LLM4Rec最新工作: 字节发布用于序列推荐的分层大模型HLLM
前几个月 Meta HSTU 点燃各大厂商对 LLM4Rec 的热情,一时间,探索推荐领域的 Scaling Law、实现推荐的 ChatGPT 时刻、取代传统推荐模型等一系列话题让人兴奋,然而理想有多丰满,现实就有多骨感,尚未有业界公开真正复刻 HSTU 的辉煌。这里面有很多原因,可能是有太多坑要踩,也有可能是 Meta HSTU 的基线较弱,导致国内已经卷成麻花的推荐领域难以应用 HSTU 产生突破性效果。

然而做起来困难并不代表不去做,总要有真的勇士率先攻克难关迈出一步。字节前几天(2024.9.19 发布 arxiv)公开的工作 ⌜HLLM⌟(分层大语言模型)便是沿着这一方向的进一步探索,论文内也提及了 follow HSTU:


论文题目:
HLLM: Enhancing Sequential Recommendations via Hierarchical Large Language Models for Item and User Modeling
论文链接:
https://arxiv.org/abs/2409.12740
代码链接:
https://github.com/bytedance/HLLM
这里我针对全文进行一个详细解析,也会有一些疑问,欢迎评论区探讨以及点赞收藏。
1. 背景
传统推荐问题:推荐重要的是建模 user、item feature,主流方法是 ID-based,将 user、item 转为 ID 并创建对应的 embedding table,然而一般都是 embedding 参数很大而模型参数较小,这会导致以下问题:
- 严重依赖 ID feature 在冷启动时表现不好
- 模型较小难以建模复杂且多样的用户兴趣
过往 LLM 探索方向:大致分为三种:
- 利用 LLM 提供一些信息给推荐系统
- 将推荐系统转变为对话驱动的形式
- 修改 LLM 不再只是文本输入/输出,比如直接输入 ID feature 给 LLM
LLM4Rec 挑战:其中一个 issue 是在相同时间 span 情况下,相比 ID-based 方法 LLM 的输入更长,复杂度更高;另一个是相对于传统方法 LLM-based 方法提升并不显著。
三个关键问题:LLM 应用到推荐有三个问题需要评估:
- LLM 预训练权重的真正价值:模型权重蕴含着世界知识,但是如何激活这些知识,只能使用文本输入吗?这也为之后使用 feature 输入埋下伏笔;
- 对推荐任务进行微调是有有必要性?直接使用 pretrain 还是说要进一步微调?
- LLM 是否可以应用在推荐系统中并呈现 scaling law?
由此提出了 Hierarchical Large Language Mode****l(HLLM)架构,训练 Item LLM(用来提取 item feature)和 User LLM (item feature 作为输入,用于预测下一个 item),实验表明在公开数据集上显著超越 ID-based 方法,并呈现了 Scaling Law 特性。在抖音落地,A/B 实验显示在重要指标上增长 0.705%。
2. 方法
2.1 HLLM
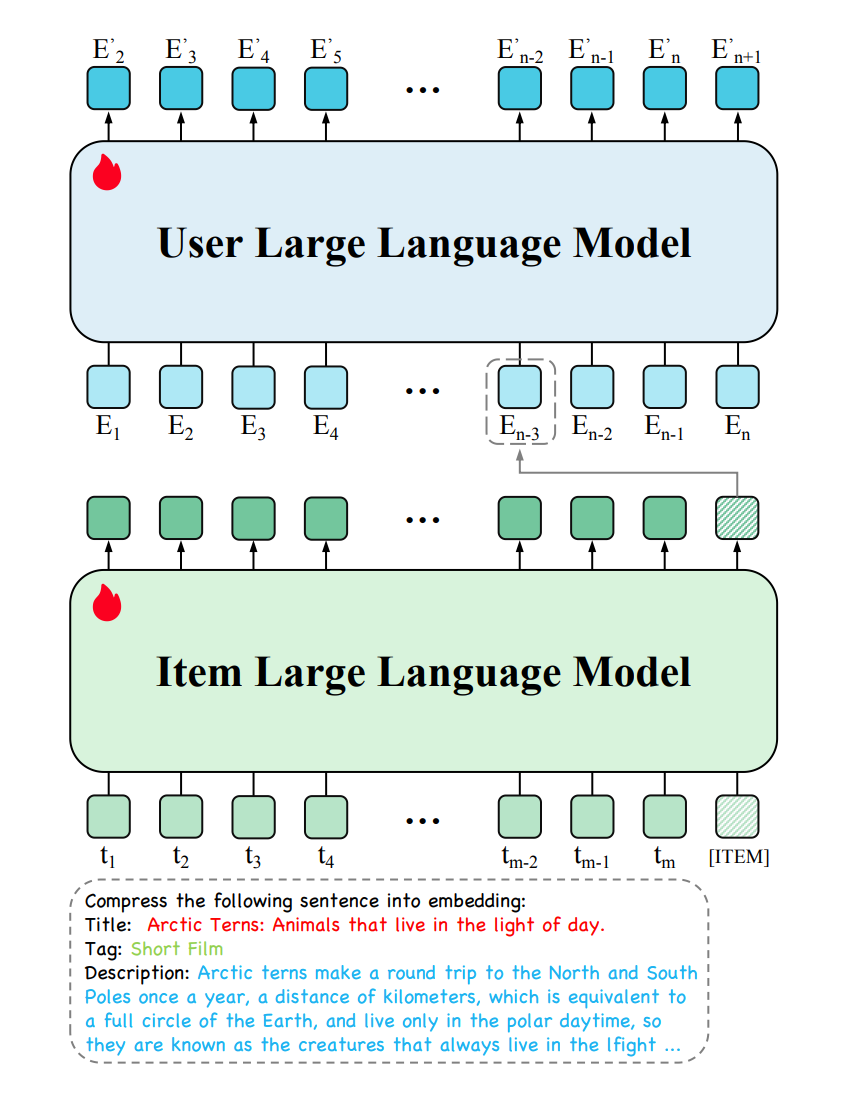
分为 Item LLM 和 User LLM,两者参数并不共享,都是可训练的并通过 next item predict 来进行优化。
可以直接基于已经预训练好的(例如 llama、baichuan)来训练。
Item LLM 使用 item 的描述作为输入,包括 Title、Tag、Description,最后再加上一个特殊 token:[ITEM],特殊 token 对应输出的代表该 item 的 embedding;
User LLM 输入是用户历史交互序列,输入序列中每个 item 就来自于 Item LLM 的输出。由于输入并非文本 token,所以会去除预训练模型的 word embedding;
2.2 优化目标
推荐系统大致分为两类:生成式推****荐与判别式推荐,而 HLLM 同时应用了这两种。
首先针对 Item LLM 的训练虽然论文没提及,但应该就是简单的 next token prediction 的训练,针对输入的每个位置预测下一个 token,损失为交叉熵损失。
其次针对 User LLM 的训练还能用 next token prediction 吗?当然不能!因为去除了 word embedding,词表都没了,还怎么预测 next token。那该怎么做呢?
生成式推荐:
实际会 User LLM 使用 InfoNCE 来作为生成损失,对于某个物品 模型输出的 是正样本,随机抽取的其他物品为负样本,不得不说将对比学习的 InfoNCE 作为预测 next token 的损失设计的很巧妙。
定义的生成式损失函数 如下所示:

这里,公式中的各个符号代表以下含义:
- 是一个相似度函数,带有可学习参数;
- 表示第 个用户的历史交互中由物品 LLM 生成的第 个物品嵌入;
- 表示由用户 LLM 为第 个用户预测的第 个物品嵌入;
- 是负采样的数量, 表示第 个负样本的嵌入;
- 表示批次中的用户总数, 表示用户历史交互的长度;
判别式推荐:
业界主要还是应用判别式推荐模型,HLLM 同样也可。
首先给出问题定义,给定用户的行为序列 和一个目标 item ,模型要预测用户对该 item 感不感兴趣(例如点击、点赞、购买)等。

如上图所示,分为 Early Fusion 和 Late Fusion(实际论文指出真正上线使用的是 Late Fusion)
Early Fusion:将 item 输入给 Item LLM 后得到的 embedding 直接拼到序列后输入给 User LLM,将对应位置的输出做分类。效果好但效率低。
Late Fusion:类似于 Item LLM,使用 User LLM 提取得到用户的 embedding,即 [USER] 拼到序列后输入给 User LLM,将对应位置的输出与 拼到一起做分类。效果差些但效率高。
这两者有点类似单塔和双塔,一个是可以早期进行交叉充分学习但由于候选项过多效率低下,另一个是后期再交叉效率更高。实际在落地使用的是 Late Fusion。
预测是个二分类问题,训练损失函数如下:

其中,y 表示训练样本的标签,x 表示预测的 logit。
经验上,next item prediction 也可以作为判别模型中的辅助损失,用于进一步提升性能。因此,最终的损失函数可以表示为:

其中 用来控制辅助损失的权重。
3. 实验
3.1 公开数据集
数据集使用 PixelRec、Amazon Book,baseline 选用 SASRec 和 HSTU;
离线实验使用生成式推荐(为了与其他方法公平对比),在线 A/B 实验使用判别式推荐(为了与线上系统兼容);
自身模型设置 HLLM-1B、HLLM-7B 两种,HLLM-1B 采用 TinyLlama-1.1B,HLLM-7B 采用 Baichuan2-7B;
HLLM 仅在 PixelRec,Book 训练 5 个 eopch,对比之下其他方法训练 50-200 epoch 不等,其他细节设置详见论文。

简单来说 HLLM 效果比 SASRec 和 HSTU 都要好。
这里有个疑问,目前 HSTU 公开的代码和设置都是忽略了动作这一输入,如若这里实验仅使用 item 并不能真正体现 HSTU 的能力,标星的都是作者自己复现的。
在线 A/B 实验:

【设置】采用 HLLM-1B,应用 判别式推荐 + Late Fusion,
【训练】采用三阶段方法训练:
阶段1:端到端训练 HLLM,包括 Item LLM 和 User LLM,用户行为长度截断为 150 来加速;
阶段2:使用阶段 1 训好的 Item LLM 所有的 item emb 存起来,然后继续只训练 User LLM,输入的 item emb 来自于库内。由于只训练 User LLM,用户行为扩大为 1000;
阶段3:经历前两个阶段大量数据训练后,HLLM 权重不再改变,提取 user feature 和 item feature 喂给线上模型训练。
【推理】在 Serving 阶段,如图所示,item emb 会在其创建时提取,user emb 会进行天级别更新仅仅当用户在前一天发生过交互。基于该方法,线上推理系统推理时间基本不发生变化。
最后做 A/B 实验,重要指标提升 0.705%。
4. 问题
4.1 微调相比直接使用预训练对于推荐目标是否有收益?

**结论1:**对于 Item LLM 和 User LLM,基于预训练微调更好;

**结论2:**预训练使用的 token 越多,效果越好;此外如果预训练后再进行 SFT(在对话场景下),效果会下降,原因可能是因为 SFT 仅仅训练 follow 指令的能力,而对推荐本身无益。

结论3:Item LLM 和 User LLM 都训练会更好。
4.2 HLLM 是否有 Scaling 特性?

针对 Item 和 User LLM 都做了Scaling 实验:
**结论:**对于模型大小具有 scaling 特性;
(模型设置都不是一种结构,LLaMA变成了BERT,这也行?)
4.3 对比 SoTA 方法(HSTU)优势是什么?
论文主要先说了 HLLM 比 HSTU 在相同设置下效果更好,又强调了当增加负样本数量和 batchsize 时,基于 ID 的模型(HSTU)提升相对有限,HSTU-Large R@200 指标 +0.76,而相同设置的 HLLM-1B +2.44。
4.4 训练和 Serving 效率如何?

结论1:相对于 HSTU,HLLM 达到相同性能只需 1/6 至 1/4 的数据,需求更少。其次在实际推理时可以先 cache 所有 item emb;所以 HLLM 可以先训练 item LLM,然后cache item emb,然后再训练 User LLM,上图便展示了在 Pixel8M 的效果。

结论2:itemcache 比原来的性能略微降低,但仍然比 HSTU 好。
值得注意的是,实验所用预训练数据量不到 Pixel8M 的一半,且部分物品未出现在预训练数据中,仍然取得了不错的性能。在工业场景下,用户行为的数据量远大于 item 数量,因此相比 ID-based 模型 cost 一致。工业上实验同时表明,随着预训练数据量的增加,item cache 与 全量微调 之间的 gap 大大缩小。
5. 消融
5.1 Item LLM

结论:Item LLM 采用 Tag + Title + Description + length=256 效果最好。

结论:采用 [ITEM] token 提取 emb 比 mean pooling 方法好。
5.2 UserLLM

结论:输入用户序列长度采用 length=50 相比其他短的会更好。

结论:UserLLM 生成的 LLM emb 比 Item ID emb 更好,LLM emb 加上 ID emb 效果变差,加上 Timestamp emb 效果最好。
5.3 工业场景

结论:工业场景下 Item LLM 和 User LLM 采用 7B 更好,User LLM 输入长度采用 1k 最好。
6. 小结
字节推出的 HLLM 利用大语言模型提取物品特征并建模用户兴趣,有效地将预训练知识集成到推荐系统中,并证明了基于推荐目标的微调至关重要。HLLM 在更大的模型参数下展现了出色的可扩展性。实验表明,HLLM 优于传统的基于 ID 的模型,在学术数据集上取得了很好的结果。在线 A/B 测试进一步验证了 HLLM 的实际效率和适用性,标志着 LLM4Rec 的重大进展。
最后如果您也对AI大模型感兴趣想学习却苦于没有方向👀
小编给自己收藏整理好的学习资料分享出来给大家💖
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码关注免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉如何学习AI大模型?👈
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

相关文章:
LLM4Rec最新工作: 字节发布用于序列推荐的分层大模型HLLM
前几个月 Meta HSTU 点燃各大厂商对 LLM4Rec 的热情,一时间,探索推荐领域的 Scaling Law、实现推荐的 ChatGPT 时刻、取代传统推荐模型等一系列话题让人兴奋,然而理想有多丰满,现实就有多骨感,尚未有业界公开真正复刻 …...

怎么高效对接SaaS平台数据?
SaaS平台数据对接是指将一个或多个SaaS平台中的数据集成到其他应用或平台中的过程。在当前的数字化时代,企业越来越倾向于使用SaaS平台来管理他们的业务和数据。然而,这些数据通常散布在不同的SaaS平台中,这对于企业数据的整合和分析来说可能…...

Spark算子使用-Map,FlatMap,Filter,diatinct,groupBy,sortBy
目录 Map算子使用 FlatMap算子使用 Filter算子使用-数据过滤 Distinct算子使用-数据去重 groupBy算子使用-数据分组 sortBy算子使用-数据排序 Map算子使用 # map算子主要使用长场景,一个转化rdd中每个元素的数据类型,拼接rdd中的元素数据…...

CSS响应式布局
CSS 响应式布局也称自适应布局,是 Ethan Marcotte 在 2010 年 5 月份提出的一个概念,简单来讲就是一个网站能够兼容多个不同的终端(设备),而不是为每个终端做一个特定的版本。这个概念是为解决移动端浏览网页而诞生的。…...

AI大模型书籍丨掌握 LLM 和 RAG 技术,这本大模型小鸟书值得一看!
本指南旨在帮助数据科学家、机器学习工程师和机器学习/AI 架构师探索信息检索与 LLMs 的集成及其相互增强。特别聚焦于 LLM 和检索增强生成(RAG)技术在信息检索中的应用,通过引入外部数据库与 LLMs 的结合,提高检索系统的性能。 …...

Mysql和Oracle使用差异和主观感受
这两种常用的关系型数据库有何差异? 支持和社区 MySQL:有一个活跃的开源社区,用户可以获取大量的文档和支持。 Oracle:提供了专业的技术支持,但通常需要额外的费用。 易用性 MySQL:通常被认为是更易于学…...

【Java】—— File类与IO流:File类的实例化与常用方法
目录 1. java.io.File类的使用 1.1 概述 1.2 构造器 1.3 常用方法 1、获取文件和目录基本信息 2、列出目录的下一级 3、File类的重命名功能 4、判断功能的方法 5、创建、删除功能 1.4 练习 练习1: 练习2: 练习3: 1. java.io.Fil…...

C++设计模式——装饰器模式
欢迎来到 破晓的历程的 博客 ⛺️不负时光,不负己✈️ 什么是装饰器模式? 装饰器模式(Decorator Pattern)是一种结构型设计模式,允许你向一个现有的对象添加新的功能,同时又不改变其结构。这种模式通过创…...

C#使用ITextSharp生成PDF文件实例详解
许多项目开发中需要生成PDF, 常规办法使用官方提供的Microsoft.Office.Interop.Worddll插件,但是这种方法需要完全安装OFFICE,另外版本不一致还会出现很多错误。一般不推荐使用。 下面介绍这种巧妙的用法,定能事半功倍。 本文使用ITextSharp完成功能。 首先,通过NuGet…...

10.9QT对话框以及QT的事件机制处理
MouseMoveEvent(鼠标移动事件) widget.cpp #include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this);// 设置窗口为无边框,去掉标题栏等装饰this->setWi…...

SiLM266x系列SiLM2661高压电池组前端充/放电高边NFET驱动器 为电池系统保护提供可靠性和设计灵活性
SiLM2661产品概述: SiLM2661能够灵活的应对不同应用场景对锂电池进行监控和保护的需求,为电池系统保护提供可靠性和设计灵活性。是用于电池充电/放电系统控制的低功耗、高边 N 沟道 FET 驱动器,高边保护功能可避免系统的接地引脚断开连接&am…...

linux中sed命令详解
sed 是 Linux 中的一个流编辑器(stream editor),主要用于处理文本的编辑和转换。它可以从文件或标准输入读取内容,然后根据指定的模式和指令对数据进行处理,最后输出修改后的结果。它的强大之处在于可以通过脚本或命令…...

vue 模板语法
Vue 使用一种基于 HTML 的模板语法,使我们能够声明式地将其组件实例的数据绑定到呈现的 DOM 上。所有的 Vue 模板都是语法层面合法的 HTML,可以被符合规范的浏览器和 HTML解析器解析。 文本插值 最基本的数据绑定形式是文本插值,它使用的是…...

bladex漏洞思路总结
Springblade框架介绍: SpringBlade是一个基于Spring Boot和Spring Cloud的微服务架构框架,它是由商业级项目升级优化而来的综合型项目。 0x1 前言 最近跟一些大佬学习了blade的漏洞,所以自己总结了一下,在渗透测试过程中&#x…...

解决SqlServer自增主键使用MybatisPlus批量插入报错问题
报错 SqlServer 表中主键设置为自增,会报以下错误。 org.springframework.jdbc.UncategorizedSQLException: Error getting generated key or setting result to parameter object. Cause: com.microsoft.sqlserver.jdbc.SQLServerException: 必须执行该语句才能获…...

leetcode:反转字符串中的单词III
题目链接 string reverse(string s1) {string s2;string::reverse_iterator rit s1.rbegin();while (rit ! s1.rend()){s2 *rit;rit;}return s2; } class Solution { public:string reverseWords(string s) {string s1; int i 0; int j 0; int length s.length(); for (i …...

深度学习常见问题
1.YOLOV5和YOLOV8的区别 YOLOv5 和 YOLOv8 是两个版本的 YOLO(You Only Look Once)目标检测算法,它们在网络架构、性能优化、功能扩展等方面有显著的区别。YOLOv5 是 YOLO 系列的重要改进版本,而 YOLOv8 是最新的一次重大升级&am…...

神经网络的一些benchmark示例
1.MLPerf https://github.com/mlcommons/inference?tabreadme-ov-file https://docs.mlcommons.org/inference/benchmarks/text_to_image/sdxl/ MLPerf 是一个业界标准的机器学习基准测试套件,旨在评估各种硬件、框架和模型的性能。它包含训练和推理两个部分&…...

如何进行统级架构设计
统级架构设计是一个复杂的过程,需要综合考虑业务需求、技术选型、系统可扩展性、可维护性等多个方面。以下是一份系统级架构设计的方法论,包括以下几个步骤: 需求分析: 与业务相关人员进行深入沟通,了解业务需求、业…...

鼓组编写:SsdSample鼓映射 GM Map 自动保存 互换midi位置 风格模板 逻辑编辑器
SsdSample音源的键位映射 方便编写鼓的技巧 可以这样去设置键位关系的面板和钢琴卷帘窗的面板,方便去写鼓。 可以先按GM的midi标准去写鼓,然后比对下鼓的键位映射的关系,去调整鼓。 可以边看自己发b站等处的图文笔记,然后边用电…...

【NotebookLM+IEA/IRENA数据融合实战】:72小时内完成新型储能技术竞争力评估
更多请点击: https://codechina.net 第一章:NotebookLM能源技术研究 NotebookLM 是 Google 推出的基于 AI 的研究协作者工具,其核心能力在于对用户上传的文档进行语义理解与上下文驱动的问答。在能源技术研究领域,NotebookLM 可显…...

考研高数救星:用Python的SymPy库5分钟搞定洛必达法则极限题
考研高数救星:用Python的SymPy库5分钟搞定洛必达法则极限题 数学分析中,洛必达法则堪称求解极限问题的"瑞士军刀",尤其对于0/0型和∞/∞型未定式。但传统手工求解往往需要反复求导验证,既耗时又容易出错。如今ÿ…...

使用Taotoken后API调用延迟与稳定性体感观察报告
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken后API调用延迟与稳定性体感观察报告 1. 引言:从直接对接模型到使用聚合平台 在开发基于大语言模型的应用…...

出库篇:仓库里的货往哪去?——WMS出库方式全解析,物流新人必读
仓库里的货往哪去?——WMS出库方式全解析,物流新人必读 摘要:货品有进必有出。上一期我们聊了WMS中货品的四大来源(采购、生产、退货、调拨入库),这一期我们来看看货品是怎么“出”去的——销售出库、采购退…...

基于HPM5E00与LAN9252的EtherCAT从站开发板全流程实战
1. 项目概述:从零到一,打造专属的 EtherCAT 从站开发板 最近在工业自动化圈子里,EtherCAT 的热度一直居高不下。它那近乎实时的通讯性能、灵活的拓扑结构,让它在运动控制、机器人、高端数控机床等领域成了“香饽饽”。但很多开发者…...
——MS MARCO 实战指南)
IR 召回评测基准(英文数据集)——MS MARCO 实战指南
1. MS MARCO数据集全景解读 第一次接触MS MARCO时,我和大多数开发者一样困惑:这个号称"信息检索领域ImageNet"的数据集到底强在哪里?经过三个实际项目的验证,我发现它的价值在于完美复现了真实搜索场景的复杂性。想象你…...

2位相位可重构天线设计与波束控制技术解析
1. 2位相位可重构天线技术概述相位可重构天线作为现代无线通信系统的关键组件,其核心价值在于能够动态调整辐射波束的方向和形状。这种能力使其成为5G/6G通信、雷达系统和卫星通信等场景中的理想选择。2位相位可重构天线通过4种离散相位状态(00、01、10、…...

米尔i.MX 93核心板:异构计算与AI赋能入门级嵌入式开发实战
1. 项目概述:米尔NXP i.MX 93核心板如何重塑入门级嵌入式体验 在嵌入式开发领域,选型往往是一场在性能、成本和功能之间的艰难平衡。对于许多从事工业HMI、智能网关、便携式医疗设备或新能源充电桩开发的工程师来说,他们既需要一颗能流畅运行…...

终极无人机仿真平台XTDrone:从入门到精通的完整指南
终极无人机仿真平台XTDrone:从入门到精通的完整指南 【免费下载链接】XTDrone UAV Simulation Platform based on PX4, ROS and Gazebo 项目地址: https://gitcode.com/gh_mirrors/xt/XTDrone XTDrone是一款基于PX4飞控、ROS机器人操作系统和Gazebo物理引擎的…...

5分钟掌握猫抓扩展:浏览器视频下载终极指南
5分钟掌握猫抓扩展:浏览器视频下载终极指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否经常遇到精彩的在线视频却无法下载保…...