepack. 项目地址: https://gitcode.com/gh_mirrors/ne/NewGAN-Manager 你是否厌倦了在Football M…...

IL-4诱导的M2INF巨噬细胞在二型免疫疾病及感染防御中的机制研究
摘要郑世进课题组通过深入研究IL-4诱导的M2INF巨噬细胞,揭示了其产生机制主要涉及糖代谢途径的重编程和组蛋白H3K4位点甲基化修饰的改变。这一发现为理解二型免疫疾病的发生发展提供了新的视角,并为相关疾病的治疗策略提供了理论依据。通过在小鼠模型&am…...