自学数据库-MYSQL
自学数据库-MYSQL
- 一.表和视图
- 1.表
- 1.1 表创建
- 1.2 索引
- 1.2.1 这里是废话,不感兴趣的可以直接更具目录的跳过这里的内容
- 1.2.1.1 索引是什么
- 1.2.1.2 相关数据结构:二叉树、红黑树、B-Tree、B+Tree、Hash…
- ①普通索引
- ②唯一索引
- ③全文索引
- ④组合索引
- 1.3 表数据操作(更新中)
- 1.3.1 增(更新中)
- 1.3.2 删(更新中)
- 1.3.3 改(更新中)
- 1.3.4 查(更新中)
- 1.3.4.1 查询语句(更新中)
- 2.视图(更新中)
- 2.1 视图创建(更新中)
- 二.存储过程/函数/触发器
- 1.存储过程
- 1.1 存储创建(语法)
- 2.函数
- 2.1 函数创建(语法)
- 3.1 触发器创建(语法)
- 1.创建只有一个执行语句的触发器
- 2.创建有多个执行语句的触发器
- 3.查看触发器
- 4.实例/注意
- 三.存储引擎
- 1.InnoDB
- ① 特点
- ② 文件
- ③ 逻辑存储结构
- 2.MyISAM
- ① 特点
- ② 文件
- 3.Memory
- ① 特点
- ② 文件
- 4.三种引擎区别及特点
- 问题:
一.表和视图
| 维度 | 表 | 视图 |
|---|---|---|
| 物理存在 | 用于存储数据的物理结构 | 基于表或多个表的查询结果集,不具有独立的物理存在,是一个或多个表的逻辑表现,它不包含数据,只包含对表中数据的引用和操作规则。 |
| 数据操作 | 是数据的物理存储单元,可以进行数据的增、删、改、查等操作 | 只是提供了一个查看和操作表数据的特定角度和规则 |
| 安全性 | 它公开了所有数据,用户的访问没有限制 | 用户只能访问其被授权访问的表的部分数据,这大大提高了数据的安全性 |
| 抽象程度 | 提供更底层、更直接的数据访问。 | 视图是表的抽象,它隐藏了表中的细节,只展示用户关心的信息 |
| 复杂查询 | 只能执行单个表的简单查询 | 可以在一个查询中组合多个表,甚至可以使用复杂的SQL语句 |
| 临时性和永久性 | 是数据库中的永久性结构 | 可以随时创建或删除,没有永久性 |
| 命名冲突 | – | 视图是逻辑结构,可以创建具有相同名称但基于不同表的视图 |
| 执行过程 | 数据库引擎直接对表进行操作,没有额外的计算成本 | 数据库需要先执行视图的查询语句,然后再对查询结果进行操作,这增加了额外的计算成本 |
| 索引优化 | 通过创建索引来提高查询效率,而视图则无法享受这种优化 | 缺乏如表中的索引优化,尤其是在使用histogram时,优化效果更为明显 |
| 数据存储和查询效率 | 1.存储实际数据 | 1.视图不存储数据,只是一个查询结果的展示 2.需要进行额外的计算和查询操作,从而影响性能 |
| 简化操作 | ------------- | 可以简化复杂的查询语句,提高查询的可读性和维护性。通过使用视图,可以隐藏复杂的查询逻辑,使查询语句更加简洁 |
| 提高安全性 | ------------- | 通过视图可以对底层表进行权限控制,只暴露需要的数据给用户,从而提高数据的安全性 |
| 降低耦合 | ------------- | 如果需要修改原表的结构,通过修改视图的定义即可,而不需要修改应用程序,这样可以降低应用程序与数据库之间的耦合度 |
1.表
1.1 表创建
CREATE TABLE table_name (column1 datatype [NOT NULL] [DEFAULT default_value],column2 datatype [NOT NULL] [DEFAULT default_value],...columnN datatype [NOT NULL] [DEFAULT default_value],PRIMARY KEY (column1, column2, ... columnN),UNIQUE KEY unique_key_name (column1, column2, ... columnN),FOREIGN KEY (column1, column2, ... columnN)REFERENCES parent_table (column1, column2, ... columnN)ON DELETE CASCADE | ON UPDATE CASCADE,INDEX index_name (column1, column2, ... columnN),...
) ENGINE=storage_engine;
| 名称 | 解释 |
|---|---|
| table_name | 是你想创建的表的名称 |
| column1, column2, …, columnN | 是表的列名称 |
| datatype | 是每列的数据类型 |
| NOT NULL | 表示列不能有NULL值。 |
| DEFAULT default_value | 设置列的默认值。 |
| PRIMARY KEY | 是你想创建的表的名称 |
| UNIQUE KEY | 是你想创建的表的名称 |
| FOREIGN KEY | 是你想创建的表的名称 |
| ON DELETE CASCADE | ON UPDATE CASCADE |
| INDEX | 是你想创建的表的名称 |
| ENGINE | 指定存储引擎,如InnoDB、MyISAM等。 |
CREATE TABLE sys_user (id INT NOT NULL AUTO_INCREMENT,username VARCHAR(50) NOT NULL comment '账号',password VARCHAR(50) NOT NULL comment '密码',email VARCHAR(100) NOT NULL comment '邮箱',created_at TIMESTAMP DEFAULT current_timestamp comment '创建时间',PRIMARY KEY (id),UNIQUE KEY unique_username (username),INDEX idx_email (email)
) ENGINE=InnoDB comment '用户基础表' charset = utf8mb3;
1.2 索引
1.2.1 这里是废话,不感兴趣的可以直接更具目录的跳过这里的内容
1.2.1.1 索引是什么
1.索引是一种数据结构,用来帮助提升查询和检索数据速度。可以理解为一本书的目录,帮助定位数据位置。
2.索引是一个文件,它要占用物理空间。
索引概述:索引(index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。
1.2.1.2 相关数据结构:二叉树、红黑树、B-Tree、B+Tree、Hash…
二叉树缺点:
- 顺序插入时,会形成一个链表,查询性能大大降低。
- 大数据量情况下,层级较深,检索速度慢。
红黑树:
- 大数据量情况下,层级较深,检索速度慢。
- (红黑树是一颗自平衡二叉树,那这样即使是顺序插入数据,最终形成的数据结构也是一颗平衡的二叉树,解决顺序插入形成链表的问题。但红黑树仍存在”大数据量情况下,层级较深,检索速度慢“)所以,在MySQL的索引结构中,并没有选择二叉树或者红黑树,而选择的是B+Tree,
B-Tree(多路平衡查找树,也叫B树):
- 5阶的B树,每一个节点最多存储4个key,对应5个指针
- 一旦节点存储的key数量到达5,就会裂变,中间元素向上分裂
- 在B树中,非叶子节点和叶子节点都会存放数据
B+Tree 相对于B-Tree区别:
- 所有的数据都会出现在叶子节点
- 叶子节点形成一个单向链表。
- 非叶子节点不存储具体数据、只起到索引数据的作用,具体的数据都是在叶子节点存放的
MySQL索引数据结构对经典的B+Tree进行了优化。在原B+Tree的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能,利于排序。
- B+ 树的叶子节点之间是用「双向链表」进行连接,既能向右遍历、也能向左遍历
- B+ 树点节点内容是数据页,数据页里存放了用户的记录以及各种信息,每个数据页默认大小是 16 KB
Hash索引:
特点:
1.Hash索引只能用于对等比较(=,in),不支持范围查询(between,>,<,…)
2.无法利用索引完成排序操作
3.查询效率高,通常只需要一次检索就可以了,效率通常要高于B+tree索引
采用一定的hash算法,将键值换算成新的hash值,映射到对应的槽位上,然后存储在hash表中。如果两个(或多个)键值,映射到一个相同的槽位上,他们就产生了hash冲突(也称为hash碰撞),可以通过链表来解决。
- Hash索引只能用于对等比较(=,in),不支持范围查询(between,>,<,…)
- 无法利用索引完成排序操作
- 查询效率高,通常只需要一次检索就可以了,效率通常要高于B+tree索引
1.磁盘读写的最小单位是扇区,扇区的大小只有 512B 大小,操作系统一次会读写多个扇区,所以操作系统的最小读写单位是块(Block)。Linux 中的块大小为 4KB,也就是一次磁盘 I/O 操作会直接读写 8 个扇区。
2.由于数据库的索引是保存到磁盘上的,因此当我们通过索引查找某行数据的时候,就需要先从磁盘读取索引到内存,再通过索引从磁盘中找到某行数据,然后读入到内存,也就是说查询过程中会发生多次磁盘 I/O,而磁盘 I/O 次数越多,所消耗的时间也就越大。所以,我们希望索引的数据结构能在尽可能少的磁盘的 I/O 操作中完成查询工作,因为磁盘 I/O 操作越少,所消耗的时间也就越小。
3.由于树是存储在磁盘中的,访问每个节点,都对应一次磁盘 I/O 操作(假设一个节点的大小「小于」操作系统的最小读写单位块的大小),也就是说树的高度就等于每次查询数据时磁盘 IO 操作的次数,所以树的高度越高,就会影响查询性能。
①普通索引
(1).新建表中添加索引
create table t_dept
(no int not null primary key,name varchar(20) null,sex varchar(2) null,info varchar(20) null,index index_no (no)
)
(2).在已建表中添加索引
create index index_name on t_dept (name);
(3).以修改表的方式添加索引
alter table t_dept add index index_name(name);
②唯一索引
(1).新建表中添加索引
create table t_dept
(no int not null primary key,name varchar(20) null,sex varchar(2) null,info varchar(20) null,unique index index_no (no)
)
(2).在已建表中添加索引
create unique index index_name on t_dept(name);
(3).以修改表的方式添加索引
alter table t_dept add unique index index_name(name);
③全文索引
(1).新建表中添加索引
create table t_dept
(no int not null primary key,name varchar(20) null,sex varchar(2) null,info varchar(20) null,fulltext index index_no (no)
)
(2).在已建表中添加索引
create fulltext index index_name on t_dept(name);
(3).以修改表的方式添加索引
alter table t_dept add fulltext index_name(name);
④组合索引
(1).新建表中添加索引
create table t_dept
(no int not null primary key,name varchar(20) null,sex varchar(2) null,info varchar(20) null,key index_no_name (no, name)
)
(2).在已建表中添加索引
create index index_name_no on t_dept(name,no)
(3).以修改表的方式添加索引
alter table t_dept add index index_name_no(name,no);
1.3 表数据操作(更新中)
1.3.1 增(更新中)
1.3.2 删(更新中)
1.3.3 改(更新中)
1.3.4 查(更新中)
1.3.4.1 查询语句(更新中)
2.视图(更新中)
2.1 视图创建(更新中)
二.存储过程/函数/触发器
1.存储过程
1.1 存储创建(语法)
2.函数
2.1 函数创建(语法)
①创建函数
CREATE FUNCTION function_name (parameter_name datatype, ...)
RETURNS return_datatype
BEGIN-- 函数逻辑RETURN value;
END;
- function_name:函数名称。
- parameter_name:输入参数的名称,可以有多个参数。
- datatype:输入参数的数据类型。
- return_datatype:函数返回值的数据类型。
- RETURN value:指定函数的返回值。
实例:
CREATE FUNCTION add_numbers(num1 INT, num2 INT)
RETURNS INT
BEGINRETURN num1 + num2;
END;
- 数据转换
函数常用于数据转换操作。例如,将日期格式转换为特定格式,或将字符串转换为大写。
CREATE FUNCTION to_uppercase(str VARCHAR(255))
RETURNS VARCHAR(255)
BEGINRETURN UPPER(str);
END;
SELECT to_uppercase('hello world');
- 计算与统计
函数可以用于各种计算和统计操作。例如,计算复利、求平均值等。
CREATE FUNCTION calculate_compound_interest(principal DECIMAL(10, 2), rate DECIMAL(5, 2), years INT)
RETURNS DECIMAL(10, 2)
BEGINRETURN principal * POWER(1 + rate / 100, years);
END;
SELECT calculate_compound_interest(1000, 5, 10) AS future_value;
- 条件逻辑
函数可以包含条件逻辑,根据输入参数的不同返回不同的结果。例如,返回某个数的正负号。
## 创建一个判断正负号的函数:
CREATE FUNCTION sign_of_number(num INT)
RETURNS VARCHAR(10)
BEGINIF num > 0 THENRETURN 'Positive';ELSEIF num < 0 THENRETURN 'Negative';ELSERETURN 'Zero';END IF;
END;
SELECT sign_of_number(-5);
- 动态 SQL 构建
函数还可以用于构建和执行动态 SQL 语句。例如,根据输入的表名和列名动态生成查询语句。
## 创建一个函数,动态查询某个表中的行数:
CREATE FUNCTION get_row_count(table_name VARCHAR(255))
RETURNS INT
BEGINSET @sql = CONCAT('SELECT COUNT(*) FROM ', table_name);PREPARE stmt FROM @sql;EXECUTE stmt;DEALLOCATE PREPARE stmt;RETURN @sql;
END;SELECT get_row_count('employees');
CREATE FUNCTION get_employee_count(department INT)
RETURNS INT
BEGINRETURN (SELECT COUNT(*) FROM employees WHERE department = department);
END;
CREATE FUNCTION get_employee_count(department INT)
RETURNS INT
BEGINRETURN (SELECT COUNT(*) FROM employees WHERE department = department);
END;
CREATE FUNCTION calculate_total_salary(department INT)
RETURNS DECIMAL(10,2)
BEGINDECLARE count INT;DECLARE salary DECIMAL(10,2);SET count = (SELECT COUNT(*) FROM employees WHERE department = department);SET salary = (SELECT SUM(salary) FROM employees WHERE department = department);RETURN (salary / count);
END;
也可以在函数中使用其他语句和控制结构,如 IF/THEN/ELSE、WHILE、FOR 等。上面面是一个复杂的示例,该函数根据部门的员工数量计算工资总额:
在这个示例中,我们首先声明了两个变量 count 和 salary,然后使用 SELECT 语句从表中检索数据。最后,我们返回 salary / count 的结果,即每个员工的平均工资。
- CREATE FUNCTION 是用来创建函数的语句。
- get_employee_count 是函数的名称。
- (department INT) 是输入参数列表,这里我们定义了一个名为 department 的整数类型参数。
- RETURNS INT 指定了函数的返回类型是整数。
- BEGIN 和 END 之间的代码是函数体。
- RETURN (SELECT COUNT(*) FROM employees WHERE department = department); 是返回语句,它返回一个值。在这个例子中,我们返回 employees 表中与输入参数 department 匹配的行数。
3.1 触发器创建(语法)
1.创建只有一个执行语句的触发器
CREATE TRIGGER trigger_name trigger_time trigger_event ON tbl_name
FOR EACH ROW trigger_stmt
其中 trigger_name标识触发器名称,用户自行指定;trigger_time标识触发时机,可以指定为before或after;trigger_event标识触发事件,包括INSERT、 UPDATE和 DELETE;tbl_name标识建立触发器的表名,即在哪张表上建立触发器;trigger_stmt是触发器执行语句。
例
CREATE TABLE account (acct_num INT,amount DECIMAL (10,2));
CREATE TRIGGER ins_sum BEFORE INSERT ON account
FOR EACH ROW SET @sum = @sum + NEW.amount;
首先创建一个account表,表中有两个字段,分别为: acct_num字段(定义为int类型),amount字段(定义成浮点类型)﹔其次创建一个名为 ins_sum的触发器,触发的条件是向数据表account插入数据之前,对新插入的amount字段值进行求和计算。
SET @sum=0;
INSERT INTO account VALUES(1,1.00),(2,2.00) ;
SELECT @sum;
首先创建一个account表,在向表account插入数据之前,计算所有新插入的account 表的amount值之和,触发器的名称为ins_sum,条件是在向表插入数据之前触发。
2.创建有多个执行语句的触发器
CREATE TRIGGER trigger_name trigger_time trigger_event
ON tbl name FOR EACH ROW
BEGIN语句执行列表END
其中 trigger_name标识触发器的名称,用户自行指定;trigger_time标识触发时机,可以指定为before或after;rigger_event标识触发事件,包括INSERT、UPDATE 和 DELETE;tbl_name标识建立触发器的表名,即在哪张表上建立触发器;触发器程序可以使用BEGIN和END作为开始和结束,中间包含多条语句。
关键字:
:NEW 和:OLD使用方法和意义,new 只出现在insert和update时,old只出现在update和delete时。在insert时new表示新插入的行数据,update时new表示要替换的新数据、old表示要被更改的原来的数据行,delete时old表示要被删除的数据。
CREATE TABLE test1(a1 INT);
CREATE TABLE test2(a2 INT);
CREATE TABLE test3(a3 INT NOT NULL AUTO_INCREMENT PRIMARY KEY);CREATE TABLE test4(a4 INT NOT NULL AUTO_INCREMENT PRIMARY KEY,b4 INT DEFAULT 0
);DELIMITER //
CREATE TRIGGER testref BEFORE INSERT ON test1 FOR EACH ROW
BEGININSERT INTO test2 SET a2 = NEW.a1;DELETE FROM test3 WHERE a3 = NEW.a1;UPDATE test4 SET b4 = b4+1 WHERE a4 = NEW.a1;
END //INSERT INTO test3(a3) VALUES
(NULL), (NULL), (NULL), (NULL), (NULL),
(NULL),(NULL), (NULL), (NULL), (NULL);
INSERT INTO test4(a4) VALUES
(0), (0),(0),(0), (0),
(0), (0),(0),(0), (0);
上面的代码是创建了一个名为testref的触发器,这个触发器的触发条件是在向表test1插入数据前执行触发器的语句,具体执行的代码如下:
INSERT INTO test1 VALUES(1), (3), (1), (7), (1), (8),(4),(4);
那么4个表中的数据如下:
SELECT * FROM test1;
SELECT * FROM test2;
SELECT * FROM test3;
SELECT * FROM test4;
执行结果显示,在向表test1插入记录的时候,test2、 test3、 test4 都发生了变化。从这个例子看INSERT触发了触发器,向test2中插入了test1 中的值,删除了test3 中相同的内容,
同时更新了test4 中的b4,即与插入的值相同的个数。
3.查看触发器
查看触发器是指查看数据库中已存在的触发器的定义、状态和语法信息等。可以通过命令
来查看已经创建的触发器。本节将介绍两种查看触发器的方法,分别是: SHOW TRIGGERS
和在triggers表中查看触发器信息。
## SHOW TRIGGERS语句查看触发器信息
SHOW TRIGGERS;4.实例/注意
创建一个在account表插入记录之后,更新myevent数据表的触发器,代码如下:
CREATE TRIGGER trig_insert AFTER INSERT ON account
FOR EACH ROW INSERT INTO myevent VALUES (2, 'after insert');
上面的代码创建了一个trig. _insert 的触发器在向表account插入数据之后会向表myevent
插入一组数据,代码执行如下:
INSERT INTO account VALUES (1, 1.00), (2, 2.00);SELECT * FROM myevent;
从执行的结果来看,是创建了一个名称为trig_insert 的触发器,它是在向account 插入记
录之后进行触发,执行的操作是向表myevent 插入一条记录。
使用触发器时须特别注意。
1.在使用触发器的时候需要注意,对于相同的表,相同的事件只能创建一一个触发器,比如对
表account创建了一个BEFOREINSERT触发器,那么如果对表account再次创建一个BEFORE
INSERT触发器,MySQL将会报错,此时,只可以在表account.上创建AFTER INSERT或者
BEFOREUPDATE类型的触发器。灵活地运用触发器将为操作省去很多麻烦。
及时删除不再需要的触发器。
1.触发器定义之后,每次执行触发事件,都会激活触发器并执行触发器中的语句。如果需求
发生变化,而触发器没有进行相应的改变或者删除,则触发器仍然会执行旧的语句,从而会影
响新的数据的完整性。因此,要将不再使用的触发器及时删除。
请根据实际情况合理的使用触发器,没有必要使用触发器可以直接使用代码进行逻辑处理
,一般中小型项目使用的比较少
三.存储引擎
| 存储引擎 | 区别 |
|---|---|
| InnoDB | 是mysql5.5之后是默认的引擎,它支持事务、外键、表级锁和行级锁 |
| MyISAM | 是早期的引擎,它不支持事务、只有表级锁、也没有外键,用的不多 |
| Memory | 主要把数据存储在内存,支持表级锁,没有外键和事务,用的也不多 |
查询当前数据库支持的存储引擎
show engines;
1.InnoDB
介绍: nnoDB是一种兼顾高可靠性和高性能的通用存储引擎,在 MySQL 5.5 之后,InnoDB是默认的 MySQL 存储引擎。
① 特点
- DML操作遵循ACID模型,支持事务;
- 行级锁,提高并发访问性能;
- 支持外键FOREIGN KEY约束,保证数据的完整性和正确性;
② 文件
- xxx.frm:xxx代表的是表名,与表相关的元数据信息都存放在frm文件,包括表结构的定义信息等。
- xxx.ibd:InnoDB DATA,表数据和索引的文件,innoDB引擎的每张表都会对应这样一个表空间文件,存储该表的表结构(frm-早期的 、sdi-新版的)、数据和索引。该表的索引(B+树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据
参数:innodb_file_per_table
show variables like 'innodb_file_per_table';
如果该参数开启,代表对于InnoDB引擎的表,每一张表都对应一个ibd文件。 我们直接打开MySQL的数据存放目录:
C:\ProgramData\MySQL\MySQL Server 8.0\Data ,
这个目录下有很多文件夹,不同的文件夹代表不同的数据库,我们直接打开jw(对应某个数据库)文件夹。
可以看到里面有很多的ibd文件,每一个ibd文件就对应一张表,比如:我们有一张表 account,就有这样的一个account.ibd文
件,而在这个ibd文件中不仅存放表结构、数据,还会存放该表对应的索引信息。 而该文件是基于二进制存储的,不能直接基于
记事本打开,我们可以使用mysql提供的一个指令 ibd2sdi ,通过该指令就可以从ibd文件中提取sdi信息,而sdi数据字典信息中
就包含该表的表结构。
③ 逻辑存储结构
- 表空间 : InnoDB存储引擎逻辑结构的最高层,ibd文件其实就是表空间文件,在表空间中可以包含多个Segment段。
- 段 : 表空间是由各个段组成的, 常见的段有数据段、索引段、回滚段等。InnoDB中对于段的管理,都是引擎自身完成,不需要人为对其控制,一个段中包含多个区。
- 区 : 区是表空间的单元结构,每个区的大小为1M。 默认情况下, InnoDB存储引擎页大小为16K, 即一个区中一共有64个连续的页。
- 页 : 页是组成区的最小单元,页也是InnoDB 存储引擎磁盘管理的最小单元,每个页的大小默认为 16KB。为了保证页的连续性,InnoDB 存储引擎每次从磁盘申请 4-5 个区。
- InnoDB 存储引擎是面向行的,也就是说数据是按行进行存放的,在每一行中除了定义表时所指定的字段以外,还包含两个隐藏字段(后面会详细介绍)。
2.MyISAM
介绍: MyISAM是MySQL早期的默认存储引擎。
① 特点
- 不支持事务,不支持外键
- 支持表锁,不支持行锁
- 访问速度快
② 文件
- xxx.sdi:存储表结构信息
- xxx.MYD: MyISAM DATA,用于存储MyISAM表的数据
- xxx.MYI: MyISAM INDEX,用于存储MyISAM表的索引相关信息
3.Memory
介绍: Memory引擎的表数据时存储在内存中的,由于受到硬件问题、或断电问题的影响,只能将这些表作为临时表或缓存使用。
① 特点
- 内存存放
- hash索引(默认)
② 文件
- xxx.sdi:存储表结构信息【数据存放在内存中,xxx.sdi存放在D:\SoftwareInstall\mysql-5.7.42-winx64\data\databaseName\xxx.sdi】
4.三种引擎区别及特点
| 特点 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| 存储限制 | 64TB | 有 | 有 |
| 事务安全 | 支持 | - | - |
| 锁机制 | 行锁 | 表锁 | 表锁 |
| B+tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | - | - | 支持 |
| 全文索引 | 支持(5.6版本之后) | 支持 | - |
| 空间使用 | 高 | 低 | N/A |
| 内存使用 | 高 | 低 | 中等 |
| 批量插入速度 | 低 | 高 | 高 |
| 支持外键 | 支持 | - | - |
问题:
InnoDB引擎与MyISAM引擎的区别?
1.InnoDB引擎, 支持事务, 而MyISAM不支持。
2.InnoDB引擎, 支持行锁和表锁, 而MyISAM仅支持表锁, 不支持行锁。
3.InnoDB引擎, 支持外键, 而MyISAM是不支持的。
存储引擎支持:在MySQL中,支持hash索引的是Memory存储引擎。 而InnoDB中具有自适应hash功能,hash索引是InnoDB存储引擎根据B+Tree索引在指定条件下自动构建的。
存储引擎选择?
1.InnoDB: 是Mysql的默认存储引擎,支持事务、外键。如果应用对事务的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询之外,还包含很多的更新、删除操作,那么InnoDB存储引擎是比较合适的选择。存储业务系统中对于事务、数据完整性要求较高的核心数据
2.MyISAM : 如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高,那么选择这个存储引擎是非常合适的。 存储业务系统的非核心事务【MYISAM索引和数据是分开的,而且其索引是压缩的,可以更好地利用内存。所以它的查询性能明显优于INNODB。压缩后的索引也能节约一些磁盘空间。MYISAM拥有全文索引的功能,这可以极大地优化LIKE查询的效率。】(业务系统中的日志、电商系统中的足迹/评论)【被NoSQL–MongoDB替代】
3.MEMORY:将所有数据保存在内存中,访问速度快,通常用于临时表及缓存。MEMORY的缺陷就是对表的大小有限制,太大的表无法缓存在内存中,而且无法保障数据的安全性。【被NoSQL–Redis替代】
为什么InnoDB存储引擎选择使用B+Tree索引结构?
1.相对于二叉树,层级更少,搜索效率高;
2.对于B-tree,无论是叶子节点还是非叶子节点,都会保存数据,这样导致一页中存储的键值减少,指针跟着减少,要同样保存大量数据,只能增加树的高度,导致性能降低;(B+ 树的非叶子节点不存放实际的记录数据,仅存放索引,因此数据量相同的情况下,相比存储即存索引又存记录的 B 树,B+树的非叶子节点可以存放更多的索引,因此 B+ 树可以比 B 树更「矮胖」,查询底层节点的磁盘 I/O次数会更少)
3.B+ 树有大量的冗余节点(所有非叶子节点都是冗余索引),这些冗余索引让 B+ 树在插入、删除的效率都更高,比如删除根节点的时候,不会像 B 树那样会发生复杂的树的变化;B+ 树叶子节点之间用链表连接了起来,有利于范围查询,而 B 树要实现范围查询,因此只能通过树的遍历来完成范围查询,这会涉及多个节点的磁盘 I/O 操作,范围查询效率不如 B+ 树
4.相对Hash索引,B+tree支持范围匹配及排序操作;
索引是否越多越好?为什么?
不是。索引是建立在原数据上的数据结构,所以不论在查询还是更新维护、一定会带来开销。
比如一本书有 100 页,我构建了 50 页的目录,你觉查询起来还会方便吗?
1.数据量小的表不需要建立索引,建立索引反而会增加额外开销。
2.数据变更后索引也需要更新,更多的索引意味着更多的维护成本。
3.索引是放在磁盘的,更能的索引也意味着更多的存储空间。
4.数据重复且分布平均的字短没必要建立索引(比如:性别)
索引什么时候会失效?
- 范围查询 大于小于
联合索引的最左匹配原则,出现范围查询(>,<),范围查询右侧的列索引失效,即范围查询的字段可以用到联合索引,但是在范围查询字段后面的字段无法用到联合索引。mysql 会一直向右匹配直到遇到索引搜索键使用>、<就停止匹配。一旦权重最高的索引搜索键使用>、<范围查询,那么其它>、<搜索键都无法用作索引。即索引最多使用一个>、<的范围列,因此如果查询条件中有两个>、<范围列则无法全用到索引。
-- 当范围查询使用> 或 < 时,走联合索引了,但是索引的长度为49,就说明范围查询右边的status字段是没有走索引的
explain select * from user where profession = '软件工程' and age > 30 and status = '0';-- 使用>= 或 <=,走联合索引了,索引的长度为54,就说明所有的字段都是走索引的
explain select * from user where profession = '软件工程' and age >= 30 and status = '0';
- like %xx 模糊查询
- 当使用LIKE操作符进行模糊查询,并且搜索键值以通配符%开头(如:like ‘%abc’),则索引失效,直接全表扫描。这是因为以%开头的模式匹配意味着匹配的字符串可以在任何位置,这使得索引无法有效定位数据
- 若只是以%结尾,索引不会失效
-- 索引生效
explain select * from user where profession like '软件%';
-- 失效
explain select * from user where profession like '%工程';
-- 失效
explain select * from user where profession like '%工%';
3.对索引列进行运算
当我们在查询条件中对索引列进行函数或表达式计算,会导致索引失效而进行全表扫描。比如:
select * from user where YEAR(birthday) < 1999;
explain select * from user where length(name)>2;
4.or 条件索引问题
用or分割开的条件, 如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到。
当or连接的条件,左右两侧字段都有索引时,索引才会生效
-- age没有索引,or连接 索引失效、全表扫描
explain select * from user where id = 10 or age = 23;
5.数据类型不一致,隐式转换导致索引失效
当列是字符串类型,传入条件 必须用引号引起来,不然报错或索引失效(字符串不加引号 索引会失效)。
explain select * from t_user where id_no = 1002;
表里的 id_no 是 varchar 类型
6.!= 问题
普通索引使用 !=索引失效,主键索引没影响。
where语句中索引列使用了负向查询,可能会导致索引失效。负向查询包括:NOT、!=、<>、NOT IN、NOT LIKE等。
-- 索引生效
explain select * from deviceinfo where device_id = '0x719d7986';
-- 索引失效
explain select * from deviceinfo where device_id != '0x719d7986';-- 索引生效
explain select * from deviceinfo where id = 32619;
-- 索引生效
explain select * from deviceinfo where id != 32619;7.联合索引 违背 最左前缀法则
如果索引了多列(联合索引),要遵守最左前缀法则。最左前缀法则指的是查询从索引的最左列开始,并且不跳过索引中的列。如果跳跃某一列,索引将会部分失效(后面的字段索引失效)。
相关文章:

自学数据库-MYSQL
自学数据库-MYSQL 一.表和视图1.表1.1 表创建1.2 索引1.2.1 这里是废话,不感兴趣的可以直接更具目录的跳过这里的内容1.2.1.1 索引是什么1.2.1.2 相关数据结构:二叉树、红黑树、B-Tree、BTree、Hash…①普通索引②唯一索引③全文索引④组合索引 1.3 表数据操作(更新…...

机器学习——多模态学习
多模态学习:机器学习领域的新视野 引言 多模态学习(Multimodal Learning)是机器学习中的一个前沿领域,它涉及处理和整合来自多个数据模式(如图像、文本、音频等)的信息。随着深度学习的蓬勃发展࿰…...

ceph掉电后无法启动osd,pgs unknown
处理办法: 只有1个osd,单副本,掉电损坏osd,只能考虑重建pg,丢失部分数据了。生产环境务必考虑2,3副本设计。避免掉电故障风险。 掉电后osdmap丢失无法启动osd的解决方案 - 武汉-磨渣 - 博客园 https://zhuanlan.zhih…...

HTML5实现古典音乐网站源码模板1
文章目录 1.设计来源1.1 网站首页1.2 古典音乐界面1.3 著名人物界面1.4 古典乐器界面1.5 历史起源界面2.效果和源码2.1 动态效果2.2 源代码源码下载万套模板,程序开发,在线开发,在线沟通作者:xcLeigh 文章地址:https://blog.csdn.net/weixin_43151418/article/details/142…...
快速生成单元测试
1. Squaretest插件 2. 依赖 <dependency><groupId>junit</groupId>...

WebGL系列教程十一(光照原理及Blinn Phong着色模型)
快速导航(持续更新中) WebGL系列教程一(开篇) WebGL系列教程二(环境搭建及着色器初始化) WebGL系列教程三(使用缓冲区绘制三角形) WebGL系列教程四(绘制彩色三角形&…...

《ASP.NET Web Forms 实现短视频点赞功能的完整示例》
在现代Web开发中,实现一个动态的点赞功能是非常常见的需求。本文将详细介绍如何在ASP.NET Web Forms中实现一个视频点赞功能,包括前端页面的展示和后端的处理逻辑。我们将确保点赞数量能够实时更新,而无需刷新整个页面。 技术栈 ASP.NET We…...

Linux SSH服务
Linux SSH(Secure Shell)服务是一种安全的远程登录协议,用于在Linux操作系统上远程登录和执行命令。它提供了加密的通信通道,可以在不安全的网络环境中安全地进行远程访问。 SSH服务在Linux系统中通常使用OpenSSH软件包来实现。它…...

MySQL--视图(详解)
目录 一、前言二、视图2.1概念2.2语法2.3创建视图2.3.1目的 2.4查看视图2.5修改数据2.5.1通过真实表修改数据,会影响视图2.5.2通过修改视图,会影响基表 2.6注意2.7 删除视图2.8 视图的优点 一、前言 欢迎大家来到权权的博客~欢迎大家对我的博客进行指导&…...

Javascript 普通非async函数调用async函数
假设我们有一个异步函数 async function asyncFunction() {console.log("开始执行异步函数");await new Promise(resolve > setTimeout(resolve, 1000)); // 模拟异步操作console.log("异步函数执行完毕"); } 我们在调用这个异步函数时,比…...
【LeetCode】修炼之路-0004-Median of Two Sorted Arrays【python】
题目 Given two sorted arrays nums1 and nums2 of size m and n respectively, return the median of the two sorted arrays. The overall run time complexity should be O(log (mn)). Example 1: Input: nums1 [1,3], nums2 [2] Output: 2.00000 Explanation: merged…...

C++面试速通宝典——10
177. #include <filename> 和 #include "filname.h" 有什么区别? 对于 #include <filename> , 编译器从标准库路径开始搜索 filename.h。 对于 #include "filename.h,编译器从用户的工作…...
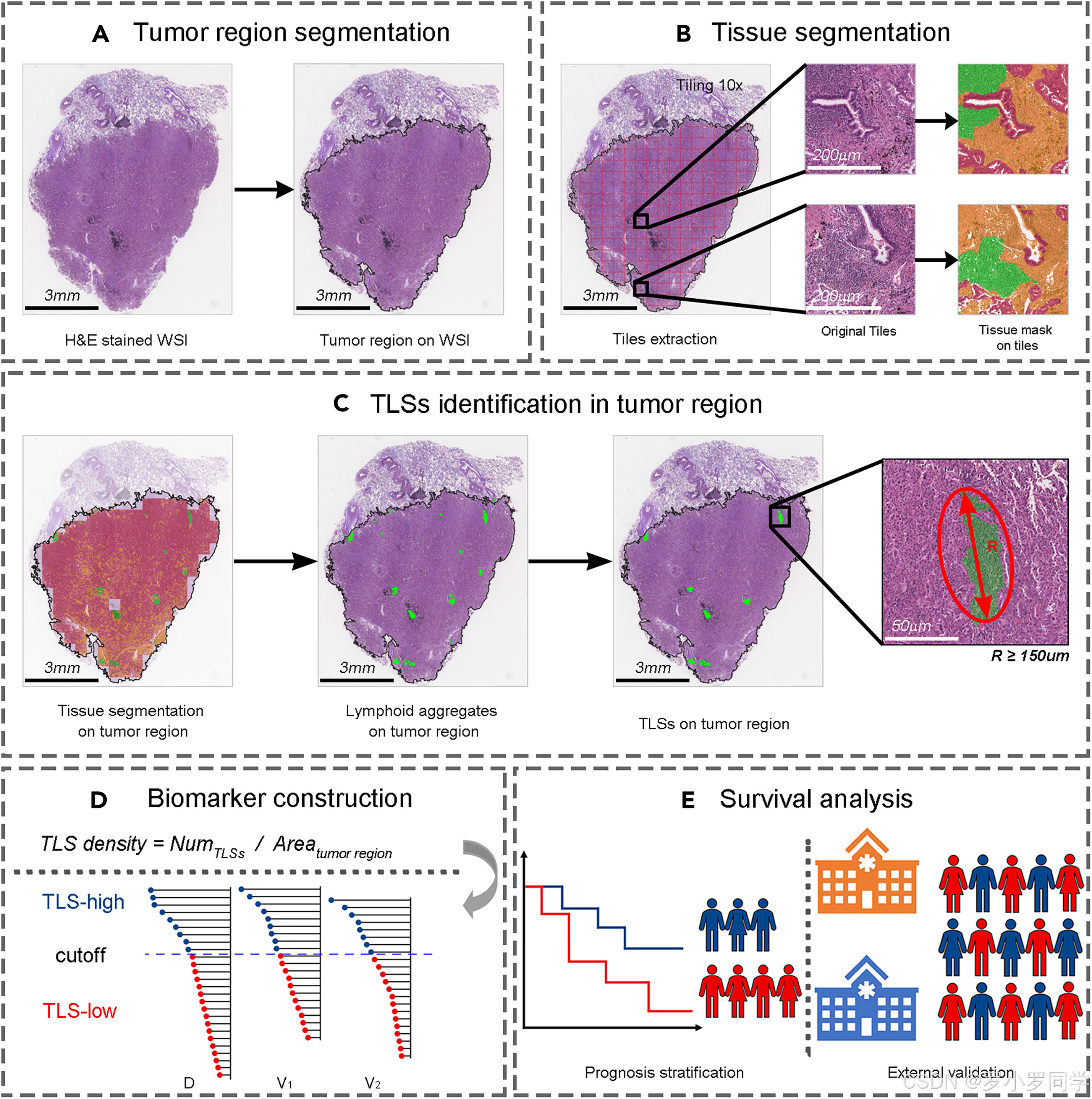
肺腺癌预后新指标:全切片图像中三级淋巴结构密度的自动化量化|文献精析·24-10-09
小罗碎碎念 本期这篇文章,我去年分享过一次。当时发表在知乎上,没有标记参考文献,配图的清晰度也不够,并且分析的还不透彻,所以趁着国庆假期重新分析一下。 这篇文章的标题为《Computerized tertiary lymphoid structu…...
基于jmeter+perfmon的稳定性测试记录
1. 引子 最近承接了项目中一些性能测试的任务,因此决定记录一下,将测试的过程和一些心得收录下来。 说起来性能测试算是软件测试行业内,有些特殊的部分。这部分的测试活动,与传统的测试任务差别是比较大的,也比较依赖…...
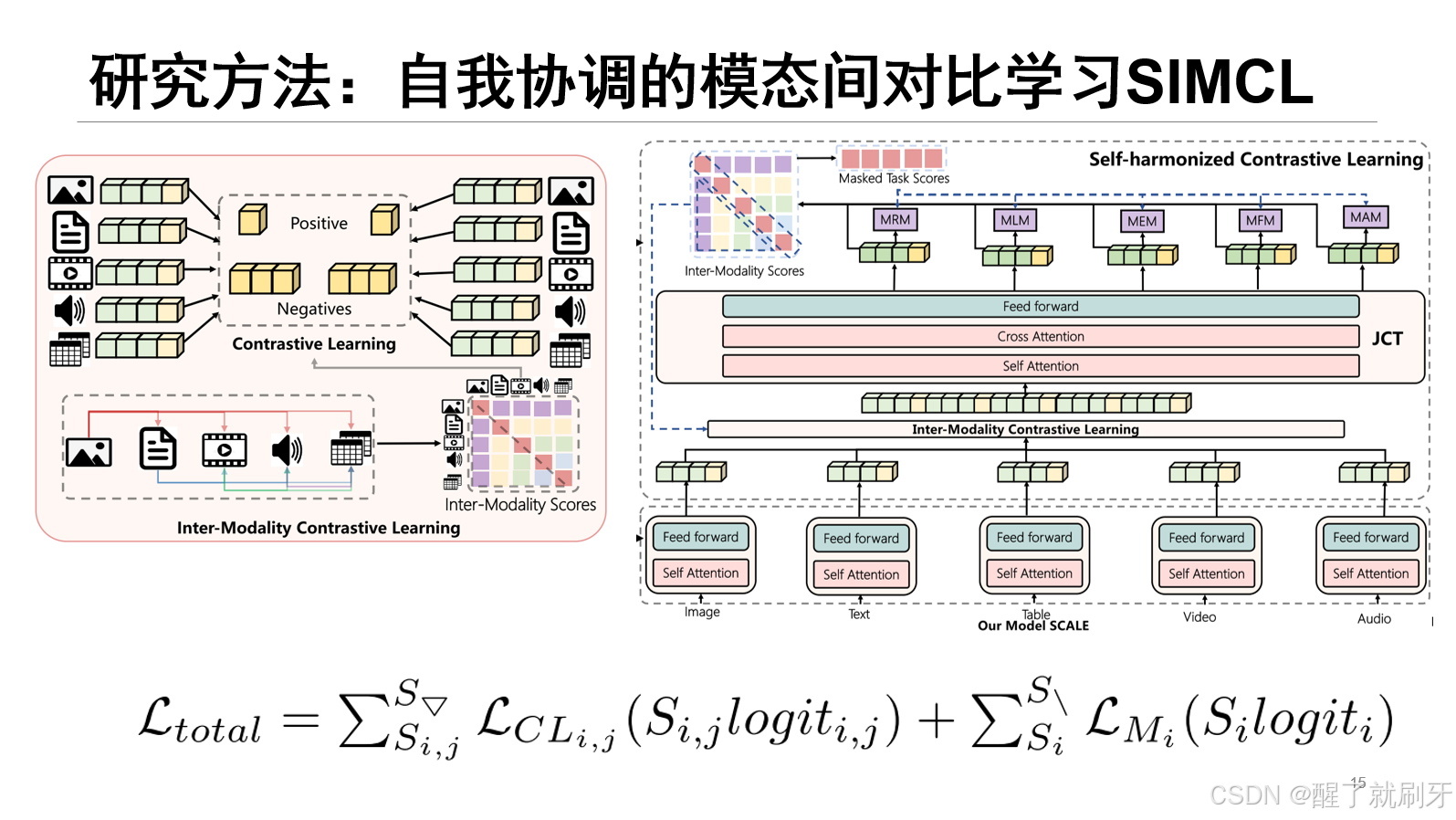
前沿论文 M5Product 组会 PPT
对比学习(Contrast learning):对比学习是一种自监督学习方法,用于在没有标签的情况下,通过让模型学习哪些数据点相似或不同来学习数据集的一般特征。假设一个试图理解世界的新生婴儿。在家里,假设有两只猫和…...

navicat~导出数据库密码
当我们mysql密码忘记了,而在navicat里有记录,我们应该如何导出这个密码呢? 第一步:文件菜单,导出链接,导出连接获取到 connections.ncx 文件 这里需要勾选 导出密码!!! 不然导出的文…...
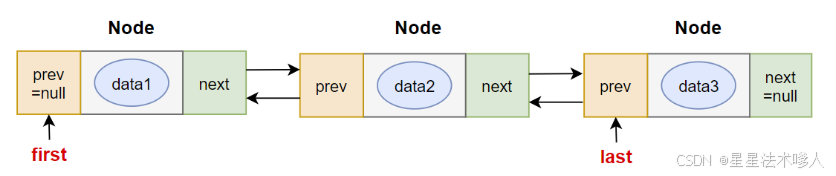
【Java】 —— 数据结构与集合源码:Vector、LinkedList在JDK8中的源码剖析
目录 7.2.4 Vector部分源码分析 7.3 链表LinkedList 7.3.1 链表与动态数组的区别 7.3.2 LinkedList源码分析 启示与开发建议 7.2.4 Vector部分源码分析 jdk1.8.0_271中: //属性 protected Object[] elementData; protected int elementCount;//构造器 public …...
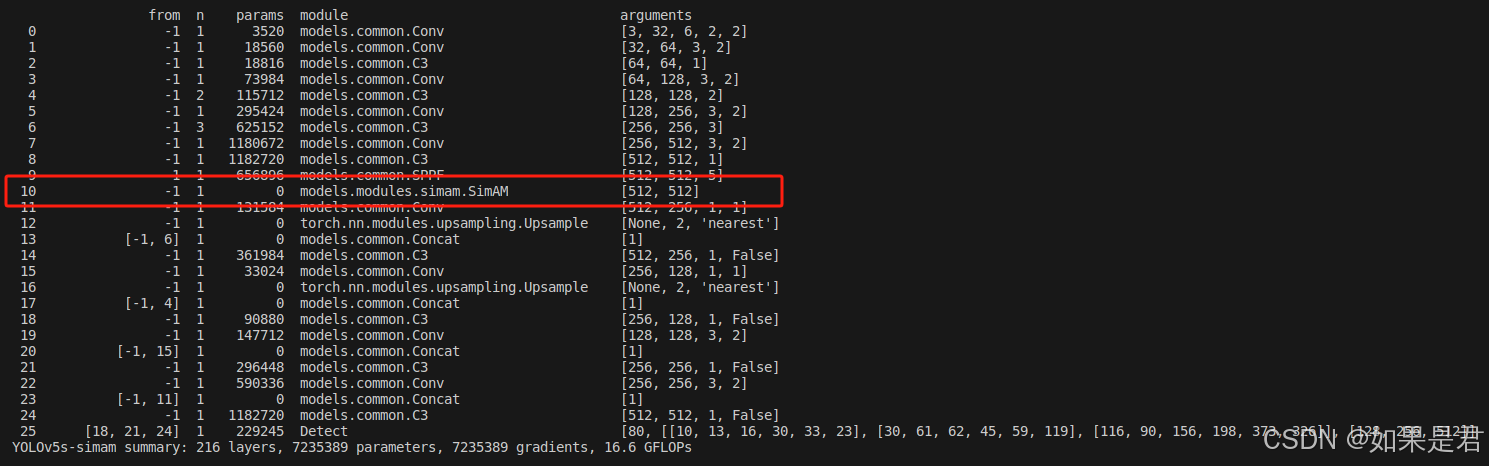
YOLOv5改进——添加SimAM注意力机制
目录 一、SimAM注意力机制核心代码 二、修改common.py 三、修改yolo.py 三、建立yaml文件 四、验证 一、SimAM注意力机制核心代码 在models文件夹下新建modules文件夹,在modules文件夹下新建一个py文件。这里为simam.py。复制以下代码到文件里面。 import…...

SQL 自学:表别名的运用与对被联结表使用聚集函数
一、表别名的概念与作用 (一)表别名的定义 表别名是为表指定的临时名称,在 SQL 查询中使用别名可以简化表名,提高代码的可读性和可维护性。当表名较长或在复杂的查询中多次引用表时,使用表别名可以避免重复输入冗长的…...

jmeter学习(2)变量
1)用户定义的变量 路径:添加-》配置元件-》用户定义的变量 用户定义的变量是全局变量,可以跨线程组被调用,但在启动运行时获取一次值,在运行过程中不再动态获取值。 注意的是,如果在某个线程组定义了全…...

Linux音频驱动开发实战:为TLV320ADC5120编写ALSA Codec驱动
1. 项目概述:从一块“哑巴”音频芯片到Linux系统的“耳朵”最近在折腾一块基于TI TLV320ADC5120的音频采集板,想把它接到我的RK3568开发板上用。芯片手册、硬件原理图都齐了,但一上电,系统里arecord -l根本找不到设备,…...

别再只用CyclicBarrier了!聊聊Java并发库里那个小众但好用的Exchanger
解锁Java并发编程中的隐藏利器:Exchanger深度实战指南 在Java并发编程的世界里,开发者们往往对CyclicBarrier、CountDownLatch这些同步工具如数家珍,却很少有人注意到并发库中那个低调但强大的Exchanger。这个专为线程间数据交换设计的同步点…...

从Struts2漏洞看Java Web安全:一个OGNL表达式注入引发的十年“血案”
OGNL表达式注入:Struts2框架安全漏洞的十年演进与启示 2006年,当Struts2作为Struts框架的下一代产品首次亮相时,开发者社区对其寄予厚望。这个基于MVC架构的Java Web框架承诺提供更简洁的代码结构和更强大的功能扩展性。然而,很少…...

【免费下载】 探索双面神技:STM32G474的USB跨界应用
探索双面神技:STM32G474的USB跨界应用 在物联网与嵌入式开发的世界里,寻找一款能兼顾数据传输与控制沟通的神器是每个开发者的心头好。今天,我们就来揭秘这样一个宝藏项目——STM32G474实现USB的MSCCDC组合功能,它巧妙地将STM32G4…...

用C++模拟堆宝塔游戏:PTA L2-045题解与STL vector实战
用C模拟堆宝塔游戏:PTA L2-045题解与STL vector实战 堆宝塔游戏是一个有趣的逻辑挑战,它要求玩家根据彩虹圈的直径大小,按照特定规则将它们堆叠成宝塔。这个游戏不仅考验玩家的逻辑思维能力,还能帮助我们深入理解C中STL容器的使用…...

AMP插件开发者工具完全指南:如何快速诊断和修复AMP验证问题
AMP插件开发者工具完全指南:如何快速诊断和修复AMP验证问题 【免费下载链接】amp-wp Enable AMP on your WordPress site, the WordPress way. 项目地址: https://gitcode.com/gh_mirrors/am/amp-wp 你是否正在为WordPress网站的AMP验证问题而烦恼࿱…...

AI Agent的推理能力边界:大模型之外的关键技术突破
AI Agent的推理能力边界:大模型之外的关键技术突破 关键词:AI Agent、推理能力边界、工具增强推理、神经符号推理、自主规划、多Agent协同、幻觉抑制 摘要:本文针对当前行业普遍存在的「大模型参数堆得越高,AI Agent推理能力就越强」的认知误区,系统拆解了大模型原生推理能…...

量子优化技术在工业数据生产规划中的应用与实践
1. 量子优化技术在工业数据生产规划中的实践探索在汽车制造领域,生产规划一直是个复杂难题。以冲压车间为例,金属板材需要通过冲压机加工成车身部件,每台冲压机都有不同的工作能力和成本特性,而每个模具组又需要分配到合适的机器上…...

3分钟掌握:ncmdumpGUI免费转换网易云音乐ncm文件的完整指南
3分钟掌握:ncmdumpGUI免费转换网易云音乐ncm文件的完整指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经从网易云音乐下载了心爱的歌…...

WandEnhancer:彻底解锁WeMod专业版功能的终极解决方案
WandEnhancer:彻底解锁WeMod专业版功能的终极解决方案 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod免费版的种种限制而烦恼吗…...