SparkSQL介绍及使用
SparkSQL介绍及使用
一、什么是SparkSQL(了解)
spark开发时可以使用rdd进行开发,spark还提供saprksql工具,将数据转为结构化数据进行操作
1-1 介绍
官网:https://spark.apache.org/sql/
Spark SQL是 Apache Spark 用于处理结构化数据(DataFrame和Datasets)的模块。
在Spark1.0版本时引入了SparkSQL
数据的结构形式
- 结构化数据
- 表,DataFrame,Datasets
- 构成
- 元数据 描述数据的数据(描述信息,类型约束)
- 数据本身
| 身高 int |
|---|
| 179 |
| 170 |
| 156 |
| 132 |
| 200 |
-
半结构化数据
-
json,xml ,有数据的描述信息,但是对数据内容的类型无法约束
-
{"name":"asdea" }
-
-
非结构化数据
- 文本文件
- 图片文件
- 视频文件
- 音频文件
sparksql可以将非结构化 ,半结构化数据统一转化为结构化数据处理
Spark中使用的结构化数据有 DataFrame ,映射表(离线数仓开发使用)
1-2 特点
- 易整合
- 使用sql配合spark一起使用,封装了不同语言的dsl方法
- 统一数据访问
- 使用read方法可以读取hdfs数据,mysql数据,不同类型的文件数据(json,csv,orc)
- 使用write方法可以写入hdfs,mysql不同类型的文件
- 兼容hive
- 使用hivesql方法
- 标准的数据连接
- 使用jdbc和odbc连接方式连接sparkSQL
1-3 SparkSQL与HiveSQL关系
- shark
- 运行的模式是hive on spark
- 会将hivesqsl转换为spark的rdd
- shark是基于hive开发的,维护麻烦,2015年停止维护
- sparkSQL
- 是spark团建独立开发的工具,2014年发布1.0版本
- sparkSQL工具对spark的兼容性更好,优化性能得到提升
- sparkSQL本质也是将sql语句转化为rdd执行,catalyst引擎负责将sql转化为rdd
- sparkSQL可以连接使用hive的metastore服务,管理表的元数据
二、DataFrame详解(理解)
DataFrame是基于RDD进行封装的结构化数据类型,增加了scheme元数据
其中DataFrame类型在计算时,还是转为rdd计算
DataFrame的结构化数据有Row(行数据)和scheme元数据构成
- Row 类型 表示一行数据
- datafram就算是多行构成
# 导入行类Row
from pyspark.sql import Row# 创建行数据
r1 = Row(1, '张三', 20)# 行数取取值 按照下标取值
data = r1[0]
print(data)
data1 = r1[1]
print(data1)# 指定字段创建行数据
r2 = Row(id=2, name='李四', age=22)
# 按照字段取值
data3 = r2['id']
print(data3)
data4 = r2['name']
print(data4)
- schema表信息
- 定义dataframe中的表的字段名和字段类型
# 导入数据类型
from pyspark.sql.types import *# 定义schema信息
# 使用StructType类进行定义
# add()方法是指定字段信息
# 第一参数,字段名
# 第二个参数,字段信息
# 第三个参数是否允许为空值 默认是True,允许为空
schema_type = StructType().\add('id',IntegerType()).\add('name',StringType()).\add('age',IntegerType(),False)
三、DataFrame创建(掌握)
创建datafram数据
需要使用一个sparksession的类创建
SparkSession类是在SparkContext的基础上进行了封装,也就是SparkSession类中包含了SparkContext
3-1 基本创建
# 导入行类Row
from pyspark.sql import SparkSession, Row
from pyspark.sql.types import *# 创建行数据
r1 = Row(id=1, name='张三', age=20)
r2 = Row(id=2, name='李四', age=22)
# 创建元数据
schema = StructType(). \add('id', IntegerType()). \add('name', StringType()). \add('age', IntegerType())# 创建dataframe
# 生成sparksession对象 按照固定写法创建
ss = SparkSession.builder.getOrCreate()
# 使用sparksession对象方法创建df
# createDataFrame 第一参数是一个列表数据,将每行数据放入列表
# 第二个参数指定表元数据信息
# df是一个dataframe类型的对象
df = ss.createDataFrame([r1, r2], schema=schema)# dataframe数据的操作
# 查看df数据
df.show() # 查看所有数据,超过20行时,默认只显示20行
# 查看元信息
df.printSchema()3-2 RDD和DF之间的转化
- rdd的二维数据转化为dataframe
- rdd.toDF()
# RDD和DF之间的转换
# 导入SparkSession
from pyspark.sql import SparkSession# 创建对象
ss = SparkSession.builder.getOrCreate()# 使用sparksession获取sparkcontext
sc = ss.sparkContext # 不要括号,可以直接获取到sparkcontext对象# 生成rdd数据
# rdd转df时,要求数据是二维嵌套列表
data = [[1,'张三',20,'男'],[2,'小红',19,'女']]
rdd = sc.parallelize(data)# rdd转df
df = rdd.toDF(schema='id int,name string,age int,gender string')# 查看df数据
df.show()# 查看表结构
df.printSchema()
- df转为rdd
# 将df转为rdd
rdd2 = df.rdd
# 查看rdd中数据
res = rdd2.collect() # [Row(),Row()]
# 转化后的rdd中每个元素是有个Row类对象
print(res)
print(res[0])
print(res[0]['name'])
3-3 pandas和spark之间转化
pandas和spark之间的df相互转化
- pandas的df转为spark的df
# Pandas和spark之间的转化
import pandas as pd
from pyspark.sql import SparkSession
# 创建pd的df
pd_df = pd.DataFrame({'id':[1,2,3,4],'name':['a','b','c','d'],'age':[20,21,22,24],'gender':['男','女','男','男']}
)
# 查看数据
print(pd_df)# 将pd_df 转为spark的df
ss = SparkSession.builder.getOrCreate()
spark_df = ss.createDataFrame(pd_df)# 查看数据
spark_df.show()
- spark的df转为pandas的df
- toPandas
# 将spark_df转为pd_df
pd_df2 = spark_df.toPandas()
print(pd_df2)
3-4 读取文件数据转为df
通过read方法读取数据转为df
- ss.read
# 读取数据转化为df
from pyspark.sql import SparkSession# 创建sparksession
ss = SparkSession.builder.getOrCreate()# 读取不同数据源
# header=True 是否需要获取表头
# sep 指定数据字段按照什么字符分割
df = ss.read.csv('hdfs://node1:8020/data/students.csv',header=True,sep=',')
# schema当没有表头时,可以自己指定字段
df2 = ss.read.csv('hdfs://node1:8020/data/students.csv',header=False,sep=',',schema='user_id string,username string,sex string,age string,cls string')df3 = ss.read.json('hdfs://node1:8020/data/employees.json')
df4 = ss.read.orc('hdfs://node1:8020/data/users.orc')
df5 = ss.read.parquet('hdfs://node1:8020/data/users.parquet')# 查看
# show中可以指定显示多少行,默认是20行
df.show(100)df2.show()
四、DataFrame基本使用(掌握)
4-1 SQL语句
使用sparksession提供的sql方法,编写sql语句执行
# 使用sql方式开发
from pyspark.sql import SparkSessionss = SparkSession.builder.getOrCreate()# 读取数据得到df数据
df = ss.read.csv('hdfs://node1:8020/data/students.csv',header=True,sep=',',schema='id string,name string,gender string,age int,cls string')# 对df数据进行sql操作
# 需要给df指定一个表名
df.createTempView('tb_user')# 编写sql语句执行
# sql执行后的结果被保存新的df中
new_df = ss.sql('select gender,avg(age) as avg_data from tb_user group by gender')
new_df.show()4-2 DSL方法
DSL方法是df提供的数据操作函数
使用方式
df.方法()
可以进行链式调用
df.方法().方法().方法()
方法执行后返回一个新的df保存计算结果
new_df = df.方法()
spark提供DSL方法和sql的关键词一样,使用方式和sql基本类似,在进行数据处理时,要按照sql的执行顺序去思考如何处理数据
from join 知道数据在哪 df本身就是要处理的数据 df.join(df2) from 表
where 过滤需要处理的数据 df.join(df2).where()
group by 聚合 数据的计算 df.join(df2).where().groupby().sum()
having 计算后的数据进行过滤 df.join(df2).where().groupby().sum().where()
select 展示数据的字段 df.join(df2).where().groupby().sum().where().select()
order by 展示数据的排序 df.join(df2).where().groupby().sum().where().select().orderBy()
limit 展示数据的数量 df.join(df2).where().groupby().sum().where().select().orderBy().limit()
DSL方法执行完成后会得到一个处理后的新的df
# 使用DSL方式开发
from pyspark.sql import SparkSessionss = SparkSession.builder.getOrCreate()# 生成df
df = ss.read.csv('hdfs://node1:8020/data/students.csv',header=True,sep=',',schema='id string,name string,gender string,age int,cls string')
# 查看df数据
df.show()print('---------------select方法----------------------')
# 使用select方法指定输出展示的数据字段
# 方式一指定字段
df_select = df.select('id','name')
# 方式二
df_select2 = df.select(df.age,df.gender)
# 方式三
df_select3 = df.select(df['id'],df['cls'])df_select.show()
df_select2.show()
df_select3.show()print('---------------alias方法----------------------')
# 字段名称修改,需要配合select中使用
df_alias = df.select(df.id.alias('user_id'),df.name.alias('username'))
df_alias.show()print('---------------cast方法----------------------')
# 修改字段的数据类型
df.printSchema()
df_cast = df.select(df.id.cast('int'),df.name,df.age)
df_cast.printSchema()print('---------------where方法----------------------')
# 数据过滤,where方法内部是调用了filter方法
# 方式1
df_where = df.where('age > 20')
df_where.show()
#方式2
df_where2 = df.where(df.age > 20)
df_where2.show()# 与或非多条件 只能使用方式1 条件的书写和在sql中的where书写内容一样
df_where3 = df.where('age > 20 and gender = "男" ')
df_where3.show()print('---------------groupby方法----------------------')
# 分组计算,可以配和聚合方法一起使用 使用该方式聚合一次只能计算一个聚合数据 ,可以使用内置函数配合agg方法
# groupby指定分组字段,可以指定多个
# avg 聚合方法 指定聚合字段 sum count avg max min
df_groupby = df.groupby('gender').avg('age')
df_groupby.show()# groupby指定分组字段,可以指定多个
df_groupby2 = df.groupby('gender','cls').avg('age')
df_groupby2.show()# 分组后的数据过滤
df_groupby3 = df.groupby('gender','cls').avg('age').where(' avg(age) > 19')
df_groupby3.show()print('---------------orderby方法----------------------')
# 数据排序 内部调用sort方法
df_orderby = df.orderBy('age')
df_orderby.show()
# ascending=False 降序
df_orderby2 = df.orderBy('age',ascending=False)
df_orderby2.show()print('---------------limit方法----------------------')
# 指定获取多条数据
df_limit = df.orderBy('age',ascending=False).limit(5)df_limit.show()五、数据的关联与和并[掌握]
5-1 join关联
- 内关联
- 左关联
- 右关联
from pyspark.sql import SparkSessionss =SparkSession.builder.getOrCreate()# 读取文件数据
df1 = ss.read.csv('hdfs://node1:8020/data/students.csv',header=True,sep=',',schema='user_id string,username string,sex string,age string,cls string')
df2 = ss.read.csv('hdfs://node1:8020/data/students2.csv',header=False,sep=',',schema='user_id string,username string,sex string,age string,cls string')# 两表进行关联
# 内关联 第一个参数,关联的df 第二参数 关联字段 第三个参数 关联方式 默认inner
df_join = df1.join(df2,df1.user_id == df2.user_id)
df_join2 = df1.join(df2,'user_id')
# 左关联
df_left= df1.join(df2,'user_id','left')
# 右关联
df_right = df1.join(df2,'user_id','right')# show查看数据
df1.show()
df2.show()
df_join.show()
df_join2.show()
print('---------------------------------')
df_left.show()
df_right.show()
5-2 Union合并
from pyspark.sql import SparkSessionss =SparkSession.builder.getOrCreate()# 读取文件数据
df1 = ss.read.csv('hdfs://node1:8020/data/students.csv',header=True,sep=',',schema='user_id string,username string,sex string,age string,cls string')
df2 = ss.read.csv('hdfs://node1:8020/data/students2.csv',header=False,sep=',',schema='user_id string,username string,sex string,age string,cls string')# 两表进行关联 合并后不会去重
df_union = df1.union(df2)df_unionAll = df1.unionAll(df2)# 合并后的数据去重
df_distinct = df_union.distinct().orderBy('user_id')# 查看数据
df_union.show(100)
print('****************************************************************')
df_unionAll.show(100)
print('****************************************************************')
df_distinct.show(100)
六、缓存和checkpoint[了解]
# df的数据持久化
from pyspark.sql import SparkSessionss = SparkSession.builder.getOrCreate()# 指定checkpoint的位置
sc = ss.sparkContext # 或sparkcontext对象
sc.setCheckpointDir('hdfs://node1:8020/df_checkpoint')# 读取文件数据
df1 = ss.read.csv('hdfs://node1:8020/data/students.csv',header=True,sep=',',schema='user_id string,username string,sex string,age int,cls string')
# 缓存 通过缓存级别指定缓存位置 默认是内存和磁盘上
# df1.persist()
# 使用checkpoint
df1.checkpoint()df1_sum = df1.groupby('sex').sum('age')#查看计算结果
df1_sum.show()
相关文章:

SparkSQL介绍及使用
SparkSQL介绍及使用 一、什么是SparkSQL(了解) spark开发时可以使用rdd进行开发,spark还提供saprksql工具,将数据转为结构化数据进行操作 1-1 介绍 官网:https://spark.apache.org/sql/ Spark SQL是 Apache Spark 用于…...

【聚星文社】3.2版一键推文工具更新啦
【聚星文社】3.2版一键推文工具更新啦。调试了好几个通宵就是为了效果和质量。 旧版尽早更新新版,从此告别手搓! 工具入口https://iimenvrieak.feishu.cn/docx/ZhRNdEWT6oGdCwxdhOPcdds7nof...

C++基础补充(03)C++20 的 std::format 函数
文章目录 1. 使用C20 std::format2. 基本用法3. 格式说明 1. 使用C20 std::format 需要将VisualStudio默认的标准修改为C20 菜单“项目”-“项目属性”,打开如下对话框 代码中加入头文件 2. 基本用法 通过占位符{}制定格式化的位置,后面传入变量 #…...

[论文笔记]DAPR: A Benchmark on Document-Aware Passage Retrieval
引言 今天带来论文DAPR: A Benchmark on Document-Aware Passage Retrieval的笔记。 本文提出了一个基准:文档感知段落检索(Document-Aware Passage Retrieval,DAPR)以及介绍了一些上下文段落表示的方法。 为了简单,下文中以翻译的口吻记录,…...

Spring Boot知识管理:智能搜索与分析
3系统分析 3.1可行性分析 通过对本知识管理系统实行的目的初步调查和分析,提出可行性方案并对其一一进行论证。我们在这里主要从技术可行性、经济可行性、操作可行性等方面进行分析。 3.1.1技术可行性 本知识管理系统采用JAVA作为开发语言,Spring Boot框…...
 (进程调度/进程调度器类型/三种进程调度/调度算法))
操作系统(2) (进程调度/进程调度器类型/三种进程调度/调度算法)
目录 1. 介绍进程调度(Introduction to Process Scheduling) 2. 优先级调度(Priority Scheduling) 3. CPU 利用率(CPU Utilization) 4. 吞吐量(Throughput) 5. 周转时间…...
鸿蒙--知乎评论
这里我们将采用组件化的思想进行开发 在开发中默认展示的是首页也就是 pages/Index.ets页面 这里存放的是所有页面的配置文件,类似与uniapp中的pages.json 如果我们此时要更改默认显示Zh...
之间实现UDP通信(C语言版本))
2024 - 两台CentOS服务器上的1000个Docker容器(每台500个)之间实现UDP通信(C语言版本)
两台CentOS服务器上的1000个Docker容器(每台500个)之间实现UDP通信(C语言版本) 给女朋友对象写得,她不会,我就写了一个 为了帮助您在两台CentOS服务器上的1000个Docker容器(每台500个)之间实现UDP通信&…...

小程序该如何上架
小程序的上架流程通常包括准备工作、代码审核、人工审核以及上线发布等关键步骤。以下是一个详细的小程序上架指南: 一、准备工作 注册开发者账号: 在微信小程序平台或支付宝开放平台等相应的小程序发布平台上注册开发者账号。 开发小程序: …...

XMOJ3065 旅游线路
10分钟没啥思路就去看题解了,结果发现很蠢。 题目大意 有一条河,河的东侧和西侧分别有 n , m n,m n,m 个景点,每个景点有个权值。有 k k k 条船,每条船连接东侧和西侧的一个景点。定义一个旅游线路是通过船连接起来的景点序列…...

量化之一:均值回归策略
文章目录 均值回归策略理论基础数学公式 关键指标简单移动平均线(SMA)标准差Z-Score 交易信号实际应用优缺点分析优点缺点 结论 实践backtrader参数:正常情况:异常情况: 均值回归策略 均值回归(Mean Rever…...

NVIDIA Bluefield DPU上的启动流程4个阶段分别是什么?作用是什么?
文章目录 Bluefield上的硬件介绍启动流程启动流程:eMMC中的两个存储分区:ATF介绍ATF启动的四个阶段:四个主要步骤:各个阶段依赖的启动文件一次烧录fw失败后的信息看启动流程综述Bluefield上的硬件介绍 本文以Bluefield2为例,可以看到RSHIM实际上是Boot相关的集合。也能看…...

最优美公式-欧拉公式,轻松理解版
Alan Becker创作的火柴人大战数学的打斗视频,风靡一时,并在B站荣耀斩获了“金知奖”。下面是网友对此视频的部分评价截图。 视频原址:火柴人 vs 数学,后续又一口气看完了“火柴人vs 几何”与“火柴人vs 物理”,通过火柴…...

【力扣 | SQL题 | 每日3题】力扣1107,1112, 1077
今天三道mid题都可以用窗口函数轻松秒杀。 1. 力扣1107:每日新用户统计 1.1 题目: Traffic 表: ------------------------ | Column Name | Type | ------------------------ | user_id | int | | activity | enum …...

计算机网络(十一) —— 数据链路层
目录 一,关于数据链路层 二,以太网协议 2.1 局域网 2.2 Mac地址 2.3 Mac帧报头 2.4 MTU 三,ARP协议 3.1 ARP是什么 3.2 ARP原理 3.3 ARP报头 3.4 模拟ARP过程 3.5 ARP周边问题 四,NAT技术 4.1 NAT技术背景 4.2 NAT转…...
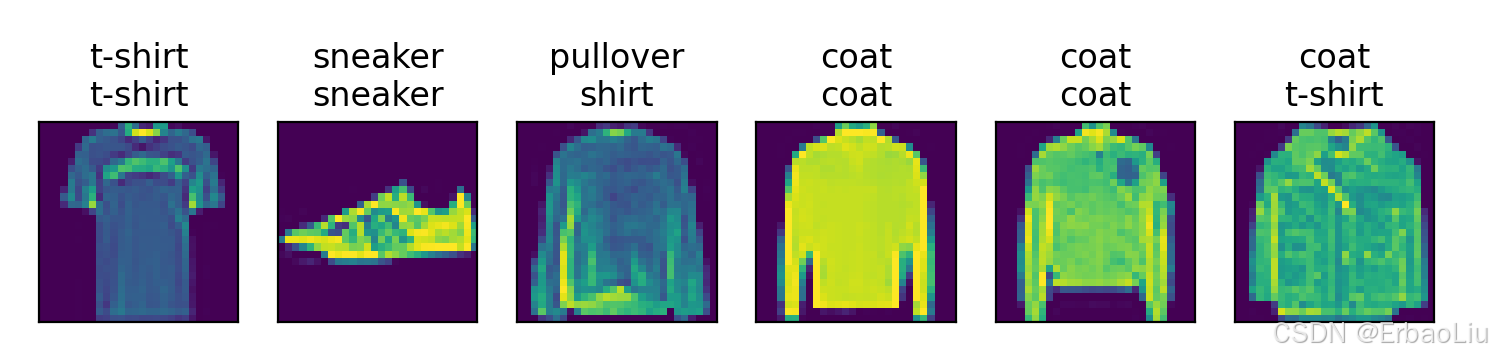
使用PyTorch从0实现Fashion-MNIST数据集分类
完整代码: from d2l import torch as d2l import torch from torchvision import transforms from torchvision import datasets from torch.utils.data import DataLoader import matplotlib.pyplot as plt from IPython import displaydef get_fashion_mnist_la…...

Java数组的值拷贝和地址拷贝
在Java中,数组的值拷贝和地址拷贝是两种不同的操作。 值拷贝是指将一个数组的值复制到另一个新的数组中。这意味着新数组和原数组独立存在,修改其中一个数组不会影响另一个数组。Java中的数组是对象,所以通过值拷贝操作实际上是复制了数组对…...
 以及 日历)
类与对象 中(剩余部分) 以及 日历
运算符重载 • 当运算符被⽤于类类型的对象时,C语⾔允许我们通过运算符重载的形式指定新的含义。C规定类类型对象使⽤运算符时,必须转换成调⽤对应运算符重载,若没有对应的运算符重载,则会编译报错。 • 运算符重载是具有特名字的…...
iOS 14 自定义画中画悬浮窗 Custom AVPictureInPictureController 实现方案
iOS 14,基于 AVPictureInPictureController,实现自定义画中画,涵盖所有功能与难点。 市面上的各种悬浮钟和提词器的原理都是基于此。 Demo源码在文末。 使用 iOS 画中画的要求: 真机,不能使用模拟器;iO…...

【C#生态园】完整解读C#网络通信库:从基础到实战应用
探索C#网络通信库:功能、用途和最佳实践 前言 随着互联网的快速发展,网络通信在现代软件开发中扮演着至关重要的角色。C#作为一种流行的编程语言,拥有多个优秀的网络通信库,为开发人员提供了丰富的选择。本文将深入探讨几种常用…...

Netgear路由器终极救援指南:如何用免费开源工具nmrpflash快速修复“变砖“设备
Netgear路由器终极救援指南:如何用免费开源工具nmrpflash快速修复"变砖"设备 【免费下载链接】nmrpflash Netgear Unbrick Utility 项目地址: https://gitcode.com/gh_mirrors/nmr/nmrpflash 当你的Netgear路由器因固件升级失败、意外断电或系统崩…...

从myplaces.shp到专题地图:手把手教你用QGIS C++ API实现点要素分级渲染
从myplaces.shp到专题地图:QGIS C API实现点要素分级渲染实战指南 当我们需要在桌面GIS应用中直观展示气象站降雨量、城市人口密度或商业网点销售额等连续型空间数据时,分级色彩渲染是最有效的可视化手段之一。本文将深入探讨如何利用QGIS强大的C API&am…...

NVIDIA Profile Inspector终极显卡优化工具:简单易用的性能调校完整指南
NVIDIA Profile Inspector终极显卡优化工具:简单易用的性能调校完整指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector是一款专业的显卡优化工具,专为…...

碧蓝航线自动化脚本:让游戏管理变得轻松高效
碧蓝航线自动化脚本:让游戏管理变得轻松高效 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 你是否厌倦了每天重…...

基于Readability算法的网页内容提取服务:从原理到工程实践
1. 项目概述:一个为现代阅读而生的开源工具 最近在折腾个人知识库和稍后读系统时,我一直在找一个能完美解决“网页内容净化与结构化”痛点的工具。市面上的方案要么太重,要么太简陋,直到我遇到了 Cat-tj/web-reader 。这不仅仅是…...

MTKClient终极指南:解锁联发科芯片调试的专业解决方案
MTKClient终极指南:解锁联发科芯片调试的专业解决方案 【免费下载链接】mtkclient MTK reverse engineering and flash tool 项目地址: https://gitcode.com/gh_mirrors/mt/mtkclient MTKClient作为一款专为联发科(MediaTek)芯片设计的…...

基于RAG的Obsidian智能插件:用AI对话重塑个人知识管理
1. 项目概述:当笔记遇上AI,一个插件如何重塑知识管理最近在折腾我的Obsidian知识库时,发现了一个让我眼前一亮的插件:Smart2Brain。这名字起得挺有意思,“Smart to Brain”,直译过来就是“从智能到大脑”。…...

终极指南:如何为你的Mac鼠标安装强大定制功能
终极指南:如何为你的Mac鼠标安装强大定制功能 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix Mac Mouse Fix是一款革命性的开源工具…...

LLM应用快速演示框架:从架构解析到智能体开发的实战指南
1. 项目概述:一个面向开发者的LLM应用快速演示框架最近在GitHub上闲逛,发现了一个名为wronai/llm-demo的项目,点进去一看,瞬间觉得眼前一亮。这可不是又一个简单的“Hello World”式的大语言模型调用示例,而是一个结构…...

轻量级服务器监控面板:从原理到部署实战
1. 项目概述:一个开源监控面板的诞生最近在折腾服务器和容器化应用,发现一个挺普遍的需求:当你手头有几台服务器,上面跑着几个Docker容器,或者一些自己写的服务,你总想知道它们现在“活”得怎么样。CPU是不…...