Python 自动化指南(繁琐工作自动化)第二版:三、函数
原文:https://automatetheboringstuff.com/2e/chapter3/

您已经熟悉了前几章中的print()、input()和len()函数。Python 提供了几个这样的内置函数,但是您也可以编写自己的函数。函数就像一个程序中的一个小程序。
为了更好地理解函数是如何工作的,让我们创建一个函数。将该程序输入文件编辑器,并保存为helloFunc.py :
def hello(): # ➊print('Howdy!') # ➋print('Howdy!!!')print('Hello there.')hello() # ➌hello()hello()
您可以在autbor.com/hellofunc查看该程序的执行情况。第一行是一个def语句 ➊,它定义了一个名为hello()的函数。跟在def语句 ➋ 后面的代码是函数体。这段代码在函数被调用时执行,而不是在函数第一次被定义时执行。*
函数 ➌ 后面的hello()行是函数调用。在代码中,函数调用就是函数名后跟括号,括号之间可能有一些参数。当程序执行到这些调用时,它将跳转到函数的第一行,并开始执行那里的代码。当它到达函数的末尾时,执行返回到调用该函数的行,并像以前一样继续遍历代码。
由于这个程序调用了hello()三次,所以hello()函数中的代码执行了三次。当您运行该程序时,输出如下所示:
Howdy!
Howdy!!!
Hello there.
Howdy!
Howdy!!!
Hello there.
Howdy!
Howdy!!!
Hello there.
函数的一个主要目的是对多次执行的代码进行分组。如果没有定义函数,您每次都必须复制并粘贴这些代码,程序看起来会像这样:
print('Howdy!')
print('Howdy!!!')
print('Hello there.')
print('Howdy!')
print('Howdy!!!')
print('Hello there.')
print('Howdy!')
print('Howdy!!!')
print('Hello there.')
一般来说,您总是希望避免重复代码,因为如果您决定更新代码——例如,如果您发现了一个需要修复的 BUG 您将不得不记住在您复制代码的任何地方更改代码。
随着你获得更多的编程经验,你会经常发现自己删除重复代码,这意味着去掉重复的或复制粘贴的代码。重复数据删除使您的程序更短、更易读、更易于更新。
带参数的def语句
当您调用print()或len()函数时,您通过在括号之间键入值来传递它们,称为参数。您也可以定义自己的接受参数的函数。将此示例输入文件编辑器,并保存为helloFunc2.py :
def hello(name): # ➊print('Hello, ' + name) # ➋hello('Alice') # ➌hello('Bob')
当您运行该程序时,输出如下所示:
Hello, Alice
Hello, Bob
您可以在autbor.com/hellofunc2查看该程序的执行情况。本程序中hello()函数的定义有一个参数叫做name➊。参数是包含参数的变量。当用参数调用函数时,参数存储在形参中。第一次调用hello()函数时,它被传递给参数'Alice'➌。程序执行进入函数,参数name自动设置为'Alice',这是由print()语句 ➋ 打印出来的。
关于参数需要特别注意的一点是,当函数返回时,存储在参数中的值会被遗忘。例如,如果你在前面的程序中在hello('Bob')后面添加了print(name),程序会给你一个NameError,因为没有名为name的变量。这个变量在函数调用hello('Bob')返回后被销毁,所以print(name)会引用一个不存在的name变量。
这类似于当程序终止时程序的变量被遗忘。在本章后面,当我讨论什么是函数的局部作用域时,我会更多地讨论为什么会发生这种情况。
定义、调用、传递、实参、形参
术语定义、调用、传递、实参、形参可能会混淆。让我们看一个代码示例来回顾这些术语:
def sayHello(name): # ➊print('Hello, ' + name)sayHello('Al') # ➋
定义函数就是创建函数,就像赋值语句创建变量一样。def语句定义了sayHello()函数 ➊。sayHello('Al')行 ➋ 调用现在创建的函数,将执行发送到函数代码的顶部。这个函数调用也被称为将字符串值'Al'传递给函数。在函数调用中传递给函数的值是实参。参数'Al'被分配给一个名为name的局部变量。被赋予实参的变量是形参。
很容易混淆这些术语,但保持它们的一致性将确保你准确地知道本章文本的意思。
返回值和返回语句
当您调用len()函数并给它传递一个参数,比如'Hello'时,函数调用会计算出整数值5,这是您传递给它的字符串的长度。一般来说,函数调用求值的值被称为函数的返回值。
当使用def语句创建函数时,可以用return语句指定返回值应该是什么。一份return语句由以下内容组成:
return关键字- 函数应该返回的值或表达式
当一个表达式与一个return语句一起使用时,返回值就是这个表达式计算的值。例如,下面的程序定义了一个函数,该函数根据作为参数传递的数字返回不同的字符串。将此代码输入文件编辑器并保存为magic8Ball.py :
import random # ➊def getAnswer(answerNumber): # ➋if answerNumber == 1: # ➌return 'It is certain'elif answerNumber == 2:return 'It is decidedly so'elif answerNumber == 3:return 'Yes'elif answerNumber == 4:return 'Reply hazy try again'elif answerNumber == 5:return 'Ask again later'elif answerNumber == 6:return 'Concentrate and ask again'elif answerNumber == 7:return 'My reply is no'elif answerNumber == 8:return 'Outlook not so good'elif answerNumber == 9:return 'Very doubtful'r = random.randint(1, 9) # ➍fortune = getAnswer(r) # ➎print(fortune) # ➏
您可以在autbor.com/magic8ball查看该程序的执行情况。当这个程序启动时,Python 首先导入random模块 ➊。然后定义getAnswer()函数 ➋。因为函数正在被定义(而不是被调用),所以执行会跳过其中的代码。接下来,用两个参数调用random.randint()函数:1和9➍。它求值为一个在1和9之间的随机整数(包括1和9本身),这个值存储在一个名为r的变量中。
使用r作为参数 ➎ 调用getAnswer()函数。程序执行移动到getAnswer()函数 ➌ 的顶部,值r存储在名为answerNumber的参数中。然后,根据answerNumber中的值,该函数返回许多可能的字符串值之一。程序执行返回到程序底部原来调用getAnswer()➎ 的那一行。返回的字符串被赋给一个名为fortune的变量,然后该变量被传递给一个print()调用 ➏ 并被打印到屏幕上。
请注意,由于可以将返回值作为参数传递给另一个函数调用,因此可以缩短这三行代码:
r = random.randint(1, 9)
fortune = getAnswer(r)
print(fortune)
到这条等价的线:
print(getAnswer(random.randint(1, 9)))
记住,表达式是由值和运算符组成的。函数调用可以在表达式中使用,因为调用计算其返回值。
None值
在 Python 中,有一个值叫做None,代表没有值。None值是NoneType数据类型的唯一值。(其他编程语言可能会将这个值称为null、nil或undefined。)就像布尔值True和False一样,None必须用大写的N来键入。
当您需要在变量中存储不会与实值混淆的内容时,这种不带值的值会很有帮助。使用None的一个地方是作为print()的返回值。print()函数在屏幕上显示文本,但它不需要像len()或input()那样返回任何内容。但是由于所有的函数调用都需要计算返回值,print()返回None。要查看这一过程,请在交互式 Shell 中输入以下内容:
>>> spam = print('Hello!')
Hello!
>>> None == spam
True
在幕后,Python 将return None添加到任何没有return语句的函数定义的末尾。这类似于while或for循环如何以continue语句隐式结束。此外,如果使用不带值的return语句(也就是说,只有return关键字本身),那么将返回None。
关键字参数和print()函数
大多数参数由它们在函数调用中的位置来标识。比如random.randint(1, 10)和random.randint(10, 1)不一样。函数调用random.randint(1, 10)将返回一个在1和10之间的随机整数,因为第一个参数是区间的低端,第二个参数是高端(而random.randint(10, 1)会导致错误)。
然而,关键字参数不是通过它们的位置,而是通过在函数调用中放在它们前面的关键字来识别的。关键字参数常用于可选参数。例如,print()函数有可选参数end和sep来分别指定应该在它的参数末尾和参数之间打印什么(分隔它们)。
如果您用以下代码运行了一个程序:
print('Hello')
print('World')
输出如下所示:
Hello
World
两个输出的字符串出现在不同的行上,因为print()函数会自动在传递的字符串末尾添加一个换行符。但是,您可以设置end关键字参数,将换行符更改为不同的字符串。例如,如果代码是这样的:
print('Hello', end='')
print('World')
输出如下所示:
HelloWorld
输出被打印在一行上,因为在'Hello'之后不再打印换行符。相反,打印空白字符串。如果您需要禁用添加到每个print()函数调用末尾的换行符,这很有用。
同样,当你传递多个字符串值给print()时,函数会自动用一个空格把它们分开。在交互式 Shell 中输入以下内容:
>>> print('cats', 'dogs', 'mice')
cats dogs mice
但是您可以通过向sep关键字参数传递一个不同的字符串来替换默认的分隔字符串。在交互式 Shell 中输入以下内容:
>>> print('cats', 'dogs', 'mice', sep=',')
cats,dogs,mice
您也可以在自己编写的函数中添加关键字参数,但是首先您必须在接下来的两章中了解列表和字典数据类型。现在,只需要知道一些函数有可选的关键字参数,可以在调用函数时指定。
调用栈
想象你和某人进行了一次曲折的对话。你谈到了你的朋友爱丽丝,这让你想起了一个关于你同事鲍勃的故事,但首先你必须解释一下你的表妹卡罗尔。你写完关于卡罗尔的故事后,继续谈论鲍勃,当你写完关于鲍勃的故事后,继续谈论爱丽丝。但这时你想起了你的哥哥大卫,所以你讲了一个关于他的故事,然后继续完成你原来关于爱丽丝的故事。你的对话遵循一个类似栈的结构,就像图 3-1 中那样。对话是栈式的,因为当前主题总是在栈的顶部。

图 3-1:你曲折的对话栈
类似于我们曲折的对话,调用一个函数不会将执行单向发送到函数的顶部。Python 会记住哪一行代码调用了这个函数,这样当执行遇到一个return语句时就可以返回那里。如果那个原始函数调用了其他函数,在从原始函数调用返回之前,执行将首先返回到那些函数调用。
打开文件编辑器窗口,输入以下代码,保存为abcdCallStack.py :
def a():print('a() starts')b() # ➊d() # ➋print('a() returns')def b():print('b() starts')c() # ➌print('b() returns')def c():print('c() starts') # ➍print('c() returns')def d():print('d() starts')print('d() returns')a() # ➎
如果运行这个程序,输出将如下所示:
a() starts
b() starts
c() starts
c() returns
b() returns
d() starts
d() returns
a() returns
您可以在autbor.com/abcdcallstack查看该程序的执行情况。当a()被调用 ➎ 时,它调用b()➊,后者又调用c()➌。c()函数不调用任何东西;它只显示c() starts、➍ 和c() returns,然后返回到b()中称其为 ➌ 的行。一旦执行返回到b()中调用c()的代码,它就返回到a()中调用b()➊ 的行。执行继续到b()函数 ➋ 中的下一行,这是对d()的调用。和c()函数一样,d()函数也不调用任何东西。在返回到调用它的b()中的行之前,它只显示d() starts和d() returns。由于b()不包含其他代码,执行返回到a()中调用b()➋ 的行。在程序 ➎ 结束返回到原来的a()调用之前,a()中的最后一行显示a() returns。
调用栈是 Python 在每次函数调用后记住返回执行结果的方式。调用栈不存储在程序的变量中;相反,Python 在幕后处理它。当你的程序调用一个函数时,Python 会在调用栈顶创建帧对象。帧对象存储原始函数调用的行号,以便 Python 可以记住返回到哪里。如果进行了另一个函数调用,Python 会将另一个帧对象放在调用栈中的另一个之上。
当函数调用返回时,Python 从栈顶移除一个帧对象,并将执行移动到存储在其中的行号。请注意,帧对象总是从栈顶部添加和移除,而不是从任何其他位置。图 3-2 展示了abcdCallStack.py中调用栈在每个函数被调用并返回时的状态。

图 3-2:调用栈的帧对象为abcdCallStack.py调用并从函数*返回
调用栈的顶部是执行当前所在的函数。当调用栈为空时,在所有函数之外的行上执行。
调用栈是一个技术细节,在编写程序时,你并不一定需要知道它。理解函数调用返回到它们被调用的行号就足够了。然而,理解调用栈会使理解局部和全局作用域变得更容易,这将在下一节中描述。
局部和全局作用域
在被调用函数中赋值的参数和变量被认为存在于该函数的局部作用域中。在所有函数之外赋值的变量被认为存在于全局作用域中。存在于局部作用域内的变量称为局部变量,而存在于全局作用域内的变量称为全局变量。变量必须是其中之一;它不可能既是局部的又是全局性的。
将作用域视为变量的容器。当作用域被销毁时,作用域变量中存储的所有值都会被遗忘。只有一个全局作用域,它是在程序开始时创建的。当你的程序终止时,全局作用域被破坏,它的所有变量都被遗忘。否则,下次运行程序时,变量会记住上次运行时的值。
每当调用一个函数时,就会创建一个局部作用域。函数中分配的任何变量都存在于函数的局部作用域内。当函数返回时,局部作用域被破坏,这些变量被遗忘。下次调用该函数时,局部变量将不会记得上次调用该函数时存储在其中的值。局部变量也存储在调用栈上的帧对象中。
作用域的重要性有几个原因:
- 所有函数之外的全局作用域内的代码不能使用任何局部变量。
- 但是,局部作用域内的代码可以访问全局变量。
- 函数局部作用域内的代码不能使用任何其他局部作用域内的变量。
- 如果不同的变量在不同的作用域内,可以使用相同的名称。也就是说,可以有一个名为
spam的局部变量和一个名为spam的全局变量。
Python 之所以有不同的作用域,而不是把所有东西都变成全局变量,是因为当代码在对函数的特定调用中修改变量时,函数只能通过它的参数和返回值与程序的其余部分进行交互。这缩小了可能导致错误的代码行数。如果你的程序除了全局变量之外什么都不包含,并且因为一个变量被设置为错误的值而出现了一个 bug,那么就很难找到这个错误的值是在哪里设置的。它可以在程序中的任何地方设置,你的程序可能有几百或几千行长!但是如果 BUG 是由一个具有错误值的局部变量引起的,那么您知道只有那个函数中的代码可能设置错误。
虽然在小程序中使用全局变量是好的,但是随着程序变得越来越大,依赖全局变量是一个坏习惯。
局部变量不能在全局作用域内使用
考虑这个程序,当您运行它时,它将导致一个错误:
def spam():eggs = 31337 # ➊
spam()
print(eggs)
如果运行这个程序,输出将如下所示:
Traceback (most recent call last):File "C:/test1.py", line 4, in <module>print(eggs)
NameError: name 'eggs' is not defined
发生错误是因为eggs变量只存在于当spam()被调用 ➊ 时创建的局部作用域中。一旦程序执行从spam返回,这个局部作用域就被破坏了,不再有一个名为eggs的变量。所以当你的程序试图运行print(eggs)时,Python 会给你一个错误,说eggs没有定义。如果你仔细想想,这是有道理的;当程序在全局作用域内执行时,不存在局部作用域,所以不可能有任何局部变量。这就是为什么在全局作用域内只能使用全局变量。
局部作用域不能使用其他局部作用域中的变量
每当调用一个函数时,包括从另一个函数调用一个函数时,都会创建一个新的局部作用域。考虑这个程序:
def spam():eggs = 99 # ➊bacon() # ➋print(eggs) # ➌def bacon():ham = 101eggs = 0 # ➍spam() # ➎
您可以在autbor.com/otherlocalscopes查看该程序的执行情况。当程序启动时,spam()函数被调用 ➎,一个局部作用域被创建。本地变量eggs➊ 被设置为99。然后调用bacon()函数 ➋,并创建第二个局部作用域。多个本地作用域可以同时存在。在这个新的局部作用域中,局部变量ham被设置为101,并且一个局部变量eggs——不同于spam()的局部作用域中的那个——也被创建 ➍ 并被设置为0。
当bacon()返回时,该调用的局部作用域被销毁,包括它的eggs变量。程序在spam()函数中继续执行,打印eggs➌ 的值。由于调用spam()的局部作用域仍然存在,唯一的eggs变量是spam()函数的eggs变量,它被设置为99。这是程序打印的内容。
结果是一个函数中的局部变量与另一个函数中的局部变量完全分离。
可以从局部作用域读取全局变量
考虑以下程序:
def spam():print(eggs)
eggs = 42
spam()
print(eggs)
您可以在autbor.com/readglobal查看该程序的执行情况。由于在spam()函数中没有名为eggs的参数或者任何给eggs赋值的代码,所以当eggs在spam()中使用时,Python 认为它是对全局变量eggs的引用。这就是为什么运行前一个程序时会打印出42。
局部和全局变量同名
从技术上讲,在 Python 中不同作用域的全局变量和局部变量使用相同的变量名是完全可以接受的。但是,为了简化你的生活,避免这样做。要查看发生了什么,请在文件编辑器中输入以下代码,并将其保存为localGlobalSameName.py:
def spam():eggs = 'spam local' # ➊print(eggs) # prints 'spam local'def bacon():eggs = 'bacon local' # ➋print(eggs) # prints 'bacon local'spam()print(eggs) # prints 'bacon local'eggs = 'global' # ➌bacon()print(eggs) # prints 'global'
当您运行该程序时,它会输出以下内容:
bacon local
spam local
bacon local
global
您可以在autbor.com/localglobalsamename查看该程序的执行情况。这个程序中实际上有三个不同的变量,但令人困惑的是它们都被命名为eggs。这些变量如下:
一个名为eggs的变量,当spam()被调用时,它存在于一个局部作用域内。 # ➊
一个名为eggs的变量,当bacon()被调用时,它存在于一个局部作用域内。 # ➋
全局作用域内存在的一个名为eggs的变量。 # ➌
因为这三个独立的变量都有相同的名称,所以在任何给定的时间跟踪哪个变量被使用可能会很混乱。这就是为什么您应该避免在不同的作用域中使用相同的变量名。
全局语句
如果你需要在一个函数中修改一个全局变量,使用global语句。如果你在一个函数的顶部有一行比如global eggs,它告诉 Python,“在这个函数中,eggs指的是全局变量,所以不要用这个名字创建一个局部变量”。例如,在文件编辑器中输入以下代码,并将其保存为globalStatement.py :
def spam():global eggs # ➊eggs = 'spam' # ➋eggs = 'global'
spam()
print(eggs)
当您运行这个程序时,最后一个print()调用将输出如下内容:
spam
您可以在autbor.com/globalstatement查看该程序的执行情况。因为eggs在spam()➊ 的顶部被语句为global,所以当eggs被设置为'spam'➋ 时,这个赋值是对全局作用域eggs完成的。没有创建本地eggs变量。
有四个规则来区分变量是在局部作用域内还是在全局作用域内:
- 如果一个变量在全局作用域内使用(即在所有函数之外),那么它总是一个全局变量。
- 如果在一个函数中有一个针对该变量的
global语句,那么它就是一个全局变量。 - 否则,如果变量在函数的赋值语句中使用,它就是局部变量。
- 但是如果变量没有在赋值语句中使用,它就是一个全局变量。
为了更好地理解这些规则,这里有一个示例程序。在文件编辑器中输入以下代码,并将其保存为sameNameLocalGlobal.py :
def spam():global eggs # ➊eggs = 'spam' # this is the global
def bacon():eggs = 'bacon' # this is a local # ➋
def ham():print(eggs) # this is the global # ➌
eggs = 42 # this is the global
spam()
print(eggs)
在spam()函数中,eggs是全局eggs变量,因为在函数 ➊ 的开头有一个eggs的global语句。在bacon()中,eggs是一个局部变量,因为在函数 ➋ 中有一个赋值语句。在ham()➌ 中,eggs是全局变量,因为在该函数中没有赋值语句或global语句。如果您运行sameNameLocalGlobal.py,输出将如下所示:
spam
在autbor.com/sameNameLocalGlobal可以查看该程序的执行情况。在函数中,变量要么总是全局的,要么总是局部的。函数中的代码不能使用名为eggs的局部变量,然后在同一个函数中使用全局变量eggs。
注
如果你想从一个函数中修改存储在一个全局变量中的值,你必须在那个变量上使用一个全局语句。
如果在给一个函数赋值之前试图在函数中使用一个局部变量,就像下面的程序一样,Python 会给出一个错误。要查看这一点,请在文件编辑器中输入以下内容,并将其保存为sameNameError.py :
def spam():print(eggs) # ERROR!eggs = 'spam local' # ➊eggs = 'global' # ➋spam()
如果运行前面的程序,它会产生一条错误消息。
Traceback (most recent call last):File "C:/sameNameError.py", line 6, in <module>spam()File "C:/sameNameError.py", line 2, in spamprint(eggs) # ERROR!
UnboundLocalError: local variable 'eggs' referenced before assignment
您可以在autbor.com/sameNameError查看该程序的执行情况。发生这个错误是因为 Python 看到在spam()函数 ➊ 中有一个针对eggs的赋值语句,因此认为eggs是局部的。但是因为print(eggs)是在eggs被赋值之前执行的,所以局部变量eggs并不存在。Python 将退回到使用全局eggs变量 ➋。
起到“黑匣子”的作用
通常,关于一个函数,你需要知道的只是它的输入(参数)和输出值;您不必总是为函数代码的实际工作方式而烦恼。当您以这种高级方式考虑函数时,通常会说您正在将函数视为“黑盒”
这个想法是现代编程的基础。本书后面的章节将向你展示几个模块,这些模块的函数是由其他人编写的。如果您好奇的话,可以看一眼源代码,但是您不需要知道这些函数是如何工作的才能使用它们。因为鼓励编写没有全局变量的函数,所以通常不必担心函数的代码与程序的其他部分相互影响。
异常处理
现在,在你的 Python 程序中得到一个错误,或者说异常,意味着整个程序将会崩溃。您不希望这种情况发生在真实世界的程序中。相反,您希望程序检测错误,处理它们,然后继续运行。
例如,考虑下面的程序,它有一个被零除的错误。打开文件编辑器窗口,输入以下代码,保存为zeroDivide.py :
def spam(divideBy):return 42 / divideBy
print(spam(2))
print(spam(12))
print(spam(0))
print(spam(1))
我们已经定义了一个名为spam的函数,给它一个参数,然后打印带有各种参数的函数值,看看会发生什么。这是您运行前面的代码时得到的输出:
21.0
3.5
Traceback (most recent call last):File "C:/zeroDivide.py", line 6, in <module>print(spam(0))File "C:/zeroDivide.py", line 2, in spamreturn 42 / divideBy
ZeroDivisionError: division by zero
您可以在autbor.com/zerodivide查看该程序的执行情况。每当你试图将一个数除以零时,就会发生一个ZeroDivisionError。根据错误消息中给出的行号,您知道spam()中的return语句导致了一个错误。
可以用try和except语句处理错误。可能有错误的代码放在一个try子句中。如果发生错误,程序执行移动到下一个except子句的开始。
您可以将之前被零除的代码放在一个try子句中,并让一个except子句包含代码来处理这个错误发生时会发生什么。
def spam(divideBy):try:return 42 / divideByexcept ZeroDivisionError:print('Error: Invalid argument.')
print(spam(2))
print(spam(12))
print(spam(0))
print(spam(1))
当try子句中的代码导致错误时,程序立即执行到except子句中的代码。运行该代码后,执行照常继续。前面程序的输出如下:
21.0
3.5
Error: Invalid argument.
None
42.0
您可以在autbor.com/tryexceptzerodivide查看该程序的执行情况。注意,在try块中的函数调用中出现的任何错误也会被捕获。考虑下面的程序,它在try块中有spam()个调用:
def spam(divideBy):return 42 / divideBy
try:print(spam(2))print(spam(12))print(spam(0))print(spam(1))
except ZeroDivisionError:print('Error: Invalid argument.')
运行该程序时,输出如下所示:
21.0
3.5
Error: Invalid argument.
您可以在autbor.com/spamintry查看该程序的执行情况。永远不执行print(spam(1))的原因是,一旦执行跳转到except子句中的代码,就不会返回到try子句。相反,它只是像平常一样继续向下移动程序。
一个短程序:之字形
让我们用你到目前为止学到的编程概念来创建一个小的动画程序。该程序将创建一个来回的锯齿形图案,直到用户通过按下 Mu 编辑器的停止按钮或按下CTRL-C来停止它。当您运行该程序时,输出将类似于以下内容:
********************************
****************************************
在文件编辑器中键入以下源代码,并将文件保存为zigzag.py :
import time, sys
indent = 0 # How many spaces to indent.
indentIncreasing = True # Whether the indentation is increasing or not.
try:while True: # The main program loop.print(' ' * indent, end='')print('********')time.sleep(0.1) # Pause for 1/10 of a second.if indentIncreasing:# Increase the number of spaces:indent = indent + 1if indent == 20:# Change direction:indentIncreasing = Falseelse:# Decrease the number of spaces:indent = indent - 1if indent == 0:# Change direction:indentIncreasing = True
except KeyboardInterrupt:sys.exit()
让我们从顶部开始,逐行查看这段代码。
import time, sys
indent = 0 # How many spaces to indent.
indentIncreasing = True # Whether the indentation is increasing or not.
首先,我们将导入time和sys模块。我们的程序使用两个变量:indent变量记录八个星号之前缩进了多少个空格,而indentIncreasing包含一个布尔值来确定缩进量是增加还是减少。
try:while True: # The main program loop.print(' ' * indent, end='')print('********')time.sleep(0.1) # Pause for 1/10 of a second.
接下来,我们将程序的其余部分放在一个 try 语句中。当用户在 Python 程序运行时按下CTRL-C时,Python 会引发KeyboardInterrupt异常。如果没有try - except语句来捕捉这个异常,程序就会崩溃,并显示一条难看的错误消息。然而,对于我们的程序,我们希望它通过调用sys.exit()来干净地处理KeyboardInterrupt异常。(代码在程序末尾的except语句中。)
无限循环将永远重复我们程序中的指令。这包括使用' ' * indent打印正确的缩进空间量。我们不想在这些空格后自动打印一个换行符,所以我们也将end=''传递给第一个print()调用。第二个print()调用打印星号带。time.sleep()函数还没有被介绍,但是可以说它在我们的程序中引入了十分之一秒的暂停。
if indentIncreasing:# Increase the number of spaces:indent = indent + 1if indent == 20:indentIncreasing = False # Change direction.
接下来,我们要调整下次打印星号时的缩进量。如果indentIncreasing是True,那么我们要给indent加一。但是一旦缩进量达到20,我们希望缩进量减少。
else:# Decrease the number of spaces:indent = indent - 1if indent == 0:indentIncreasing = True # Change direction.
同时,如果indentIncreasing是False,我们要从indent中减去一。一旦缩进量达到0,我们希望缩进量再次增加。无论哪种方式,程序执行都将跳回到主程序循环的开始,再次打印星号。
except KeyboardInterrupt:sys.exit()
如果用户在try程序块中的任何一点按下CTRL-C,则KeyboardInterrrupt异常被引发,并由该except语句处理。程序执行在except块内移动,运行sys.exit()并退出程序。这样,即使主程序循环是一个无限循环,用户也有办法关闭程序。
总结
函数是将代码划分成逻辑组的主要方式。由于函数中的变量存在于它们自己的局部作用域内,所以一个函数中的代码不能直接影响其他函数中变量的值。这限制了哪些代码可能会更改变量的值,这对调试代码很有帮助。
函数是帮助你组织代码的一个很好的工具。你可以把它们想象成黑盒:它们有参数形式的输入和返回值形式的输出,其中的代码不会影响其他函数中的变量。
在前几章中,一个错误就可能导致你的程序崩溃。在本章中,你学习了try和except语句,它们可以在检测到错误时运行代码。这可以使你的程序对常见的错误更有弹性。
练习题
-
为什么函数在你的程序中有优势?
-
函数中的代码什么时候执行:定义函数的时候还是调用函数的时候?
-
哪个语句创建了一个函数?
-
函数和函数调用的区别是什么?
-
一个 Python 程序中有多少个全局作用域?多少个本地示波器?
-
当函数调用返回时,局部作用域内的变量会发生什么?
-
什么是返回值?返回值可以是表达式的一部分吗?
-
如果一个函数没有返回语句,那么调用这个函数的返回值是什么?
-
你怎么能强迫一个函数中的变量引用全局变量呢?
-
None的数据类型是什么? -
import areallyourpetsnamederic语句是做什么的? -
如果你在一个名为
spam的模块中有一个名为bacon()的函数,导入spam后你会如何调用它? -
当程序出错时,如何防止它崩溃?
-
try子句中包含什么?except子句中包含什么?
实践项目
为了练习,编写程序来完成以下任务。
编写一个名为collatz()的函数,它有一个名为number的参数。如果number是偶数,那么collatz()应该打印number // 2并返回这个值。如果number是奇数,那么collatz()应该打印并返回3 * number + 1。
然后编写一个程序,让用户输入一个整数,并一直调用这个数字的collatz(),直到函数返回值1。(令人惊讶的是,这个序列实际上适用于任何整数——迟早,使用这个序列,你会得到 1!甚至数学家也不确定为什么。你的程序正在探索所谓的 Collatz 序列,有时被称为“最简单的不可能的数学问题”)
记得用int()函数把input()的返回值转换成整数;否则,它将是字符串值。
提示:整数number如果number % 2 == 0是偶数,如果number % 2 == 1是奇数。
该程序的输出可能如下所示:
Enter number:
3
10
5
16
8
4
2
1
输入验证
将try和except语句添加到前面的项目中,以检测用户是否键入了非整数字符串。通常情况下,int()函数如果被传递了一个非整数字符串,就会引发一个ValueError错误,就像在int('puppy')中一样。在except子句中,打印一条消息给用户,告诉他们必须输入一个整数。*
相关文章:
Python 自动化指南(繁琐工作自动化)第二版:三、函数
原文:https://automatetheboringstuff.com/2e/chapter3/ 您已经熟悉了前几章中的print()、input()和len()函数。Python 提供了几个这样的内置函数,但是您也可以编写自己的函数。函数就像一个程序中的一个小程序。 为了更好地理解函数是如何工作的&#…...

c++多线程 1
https://www.runoob.com/cplusplus/cpp-multithreading.html 两种类型的多任务处理:基于进程和基于线程。 基于进程的多任务处理是程序的并发执行。 基于线程的多任务处理是同一程序的片段的并发执行。 线程 c11以后有了 标准库 1 函数 2 类成员函数 3 lambda函…...
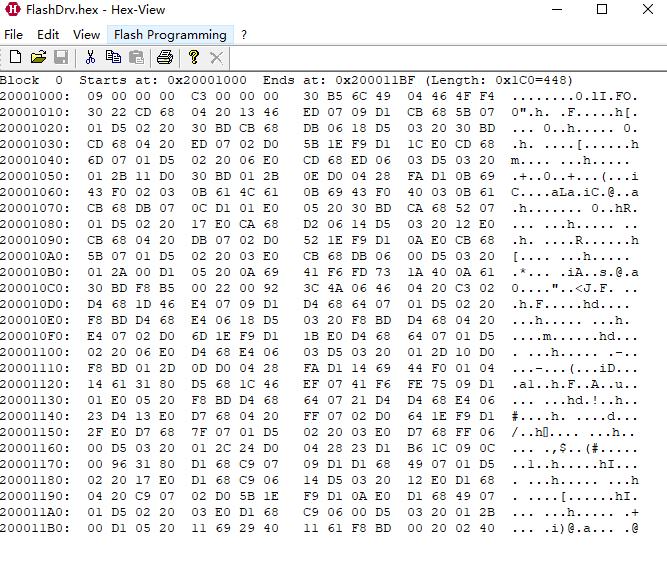
STM32F103制作FlashDriver
文章目录前言芯片内存定义实现过程FlashDriver生成段定义擦除函数写入函数编译后的map手动测试HexView提取指定地址内容并重映射总结前言 在汽车行业控制器软件刷新流程中,一般会将Flash驱动单独进行刷写,目的是防止程序中一直存在Flash驱动的话&#x…...
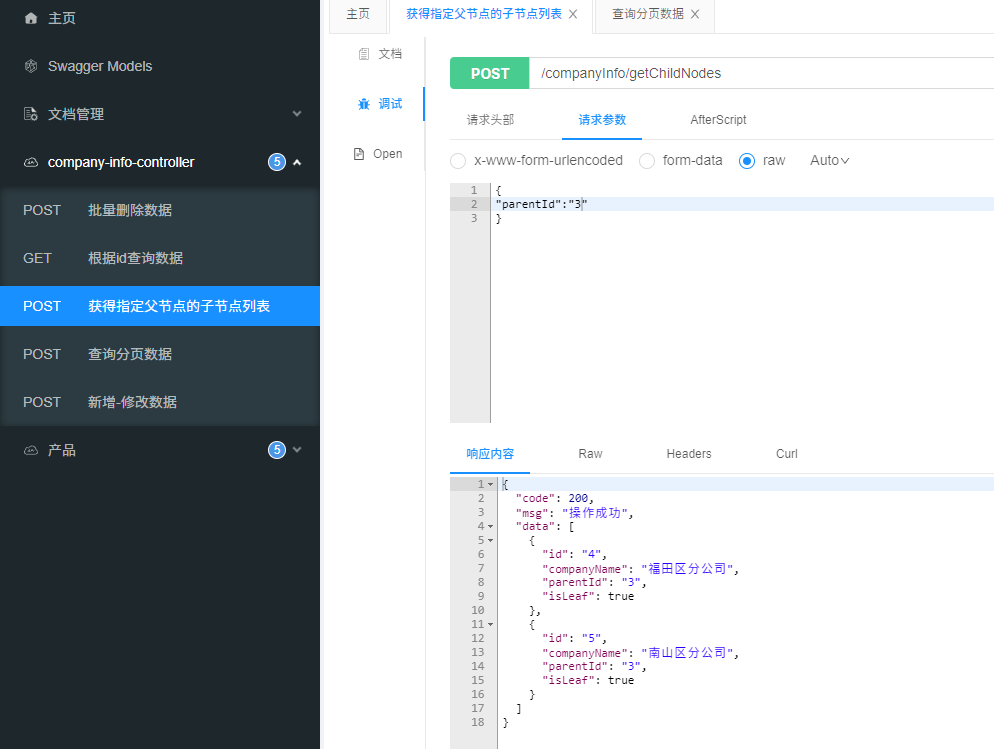
springboot树形结构接口, 懒加载实现
数据库关系有父子id的, 作为菜单栏展示时需要用前端需要用到懒加载, 所谓懒加载就是接口有一个标志位isLeaf, 前端请求后通过该字段判断该节点是否还有子节点数据 创建数据库表 t_company_info结构有id和parentId标识, 用来表示父子关系 /*Navicat Premium Data TransferSourc…...
java企业级信息系统开发学习笔记02初探spring——利用组件注解符精简spring配置文件
文章目录一、学习目标二、打开01的项目三、利用组件注解符精简spring配置文件(一)创建新包,复制四个类(二)修改杀龙任务类(三)修改救美任务类(四)修改勇敢骑士类…...

用Python发送电子邮件?这也太丝滑了吧(21)
小朋友们好,大朋友们好! 我是猫妹,一名爱上Python编程的小学生。 欢迎和猫妹一起,趣味学Python。 今日主题 猫爸赚钱养家,细想起来真的不容易啊! 起早贪黑,都是6点早起做早饭,送…...

分类预测 | MATLAB实现CNN-GRU-Attention多输入分类预测
分类预测 | MATLAB实现CNN-GRU-Attention多输入分类预测 目录分类预测 | MATLAB实现CNN-GRU-Attention多输入分类预测分类效果模型描述程序设计参考资料分类效果 模型描述 Matlab实现CNN-GRU-Attention多变量分类预测 1.data为数据集,格式为excel,12个输…...

C++提高编程(1)
C提高编程1.模板1.1模板的概念1.2函数模板1.2.1函数模板语法1.2.2函数模板注意事项1.2.3函数模板案例1.2.4普通函数与函数模板的区别1.2.5普通函数与函数模板的调用规则1.2.6模板的局限性1.3类模板1.3.1类模板语法1.3.2类模板和函数模板区别1.3.3类模板中成员函数创建时机1.3.4…...

day26 回溯算法的部分总结
回溯算法的部分总结 回溯算法是一种常用于解决排列组合问题、搜索问题的算法,它的基本思想是将问题的解空间转化为一棵树,通过深度优先搜索的方式遍历树上的所有节点,找到符合条件的解。回溯算法通常使用递归实现,每次递归时传入…...

带你玩转Python爬虫(胆小者勿进)千万别做坏事·······
这节课很危险,哈哈哈哈,逗你们玩的 目录 写在前面 1 了解robots.txt 1.1 基础理解 1.2 使用robots.txt 2 Cookie 2.1 两种cookie处理方式 3 常用爬虫方法 3.1 bs4 3.1.1 基础介绍 3.1.2 bs4使用 3.1.2 使用例子 3.2 xpath 3.2.1 xpath基础介…...
【JavaScript 】严格模式,With关键字,测试框架介绍,assert
❤️ Author: 老九 ☕️ 个人博客:老九的CSDN博客 🙏 个人名言:不可控之事 乐观面对 😍 系列专栏: 文章目录静态类型语言弱类型严格模式将过失错误转化为异常简化变量的使用With测试框架try-catch选择性捕获…...
编写流程)
mybatis实现一个简单的CRUD功能的小案例(后端)编写流程
下面是一个使用mybatis实现增删改查功能的示例程序: 1.创建一个数据库 首先需要创建一个名为test_db的数据库,里面包含一个名为user_info的表,其中包含id、name、age三个字段。 2.配置mybatis 在项目的pom.xml文件中添加mybatis和mysql依…...

腾讯云轻量应用服务器价格表(2023版)
2023腾讯云轻量应用服务器2核2G4M带宽88元一年、2核4G6M带宽159元/年、4核8G10M优惠价425元、8核16G14M价格1249、16核32G20M服务器2499元一年,今天分享2023腾讯云服务器配置及精准报价。 腾讯云轻量应用服务器优惠价格表 腾讯云服务器分为轻量应用服务器和云服务器…...

网络层IP协议和数据链路层
目录IP协议协议头格式分片网段划分特殊的IP地址IP地址的数量限制NAT技术NAT技术背景NAT IP转换过程NAPTNAT技术的缺陷NAT和代理服务器私有IP地址和公网IP地址路由路由表生成算法数据链路层认识以太网以太网帧格式认识MAC地址对比理解MAC地址和IP地址认识MTUMTU对IP协议的影响MT…...

零基础学习Java 03
目录 数组 动态初始化数组 静态初始化 数组的应用 数组两种典型的异常 length关键字求出数组的长度 数组遍历在IDEA中输出快捷语句 对象数组 数组的遍历:foreach方法 二维数组 枚举(enum) 数组 1在方法中可以返回一个数组,但是在定义方法时类型要…...

PG数据库超时退出 TCP设定
数据库在使用psql工具以及jdbc进行远程连接时,在经过一定时间之后报错-致命错误: terminating connection due to client no input timeout。 排查安全参数,hg_clientnoinput 0; 问题原因 操作系统TCP相关参数设置不正确&…...

每日学术速递4.4
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理 Subjects: cs.CL 1.Baize: An Open-Source Chat Model with Parameter-Efficient Tuning on Self-Chat Data 标题:Baize:一种对自聊天数据进行参数高效调优的开源聊天模型 作者…...

ChatGPT将引发大量而普遍的网络安全隐患
ChatGPT是一个基于人工智能的语言生成模型,它可以在任何给定的时间,使用自然语言生成技术,生成文本、对话和文章。它不仅可以被用来编写文本,还可以用来编写语言、生成图像和视频。目前, ChatGPT已广泛应用于语言翻译、…...

购买学生护眼台灯几瓦最好?有哪些推荐护眼灯
现今的近视已然成为普遍现象,而且有往低年龄段发展的趋势。究其原因,长期使用电子设备是一方面,还是就是我们日常工作、学习、生活没有很好的护眼环境,很多时候我们不经意的错误习惯,久而久之就有可能诱发近视。对孩子…...
什么是 SYN 攻击?如何避免 SYN 攻击?
SYN 攻击方式最直接的表现就会把 TCP 半连接队列打满,这样当 TCP 半连接队列满了,后续再在收到 SYN 报文就会丢弃,导致客户端无法和服务端建立连接。 避免 SYN 攻击方式,可以有以下四种方法: 调大 netdev_max_backlo…...

Spring Authorization Server Redis缓存优化:构建高性能分布式授权服务的架构设计与性能调优指南
Spring Authorization Server Redis缓存优化:构建高性能分布式授权服务的架构设计与性能调优指南 【免费下载链接】spring-authorization-server Spring Authorization Server 项目地址: https://gitcode.com/gh_mirrors/sp/spring-authorization-server 在现…...

Cardano节点高级功能探索:质押池、智能合约与治理的终极指南
Cardano节点高级功能探索:质押池、智能合约与治理的终极指南 【免费下载链接】cardano-node The core component that is used to participate in a Cardano decentralised blockchain. 项目地址: https://gitcode.com/gh_mirrors/ca/cardano-node Cardano节…...
)
告别手写C库!用Buddy-MLIR一键编译PyTorch模型到Gemmini加速器(实战避坑)
告别手写C库!用Buddy-MLIR一键编译PyTorch模型到Gemmini加速器(实战避坑) 当算法工程师面对定制硬件加速器时,最头疼的莫过于如何将训练好的模型高效部署到专用计算架构上。传统手工编写C库的方法不仅耗时费力,更成为阻…...

别再傻傻分不清!一文讲透华为设备CRU与FRU区别及SmartKit工具的正确打开方式
华为设备维护进阶指南:CRU与FRU的深度解析及SmartKit高效应用 在数据中心运维和IT设备管理领域,华为设备的可靠性和性能一直备受认可。然而,即便是经验丰富的运维团队,在面对设备部件更换决策时,也常常陷入概念混淆和操…...

3步实现专业级字幕去除:面向视频创作者的AI处理工具全指南
3步实现专业级字幕去除:面向视频创作者的AI处理工具全指南 【免费下载链接】video-subtitle-remover 基于AI的图片/视频硬字幕去除、文本水印去除,无损分辨率生成去字幕、去水印后的图片/视频文件。无需申请第三方API,本地实现。AI-based too…...
)
数模小白别慌!手把手教你用Python和MATLAB搞定国赛美赛(附2022年M奖/省一代码)
数模竞赛入门指南:从零到获奖的Python与MATLAB实战路径 数学建模竞赛对于初学者而言,往往像一座难以攀登的高山。第一次面对赛题时,那种无从下手的迷茫感我至今记忆犹新——三个队友围着一道看似简单的题目,却连该用什么工具、从哪…...

传世无双光武系统全解析:蓝紫橙红金星位进阶,特效酷炫战力飙升新高度!
在传奇类手游百花齐放的今天,《金装裁决之传世无双》凭借官方正版授权的品质保障、每周稳定开新区的公平生态,以及不断创新的玩法体系,成为无数玩家心中的热血首选。而即将于2026 年 3 月 30 日 10:00震撼开启的【无双 1371 区】,…...

ResNet残差连接实战:为什么你的深层网络总是不收敛?
ResNet残差连接实战:为什么你的深层网络总是不收敛? 训练深度神经网络时,最令人沮丧的莫过于看着损失函数在迭代中纹丝不动,或是验证集指标像过山车一样上下波动。我曾在一个图像分类项目中使用标准CNN架构,当层数超过…...

地热模拟实战:当岩石遇上高温水流
Comsol地热开采-热流固耦合(两个模型,均质和裂隙岩体)附赠参考文献。地热开采就像给地球做"针灸",要在不透水的花岗岩里造出人工热储层。最近用COMSOL折腾了两个典型模型:人畜无害的均质岩体和自带裂隙的破碎…...

Llama Factory应用场景:快速打造行业专属的智能客服模型
Llama Factory应用场景:快速打造行业专属的智能客服模型 1. 引言:当智能客服遇见“模型工厂” 想象一下这个场景:一家电商公司,每天要处理成千上万的客户咨询。从“这个衣服有货吗”到“我的订单为什么还没发货”,客…...