带你玩转Python爬虫(胆小者勿进)千万别做坏事·······
这节课很危险,哈哈哈哈,逗你们玩的
目录
写在前面
1 了解robots.txt
1.1 基础理解
1.2 使用robots.txt
3 常用爬虫方法
3.1 bs4
3.1.1 基础介绍
3.1.2 bs4使用
3.1.2 使用例子
3.2 xpath
3.2.1 xpath基础介绍
3.2.2 xpath使用
3.2.3 使用例子
写在最后

写在前面
今天给大家找了很多我之前学习爬虫时候的资料,虽然我现在不玩爬虫了(害怕),但是大家还是可以去查阅啥的哈,最后求大家给个关注,冲冲W粉,谢谢!!!!
1 了解robots.txt
1.1 基础理解
robots.txt是一个纯文本文件,在这个文件中网站管理者可以声明该网站中不想被robots访问的部分,或者指定搜索引擎只收录指定的内容,一般域名后加/robots.txt,就可以获取
当一个搜索机器人(有的叫搜索蜘蛛)访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,那么搜索机器人就沿着链接抓取
另外,robots.txt必须放置在一个站点的根目录下,而且文件名必须全部小写。robots.txt写作语法
首先,我们来看一个robots.txt范例:https://fanyi.youdao.com/robots.txt
访问以上具体地址,我们可以看到robots.txt的具体内容如下
User-agent: Mediapartners-Google
Disallow:User-agent: *
Allow: /fufei
Allow: /rengong
Allow: /web2/index.html
Allow: /about.html
Allow: /fanyiapi
Allow: /openapi
Disallow: /app
Disallow: /?
以上文本表达的意思是允许所有的搜索机器人访问fanyi.youdao.com站点下的所有文件
具体语法分析:User-agent:后面为搜索机器人的名称,后面如果是*,则泛指所有的搜索机器人;Disallow:后面为不允许访问的文件目录
1.2 使用robots.txt
robots.txt自身是一个文本文件。它必须位于域名的根目录中并被命名为robots.txt。位于子目录中的 robots.txt 文件无效,因为漫游器只在域名的根目录中查找此文件。例如,http://www.example.com/robots.txt 是有效位置,http://www.example.com/mysite/robots.txt 则不是有效位置
2 Cookie
由于http/https协议特性是无状态特性,因此需要服务器在客户端写入cookie,可以让服务器知道此请求是在什么样的状态下发生
2.1 两种cookie处理方式
cookie简言之就是让服务器记录客户端的相关状态信息,有两种方式:
- 手动处理
通过抓包工具获取cookie值,然后将该值封装到headers中
headers={'cookie':"...."}
在发起请求时把cookie封装进去
- 自动处理
自动处理时,要明白cookie的值来自服务器端,在模拟登陆post后,服务器端创建并返回给客户端
主要是通过session会话对象来操作cookie,session作用:可以进行请求的发送;如果请求过程中产生了cookie会自动被存储或携带在该session对象中
创建session对象:session=requests.Session(),使用session对象进行模拟登陆post请求发送(cookie会被存储在session中)
发送session请求:session.post()在发送时session对象对要请求的页面对应get请求进行发送(携带了cookie)
3 常用爬虫方法
用python爬取数据解析原理:
- 标签定位
- 提取标签、标签属性中存储的数据值
3.1 bs4
3.1.1 基础介绍
bs4进行网页数据解析bs4解析原理:
- 通过实例化一个
BeautifulSoup对象,并且将页面源码数据加载到该对象中 - 通过调用
BeautifulSoup对象中相关的属性或者方法进行标签定位和数据提取
环境安装:
pip install bs4
pip install lxml
3.1.2 bs4使用
3.1.2.1 获取解析对象
如何实例化BeautifulSoup对象:
导包from bs4 import BeautifulSoup
对象的实例化,有两种,本地和远程:
- 将本地的
html文档中的数据加载到该对象中
page_text = response.text
soup=BeautifulSoup(page_text,'lxml')
3.1.2.2 使用bs4解析
使用bs4提供的用于数据解析的方法和属性:
-
soup.tagName:返回的是文档中第一次出现的tagName对应的标签,比如soup.a获取第一次出现的a标签信息 -
soup.find():
在使用find('tagName')效果是等同于soup.tagName;
进行属性定位,soup.find(‘div’,class_(或id或attr)='song'):示例就是定位带有class='song'的div标签,class_必须有下划线是为了规避python关键字
还可以是其他比如:soup.find(‘div’,id='song'):定位id是song的div标签soup.find(‘div’,attr='song'):定位attr是song的div标签 -
soup.find_all('tagName'):返回符合要求的所有标签(列表)
select用法:
select('某种选择器(id,class,标签..选择器)')返回的是一个列表
获取标签之间文本数据
可以使用text或string或get_text(),主要区别:
text或get_text()可以获取某一个标签中所有的文本内容string:只可以获取该标签下面直系的文本内容
获取标签中属性值:
- 使用
python获取字典方法获取,比如:soup.a['href']就是获取<a>中的href值
3.1.2 使用例子
import os
import requests
from bs4 import BeautifulSoupheaders={'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}
url="https://www.test.com/chaxun/zuozhe/77.html"def getPoems():res= requests.get(url=url,headers=headers)res.encoding='UTF-8'page_text=res.text#在首页解析出章节soup = BeautifulSoup(page_text,'lxml')shici_list = soup.select(".shici_list_main > h3 > a")shici_name=[]for li in shici_list:data_url = "https://www.test.com"+li['href']# print(li.string+"======="+data_url)shici_name.append(li.string)detail_res = requests.get(url=data_url,headers=headers)detail_res.encoding='UTF-8'detail_page_text=detail_res.textdetail_soup = BeautifulSoup(detail_page_text,'lxml')detail_content = detail_soup.find("div",class_="item_content").text# print(detail_content)with open("./shici.txt",'a+',encoding= 'utf8') as file:if shici_name.count(li.string)==1:file.write(li.string)file.write(detail_content+"\n")print(li.string+"下载完成!!!!") if __name__=="__main__":getPoems()
3.2 xpath
xpath解析:最常用且最便捷高效的一种解析方式
3.2.1 xpath基础介绍
xpath解析原理:
- 实例化一个
etree的对象,且需要将被解析的页面源码数据加载到该对象中 - 调用
etree对象中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获
环境安装:
pip install lxml
3.2.2 xpath使用
3.2.2.1 获取相关对象
先实例化一个etree对象,先导包:from lxml import etree
- 将本地的
html文档中的源码数据加载到etree对象中
tree=etree.parse(filepath)
- 可以将从互联网上获取的源码数据加载到该对象中
page_text = response.text
tree=etree.HTML(page_text)
3.2.2.2 通过xpath解析
通过xpath表达式:tree.xpath(xpath表达式):xpath表达式:
/:表示的是从根节点开始定位,表示的是一个层级//:表示的是多个层级,可以表示从任意位置开始定位- 属性定位:
tag[@attrName='attrValue']
比如//div[@class='song']表示的是获取到任意位置class='song'的<div>标签 - 索引定位:
//div[@class='song']/p[3]表示的是任意位置class='song'的<div>标签下面的第三个<p>标签,注意:索引定位是从1开始的 - 取文本:
/text():获取的是标签中直系文本内容//text():标签中非直系的文本内容(所有的文本内容) - 取属性:
/@attrName:获取某个属性的值,比如://img/@src获取任意的img标签的src值
注意:xpath中也可以使用管道符|,如果第一个没有取到就去取管道符后面的,比如:xpath('//div/b/text() | //div/a/test()'),如果管道符左边生效就取左边,若右边生效就取右边注意:xpath中不能出现tbody标签
3.2.3 使用例子
import requests
from lxml import etree
import reheaders={'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}
url="https://www.test.com/chaxun/zuozhe/77.html"def getPoemsByXpath():res= requests.get(url=url,headers=headers)res.encoding='UTF-8'page_text=res.text#在首页解析出章节tree = etree.HTML(page_text)shici_list = tree.xpath("//div[@class='shici_list_main']")shici_name_out=''for shici in shici_list:#此处使用相对路径shici_name=shici.xpath("h3/a/text()")[0]# print(shici_name)shici_text_list=shici.xpath("div//text()")# print(shici_text_list)with open("./shicibyxpath.txt",'a+',encoding= 'utf8') as file:if shici_name_out!=shici_name:file.write(shici_name+"\n")for text in shici_text_list:if "展开全文"==text or "收起"==text or re.match(r'^\s*$',text)!=None or re.match(r'^\n\s*$',text)!=None:continuere_text=text.replace(' ','').replace('\n','')file.write(re_text+"\n")if shici_name_out!=shici_name:print(shici_name+"下载完成!!!!") shici_name_out=shici_nameif __name__=="__main__":getPoemsByXpath()写在最后

不要去干坏事,因为爬虫程序采集到公民的姓名、身份证件号码、通信通讯联系方式、住址、账号密码、财产状况、行踪轨迹等个人信息,并将之用于非法途径的,则肯定构成非法获取公民个人信息的违法行为。也就是说你爬虫爬取信息没有问题,但不能涉及到个人的隐私问题,如果涉及了并且通过非法途径收益了,那肯定是违法行为。另外,还有下列三种情况,爬虫有可能违法,严重的甚至构成犯罪:爬虫程序规避网站经营者设置的反爬虫措施或者破解服务器防抓取措施,非法获取相关信息,情节严重的,有可能构成“非法获取计算机信息系统数据罪”。爬虫程序干扰被访问的网站或系统正常运营,后果严重的,触犯刑法,构成“破坏计算机信息系统罪”爬虫采集的信息属于公民个人信息的,有可能构成非法获取公民个人信息的违法行为,情节严重的,有可能构成“侵犯公民个人信息罪”
所以,学习Python爬虫是没问题的,但是心一定要正!!
相关文章:
带你玩转Python爬虫(胆小者勿进)千万别做坏事·······
这节课很危险,哈哈哈哈,逗你们玩的 目录 写在前面 1 了解robots.txt 1.1 基础理解 1.2 使用robots.txt 2 Cookie 2.1 两种cookie处理方式 3 常用爬虫方法 3.1 bs4 3.1.1 基础介绍 3.1.2 bs4使用 3.1.2 使用例子 3.2 xpath 3.2.1 xpath基础介…...
【JavaScript 】严格模式,With关键字,测试框架介绍,assert
❤️ Author: 老九 ☕️ 个人博客:老九的CSDN博客 🙏 个人名言:不可控之事 乐观面对 😍 系列专栏: 文章目录静态类型语言弱类型严格模式将过失错误转化为异常简化变量的使用With测试框架try-catch选择性捕获…...
编写流程)
mybatis实现一个简单的CRUD功能的小案例(后端)编写流程
下面是一个使用mybatis实现增删改查功能的示例程序: 1.创建一个数据库 首先需要创建一个名为test_db的数据库,里面包含一个名为user_info的表,其中包含id、name、age三个字段。 2.配置mybatis 在项目的pom.xml文件中添加mybatis和mysql依…...

腾讯云轻量应用服务器价格表(2023版)
2023腾讯云轻量应用服务器2核2G4M带宽88元一年、2核4G6M带宽159元/年、4核8G10M优惠价425元、8核16G14M价格1249、16核32G20M服务器2499元一年,今天分享2023腾讯云服务器配置及精准报价。 腾讯云轻量应用服务器优惠价格表 腾讯云服务器分为轻量应用服务器和云服务器…...

网络层IP协议和数据链路层
目录IP协议协议头格式分片网段划分特殊的IP地址IP地址的数量限制NAT技术NAT技术背景NAT IP转换过程NAPTNAT技术的缺陷NAT和代理服务器私有IP地址和公网IP地址路由路由表生成算法数据链路层认识以太网以太网帧格式认识MAC地址对比理解MAC地址和IP地址认识MTUMTU对IP协议的影响MT…...

零基础学习Java 03
目录 数组 动态初始化数组 静态初始化 数组的应用 数组两种典型的异常 length关键字求出数组的长度 数组遍历在IDEA中输出快捷语句 对象数组 数组的遍历:foreach方法 二维数组 枚举(enum) 数组 1在方法中可以返回一个数组,但是在定义方法时类型要…...

PG数据库超时退出 TCP设定
数据库在使用psql工具以及jdbc进行远程连接时,在经过一定时间之后报错-致命错误: terminating connection due to client no input timeout。 排查安全参数,hg_clientnoinput 0; 问题原因 操作系统TCP相关参数设置不正确&…...

每日学术速递4.4
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理 Subjects: cs.CL 1.Baize: An Open-Source Chat Model with Parameter-Efficient Tuning on Self-Chat Data 标题:Baize:一种对自聊天数据进行参数高效调优的开源聊天模型 作者…...

ChatGPT将引发大量而普遍的网络安全隐患
ChatGPT是一个基于人工智能的语言生成模型,它可以在任何给定的时间,使用自然语言生成技术,生成文本、对话和文章。它不仅可以被用来编写文本,还可以用来编写语言、生成图像和视频。目前, ChatGPT已广泛应用于语言翻译、…...

购买学生护眼台灯几瓦最好?有哪些推荐护眼灯
现今的近视已然成为普遍现象,而且有往低年龄段发展的趋势。究其原因,长期使用电子设备是一方面,还是就是我们日常工作、学习、生活没有很好的护眼环境,很多时候我们不经意的错误习惯,久而久之就有可能诱发近视。对孩子…...
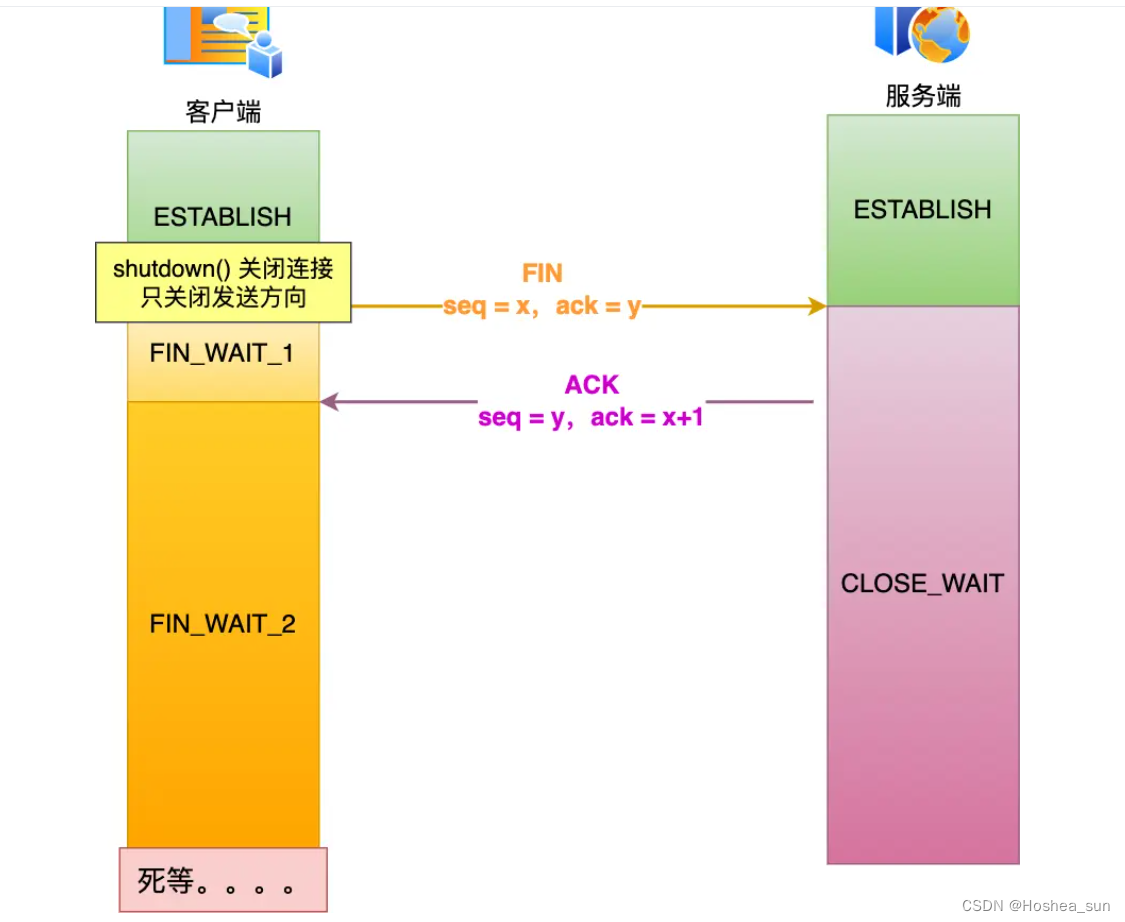
什么是 SYN 攻击?如何避免 SYN 攻击?
SYN 攻击方式最直接的表现就会把 TCP 半连接队列打满,这样当 TCP 半连接队列满了,后续再在收到 SYN 报文就会丢弃,导致客户端无法和服务端建立连接。 避免 SYN 攻击方式,可以有以下四种方法: 调大 netdev_max_backlo…...

数据分析练习——学习一般分析步骤
目录 一、准备工作 二、导入库和数据 1、导入必要的库: 2、模拟数据 三、数据分析过程 1、读取数据: 2、数据概览和描述性统计: 2.1、查看数据概览: 2.2、查看描述性统计: 3、数据清洗: 3.1、处…...

Linux环境下挂载exfat格式U盘,以及安装exfat文件系统
目录Linux一般支持的文件系统有:1.安装exfat软件安装工具环境以及exfat件依赖的系统软件下载exfat源码包并安装2.挂载exfat格式U盘查看U盘在那个目录执行挂载命令Linux一般支持的文件系统有: 文件系统名称详情ext专门为Linux核心做的第一个文件系统&…...
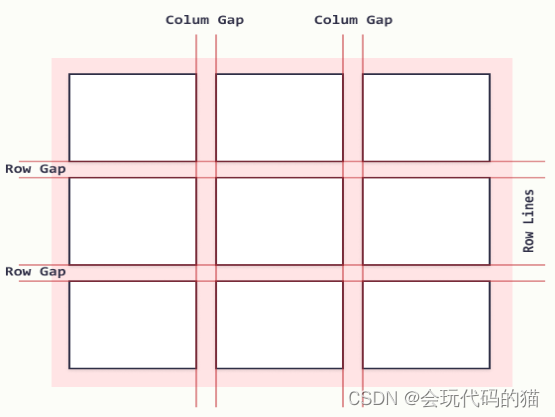
网格布局grid
grid网格定义 css网格是一个用于web的二维(行和列的组合)布局,利用网格,你可以把内容按照行和列的格式进行排版,另外,可以轻松的实现复杂布局。 1.定义网格和fr单位 1.1定义网格 在父元素加上ÿ…...

《扬帆优配》环境更优!这类资金,迎利好!
近来,第一批主板注册制新股连续发动申购,网下询价中,组织出资者频繁现身打新商场,公募基金、社保基金、养老金、保险资金等中长时间资金,成为全面注册制下新股发行商场的重要参加者。 多位业内人士对此表明,…...
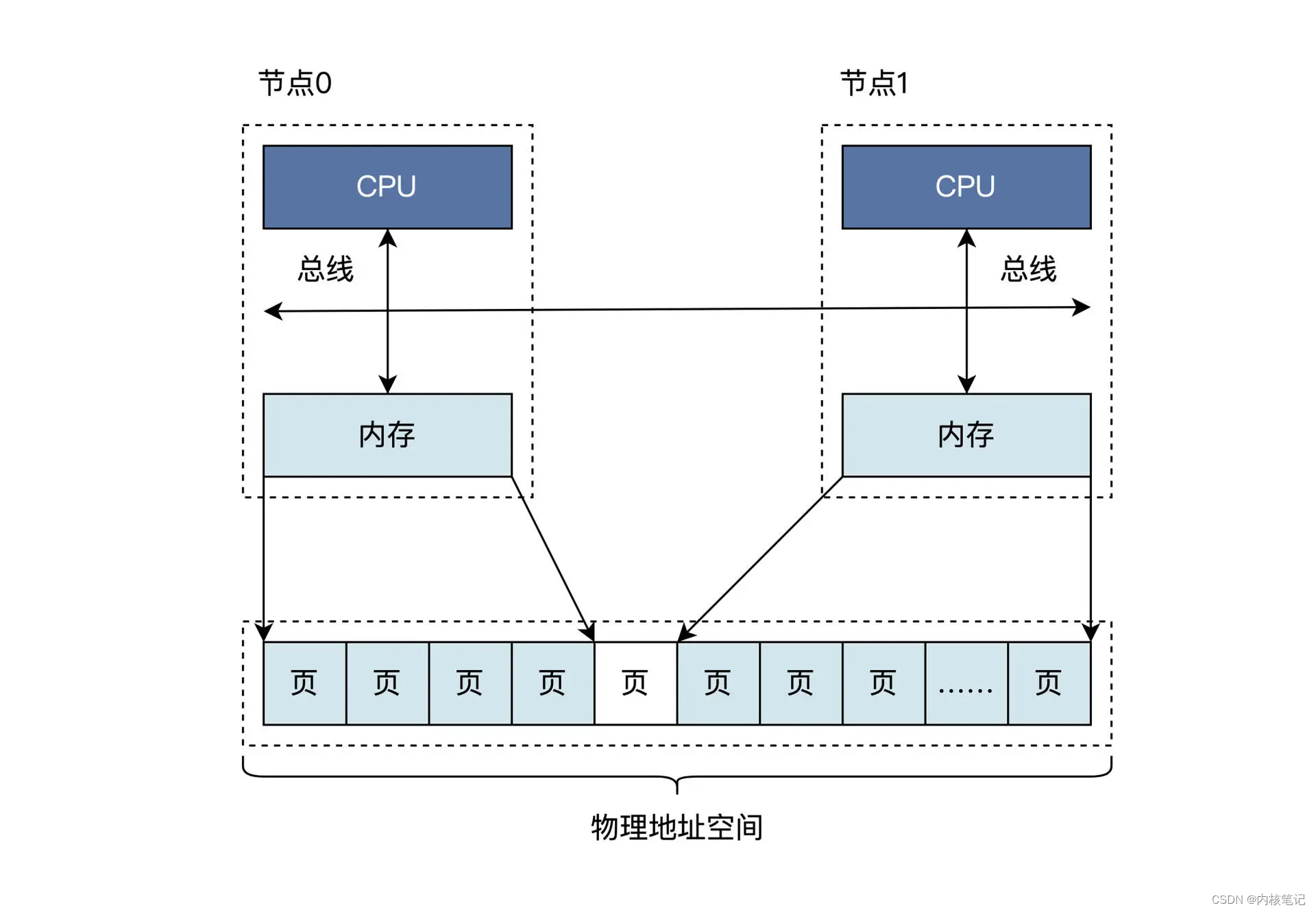
RK3568平台开发系列讲解(内存篇)内存管理的相关结构体
🚀返回专栏总目录 文章目录 一、硬件架构二、Linux 物理内存管理结构体沉淀、分享、成长,让自己和他人都能有所收获!😄 📢应用程序想要使用内存,必须得先找操作系统申请,我们有必要先了解一下 Linux 内核怎么来管理内存,这样再去分析应用程序的内存管理细节的时候,…...

如何理解二叉树与递归的关系
二叉树一般都是和递归有联系的,二叉树的遍历包括了前序,后序,中序,大部分题目只要考虑清楚应该用那种遍历顺序,然后特殊情况的条件,题目就会迎刃而解。 1. 先来说说二叉树的遍历方式 其实二叉树的遍历很简…...

CSS 高级技巧
目录 1.精灵图 1.1为什么需要精灵图 1.2 精灵图(sprites)的使用 2.字体图标 2.1字体图标的产生 2.2字体图标的优点 2.3字体图标的下载 2.4字体图标的引入 2.5字体图标的追加 1.精灵图 1.1为什么需要精灵图 一个网站往往回应用很多的小背景图像作…...

ToBeWritten之MIPS汇编基础铺垫
也许每个人出生的时候都以为这世界都是为他一个人而存在的,当他发现自己错的时候,他便开始长大 少走了弯路,也就错过了风景,无论如何,感谢经历 转移发布平台通知:将不再在CSDN博客发布新文章,敬…...

MySQL数据库对数据库表的创建和DML操作
1.创建表user,其中包含id、name、password,其中主键自增,name,唯一是可变长度,最大长度是30,密码,可变长度,最大长度为20,不为空。 以下是创建符合要求的user表的SQL语句…...

03-CAPL 常用函数大全
专栏:《CAPL 脚本编写实战指南》第 3 篇 作者:一线汽车电子测试工程师 适合人群:已掌握 CAPL 基础的测试人员、想系统学习 CAPL 函数的工程师开篇:为什么要学 CAPL 函数? 这是我刚学 CAPL 时的真实经历。 当时的情况&a…...

【无标题】260329
一切都只是我想多了么看到你的博文看到你的新年快乐现在看到你删库跑路为什么要这样出现又消失。。。本来就虚无缥缈的一点儿联系又消失殆尽如果现在可以见到你我心里有N个为什么想问你只是觉得憋屈可能是我理解能力不足共情能力有限我猜不到你的心思啊你到底是想联系还是不想联…...
)
Qwen3-VL-8B-Instruct-GGUF效果分享:100张用户实测图平均响应时间<1.8s(A10 GPU)
Qwen3-VL-8B-Instruct-GGUF效果分享:100张用户实测图平均响应时间<1.8s(A10 GPU) 1. 模型效果实测:速度与精度的双重惊喜 当我第一次看到Qwen3-VL-8B-Instruct-GGUF的测试结果时,确实被惊艳到了。这个模型在A10 G…...

Sentinel-1A极化矩阵处理实战:用SNAP生成C2矩阵的7个关键参数解析与效果对比
Sentinel-1A极化矩阵处理实战:用SNAP生成C2矩阵的7个关键参数解析与效果对比 当处理Sentinel-1A极化SAR数据时,C2矩阵的生成质量直接影响后续地物分类、变化检测等应用的精度。许多初学者在使用SNAP的Polarimetric-Matrices算子时,往往直接采…...
)
STM32光敏电阻传感器实战:从硬件接线到代码调试全流程(附避坑指南)
STM32光敏电阻传感器实战:从硬件接线到代码调试全流程(附避坑指南) 在智能家居和环境监测项目中,光照强度检测是一个基础但关键的功能模块。光敏电阻因其成本低廉、使用简单,成为许多开发者的首选传感器。本文将带你从…...
及其特性对比)
实战指南:利用Python可视化常见激活函数(Sigmoid、Tanh、ReLU、PReLU)及其特性对比
1. 为什么需要可视化激活函数? 在深度学习的世界里,激活函数就像是神经网络的"开关",决定了神经元是否应该被激活。但很多初学者在学习时,往往只是死记硬背公式,却不知道这些函数长什么样、在什么情况下会有…...

Paimon实时数据湖实战:五种分桶模式选型与性能调优指南
1. Paimon分桶机制的核心价值 分桶是Paimon数据湖架构中提升性能的关键设计。想象你管理一个超大型图书馆,如果所有书籍都堆放在一起,每次找书都需要全馆搜索。但如果你按照书籍编号将书架分成100个区域,找书时只需计算编号哈希就能直达对应区…...
)
PX4无人机开发实战:5个关键ROS话题的订阅与发布详解(附代码示例)
PX4无人机开发实战:5个关键ROS话题的订阅与发布详解(附代码示例) 当你在PX4无人机开发中首次接触ROS通信时,可能会被各种话题和服务搞得晕头转向。作为连接飞控与外部系统的桥梁,这些通信接口直接决定了无人机的可控性…...

【Spring】实战:构建SpringBoot + OAuth2.0微服务安全网关
1. 为什么需要微服务安全网关? 在电商后台这类复杂的微服务架构中,每个服务都需要处理用户认证和权限控制。想象一下,如果每个微服务都自己实现一套登录验证逻辑,不仅会造成代码重复,更会导致安全策略不一致、维护成本…...

CUA Computer SDK:虚拟机自动化的终极解决方案,让AI代理掌控桌面级交互
CUA Computer SDK:虚拟机自动化的终极解决方案,让AI代理掌控桌面级交互 【免费下载链接】cua Create and run high-performance macOS and Linux VMs on Apple Silicon, with built-in support for AI agents. 项目地址: https://gitcode.com/GitHub_T…...