Hive优化操作(一)
Hive SQL 优化指南
在使用 Hive 进行数据分析时,提高查询性能至关重要。以下是一些具体的优化策略,帮助我们在工作中更有效地管理和查询数据。
一、 减少数据量进行优化
1. 分区表优化
-
分区是一种表的子集,用于按某一列(如日期、地区等)将数据划分成多个部分。
-
当查询一个分区表时,Hive 会只扫描相关的分区,而不是整个表。这能显著减少需要读取的数据量,从而提高查询速度。
示例:
CREATE TABLE sales (id INT,amount DECIMAL(10,2),date STRING
) PARTITIONED BY (year INT, month INT);
在插入数据时,指定每个记录的分区信息。
2. 分桶表优化
-
分桶将数据分成多个“桶”,每个桶是一个独立的数据集合。
-
在进行 JOIN 操作时,分桶表可以避免全表扫描,提高查询效率。
示例:
CREATE TABLE employees (id INT,name STRING
) CLUSTERED BY (id) INTO 10 BUCKETS;
这里,表会按照 id 列划分为 10 个桶。
3. 拆分大表为临时表
-
将一个大表拆分成多个小的临时表。
-
小表的处理速度通常更快,可以在查询时更灵活地组合和查询。
临时表用于存储在会话期间存在的数据,通常不需要持久化,主要用于存储临时计算结果。
优化原理:
- 避免数据写入磁盘:临时表只在会话中存在,在会话结束时自动消失,避免了对磁盘的I/O操作。
- 加速数据处理:适合用于存储需要在多个查询中使用的中间结果,可以减少重复计算,提高查询效率。
示例:
CREATE TEMPORARY TABLE temp_table AS
SELECT customer_id, COUNT(*) as order_count
FROM sales
GROUP BY customer_id;SELECT * FROM temp_table WHERE order_count > 10;
4. 列裁剪
-
只选择查询所需的列,万万不可使用
SELECT *。 -
聚合分析,连接其它表前使用列裁剪,能减少传输的数据量,降低 I/O 成本。
示例:
SELECT amount FROM sales;
5. 数据过滤
-
在聚合分析,连接其它表前使用
WHERE子句提前过滤不必要的数据。 -
这样可以减少后续处理的数据量,提高性能。
示例:
SELECT SUM(amount) FROM sales WHERE amount > 1000;
6. 中间表制作
-
在执行复杂查询时,先将部分结果存入中间表,然后再进行后续查询。
-
这样可以让查询逻辑更清晰,也有助于提高性能。
中间表通常用于在复杂查询中存储中间结果,以便于后续的查询或分析。这种做法可以降低重复计算的开销。
优化方式:
- 分步执行:将复杂的查询拆分为多个小查询,使用中间表保存中间结果,避免重复计算。
- 数据分区:可以对中间表进行分区,以加速数据读取和查询。
- 聚合和过滤:在生成中间表时,可以进行初步的聚合和过滤,减少后续操作的数据量。
示例:
CREATE TABLE intermediate_table AS
SELECT customer_id, SUM(amount) AS total_amount
FROM sales
GROUP BY customer_id;SELECT * FROM intermediate_table WHERE total_amount > 1000;
二、 对数据进行压缩,行列存储格式转换
1. 磁盘 I/O
什么是 I/O?
- I/O 指的是数据在计算机系统与外部存储(如磁盘驱动器、SSD、HDFS)之间的传输过程。对大数据来说,这通常涉及从硬盘读取数据或将数据写入硬盘。
2. HDFS 的 工作原理
HDFS 中的数据存储
- HDFS 将文件分割成固定大小的块(默认是 128MB 或 256MB),并将这些块分散存储在多个节点上。每个块可能会有多个副本(通常是 3 个),以确保数据的可靠性。
数据访问
- 当进行查询时,Hive 需要访问存储在 HDFS 上的这些数据块。为了执行查询,Hive 需要读取相应的数据块,并将它们加载到内存中进行处理。
3. 磁盘 I/O 在 HDFS 中的影响
3.1 数据读取
- 读取效率:HDFS 的设计旨在处理大文件的顺序访问,但在执行复杂查询时,如果查询涉及多个数据块,就需要频繁进行磁盘读取。
- 随机访问 vs 顺序访问:虽然 HDFS 优化了顺序访问,但对于随机读取操作,磁盘 I/O 会显著增加,因为每次读取都可能涉及不同的物理位置,导致寻址时间增加。
3.2 数据写入
- 写入操作:在将数据写入 HDFS 时,系统同样需要进行 I/O 操作。写入操作必须将数据写入到多个节点上(副本),这也会消耗 I/O 带宽。
- 数据块的分散写入:HDFS 将文件的每个块写入不同的节点,这个过程可能会导致额外的 I/O 开销。
4. 压缩优化原理
4.1 减少 I/O 负担
- 小数据量:通过压缩,读取的数据量减少,进而减少了所需的磁盘 I/O 操作。例如,读取一个 100MB 的压缩文件可能只需读取 20MB 的数据。
- 提高效率:减少 I/O 直接提高了查询的速度,因为磁盘读取的次数减少,CPU 等待数据的时间也降低。
4.2 列式查询
- 优化查询:列式存储格式使得 Hive 在执行查询时能够跳过不必要的列读取,只读取与查询相关的列数据。当查询只涉及几个列时,列式存储可以显著减少读取的数据量。
- 聚合和扫描:列格式通常对聚合和分析操作进行了优化,能加速这些操作的执行速度。
三、 Hive 的 MapReduce阶段优化
在使用Hive进行大数据处理时,合理优化Map和Reduce的执行是提高任务效率的关键。下文将详细介绍如何优化Map和Reduce,以提高Hive任务的性能。
1. 合理设置Map数量
-
影响因素:
- 输入文件的总数量和大小
- 集群设置的文件块大小
-
优化策略:
- 小文件过多时,每个文件会作为一个独立的Map任务,启动和初始化时间长,造成资源浪费。应尽量合并小文件以提高效率。
- 如果文件较大且任务复杂,可以通过调整
maxSize参数来增加Map任务数量,以减少每个Map处理的数据量,提高效率。
1.1 合并小文件(减少Map数量)
-
小文件过多弊端:
- HDFS上每个文件需要在NameNode创建元数据,占用内存空间,影响索引速度。
- 过多小文件会导致MapTask数量增加,单个MapTask处理数据量小,资源消耗大。
-
解决方案:
- 数据采集阶段合并小文件。
- 使用
CombineHiveInputFormat在Map执行前合并小文件。set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
1.2 调整maxSize参数(增加Map数量)
- 要调整
maxSize参数,可以在Hive的配置中设置以下属性:
SET mapreduce.input.fileinputformat.split.maxsize=<desired_size>;
注意:
maxSize参数指的是每个Map任务处理的数据块的最大大小。通过调整这个参数,可以控制Map任务的数量,但它并不直接指定Map任务的数量。- 将
maxSize设置为小于HDFS的块大小(blocksize),这样可以分割数据成更多块,每个块会启动一个Map任务。 - 通过设置较小的
maxSize,可以让输入数据分割成更多的块,从而增加Map任务的数量,减少每个Map处理的数据量。 - 例如,如果HDFS块大小是128MB,可以将
maxSize设置为64MB,这样会生成更多的Map任务,每个任务处理较少的数据量。
2. 合理设置Reduce数量
Reduce数量 = min(参数2, 总数据量/参数1)- 可以在
mapred-default.xml文件中设置参数2:<property><name>mapreduce.job.reduces</name><value>15</value> </property> - Reduce数量不宜过多,以免资源浪费。
3. 设置缓冲区大小
- 默认缓冲区为100M,可以提升至200M,减少溢写次数,提高效率。
4. 使用压缩技术
- 使用Snappy压缩减少磁盘I/O,提高性能。
5. 提高MapTask默认内存
- 默认内存为1024M,可以根据需要提升以处理更大的数据量。
6. 增加MapTask的CPU核数
- 对于计算密集型任务,增加CPU核数可以提升处理速度。
7. 增加Reduce阶段的并行度
- 默认从Map中拉取数据的并行数为5,可以适当提高。
8. 提高ReduceTask的内存上限
- 可以根据任务需要,适当提高内存上限。
9. 提高ReduceTask的CPU核数
- 根据任务的复杂程度,增加CPU核数以提升性能。
相关文章:
)
Hive优化操作(一)
Hive SQL 优化指南 在使用 Hive 进行数据分析时,提高查询性能至关重要。以下是一些具体的优化策略,帮助我们在工作中更有效地管理和查询数据。 一、 减少数据量进行优化 1. 分区表优化 分区是一种表的子集,用于按某一列(如日期…...
)
Vue中常用指令——(详解,并附有代码)
文章目录 一.指令合集1.0 概述1.1 插值表达式1.2 v-text/v-html1.3 v-show/ v-if1.4 v-on1.4.1 内联语句1.4.2 事件处理函数 1.5 v-bind1.6 Test1.7 v-for 一.指令合集 内容渲染指令(v-html、v-text)条件渲染指令(v-show、v-if、v-else、v-e…...

redistemplate实现点赞相关功能
使用Redis的SET数据结构来存储每个实体的点赞用户ID列表,方便进行点赞数量的计数和用户点赞状态的检查。以下是一个小demo,只提供简单思路。 Service public class LikeService {Autowiredprivate RedisTemplate redisTemplate;//点赞public Long like(…...

C++ 算法学习——7.4.1 优化算法——双指针
双指针法(Two Pointers)是一种常用的算法技巧,通常用于解决数组或链表中的问题。这种技巧通过维护两个指针,通常分别指向数组或链表的不同位置,来协同解决问题。双指针法一般有两种类型:快慢指针和左右指针…...
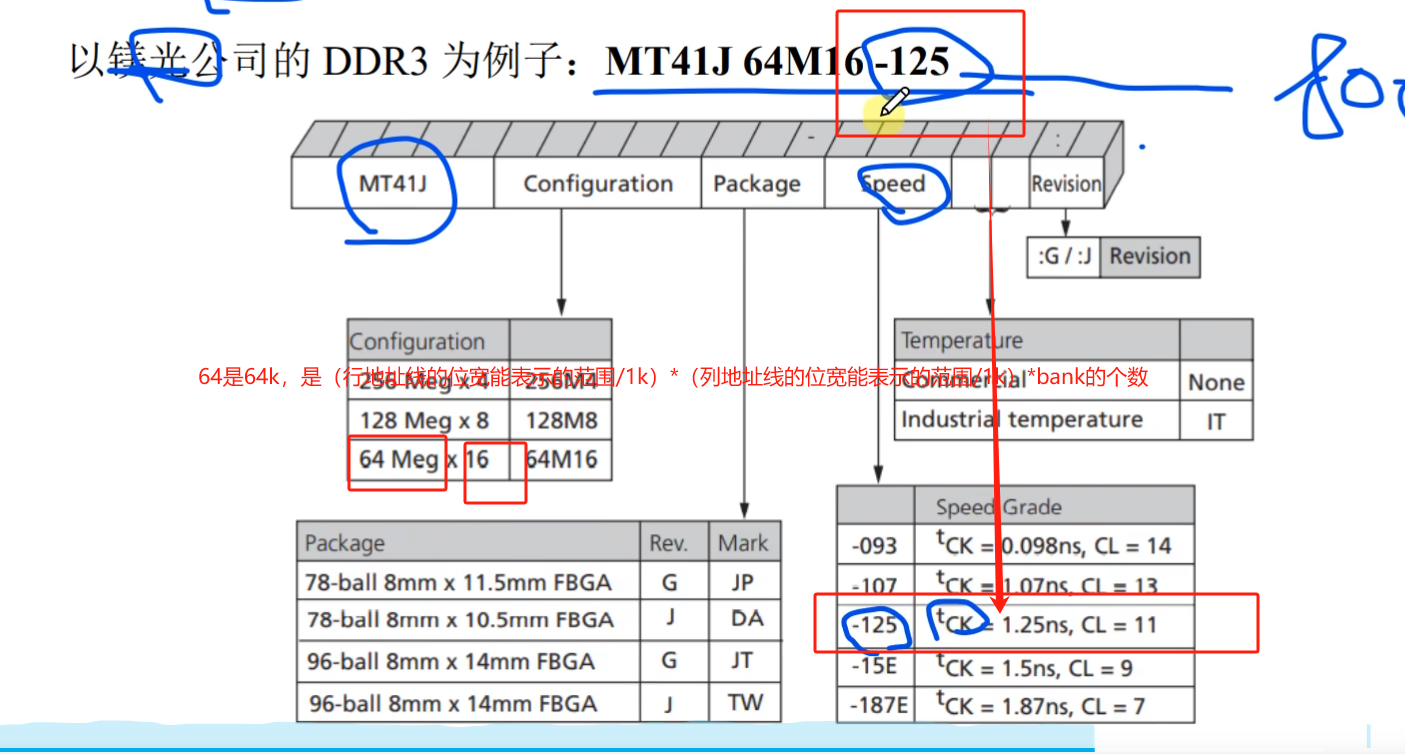
镁光DDR3的命名
64M16的解释如图。 125是指一个时钟周期需要1.25ns走完,1us对应 1MHZ, 1ns对应1000MHZ ,那么1.25ns对应的时钟频率,就先用 1/1.25得到 1.25us对应的时钟频率 0.8 ,然后再乘以1000,得到800就是MHZ 带宽的计算就是 800M…...

[Git] Git下载及使用 从入门到精通 详解(附下载链接)
前言 目录 Git概述 简介 下载 Git代码托管服务 Git常用命令 Git全局配置 获取Git仓库 在本地初始化一个Git仓库 从远程仓库克隆 基本概念 工作区文件状态 本地仓库操作 远程仓库操作 分支操作 标签操作 在IDEA中使用Git 在IDEA中配置Git 本地仓库操作 远程仓…...

Linux源码阅读笔记-USB驱动分析
基础层次详解 通用串行总线(USB)主要用于连接主机和外部设备(协调主机和设备之间的通讯),USB 设备不能主动向主机发送数据。USB 总线采用拓扑(树形),主机侧和设备侧的 USB 控制器&a…...

【超级详细解释】力扣每日一题 134.加油站 48. 旋转图像
134.加油站 力扣 这是一个很好的问题。这个思路其实基于一种贪心策略。我们从整个路径的油量变化来理解它,结合一个直观的“最低点法则”,来确保找到正确的起点。 问题的核心:油量差值的累积 对于每个加油站,我们有两个数组&…...

数据挖掘基本架构知识点
数据挖掘的基本架构主要包含以下几个部分: 一、数据获取 1. 数据源 - 可以是数据库(如关系型数据库MySQL、Oracle等)、文件系统(如CSV文件、XML文件等)、网络数据(如网页内容、社交媒体数据)等…...

LangChain中使用Prompt01
1.引入提示模板 from langchain.prompts import (SystemMessagePromptTemplate,AIMessagePromptTemplate,HumanMessagePromptTemplate, )2.设置系统提示 system_template_text"你是一位专业的翻译,能够将{input_language}翻译成{output_language},…...
如何使用bpmn-js实现可视化流程管理
介绍 BPMN-JS是一个流行的开源库,用于在Web应用程序中可视化、创建、编辑和分析BPMN(Business Process Model and Notation,业务流程建模与表示法)2.0 图。BPMN是一种国际标准的图形化语言,用于描述企业中的业务流程&a…...

【PostgreSQL 】实战篇——如何使用 EXPLAIN 和 ANALYZE 工具分析查询计划和性能,优化查询
在数据库管理中,优化查询性能是确保应用程序高效运行的关键因素之一。 随着数据量的不断增长和复杂查询的增多,理解查询的执行计划变得尤为重要。 PostgreSQL 提供了强大的工具 EXPLAIN 和 ANALYZE,帮助开发者分析查询计划和性能࿰…...

List、Map、Set 三个接口存取元素时,各有什么特点
List、Map、Set是Java集合框架中的三个核心接口,它们在存取元素时各自具有独特的特点。以下是对这三个接口存取元素特点的详细分析: List接口 有序性: List中的元素是有序的,它们按照插入的顺序进行排列。 可重复性:…...

掌握 ASP.NET Web 开发:从基础到身份验证
ASP.NET 是微软开发的一个功能强大的框架,广泛用于构建现代化的 Web 应用程序。它支持 MVC 架构、Web API、Razor 语法,并提供完善的身份验证与授权机制。本文将介绍 ASP.NET 的基础知识、MVC 模式、Web API 开发、Razor 语法,以及如何实现身…...

【C++图文并茂】01背包问题不会?超详细的详解,看完保证你会
大家好,今天 给大家讲解01背包问题 有N件物品和一个容量为V的背包。第i件物品的体积是c[i],价值是w[i] 。每件物品只能用一次,求解将哪些物品装入背包里物品价值总和最大。 01背包问题是典型的动态规划问题,我们拿葡萄矿泉水和西…...

SQL自学:什么是子查询,如何使用它们
在 SQL(Structured Query Language,结构化查询语言)的世界里,子查询是一种强大的工具,它允许我们在一个 SQL 查询内部嵌套另一个查询。子查询也被称为内部查询或嵌套查询,为我们提供了一种灵活且强大的方式…...

No.10 笔记 | PHP学习指南:PHP数组掌握
本指南为PHP开发者提供了一个全面而简洁的数组学习路径。从数组的基本概念到高级操作技巧,我们深入浅出地解析了PHP数组的方方面面。无论您是初学者还是寻求提升的中级开发者,这份指南都能帮助您更好地理解和运用PHP数组,提高编码效率和代码质…...

RS-232 串口通信和 RS-485 串口通信的区别
RS-232 串口通信和 RS-485 串口通信有以下区别: 1. 通信方式: RS-232:全双工通信方式,即数据的发送和接收可以同时进行。在全双工模式下,通信双方可以在同一时刻既发送数据又接收数据,就像两个人可以同时…...
:Kubernetes 安全机制之 RBAC)
【K8s】专题十四(1):Kubernetes 安全机制之 RBAC
本文内容均来自个人笔记并重新梳理,如有错误欢迎指正! 如果对您有帮助,烦请点赞、关注、转发、订阅专栏! 专栏订阅入口 | 精选文章 | Kubernetes | Docker | Linux | 羊毛资源 | 工具推荐 | 往期精彩文章 【Docker】(全网首发)Kylin V10 下 MySQL 容器内存占用异常的解决…...

8. 多态、匿名内部类、权限修饰符、Object类
文章目录 一、多态 -- 花木兰替父从军1. 情境2. 小结 二、匿名内部类三、权限修饰符四、Object -- 所有类的父类(包括我们自己定义的类)五、内容出处 一、多态 – 花木兰替父从军 1. 情境 我们现在新建两个类HuaMuLan和HuaHu。HuMuLan是HuaHu的女儿,所以她会有她父…...

B站缓存视频转换神器:3分钟让m4s文件重获新生的终极指南
B站缓存视频转换神器:3分钟让m4s文件重获新生的终极指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经为B站缓存视频无法…...
)
Python(while循环)
目录 1.while 循环的基本概念 1.1 语法格式 1.2 最简单的示例 1.3 while 与 for 的对比 2. 代码执行顺序详解 3. 无限循环及其控制 3.1 无限循环的基本写法 3.2 避免无限循环的常见错误 4. break、continue 与 else 4.1 break:提前终止整个循环 4.2 cont…...

3种高级策略突破AI编辑器限制:Cursor Pro逆向工程技术解析
3种高级策略突破AI编辑器限制:Cursor Pro逆向工程技术解析 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your…...

不只是F5隐写:一次CTF解题,带你深入理解ZIP伪加密的底层原理与手动修复
深入解析ZIP伪加密:从CTF实战到二进制手动修复 在CTF竞赛中,ZIP伪加密一直是Misc类题目的经典考点。不同于常规的加密破解,伪加密巧妙地利用了ZIP文件格式的设计特性,在不实际加密数据的情况下制造出需要密码的假象。本文将带您深…...
到底怎么玩)
别再只把JTAG当烧录器了!一文搞懂它的边界扫描(Boundary-Scan)到底怎么玩
解锁JTAG边界扫描的隐藏技能:从烧录到硬件诊断的全能玩法 在嵌入式开发领域,JTAG接口常被简化为"烧录工具"的代名词——这种认知偏差让我们错失了它最强大的能力。想象一下:当PCB上某个关键信号无法测量时,当BGA封装的芯…...

Linux网络数据包处理全流程:从系统调用到网卡驱动的深度解析
1. 项目概述:从代码到比特流的旅程如果你在Linux上写过网络程序,无论是用C的send()还是Python的socket.sendall(),你可能都曾好奇过:我调用完这个函数之后,数据到底经历了什么才变成网线上的电信号?反过来&…...

诺丽果汁终极选购指南——五大品牌全维度对比
我们聊过挑选诺丽果汁需要“看出身、看真材、看底牌”三大原则。今天,我们把这套标准真正落到实处,对市场上最具代表性的五个品牌——艾多美、美商大溪地、可可椰、美乐家、合百诺丽进行全维度对比,帮你看清每家的真实水平。快速结论放在最前…...

从标签页混乱到高效工作流:Tabee如何彻底改变我的浏览器体验
从标签页混乱到高效工作流:Tabee如何彻底改变我的浏览器体验 【免费下载链接】chrome-tab-modifier Take control of your tabs 项目地址: https://gitcode.com/gh_mirrors/ch/chrome-tab-modifier 你是否曾经在几十个标签页中迷失方向?每个标签页…...
)
不止图表引用!VSCode+LaTeX完整编译链配置指南(含BibTeX文献处理)
VSCodeLaTeX高效工作流:从交叉引用到文献管理的全栈配置指南 当你第一次在VSCode中尝试用LaTeX撰写学术论文时,是否曾被那些顽固的"??"标记困扰?这些问号背后隐藏着LaTeX编译机制的核心逻辑——交叉引用需要多轮编译才能正确解析…...

RK3566安卓11开发板千兆网卡RTL8211F移植避坑指南:从原理图到DTS配置全流程
RK3566安卓11平台RTL8211F千兆网卡移植实战:硬件原理到DTS配置的深度解析 当开发者需要在RK3566安卓11平台上实现千兆以太网功能时,RTL8211F PHY芯片的移植往往成为关键挑战。不同于简单的驱动加载,实际项目中常会遇到"软件配置看似正常…...