NLP自然语言处理
计算机视觉和图像处理
- Tensorflow入门
- 深度神经网络
- 图像分类
- 目标检测
- 图像分割
- OpenCV
- Pytorch
- NLP自然语言处理
NLP自然语言处理
- 一、NLP简介
- 二、文本预处理
- 2.1 文本预处理简介
- 2.2 文本处理的基本方法
- 2.3 文本张量表示方法
- 2.3.1 onehot编码
- 2.3.2 word2vec编码
- 2.4 文本数据分析
- 2.5 文本特征处理
- 2.5.1 添加n_grams特征
- 2.5.2 文本长度规范
- 2.6 文本数据增强
- 三、HMM和CRF
- 四、RNN架构解析
- 4.1 RNN模型简介
- 4.2 传统RNN的使用
- 4.3 LSTM模型的使用
- 4.4 GRU模型的使用
- 4.5 注意力机制
- 五、RNN经典案例——人名分类器
- 五、Transformer
一、NLP简介
自然语言处理(Natural Language Processing,简称 NLP)是计算机科学、人工智能和语言学的一个分支,旨在使计算机能够理解、解释和生成人类的自然语言。NLP 的目标是弥合人类通信和计算机理解之间的差距,使得计算机能够以更智能、更有效的方式处理文本和语音数据。
NLP 的主要任务
- 文本分类:
- 情感分析:判断文本的情感倾向,如正面、负面或中性。
- 主题分类:将文档归类到预定义的主题类别中。
- 垃圾邮件检测:识别电子邮件或消息是否为垃圾信息。
- 命名实体识别(NER):
- 识别文本中的特定实体,如人名、地名、组织名、日期等。
- 关系抽取:
- 从文本中提取实体之间的关系,如“奥巴马是美国的总统”。
- 句法分析:
- 词性标注:为每个词标注其词性(名词、动词、形容词等)。
- 依存关系分析:分析句子中词与词之间的依存关系。
- 语义分析:
- 语义角色标注:识别句子中的谓词及其论元。
- 共指消解:确定文本中哪些词语指的是同一个实体。
- 机器翻译:
- 将一种自然语言翻译成另一种自然语言,如将英文翻译成中文。
- 对话系统:
- 聊天机器人:构建能够与用户进行自然对话的系统。
- 语音识别:将语音信号转换为文本。
- 语音合成:将文本转换为语音信号。
- 文本生成:
- 自动摘要:生成文本的简洁摘要。
- 创意写作:生成诗歌、故事等创意文本。
NLP 的技术方法
- 统计方法:
- 使用统计模型(如朴素贝叶斯、支持向量机、隐马尔可夫模型等)来处理文本数据。
- 深度学习方法:
- 循环神经网络(RNN):处理序列数据,适用于文本生成和序列标注任务。
- 长短期记忆网络(LSTM):改进的 RNN,能够更好地处理长依赖问题。
- Transformer 模型:基于自注意力机制的模型,广泛应用于各种 NLP 任务,如 BERT、GPT 等。
- 卷积神经网络(CNN):用于提取局部特征,适用于文本分类任务。
二、文本预处理
2.1 文本预处理简介
文本语料在输送给模型前一般需要一系列的预处理工作, 才能符合模型输入的要求, 如: 将文本转化成模型需要的张量, 规范张量的尺寸等, 而且科学的文本预处理环节还将有效指导模型超参数的选择, 提升模型的评估指标.
2.2 文本处理的基本方法
分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。
分词的作用:
词作为语⾔语义理解的最小单元, 是⼈类理解文本语言的基础. 因此也是AI解决NLP领域高阶任务, 如自动问答, 机器翻译, 文本生成的重要基础环节.
jieba分词器
使用jieba前需要先导包,在命令行输入:pip install jieba

- 精确模式分词,试图将句子最精确地切开,适合文本分析.
import jieba# 精确模式分词,cut_all=False
content = "它的主要功能是作为Jupyter的内核,允许 Jupyter Notebook与不同的Python环境进行交互。"
jieba.cut(content,cut_all=False)
返回一个生成器对象

# lcut直接显示分词内容
words = jieba.lcut(content)
result = ' '.join(words)
result

- 全模式分词,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能消除歧义
# 全模式分词,cut_all=True
content = "它的主要功能是作为Jupyter的内核,允许 Jupyter Notebook与不同的Python环境进行交互"
jieba.cut(content,cut_all=True)

words = jieba.lcut(content)
result = ' '.join(words)
result

- 搜索引擎模式分词,在精确模式的基础上,对长词再次切分,提高召回率。
# 搜索引擎模式分词
content = "它的主要功能是作为Jupyter的内核,允许 Jupyter Notebook与不同的Python环境进行交互"
jieba.cut_for_search(content)words = jieba.lcut_for_search(content)
result = ' '.join(words)
result

- 中文繁体分词
content = "煩惱即是菩提,我暫且不提"
jieba.cut(content,cut_all=False)
jieba.lcut(content)

- 自定义词典分词
# 使用不了自定义词典,加载不到userdict.txt! 但方法就是这方法
jieba.load_userdict("./userdict.txt")
jieba.lcut("⼋⼀双⿅更名为⼋⼀南昌篮球队!")
- 使用jieba进行中文词性标注
# 使用jieba进行中文词性标注
import jieba.posseg as pseg
pseg.lcut("我爱北京天安门")

2.3 文本张量表示方法
2.3.1 onehot编码
# 用于对象的保存和加载
import joblib
from tensorflow.keras.preprocessing.text import Tokenizer
# onehot编码
words = {"周杰伦", "陈奕迅", "王力宏", "李宗盛", "吴亦凡", "鹿晗"}# 实例化词汇映射器对象
# char_level词汇单位是单词而不是字符
t = Tokenizer(num_words=None,char_level=False)
# 拟合现有的文本数据
t.fit_on_texts(words)
print(f"词汇表及索引:{t.word_index}")for word in words:one_hot = [0]*len(words)# texts_to_sequences将当前词汇转换为其在词汇表中的索引位置# 返回样式[[1]]、[[2]]等word_index = t.texts_to_sequences([word])[0][0] - 1one_hot[word_index] = 1print(f"{word} 的one-hot编码为:{one_hot}")#保存映射
tokenizer_path = "./Tokenizer"
joblib.dump(t,tokenizer_path)

# onehot编码器的使用# 加载之间保存的Tokenizer
t = joblib.load(tokenizer_path)
# 编码王力宏
word = "王力宏"
word_index = t.texts_to_sequences([word])[0][0] - 1
one_hot[word_index] = 1
print(f"{word}的one-hot编码为:{one_hot}")

2.3.2 word2vec编码
fasttext包我导不进来,调了两三个小时!
import fasttext# 第一步:获取训练数据
data = ["周杰伦是一位著名的歌手","陈奕迅的歌曲非常受欢迎","王力宏的音乐风格多样","李宗盛的歌词很有深度","吴亦凡出演过多部电影","鹿晗在社交媒体上非常活跃"
]# 将数据写入文件
with open('train.txt', 'w', encoding='utf-8') as f:for line in data:f.write(line + '\n')# 第二步:训练词向量
# 模型超参数设定
model = fasttext.train_unsupervised('train.txt',model='cbow', # 模型类型:cbow 或 skipgramdim=100, # 词向量的维度ws=5, # 窗口大小epoch=5, # 训练轮数minCount=1 # 最小词频
)# 第四步:模型效果检验
vector = model.get_word_vector("周杰伦")
print(f"周杰伦的词向量: {vector}")similar_words = model.get_nearest_neighbors("周杰伦", k=5)
print(f"与周杰伦最相似的词: {similar_words}")# 第五步:模型的保存与重加载
model.save_model("model.bin")# 重加载模型
loaded_model = fasttext.load_model("model.bin")# 检查重加载的模型
vector = loaded_model.get_word_vector("周杰伦")
print(f"重加载后周杰伦的词向量: {vector}")similar_words = loaded_model.get_nearest_neighbors("周杰伦", k=5)
print(f"重加载后与周杰伦最相似的词: {similar_words}")
2.4 文本数据分析
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
- 绘制数据标签数量分布
# 读取数据
# TSV文件使用制表符(\t)作为分隔符
train_data = pd.read_csv("./train.tsv", sep='\t')
test_data = pd.read_csv("./dev.tsv", sep='\t')# 绘制数据标签数量分布
sns.countplot(x="label",data=train_data)
plt.title("train_data")
plt.show()sns.countplot(x="label",data=test_data)
plt.title("test_data")
plt.show()

在深度学习模型评估中, 我们一般使用ACC作为评估指标, 若想将ACC的基线定义在50%左右, 则需要我们的正负样本比例维持在1:1左右, 否则就要进行必要的数据增强或数据删减. 上图中训练和验证集正负样本都稍有不均衡, 可以进行一些数据增强.
- 绘制句子长度分布图
# 获取训练集和验证集的句子长度分布
train_data["sentence_length"] = list(map(lambda x:len(x),train_data["sentence"]))
test_data["sentence_length"] = list(map(lambda x:len(x),test_data["sentence"]))sns.countplot(x="sentence_length",data=train_data)
plt.xticks([])
plt.show()# 绘制dist长度分布图
sns.distplot(train_data["sentence_length"])
plt.yticks([])
plt.show()sns.countplot(x="sentence_length",data=test_data)
plt.xticks([])
plt.show()# 绘制dist长度分布图
sns.distplot(test_data["sentence_length"])
plt.yticks([])
plt.show()




通过绘制句子长度分布图, 可以得知我们的语料中大部分句子长度的分布范围, 因为模型的输入要求为固定尺寸的张量,合理的长度范围对之后进行句子截断补齐(规范长度)起到关键的指导作用. 上图中大部分句子长度的范围大致为20-250之间.
- 绘制样本长度散点图
# 获取训练集和验证集的正负样本长度散点分布
sns.stripplot(x="label",y="sentence_length",data=train_data)
plt.show()sns.stripplot(x="label",y="sentence_length",data=test_data)
plt.show()


通过查看正负样本长度散点图, 可以有效定位异常点的出现位置, 帮助我们更准确进行人工语料审查. 上图中在训练集正样本中出现了异常点, 它的句子长度近3500左右, 需要我们人工审查。
- 统计不同词汇总数
# 获取训练集和验证集不同词汇总数统计
import jieba
# 使用chain方法扁平化列表
from itertools import chain# 对训练集的句子进行分词,并统计出不同词汇的总数
# 解包操作符 * 将 map 返回的迭代器中的每个列表展开,使 chain 能够将它们连接在一起。
train_words = set(chain(*map(lambda x:jieba.lcut(x),train_data["sentence"])))
print("训练集共包含不同词汇总数为:",len(train_words))test_words = set(chain(*map(lambda x:jieba.lcut(x),test_data["sentence"])))
print("训练集共包含不同词汇总数为:",len(test_words))

- 绘制高频形容词词云
# 获得训练集上正负样本的高频形容词词云# 使⽤jieba中的词性标注功能
import jieba.posseg as pseg
from wordcloud import WordCloud
# 获取形容词
def get_list(text):r =[]for g in pseg.lcut(text):if g.flag == 'a':r.append(g.word)return r# 绘制词云
def get_word_cloud(keywords_list):# 实例化绘制词云类wordcloud = WordCloud(font_path="./SimHei.ttf",max_words=100,background_color="white")# 将传入的列表转化为字符串keywords_string = ' '.join(keywords_list)# 生成词云wordcloud.generate(keywords_string)# 绘制图像plt.figure(figsize=(10,8))plt.imshow(wordcloud)plt.axis('off')plt.show()# 获得训练集上正样本
p_train_data = train_data[train_data["label"]==1]['sentence']
# 获取形容词
p_train_adj = chain(*map(lambda x:get_list(x),p_train_data))# 获得训练集上负样本
n_train_data = train_data[train_data["label"]==0]['sentence']
# 获取形容词
n_train_adj = chain(*map(lambda x:get_list(x),n_train_data))get_word_cloud(p_train_adj)
get_word_cloud(n_train_adj)


根据高频形容词词云显示, 我们可以对当前语料质量进行简单评估, 同时对违反语料标签含义的词汇进行人工审查和修正, 来保证绝大多数语料符合训练标准. 上图中的正样本大多数是褒义词, 而负样本⼤多数是贬义词, 基本符合要求, 但是负样本词云中也存在"便利"这样的褒义词, 因此可以人工进行审查.
2.5 文本特征处理
2.5.1 添加n_grams特征
n-gram 是自然语言处理(NLP)中的一种常用技术,通过将文本分割成连续的子序列(称为“n-grams”)来捕捉文本中的局部结构。
import jieba
# CountVectorizer用于将文本数据转换为数值型特征向量
from sklearn.feature_extraction.text import CountVectorizer# 示例文本
documents = ["我喜欢编程,Python 很强大","今天天气真好,适合出去玩","Python 是一门强大的编程语言"
]# 分词
tokenized_documents = [" ".join(jieba.cut(doc)) for doc in documents]# 创建 CountVectorizer 实例,指定 n-gram 范围
# ngram_range=(2, 2) 生成两个词和双组合的n_grams
vectorizer = CountVectorizer(ngram_range=(2, 2)) # 拟合并转换文本数据
# 首先学习词汇表,然后将文档转换为词频矩阵。
x = vectorizer.fit_transform(tokenized_documents)# 获取特征名称
# 返回词汇表中的所有特征名称,包含所有生成的 n-gram 特征名称
feature_names = vectorizer.get_feature_names_out()# 打印特征名称和对应的计数值
print("Feature names:", feature_names)
# n-gram出现的次数
print("Counts:\n", x.toarray())

2.5.2 文本长度规范
# 截断文本到指定的最大长度
def truncate_text(text, max_length, truncation_type='end'):if len(text) > max_length:if truncation_type == 'start':return text[:max_length]elif truncation_type == 'middle':start = (len(text) - max_length) // 2return text[start:start + max_length]else: # 'end'return text[-max_length:]return text# 填充文本到指定的最大长度
def pad_text(text, max_length, padding_token='<PAD>', padding_type='post'):if len(text) < max_length:num_padding = max_length - len(text)if padding_type == 'pre':return (padding_token * num_padding) + textelse: # 'post'return text + (padding_token * num_padding)return text# 规范化文本长度,先截断再填充
def normalize_text_length(text, max_length, truncation_type='end', padding_token='<PAD>', padding_type='post'):# 截断truncated_text = truncate_text(text, max_length, truncation_type)# 填充normalized_text = pad_text(truncated_text, max_length, padding_token, padding_type)return normalized_text# 示例文本
texts = ["This is a short sentence.","This is a much longer sentence that needs to be truncated or padded to fit the specified length.","Another example sentence."
]# 设置最大长度
max_length = 27# 规范化文本长度
normalized_texts = [normalize_text_length(text, max_length) for text in texts]# 打印结果
for original, normalized in zip(texts, normalized_texts):print(f"Original: {original}")print(f"Normalized: {normalized}\n")

2.6 文本数据增强
回译数据增强法
是将源语言的句子翻译成另一种语言,然后再将翻译后的句子翻译回源语言,从而生成新的训练样本。这种方法可以增加训练数据的多样性,提高模型的泛化能力。
from transformers import MarianMTModel,MarianTokenizer
import torch# 加载中文到英文的翻译模型和分词器
# huggingFace官网进不去,无法下载Helsinki-NLP/opus-mt-zh-en
model_name_zh_to_en = "Helsinki-NLP/opus-mt-zh-en"
tokenizer_zh_to_en = MarianTokenizer.from_pretrained(model_name_zh_to_en)
model_zh_to_en = MarianMTModel.from_pretrained(model_name_zh_to_en)# 加载英文到中文你的翻译模型和分词器
model_name_en_to_zh = 'Helsinki-NLP/opus-mt-en-zh'
tokenizer_en_to_zh = MarianTokenizer.from_pretrained(model_name_en_to_zh)
model_en_to_zh = MarianMTModel.from_pretrained(model_name_en_to_zh)# 翻译文本
def translate(text,tokenizer,model):# 将文本转换为模型可以处理的数值形式inputs = tokenizer(text,return_tensors="pt")print(inputs)with torch.no_grad:# **操作符用于解包字典,将字典中的键值对作为关键字参数传递给函数。outputs = model.generate(**inputs)# 将生成的张量解码为文本translated_text = tokenizer.batch_decode(outputs,skip_special_tokens=True)return translated_text# 回译文本
def back_translate(text,tokenizer1,model1,tokenizer2,model2):# zh_to_entranslated_text = translate(text,tokenizer1,model1)# en_to_zhback_translated_text = translate(translated_text,tokenizer2,model2)return back_translated_texttexts = ["这是一个简短的句子。","这是一个需要回译的较长句子。","另一个示例句子。"
]back_translated_texts = [back_translate(text,tokenizer_zh_to_en, model_zh_to_en, tokenizer_en_to_zh, model_en_to_zh) for text in texts]for original,back_translated in zip(texts,back_translated_texts):print(f"Original:{original}")print(f"Back_Translated:{back_translated}")
三、HMM和CRF
HMM和CRF慢慢淡出⼈们的视野
HMM 是一种用来预测隐藏状态的模型。想象你有一串观察到的数据(比如一句话中的单词),你想要知道每个单词背后隐藏的状态(比如每个单词的词性。
CRF是一种用来预测输出序列的模型,它直接根据输入序列来预测输出序列,而不是像 HMM 那样通过隐藏状态来间接预测。
四、RNN架构解析
4.1 RNN模型简介
RNN,中文称作循环神经网络,他一般以序列数据为输入,通过网络内部的结构设计有效捕捉序列之间的关系特征,一般也是以序列形式进行输出。
RNN 的基本概念
循环结构:
- RNN 的核心特点是其循环结构,这意味着网络中的某些节点不仅接收当前时间步的输入,还接收前一个时间步的隐藏状态。
- 这种结构使得 RNN 能够捕捉输入序列中的时间依赖关系。
隐藏状态:
- RNN 维护一个隐藏状态(hidden state),它在每个时间步更新。
- 隐藏状态可以看作是网络的记忆,用于存储过去的信息。
时间步:
- 在处理序列数据时,每个时间步对应序列中的一个元素。
- 例如,在处理一个句子时,每个时间步可以对应一个单词。
RNN模型的作用
因为RNN结构能够很好利用序列之间的关系, 因此针对自然界具有连续性的输入序列, 如人类的语言, 语音等进行很好的处理, 广泛应用于NLP领域的各项任务, 如文本分类, 情感分析, 意图识别, 机器翻译等。
4.2 传统RNN的使用
import torch
import torch.nn as nn
# 实例化RNN对象
# 第一个参数:input_size输入张量x的维度
# 第二个参数:hidden_size隐藏层的维度,隐藏层神经元个数
# 第三个参数:num_layers隐藏层的层数
rnn = nn.RNN(5,6,1)
# 设定输入张量x
# 第一个参数:sequence_length输入序列的长度,时间步
# 第二个参数:batch_size批次的样本数
# 第三个参数:input_size输入张量x的维度
inputs = torch.randn(1,3,5)
# 创建初始隐藏状态张量
# 第一个参数:num_layers隐藏层的层数
# 第二个参数:batch_size批量大小
# 第三个参数:hidden_size隐藏层的维度
h0 = torch.randn(1,3,6)# 运行RNN
output,hn = rnn(inputs,h0)# RNN 的输出张量
print(output)
# 最后一个时间步的隐藏状态张量
print(hn)

4.3 LSTM模型的使用
LSTM也称长短时记忆结构,它是传统RNN的变体,与经典RNN相比能够有效捕捉长序列之间的语义关联,缓解梯度消失或爆炸现象。
import torch
import torch.nn as nn# 实例化LSTM
# 第一个参数:input_size输入特征维度
# 第二个参数:hidden_size隐藏层的状态维度
# 第三个参数:num_layers隐藏层数量,表示两层LSTM单元
rnn = nn.LSTM(5,6,2)# 设定LSTM的输入
# 第一个参数:sequence_length序列长度
# 第二个参数:batch_size批量大小
# 第三个参数:input_size输入特征维度
input = torch.randn(2,3,5)# 初始化隐藏层状态和细胞状态
# 第一个参数:num_layers隐藏层数量
# 第二个参数:batch_size批量大小
# 第三个参数:hidden_size输入特征维度
h0 = torch.randn(2,3,6)
c0 = torch.randn(2,3,6)# cn最后一个细胞状态张量
output,(hn,cn) = rnn(input,(h0,c0))# 遍历 output 的每个时间步
for i in range(output.size(0)):print(f"Output at time step {i}:")print(output[i])

4.4 GRU模型的使用
GRU也称门控循环单元结构,它是传统RNN的变体,能够有效捕捉长序列之间的语义关联,缓解梯度消失或爆炸现象。
import torch
import torch.nn as nnrnn = nn.GRU(5,6,2)
input = torch.randn(1,3,5)
h0 = torch.randn(2,3,6)output,hn = rnn(input,h0)
output

4.5 注意力机制
注意力机制是一种在深度学习模型中用于增强模型对输入序列中重要部分的关注的技术。注意力机制的核心思想是让模型在处理每个时间步时,能够动态地关注输入序列中的不同部分,从而提高模型的性能和解释性。
注意力机制的基本概念
查询(Query):
- 查询是模型在当前时间步的输入或隐藏状态,用于决定应该关注输入序列的哪些部分。
键(Key):
- 键是输入序列中的每个元素的表示,用于与查询进行匹配。
值(Value):
- 值是输入序列中的每个元素的表示,用于生成最终的加权和。
注意力分数:
- 注意力分数是查询与键之间的相似度度量,通常通过点积或加性方法计算。
注意力权重:
- 注意力权重是对注意力分数进行归一化后的结果,通常使用 softmax 函数。
上下文向量:
- 上下文向量是值的加权和,权重由注意力权重确定。
import torch
import torch.nn as nn
import torch.nn.functional as Fclass Attention(nn.Module):def __init__(self,query_dim,key_dim,value_dim):super(Attention,self).__init__()# 缩放因子self.scale = 1.0/(key_dim ** 0.5)def forward(self,query,key,value):# query: (batch_size, query_dim)# key: (batch_size, seq_len, key_dim)# value: (batch_size, seq_len, value_dim)# 计算注意力分数scores = torch.bmm(query.unsqueeze(1),key.transpose(1,2)) #(batch_size, 1, seq_len)# 防止点积结果过大导致梯度消失或爆炸scores = scores * self.scale# 计算注意力权重,表示每个查询向量对每个键向量的注意力权重attn_weights = F.softmax(scores,dim=2) # (batch_size, 1, seq_len)# 计算上下文向量context = torch.bmm(attn_weights,value).squeeze(1) # (batch_size, value_dim)return attn_weights,contextbatch_size = 2
query_dim = 10
key_dim = 10
value_dim = 15
seq_len = 5# 随机生成输入
query = torch.randn(batch_size, query_dim)
key = torch.randn(batch_size, seq_len, key_dim)
value = torch.randn(batch_size, seq_len, value_dim)# 创建注意力机制实例
attention = Attention(query_dim, key_dim, value_dim)# 计算注意力
context, attn_weights = attention(query, key, value)print("Context Vector:", context)
print("Attention Weights:", attn_weights)

五、RNN经典案例——人名分类器
点击跳转新的页面进行查看:人名分类器
五、Transformer
正在学习ing
相关文章:
NLP自然语言处理
计算机视觉和图像处理 Tensorflow入门深度神经网络图像分类目标检测图像分割OpenCVPytorchNLP自然语言处理 NLP自然语言处理 一、NLP简介二、文本预处理2.1 文本预处理简介2.2 文本处理的基本方法2.3 文本张量表示方法2.3.1 onehot编码2.3.2 word2vec编码 2.4 文本数据分析2.5…...

web自动化测试基础(从配置环境到自动化实现登录测试用例的执行,vscode如何导入自己的python包)
接下来的一段时间里我会和大家分享自动化测试相关的一些知识希望大家可以多多支持,一起进步。 一、环境的配置 前提安装好了python解释器并配好了环境,并安装好了VScode 下载的浏览器和浏览器驱动需要一样的版本号(只看大版本)。 1、安装浏览器 Chro…...
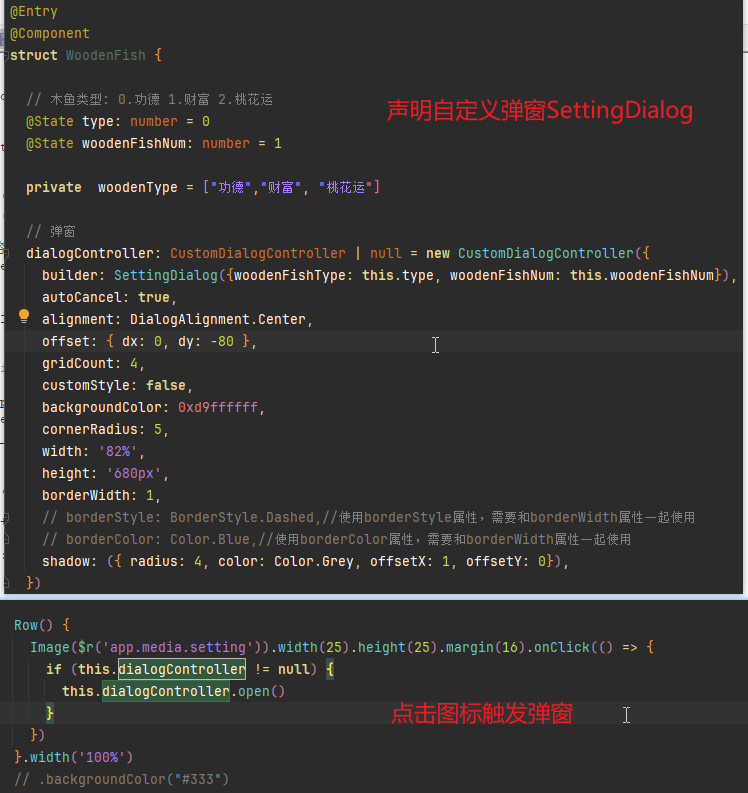
鸿蒙 Next 实战: 电子木鱼
前言 正所谓:Hello Word 是程序员学任何一门语言的第一个程序实践。这其实也是一个不错的正反馈,那如何让学习鸿蒙 Next 更有成就感呢?下面就演示一下从零开发一个鸿蒙 Next 版的电子木鱼,主打就是一个抽象! 实现要点…...

SQLite SQL调优指南及高级SQL技巧
记忆已更新 以下是《SQLite SQL调优指南及高级SQL技巧》文章的完整输出,字数目标为30000字,详细介绍并结合2024年最新技术趋势和优化策略。代码部分不计入字数统计。 SQLite SQL调优指南及高级SQL技巧 SQLite 是广泛使用的嵌入式数据库,因其…...
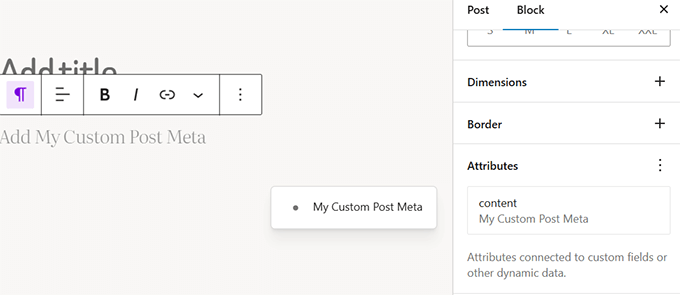
WordPress 6.7即将发布的新功能(和截图)
我们一直在密切关注 WordPress 6.7 的开发并测试该版本的测试版,它将带来一些令人兴奋的更新和几个新功能。 例如,我们很高兴地发现即将发布的版本将附带全新的默认主题,并对块编辑器和站点编辑体验进行大规模改进。 在本文中,我…...

SpringBoot整合QQ邮箱
SpringBoot可以通过导入依赖的方式集成多种技术,这当然少不了我们常用的邮箱,现在本章演示SpringBoot整合QQ邮箱发送邮件.... 下面按步骤进行: 1.获取QQ邮箱授权码 1.1 登录QQ邮箱 1.2 开启SMTP服务 找到下图中的SMTP服务区域,…...

低质量数据的多模态融合方法
目录 多模态融合 低质量多模态融合的核心挑战 噪声多模态数据学习 缺失模态插补 平衡多模态融合 动态多模态融合 启发式动态融合 基于注意力的动态融合 不确定性感知动态融合 论文 多模态融合 多模态融合侧重于整合多种模态的信息,以实现更准确的预测,在自动驾驶、…...

计算机毕业设计 基于Django的在线考试系统的设计与实现 Python+Django+Vue 前后端分离 附源码 讲解 文档
🍊作者:计算机编程-吉哥 🍊简介:专业从事JavaWeb程序开发,微信小程序开发,定制化项目、 源码、代码讲解、文档撰写、ppt制作。做自己喜欢的事,生活就是快乐的。 🍊心愿:点…...
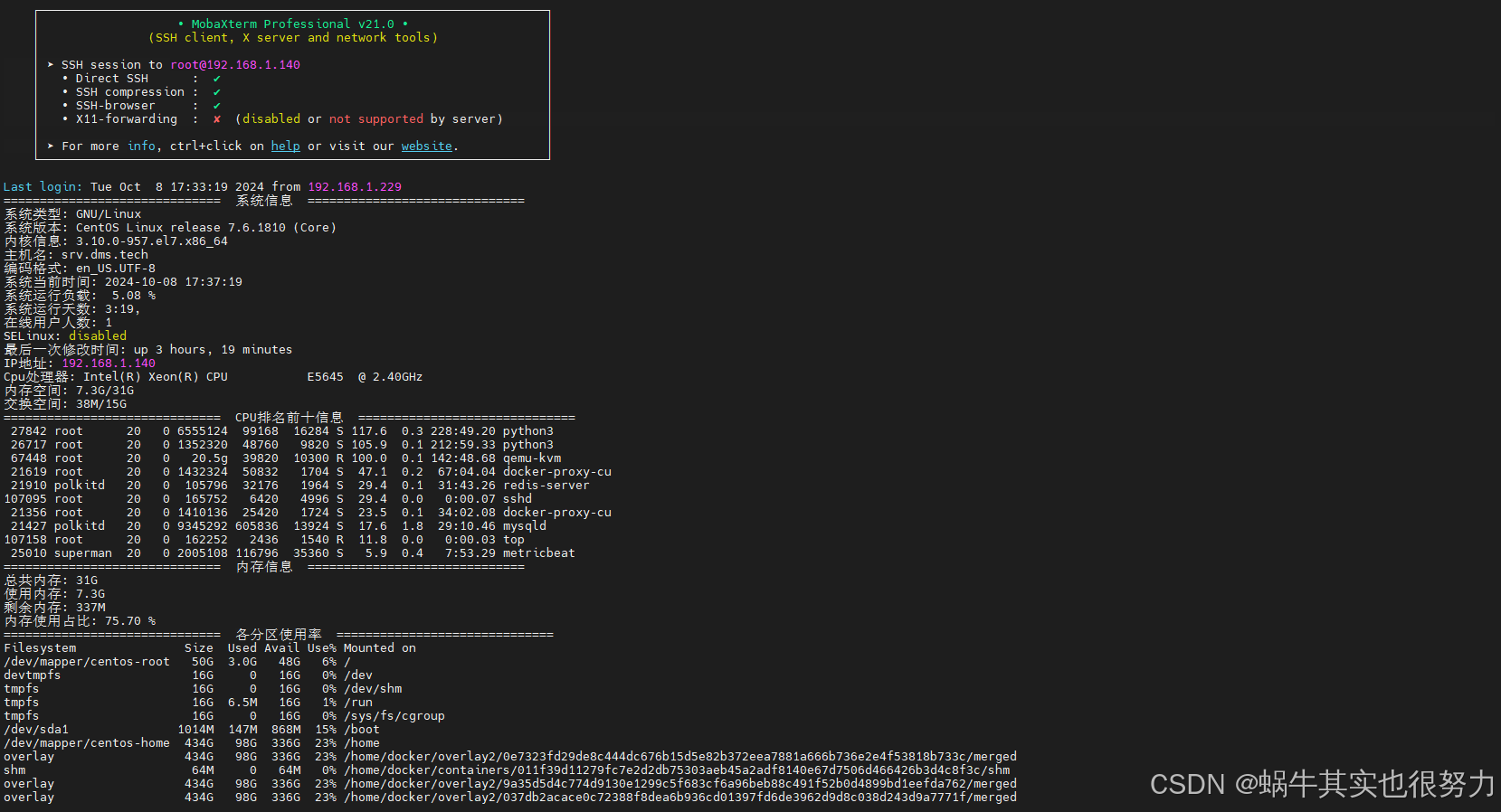
Shell脚本linux登录自动检查
.bashrc 用于设置用户的 Bash shell 环境,在每次打开一个新的终端窗口或启动一个新的 Bash 会话时被执行 代码 login_check.sh #!/bin/bash clear LogFileNamepolling.$(date %F-%T) EchoFormat$(for (( i0; i<30; i )); do echo -n ""; done)# 显示…...

Golang | Leetcode Golang题解之第450题删除二叉搜索树的节点
题目: 题解: func deleteNode(root *TreeNode, key int) *TreeNode {var cur, curParent *TreeNode root, nilfor cur ! nil && cur.Val ! key {curParent curif cur.Val > key {cur cur.Left} else {cur cur.Right}}if cur nil {retur…...

Linux 之 Linux应用编程概念、文件IO、标准IO
Linux应用编程概念、文件IO、标准IO 学习任务: 1、 学习Linux 应用开发概念,什么是系统调用,什么是库函数 2、 学习文件IO:包括 read、write、open、close、lseek 3、 深入文件IO:错误处理、exit 等 4、 学习标准IO&a…...

PDF处理技巧:Windows电脑如何选择合适的 PDF 编辑器
您可以阅读本文以了解用于在 PC 上编辑 PDF 的顶级免费软件,而无需花费任何费用即可轻松进行快速编辑、拆分、合并、注释、转换和共享您的 PDF。 PDF 或可移植文档文件是由 Adobe 创建的一种多功能文件格式。它可以帮助您轻松可靠地交换文档,无论相关方…...

【c++】初步了解类和对象2
1、类的作用域 类定义了一个新的作用域,类的所有成员都在类的作用域中。在类体外定义成员时,需要使用 :: 作用域操作符指明成员属于哪个类域。 如图,此时在类内声明了函数firstUniqChar(),在类外进行了函数体的具体定义。 但是却…...

Python库pandas之四
Python库pandas之四 输入/输出read_json函数应用实列 输入/输出 read_json 函数 词法:pandas.read_json(path_or_buf, *, orientNone, typ‘frame’, dtypeNone, convert_axesNone, convert_datesTrue, keep_default_datesTrue, precise_floatFalse, date_unitNo…...

网络攻防技术--第三次作业
文章目录 第三次作业一、通过搜索引擎搜索自己在因特网上的足迹,并确认是否存在隐私和敏感信息泄露问题。如果有信息泄露,提出解决方法。二、结合实例总结web搜索和挖掘的方法。三、网络扫描有哪几种类型?分别有什么作用?利用一种…...

带隙基准Bandgap电路学习(一)
一、原理图 Bandgap中的运放(折叠式Cascode)采用P输入对,是因为运放输入端接的PNP三极管发射极端的电位,电压小,为了确保输入对管能够饱和工作,故采用P输入对管。此外,P管作为输入管,…...

[前端][easyui]easyui select 默认值
function initRegion(key, val) {$(#Region).combobox({url: path /getTypeVaule.do?itemregion&key key "&value" val,editable: false, //不可编辑状态cache: false,valueField: TEMID,textField: TEMID,loadFilter: function (data) {data.unshift({…...

项目开发--大模型--个人问答知识库--chain控制
背景 1、langchain当中的chain prompt | llm | output_parser这个链能更长吗? 在 LangChain 中,链(chain)可以根据需要变得非常长,并且可以包含多种不同类型的组件。链的目的是将多个步骤串联起来,以便以…...

STM32—SPI通讯协议
前言 由于I2C开漏外加上拉电阻的电路结构,使得通信线高电平的驱动能力比较弱,这就会号致,通信线由候电平变到高电平的时候,这个上升沿耗时比较长,这会限制I2C的最大通信速度, 所以,I2C的标准模…...

Android 安装过程五 MSG_INSTALL消息的处理 安装
现在马上进入正式的安装流程。 从前面文章 Android 安装过程四 MSG_INSTALL消息的处理 安装之前的验证知道,在验证之后没有什么问题的情况下,会回调onVerificationComplete()方法,它位于PackageInstallerSession类中。 private void onVe…...

突破Windows资源管理器性能瓶颈:智能缩略图预加载解决方案
突破Windows资源管理器性能瓶颈:智能缩略图预加载解决方案 【免费下载链接】WinThumbsPreloader-V2 WinThumbsPreloader is a powerful open source tool for quickly preloading thumbnails in Windows Explorer. 项目地址: https://gitcode.com/gh_mirrors/wi/W…...

终极音频格式转换指南:FlicFlac让音乐文件兼容性不再是难题!
终极音频格式转换指南:FlicFlac让音乐文件兼容性不再是难题! 【免费下载链接】FlicFlac Tiny portable audio converter for Windows (WAV FLAC MP3 OGG APE M4A AAC) 项目地址: https://gitcode.com/gh_mirrors/fl/FlicFlac 还在为不同设备无法…...
)
告别PPT!用UE5.2+Lumen打造电商级产品交互展示(附MetaShoot插件实战)
用UE5.2与Lumen零代码打造电商级3D产品交互展示全指南 想象一下,当消费者在你的电商页面上不仅能360度旋转查看产品,还能像实体店一样拆解零件、切换材质,甚至模拟产品在真实环境中的使用效果——这种沉浸式体验能将转化率提升300%以上。传统…...
)
给Hadoop初学者的环境搭建备忘录:为什么你的JDK配置总在重启后‘消失’?(Linux基础解惑)
Hadoop环境搭建中的Linux系统原理:为什么你的配置总在重启后"消失"? 很多Hadoop初学者在搭建开发环境时,都会遇到一个令人困惑的问题:明明按照教程一步步配置好了JDK和Hadoop,为什么重启后环境变量就"消…...

3个核心功能+5个实战技巧:用B站神奇弹幕彻底解放你的直播双手
3个核心功能5个实战技巧:用B站神奇弹幕彻底解放你的直播双手 【免费下载链接】MagicalDanmaku 本仓库及所有相关项目已永久停止开发、维护和任何形式的分发。 项目地址: https://gitcode.com/gh_mirrors/bi/MagicalDanmaku 你是否还在直播时手忙脚乱地回复弹…...

CH340G模块除了下载程序,还能这么玩?一个硬件调试小技巧分享
CH340G模块的隐藏技能:用串口调试提升硬件开发效率 当你拿到一片CH340G模块时,第一反应可能是"这是个下载程序的好工具"。确实,这个价格亲民的小模块在51单片机开发中扮演着重要角色。但今天,我要分享的是它另一个被低估…...

终极GitHub加速解决方案:告别国内访问缓慢的完整指南
终极GitHub加速解决方案:告别国内访问缓慢的完整指南 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 对于众多国内开发…...

使用Nodejs与Taotoken构建稳定可靠的AI对话服务后端
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Nodejs与Taotoken构建稳定可靠的AI对话服务后端 在构建集成AI能力的后端服务时,开发者常常面临模型选择、API稳定性…...

Unity URP专业UI模糊效果实战指南:4步实现高性能毛玻璃界面
Unity URP专业UI模糊效果实战指南:4步实现高性能毛玻璃界面 【免费下载链接】Unified-Universal-Blur UI blur (translucent) effect for Unity. 项目地址: https://gitcode.com/gh_mirrors/un/Unified-Universal-Blur 在Unity游戏开发中,UI界面的…...

深度解析Real-ESRGAN:6B轻量模型实现专业级图像超分辨率
深度解析Real-ESRGAN:6B轻量模型实现专业级图像超分辨率 【免费下载链接】Real-ESRGAN Real-ESRGAN aims at developing Practical Algorithms for General Image/Video Restoration. 项目地址: https://gitcode.com/gh_mirrors/re/Real-ESRGAN Real-ESRGAN_…...