A General Framework for Uncertainty Estimation in Deep Learning源码阅读(二)
接上文
ResNet定义:
代码使用
def ResNet18ADF(noise_variance=1e-3, min_variance=1e-3):return ResNet(BasicBlock, [2,2,2,2], num_classes=10, noise_variance=1e-3, min_variance=1e-3, initialize_msra=False)
定义模型,其中ResNet定义为:
class ResNet(nn.Module):def __init__(self, block, num_blocks, num_classes=10, noise_variance=1e-3, min_variance=1e-3, initialize_msra=False):super(ResNet, self).__init__()self.keep_variance_fn = lambda x: keep_variance(x, min_variance=min_variance)self._noise_variance = noise_varianceself.in_planes = 64self.conv1 = adf.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False, keep_variance_fn=self.keep_variance_fn)self.bn1 = adf.BatchNorm2d(64, keep_variance_fn=self.keep_variance_fn)self.ReLU = adf.ReLU(keep_variance_fn=self.keep_variance_fn)self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1, keep_variance_fn=self.keep_variance_fn)self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2, keep_variance_fn=self.keep_variance_fn)self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2, keep_variance_fn=self.keep_variance_fn)self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2, keep_variance_fn=self.keep_variance_fn)self.linear = adf.Linear(512*block.expansion, num_classes, keep_variance_fn=self.keep_variance_fn)self.AvgPool2d = adf.AvgPool2d(keep_variance_fn=self.keep_variance_fn)def _make_layer(self, block, planes, num_blocks, stride, keep_variance_fn=None):strides = [stride] + [1]*(num_blocks-1)layers = []for stride in strides:layers.append(block(self.in_planes, planes, stride, keep_variance_fn=self.keep_variance_fn))self.in_planes = planes * block.expansionreturn adf.Sequential(*layers)def forward(self, x):inputs_mean = xinputs_variance = torch.zeros_like(inputs_mean) + self._noise_variancex = inputs_mean, inputs_varianceout = self.ReLU(*self.bn1(*self.conv1(*x)))out = self.layer1(*out)out = self.layer2(*out)out = self.layer3(*out)out = self.layer4(*out)out = self.AvgPool2d(*out, 4)out_mean = out[0].view(out[0].size(0), -1) # Flattenout_var = out[1].view(out[1].size(0), -1)out = out_mean, out_varout = self.linear(*out)return out
其中,*的作用是:
在Python中,一个星号(*)通常被用来进行解包(unpacking)操作。当一个星号出现在函数调用中的一个参数前面时,它会告诉Python将该参数解包成多个独立的值,然后再将这些值传递给函数。
当一个星号出现在一个变量名前面时,它可以被用来表示一个可变数量的参数。这被称为可变参数列表(variable-length argument list)或者不定长参数(arbitrary argument)。这样的语法允许函数接受不定数量的参数。
下面是一个例子,展示了如何使用星号来定义一个可变参数列表:
def my_func(*args):
for arg in args:
print(arg)
my_func(1, 2, 3, 4, 5)
这个函数可以接受任意数量的参数,并将它们打印出来。在函数中,参数args被定义为一个元组,其中包含了传递给函数的所有参数。
(可以观察到,self.layer等模型层输出的out应该包含两部分)
adf.Sequential()
ResNet中比较关键的是_make_layer,其中用到了adf.Sequential:
class Sequential(nn.Module):def __init__(self, *args):super(Sequential, self).__init__()if len(args) == 1 and isinstance(args[0], OrderedDict):for key, module in args[0].items():self.add_module(key, module)else:for idx, module in enumerate(args):self.add_module(str(idx), module)def _get_item_by_idx(self, iterator, idx):"""Get the idx-th item of the iterator"""size = len(self)idx = operator.index(idx)if not -size <= idx < size:raise IndexError('index {} is out of range'.format(idx))idx %= sizereturn next(islice(iterator, idx, None))def __getitem__(self, idx):if isinstance(idx, slice):return Sequential(OrderedDict(list(self._modules.items())[idx]))else:return self._get_item_by_idx(self._modules.values(), idx)def __setitem__(self, idx, module):key = self._get_item_by_idx(self._modules.keys(), idx)return setattr(self, key, module)def __delitem__(self, idx):if isinstance(idx, slice):for key in list(self._modules.keys())[idx]:delattr(self, key)else:key = self._get_item_by_idx(self._modules.keys(), idx)delattr(self, key)def __len__(self):return len(self._modules)def __dir__(self):keys = super(Sequential, self).__dir__()keys = [key for key in keys if not key.isdigit()]return keysdef forward(self, inputs, inputs_variance):for module in self._modules.values():inputs, inputs_variance = module(inputs, inputs_variance)return inputs, inputs_variance其中,add_module()作用是:
add_module() 是 PyTorch 中 nn.Module 类的一个方法,用于将子模块添加到当前模块中。它接受两个参数:
name:子模块的名称。 module:要添加的子模块。 下面是一个例子,展示了如何使用 add_module()
方法向一个模块中添加子模块:import torch.nn as nnclass MyModel(nn.Module): def __init__(self):super(MyModel, self).__init__()self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1)self.relu1 = nn.ReLU()self.conv2 = nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1)self.relu2 = nn.ReLU()self.fc1 = nn.Linear(32 * 28 * 28, 1024)self.relu3 = nn.ReLU()self.fc2 = nn.Linear(1024, 10)self.softmax = nn.Softmax(dim=1)# 使用 add_module() 方法添加一个 BatchNorm2d 模块self.bn = nn.BatchNorm2d(32)self.add_module('batch_norm', self.bn) def forward(self, x):x = self.conv1(x)x = self.relu1(x)x = self.conv2(x)x = self.bn(x)x = self.relu2(x)x = x.view(-1, 32 * 28 * 28)x = self.fc1(x)x = self.relu3(x)x = self.fc2(x)x = self.softmax(x)return x在这个例子中,我们创建了一个自定义的模型 MyModel,并使用 add_module() 方法将一个 BatchNorm2d 模块添加到模型中。这个方法可以方便地管理模型中的子模块,并在需要时进行访问和修改。
在上面的代码中,确实可以直接使用 self.bn 调用 BatchNorm2d
模块,而不需要使用 add_module() 方法。然而,使用 add_module()
方法可以将模块的名称与其实例进行绑定,从而使模块的名称可以在模型的其他地方进行访问和修改。这在模型较复杂的情况下非常有用。举个例子,如果我们想要访问模型中的所有 BatchNorm2d 模块,可以使用 named_modules()
方法来获取所有模块及其名称,并在其中筛选出 BatchNorm2d 模块:for name, module in my_model.named_modules():if isinstance(module, nn.BatchNorm2d):print(f'{name}: {module}') 这将输出模型中所有的 BatchNorm2d 模块及其名称。另外,add_module() 方法还可以与 register_parameter()
方法和其他方法一起使用,方便地管理模型的参数和其他属性。因此,在设计复杂的模型时,使用 add_module()
方法可以提高代码的可读性和可维护性。
在forward中,读取add后的module进行计算:
def forward(self, inputs, inputs_variance):for module in self._modules.values():inputs, inputs_variance = module(inputs, inputs_variance)return inputs, inputs_variance
BasicBlock
ResNet中比较关键的是_make_layer,其中用到了block(),指的是:
class BasicBlock(nn.Module):expansion = 1def __init__(self, in_planes, planes, stride=1, keep_variance_fn=None):super(BasicBlock, self).__init__()self.keep_variance_fn = keep_variance_fnself.conv1 = adf.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False, keep_variance_fn=self.keep_variance_fn)self.bn1 = adf.BatchNorm2d(planes, keep_variance_fn=self.keep_variance_fn)self.conv2 = adf.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False, keep_variance_fn=self.keep_variance_fn)self.bn2 = adf.BatchNorm2d(planes, keep_variance_fn=self.keep_variance_fn)self.ReLU = adf.ReLU(keep_variance_fn=self.keep_variance_fn)self.shortcut = adf.Sequential()if stride != 1 or in_planes != self.expansion*planes:self.shortcut = adf.Sequential(adf.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False, keep_variance_fn=self.keep_variance_fn),adf.BatchNorm2d(self.expansion*planes, keep_variance_fn=self.keep_variance_fn))def forward(self, inputs_mean, inputs_variance):x = inputs_mean, inputs_varianceout = self.ReLU(*self.bn1(*self.conv1(*x)))out_mean, out_var = self.bn2(*self.conv2(*out))shortcut_mean, shortcut_var = self.shortcut(*x)out_mean, out_var = out_mean + shortcut_mean, out_var + shortcut_varout = out_mean, out_var out = self.ReLU(*out)return out
BasicBlock里把mean和var合成了一个out,而Sequential选择分开传播mean和var,有什么说法吗?
adf.Conv2d()
可以看到BasicBlock使用了adf.Conv2d():
class Conv2d(_ConvNd):def __init__(self, in_channels, out_channels, kernel_size, stride=1,padding=0, dilation=1, groups=1, bias=True,keep_variance_fn=None, padding_mode='zeros'):self._keep_variance_fn = keep_variance_fnkernel_size = _pair(kernel_size)stride = _pair(stride)padding = _pair(padding)dilation = _pair(dilation)super(Conv2d, self).__init__(in_channels, out_channels, kernel_size, stride, padding, dilation,False, _pair(0), groups, bias, padding_mode)def forward(self, inputs_mean, inputs_variance):outputs_mean = F.conv2d(inputs_mean, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups)outputs_variance = F.conv2d(inputs_variance, self.weight ** 2, None, self.stride, self.padding, self.dilation, self.groups)if self._keep_variance_fn is not None:outputs_variance = self._keep_variance_fn(outputs_variance)return outputs_mean, outputs_variance
其中,对于均值和方差是共享权重的:
outputs_mean, outputs_variance两个卷积操作共享权重吗?
是的,outputs_mean 和 outputs_variance 两个卷积操作在这个类中是共享权重的。在这个类的 init() 方法中,使用父类 _ConvNd 的构造函数初始化了模型的卷积核权重和偏置,并在 forward() 方法中对这些权重和偏置进行了调用。
具体来说,F.conv2d() 函数的第一个参数 inputs_mean 和第二个参数 inputs_variance 都使用了 self.weight 权重作为卷积核,这意味着这两个卷积操作共享相同的权重。同时,由于 inputs_variance 使用了 self.weight 的平方作为卷积核,因此两个卷积操作的权重实际上也是不同的。
需要注意的是,在卷积神经网络中,共享权重是一种常见的技术,它可以减少模型中需要训练的参数数量,从而减轻过拟合的风险。但是,共享权重也可能会限制模型的表达能力,因此需要根据具体问题和数据集的情况进行权衡和选择。
这个代码,使用weight2weight^2weight2作为方差的权重,有什么道理嘛?勉强可以理解吧!
adf.BatchNorm2d()
可以看到BasicBlock中使用了adf.BatchNorm2d():
class BatchNorm2d(nn.Module):_version = 2__constants__ = ['track_running_stats', 'momentum', 'eps', 'weight', 'bias','running_mean', 'running_var', 'num_batches_tracked']def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True,track_running_stats=True, keep_variance_fn=None):super(BatchNorm2d, self).__init__()self._keep_variance_fn = keep_variance_fnself.num_features = num_featuresself.eps = epsself.momentum = momentumself.affine = affineself.track_running_stats = track_running_statsif self.affine:self.weight = Parameter(torch.Tensor(num_features))self.bias = Parameter(torch.Tensor(num_features))else:self.register_parameter('weight', None)self.register_parameter('bias', None)if self.track_running_stats:self.register_buffer('running_mean', torch.zeros(num_features))self.register_buffer('running_var', torch.ones(num_features))self.register_buffer('num_batches_tracked', torch.tensor(0, dtype=torch.long))else:self.register_parameter('running_mean', None)self.register_parameter('running_var', None)self.register_parameter('num_batches_tracked', None)self.reset_parameters()def reset_running_stats(self):if self.track_running_stats:self.running_mean.zero_()self.running_var.fill_(1)self.num_batches_tracked.zero_()def reset_parameters(self):self.reset_running_stats()if self.affine:nn.init.uniform_(self.weight)nn.init.zeros_(self.bias)def _check_input_dim(self, input):raise NotImplementedErrordef forward(self, inputs_mean, inputs_variance):# exponential_average_factor is self.momentum set to# (when it is available) only so that if gets updated# in ONNX graph when this node is exported to ONNX.if self.momentum is None:exponential_average_factor = 0.0else:exponential_average_factor = self.momentumif self.training and self.track_running_stats:if self.num_batches_tracked is not None:self.num_batches_tracked += 1if self.momentum is None: # use cumulative moving averageexponential_average_factor = 1.0 / float(self.num_batches_tracked)else: # use exponential moving averageexponential_average_factor = self.momentumoutputs_mean = F.batch_norm(inputs_mean, self.running_mean, self.running_var, self.weight, self.bias,self.training or not self.track_running_stats,exponential_average_factor, self.eps)outputs_variance = inputs_varianceweight = ((self.weight.unsqueeze(0)).unsqueeze(2)).unsqueeze(3)outputs_variance = outputs_variance*weight**2"""for i in range(outputs_variance.size(1)):outputs_variance[:,i,:,:]=outputs_variance[:,i,:,:].clone()*self.weight[i]**2"""if self._keep_variance_fn is not None:outputs_variance = self._keep_variance_fn(outputs_variance)return outputs_mean, outputs_variance
对于均值与方差来说,只有均值需要进行归一化,方差不需要;
而本函数添加了两个可学习的参数:
在 BatchNorm2d 类的构造函数中,当 affine 参数为 True 时,会初始化 self.weight 和 self.bias 两个可学习参数。具体来说,这里的 self.weight 是一个形状为 (num_features,) 的一维张量,用于缩放归一化后的数据。而 self.bias 也是一个形状为 (num_features,) 的一维张量,用于平移归一化后的数据。
这两个参数在 forward() 方法中会被应用于输出张量上,从而进一步提高模型的表达能力和灵活性。在 forward() 方法中,self.weight 用于对归一化后的数据进行缩放,即将均值为 0、方差为 1 的数据缩放为均值为 0、方差为 self.weight 的数据。而 self.bias 则用于对归一化后的数据进行平移,即将缩放后的数据加上一个偏置项 self.bias,从而使得模型能够适应更加复杂和多样的数据分布。
需要注意的是,如果在构造函数中将 affine 参数设为 False,则不会初始化 self.weight 和 self.bias,也就不会应用缩放和平移操作。在这种情况下,BatchNorm2d 类实际上只是对输入的数据进行了均值和方差的归一化处理,而没有引入额外的可学习参数。
adf.ReLU()
可以看到BasicBlock中使用了adf.ReLU():
class ReLU(nn.Module):def __init__(self, keep_variance_fn=None):super(ReLU, self).__init__()self._keep_variance_fn = keep_variance_fndef forward(self, features_mean, features_variance):features_stddev = torch.sqrt(features_variance)div = features_mean / features_stddevpdf = normpdf(div)cdf = normcdf(div)outputs_mean = features_mean * cdf + features_stddev * pdfoutputs_variance = (features_mean ** 2 + features_variance) * cdf \+ features_mean * features_stddev * pdf - outputs_mean ** 2if self._keep_variance_fn is not None:outputs_variance = self._keep_variance_fn(outputs_variance)return outputs_mean, outputs_variance
在 forward() 方法中,输入的参数包含两部分,即 features_mean 表示输入特征的均值,features_variance 表示输入特征的方差。在计算输出时,首先计算输入特征的标准差 features_stddev,然后计算出 cdf 和 pdf,这两个量分别表示标准正态分布的累积分布函数和概率密度函数。最后,根据 ReLU 函数的定义,对均值和方差分别进行处理,得到输出特征的均值 outputs_mean 和方差 outputs_variance。
相关文章:
)
A General Framework for Uncertainty Estimation in Deep Learning源码阅读(二)
接上文 ResNet定义: 代码使用 def ResNet18ADF(noise_variance1e-3, min_variance1e-3):return ResNet(BasicBlock, [2,2,2,2], num_classes10, noise_variance1e-3, min_variance1e-3, initialize_msraFalse)定义模型,其中ResNet定义为: …...

串行通信协议---HART协议
实际应用中,HART协议是仅次于Modbus协议的最接近统一现场总线的标准,主要是在4~20mA电流信号上面叠加数字信号,物理层采用Bell 202标准的FSK技术成功实现模拟信号和数字信号双向同时通信而互不干扰。HART协议规定了传输的物理形式、消息结构、…...
)
【独家】华为OD机试 - 寻找密码(C 语言解题)
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为od机试,独家整理 已参加机试人员的实战技巧本期题目:寻找密码 题目 小王在进行游…...

FPGA有哪些优质的带源码的IP开源网站?
这是某乎上的一个问题,我觉得还不错,今天就系统性的总结一下1、fpga4funhttps://www.fpga4fun.com/你能在这个网站上找到什么?您可以找到信息页面,以及使用 FPGA 板构建的 FPGA 项目。注重点:项目。FPGA 项目使用一种称…...
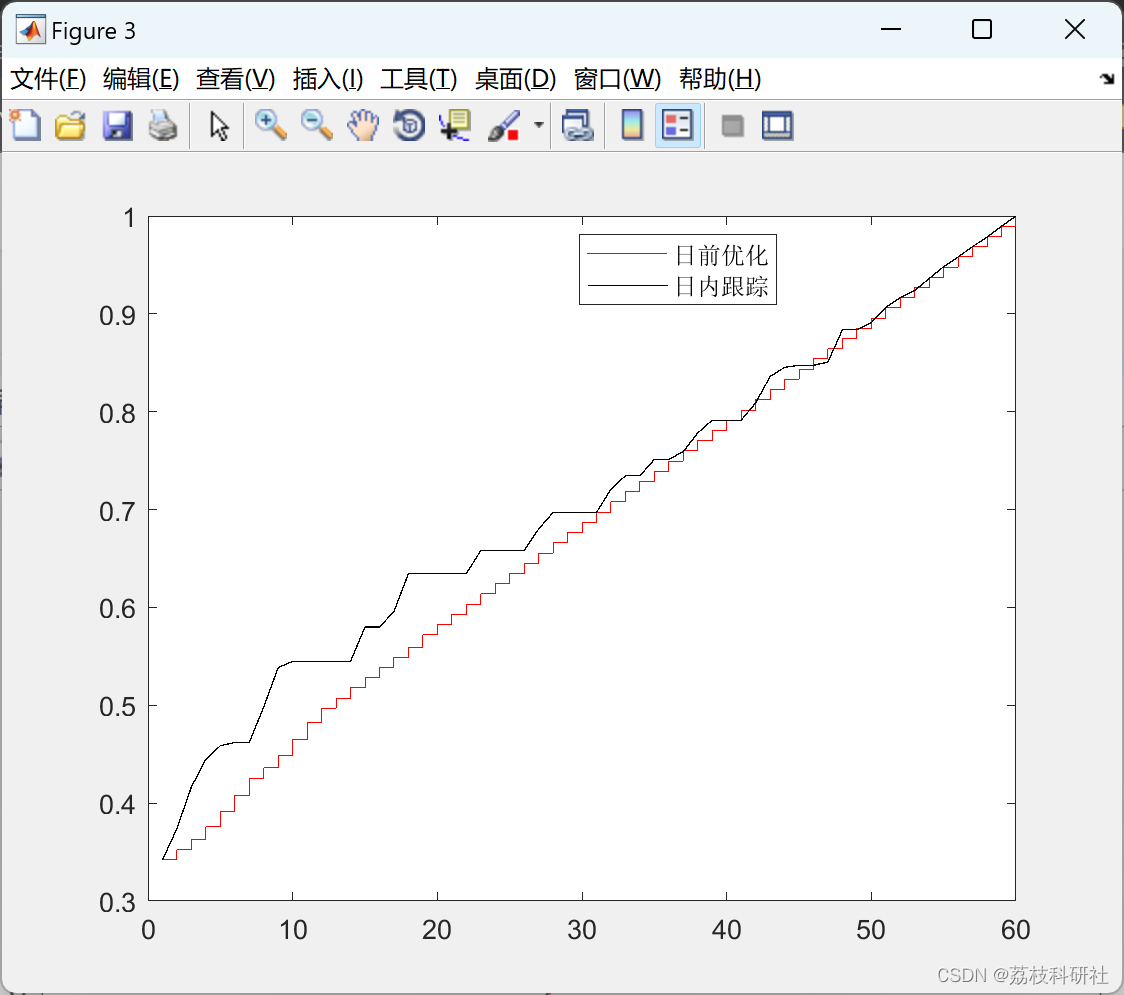
基于模型预测控制(MPC)的微电网调度优化的研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
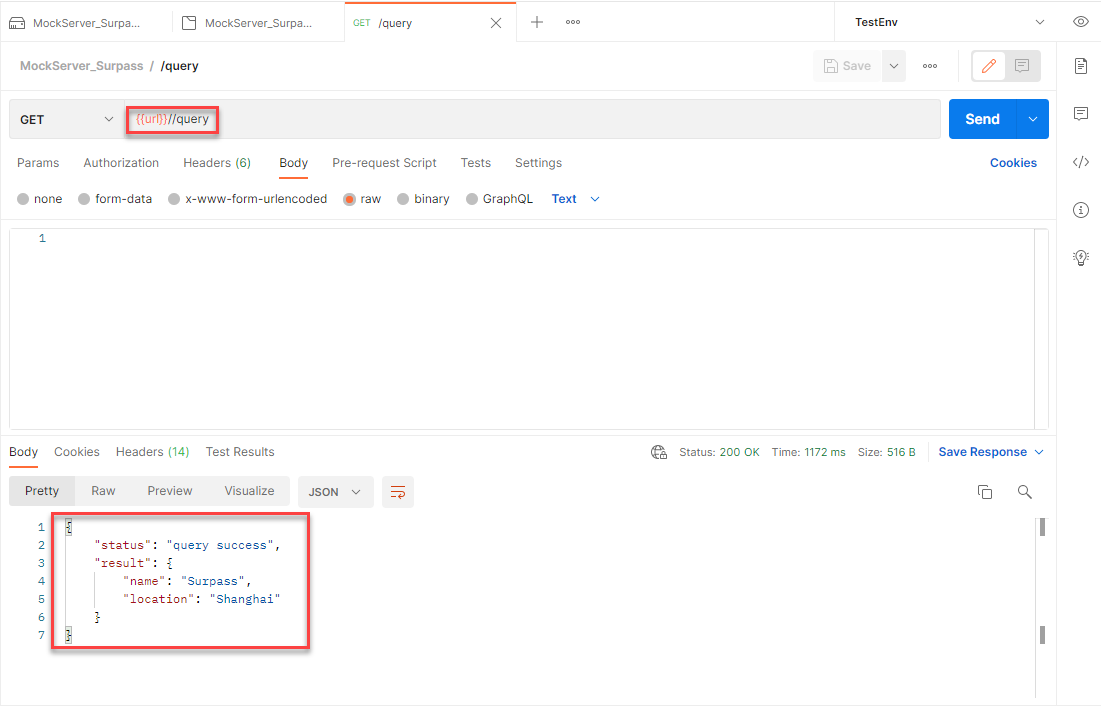
Postman接口测试之Mock快速入门
一、Mock简介 1.Mock定义 Mock是一种比较特殊的测试技巧,可以在没有依赖项的情况下进行接口或单元测试。通常情况下,Mock与其他方法的区别是,用于模拟代码依赖对象,并允许设置对应的期望值。简单一点来讲,就是Mock创建…...

分享一个国内可用的免费ChatGPT网站
背景 ChatGPT作为一种基于人工智能技术的自然语言处理工具,近期的热度直接沸腾🌋。 作为一个程序员,我也忍不住做了一个基于ChatGPT的网站,免费!免登陆!!国内可直接对话ChatGPT,也…...
)
15. 三数之和(Java)
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请 你返回所有和为 0 且不重复的三元组。 注意:答案中不可以包含重复的三元组。 示例 …...

Navicat Premium 16安装教程
1.鼠标右击【Navicat Premium 16(64bit)】压缩包(win11及以上系统需先选择“显示更多选项”)选择【解压到 Navicat Premium 16(64bit)】。 2.打开解压后的文件夹,鼠标右击【setup】选择【以管理员身份运行】。 3.点击【下一步】。 4.选择【我…...

蓝桥杯刷题冲刺 | 倒计时8天
作者:指针不指南吗 专栏:蓝桥杯倒计时冲刺 🐾马上就要蓝桥杯了,最后的这几天尤为重要,不可懈怠哦🐾 文章目录1.三角形的面积2.图中点的层次1.三角形的面积 题目 链接: 三角形的面积 - 蓝桥云课 …...

四.JAVA基础面试题:重要知识
四.JAVA基础面试题:重要知识 1.为什么JAVA只有值传递 2.JAVA获取运行时类的四种方式 四.JAVA基础面试题:重要知识 1.为什么JAVA只有值传递 实参:传递给形参的实际参数。 形参:接受实参的参数。值传递:方法接受实参…...

某面试官分享经验:看求职者第一眼,开口说第一句话,面试结果就差不多定了,准确率高达90%以上...
我们以前分享过许多经验,但大多是站在打工人的视角上,今天给大家带来一个面试官的经验:1. 看求职者第一眼,开口说第一句话,面试结果就差不多定了,准确率高达90%以上。2. 绝不考八股文,如果问技术…...

Java开发 - 消息队列之RabbitMQ初体验
目录 前言 RabbitMQ 什么是RabbitMQ RabbitMQ特点 安装启动 RabbitMQ和Kafka的消息收发区别 RabbitMQ使用案例 添加依赖 添加配置 创建RabbitMQ配置类 RabbitMQ消息的发送 RabbitMQ消息的接收 测试 结语 前言 前一篇,我们学习了Kafka的基本使用&#…...
蓝桥杯入职项目(HTML + springBoot)
文章目录需要解决npm包安装axioshttp-servedebug开发下个阶段测试运行方式注意清理磁盘缓存问题解决HTML Web项目的结构通常是基于MVC(Model-View-Controller)模式设计的。下面是一般的项目结构:index.html:项目的入口文件&#x…...

【IAR工程】STM8S208RB基于ST标准库下按键检测
【IAR工程】STM8S208RB基于ST标准库下按键检测📍相关篇《【IAR工程】STM8S208RB基于ST标准库下GPIO点灯示例》🎈《【IAR工程】STM8S208RB基于ST标准库下EXTI外部中断》🔖基于ST STM8S/A标准外设库:STSW-STM8069,版本号:2.3.1&…...
)
【5】深度学习之Pytorch——如何使用张量处理文本数据集(语料库数据集)
在计算机领域,不断崛起的两个领域,一个是CV一个是NLP,下面我们可以探索一下深度学习在NLP的应用和特点。 深度学习在自然语言处理(NLP)领域有广泛的应用。以下是一些主要的应用和特点: 语音识别࿱…...

《Spring系列》第5章 refresh()
前言 Spring框架中最重要的肯定是IOC容器,那么其如何进行初始化,就是通过refresh()这个方法,无论是单独使用Spring框架,还是SpringBoot,最终都会通过执行到这个方法,那么下面会介绍一下这个方法 一、IOC容…...
ThreeJS-缩放、旋转(四)
代码: <template> <div id"three_div"> </div> </template> <script> import * as THREE from "three"; import {OrbitControls } from three/examples/jsm/controls/OrbitControls export default { name: &quo…...

数据更新 | CnOpenData法拍房数据
法拍房数据 一、数据简介 法拍房,即“法院拍卖房产”,是被法院强制执行拍卖的房屋 。当债务人(业主)无力履行借款合约或无法清偿债务时,而被债权人经司法程序向法院申请强制执行,将债务人名下房屋拍卖&…...
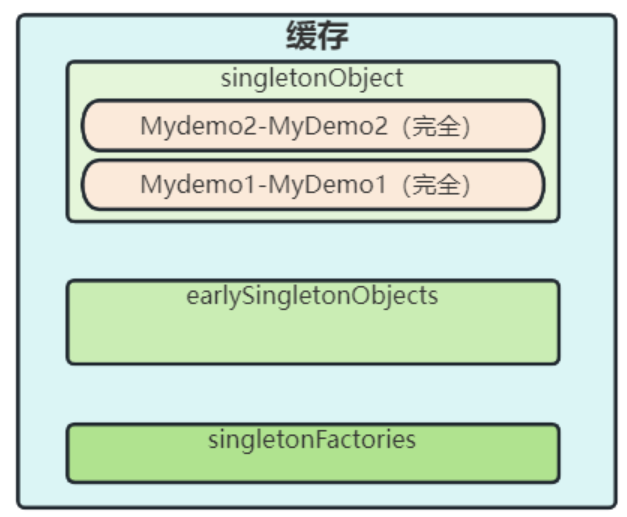
【Spring从成神到升仙系列 五】从根上剖析 Spring 循环依赖
👏作者简介:大家好,我是爱敲代码的小黄,独角兽企业的Java开发工程师,CSDN博客专家,阿里云专家博主📕系列专栏:Java设计模式、数据结构和算法、Kafka从入门到成神、Kafka从成神到升仙…...

LeetCode每日练习题---49.字母异位词分组
49.字母异位词分组 条件 已知: 字符串数组 目标: 将字母异位词组合在一起 思想(时间复杂度太高超时了) 我的想法是,双重遍历的暴力方法 , 先对字符串数组中的元素进行遍历 ,第一层遍历ÿ…...

QMCFLAC2MP3终极指南:一键解锁QQ音乐格式限制的完整解决方案
QMCFLAC2MP3终极指南:一键解锁QQ音乐格式限制的完整解决方案 【免费下载链接】qmcflac2mp3 直接将qmcflac文件转换成mp3文件,突破QQ音乐的格式限制 项目地址: https://gitcode.com/gh_mirrors/qm/qmcflac2mp3 你是否曾经从QQ音乐下载了心爱的歌曲…...

2025届必备的AI学术方案实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在当下的学术写作情形里,免费的人工智能论文工具达成了从文献查找、大纲制作直至…...

别再死记硬背了!用‘借位法’5分钟搞定子网划分,网工面试必看
别再死记硬背了!用‘借位法’5分钟搞定子网划分,网工面试必看 刚入行的网络工程师最怕什么?十个人里有九个会说是子网划分。那些密密麻麻的二进制数字、复杂的计算公式,简直像天书一样让人望而生畏。但今天我要告诉你一个秘密&…...

EPSON机器人通信避坑指南:TCP/IP协议在LS3-401S上的常见问题与解决方案
EPSON机器人通信避坑指南:TCP/IP协议在LS3-401S上的常见问题与解决方案 在工业自动化领域,EPSON LS3-401S机器人凭借其高精度和可靠性广受青睐。然而,在实际部署过程中,TCP/IP通信问题往往成为工程师们的"拦路虎"。本文…...

WMIC命令行高效卸载Windows软件:从入门到精通
1. 为什么选择WMIC卸载软件? 每次电脑卡顿的时候,打开C盘一看,总会被各种不明所以的软件占满空间。传统的卸载方式要经过"控制面板-程序和功能-找到目标-点击卸载"的繁琐流程,而WMIC只需要几行命令就能搞定。我在帮同事…...

告别云服务器开销:手把手教你用Docker Compose在本地Linux虚拟机部署Dify
告别云服务器开销:手把手教你用Docker Compose在本地Linux虚拟机部署Dify 在云计算成本不断攀升的今天,越来越多的独立开发者和小团队开始寻求更经济高效的解决方案。对于数据敏感型项目或内部测试环境而言,本地化部署不仅能显著降低长期运营…...

openclaw里面如何添加channel
在 OpenClaw 中添加 Channel(消息通道 / 渠道),核心是通过 CLI 命令 或直接编辑 配置文件,将 Telegram、Discord、飞书、WhatsApp 等 IM 平台接入网关(Gateway),并绑定到 Agent。以下是完整、可…...

3款高效AI答题工具助力B站硬核会员试炼
3款高效AI答题工具助力B站硬核会员试炼 【免费下载链接】bili-hardcore bilibili 硬核会员 AI 自动答题脚本,直接调用 B 站 API,非 OCR 实现 项目地址: https://gitcode.com/gh_mirrors/bi/bili-hardcore B站硬核会员试炼要求用户在100道专业题目…...

2026最权威的十大降AI率神器实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 想切实降低文本的AIGC率,重点在于削减机器生成的规律性迹象。给出如下方法提议&a…...