ML@sklearn@ML流程Part3@AutomaticParameterSearches
文章目录
- Automatic parameter searches
- demo
- model_selection::Hyper-parameter optimizers
- GridSearchCV
- eg
- RandomizedSearchCV
- eg
- Note
- RandomForestRegressor
- MSE
- pipeline交叉验证🎈
- eg
- L1@L2正则
- Next steps
- User Guide vs Tutorial
Automatic parameter searches
-
Automatic parameter search是指使用算法来自动搜索模型的最佳超参数(hyperparameters)的过程。超参数是模型的配置参数,它们不是从数据中学习的,而是由人工设定的,例如学习率、正则化强度、最大深度等。超参数的选择对模型的性能和泛化能力有很大的影响,因此选择最佳的超参数是机器学习中一个非常重要的任务。
-
自动参数搜索通常使用的算法是网格搜索(Grid Search)、随机搜索(Random Search)和贝叶斯优化(Bayesian Optimization)等。这些算法具有不同的优缺点,可以根据问题的性质和数据集的大小选择合适的算法。一般来说,网格搜索是最简单、最直观的方法,但需要搜索的空间较大时会非常耗时;随机搜索可以在更短的时间内找到合适的超参数,但可能无法在搜索空间中全面覆盖;贝叶斯优化则是一种更高级的方法,它可以根据先前的搜索结果来调整搜索空间,从而更快地找到最优解。
-
自动参数搜索的优点是可以避免手动调参的繁琐过程,同时可以更全面地搜索超参数的空间,从而得到更好的模型性能。缺点则是需要消耗大量的计算资源和时间,尤其是在搜索空间较大的情况下。因此,自动参数搜索通常用于对模型进行精细调整时,而不是在模型选择和原型开发阶段使用。
-
All estimators have parameters (often called hyper-parameters in the literature) that can be tuned.
-
The generalization power of an estimator often critically depends on a few parameters.
- For example a
RandomForestRegressorhas an_estimatorsparameter that determines the number of trees in the forest, and amax_depthparameter that determines the maximum depth of each tree.
- For example a
-
Quite often, it is not clear what the exact values of these parameters should be since they depend on the data at hand.
-
Scikit-learnprovides tools to automatically find the best parameter combinations (via cross-validation). -
In the following example, we randomly search over the parameter space of a random forest with a
RandomizedSearchCVobject. -
When the search is over, the
RandomizedSearchCVbehaves as aRandomForestRegressorthat has been fitted with the best set of parameters. Read more in the User Guide: -
3.2. Tuning the hyper-parameters of an estimator — scikit-learn documentation
demo
from sklearn.datasets import fetch_california_housing
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import RandomizedSearchCV,GridSearchCV
from sklearn.model_selection import train_test_split
from scipy.stats import randintX, y = fetch_california_housing(return_X_y=True)
iris=load_iris()
X,y=iris.data,iris.target # type: ignore
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)##
# define the parameter space that will be searched over
param_distributions = {'n_estimators': randint(1, 5),'max_depth': randint(3,6)}# now create a searchCV object and fit it to the data
#根据超参数空间,构造CV对象
RFsearch = RandomizedSearchCV(estimator=RandomForestRegressor(random_state=0),n_iter=5,param_distributions=param_distributions,verbose=3,random_state=0)
# 开始搜索(调用SearchCV对象的fit方法)
RFsearch.fit(X_train, y_train)
#从搜索结果中获取最优参数
print(RFsearch.best_params_,"@{search.best_params_}")
#计算得分
RFsearch.score(X_test, y_test)-
Fitting 3 folds for each of 12 candidates, totalling 36 fits [CV 1/3] END .......max_depth=3, n_estimators=1;, score=0.892 total time= 0.0s [CV 2/3] END .......max_depth=3, n_estimators=1;, score=0.967 total time= 0.0s [CV 3/3] END .......max_depth=3, n_estimators=1;, score=0.917 total time= 0.0s [CV 1/3] END .......max_depth=3, n_estimators=2;, score=0.908 total time= 0.0s [CV 2/3] END .......max_depth=3, n_estimators=2;, score=0.988 total time= 0.0s [CV 3/3] END .......max_depth=3, n_estimators=2;, score=0.917 total time= 0.0s [CV 1/3] END .......max_depth=3, n_estimators=3;, score=0.920 total time= 0.0s [CV 2/3] END .......max_depth=3, n_estimators=3;, score=0.992 total time= 0.0s [CV 3/3] END .......max_depth=3, n_estimators=3;, score=0.912 total time= 0.0s [CV 1/3] END .......max_depth=4, n_estimators=1;, score=0.913 total time= 0.0s [CV 2/3] END .......max_depth=4, n_estimators=1;, score=0.967 total time= 0.0s [CV 3/3] END .......max_depth=4, n_estimators=1;, score=0.917 total time= 0.0s [CV 1/3] END .......max_depth=4, n_estimators=2;, score=0.913 total time= 0.0s [CV 2/3] END .......max_depth=4, n_estimators=2;, score=0.992 total time= 0.0s [CV 3/3] END .......max_depth=4, n_estimators=2;, score=0.917 total time= 0.0s [CV 1/3] END .......max_depth=4, n_estimators=3;, score=0.923 total time= 0.0s [CV 2/3] END .......max_depth=4, n_estimators=3;, score=0.996 total time= 0.0s [CV 3/3] END .......max_depth=4, n_estimators=3;, score=0.912 total time= 0.0s [CV 1/3] END .......max_depth=5, n_estimators=1;, score=0.913 total time= 0.0s [CV 2/3] END .......max_depth=5, n_estimators=1;, score=0.967 total time= 0.0s [CV 3/3] END .......max_depth=5, n_estimators=1;, score=0.917 total time= 0.0s [CV 1/3] END .......max_depth=5, n_estimators=2;, score=0.913 total time= 0.0s [CV 2/3] END .......max_depth=5, n_estimators=2;, score=0.992 total time= 0.0s [CV 3/3] END .......max_depth=5, n_estimators=2;, score=0.917 total time= 0.0s ... [CV 1/3] END .......max_depth=6, n_estimators=3;, score=0.923 total time= 0.0s [CV 2/3] END .......max_depth=6, n_estimators=3;, score=0.996 total time= 0.0s [CV 3/3] END .......max_depth=6, n_estimators=3;, score=0.912 total time= 0.0s f{'max_depth': 4, 'n_estimators': 3} 0.9794037940379404 -
这段代码使用了Scikit-learn库中的随机搜索(Randomized Search)方法来寻找最佳的随机森林模型超参数。具体来说,该代码执行了以下步骤:
- 从Scikit-learn库中导入了California Housing数据集,随机森林回归器(RandomForestRegressor),随机搜索交叉验证(RandomizedSearchCV)和随机整数生成函数(randint)等必要的模块。
- 使用
fetch_california_housing()函数从California Housing数据集中获取数据X和目标y,并将它们分为训练集和测试集。(但是考虑该数据集较大,运行需要执行较长时间,因此改用小数据集iris) - 定义了一个超参数空间
param_distributions,包含了n_estimators和max_depth两个超参数。其中,n_estimators表示随机森林模型中树的数量,取值范围为1到5之间的随机整数;max_depth表示每棵树的最大深度,取值范围为5到10之间的随机整数。 - 创建了一个随机搜索交叉验证对象
search,并指定了它的参数,包括要搜索的超参数空间、要搜索的迭代次数(n_iter)等。 - 调用
fit()函数对search对象进行拟合,使其从训练集中寻找最佳的超参数组合。 - 输出
search对象的最佳超参数组合search.best_params_。 - 最后,使用
search对象的score()函数在测试集上评估模型的性能,并输出模型的得分。
需要注意的是,随机搜索方法在给定的超参数空间中随机抽样一组超参数进行训练,并计算其性能。因此,每次运行该代码可能会得到不同的最佳超参数组合和模型得分。
-
param_grid = {'n_estimators': [1,2,3],'max_depth': [3, 4, 5, 6] }# Create a GridSearchCV object and fit it to the data Gsearch = GridSearchCV(estimator=RandomForestRegressor(random_state=0),param_grid=param_grid,cv=3,verbose=3) Gsearch.fit(X_train, y_train)print(f"f{Gsearch.best_params_}") Gsearch.score(X_test, y_test)-
Fitting 3 folds for each of 12 candidates, totalling 36 fits [CV 1/3] END .......max_depth=3, n_estimators=1;, score=0.892 total time= 0.0s [CV 2/3] END .......max_depth=3, n_estimators=1;, score=0.967 total time= 0.0s [CV 3/3] END .......max_depth=3, n_estimators=1;, score=0.917 total time= 0.0s [CV 1/3] END .......max_depth=3, n_estimators=2;, score=0.908 total time= 0.0s [CV 2/3] END .......max_depth=3, n_estimators=2;, score=0.988 total time= 0.0s [CV 3/3] END .......max_depth=3, n_estimators=2;, score=0.917 total time= 0.0s [CV 1/3] END .......max_depth=3, n_estimators=3;, score=0.920 total time= 0.0s [CV 2/3] END .......max_depth=3, n_estimators=3;, score=0.992 total time= 0.0s [CV 3/3] END .......max_depth=3, n_estimators=3;, score=0.912 total time= 0.0s [CV 1/3] END .......max_depth=4, n_estimators=1;, score=0.913 total time= 0.0s ... [CV 1/3] END .......max_depth=6, n_estimators=3;, score=0.923 total time= 0.0s [CV 2/3] END .......max_depth=6, n_estimators=3;, score=0.996 total time= 0.0s [CV 3/3] END .......max_depth=6, n_estimators=3;, score=0.912 total time= 0.0s f{'max_depth': 4, 'n_estimators': 3} 0.9794037940379404
-
model_selection::Hyper-parameter optimizers
-
model_selection document
-
Methods Descriptions model_selection.GridSearchCV(estimator, …)Exhaustive search over specified parameter values for an estimator. model_selection.HalvingGridSearchCV(…[, …])Search over specified parameter values with successive halving. model_selection.ParameterGrid(param_grid)Grid of parameters with a discrete number of values for each. model_selection.ParameterSampler(…[, …])Generator on parameters sampled from given distributions. model_selection.RandomizedSearchCV(…[, …])Randomized search on hyper parameters. model_selection.HalvingRandomSearchCV(…[, …])Randomized search on hyper parameters. -
其中列出了
GridSearchCV、RandomizedSearchCV、HalvingGridSearchCV等类,以及它们的参数和用法。这些类可以用于寻找最佳的超参数组合,帮助用户优化模型性能。GridSearchCV通过穷举搜索超参数空间中所有的可能组合,来寻找最佳的超参数组合。RandomizedSearchCV通过随机采样超参数空间中的一些点,来寻找最佳的超参数组合。HalvingGridSearchCV通过迭代地削减搜索空间来加速网格搜索的过程,从而在更短的时间内找到最佳的超参数组合。
GridSearchCV
GridSearchCV是scikit-learn中用于进行网格搜索的类。它可以在给定的参数空间内进行全面搜索,找到最佳的超参数组合,从而优化模型性能。
GridSearchCV的使用方法比较简单,只需要定义一个超参数空间,并在其中指定要搜索的超参数及其取值范围。然后,GridSearchCV会在所有的超参数组合中进行搜索,并返回最佳的超参数组合及其对应的模型性能指标。
eg
-
下面是一个简单的
GridSearchCV的例子: -
from sklearn import svm, datasets from sklearn.model_selection import GridSearchCV# 加载数据集 iris = datasets.load_iris() X = iris.data y = iris.target# 设置要优化的超参数范围 parameters = {'kernel':('linear', 'rbf'), 'C':[1, 10]}# 创建SVM分类器对象 svc = svm.SVC()# 创建GridSearchCV对象,并设置参数 clf = GridSearchCV(svc, parameters)# 在训练集上拟合GridSearchCV对象 clf.fit(X, y)# 输出最佳的超参数组合和对应的评分 print("Best parameters set found on development set:") print(clf.best_params_) print("Best score:") print(clf.best_score_)-
Best parameters set found on development set: {'C': 1, 'kernel': 'linear'} Best score: 0.9800000000000001
-
-
这个示例使用了GridSearchCV来搜索SVC模型的最佳超参数组合。首先,加载iris数据集,并将特征矩阵和标签向量分别存储在X和y中。然后,设置要优化的超参数范围,包括kernel和C两个参数。接着,创建svm.SVC()分类器对象,并将其作为参数传递给GridSearchCV()函数,同时将超参数范围parameters也传递给该函数。然后,调用fit()方法在训练集上拟合GridSearchCV对象。最后,输出最佳的超参数组合和对应的评分。
-
需要注意的是,网格搜索是一种全面搜索方法,可以保证找到全局最优解,但计算代价比较高,尤其是在超参数空间较大的情况下。
RandomizedSearchCV
RandomizedSearchCV是scikit-learn中用于进行随机搜索的类。它可以在给定的参数空间内进行随机搜索,找到最佳的超参数组合,从而优化模型性能。RandomizedSearchCV的使用方法与GridSearchCV类似,只是它不是在所有的超参数组合中进行搜索,而是在指定的超参数分布中进行抽样。这样可以减少搜索空间,从而在更短的时间内找到最佳的超参数组合。
eg
下面是一个简单的RandomizedSearchCV的例子:
-
from sklearn.datasets import load_iris from sklearn.linear_model import LogisticRegression from sklearn.model_selection import RandomizedSearchCV from scipy.stats import uniform iris = load_iris() logistic = LogisticRegression(solver='saga', tol=1e-2, max_iter=200,random_state=0) distributions = dict(C=uniform(loc=0, scale=4),penalty=['l2', 'l1']) clf = RandomizedSearchCV(logistic, distributions, random_state=0) search = clf.fit(iris.data, iris.target) print(search.best_params_)-
{'C': 2.195254015709299, 'penalty': 'l1'}
-
-
这个示例使用了
RandomizedSearchCV来搜索LogisticRegression模型的最佳超参数组合。首先,使用load_iris()函数加载iris数据集。 -
然后,创建一个
LogisticRegression分类器对象logistic,并设置其超参数,包括solver、tol和max_iter等。 -
接着,设置要搜索的超参数空间,包括
C和penalty两个参数,其中C的分布是uniform(loc=0, scale=4),表示在0到4之间均匀分布,penalty的值是['l2', 'l1']中的一个。 -
然后,创建
RandomizedSearchCV对象clf,并传入logistic分类器对象和超参数空间distributions。调用fit()方法,在iris数据集上拟合RandomizedSearchCV对象,并返回一个search对象。最后,输出最佳的超参数组合。这个例子展示了使用
RandomizedSearchCV进行超参数优化的基本用法,包括如何设置超参数范围、创建分类器对象、拟合RandomizedSearchCV对象和输出最佳的超参数组合。与GridSearchCV不同的是,RandomizedSearchCV不会对所有可能的超参数组合进行搜索,而是在超参数空间中随机采样一些点进行搜索,可以在大数据集上更加高效。
Note
-
In practice, you almost always want to search over a pipeline, instead of a single estimator. One of the main reasons is that if you apply a pre-processing step to the whole dataset without using a pipeline, and then perform any kind of cross-validation, you would be breaking the fundamental assumption of independence between training and testing data.
-
Indeed, since you pre-processed the data using the whole dataset, some information about the test sets are available to the train sets. This will lead to over-estimating the generalization power of the estimator (you can read more in this Kaggle post).
-
Using a pipeline for cross-validation and searching will largely keep you from this common pitfall.
-
实际上,你几乎总是想要在一个pipeline上进行搜索,而不是一个单一的估计器。其中一个主要原因是,如果你在不使用pipeline的情况下对整个数据集应用预处理步骤,然后执行任何形式的交叉验证,你将违反训练和测试数据之间独立性的基本假设。
实际上,由于你使用整个数据集对数据进行预处理,因此一些关于测试集的信息可用于训练集。这将导致高估估计器的泛化能力。
-
使用pipeline进行交叉验证和搜索将大大避免这种常见的问题。🎈
RandomForestRegressor
-
RandomForestRegressor是一种基于随机森林的回归模型。 -
它是一种集成学习方法,通过组合多个决策树来提高预测的准确性和稳定性。每个决策树都是独立的,并且采用随机选择的样本和特征来进行训练。
-
在预测时,随机森林将所有决策树的预测结果进行平均或投票,以得到最终的预测结果。
-
该模型可以用于解决回归问题,例如预测房价、股票价格等连续变量的值。
-
RandomForestRegressor类是Scikit-learn中实现随机森林回归模型的类。它使用多个决策树来拟合数据,并使用Bagging方法(自助采样)来减少过拟合。在训练模型时,我们可以指定决策树的数量、每个决策树的最大深度、每个决策树使用的特征数量等参数。 -
下面是一个使用
RandomForestRegressor类来训练和预测的简单例子: -
from sklearn.datasets import load_diabetes from sklearn.ensemble import RandomForestRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error# load data diabetes = load_diabetes() X, y = diabetes.data, diabetes.target# split data into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# train the model model = RandomForestRegressor(n_estimators=100, max_depth=5, random_state=42) model.fit(X_train, y_train)# make predictions on test set y_pred = model.predict(X_test)# evaluate the model mse = mean_squared_error(y_test, y_pred) print("Mean Squared Error:", mse)- 在这个例子中,我们首先加载糖尿病数据集,并将数据集拆分为训练集和测试集。接着,我们使用
RandomForestRegressor类来训练模型。在训练模型时,我们指定了100个决策树、每个决策树的最大深度为5、使用随机种子为42。 - 最后,我们在测试集上进行预测,并使用均方误差(MSE)来评估模型的性能。
- 在这个例子中,我们首先加载糖尿病数据集,并将数据集拆分为训练集和测试集。接着,我们使用
MSE
-
均方误差(Mean Squared Error,MSE)是一个用于评估回归模型性能的指标。它度量了模型预测值和真实值之间的平均差的平方。
-
具体地,设预测值为 y^i\hat{y}_iy^i,真实值为 yiy_iyi,样本数量为 nnn,则 MSE 的计算公式为:
MSE=1n∑i=1n(y^i−yi)2MSE = \frac{1}{n}\sum_{i=1}^{n}(\hat{y}_i - y_i)^2MSE=n1i=1∑n(y^i−yi)2
MSE越小,表示预测值与真实值之间的差异越小,模型的性能越好。(在深度学习作为损失函数的一种)
MSE 的值受到离群值的影响较大,因为它计算的是差异的平方,而离群值的差异往往比较大。
MSE 与均方根误差(RMSE)有密切关系,RMSE 是 MSE 的平方根,用于量化预测值与真实值之间的平均差异。RMSE 的单位与预测值和真实值的单位相同,因此更加直观。
pipeline交叉验证🎈
-
3.1. Cross-validation: evaluating estimator performance — scikit-learn 1.2.2 documentation
-
Learning the parameters of a prediction function and testing it on the same data is a methodological mistake: a model that would just repeat the labels of the samples that it has just seen would have a perfect score but would fail to predict anything useful on yet-unseen data. This situation is called overfitting. To avoid it, it is common practice when performing a (supervised) machine learning experiment to hold out part of the available data as a test set X_test, y_test. Note that the word “experiment” is not intended to denote academic use only, because even in commercial settings machine learning usually starts out experimentally. Here is a flowchart of typical cross validation workflow in model training. The best parameters can be determined by grid search techniques.
在学习预测函数的参数并在同一数据上进行测试是一种方法论上的错误:一个只会重复其刚刚看到的样本标签的模型会得到完美的分数,但在尚未见过的数据上将无法预测任何有用的信息,这种情况称为过度拟合。
为了避免这种情况,在进行(监督)机器学习实验时,通常将可用数据的一部分保留为测试集X_test,y_test。请注意,“实验”这个词不仅用于学术用途,因为即使在商业环境中,机器学习通常也是从实验开始的。下面是模型训练中典型交叉验证工作流程的流程图。最佳参数可以通过网格搜索技术确定。
-
-
假设我们有一个数据集,其中包含了房屋的面积、房间数量和价格等特征。我们想要使用支持向量机(SVM)来预测房屋价格。在使用SVM之前,我们需要对数据进行预处理,例如将特征缩放到相同的尺度上。
-
如果我们不使用pipeline,而是先对整个数据集进行缩放,然后将缩放后的数据集拆分为训练集和测试集,并对它们进行交叉验证和搜索,那么我们将会存在数据泄漏(data leakage)的问题。
-
这是因为,我们在对整个数据集进行缩放时,已经使用了测试集中的信息,从而使得训练集和测试集之间不再是独立的。
-
具体来说,如果我们在对整个数据集进行缩放后再对其进行拆分,那么训练集中的某些数据可能已经“知道”了测试集中的一些信息,这将导致我们高估SVM的性能。因此,我们需要使用pipeline来确保在交叉验证和搜索过程中,预处理步骤仅使用训练集中的信息,而不涉及测试集。
-
eg
使用pipeline的例子如下:
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# 生成二分类数据集
X, y = make_classification(n_samples=500, n_features=5,n_informative=3, n_classes=3, random_state=42)
X_train,X_test,y_train,y_test=train_test_split(X,y)
# 查看数据集的形状和标签分布
print(X.shape)
print(y[:10])
##from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVR
from sklearn.model_selection import GridSearchCV# create a pipeline with scaling and SVM
pipeline = Pipeline([('scaler', StandardScaler()),('svm', SVR())
])# define the parameter space for grid search
param_grid = {# 'svm__kernel':['linear','rbf'],'svm__C': [0.1, 1, 10],'svm__gamma': [0.01, 0.1,1],
}# create a grid search object and fit to the data
grid_search = GridSearchCV(pipeline, param_grid, cv=5,verbose=3)
grid_search.fit(X_train, y_train)# evaluate the best model on the test set
grid_search.score(X_test, y_test)
-
.... [CV 2/5] END ...........svm__C=10, svm__gamma=1;, score=0.577 total time= 0.0s [CV 3/5] END ...........svm__C=10, svm__gamma=1;, score=0.445 total time= 0.0s [CV 4/5] END ...........svm__C=10, svm__gamma=1;, score=0.624 total time= 0.0s [CV 5/5] END ...........svm__C=10, svm__gamma=1;, score=0.670 total time= 0.0s0.7792794616124854 -
在这个例子中,我们创建了一个pipeline对象,其中包含了一个StandardScaler对象和一个SVR对象。StandardScaler对象用于对数据进行缩放,而SVR对象用于进行支持向量机回归。
-
然后,我们定义了一个参数空间param_grid,其中包含了SVM的两个超参数C和gamma的取值范围。接着,我们使用GridSearchCV进行交叉验证和搜索,将pipeline作为估计器对象,并传入参数空间param_grid。
-
最后,我们在测试集上评估了最佳模型的性能。
-
需要注意的是,在这个例子中,我们使用了Pipeline对象来将多个步骤组合在一起,并确保在交叉验证和搜索过程中,每个步骤仅使用训练集中的信息,而不涉及测试集。这样,我们可以避免数据泄漏问题,并获得更准确的模型评估结果。
L1@L2正则
-
L1正则和L2正则是正则化方法中最常用的两种方法。
-
L1正则化(也称为Lasso|least absolute shrinkage and selection operator; also Lasso or LASSO)是一种线性回归的正则化方法,在损失函数中加入L1范数惩罚项,使得模型中的一些系数变为0,从而实现特征选择的作用。L1正则化可以用于特征选择,因为它可以将一些不重要或冗余的特征系数缩小甚至置0,从而提高模型的泛化能力。
L2正则化(也称为Ridge)是一种线性回归的正则化方法,在损失函数中加入L2范数惩罚项,使得模型中的系数变得更小,从而防止模型过拟合。L2正则化可以用于处理高共线性数据,因为它可以通过减小系数的大小来缩小共线性的影响。
-
L1正则化和L2正则化的区别在于惩罚项的形式不同。L1正则化的惩罚项是系数向量中各个系数的绝对值之和,而L2正则化的惩罚项是系数向量中各个系数的平方和。
-
因此,L1正则化更倾向于产生稀疏解,即一些系数为0,而L2正则化更倾向于产生系数较小的解,可以避免过拟合。在实际应用中,通常需要根据具体的问题和数据集选择合适的正则化方法。
-
假设我们有一个分类问题,需要建立一个支持向量机(SVM)模型来分类。我们可以使用L1正则化或L2正则化来训练模型,并比较它们的效果。
首先,我们使用L1正则化训练模型。在损失函数中,我们加入L1范数惩罚项,使得模型中的一些特征系数变为0,从而实现特征选择的作用。这意味着,一些特征将被完全忽略,并从模型中剔除。这可以避免特征之间的共线性,提高模型的泛化能力。
from sklearn.datasets import load_iris from sklearn.svm import LinearSVC# 加载数据集 iris = load_iris()# 创建L1正则化SVM模型对象 l1_svm = LinearSVC(penalty='l1', dual=False,max_iter=3000)# 在数据集上训练模型 l1_svm.fit(iris.data, iris.target)# 输出模型系数 print(l1_svm.coef_)在这个例子中,我们使用
LinearSVC模型对象来训练模型,并将penalty参数设置为’l1’,这是L1正则化的超参数。fit()方法将模型拟合到数据集上,并返回模型系数。输出的系数向量中,一些系数为0,这意味着它们对模型的贡献很小,被完全忽略。接下来,我们使用L2正则化训练模型。在损失函数中,我们加入L2范数惩罚项,使得模型中的系数变得更小,从而防止模型过拟合。这意味着,所有特征都被保留,但它们的系数被缩小,以避免过度拟合。
# 创建L2正则化SVM模型对象 l2_svm = LinearSVC(penalty='l2', dual=False)# 在数据集上训练模型 l2_svm.fit(iris.data, iris.target)# 输出模型系数 print(l2_svm.coef_)在这个例子中,我们使用
LinearSVC模型对象来训练模型,并将penalty参数设置为’l2’,这是L2正则化的超参数。fit()方法将模型拟合到数据集上,并返回模型系数。输出的系数向量中,所有系数都被保留,但它们的大小被缩小。可以看到,在这个示例中,L1正则化和L2正则化的效果是不同的。L1正则化通过特征选择去除了一些特征,而L2正则化则保留了所有特征,但缩小了它们的系数。在实际应用中,需要根据具体的问题和数据集选择合适的正则化方法。
Next steps
-
We have briefly covered estimator fitting and predicting, pre-processing steps, pipelines, cross-validation tools and automatic hyper-parameter searches. This guide should give you an overview of some of the main features of the library, but there is much more to
scikit-learn! -
Please refer to our User Guide for details on all the tools that we provide. You can also find an exhaustive list of the public API in the API Reference.
-
You can also look at our numerous examples that illustrate the use of
scikit-learnin many different contexts. -
The tutorials also contain additional learning resources.
User Guide vs Tutorial
-
scikit-learn提供了用户指南(User Guide)和教程(Tutorial)两种不同类型的文档,它们的目的和用途略有不同。- User guide: contents — scikit-learn documentation
用户指南(User Guide)是一份详细的文档,它以任务为导向,介绍了
scikit-learn中提供的各种机器学习算法和工具的用法、原理、参数设置、优化技巧等方面的内容。用户指南的主要受众是那些已经对机器学习有一定了解,并且想要使用scikit-learn构建复杂的机器学习系统的用户。用户指南的目的是帮助用户深入理解scikit-learn的功能和设计,掌握使用scikit-learn构建机器学习系统的方法和技巧。教程(Tutorial)则是一份更为简单和易于入门的文档,它主要是为那些新手用户准备的。教程从基础开始,介绍了
scikit-learn的核心概念、数据预处理、模型选择、模型评估等方面的内容,并提供了一些示例代码和练习题,帮助用户逐步掌握scikit-learn的使用方法。教程的目的是帮助用户快速入门scikit-learn,了解基本的机器学习流程和工具,为进一步深入学习和实践打下基础。总之,用户指南适合那些希望深入理解
scikit-learn的机制、算法和工具的用户,而教程则适合那些刚开始接触机器学习和scikit-learn的新手用户。
相关文章:
ML@sklearn@ML流程Part3@AutomaticParameterSearches
文章目录Automatic parameter searchesdemomodel_selection::Hyper-parameter optimizersGridSearchCVegRandomizedSearchCVegNoteRandomForestRegressorMSEpipeline交叉验证🎈egL1L2正则Next stepsUser Guide vs TutorialAutomatic parameter searches Automatic p…...
Ubuntu22安装OpenJDK
目录 一、是否自带JDK 二、 删除旧JDK(如果自带JDK满足需求就直接使用了) 三、下载OpenJDK 四、新建/home/user/java/文件夹 五、 设置环境变量 六、查看完成 附:完整版连接: 一、是否自带JDK java -version 二、 删除旧…...
【数据库管理】②实例管理及数据库启动关闭
1. 实例和参数文件 1.1 instance 用于管理和访问 database. instance 在启动阶段读取初始化参数文件(init parameter files). 1.2 init parameter files [rootoracle-db-19c ~]# su - oracle [oracleoracle-db-19c ~]$ [oracleoracle-db-19c ~]$ cd $ORACLE_HOME/dbs [oracl…...
【2023】Kubernetes之Pod与容器状态关系
目录简单创建一个podPod运行阶段:容器运行阶段简单创建一个pod apiVersion: v1 kind: pod metadata: name: nginx-pod spec:containers:- name: nginximages: nginx:1.20以上代码表示创建一个名为nginx-pod的pod资源对象。 Pod运行阶段: Pod创建后&am…...
LabVIEW阿尔泰PCIE 5654 例程与相关资料
LabVIEW阿尔泰PCIE 5654 例程与相关资料 阿尔泰PCIE 5654多功能采集卡,具有500/250Ksps、32/16路模拟量输入;100Ksps,16位,4/2/0路同步电压模拟量输出;8路DIO ;8路PFI;1路32位多功能计数器。PC…...
spark2.4.4有哪些主要的bug
Issue Navigator - ASF JIRA -...

信息学奥赛一本通 1347:【例4-8】格子游戏
【题目链接】 ybt 1347:【例4-8】格子游戏 【题目考点】 1. 并查集:判断无向图是否有环 【解题思路】 该题为判断无向图是否有环。可以使用并查集来完成。 学习并查集时,每个元素都由一个整数来表示。而该问题中每个元素是一个坐标点&a…...

acwing3417. 砝码称重
acwing3417. 砝码称重算法 1: DFS算法2 : DP算法 1: DFS /*** 数据范围 对于 50%的评测用例,1≤N≤15. 对于所有评测用例,1≤N≤100,N 个砝码总重不超过 1e5. */ /* 算法 1: DFS 思路 : 对于每个砝码,有放在左边,放在右边,和不放三种选择,使…...

生成式 AI:百度“文心一言”对标 ChatGPT?什么技术趋势促使 ChatGPT 火爆全网?
文章目录前言一、生成式 AI 的发展和现状1.1、什么是生成式 AI?1.2、生成式 AI 的发展趋势1.3、AI 生成内容的业务场景和分类二、生成式 AI 从分析领域到创作领域2.1、 降低内容创作门槛,增加 UGC 用户群体2.2、提升创作及反馈效率,铺垫线上实…...
PCL 非线性最小二乘法拟合圆柱
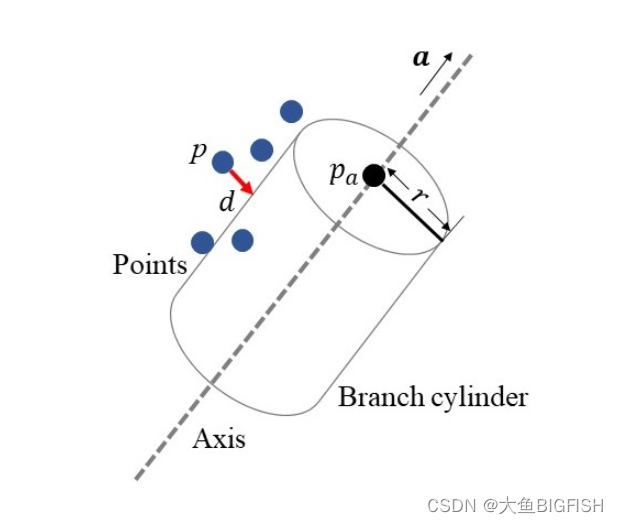
文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 这里通过非线性最小二乘的方法来实现圆柱体的拟合,具体的计算过程如下所述: 图中, p p p为输入数据的点位置,求解的参数为柱体的轴向向量 a...
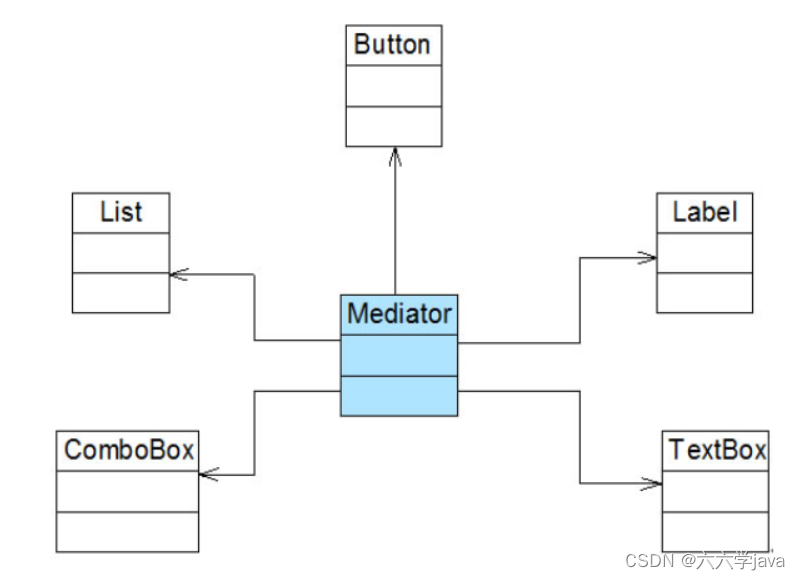
【设计模式】迪米特法则
文章目录一、迪米特法则定义二、迪米特法则分析三、迪米特法则实例一、迪米特法则定义 迪米特法则(Law of Demeter, LoD):一个软件实体应当尽可能少地与其他实体发生相互作用。 二、迪米特法则分析 如果一个系统符合迪米特法则,那么当其中某一个模块发…...

CSS3笔试题精讲1
Q1 BFC专题 防止父元素高度坍塌 4种方案 父元素的高度都是由内部未浮动子元素的高度撑起的。 如果子元素浮动起来,就不占用普通文档流的位置。父元素高度就会失去支撑,也称为高度坍塌。 即使有部分元素留在普通文档流布局中支撑着父元素,如果浮动 起来的元素高度高于留下的…...
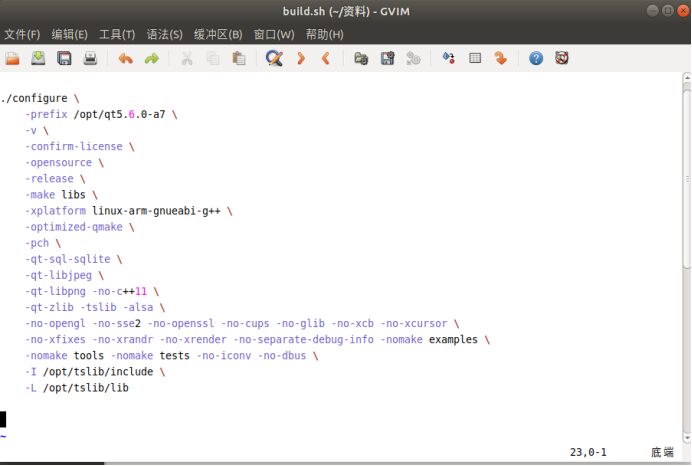
交叉编译用于移植的Qt库
前言 如果在Ubuntu上使用qt开发可移植到周立功开发板的应用程序,需要在Ubuntu上交叉编译用于移植的Qt库,具体做法如下: 1、下载源码 源码qt-everywhere-opensource-src-5.9.6.tar.xz拷贝到ubuntu自建的software文件下 2、解压 点击提取到此处 3、安装配置 运行脚本文…...

泰凌微TLSR8258 zigbee开发环境搭建
目录必备软件工具抓包分析辅助工具软件开发包PC 辅助控制软件 (ZGC)必备软件工具 下载地址:http://wiki.telink-semi.cn/ • 集成开发环境: TLSR8 Chips: Telink IDE for TC32 TLSR9 Chips: Telink RDS IDE for RISC-V • 下载调试工具: Telink Burning and Debugg…...

C#实现商品信息的显示异常处理
实验四:C#实现商品信息的显示异常处理 任务要求: 在进销存管理系统中,商品的库存信息有很多种类,比如商品型号、商品名称、商品库存量等。在面向对象编程中,这些商品的信息可以存储到属性中,然后当需要使…...
)
细数N个获取天气信息的免费 API ,附超多免费可用API 推荐(三)
前言 市面上有 N 多个查询天气信息的软件、小程序以及网页入口,基本都是通过调用天气查询 API 去实现的。 今天整理了一下多种场景的天气预报API 接口分享给大家,有需要赶紧收藏起来。 天气预报查询 天气预报查询支持全国以及全球多个城市的天气查询…...

20230404英语学习
今日单词 decade n.十年 allocate vt.分配,分派,把…拨给 compress v.压缩;缩短;浓缩 regenerate v.(使)复兴,(使)振兴;(使)再生 …...
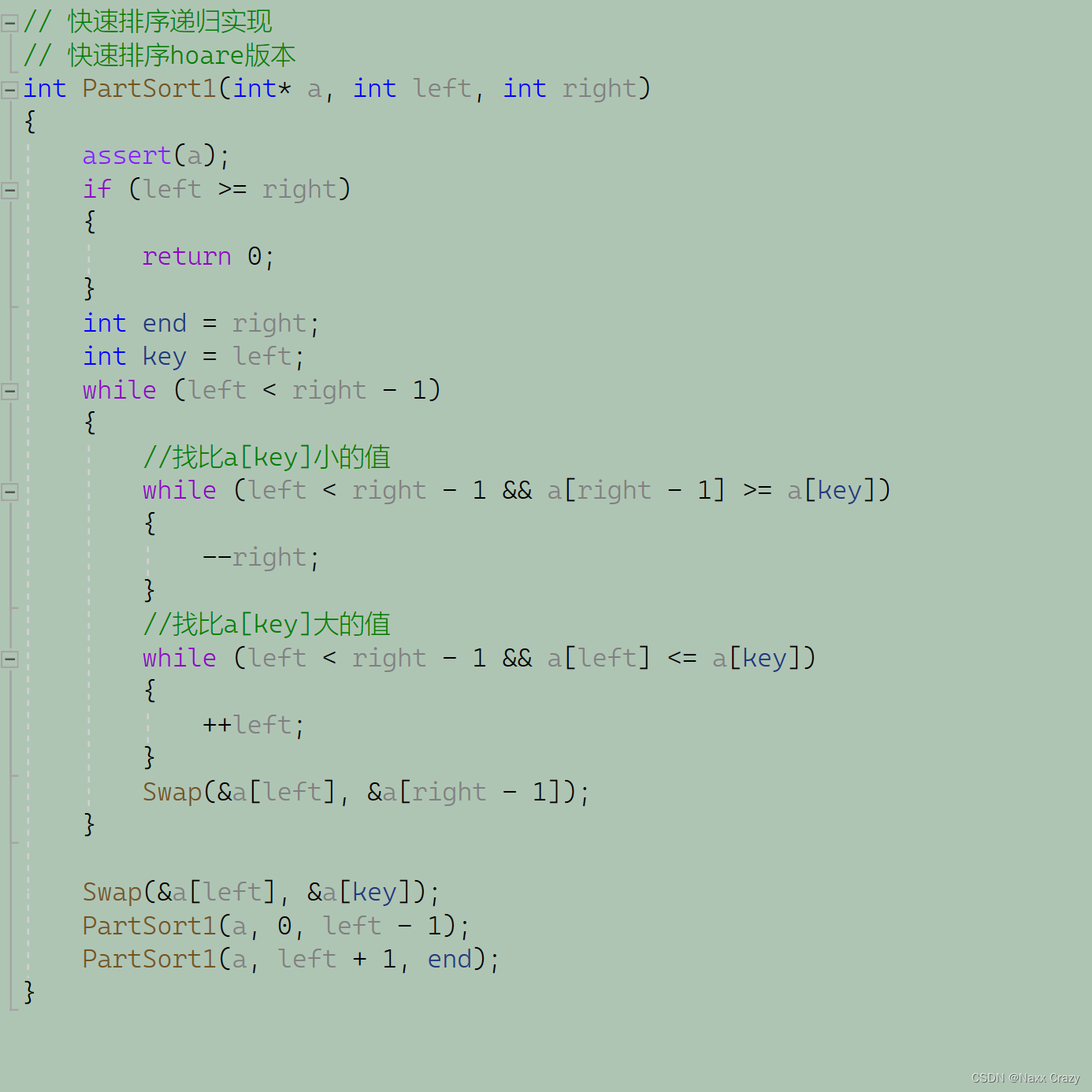
冒泡排序 快排(hoare递归)
今天要讲一个是冒泡排序,进一个是快排,首先是冒泡排序,我相信大家接触的第一个排序并且比较有用的算法就是冒泡排序了,冒泡排序是算法里面比较简单的一种,所以我们先看看一下冒泡排序 还是个前面一样,我们…...

49天精通Java,第24天,Java链表、散列表、HashSet、TreeSet
目录一、链表二、散列表三、HashSet四、TreeSet五、TreeSet常用方法大家好,我是哪吒。 一、链表 从数组中间删除一个元素开销很大,其原因是向数组中插入元素时,此元素之后的所有元素都要向后端移动,删除时也是,数组中…...

HashMap源码分析小结
HashMap相关问题 HashMap实现原理 HashMap是以键值对的形式存储数据,内部是通过数组链表结构实现,在1.7之后的版本,链表结构可以升级为红黑树,提高查询效率 key和value都支持为null;key为null时hash值是0࿰…...

Windows热键侦探:3分钟快速找出占用快捷键的程序
Windows热键侦探:3分钟快速找出占用快捷键的程序 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否曾经遇到…...

苹果单图生成3D数字人像技术解析:从神经纹理到可微分渲染
1. 项目概述:从二维到三维的“升维”革命 最近在计算机视觉和生成式AI的圈子里,一个来自苹果的研究成果引起了不小的震动。简单来说,他们搞出了一个模型,只需要你的一张正面照片,就能生成一个可以360度旋转、表情生动的…...

大模型时代:程序员小白如何抓住机遇,收藏这份高薪就业指南?
文章分析了2026年互联网技术就业市场的冰火两重天现象,AI相关岗位需求激增,传统岗位被替代。后端开发仍是中坚力量,前端市场饱和但高端人才稀缺,算法与AI工程师站在浪潮之巅,数据工程师因大模型需求水涨船高࿰…...

Python趣味编程:用turtle库复刻经典动漫形象,附完整源码和参数详解
Python趣味编程:用turtle库复刻经典动漫形象,附完整源码和参数详解 还记得小时候用圆规和尺子在作业本上涂鸦的日子吗?现在,我们完全可以用代码重现这种创作的乐趣。Python的turtle库就像数字化的画笔,让编程变成一场视…...

从手机耗电到网络覆盖:深入浅出聊聊LTE PUCCH功率控制那点事
从手机耗电到网络覆盖:深入浅出聊聊LTE PUCCH功率控制那点事 你有没有遇到过这种情况:在地下车库刷视频时,手机电量像开了闸的水龙头一样往下掉?或者在高层建筑的电梯里,明明信号满格,手机却烫得能煎鸡蛋&…...

LinkSwift:重新定义网盘文件下载体验的本地化革命
LinkSwift:重新定义网盘文件下载体验的本地化革命 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘…...

终极指南:ChatGPT Google 扩展的API设计与内部模块通信接口规范
终极指南:ChatGPT Google 扩展的API设计与内部模块通信接口规范 【免费下载链接】chatgpt-google-extension This project is deprecated. Check my new project ChatHub: 项目地址: https://gitcode.com/gh_mirrors/ch/chatgpt-google-extension ChatGPT Go…...

Angular 响应式原理深度解析:核心机制与源码解读
一、前言Angular 响应式原理深度解析:核心机制与源码解读。本文深入源码层面,剖析核心设计原理,帮你从"会用"升级到"精通"。二、核心原理深度剖析2.1 数据结构设计// Angular 核心数据结构与算法 // 理解 Angular 的底层…...

hLife Collection | Oncology
1. Interactions between microbiota and innate immunity in tumor microenvironment: Novel insights into cancer progression and immunotherapy hLife | 肿瘤微环境中的微生物与固有免疫互作:肿瘤免疫治疗新视角 通信作者:徐冉、韩新巍 本文总结…...

数据结构--------单链表下
书接上回,本章主要讲的是单链表的头删,尾删,指定位置插入删除,链表的查找和链表的销毁;一.链表的操作1.头删文字描述如下:正所谓头删,删除的肯定是链表的头元素,但是我们要怎么样进行…...