Python3 爬虫 中间人爬虫
中间人(Man-in-the-Middle,MITM)攻击是指攻击者与通信的两端分别创建独立的联系,并交换其所收到的数据,使通信的两端认为其正在通过一个私密的连接与对方直接对话,但事实上整个会话都被攻击者完全控制。在中间人攻击中,攻击者可以拦截通信双方的通话,并插入新的内容或者修改原有内容。
中间人攻击,名字看起来很高级的样子,其实大多数人在小时候都遭受过甚至使用过——上课传纸条。A要把纸条传给B,但是A与B距离太远,于是让C来转交纸条。此时,C作为一个中间人,他有两种攻击方式:仅仅偷偷查看纸条的内容,或者先篡改纸条的内容再传给B。
中间人爬虫就是利用了中间人攻击的原理来实现数据抓取的一种爬虫技术。数据抓包就是中间人爬虫的一个简单应用。所以使用Charles也是一种中间人攻击。
在前面分享中讲到模拟登录的时候,有一种方法是在Chrome的开发者工具中把Cookies复制出来,拿给requests来实现绕过登录。所以肯定有读者会想到,使用Charles也可以获得网站的Cookies,然后复制出来给requests登录。这个想法很好,但问题是,无论Chrome还是Charles都是图形界面的软件,所有操作都需要鼠标来协助完成,把Cookies复制出来这个简单的动作难以实现自动化。这个时候,就需要使用mitmproxy了。
一、mitmproxy的介绍和安装
对编程有了解的读者一定听说过“Linux比Windows好”这种言论,那么Linux哪一点比Windows好呢?Linux好就好在它里面有无数强大的命令行下的软件。这些软件不需要鼠标,也没有图形界面,所有的操作就是输入命令。而命令本质上就是文本。操作文本比操作图形界面容易得多。操作文本可以实现自动化,而操作图形界面却难以实现自动化。
所以,请想一想,有什么办法能自动把Charles里面的Cookies拿给爬虫使用?如何把鼠标指针自动移动到Charles的窗口里?如何自动选中Cookies然后自动复制?如何再把鼠标指针自动移动到另一个终端窗口里面,自动写代码并把Cookies放到Redis中,最后爬虫自动从Redis里面取Cookies,安装到自己身上再去爬网站?
除了最后一步,爬虫从Redis取Cookies很容易以外,其他操作要实现自动化都极其困难。
但是如果有一个命令行下面的抓包工具,所有的操作都是文本型的命令,不需要鼠标,不需要图形界面,它抓到的数据包直接就是文本信息,并且可以无缝传递给其他程序,会怎么样呢?
mitmproxy是一个命令行下的抓包工具,它的作用和Charles差不多,但它可以在终端下工作。使用mitmproxy就可以实现自动化的抓包并从数据包里面得到有用的信息。
请开发者在Linux、Mac OS或者Windows 10自带的Ubuntu Bash下使用mitmproxy,只有这样,才能发挥它的最大能力。
对于Mac OS系统,使用Homebrew安装mitmproxy,命令为:
brew install mitmproxy在Ubuntu中,要安装mitmproxy,首先需要保证系统的Python为Python 3.5或者更高版本,然后执行下面两条命令:
sudo apt-get install python3-dev python3-pip libffi-dev libssl-devsudo pip3 install mitmproxy二、mitmproxy的使用
安装好mitmproxy以后,在终端执行下面的命令,此时会弹出一个窗口,窗口的文字根据系统的不同,可能是英文也可能是中文,大意是询问是否允许Python 3.6接收收入的网络连接,单击“允许”按钮或者“Allow”按钮,如图

接下来会打开一个命令行下的数据监控窗口,如图所示:

mitmproxy的端口为8080端口,在浏览器或者在手机上设置代理,代理IP为计算机IP,端口为8080端口,如图:

设置好代理以后,在手机上打开一个App或者打开一个网页,可以看到mitmproxy上面有数据滚动,如图:

用鼠标在终端窗口上单击其中的任意一个请求,可以显示这个数据包的详情信息,如图:

此时只能访问HTTP网站,要访问HTTPS网站,还需要安装mitmproxy的证书。在手机设置了mitmproxy的代理以后,通过手机浏览器访问http://mitm.it/这个网址,会出现图所示的网页。

根据自己的手机选择对应的图标,就可以弹出安装证书的界面。界面与安装Charles的证书界面基本一样。安装完成证书以后,就可以截获HTTPS的数据包了,如图所示。

到目前为止,mitmproxy就可以像Charles一样使用了。但是既然有了Charles,何必单独介绍一个功能重复的东西呢?那是因为mitmproxy有它擅长的地方,就是可使用Python来定制mitmproxy的行为。
三、使用Python定制mitmproxy
mitmproxy的强大之处在于它还自带一个mitmdump命令。这个命令可以用来运行符合一定规则的Python脚本,并在Python脚本里面直接操作HTTP和HTTPS的请求,以及返回的数据包。
为了自动化地监控网站或者手机发出的请求头部信息和Body信息,并接收网站返回的头部信息和Body信息,就需要掌握如何在Python脚本中获得请求和返回的数据包。
1. 请求数据包
创建一个parse_request.py文件,其文件内容只有两行代码:
def request(flow):print(flow.request.headers)在命令行下执行命令:
mitmdump -s parse_request.py运行命令以后,在手机上打开一个App,可以看到这个App请求的头部信息已经出现在终端窗口中,如图所示。

当然,除了显示头部信息以外,还可以查看请求的Cookies或者Body信息。修改parse_request.py:
def request(flow): req = flow.requestprint(f'当前请求的URL为: {req.url}') print(f'当前的请求方式为: {req.method}') print(f'当前的Cookies为: {req.cookies}') print(f'请求的body为: {req.text}')运行结果如图:

2. 返回数据包
对于网站返回的数据包,可以再实现一个response()函数。创建一个parse_response.py文件,其内容如下:
import jsondef response(flow): resp = flow.responseprint(f'返回的头部为:{resp.headers}') print(f'返回的body为:{json.loads(resp.content)}')如果网站返回的body正好是JSON格式的字符串,那么就可以使用Python的JSON模块来解析。当然,由于这个函数要处理所有的网络返回的数据包,对返回内容不是JSON格式字符串的情况就会报错,如图:

此时,可以在Python脚本里面针对性地处理某个网站返回的数据。这个时候,就把请求和返回内容放在一起,且函数名必须为“response”,代码如下:
def response(flow): req = flow.request response = flow.response if 'kingname.info' in req.url:print('这是kingname的网站,也是我的目标网站')print(f'请求的headers是: {req.headers}')print(f'请求的UA是: {req.headers["User-Agent"]}')print(f'返回的内容是:{response.text}')运行结果如图:

四、mitmdump的使用场景
网站返回的Headers中经常有Cookies,如图:

那是否可以这样写代码:

得到网站返回的Cookies以后就直接塞进Redis里面,这样爬虫就可以直接从Redis里面取已经登录的Cookies了。
这个想法非常好,但是实际做起来会发现,Redis里面始终是空的。这是由于mitmdump的脚本对第三方库的支持有缺陷,很多第三方库都不能运行,甚至Python自带的写文件功能都不能运行。
为了解决这个问题,就需要用到Linux/Mac OS里面非常厉害又很简单的一个工具——管道。这个工具在终端里面就是一根竖线。它可以把左边的内容传递给右边。
mitmdump的脚本使用print()函数把Cookies打印出来,然后通过管道传递给另一个普通的正常的Python脚本。在另一个脚本里面,得到管道传递进来的Cookies,再把它放进Redis里面。
首先是mitmdump的脚本,其代码如下:

代码的运行结果如图:

代码运行以后,会把Cookies放在>>>和<<<中间。
另外创建一个普通的extract.py文件,其内容如下:

如果直接使用Python运行这个代码,会发现它似乎“卡住”了,不会自动结束,也没有任何输出,如图:

如果输入不同的内容,就会发现奥妙所在。当输入普通字符串并按下Enter键的时候,不会有任何内容返回。但是如果按照“>>>内容<<<”的格式输入,就会发现有内容返回出来,如图:

现在需要使用管道把mitmdump运行的脚本和这个Python脚本连接在一起。运行命令:
mitmdump -s parse_one_site.py | python3 extract.py运行命令以后,在手机上访问网站或者刷新App就会看到图所示的输出。

整个窗口看起来简洁了非常多。这个命令会一直运行,之后就不需要关闭它了。只要有包含Cookies的网络请求,并且域名包含“kingname.info”,那么Cookies就会被截获。由于extract.py是一个普通的Python脚本,任何第三方库都可以在上面正常运行,于是就可以使用Redis来存放Cookies了,代码如下:

到目前为止,自动获取Cookies的功能已经实现了。当然不仅仅是Cookies,Headers里面的所有数据、请求发送的Body里面的所有数据都可以使用这种方式截取下来。
假设有这样一个网站,它的每一个请求都带有一个参数:Token。这个Token的有效期为5min,每过5min就会自动更换。如果使用错误的或者过期的Token来请求网站,就会自动跳转到404页面。现在不知道这个Token是怎么生成的,只知道如果使用浏览器访问的话,这个Token就会出现在请求的Headers里面。有了mitmpdump脚本的功能以后,就不需要关心这个Token是怎么生成的了。首先使用Python与Selenium操作浏览器,设置代理,从而使数据经过mitmdump的脚本,然后用PhantomJS访问这个网页,于是mitmdump就可以成功把这个Token给截获下来并放到Redis里面。那么爬虫就可以从Redis里面读取这个Token并直接使用了。
这里给出为PhantomJS设置代理的代码:

这个脚本可以每5min运行一次来刷新Token。
由于Windows自带的CMD是没有管道这种强大的工具的,因此Windows是没有办法直接完成这个流程的。
也许会有读者疑惑,直接使用Python的第三方库Selenium中的接口,就可以从Phantomjs中读取出Headers和Cookies,为什么还要使用mitmproxy呢?
这是因为,mitmproxy在这里做的是代理的角色,网络请求都可以通过它发出去。而Selenium只是一个网页自动化测试工具,它们负责的是不同的事情,只不过在获取计算机网页的请求上面有一小部分功能重叠而已。Selenium也无法获取App和微信小程序的网络请求。
同时,由于mitmproxy是一个代理,HTTP/HTTPS流量数据经过它,就会被截获。那么Phantomjs没有必要和mitmproxy运行在同一个服务器上。只要mitmproxy运行在一个公网服务器即可。Phantomjs可以运行在个人计算机中,并将代理IP设置为公网服务器的IP。如果Phantomjs写代码的操作特别麻烦,直接为浏览器设置代理来实现手工操作网页也可以让mitmproxy实现抓包。
五、总结
抓包是爬虫开发过程中非常有用的一个技巧。使用Charles,可以把爬虫的爬取范围从网页瞬间扩展到手机App和微信小程序。由于微信小程序的反爬虫机制在大多数情况下都非常脆弱,所以如果目标网站有微信小程序,那么可以大大简化爬虫的开发难度。
当然,网站有可能会对接口的数据进行加密,App得到密文以后,使用内置的算法进行解密。对于这种情况,单纯使用抓包就没有办法处理了,就需要使用下一章所要讲到的技术来解决。
使用mitmproxy可以实现爬虫的全自动化操作。对于拥有复杂参数的网站,使用这种先抓包再提交的方式可以在一定程度上绕过网站的反爬虫机制,从而实现数据抓取。
--------------------------------------
没有自由的秩序和没有秩序的自由,同样具有破坏性。
相关文章:
Python3 爬虫 中间人爬虫
中间人(Man-in-the-Middle,MITM)攻击是指攻击者与通信的两端分别创建独立的联系,并交换其所收到的数据,使通信的两端认为其正在通过一个私密的连接与对方直接对话,但事实上整个会话都被攻击者完全控制。在中…...

Leetcode 50. Pow ( x , n ) 快速幂、取模 C++实现
问题:Leetcode 50. Pow ( x , n ) 实现 pow(x, n) ,即计算 x 的整数 n 次幂函数。 算法: 具体实现流程如下: 代码: class Solution { public:double myPow(double x, int N) {double ans 1;long long n N;if (n <…...

Java SE vs Java EE 与 JVM vs JDK vs JRE
Java SE(Java Platform,Standard Edition): Java 平台标准版,Java 编程语言的基础,它包含了支持 Java 应用程序开发和运行的核心类库以及虚拟机等核心组件。Java SE 可以用于构建桌面应用程序或简单的服务器应用程序。…...

Linux YUM设置仓库优先级
1.安装yum-plugin-priorities优先级插件 yum install yum-plugin-priorities -y 2.设置仓库优先级 vim /etc/yum.repos.d/local.repo [local] namecentos7.5 baseurlfile:///mnt enable1 gpgcheck0 priority1 注释: priority1 #数字越小代表优先级越高ÿ…...

做一个不断更新的链接库
做一个不断更新的链接库 anaconda anaconda官方镜像源 anaconda清华镜像源 社区 CSDN CSDN-华为开发者空间 python开发库 股票爬虫 - akshare...

Ping32企业加密软件:保护数据安全
在数字化时代,数据安全已成为每个企业不可忽视的重要课题。无论是客户信息、财务报表,还是商业机密,数据的安全性直接关系到企业的声誉与运营。为了应对不断变化的安全威胁,选择一款可靠的企业加密软件尤为重要。在这里࿰…...

【Java】异常的处理-方式【主线学习笔记】
文章目录 前言1、处理概述2、Java异常处理机制(方式)方式一(抓抛模型):try-catch-finally方式二:throws 异常类型总结 前言 Java是一门功能强大且广泛应用的编程语言,具有跨平台性和高效的执行…...

React modal暴露ref简洁使用
父组件使用 import { useRef } from react import { FormModal } from ./modalconst IndexRoute () > {const formRef useRef<any>()const openModal (row?: any) > {const params {title: row?.id ? 【${row.name}】编辑 : 创建,isView: false,row,api: r…...

小米路由器ax1500+DDNS+公网IP+花生壳实现远程访问
有远程办公的需求,以及一些其他东西。 为什么写? ax1500路由器好像没搜到相关信息。以及其中有一点坑。 前置 公网ip Xiaomi路由器 AX1500 MiWiFi 稳定版 1.0.54 实现流程 花生壳申请壳域名https://console.hsk.oray.com/ 这里需要为域名实名认证 …...

毕设分享 大数据用户画像分析系统(源码分享)
文章目录 0 前言2 用户画像分析概述2.1 用户画像构建的相关技术2.2 标签体系2.3 标签优先级 3 实站 - 百货商场用户画像描述与价值分析3.1 数据格式3.2 数据预处理3.3 会员年龄构成3.4 订单占比 消费画像3.5 季度偏好画像3.6 会员用户画像与特征3.6.1 构建会员用户业务特征标签…...

使用 Redis 实现分布式锁:原理、实现与优化
在分布式系统中,分布式锁是确保多个进程或线程在同一时间内对共享资源进行互斥访问的重要机制。Redis 作为一个高性能的内存数据库,提供了多种实现分布式锁的方式。本文将详细介绍如何使用 Redis 实现分布式锁,包括基本原理、实现方法、示例代…...

Android常用C++特性之std::make_pair
声明:本文内容生成自ChatGPT,目的是为方便大家了解学习作为引用到作者的其他文章中。 std::make_pair 是 C 标准库中的一个函数模板,用于创建一个 std::pair 对象。std::pair 是一种可以存储两个不同类型值的简单数据结构,类似于二…...

Kafka-参数详解
一、上下文 从《Kafka-初识》中可以看到运行kafka-console-producer和 kafka-console-consumer来生产和消费数据时会打印很多参数,这些参数给我们应对多种场景提供了遍历,除了producer和consumer的提供了参数外,Kafka服务器集群中的broker也…...

Docker Overlay2 空间优化
目录 分析优化数据路径规划日志大小限制overlay2 大小限制清理冗余数据 总结 分析 overlay2 目录占用磁盘空间较大的原因通常与 Docker 容器和镜像的存储机制以及它们的长期累积相关,其实我之前在 Docker 原理那里已经提到过了。 通常时以下几种原因导致ÿ…...

第 3 章:使用 Vue 脚手架
1. 初始化脚手架 1.1 说明 Vue 脚手架是 Vue 官方提供的标准化开发工具(开发平台)。最新的版本是 5.x。文档: https://cli.vuejs.org/zh/ 1.2 具体步骤 第一步(仅第一次执行):全局安装vue/cli。 npm install -g vu…...

Spring 循环依赖详解:问题分析与三级缓存解决方案
在Spring框架中,循环依赖(Circular Dependency)是指多个Bean相互依赖,形成一个循环引用。例如,Bean A依赖于Bean B,而Bean B又依赖于Bean A。这种情况在Bean创建时可能导致Spring容器无法正常完成初始化&am…...

爬虫prc技术----小红书爬取解决xs
知识星球:知识星球 | 深度连接铁杆粉丝,运营高品质社群,知识变现的工具知识星球是创作者连接铁杆粉丝,实现知识变现的工具。任何从事创作或艺术的人,例如艺术家、工匠、教师、学术研究、科普等,只要能获得一…...

uni-app之旅-day06-加入购物车
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言8.0 创建 cart 分支8.1 配置 vuex8.2 创建购物车的 store 模块8.3 在商品详情页中使用 Store 中的数据8.4 实现加入购物车的功能8.5 动态统计购物车中商品的总数…...

【Kubernetes】常见面试题汇总(五十六)
目录 123. pod 创建失败? 124. kube-flannel-ds-amd64-ndsf7 插件 pod 的 status 为 Init:0/1 ? 特别说明: 题目 1-68 属于【Kubernetes】的常规概念题,即 “ 汇总(一)~(二十二&#x…...
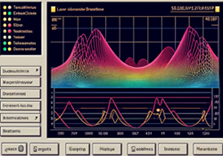
LabVIEW激光诱导击穿光谱识别与分析系统
LabVIEW激光诱导击穿光谱(LIBS)分析系统利用高能量脉冲激光产生高温等离子体,通过分析等离子体发出的光谱来定性分析样品中的元素种类。该系统的开发集成了软件与硬件的设计,实现了自动识别和定性分析功能,适用于环境监…...

别再死记硬背了!用USB的NRZI编码和Bit-Stuffing,搞懂自同步通信的底层逻辑
从NRZI编码到自同步通信:USB协议中的时钟同步艺术 当你在调试USB设备时突然发现数据包丢失,或是试图理解为什么USB仅用两根数据线就能实现高速通信,背后的秘密就藏在NRZI编码和位填充(Bit-Stuffing)这两个看似简单的技…...

告别环境配置烦恼:Windows 10/11下RT-Thread Studio 2.2.7保姆级安装与首次运行指南
告别环境配置烦恼:Windows 10/11下RT-Thread Studio 2.2.7保姆级安装与首次运行指南 对于刚接触嵌入式开发的初学者来说,环境配置往往是第一个"拦路虎"。本文将手把手带你完成RT-Thread Studio在Windows系统下的完整安装流程,避开常…...

深耕财税赋能+精准GEO推广 好账本兰宝玺双线发力助企破局
在数字经济飞速发展的当下,财税服务的专业性与营销推广的精准度,成为中小微企业稳健成长的两大核心支撑。深耕苏州、昆山财税领域八年的98后实干者兰宝玺,依托好账本财税平台的坚实后盾,不仅以精细化财税服务为创业者保驾护航&…...

避坑指南:在Simplicity Studio 5中为BLE工程添加串口控制与软定时器时,我踩过的那些雷
Simplicity Studio 5 BLE开发实战:串口控制与软定时器的七个关键陷阱与解决方案 当你在Simplicity Studio 5中完成基础BLE工程搭建后,真正挑战才刚刚开始。我曾在一个智能照明项目中,需要同时处理BLE连接、串口指令控制和LED定时闪烁功能&…...

CANoe离线回放保姆级教程:手把手教你用BLF/ASC日志复现CAN总线问题
CANoe离线回放实战指南:从日志解析到问题定位的全流程精解 当CAN总线上的"幽灵问题"反复出现却又难以在实验室复现时,那种挫败感每个汽车电子工程师都深有体会。上周深夜,我正面对一个诡异的CAN信号跳变问题——产线报告车辆偶尔出…...

别再复制粘贴了!保姆级教程:在CentOS 7上用三台虚拟机搞定Hadoop 3.1.3完全分布式集群
从零构建Hadoop 3.1.3完全分布式集群:原理剖析与避坑实战 当你在搜索引擎里输入"Hadoop完全分布式安装"时,是否曾被各种教程中机械复制的命令列表搞得一头雾水?作为曾经同样困惑的实践者,我深刻理解新手面对那些看似简单…...

国产高性能MCU如何破局?拆解先楫半导体RISC-V芯片的落地逻辑
1. 从展会到产线:拆解先楫半导体高性能MCU的落地逻辑前几天在深圳的Elexcon电子展上逛了一圈,最大的感触是,国产芯片的“高性能”这三个字,终于不再是PPT上的口号,而是能实实在在摸到、测到、甚至直接拿来设计产品的硬…...

新消费品牌的详情页,不该是产品说明书
很多企业做电商页面时,会把重点放在“展示产品”上。图片要好看,卖点要完整,参数要齐全,详情页要显得丰富,品牌故事要讲出来,工艺优势要摆出来,证书、原料、产地、功能、包装、规格、适用人群&a…...

座机号码认证支持哪些机型?固话企业认证覆盖华为/小米/OPPO/vivo等手机
很多做业务的朋友都有这种体会:好不容易联系到一个精准意向客户,电话拨过去,还没等开口,对方直接挂断。更有甚者,手机屏幕上赫然跳出“疑似推销”四个大字。现在的职场沟通,信任成本高得离谱。如果你还指望…...

LabVIEW图形化编程实战:从数据流原理到高效测控系统开发
1. 项目概述与核心价值今天咱们来聊聊LabVIEW这门工具。很多刚接触自动测试、数据采集或者仪器控制的朋友,可能都听说过它的大名,但上手时总觉得它和传统的文本编程语言(比如C、Python)不太一样,有点无从下手。我最早接…...