MySQL 实验 10:数据查询(3)—— 聚合函数与分组查询
MySQL 实验 10:数据查询(3)—— 聚合函数与分组查询
目录
- MySQL 实验 10:数据查询(3)—— 聚合函数与分组查询
- 一、聚合函数
- 1、计数函数(COUNT)
- 2、求和函数(SUM)
- 3、求平均值函数(AVG)
- 4、求最大值函数(MAX)
- 5、求最小值函数(MIN)
- 6、连接数据值函数(GROUP_CONCAT)
- 二、分组查询
- 1、GROUP BY 的语法
- 2、使用列名分组
- 3、使用表达式分组
- 4、分组的同时使用 WHERE 子句
- 5、使用 HAVING 对分组进行选择
- 6、WITH ROLLUP 参数
聚合函数又称为统计函数,可以对查询结果进行统计和汇总,对表中某一列的数据值进行计算并返回一个单一值。
使用 GROUP BY 关键字可以将查询结果按照一个或多个列或者表达式进行分组,分组的依据为 GROUP BY 后面的列名或表达式。GROUP BY 通常与聚合函数合用。
一、聚合函数
常用的聚合函数包括 SUM、COUNT、AVG、MAX 和 MIN,实现对表中数据的统计,GROUP_CONCAT 函数的功能与聚合函数类似,可以对某一列中的数据值进行连接操作。聚合函数的语法格式如下:
-- 1、计数函数(count):使用 count(*) 时不忽略 NULL 值,使用 count(列名|表达式) 时忽略 NULL 值
-- 使用 distinct 可以去除重复数据
COUNT(distinct *|列名|表达式)-- 2、求和函数(sum):列的类型或表达式返回值的类型必须是数值类型
SUM(列名|表达式)-- 3、求平均值函数:列的类型或表达式返回值的类型必须是数值类型
AVG(列名|表达式)-- 4、求最大值函数:列的类型或表达式返回值的类型可以是任意类型
MAX(列名|表达式)-- 5、求最小值函数:列的类型或表达式返回值的类型可以是任意类型
MIN(列名|表达式)-- 6、连接数据值函数:列的类型或表达式返回值的类型可以是任意类型
-- 使用 separator 指定数据之间的分隔符,如果省略 separator,则默认的分隔符为逗号
-- 使用 distinct 可以去除重复数据
GROUP_CONCAT([distinct] 列名 separator '分隔符')
说明:
(1)如果查询中使用了聚合函数,在没有分组的情况下,查询结果只有一行(只有一个统计结果)。如果使用 GROUP BY 分组,则每一个分组有一个统计结果。
(2)如果查询中使用了聚合函数,在没有分组的情况下,SELECT 后面除了聚合函数之外,一般不能有列名。
1、计数函数(COUNT)
使用 COUNT( ) 函数用于统计记录数量,通常与 GROUP BY 子句合用。
语法格式如下:
COUNT(distinct *|列名|表达式)-- 说明:使用 count(*) 时不忽略 NULL 值,使用 count(字段|表达式) 时忽略 NULL 值
例如:
(1)统计学生人数
mysql> select count(*) stu_cnt from stu;
+---------+
| stu_cnt |
+---------+
| 14 |
+---------+
1 row in set (0.00 sec)
(2)统计学生所在院系的数量
mysql> select count(distinct dept_id) as dept_cnt from stu;
+----------+
| dept_cnt |
+----------+
| 4 |
+----------+
1 row in set (0.00 sec)
(3)统计女生人数
mysql> select count(1) stu_cnt from stu where gender='女';
+---------+
| stu_cnt |
+---------+
| 6 |
+---------+
1 row in set (0.00 sec)
2、求和函数(SUM)
使用 SUM( ) 函数可以对表中某一列的数据求和,统计时忽略 NULL 值。如果没有匹配行,则返回 NULL 值。常与 GROUP BY 子句合用。语法格式如下:
SUM(字段|表达式)-- 说明:列的类型或表达式返回值的类型必须是数值类型
例如:
(1)统计学号为【20220124002】的同学选修的所有课程的总分
mysql> select sum(score) total_score from xk where s_id='20220124002';
+-------------+
| total_score |
+-------------+
| 226.00 |
+-------------+
1 row in set (0.00 sec)
(2)统计女生人数
mysql> select sum(1) stu_cnt from stu where gender='女';
+---------+
| stu_cnt |
+---------+
| 6 |
+---------+
1 row in set (0.00 sec)
(3)统计男生人数
mysql> select sum(if(gender='男',1,0)) stu_cnt from stu;
+---------+
| stu_cnt |
+---------+
| 8 |
+---------+
1 row in set (0.00 sec)
3、求平均值函数(AVG)
使用 AVG( ) 函数可以计算表中某一列数据的平均值。统计时忽略 NULL 值。常与 GROUP BY 子句合用。语法格式如下:
AVG(字段|表达式)-- 说明:列的类型或表达式返回值的类型必须是数值类型
例如:
(1)统计学号为【20220124002】的同学选修的所有课程的平均分
mysql> select avg(score) avg_score from xk where s_id='20220124002';
+-------------+
| avg_score |
+-------------+
| 75.333333 |
+-------------+
1 row in set (0.00 sec)
(2)统计学生的平均年龄
mysql> select avg(year(now())-year(birth)) avg_age from stu;
+---------+
| avg_age |
+---------+
| 22.0714 |
+---------+
1 row in set (0.00 sec)
4、求最大值函数(MAX)
使用 MAX( ) 函数统计某一列数据的最大值。统计时忽略 NULL 值。常与 GROUP BY 子句合用。语法格式如下:
MAX(字段|表达式)-- 说明:列的类型或表达式返回值的类型可以是任意类型
例如:
(1)查询所有学生的最大年龄
mysql> select max(year(now())-year(birth)) max_age from stu;
+---------+
| max_age |
+---------+
| 24 |
+---------+
1 row in set (0.00 sec)
(2)查询编号为【C01002】的课程的最高分
mysql> select max(score) max_score from xk where c_id='C01002';
+-----------+
| max_score |
+-----------+
| 69.00 |
+-----------+
1 row in set (0.00 sec)
5、求最小值函数(MIN)
使用 MIN( ) 函数统计某一列数据的最小值。统计时忽略 NULL 值。常与 GROUP BY 子句合用。语法格式如下:
MIN(字段|表达式)-- 说明:列的类型或表达式返回值的类型可以是任意类型
例如:
(1)查询所有学生的最小年龄
mysql> select min(year(now())-year(birth)) min_age from stu;
+---------+
| min_age |
+---------+
| 21 |
+---------+
1 row in set (0.00 sec)
(2)查询编号为【C01002】的课程的最低分
mysql> select min(score) min_score from xk where c_id='C01002';
+-----------+
| min_score |
+-----------+
| 68.00 |
+-----------+
1 row in set (0.00 sec)
6、连接数据值函数(GROUP_CONCAT)
使用 GROUP_CONCAT( ) 函数可以把某一列的数据值连接成一个字符串,数据值之间使用指定的分隔符分隔(默认为逗号)。语法格式如下:
GROUP_CONCAT([distinct] 列名 separator '分隔符')-- 说明:列的类型或表达式返回值的类型可以是任意类型
-- 使用 separator 指定数据之间的分隔符,如果省略 separator,则默认的分隔符为逗号
例如:
(1)查询编号为【D01】的学院的学生名单
mysql> select group_concat(s_name) from stu where dept_id='D01';
+-----------------------------+
| group_concat(s_name) |
+-----------------------------+
| 薛智玲,杨铭华,张从超,孙金航 |
+-----------------------------+
1 row in set (0.00 sec)
(2)查询编号为【D02】的学院的学生名单,学生之间用空格分隔
mysql> select group_concat(s_name separator ' ') from stu where dept_id='D01';
+-------------------------------------+
| group_concat(s_name separator ' ') |
+-------------------------------------+
| 薛智玲 杨铭华 张从超 孙金航 |
+-------------------------------------+
1 row in set (0.00 sec)
二、分组查询
使用 GROUP BY 关键字可以将查询结果按照一个或多个列或者表达式进行分组,分组的依据为 GROUP BY 后面的列名或表达式。GROUP BY 通常与聚合函数合用。
1、GROUP BY 的语法
GROUP BY 子句的语法格式如下:
GROUP BY <列名|表达式>[,...] [HAVING 条件表达式] [WITH ROLLUP]--说明:
(1)使用分组查询时,select 后面的字段列表只能包含 GROUP BY 后面的列名或表达式以及聚合函数,不能包含其他的列或表达式,否则会报错。
(2)列名|表达式:分组依据,按列名或表达式进行分组。
(3)HAVING 条件表达式:对分组进行选择,符合条件表达式的结果才会显示。
(4)WITH ROLLUP:在所有记录的最后加上一条记录,该记录为对所有行的统计结果(求和)。
2、使用列名分组
例如:按照 s_id 分组,统计每个学生所学课程的平均分
mysql> select s_id, avg(score) avg_score from xk group by s_id;
+-------------+-----------+
| s_id | avg_score |
+-------------+-----------+
| 20220124001 | 73.666667 |
| 20220124002 | 75.333333 |
| 20220124003 | 94.500000 |
| 20220124004 | 88.500000 |
| 20220214001 | 85.666667 |
| 20220214002 | 68.000000 |
| 20220214003 | 87.333333 |
| 20220325101 | 80.000000 |
| 20220325102 | 80.333333 |
| 20220325103 | 69.333333 |
| 20220410101 | 82.666667 |
| 20220410102 | 70.666667 |
| 20220410103 | 69.333333 |
| 20220410104 | 69.500000 |
+-------------+-----------+
14 rows in set (0.00 sec)
3、使用表达式分组
例如:按照学生的姓氏分组,查询每组对应的学生人数
mysql> select left(s_name, 2) surname, count(*) stu_cnt from stu group by surname;
+---------+---------+
| surname | stu_cnt |
+---------+---------+
| 孙 | 1 |
| 夏 | 1 |
| 谭 | 1 |
| 杨 | 1 |
| 薛 | 1 |
| 赵 | 2 |
| 张 | 2 |
| 裴 | 1 |
| 聂 | 1 |
| 周 | 1 |
| 董 | 1 |
| 江 | 1 |
+---------+---------+
12 rows in set (0.00 sec)
4、分组的同时使用 WHERE 子句
分组时如果使用了 WHERE 子句,则先使用 WHERE 对表中的数据进行筛选,然后进行分组和统计。
例如:利用 xk 表统计每门课程考试分数大于 80 分的学生人数
mysql> select c_id, count(*) stu_cnt from xk where score>80 group by c_id;
+--------+---------+
| c_id | stu_cnt |
+--------+---------+
| C01001 | 3 |
| C01003 | 3 |
| C02102 | 1 |
| C02103 | 2 |
| C03201 | 2 |
| C03202 | 2 |
| C04112 | 2 |
| C04113 | 1 |
+--------+---------+
8 rows in set (0.00 sec)
5、使用 HAVING 对分组进行选择
使用 HAVING 子句可以对分组进行选择。当 HAVING 子句与 WHER 子句同时使用时,查询执行的顺序为:先使用 WHERE 对表中的记录进行筛选,然后对满足条件的记录分组与统计,再使用 HAVING 子句对分组进行选择。
例如:
(1)利用 xk 表查询每门课的选修人数,并且只显示选修人数大于 3 门的课程信息
mysql> select c_id, count(*) stu_cnt from xk group by c_id having stu_cnt>3;
+--------+---------+
| c_id | stu_cnt |
+--------+---------+
| C01001 | 4 |
| C01003 | 4 |
| C04111 | 4 |
| C04112 | 4 |
+--------+---------+
4 rows in set (0.00 sec)
(2)利用 stu 表查询每个学院的男生人数,并且只显示男生人数大于 3 人的学院信息
mysql> select dept_id, count(*) stu_cnt from stu where gender='男' group by dept_id having stu_cnt>2;
+---------+---------+
| dept_id | stu_cnt |
+---------+---------+
| D03 | 3 |
+---------+---------+
1 row in set (0.00 sec)
6、WITH ROLLUP 参数
在所有记录的最后加上一条记录,该记录为对所有行的统计结果(求和)。
例如:
(1)利用 stu 表查询每个学院的学生人数以及总人数
-- 把 dept_id 为空的学生的 dept_id 修改为 D04
mysql> update stu set dept_id='D04' where dept_id is null;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0-- 分组查询
mysql> select dept_id, count(*) stu_cnt from stu group by dept_id with rollup;
+---------+---------+
| dept_id | stu_cnt |
+---------+---------+
| D01 | 4 |
| D02 | 3 |
| D03 | 3 |
| D04 | 4 |
| NULL | 14 |
+---------+---------+
5 rows in set (0.00 sec)
(2)利用 stu 表查询每个学院的学生人数以及总人数,并把最后一行的 NULL 修改为 stu_total
mysql> select ifnull(dept_id, 'total') dept_id, count(*) stu_cnt from stu group by dept_id with rollup;
+---------+---------+
| dept_id | stu_cnt |
+---------+---------+
| D01 | 4 |
| D02 | 3 |
| D03 | 3 |
| D04 | 4 |
| total | 14 |
+---------+---------+
5 rows in set, 1 warning (0.00 sec)
相关文章:
—— 聚合函数与分组查询)
MySQL 实验 10:数据查询(3)—— 聚合函数与分组查询
MySQL 实验 10:数据查询(3)—— 聚合函数与分组查询 目录 MySQL 实验 10:数据查询(3)—— 聚合函数与分组查询一、聚合函数1、计数函数(COUNT)2、求和函数(SUM࿰…...

感知机学习算法
感知机 一、感知机简介二、感知机模型2.1 感知机的基本组成2.2 求和函数2.2.1 时间总合2.2.2 空间总合 2.3 激活函数2.4 学习算法2.4.1 赫布学习规则2.4.2 Delta学习规则 三、 结论参考文献 一、感知机简介 M-P神经元模型因其对生物神经元激发过程的极大简化而成为神经网络研究…...
2024年双十一有什么好物推荐?双十一必买清单大汇总
随着科技的飞速发展,数码产品已成为我们生活中不可或缺的伙伴。2024年双十一购物狂欢节即将来临,众多消费者早已摩拳擦掌,准备在这个年度盛事中淘到心仪的数码好物。在这个信息爆炸的时代,如何从琳琅满目的商品中挑选出性价比高、…...

C语言贪吃蛇
#只讲逻辑不讲一些基础,基础大概过一遍就行# project-one: 无 (gitee.com)仓库里面有原代码 一、基础工作 1、先将你的编译器换成32位环境,也就是x86, 如果是控制台主机窗口则管,若不是需要改为控制台主机窗口 打开运行窗口后点…...

SpringBoot宠物咖啡馆平台:创新设计与高效实现
1系统概述 1.1 研究背景 随着计算机技术的发展以及计算机网络的逐渐普及,互联网成为人们查找信息的重要场所,二十一世纪是信息的时代,所以信息的管理显得特别重要。因此,使用计算机来管理基于Spring Boot的宠物咖啡馆平台的设计与…...

李宏毅深度学习-梯度下降和Batch Normalization批量归一化
Gradient Descent梯度下降 ▽ -> 梯度gradient -> vector向量 -> 下图中的红色箭头(loss等高线的法线方向) Tip1: Tuning your learning rates Adaptive Learning Rates自适应lr 通常lr会越来越小 Adaptive Learning Rates中每个参数都给它不…...

java集合框架都有哪些
Java集合框架(Java Collections Framework)是Java提供的一套设计良好的支持对一组对象进行操作的接口和类。这些接口和类定义了如何添加、删除、遍历和搜索集合中的元素。Java集合框架主要包括以下几个部分: 接口: Collection&…...
线程与进程)
笔记整理—linux进程部分(8)线程与进程
前面用了高级IO去实现鼠标和键盘的读取,也说过要用多进程方式进行该操作: int mian(void) {int ret-1;int fd-1;char bug[100]{0};retfork();if(0ret){//子进程,读鼠标}if(0<ret){//父进程,读键盘}else{perror("fork&quo…...

使用 Python 实现遗传算法进行无人机路径规划
目录 使用 Python 实现遗传算法进行无人机路径规划引言1. 遗传算法概述1.1 定义1.2 基本步骤1.3 遗传算法的特点 2. 使用 Python 实现遗传算法2.1 安装必要的库2.2 定义类2.2.1 无人机模型类2.2.2 遗传算法类 2.3 示例程序 3. 遗传算法的优缺点3.1 优点3.2 缺点 4. 改进方向5. …...

JAVA基础: synchronized 和 lock的区别、synchronized锁机制与升级
1 synchronized 和 lock的区别 synchronized是一个关键字, lock是一个接口,实际使用的是实现类 synchronized通过触发的是系统级别的锁机制, lock是API级别的锁机制 synchronized自动获得锁,自动释放锁。 lock需要通过方法获得锁…...

自动驾驶 车道检测实用算法
自动驾驶 | 车道检测实用算法 车道识别是自动驾驶领域的一个重要问题,今天介绍一个利用摄像头图像进行车道识别的实用算法。该算法利用了OpenCV库和Udacity自动驾驶汽车数据库的相关内容。 该算法包含以下步骤: 摄像头校准,以移除镜头畸变&…...

22.第二阶段x86游戏实战2-背包遍历REP指令详解
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 本次游戏没法给 内容参考于:微尘网络安全 本人写的内容纯属胡编乱造,全都是合成造假,仅仅只是为了娱乐,请不要…...

java 的三种IO模型(BIO、NIO、AIO)
java 的三种IO模型(BIO、NIO、AIO) 一、BIO 阻塞式 IO(Blocking IO)1.1、BIO 工作机制1.2、BIO 实现单发单收1.3、BIO 实现多发多收1.4、BIO 实现客户端服务端多对一1.5、BIO 模式下的端口转发思想 二、NIO 同步非阻塞式 IO&#…...

低级语言和高级语言、大小写敏感、静态语言和动态语言、链接
低级语言和高级语言 一般而言,更接近硬件的语言被称为低级语言,反之,更远离硬件被称为高级语言。C语言既有低级语言的特点,又有高级语言的特点,又被称为系统语言。Java/Python一般被称为高级语言。 大小写敏感 DOS/Win…...

P3197 [HNOI2008] 越狱
题目传送门 题面 [HNOI2008] 越狱 题目描述 监狱有 n n n 个房间,每个房间关押一个犯人,有 m m m 种宗教,每个犯人会信仰其中一种。如果相邻房间的犯人的宗教相同,就可能发生越狱,求有多少种状态可能发生越狱。 …...
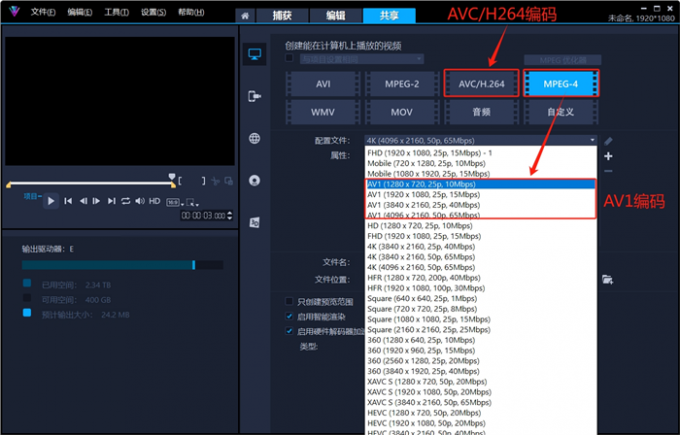
会声会影导出视频mp4格式哪个最高清,会声会影输出格式哪个清晰
调高分辨率后,mp4视频还是不清晰。哪怕全部使用4K级素材,仍然剪不出理想中的高画质作品。不是你的操作有问题,而是剪辑软件没选对。Corel公司拥有全球顶尖的图像处理技术,该公司研发的会声会影视频剪辑软件,在过去的20…...

Linux:进程调度算法和进程地址空间
✨✨✨学习的道路很枯燥,希望我们能并肩走下来! 文章目录 目录 文章目录 前言 一 进程调度算法 1.1 进程队列数据结构 1.2 优先级 编辑 1.3 活动队列 编辑 1.4 过期队列 1.5 active指针和expired指针 1.6 进程连接 二 进程地址空间 2.1 …...

TCP ---滑动窗口以及拥塞窗口
序言 在上一篇文章中我们介绍了 TCP 中的协议段格式,以及保证其可靠传输的重传机制,着重介绍了三次握手建立连接,四次挥手断开连接的过程(👉点击查看)。 这只是 TCP 保证通信可信策略的一部分,现在让我们继续深入吧&…...

第十二章--- fixed 和 setprecision 函数、round 函数、进制转换及底层逻辑
1. 保留几位小数 在C中,如果你想要控制输出的小数点后的位数,可以使用<iomanip>头文件提供的fixed和setprecision函数。这里的fixed用于设置浮点数的输出格式为定点表示法,而setprecision(n)则用来指定小数点后保留的位数。具体用法如…...

ASP.NetCore---I18n(internationalization)多语言版本的应用
文章目录 0.实现的效果如下1.创建新项目I18nBaseDemo2.添加页面中的下拉框3.在HomeController中添加ChangeLanguage方法4.在Progress.cs 文件中添加如下代码:5. 在progress.cs中添加code6.添加Resource资源文件7.在页面中引用i18n的变量8. 重启项目,应该…...

PlantUML Editor:用代码思维重塑UML绘图的现代工具
PlantUML Editor:用代码思维重塑UML绘图的现代工具 【免费下载链接】plantuml-editor PlantUML online demo client 项目地址: https://gitcode.com/gh_mirrors/pl/plantuml-editor 你是否厌倦了传统拖拽式UML工具的繁琐操作?PlantUML Editor将彻…...

TSSP77038红外解调器:从原理到实战,打造高可靠接近传感与光束中断系统
1. 项目概述:从“遥控”到“感知”的红外新思路在嵌入式开发和电子制作领域,红外(IR)技术几乎是每个玩家都会接触到的老朋友。我们最熟悉的莫过于家里的电视、空调遥控器,它们通过发射一串调制在38KHz载波上的红外脉冲…...

xpull:轻量级声明式文件同步工具的设计原理与K8s实战
1. 项目概述:一个轻量级、高可用的文件同步利器在分布式系统、微服务架构乃至日常的自动化运维中,文件同步是一个看似基础却至关重要的环节。无论是将日志文件从边缘服务器拉取到中心进行分析,还是将配置文件从版本库分发到成百上千个实例&am…...

危化园区 ReID 跨镜管控难,镜像视界无感定位筑牢安全防线
危化园区 ReID 跨镜管控难,镜像视界无感定位筑牢安全防线危化工业园区作为化工生产、仓储、运输的核心载体,承载着易燃易爆、有毒有害等高危物料的全流程作业,其安全管控水平直接关系到人员生命安全、财产安全与生态环境安全。不同于普通工业…...

AI驱动的代码安全审计工具OpenClaw:原理、部署与实战调优
1. 项目概述:当AI成为代码审计的“利爪” 最近在安全圈和开源社区里,一个名为“OpenClaw”的项目引起了我的注意。它的全称是 zast-ai/openclaw-security-audit ,从名字就能嗅到一股“技术极客”的味道——“zast-ai”暗示着AI驱动…...

3步解放暗黑2存档:Diablo Edit2角色编辑器完全指南
3步解放暗黑2存档:Diablo Edit2角色编辑器完全指南 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否曾因暗黑破坏神2角色build失误而懊恼?是否厌倦了数百小时刷装备却…...

3分钟搞定!FigmaCN终极中文插件:让英文界面秒变中文的免费神器
3分钟搞定!FigmaCN终极中文插件:让英文界面秒变中文的免费神器 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma的英文界面而烦恼吗?专业术…...

为Cursor编辑器构建本地AI大脑:基于RAG与智能体的代码助手实战
1. 项目概述:当你的代码编辑器拥有了“大脑”在程序员的世界里,工具的效率直接决定了生产力的天花板。从简单的文本编辑器到功能强大的IDE,再到如今集成了AI能力的智能编程助手,我们一直在寻找那个能理解我们意图、甚至能预测我们…...

Unity3D项目跨平台部署实战:从Windows到Linux的完整流程与避坑指南
1. 环境准备:搭建跨平台开发基础 跨平台部署的第一步是确保开发环境配置正确。很多开发者容易忽略这一步,结果在后续流程中遇到各种奇怪的问题。我在实际项目中遇到过多次因为环境不匹配导致的编译失败,所以特别强调环境准备的重要性。 首先需…...

Next.js静态站点图片优化实战:next-image-export-optimizer配置指南
1. 项目概述:为什么我们需要一个“静态图片优化器”?如果你和我一样,经常用 Next.js 做项目,那你肯定对next/image组件又爱又恨。爱的是它开箱即用的图片懒加载、自动格式转换和响应式适配,恨的是它在构建和部署时带来…...