大数据处理从零开始————9.MapReduce编程实践之信息过滤之学生成绩统计demo
1.项目目标
1.1 需求概述
现在我们要统计某学校学生的成绩信息,筛选出成绩在60分及以上的学生。
1.2 业务分析
如果我们想实现该需求,可以通过编写一个MapReduce程序,来处理包含学生信息的文本文件,每行包含【学生的姓名,科目,分数】,以逗号分隔,要求如下:
分别编写一个Student类和一个Mapper类;
Student 类包含以下字段:姓名(String)、科目(String)、分数(int);
需要自定义 Student 对象的序列化和反序列化方法,以便Hadoop能够正确处理它;
Mapper类将输入文本数据解析为 Student 对象,并且只输出成绩大于60分的学生;
以固定字符串"学生信息"为Key,Student对象为Value,作为该Mapper的输出。
2. 新建项目
如果没有进行配置项目,则需要先进行配置,可以参考下文的前半部分:
大数据处理从零开始————8.基于Java构建WordCount项目-CSDN博客
如果配置好就可以直接进行下一步。新建项目后,确定好项目的名称,组ID,工作ID的信息。
打开pom.xml文件,添加项目配置,添加如下配置。
<dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.13.2</version><!--<scope>test</scope>--></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.3.3</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.3.3</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>3.3.3</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.11</version></dependency></dependencies>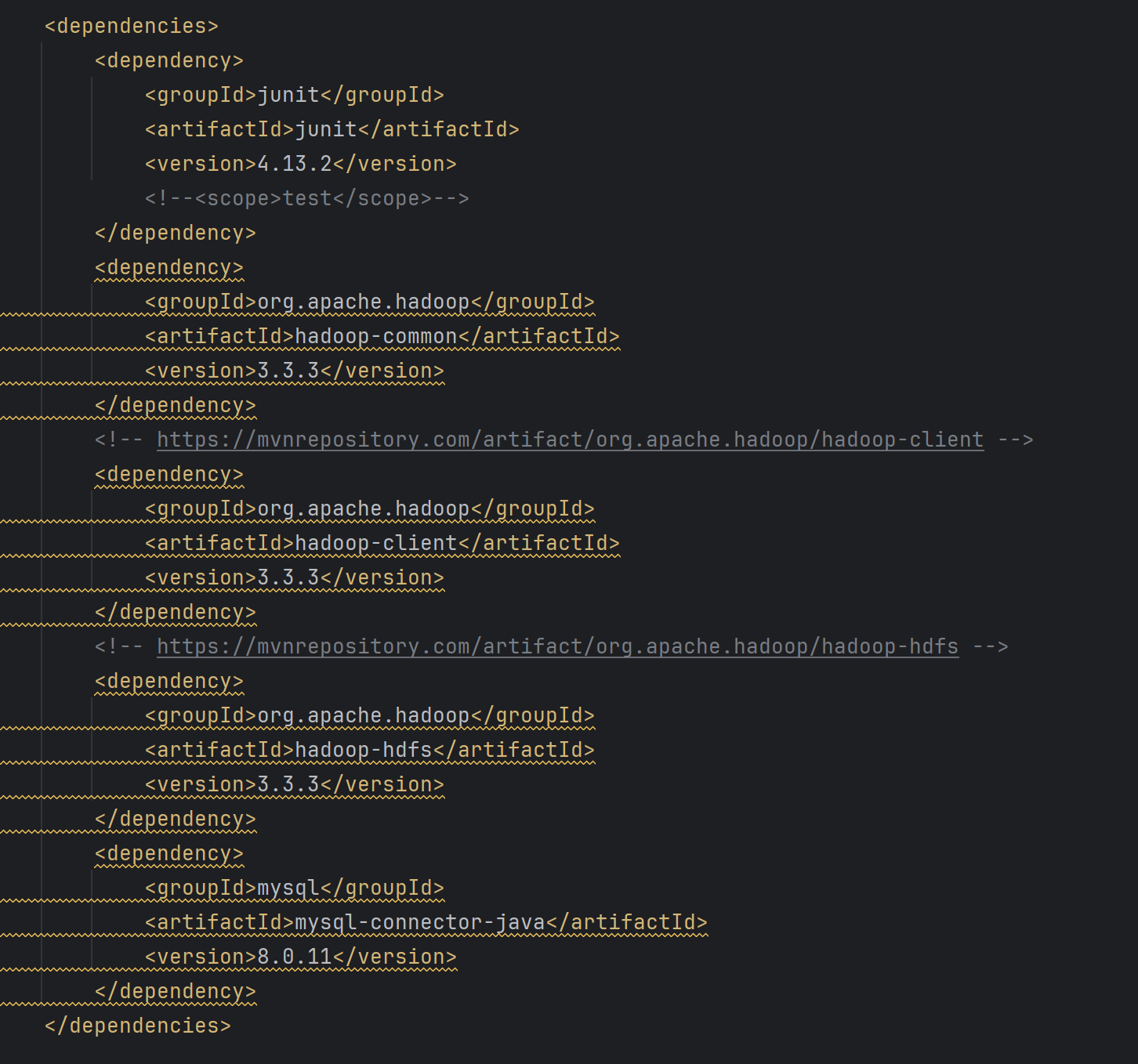
如果pom.xml全部标红可以看上一节解决方法,完全相同。
3.完善项目代码
3.1 创建Student类
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;public class Student implements Writable {private String name;private String subject;private int score;public Student() {}public Student(String name, String subject, int score) {this.name = name;this.subject = subject;this.score = score;}public void write(DataOutput out) throws IOException {out.writeUTF(name);out.writeUTF(subject);out.writeInt(score);}public void readFields(DataInput in) throws IOException {name = in.readUTF();subject = in.readUTF();score = in.readInt();}public String getName() {return name;}public void setName(String name) {this.name = name;}public String getSubject() {return subject;}public void setSubject(String subject) {this.subject = subject;}public int getScore() {return score;}public void setScore(int score) {this.score = score;}@Overridepublic String toString() {return "姓名:" + name + ", 科目:" + subject + ", 分数:" + score;}
}在这里可能由很多人不明白,我们来解释一下这段代码的关键点:
首先它实现了Writable接口,Writable接口主要实现了序列化和反序列化。Writable接口定义了两个方法。1. void write(DataOutput out):主要用于将对象的字段写入数据输入流DataOutput中;在实现此方法时,需要按照某种顺序依次写入对象的所有属性,确保与readFields方法对应。2.void readfields(DataInput in):该方法用于从数据输入流 DataInput 中读取对象的字段;按照与 write 方法相同的顺序读取,确保数据能正确映射回对象的属性。
其次重写了toString方法。

3.2 实现Mapper类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;public class StudentMapper extends Mapper<LongWritable, Text, Text, Student> {private static final Text outputKey = new Text("学生信息");@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {// 解析每行文本String line = value.toString();String[] fields = line.split(",");// 创建Student对象if (fields.length == 3) {String name = fields[0].trim();String subject = fields[1].trim();int score = Integer.parseInt(fields[2].trim());// 只输出成绩大于60分的学生if (score > 60) {Student student = new Student(name, subject, score);context.write(outputKey, student);}}}
}首先通过泛型确保了输入形式是key——value的形式。
然后创建了一个名为 outputKey 的常量,它代表输出的键,值为 "学生信息"。这个常量在整个类中是共享的,避免了在每次调用 map 方法时重复创建。
接着实现了map方法,在map方法中先将输入值逐行改成字符串数组形式;然后检查字段数组是否为三,确保数组行格式正确,接着分别提取姓名、科目和分数,并进行适当的修剪以去除多余的空格,进一步使用 Integer.parseInt() 方法将分数字符串转换为整数;最后输出大于60分的人。

3.3 构建驱动器StudentDriver类
在构建完map类后,程序并不能直接运行,因此我们还要构建一个Driver类来驱动程序。Driver类是一个 Hadoop MapReduce 程序的驱动程序,负责设置作业的配置并启动 MapReduce 任务。
import org.apache.hadoop.conf.Configuration; // 导入 Hadoop 配置类
import org.apache.hadoop.fs.Path; // 导入路径类,用于文件路径处理
import org.apache.hadoop.io.Text; // 导入 Text 类,表示字符串形式的键
import org.apache.hadoop.mapreduce.Job; // 导入 Job 类,用于定义一个 MapReduce 作业
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; // 导入输入格式类
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; // 导入输出格式类 public class StudentDriver { public static void main(String[] args) throws Exception { // 检查命令行参数数量,要求输入两个参数 if (args.length != 2) { System.err.println("Usage: StudentDriver <input path> <output path>"); System.exit(-1); // 如果参数数量不对,打印用法并退出 } // 创建 Hadoop 配置对象 Configuration conf = new Configuration(); // 创建一个新的 Job 实例,作业名称为 "Student Info Filter" Job job = Job.getInstance(conf, "Student Info Filter"); // 设置程序的 Jar 文件位置 job.setJarByClass(StudentDriver.class); // 设置使用的 Mapper 类 job.setMapperClass(StudentMapper.class); // 设置 Mapper 的输出键值类型 job.setMapOutputKeyClass(Text.class); // 输出键的类型为 Text job.setMapOutputValueClass(Student.class); // 输出值的类型为 Student(自定义类型) // 设置最终输出的键值类型 job.setOutputKeyClass(Text.class); // 输出键的类型为 Text job.setOutputValueClass(Student.class); // 输出值的类型为 Student // 设置输入和输出路径 FileInputFormat.addInputPath(job, new Path(args[0])); // 设置输入路径 FileOutputFormat.setOutputPath(job, new Path(args[1])); // 设置输出路径 // 提交作业,并根据完成情况退出 System.exit(job.waitForCompletion(true) ? 0 : 1); }
}详细解释看代码注释。

4.运行程序
首先给程序打包。

然后给程序重命名。

接着上传到hadoop中。

启动hadoop,并将程序上传到hadoop中。
./myhadoop.sh start 启动hadoop
cd /user/local/data #转到文件夹下
ll #查看是否上传成功
vim student #创立测试文件
hdfs dfs -put student /cs #将student上传到/cs中注意:我这里有cs,如果没有的话,应该先用下面命令创建/cs
hdfs dfs mkdir /cs #在hadoop下创建一个cs文件。

运行jar包:hadoop jar map.jar com.jyd.StudentDriver /cs /ssoutput

查看结果: hdfs dfs -cat /ssoutput/part-r-00000

相关文章:
大数据处理从零开始————9.MapReduce编程实践之信息过滤之学生成绩统计demo
1.项目目标 1.1 需求概述 现在我们要统计某学校学生的成绩信息,筛选出成绩在60分及以上的学生。 1.2 业务分析 如果我们想实现该需求,可以通过编写一个MapReduce程序,来处理包含学生信息的文本文件,每行包含【学生的姓名&#x…...

自动化测试 | 窗口截图
driver.get_screenshot_as_file 是 Selenium WebDriver 的一个方法,它允许你将当前浏览器窗口(或标签页)的截图保存为文件。这个方法对于自动化测试中的截图验证非常有用,因为它可以帮助你捕获测试执行过程中的页面状态。 以下是…...

初中数学网上考试系统的设计与实现(论文+源码)_kaic
初中数学网上考试系统的设计与实现 学生: 指导教师: 摘 要:科技在人类的历史长流中愈洗愈精,不仅包括人们日常的生活起居,甚至还包括了考试的变化。之前的考试需要大量的时间和精力,组织者还需要挑选并考查…...

关系运算(3)
关系代数 昨天讲完附加关系代数运算,今天讲扩展关系代数运算。 扩展代数运算 正如其名,这种运算定义了前面基本和附加都没有的运算。 去重运算 可以将关系R中跟查询条件相关但是形成了重复的元组去除,只保留查询结果(简洁&…...

tp6的系统是如何上架的
TP6(ThinkPHP6)的系统上架过程,通常指的是将基于ThinkPHP6框架开发的应用程序部署到生产环境,并使其可以通过互联网访问。以下是一个大致的上架流程,包括准备工作、部署步骤以及后续维护等方面: 一、准备工…...

Vue:开发小技巧
目录 1. Table表格偏移 1. Table表格偏移 通过设置自小的宽度进行控制 :min-width <el-table-column label"操作" align"center" class-name"small-padding fixed-width" fixed"right" min-width"150px"><templa…...

力扣之1369.获取最近第二次的活动
题目: sql建表语句 Create table If Not Exists UserActivity (username varchar(30), activity varchar(30), startDate date, endDate date); Truncate table UserActivity; insert into UserActivity (username, activity, startDate, endDate) values (Alic…...

Python 和 Jupyter Kernel 版本不一致
使用jupyter notebook时明明已经安装了包,但是导入时提示: ModuleNotFoundError: No module named ptitprince 1、检查安装环境 !pip show ptitprince Name: ptitprince Version: 0.2.7 Summary: A Python implementation of Rainclouds, originally…...
Android常用布局
目录 布局文件中常见的属性 1. 基本布局属性 1)android:layout_width 2)android:layout_height 3)android:layout_margin 4)android:padding 2. 线性布局 (LinearLayout) 属性 1)android:orientation 2)and…...

初级网络工程师之从入门到入狱(五)
本文是我在学习过程中记录学习的点点滴滴,目的是为了学完之后巩固一下顺便也和大家分享一下,日后忘记了也可以方便快速的复习。 网络工程师从入门到入狱 前言一、链路聚合1.1、手动进行链路聚合1.1.1、 拓扑图:1.1.2、 LSW11.1.3、 LSW2 1.2、…...

JavaScript轮播图实现
这个代码创建了一个简单的轮播图,可以通过点击左右箭头或自动播放来切换图片。 <!DOCTYPE html> <html><head><meta charset"utf-8" /><title>js轮播图练习</title><style>.box {width: 60vw;height: 500px;m…...

【LLM开源项目】LLMs-开发框架-Langchain-Tutorials-Basics-v2.0
【1】使用LCEL构建简单的LLM应用程序(Build a Simple LLM Application with LCEL) https://python.langchain.com/docs/tutorials/llm_chain/ 如何使用LangChain构建简单的LLM应用程序。功能:将把文本从英语翻译成另一种语言。 实现:LLM调用加上一些提…...

Python 爬取天气预报并进行可视化分析
今天,我们就来学习如何使用 Python 爬取天气预报数据,并用数据可视化的方式将未来几天的天气信息一目了然地展示出来。 在本文中,我们将分三步完成这一任务: 使用 Python 爬取天气数据数据解析与处理用可视化展示天气趋势 让我…...

最左侧冗余覆盖子串
题目描述 给定两个字符串 s1 和 s2 和正整数 k,其中 s1 长度为 n1,s2 长度为 n2。 在 s2 中选一个子串,若满足下面条件,则称 s2 以长度 k 冗余覆盖 s1 该子串长度为 n1 k 该子串中包含 s1 中全部字母 该子串每个字母出现次数…...

性能测试-JMeter(2)
JMeter JMeter断言响应断言JSON断言断言持续时间 JMeter关联正则表达式提取器正则表达式正则表达式提取器 XPath提取器JSON提取器 JMeter属性JMeter录制脚本 JMeter断言 断言:让程序自动判断预期结果和实际结果是否一致 提示: -Jmeter在请求的返回层面有…...
芯课堂 | Synwit_UI_Creator(μgui)平台之图像处理篇
今天小编给大家介绍的是UI_Creator(μgui)平台下关于图像处理的选项。 UI_Creator(μgui)平台图片类控件有图像控件和分级图像控件,均包含以下选项: 1、消除水波纹: 由于16位真彩色(…...

QT C++ 软键盘/悬浮键盘/触摸屏键盘的制作
目录 1、前言 2、界面设计 3、英文、数字的输入 4、符号的输入 5、中文的输入 6、中文拼音库的选择 7、其他 8、结语 1、前言 使用QT C在带显示器的Linux系统 开发板上(树莓派等)编写操作UI界面时,很多时候都需要一个软键盘来输入文字…...

element-ui点击文字查看图片预览功能
今天做一个点击文字查看图片的功能,大体页面长这样子,点击查看显示对应的图片 引入el-image-viewer,点击的文字时候设置图片预览组件显示并传入图片的地址 关键代码 <el-link v-if"scope.row.fileList.length > 0" type&…...

SpringBoot集成Redis使用Cache缓存
使用SpringBoot集成Redis使用Cache缓存只要配置相应的配置类,然后使用Cache注解就能实现 RedisConfig配置 新建RedisConfig配置类 package com.bdqn.redis.config;import com.fasterxml.jackson.annotation.JsonAutoDetect; import com.fasterxml.jackson.annota…...

【瑞萨RA8D1 CPK开发板】lcd显示
1.8寸lcd使用gpio模拟spi驱动 由于板子引出的接口限制,故使用gpio模拟spi驱动中景园的1.8寸lcd 1.77寸液晶屏 1.8寸TFT LCD SPI TFT彩屏st7735驱动128x160高清屏-淘宝网 (taobao.com) 使用RASC 的gpio配置 根据厂家提供的驱动文件移植 #define LCD_SCLK_Clr() g…...

基于瑞萨RX63N与摇杆的模拟信号采集与上位机控制实践
1. 项目概述与核心思路最近在整理手头的开发板,翻出了这块瑞萨的Sakura板(RX63N),想着不能让它吃灰,得做点有意思的东西。手头正好有个摇杆模块,灵机一动,不如用它来做个模拟输入控制视频播放的…...

帆软FineReport 10升级实战:从路径映射到安全配置的完整指南
1. 从FineReport 9到10的升级背景与准备工作 最近接手了一个企业级报表系统的升级项目,需要将现有的FineReport 9环境迁移到最新的10版本。在实际操作过程中发现,这不仅仅是简单的版本替换,而是涉及到路径映射、参数调整、安全配置等多个关键…...

Python随机密码生成器实战
求赞 求关注 当然写的不怎么好,因为我才刚初一,更新速度也慢。 如果想下载这里有链接 https://download.csdn.net/download/mc54321/91240180 正文开始 在编写这个程序我们需要导入random模块。 import random random 模块是 Python 标准库中的一个…...

如何一键自动化部署Office:LKY Office Tools完整配置指南
如何一键自动化部署Office:LKY Office Tools完整配置指南 【免费下载链接】LKY_OfficeTools 一键自动化 下载、安装、激活 Office 的利器。 项目地址: https://gitcode.com/GitHub_Trending/lk/LKY_OfficeTools 在Windows系统中安装Microsoft Office一直是个…...

训练和微调
训练和微调微调本质上就是在调整(更新)模型的参数。当我们说“调整参数”时,指的是调整神经网络内部数以亿计的权重(Weights)和偏置(Biases)。全量微调(Full Fine-Tuning)…...

如何快速部署AI视觉瞄准系统:3个版本满足不同需求的终极指南
如何快速部署AI视觉瞄准系统:3个版本满足不同需求的终极指南 【免费下载链接】AI-Aimbot Worlds Best AI Aimbot - CS2, Valorant, Fortnite, APEX, every game 项目地址: https://gitcode.com/gh_mirrors/ai/AI-Aimbot 欢迎来到AI视觉瞄准系统的完整实战教程…...

终极游戏加速指南:如何使用OpenSpeedy免费提升游戏体验
终极游戏加速指南:如何使用OpenSpeedy免费提升游戏体验 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 你是否厌倦了游戏中漫长的等待时间?是否想在单…...

智绘低空新图景:黎阳之光以数智技术赋能低空经济高质量发展
在长三角一体化战略纵深推进、新质生产力加速培育的时代浪潮中,低空经济正成为驱动区域经济转型升级的重要引擎。华东师范大学大虹桥低空经济研究院的成立,为行业搭建起“理论实践技术人才”的全链条创新平台;而北京黎阳之光科技有限公司&…...
)
2026年唯一通过广电AIGC内容安全认证的3款视频生成工具(附检测报告编号+审核链路图解)
更多请点击: https://kaifayun.com 第一章:2026年AI视频生成工具排行榜 2026年,AI视频生成技术已迈入“语义帧精控”与“跨模态时序对齐”新阶段。主流工具普遍支持 毫秒级动作锚点标注、 物理引擎协同渲染及 多镜头逻辑自动剪辑,…...

std::accumulate算法深度解析:从求和到通用折叠,解锁STL隐藏的瑞士军刀
1. 重新认识std::accumulate:不只是求和工具 第一次接触std::accumulate时,大多数人都是从求和开始的。确实,这个算法默认行为就是对范围内的元素进行累加。但如果你只把它当作一个高级计算器,那就太小看这个STL中的"瑞士军刀…...