神经网络的一些benchmark示例
1.MLPerf
https://github.com/mlcommons/inference?tab=readme-ov-file
https://docs.mlcommons.org/inference/benchmarks/text_to_image/sdxl/
MLPerf 是一个业界标准的机器学习基准测试套件,旨在评估各种硬件、框架和模型的性能。它包含训练和推理两个部分,涵盖多种机器学习任务,例如图像分类、对象检测、自然语言处理、推荐系统等。MLPerf 主要分为几个子项目,包括 Training(训练)、Inference(推理)和 Tiny(针对低功耗设备的测试)。它支持多种平台,如 CPU、GPU 和专用的 AI 加速器,广泛用于学术界、企业和开源社区评估 AI 系统的性能
下文以https://docs.mlcommons.org/inference/benchmarks/text_to_image/sdxl/#__tabbed_1_1 为例
1. 安装cm
python >=3.8(本例使用的是3.9)
git 版本不能太低,否则有些命令执行不了
pip install cmind
pip install --no-use-pep517 cm4mlops
#需要绕过pep517 ,否则报一下错误
note: This error originates from a subprocess, and is likely not a problem with pip.ERROR: Failed building wheel for cm4mlopsRunning setup.py clean for cm4mlops
Failed to build cm4mlops
ERROR: ERROR: Failed to build installable wheels for some pyproject.toml based projects (cm4mlops)
2. inference
MLCommons-Python -> pytoch -> cuda -> native -> Performance Estimation for Offline Scenario
cm run script --tags=install,python-venv --name=mlperf
export CM_SCRIPT_EXTRA_CMD="--adr.python.name=mlperf"
cm run script --tags=run-mlperf,inference,_find-performance,_full,_r4.1-dev \--model=sdxl \--implementation=reference \--framework=pytorch \--category=edge \--scenario=Offline \--execution_mode=test \--device=cuda \--quiet \--test_query_count=50
如果git clone https://github.com/mlcommons/inference.git不了,手动下载之后在上述命令假如下述路径
--inference_src=${USER_PATH}$/cuda/inference部分数据下载较久
Collecting torchDownloading torch-2.4.1-cp39-cp39-manylinux1_x86_64.whl (797.1 MB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 797.1/797.1 MB 4.1 MB/s eta 0:00:00
Collecting nvidia-nccl-cu12==2.20.5Downloading nvidia_nccl_cu12-2.20.5-py3-none-manylinux2014_x86_64.whl (176.2 MB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 176.2/176.2 MB 3.8 MB/s eta 0:00:00
Collecting nvidia-cudnn-cu12==9.1.0.70Downloading nvidia_cudnn_cu12-9.1.0.70-py3-none-manylinux2014_x86_64.whl (664.8 MB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 664.8/664.8 MB 2.0 MB/s eta 0:00:00
Collecting nvidia-cublas-cu12==12.1.3.1Downloading nvidia_cublas_cu12-12.1.3.1-py3-none-manylinux1_x86_64.whl (410.6 MB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 410.6/410.6 MB 3.6 MB/s eta 0:00:00
Requirement already satisfied: sympy in /home/u200810220/CM/repos/local/cache/13d32961b74a4500/mlperf/lib/python3.9/site-packages (from torch) (1.13.3)
Collecting filelockDownloading filelock-3.16.1-py3-none-any.whl (16 kB)
Collecting nvidia-cufft-cu12==11.0.2.54Downloading nvidia_cufft_cu12-11.0.2.54-py3-none-manylinux1_x86_64.whl (121.6 MB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 121.6/121.6 MB 7.2 MB/s eta 0:00:00
Collecting nvidia-cusparse-cu12==12.1.0.106Downloading nvidia_cusparse_cu12-12.1.0.106-py3-none-manylinux1_x86_64.whl (196.0 MB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 196.0/196.0 MB 3.6 MB/s eta 0:00:00
Collecting nvidia-cuda-nvrtc-cu12==12.1.105Downloading nvidia_cuda_nvrtc_cu12-12.1.105-py3-none-manylinux1_x86_64.whl (23.7 MB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 23.7/23.7 MB 4.1 MB/s eta 0:00:00
Collecting nvidia-cusolver-cu12==11.4.5.107Downloading nvidia_cusolver_cu12-11.4.5.107-py3-none-manylinux1_x86_64.whl (124.2 MB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 124.2/124.2 MB 8.9 MB/s eta 0:00:00
Collecting nvidia-nvtx-cu12==12.1.105Downloading nvidia_nvtx_cu12-12.1.105-py3-none-manylinux1_x86_64.whl (99 kB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 99.1/99.1 kB 9.4 MB/s eta 0:00:00
Collecting triton==3.0.0Downloading triton-3.0.0-1-cp39-cp39-manylinux2014_x86_64.manylinux_2_17_x86_64.whl (209.4 MB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 209.4/209.4 MB 4.8 MB/s eta 0:00:00
Collecting fsspecDownloading fsspec-2024.9.0-py3-none-any.whl (179 kB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 179.3/179.3 kB 6.7 MB/s eta 0:00:00
Collecting nvidia-curand-cu12==10.3.2.106Downloading nvidia_curand_cu12-10.3.2.106-py3-none-manylinux1_x86_64.whl (56.5 MB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 56.5/56.5 MB 4.8 MB/s eta 0:00:00
Collecting nvidia-cuda-cupti-cu12==12.1.105Downloading nvidia_cuda_cupti_cu12-12.1.105-py3-none-manylinux1_x86_64.whl (14.1 MB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 14.1/14.1 MB 5.5 MB/s eta 0:00:00
Collecting networkxDownloading networkx-3.2.1-py3-none-any.whl (1.6 MB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.6/1.6 MB 5.4 MB/s eta 0:00:00
Collecting jinja2Downloading jinja2-3.1.4-py3-none-any.whl (133 kB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 133.3/133.3 kB 4.9 MB/s eta 0:00:00
Collecting nvidia-cuda-runtime-cu12==12.1.105Downloading nvidia_cuda_runtime_cu12-12.1.105-py3-none-manylinux1_x86_64.whl (823 kB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 823.6/823.6 kB 6.3 MB/s eta 0:00:00
Requirement already satisfied: typing-extensions>=4.8.0 in /home/u200810220/CM/repos/local/cache/13d32961b74a4500/mlperf/lib/python3.9/site-packages (from torch) (4.12.2)
Collecting nvidia-nvjitlink-cu12Downloading nvidia_nvjitlink_cu12-12.6.77-py3-none-manylinux2014_x86_64.whl (19.7 MB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 19.7/19.7 MB 5.2 MB/s eta 0:00:00Downloading: rclone sync 'mlc-inference:mlcommons-inference-wg-public/stable_diffusion_fp32' '/home/u200810220/CM/repos/local/cache/e00a5f70d26c4213/stable_diffusion_fp32' -P --error-on-no-transfer
Transferred: 12.824 GiB / 12.926 GiB, 99%, 28.401 KiB/s, ETA 1h2m34s
Transferred: 18 / 19, 95%
Elapsed time: 23m42.3s
Transferring:* checkpoint_pipe/unet/d…orch_model.safetensors: 98% /9.565Gi, 28.421Ki/s, 1h2m31s^Z
[5]+ Stopped cm run script --tags=run-mlperf,inference,_find-performance,_full,_r4.1-dev --model=sdxl --implementation=reference --framework=pytorch --category=edge --scenario=Offli
Transferred: 12.841 GiB / 12.926 GiB, 99%, 27.910 KiB/s, ETA 53m11s
Transferred: 18 / 19, 95%
Elapsed time: 34m2.3s
Transferring:* checkpoint_pipe/unet/d…orch_model.safetensors: 99% /9.565Gi, 28.406Ki/s, 52m16s^Z
[5]+ Stopped cm run script --tags=run-mlperf,inference,_find-performance,_full,_r4.1-dev --model=sdxl --implementation=reference --framework=pytorch --category=edge --scenario=Offli
Transferred: 12.858 GiB / 12.926 GiB, 99%, 27.617 KiB/s, ETA 42m33s
Transferred: 18 / 19, 95%
Elapsed time: 44m44.3s
Transferring:* checkpoint_pipe/unet/d…orch_model.safetensors: 99% /9.565Gi, 27.648Ki/s, 42m30s2.CUDA_benchmark
https://github.com/hibagus/CUDA_Bench
CUDA Benchmark 是一种用于评估在 NVIDIA GPU 上运行的程序性能的工具。它提供了一系列基准测试,用来测量不同算法、库或工作负载在 CUDA 平台上的性能表现。常见的测试类型包括矩阵乘法、向量加法、卷积操作等,通过这些基准可以有效评估硬件资源的利用率、带宽、延迟等关键指标,帮助开发者优化 CUDA 程序的性能。CUDA Benchmark 通常用于比较不同 GPU 或优化代码执行效率。
CMake更新办法:
需要cmake3.20.1以上版本
sudo apt remove cmake
wget https://github.com/Kitware/CMake/releases/download/v3.20.1/cmake-3.20.1-linux-x86_64.sh
sudo bash cmake-3.20.1-linux-x86_64.sh --skip-license --prefix=/usr/local
export PATH=/usr/local/bin:$PATHmake 不通过 手动下载https://github.com/rapidsai/rapids-cmake 适配不成功
(base) @n1:~/cuda/CUDA_Bench/build$ make
[ 11%] Built target cutlass
[ 13%] Performing configure step for 'nvbench'
make[3]: Entering directory '/home/u200810220/cuda/CUDA_Bench/build/nvbench/build/src/nvbench-build/_deps/rapids-cmake-subbuild'
make[4]: Entering directory '/home/u200810220/cuda/CUDA_Bench/build/nvbench/build/src/nvbench-build/_deps/rapids-cmake-subbuild'
make[5]: Entering directory '/home/u200810220/cuda/CUDA_Bench/build/nvbench/build/src/nvbench-build/_deps/rapids-cmake-subbuild'
make[5]: Leaving directory '/home/u200810220/cuda/CUDA_Bench/build/nvbench/build/src/nvbench-build/_deps/rapids-cmake-subbuild'
make[5]: Entering directory '/home/u200810220/cuda/CUDA_Bench/build/nvbench/build/src/nvbench-build/_deps/rapids-cmake-subbuild'
[ 11%] Performing update step for 'rapids-cmake-populate'
fatal: unable to access 'https://github.com/rapidsai/rapids-cmake.git/': Failed to connect to github.com port 443: Connection timed out
CMake Error at /home/u200810220/cuda/CUDA_Bench/build/nvbench/build/src/nvbench-build/_deps/rapids-cmake-subbuild/rapids-cmake-populate-prefix/tmp/rapids-cmake-populate-gitupdate.cmake:97 (execute_process):execute_process failed command indexes:1: "Child return code: 128"CMakeFiles/rapids-cmake-populate.dir/build.make:135: recipe for target 'rapids-cmake-populate-prefix/src/rapids-cmake-populate-stamp/rapids-cmake-populate-update' failed
make[5]: *** [rapids-cmake-populate-prefix/src/rapids-cmake-populate-stamp/rapids-cmake-populate-update] Error 1
make[5]: Leaving directory '/home/u200810220/cuda/CUDA_Bench/build/nvbench/build/src/nvbench-build/_deps/rapids-cmake-subbuild'
CMakeFiles/Makefile2:82: recipe for target 'CMakeFiles/rapids-cmake-populate.dir/all' failed
make[4]: *** [CMakeFiles/rapids-cmake-populate.dir/all] Error 2
make[4]: Leaving directory '/home/u200810220/cuda/CUDA_Bench/build/nvbench/build/src/nvbench-build/_deps/rapids-cmake-subbuild'
Makefile:90: recipe for target 'all' failed
make[3]: *** [all] Error 2
make[3]: Leaving directory '/cuda/CUDA_Bench/build/nvbench/build/src/nvbench-build/_deps/rapids-cmake-subbuild'CMake Error at /usr/local/share/cmake-3.20/Modules/FetchContent.cmake:1012 (message):Build step for rapids-cmake failed: 2
Call Stack (most recent call first):/usr/local/share/cmake-3.20/Modules/FetchContent.cmake:1141:EVAL:2 (__FetchContent_directPopulate)/usr/local/share/cmake-3.20/Modules/FetchContent.cmake:1141 (cmake_language)/usr/local/share/cmake-3.20/Modules/FetchContent.cmake:1184 (FetchContent_Populate)/home/u200810220/cuda/CUDA_Bench/build/nvbench/build/src/nvbench-build/NVBENCH_RAPIDS.cmake:35 (FetchContent_MakeAvailable)cmake/NVBenchRapidsCMake.cmake:9 (include)CMakeLists.txt:16 (nvbench_load_rapids_cmake)-- Configuring incomplete, errors occurred!
See also "/cuda/CUDA_Bench/build/nvbench/build/src/nvbench-build/CMakeFiles/CMakeOutput.log".
CMakeFiles/nvbench.dir/build.make:91: recipe for target 'nvbench/build/src/nvbench-stamp/nvbench-configure' failed
make[2]: *** [nvbench/build/src/nvbench-stamp/nvbench-configure] Error 1
CMakeFiles/Makefile2:252: recipe for target 'CMakeFiles/nvbench.dir/all' failed
make[1]: *** [CMakeFiles/nvbench.dir/all] Error 2
Makefile:90: recipe for target 'all' failed
make: *** [all] Error 2
[ 11%] Built target cutlass
[ 13%] Performing configure step for 'nvbench'
3.NAS-Bench-Graph
https://github.com/THUMNLab/NAS-Bench-Graph
https://github.com/THUMNLab/AutoGL/tree/agnn
NAS-Bench-Graph 是一个用于神经架构搜索(Neural Architecture Search, NAS)的基准测试工具,专注于图神经网络(Graph Neural Networks, GNNs)。它提供了一个预定义的搜索空间,涵盖了多种图神经网络架构,并包含了这些架构在多个数据集上的训练与评估结果。通过这个基准,研究人员可以更轻松地进行神经架构搜索的实验,并快速比较不同方法的性能。这一工具大大加速了 GNN 的架构搜索和优化研究。
版本不适配
graph_neural_network
https://github.com/mlcommons/training/tree/master/graph_neural_network
cd training/gnn_node_classification/
docker build -f Dockerfile -t training_gnn:latest .
高性能平台docker 命令被拒绝
4.ogb
https://github.com/snap-stanford/ogb
OGB(Open Graph Benchmark)是一个专门用于图神经网络(GNN)研究的大规模基准测试集合,涵盖各种真实世界的图数据集,如社交网络、知识图谱和分子图。OGB 提供标准化的数据集和性能评估指标,使研究人员能够更有效地比较不同的图神经网络模型。它支持不同任务类型,包括节点分类、边预测和图分类,适用于大规模的图结构数据,推动图神经网络研究和应用的发展。
pip install ogb
依赖版本不适配
5.nasbench301
NAS-Bench-301 是一个神经架构搜索(NAS)基准,专门用于提升 NAS 方法的研究效率。它提供了一个更具挑战性的搜索空间,并基于更广泛的架构评估结果,避免了对真实硬件的高昂训练成本。NAS-Bench-301 提供了一个高效的代理模型,能够快速预测神经网络架构的性能,而无需重新训练每个架构。这个基准支持多种搜索策略,并帮助研究人员更轻松地进行实验与评估。
https://github.com/automl/nasbench301
https://www.cnblogs.com/pprp/p/15491922.html
6.benchmarking-gnns
https://github.com/graphdeeplearning/benchmarking-gnns
https://www.cvmart.net/community/detail/1578
Benchmarking-GNNs 是一个专注于图神经网络(Graph Neural Networks, GNNs)的基准测试框架,用于系统地比较各种 GNN 模型在不同图形任务上的性能。它为 GNN 研究提供了标准化的数据集和实验环境,支持的任务包括节点分类、边预测和图分类。该基准测试框架的目标是推动 GNN 研究的进展,使研究人员能够更有效地开发和优化 GNN 模型,提升其在真实世界应用中的性能。
# Setup CUDA 10.2 on Ubuntu 18.04
sudo apt-get --purge remove "*cublas*" "cuda*"
sudo apt --purge remove "nvidia*"
sudo apt autoremove
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-repo-ubuntu1804_10.2.89-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu1804_10.2.89-1_amd64.deb
sudo apt-key adv --fetch-keys http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub
sudo apt update
sudo apt install -y cuda-10-2
sudo reboot
cat /usr/local/cuda/version.txt # Check CUDA version is 10.2# Clone GitHub repo
conda install git
git clone https://github.com/graphdeeplearning/benchmarking-gnns.git
cd benchmarking-gnns# Install python environment
conda env create -f environment_gpu.yml # Activate environment
conda activate benchmark_gnn
cuda 版本不适配
7.gnn-benchmark
https://github.com/shchur/gnn-benchmark
(base) :~/cuda$ sudo apt-get install -y mongodb-org=3.6.4 mongodb-org-server=3.6.4 mongodb-org-shell=3.6.4 mongodb-org-mongos=3.6.4 mongodb-org-tools=3.6.4
Reading package lists... Done
Building dependency tree
Reading state information... Done
E: Unable to locate package mongodb-org
E: Unable to locate package mongodb-org-server
E: Unable to locate package mongodb-org-shell
E: Unable to locate package mongodb-org-mongos
E: Version '3.6.4' for 'mongodb-org-tools' was not found
原版本要求的MongoDB在ubuntu18.04中找不到
相关文章:

神经网络的一些benchmark示例
1.MLPerf https://github.com/mlcommons/inference?tabreadme-ov-file https://docs.mlcommons.org/inference/benchmarks/text_to_image/sdxl/ MLPerf 是一个业界标准的机器学习基准测试套件,旨在评估各种硬件、框架和模型的性能。它包含训练和推理两个部分&…...

如何进行统级架构设计
统级架构设计是一个复杂的过程,需要综合考虑业务需求、技术选型、系统可扩展性、可维护性等多个方面。以下是一份系统级架构设计的方法论,包括以下几个步骤: 需求分析: 与业务相关人员进行深入沟通,了解业务需求、业…...

鼓组编写:SsdSample鼓映射 GM Map 自动保存 互换midi位置 风格模板 逻辑编辑器
SsdSample音源的键位映射 方便编写鼓的技巧 可以这样去设置键位关系的面板和钢琴卷帘窗的面板,方便去写鼓。 可以先按GM的midi标准去写鼓,然后比对下鼓的键位映射的关系,去调整鼓。 可以边看自己发b站等处的图文笔记,然后边用电…...

使用YOLOv11进行视频目标检测
使用YOLOv11进行视频目标检测 完整代码 import cv2 from ultralytics import YOLOdef predict(chosen_model, img, classes[], conf0.5):if classes:results chosen_model.predict(img, classesclasses, confconf)else:results chosen_model.predict(img, confconf)return r…...

DEEP和DeepBook V3将于10月14日推出
10月14日星期一,DeepBook V3和DEEP token将同时在Sui上线。这两个公告标志着Sui生态内流动性发展的重要时刻,同时引入了去中心化和治理机制。 经过数月的开发,基于Sui构建的安全且完全链上的中央限价订单簿(Central Limit Order …...

学习之高阶编程列表推导式,字典推导式
def test_list_one(): “”“快速生成一个[“data0”, “data1”,]列表”“” list1 [] for i in range(100): list1.append(“data{}”.format(i)) return list1 def test_list_two(): “”" 快速生成一个[“data0”, “data1”,]列表 列表推导式:[x for x …...

QT实现QInputDialog中文按钮
这是我记录Qt学习过程心得文章的第三篇,主要是为了方便QInputDialog输入框的使用,通过自定义的方式,按钮中文化,统一封装成一个函数,还是写在了Skysonya类里面。 实现代码: //中文按钮文本输入对话框 QSt…...

Redis 常用指令技术解读
全文目录: 前言前言摘要简介概述Redis的核心特性Redis指令分类 核心源码解读SET和GET指令EXPIRE指令HSET和HGET指令LPUSH和LPOP指令SADD和SMEMBERS指令ZADD和ZRANGE指令 案例分析案例1:用户登录会话管理案例2:排行榜实现 应用场景演示优缺点分…...

Web前端入门
文章目录 前言1 Web前端概述1.1 网站和网页1.2 HTML语言1.3 网页的形成1.4 常用浏览器1.5 浏览器内核(渲染引擎)1.6 web标准 2 HTML标签2.1 开发工具2.2 HTML语法规则2.3 标签的关系2.4 HTML注释标签2.5 结构标签 3 常用标签3.1 标题标签3.2 段落标签3.3 换行标签3.…...

贝塞尔曲线详细讲解,如何用 Canvas 绘制三阶贝塞尔曲线?
比如我们要画一个这样的曲线,我们该怎么画了 两个点Y轴一样高,起点:(200,100)终点:(300,100)中间的弧度怎么弄了? <canvas id"c1" width"6…...

Ubuntu20.04卸载ros2 foxy版本安装ros1 noetic版本
前言 如果你ubuntu中没有ros,可以试着直接从鱼香ros一键安装包指令处开始。 卸载ros2 sudo apt-get remove ros-*接下来如果你直接使用鱼香ros的一键安装命令,会出错。 设置源 设置源,这里使用的是中科大的。 sudo sh -c . /etc/lsb-r…...
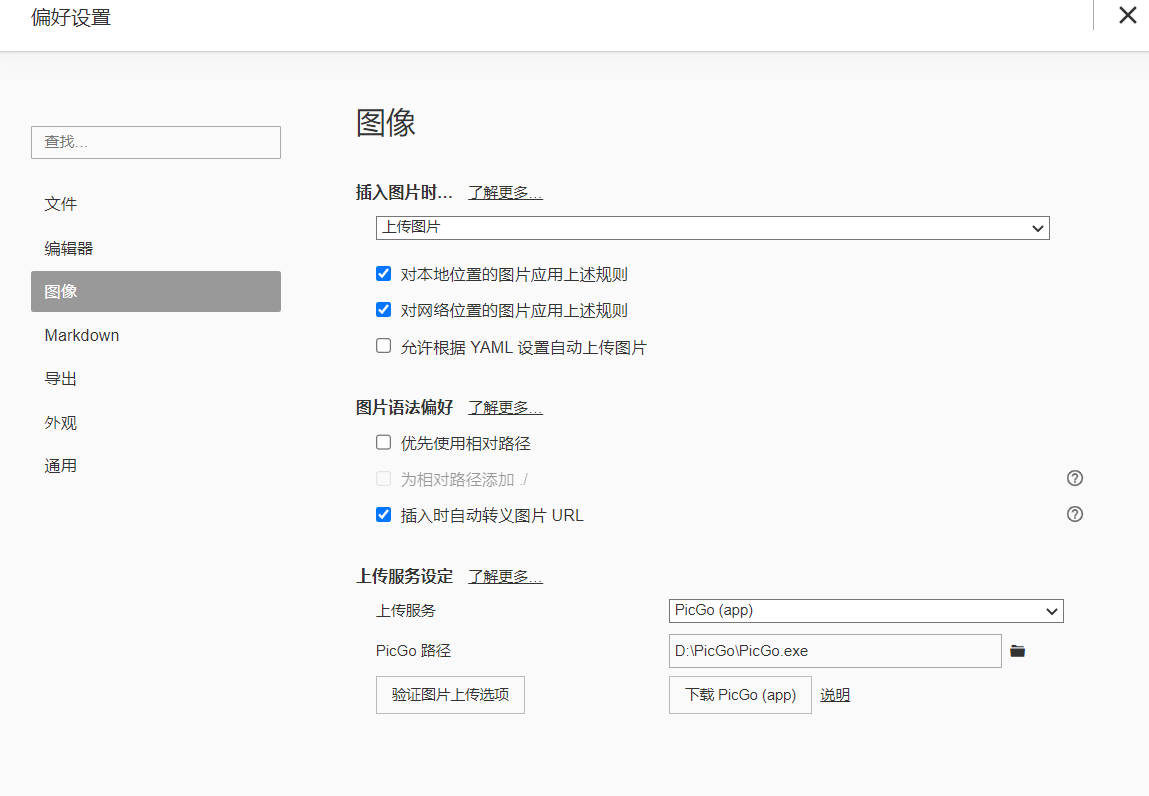
PicGo+Gitee搭建Typora图床
PicGoGitee搭建Typora图床 下载PicGo 下载链接:https://picgo.github.io/PicGo-Doc/zh/guide/#%E4%B8%8B%E8%BD%BD%E5%AE%89%E8%A3%85 配置PicGo 插件安装 在PicGo的【插件设置】中搜索gitee-uploader插件并安装 在【图床设置】下配置Gitee repo:用…...

MySQL 脱敏函数使用详解:保护数据隐私的关键手段
全文目录: 前言前言为什么需要数据脱敏?MySQL 中常用的脱敏方法1. 字符串类型数据的脱敏案例:脱敏姓名案例:脱敏邮箱 2. 数字类型数据的脱敏案例:脱敏手机号案例:脱敏身份证号 3. 自定义脱敏函数自定义姓名…...

nginx之virtual host
vhost 是“virtual host”的缩写,中文译为“虚拟主机”。在Web服务器(如Nginx、Apache等)中,虚拟主机是指在同一台物理服务器上运行多个独立的网站或应用程序的技术。每个虚拟主机都有自己的域名、文档根目录、配置文件等…...

Windows 下纯手工打造 QT 开发环境
用过 QtCreator 和 VS QT 插件,都觉得不是很理想。所以有了这个想法。 手工打造的 QT 的开发环境,是不需要安装上面两个程序的。 1、下载 vcpkg,编译 QT6 下载地址:https://github.com/microsoft/vcpkg.git 进入到 …...

k8s的安装和部署
配置三台主机,分别禁用各个主机上的swap,并配置解析 systemctl mask swap.target swapoff -a vim /etc/fstab配置这三个主机上的主机以及harbor仓库的主机 所有主机设置docker的资源管理模式为system [rootk8s-master ~]# vim /etc/docker/daemon.json…...

第十八篇:一文说清楚ICMP的底层原理
作为程序员或者网络工程师,有时候无法访问对方主机;导致这个现象的有很多原因,那要排查具体的网络原因,可能会用到ping的指令。而ping的底层实现是互联⽹控制报⽂协议(ICMP)。 ICMP 全称是 Internet Contr…...

【优选算法】(第三十二篇)
目录 ⼆进制求和(easy) 题目解析 讲解算法原理 编写代码 字符串相乘(medium) 题目解析 讲解算法原理 编写代码 ⼆进制求和(easy) 题目解析 1.题目链接:. - 力扣(LeetCode&a…...
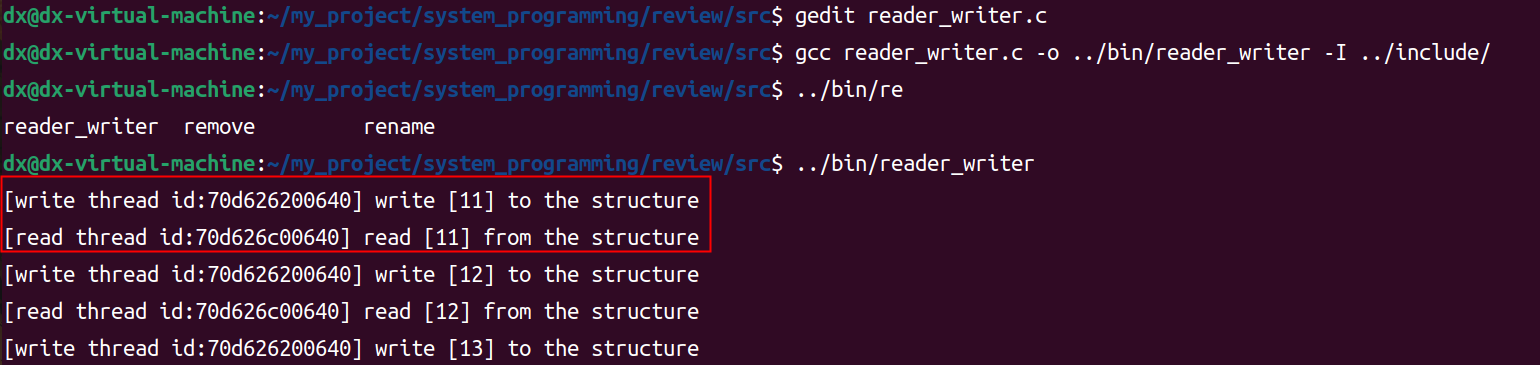
线程(四)线程的同步——条件变量
文章目录 线程线程的同步和互斥线程同步--条件变量什么是线程同步示例--条件变量的使用示例--使用两个线程对同一个文件进行读写示例--一个读者一个写者使用条件变量来实现同步 线程 线程的同步和互斥 线程同步–条件变量 是一个宏观概念,在微观上包含线程的相互…...
(上(这只是简单讲解)))
二维数组的旋转与翻转(C++)(上(这只是简单讲解))
二维数组的旋转与翻转(C) 引言 在计算机科学中,二维数组是一种常见的数据结构,广泛应用于图像处理、数据挖掘、机器学习等多个领域。二维数组的旋转与翻转是处理二维数据时经常需要用到的操作。本文将详细介绍二维数组的旋转与翻…...

Legado-Harmony:免费开源阅读器打造个性化电子书库终极指南
Legado-Harmony:免费开源阅读器打造个性化电子书库终极指南 【免费下载链接】legado-Harmony 开源阅读鸿蒙版仓库 项目地址: https://gitcode.com/gh_mirrors/le/legado-Harmony legado-Harmony是一款专为鸿蒙系统设计的免费开源阅读应用,为用户提…...

为什么92%的戏剧研究生还没用上NotebookLM真正能力?——解锁其多源文本互文性推理的3个密钥
更多请点击: https://intelliparadigm.com 第一章:NotebookLM戏剧研究辅助的范式革命 传统戏剧研究长期依赖人工文本比对、手写批注与线性阅读,面对莎士比亚全集、元杂剧数百种版本、当代实验戏剧脚本等海量非结构化文本,知识提取…...

Fan Control:Windows平台终极风扇控制解决方案
Fan Control:Windows平台终极风扇控制解决方案 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/FanCon…...
M.2 SSD系统迁移实战:从克隆到无缝启动)
【玩转Jetson TX2 NX】(四)M.2 SSD系统迁移实战:从克隆到无缝启动
1. 为什么需要将系统迁移到M.2 SSD? Jetson TX2 NX作为一款嵌入式AI计算设备,默认搭载的eMMC存储空间往往捉襟见肘。我在实际项目中发现,16GB的eMMC在安装完JetPack系统后,剩余空间连一个中等规模的深度学习模型都放不下。更不用…...

嵌入式Linux CPU频率固定:原理、方法与ElfBoard实战
1. 项目概述:为什么需要固定CPU频率?在嵌入式开发领域,尤其是像ElfBoard这样的ARM开发板上进行应用开发或性能调优时,CPU频率的动态调整(DVFS,动态电压频率调整)有时会成为一把双刃剑。对于追求…...

为ClaudeCode配置Taotoken作为稳定可靠的API供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为ClaudeCode配置Taotoken作为稳定可靠的API供应商 Claude Code 是一款广受开发者欢迎的编程助手工具,它依赖于后端的大…...

如何快速构建高质量平行语料库:Lingtrain Aligner智能文本对齐完全指南
如何快速构建高质量平行语料库:Lingtrain Aligner智能文本对齐完全指南 【免费下载链接】lingtrain-aligner Lingtrain Aligner — ML powered library for the accurate texts alignment. 项目地址: https://gitcode.com/gh_mirrors/li/lingtrain-aligner 平…...

网络安全5大高薪赛道,哪条是你的职业快车道?
1. 政企安全:国家队的黄金赛道 政企安全领域就像网络安全行业的"公务员体系",稳定性和薪资待遇都处于行业头部水平。我接触过不少从互联网公司转行做政企安全的工程师,他们普遍反馈"虽然加班也不少,但项目预算充足…...

AI智能体评估框架AgentEval:模块化设计与自动化评测实践
1. 项目概述:AgentEval,一个为AI智能体“打分”的裁判最近在折腾AI智能体(Agent)的开发,从简单的自动化脚本到复杂的多步推理系统,我前前后后也做了不少。但每次做完一个Agent,最头疼的问题就来…...

AI Agent Skill 从入门到精通:定义、结构、调用链路与底层原理
一篇帮你从"知道 Skill 这个词"到"能独立设计生产级 Skill"的系统教学,含 3 个完整实战案例。阅读提示适合谁看:正在做或准备做 AI Agent 开发的工程师,尤其是从传统后端 / 数据仓库转过来的同学看完能做什么:…...