Python 网络爬虫高阶用法
网络爬虫成为了自动化数据抓取的核心工具。Python 拥有强大的第三方库支持,在网络爬虫领域的应用尤为广泛。本文将深入探讨 Python 网络爬虫的高阶用法,包括处理反爬虫机制、动态网页抓取、分布式爬虫以及并发和异步爬虫等技术。以下内容结合最新技术发展,旨在帮助读者掌握高级 Python 爬虫技术。
目录
- 常用 Python 爬虫工具回顾
- 动态网页数据抓取
- 反爬虫机制与应对策略
- Scrapy 高级应用
- 分布式爬虫与异步爬虫
- 爬虫数据存储与处理
- 实战案例:电商商品数据抓取
1. 常用 Python 爬虫工具回顾
1.1 Requests 和 BeautifulSoup
Requests 和 BeautifulSoup 是 Python 中常用的组合,用于抓取和解析静态网页。Requests 处理 HTTP 请求,而 BeautifulSoup 则解析 HTML 内容。
import requests
from bs4 import BeautifulSoup# 发起 HTTP 请求
response = requests.get('https://example.com')
# 解析 HTML 内容
soup = BeautifulSoup(response.text, 'html.parser')# 提取特定元素
title = soup.find('title').text
print(title)
1.2 Scrapy
Scrapy 是一个功能强大的爬虫框架,适合大型项目和需要高效抓取的场景。Scrapy 提供了完善的爬虫流程,支持异步抓取、数据存储等功能。
# 爬虫示例代码,需在 Scrapy 项目中使用
import scrapyclass ExampleSpider(scrapy.Spider):name = 'example'start_urls = ['https://example.com']def parse(self, response):title = response.css('title::text').get()yield {'title': title}
2. 动态网页数据抓取
动态网页中的数据通常由 JavaScript 渲染,传统的爬虫工具无法直接获取。这时可以使用 Selenium 或 Pyppeteer 等工具来抓取动态网页。
2.1 Selenium 动态抓取
Selenium 模拟浏览器行为,加载并渲染动态网页,适合处理复杂的交互页面。
from selenium import webdriver# 初始化 WebDriver
driver = webdriver.Chrome()# 打开动态网页
driver.get('https://example.com')# 等待页面完全加载
driver.implicitly_wait(5)# 获取网页源代码
html = driver.page_source# 关闭浏览器
driver.quit()
2.2 Pyppeteer 动态抓取
Pyppeteer 是 Puppeteer 的 Python 版本,使用无头浏览器抓取动态页面,适合需要高效抓取的场景。
import asyncio
from pyppeteer import launchasync def main():browser = await launch()page = await browser.newPage()await page.goto('https://example.com')content = await page.content()print(content)await browser.close()asyncio.get_event_loop().run_until_complete(main())
3. 反爬虫机制与应对策略
为了防止数据滥用,许多网站引入了反爬虫机制。常见的反爬虫手段包括 IP 封禁、请求频率限制、验证码等。为了应对这些机制,可以采取以下策略:
3.1 模拟用户行为
通过调整请求头信息和行为模式,可以模拟真实用户的操作,从而绕过反爬虫机制。
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}response = requests.get('https://example.com', headers=headers)
3.2 使用代理池
使用代理 IP 来隐藏爬虫的真实 IP,避免被封禁。可以通过轮换多个代理来规避封锁。
proxies = {'http': 'http://10.10.1.10:3128','https': 'http://10.10.1.10:1080',
}response = requests.get('https://example.com', proxies=proxies)
3.3 Cookie 和 Session 处理
为了保持登录状态或模拟用户交互,爬虫需要处理 Cookie 和 Session。Requests 库提供了会话保持功能。
# 使用会话保持
session = requests.Session()# 设置初始的 cookie
session.cookies.set('name', 'value')# 发送带有 cookie 的请求
response = session.get('https://example.com')
4. Scrapy 高级应用
Scrapy 框架不仅支持基本的爬虫功能,还可以通过中间件、pipeline 等机制扩展功能。
4.1 数据存储与处理
Scrapy 提供了多种数据存储方式,支持将抓取到的数据直接保存到数据库或文件中。
# pipelines.py 示例
import pymongoclass MongoPipeline:def open_spider(self, spider):self.client = pymongo.MongoClient("mongodb://localhost:27017/")self.db = self.client["example_db"]def close_spider(self, spider):self.client.close()def process_item(self, item, spider):self.db.example_collection.insert_one(dict(item))return item
4.2 分布式爬虫
对于大型项目,分布式爬虫可以显著提升爬取速度和效率。Scrapy 可以结合 Redis 实现分布式爬取。
# 在 Scrapy 项目中使用 scrapy-redis 进行分布式爬虫
# 安装 scrapy-redis 并配置 settings.py
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
5. 分布式爬虫与异步爬虫
为了提升抓取效率,分布式和异步爬虫是非常重要的技术。Python 提供了 asyncio 和 aiohttp 等异步库,能够有效提高并发抓取能力。
5.1 asyncio 与 aiohttp
asyncio 与 aiohttp 是 Python 的异步编程库,支持并发执行多个网络请求。
import asyncio
import aiohttpasync def fetch(session, url):async with session.get(url) as response:return await response.text()async def main():async with aiohttp.ClientSession() as session:html = await fetch(session, 'https://example.com')print(html)asyncio.run(main())
5.2 多线程与多进程
对于 CPU 密集型任务,可以使用 Python 的 concurrent.futures 库来实现多线程和多进程并发。
from concurrent.futures import ThreadPoolExecutordef fetch(url):response = requests.get(url)return response.textwith ThreadPoolExecutor(max_workers=5) as executor:results = executor.map(fetch, ['https://example.com'] * 5)for result in results:print(result)
6. 爬虫数据存储与处理
在爬虫抓取到大量数据后,需要有效地存储和处理。常见的存储方式包括数据库存储和文件存储。
6.1 数据库存储
可以将爬虫数据存储到关系型数据库(如 MySQL)或非关系型数据库(如 MongoDB)。
import pymysql# 连接 MySQL 数据库
connection = pymysql.connect(host='localhost',user='user',password='passwd',db='database')# 插入数据
with connection.cursor() as cursor:sql = "INSERT INTO `table` (`column1`, `column2`) VALUES (%s, %s)"cursor.execute(sql, ('value1', 'value2'))connection.commit()
6.2 文件存储
对于小规模的数据,可以直接将数据存储为 CSV 或 JSON 格式文件。
import csv# 写入 CSV 文件
with open('data.csv', mode='w') as file:writer = csv.writer(file)writer.writerow(['column1', 'column2'])writer.writerow(['value1', 'value2'])
7. 实战案例:电商网站商品数据抓取
在实际项目中,爬虫常用于抓取电商网站的商品信息。以下为一个简单的商品数据抓取流程:
- 使用
Requests获取商品列表页面。 - 使用
BeautifulSoup解析 HTML,提取商品信息。 - 将数据存储到 CSV 文件中。
import requests
from bs4 import BeautifulSoup
import csv# 发送 HTTP 请求
response = requests.get('https://example.com/products')# 解析 HTML 内容
soup = BeautifulSoup(response.text, 'html.parser')# 提取商品信息
products = soup.find_all('div', class_='product')# 写入 CSV 文件
with open('products.csv', mode='w') as file:writer = csv.writer(file)writer.writerow(['Product Name', 'Price'])for product in products:name = product.find('h2').textprice = product.find('span', class_='price').textwriter.writerow([name, price])
结语
通过学习本文的内容,读者应掌握 Python 网络爬虫的高级用法,并能够应对反爬虫机制、抓取动态网页、实现分布式和异步爬虫。网络爬虫技术在数据抓取、信息采集等方面有着广泛的应用,掌握这些技能将大大提升数据处理和分析的效率。
相关文章:

Python 网络爬虫高阶用法
网络爬虫成为了自动化数据抓取的核心工具。Python 拥有强大的第三方库支持,在网络爬虫领域的应用尤为广泛。本文将深入探讨 Python 网络爬虫的高阶用法,包括处理反爬虫机制、动态网页抓取、分布式爬虫以及并发和异步爬虫等技术。以下内容结合最新技术发展…...
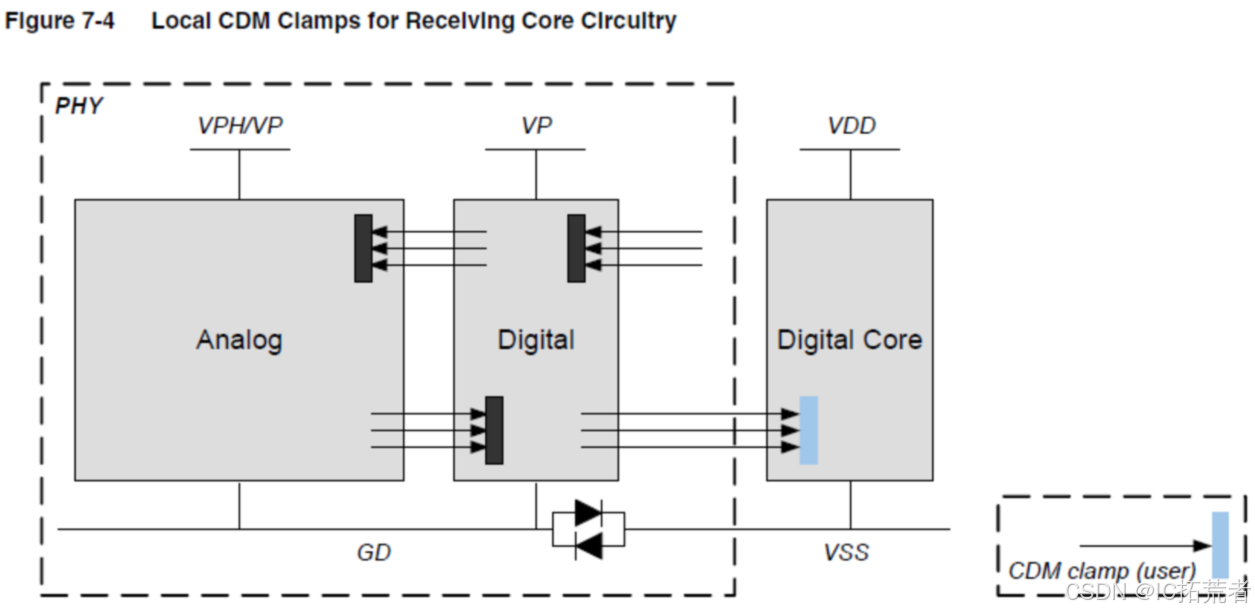
芯片Tapeout前GDS Review | Calibre中如何切出gds中指定区域版图?
在SoC芯片实现阶段我们会用到很多模拟IP,IO。对于这类模拟IP相关的电源连接,ESD保护电路连接,信号线连接都需要跟IP Vendor进行Review。但芯片整体版图涉及商业机密,我们不希望整个芯片的版图被各大vendor看到,因此我们…...
:如何设计实现一个集群环境下的分布式单例模式?)
43 | 单例模式(下):如何设计实现一个集群环境下的分布式单例模式?
上两篇文章中,我们针对单例模式,讲解了单例的应用场景、几种常见的代码实现和存在的问题,并粗略给出了替换单例模式的方法,比如工厂模式、IOC 容器。今天,我们再进一步扩展延伸一下,一块讨论一下下面这几个…...

PHP如何解决异常处理
在PHP中,异常处理是通过使用try、catch、throw以及finally这几个关键字来实现的。以下是一个简单的介绍和示例: 异常处理的基本步骤 抛出异常: 使用throw关键字抛出一个异常对象。异常对象通常是Exception类或其子类的实例。 捕获异常&…...
)
C++ socket编程(3)
前面文章,介绍了一个简单socket通讯Demo, 客户端和服务器进行简单的交互。两个代码都很简单,如果情况一复杂,就会出错。这节我们把代码完善一下,实现一个客户端输入,发送,服务器echo的交互。本文…...
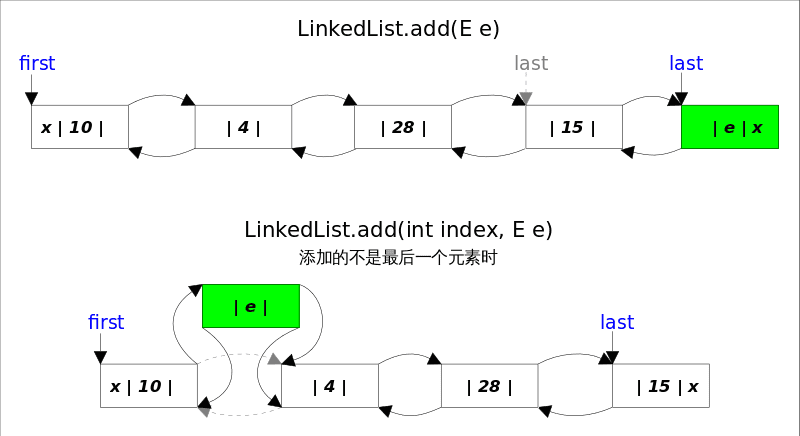
Collection-LinkedList源码解析
文章目录 概述LinkedList实现底层数据结构构造函数getFirst(), getLast()removeFirst(), removeLast(), remove(e), remove(index)add()addAll()clear()Positional Access 方法查找操作 概述 LinkedList同时实现了List接口和Deque接口,也就是说它既可以看作一个顺序…...

vue判断对象数组里是否有重复数据
TOCvue判断对象数组里是否有重复数据 try {//通过产品编码赛选出新的数组 在比较let names this.goodsJson.map(item > item["productCode"]);let nameSet new Set(names)if (nameSet.size ! names.length) {this.$message({message: 警告!产品选项…...

CSS 3D转换
在 CSS 中,除了可以对页面中的元素进行 2D 转换外,您也可以对象元素进行 3D转换(将页面看作是一个三维空间来对页面中的元素进行移动、旋转、缩放和倾斜等操作)。与 2D 转换相同,3D 转换同样不会影响周围的元素&#x…...

51单片机数码管循环显示0~f
原理图: #include <reg52.h>sbit dulaP2^6;//段选信号 sbit welaP2^7;//位选信号unsigned char num;//数码管显示的数字0~funsigned char code table[]{ 0x3f,0x06,0x5b,0x4f, 0x66,0x6d,0x7d,0x07, 0x7f,0x6f,0x77,0x7c, 0x39,0x5e,0x79,0x71};//定义数码管显…...

【编程进阶知识】Java NIO:掌握高效的I/O多路复用技术
Java NIO:掌握高效的I/O多路复用技术 摘要: 本文将带你深入了解Java NIO(New I/O)中的Selector类,探索如何利用它实现高效的I/O多路复用,类似于Linux中的select和epoll系统调用。文章将提供详细的代码示例…...

vscode创建flutter项目,运行flutter项目
打开View(查看) > Command Palette...(命令面板)。 可以按下 Ctrl / Cmd Shift P 输入 flutter 选择Flutter: New Project 命令 按下 Enter 。选择Application 选择项目地址 输入项目名称 。按下 Enter 等待项目初始化完成 …...

STM32之CAN外设
相信大家在学习STM32系列的单片机时,在翻阅芯片的数据手册时,都会看到这么一个寄存器外设——CAN外设寄存器。那么,大家知道这个外设的工作原理以及该如何使用吗?这节的内容将会详细介绍STM32上的CAN外设,文章结尾附有…...

【阅读笔记】水果轻微损伤的无损检测技术应用
一、水果轻微损伤检测技术以及应用 无损检测技术顾名思义就是指在不破坏水果样品完整性的情况下对样品进行品质鉴定。目前比较常用的农产品水果类无损检测法有:基于红外热成像、机器视觉技术的图像处理方法、光谱检测技术、介电特性技术检测法等。 1.1 基于红外热…...
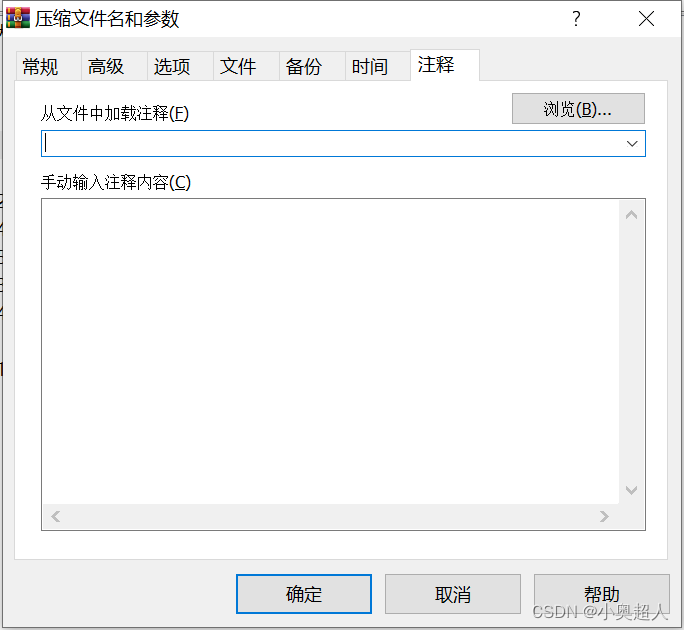
忘记7-zip密码,如何解压文件?
7z压缩包设置了密码,解压的时候就需要输入正确对密码才能顺利解压出文件,正常当我们解压文件或者删除密码的时候,虽然方法多,但是都需要输入正确的密码才能完成。忘记密码就无法进行操作。 那么,忘记了7z压缩包的密码…...
)
SpringBoot基础(一)
1.SpringBoot简介 Spring Boot是Spring社区发布的一个开源项目,旨在帮助开发者快速并且更简单的构建项目。它 使用习惯优于配置的理念让你的项目快速运行起来,使用Spring Boot很容易创建一个独立运行 (运行jar,内置Servlet容器&am…...

Java智能匹配灵活用工高效人力资源管理系统小程序源码
智能匹配灵活用工高效人力资源管理系统 💼🚀 🚀 开篇:职场新风尚,智能匹配引领变革 在这个瞬息万变的时代,职场也在经历着前所未有的变革。传统的用工模式已难以满足现代企业的需求,而“智能匹…...
openpdf
1、简介 2、示例 2.1 引入依赖 <dependency><groupId>com.github.librepdf</groupId><artifactId>openpdf</artifactId><version>1.3.34</version></dependency><dependency><groupId>com.github.librepdf</…...

C#垃圾回收机制详解
本文详解C#垃圾回收机制。 目录 一、C#垃圾收集器定义 二、C#中的垃圾收集器特点 三、垃圾回收触发条件 四、常见的内存泄漏情况 五、高性能应用程序的垃圾回收策略 六、最佳实践和建议 七、实例 一、C#垃圾收集器定义 int、string变量,这些数据都存储在内存中,如果…...

身份证二要素核验操作指南
身份证二要素核验主要涉及验证身份证上的姓名和身份证号码这两个关键信息,以下是详细的操作指南: 一、核验流程 输入信息:用户在客户端(如APP、网站等)输入自己的姓名和身份证号码。 信息加密与传输:客户端…...
量子数字签名概述
我们都知道,基于量子力学原理研究密钥生成和使用的学科称为量子密码学。其内容包括了量子密钥分发、量子秘密共享、量子指纹识别、量子比特承诺、量子货币、秘密通信扩展量子密钥、量子安全计算、量子数字签名、量子隐性传态等。虽然各种技术发展的状态不同…...

国产多模态大模型:产业协同全景与实战指南
国产多模态大模型:产业协同全景与实战指南 引言 在人工智能浪潮席卷全球的背景下,国产多模态大模型正从技术探索迈向广泛的产业协同应用。与只能处理文本或图像的单一模态模型相比,多模态大模型能同时理解、关联和生成文本、图像、音频、视频…...

乡村智慧民宿系统|提质增收!巨有科技打造乡村旅居新模式
乡村旅居、民宿康养已经成为乡村文旅主流消费趋势。但大量乡村民宿依旧处于散户经营状态,预定混乱、管控松散、对账困难、同质化严重。巨有科技贴合乡村民宿分散、小规模、本土化的特点,搭建智慧民宿管理系统,用数字化手段规范经营、优化体验…...

CNC木质树莓派外壳制作:从设计到加工的全流程实践
1. 项目概述:当数字制造遇上经典木艺 给树莓派找个“家”,这事儿我干过不少。从3D打印的塑料壳到亚克力板拼的“鱼缸”,总觉得差点意思。塑料感太强,亚克力又显得冰冷。直到有一次在工作室里看到一块边角料的硬枫木,纹…...

用Python实现编译器前端:从Kaleidoscope到LLVM IR的实践指南
1. 项目概述:从“玩具”到“宝藏”的编译器学习之旅如果你对编译原理这门计算机科学的“硬核”课程感到既敬畏又头疼,觉得那些词法分析、语法树、中间代码优化等概念如同天书,那么你很可能已经尝试过一些经典的“龙书”配套项目,比…...

可定制尺寸的工业烤盘公司
江苏台烁是专注为大中型食品生产企业提供可定制尺寸全品类工业烤盘的专业厂商,核心竞争优势为全尺寸高精度定制能力搭配智能生产体系,可提供节能耐用、适配产线的工业化烘焙器具解决方案。核心优势与关键数据生产与资质基础:拥有4.8万㎡智能工…...

电容触摸传感与微控制器互动:打造万圣节智能蝙蝠装饰
1. 项目概述:当电容触摸遇上万圣节蝙蝠又到了一年一度可以名正言顺“吓唬人”的季节。每年万圣节,除了南瓜灯和糖果,我总想搞点不一样的、能和人互动的装饰。市面上的那些一动就吱呀乱叫的塑料道具,总觉得少了点灵魂和“技术含量”…...

别再为485传感器没文档发愁了!一个USB转485模块+两款免费软件,5分钟搞定Modbus通信测试
5分钟极简方案:用USB转485模块与开源工具破解Modbus传感器通信 当你拿到一个没有文档的485温湿度传感器时,是否曾为如何读取数据而头疼?本文将分享一套经过实战验证的极简工具组合——仅需一个常见的USB转485转换器和两款免费软件,…...

CircuitFusion:多模态AI在集成电路设计中的革命性应用
1. 集成电路设计的多模态革命:CircuitFusion技术解析在AI芯片设计领域,一个令人头疼的现实是:随着芯片复杂度呈指数级增长,传统设计流程已难以应对。以7nm工艺节点为例,单个芯片可能包含数十亿个晶体管,设计…...

别再死记硬背了!PADS Logic/Layout/Router这三个界面,到底该怎么分工协作?
PADS三剑客协作指南:从原理图到PCB的高效设计流 在电子设计自动化(EDA)领域,Mentor Graphics(现为Siemens EDA)的PADS系列工具以其专业性和高效性著称。然而,许多初学者常陷入一个误区——将PAD…...
)
软考高级之系统架构师之系统安全性和保密性设计(二)
认证 PKI/CA 参考PKI/CA体系介绍。 Kerberos Kerberos是一种网络认证协议,其设计目标是通过密钥系统为客户机/服务器应用程序提供强大的认证服务。该认证过程的实现不依赖于主机操作系统的认证,无需基于主机地址的信任,不要求网络上所有主…...