图像分类-demo(Lenet),tensorflow和Alexnet
目录
demo(Lenet)
代码实现基本步骤:
TensorFlow
一、核心概念
二、主要特点
三、简单实现
参数:
模型编译
模型训练
模型评估
Alexnet
model.py
train.py
predict.py
demo(Lenet)
PyTorch提供了一个名为“torchvision”的附加库,其中包含了各种预训练的模型和常用的数据集,以及用于构建和训练计算机视觉模型的实用工具。
LeNet是一个经典的卷积神经网络架构,用于手写数字识别任务(如MNIST数据集)。

pytorch tensor的通道排序:[batch, channel, height, width]
Lenet是一个 7 层的神经网络,包含 3 个卷积层,2 个池化层,1 个全连接层,1个输出层。其中所有卷积层的卷积核都为 5x5,步长=1,池化方法都为平均池化,激活函数为 ReLu。图中最后一步是要和全连接层连接,所以要转换为一维向量。函数用view。
代码实现基本步骤:
- model.py:定义LeNet网络模型
- train.py:加载数据集并训练,计算loss和accuracy,保存训练好的网络参数
- predict.py:用自己的数据集进行分类测试
TensorFlow
TensorFlow是一个由谷歌开发的开源机器学习框架,被广泛应用于构建和训练各种类型的机器学习模型。
一、核心概念
TensorFlow的核心概念是使用数据流图来表示数学计算的过程。数据流图由一系列节点和边组成的有向图,其中节点表示数学计算操作,而边则表示数据(张量)的流动。这种表示方式使得TensorFlow能够高效地处理复杂的数学计算和机器学习算法。
二、主要特点
- 灵活性:TensorFlow支持动态图和静态图两种模式,用户可以根据需要选择适合自己的开发模式。
- 自动微分:TensorFlow自带自动微分功能,可以方便地计算模型的梯度,这对于优化机器学习模型至关重要。
- 分布式训练:TensorFlow支持分布式训练,可以在多台机器上分布式训练模型,这对于处理大规模数据集和复杂模型非常有用。
- 高级API:TensorFlow提供了高级API,如Keras,可以方便地构建和训练模型。Keras已经发展成一个独立的深度学习框架,并在TensorFlow 2.x版本中得到了更好的支持和集成。
(ps:后面我们也会学习低级API,需要手动定义输入Tensor、各个层的计算过程(如卷积、激活、池化等),并将这些计算过程组合成一个完整的计算图。) - 部署和移动端支持:TensorFlow支持将训练好的模型部署到生产环境和移动端,方便用户在不同平台上进行应用。
三、简单实现
import tensorflow as tf | |
from tensorflow.keras import layers, models | |
# 加载和预处理数据(这里以MNIST手写数字数据集为例) | |
mnist = tf.keras.datasets.mnist | |
(x_train, y_train), (x_test, y_test) = mnist.load_data() | |
x_train, x_test = x_train / 255.0, x_test / 255.0 # 归一化像素值到0-1之间 | |
# 构建模型 | |
model = models.Sequential([ | |
layers.Flatten(input_shape=(28, 28)), # 将28x28的输入图像展平为一维向量 | |
layers.Dense(128, activation='relu'), # 全连接层,128个神经元,ReLU激活函数 | |
layers.Dropout(0.2), # Dropout层,用于减少过拟合,丢弃20/神经元 | |
layers.Dense(10, activation='softmax') # 输出层,10个神经元(对应10个类别),softmax激活函数 | |
]) | |
# 编译模型 | |
model.compile(optimizer='adam', | |
loss='sparse_categorical_crossentropy', | |
metrics=['accuracy']) | |
# 训练模型 | |
model.fit(x_train, y_train, epochs=5) | |
# 评估模型 | |
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2) | |
print(f'\nTest accuracy: {test_acc}') |
- 我们首先加载了MNIST数据集,并将其分为训练集和测试集。
- 接着,我们对图像数据进行了归一化处理,将像素值从0-255缩放到0-1之间。
- 然后,我们构建了一个简单的神经网络模型,该模型包含一个展平层、一个全连接层(带有ReLU激活函数)、一个Dropout层(用于减少过拟合)和一个输出层(带有softmax激活函数,用于多分类任务)。
- 我们编译了模型,指定了优化器(Adam)、损失函数(稀疏分类交叉熵)和评估指标(准确率)。
- 最后,我们训练了模型,并在测试集上评估了其性能。
参数:
-
layers.Flatten(input_shape=(28, 28)):Flatten层用于将输入图像(28x28像素)展平为一维向量(784个元素)。这是必要的,因为全连接层需要一维输入。 -
layers.Dense(10, activation='softmax'): 这是输出层,具有10个神经元(对应于10个数字类别)。使用softmax激活函数将输出转换为概率分布。
模型编译
-
optimizer='adam': 指定优化器为Adam。 -
loss='sparse_categorical_crossentropy': 指定损失函数为稀疏分类交叉熵。由于y_train和y_test是整数标签而不是one-hot编码,因此使用稀疏版本。 -
metrics=['accuracy']: 指定评估模型性能的指标为准确率。
模型训练
model.fit(x_train, y_train, epochs=5): 使用训练数据x_train和y_train来训练模型,训练5个周期(epoch)。每个周期都会遍历整个训练集一次。
模型评估
-
model.evaluate(x_test, y_test, verbose=2): 使用测试数据x_test和y_test来评估模型的性能。verbose=2表示在评估过程中显示每个批次的损失和准确率。
Alexnet

ISLVRC 2012
训练集:1,281,167张已标注图片
验证集:50,000张已标注图片
测试集:100,000张未标注图片
经卷积后的矩阵尺寸大小计算公式为: N = (W − F + 2P ) / S + 1
① 输入图片大小 W(高)×W(宽) ② Filter(卷积核)大小 F×F ③ 步长 S ④ padding的像素数 P

例如:像卷积1中,因为作者用了两个GPU,我们只看一个。kernels=48*2,已知输入为[224,224,3(深度为3)]输出为55*55*96(48*2)高*宽*池化核数。
N = (W − F + 2P ) / S + 1 =[224-11+(1+2)]/4+1=55

代码示例:
import torch.nn as nn
import torch
class AlexNet(nn.Module):
def __init__(self, num_classes=1000, init_weights=False):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
model.py
这个文件一个用于图像分类的卷积神经网络模型。
- 初始化函数
__init__:num_classes:模型输出的类别数,默认为1000。init_weights:一个布尔值,指示是否在初始化时自动设置模型权重,默认为False。self.features:定义了模型的特征提取部分,包括一系列的卷积层、ReLU激活函数和最大池化层。self.classifier:定义了模型的分类部分,包括全连接层、Dropout层和ReLU激活函数。- 如果
init_weights为True,则调用_initialize_weights函数来初始化权重。
- 前向传播函数
forward:- 输入图像
x通过self.features进行特征提取,然后通过torch.flatten将特征图展平为一维向量。 - 展平后的特征向量通过
self.classifier进行分类,输出每个类别的预测得分。
- 输入图像
- 权重初始化函数
_initialize_weights:- 遍历模型的所有模块,如果模块是卷积层或全连接层,则使用特定的方法初始化其权重和偏置。
import os
import sys
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from tqdm import tqdm
from model import AlexNet
tqdm用于显示进度条。
from model import AlexNet导入了自定义的AlexNet模型。
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
检查CUDA是否可用,并据此选择使用GPU还是CPU。
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
定义了训练和验证数据的预处理步骤,包括随机裁剪、水平翻转、调整大小、归一化
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
image_path = os.path.join(data_root, "data_set", "flower_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
使用datasets.ImageFolder加载训练和验证数据集。
类标签处理
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
将类别索引映射到类别名称,并保存到JSON文件中。
数据加载器
batch_size = 32
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
创建数据加载器,用于批量加载数据。
num_workers指定了加载数据时使用的进程数。
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=4, shuffle=False,
num_workers=nw)
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
# test_data_iter = iter(validate_loader)
# test_image, test_label = test_data_iter.next()
#
# def imshow(img):
# img = img / 2 + 0.5 # unnormalize
# npimg = img.numpy()
# plt.imshow(np.transpose(npimg, (1, 2, 0)))
# plt.show()
#
# print(' '.join('%5s' % cla_dict[test_label[j].item()] for j in range(4)))
# imshow(utils.make_grid(test_image))
模型、损失函数和优化器
net = AlexNet(num_classes=5, init_weights=True)
net.to(device) #网络指定到我们设备中
loss_function = nn.CrossEntropyLoss()
# pata = list(net.parameters())
optimizer = optim.Adam(net.parameters(), lr=0.0002)
初始化AlexNet模型,并设置类别数为5。
将模型移动到指定的设备上(GPU或CPU)。
使用交叉熵损失函数。
使用Adam优化器。
epochs = 10
save_path = './AlexNet.pth'
best_acc = 0.0
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# validate
net.eval() #在网络搭建过程中,我们失去了一部分神经元但我们只希望在训练中,不希望在预测过程中起作用
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
训练过程分为多个epoch。
在每个epoch中,模型先切换到训练模式,然后遍历训练数据集。
使用优化器更新模型参数。
每个epoch结束后,模型切换到评估模式,遍历验证数据集以计算准确率。
如果当前epoch的验证准确率高于之前的最高准确率,则保存模型。
print('Finished Training')
if __name__ == '__main__':
main()
train.py
训练AlexNet模型的完整流程。
- 设置设备(GPU或CPU)。
- 定义数据预处理流程
data_transform,包括随机裁剪、水平翻转、归一化等。 - 设置数据集的路径,并加载训练和验证数据集。
- 将类别索引映射到类别名称,并保存为JSON文件。
- 配置数据加载器
DataLoader,包括批量大小、是否打乱数据、工作线程数等。 - 初始化
AlexNet模型,设置损失函数(交叉熵损失)和优化器(Adam)。 - 训练模型:
- 在每个epoch中,模型首先在训练集上进行训练,计算损失并更新权重。
- 然后,在验证集上评估模型的准确性。
- 记录每个epoch的训练损失和验证准确性。
- 如果当前epoch的验证准确性高于之前的最佳准确性,则保存模型权重。
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import AlexNet
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
定义了一个预处理管道,它首先将图像调整到224x224像素(AlexNet的输入大小),然后将图像转换为PyTorch张量,并对每个通道进行归一化处理。归一化使用均值(0.5, 0.5, 0.5)和标准差(0.5, 0.5, 0.5)
# load image
img_path = r"D:\pycharm\深度学习-图像分类\data_set\flower_data\train\tulips\11746276_de3dec8201.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W],
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
将图像通过预处理管道,并增加一个批量维度,因为PyTorch模型期望输入是一个四维张量,其中N是批量大小,C是通道数,H和W分别是高度和宽度。
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
class_indict = json.load(f)
读取包含类别索引映射的JSON文件,这个文件应该有一个从类别索引到类别名称的映射。
# create model
model = AlexNet(num_classes=5).to(device)
# load model weights
weights_path = "./AlexNet.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path))
model.eval()
创建AlexNet模型实例,指定类别数为5,并将模型移动到之前设置的设备上(GPU或CPU)。然后加载预训练的权重,并将模型设置为评估模式,这意味着在推理期间不会进行梯度计算或权重更新。
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
使用torch.no_grad()禁用梯度计算,因为我们在进行推理而不是训练。将图像张量移动到设备上,通过模型进行前向传播,得到输出。然后应用softmax函数得到概率分布,并找到概率最高的类别的索引。
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].numpy()))
plt.show()
打印出预测结果,包括类别名称和对应的概率,并在图像上显示这个信息作为标题。然后遍历所有类别的概率,并打印出来。最后,显示图像。
if __name__ == '__main__':
main()
predict.py
使用PyTorch框架和AlexNet模型进行图像分类的完整示例。
- 设置设备:根据是否检测到CUDA设备(GPU),设置PyTorch使用CPU或GPU。
- 定义数据转换:使用
transforms.Compose定义一个转换序列,包括调整图像大小到224x224,转换为Tensor,然后进行归一化。 - 加载图像:使用PIL打开指定路径的图像,并检查文件是否存在。
- 显示原始图像:使用matplotlib显示原始图像。
- 图像预处理:应用之前定义的转换序列,并增加批量维度以匹配模型输入要求。
- 读取类别索引:从JSON文件中加载类别索引映射,用于将模型预测的数字标签转换为可读的类别名称。
- 创建模型:实例化AlexNet模型,设置类别数为5(假设有5个类别),并将模型移至之前确定的设备(CPU或GPU)。
- 加载模型权重:从指定路径加载训练好的模型权重。
- 模型评估模式:设置模型为评估模式,关闭dropout和batch normalization的训练特性。
- 进行预测:
- 使用
torch.no_grad()上下文管理器关闭梯度计算,减少内存消耗,加快计算速度。 - 将预处理后的图像传入模型进行预测,对输出进行squeeze操作去除多余的维度,然后将结果移至CPU。
- 应用softmax函数计算每个类别的预测概率。
- 找到概率最高的类别作为预测结果。
- 使用
- 显示结果:打印并显示预测类别和概率,以及所有类别的预测概率。
相关文章:
图像分类-demo(Lenet),tensorflow和Alexnet
目录 demo(Lenet) 代码实现基本步骤: TensorFlow 一、核心概念 二、主要特点 三、简单实现 参数: 模型编译 模型训练 模型评估 Alexnet model.py train.py predict.py demo(Lenet) PyTorch提供了一个名为“torchvision”的附加库,其中包含…...

excel 单元格嵌入图片
1.图片右键,设置图片格式 2.属性 随单元格改为位置和大小 这样的话,图片就会嵌入到单元格,也会跟着单元格的大小而改变...
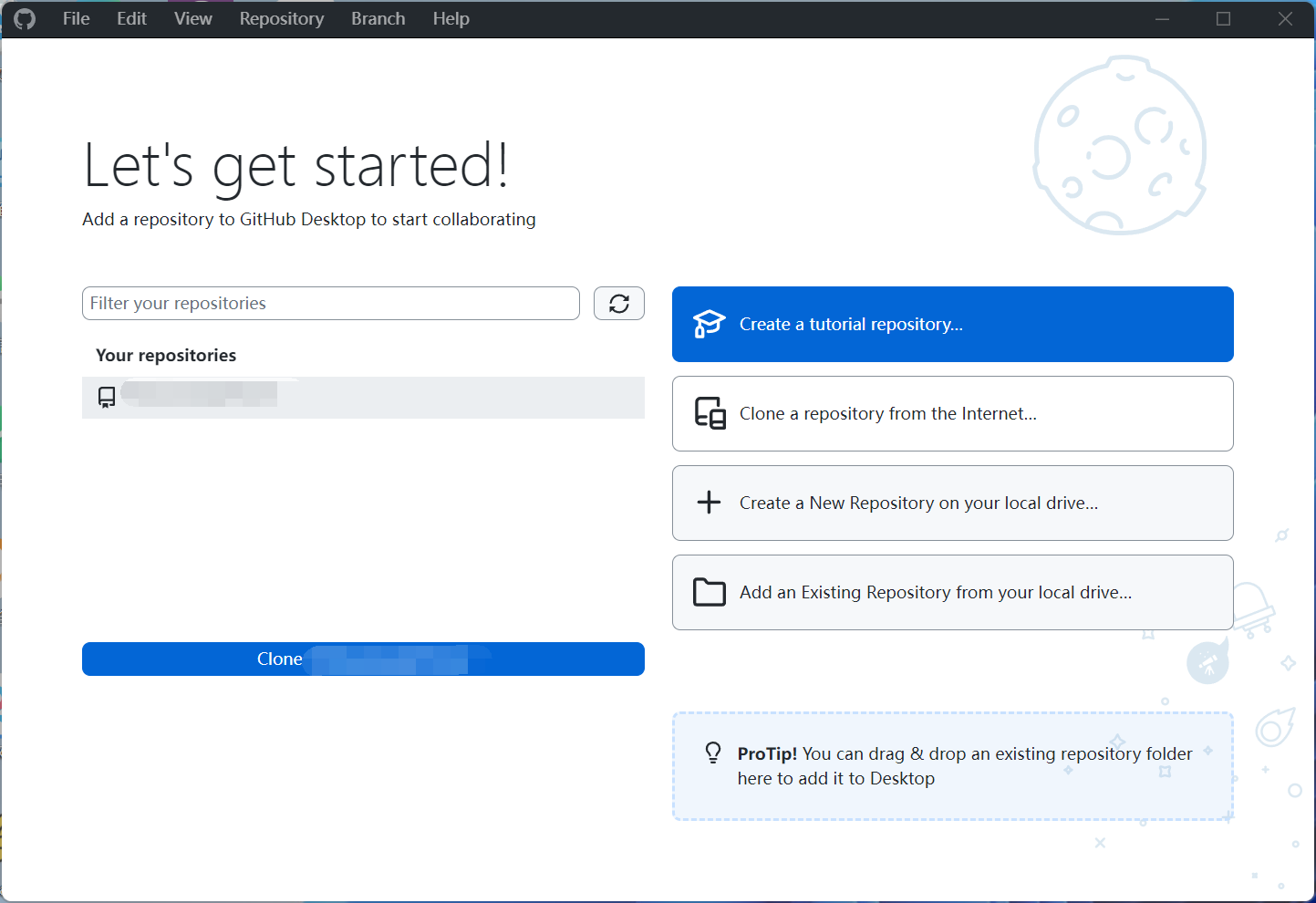
GitHub简介与安装使用入门教程
1、Git与GitHub的简介 Git是目前世界上最先进的分布式控制系统,它允许开发者跟踪和管理源代码的改动历史记录等,可以将你的代码恢复到某一个版本,支持多人协作开发。它的核心功能包括版本控制、分支管理、合并和冲突解决等,其操作…...

HTML(五)列表详解
在HTML中,列表可以分为两种,一种为有序列表。另一种为无序列表 今天就来详细讲解一下这两种列表如何实现,效果如何 1.有序列表 有序列表的标准格式如下: <ol><li>列表项一</li><li>列表项二</li>…...

SparkSQL介绍及使用
SparkSQL介绍及使用 一、什么是SparkSQL(了解) spark开发时可以使用rdd进行开发,spark还提供saprksql工具,将数据转为结构化数据进行操作 1-1 介绍 官网:https://spark.apache.org/sql/ Spark SQL是 Apache Spark 用于…...

【聚星文社】3.2版一键推文工具更新啦
【聚星文社】3.2版一键推文工具更新啦。调试了好几个通宵就是为了效果和质量。 旧版尽早更新新版,从此告别手搓! 工具入口https://iimenvrieak.feishu.cn/docx/ZhRNdEWT6oGdCwxdhOPcdds7nof...

C++基础补充(03)C++20 的 std::format 函数
文章目录 1. 使用C20 std::format2. 基本用法3. 格式说明 1. 使用C20 std::format 需要将VisualStudio默认的标准修改为C20 菜单“项目”-“项目属性”,打开如下对话框 代码中加入头文件 2. 基本用法 通过占位符{}制定格式化的位置,后面传入变量 #…...

[论文笔记]DAPR: A Benchmark on Document-Aware Passage Retrieval
引言 今天带来论文DAPR: A Benchmark on Document-Aware Passage Retrieval的笔记。 本文提出了一个基准:文档感知段落检索(Document-Aware Passage Retrieval,DAPR)以及介绍了一些上下文段落表示的方法。 为了简单,下文中以翻译的口吻记录,…...

Spring Boot知识管理:智能搜索与分析
3系统分析 3.1可行性分析 通过对本知识管理系统实行的目的初步调查和分析,提出可行性方案并对其一一进行论证。我们在这里主要从技术可行性、经济可行性、操作可行性等方面进行分析。 3.1.1技术可行性 本知识管理系统采用JAVA作为开发语言,Spring Boot框…...
 (进程调度/进程调度器类型/三种进程调度/调度算法))
操作系统(2) (进程调度/进程调度器类型/三种进程调度/调度算法)
目录 1. 介绍进程调度(Introduction to Process Scheduling) 2. 优先级调度(Priority Scheduling) 3. CPU 利用率(CPU Utilization) 4. 吞吐量(Throughput) 5. 周转时间…...
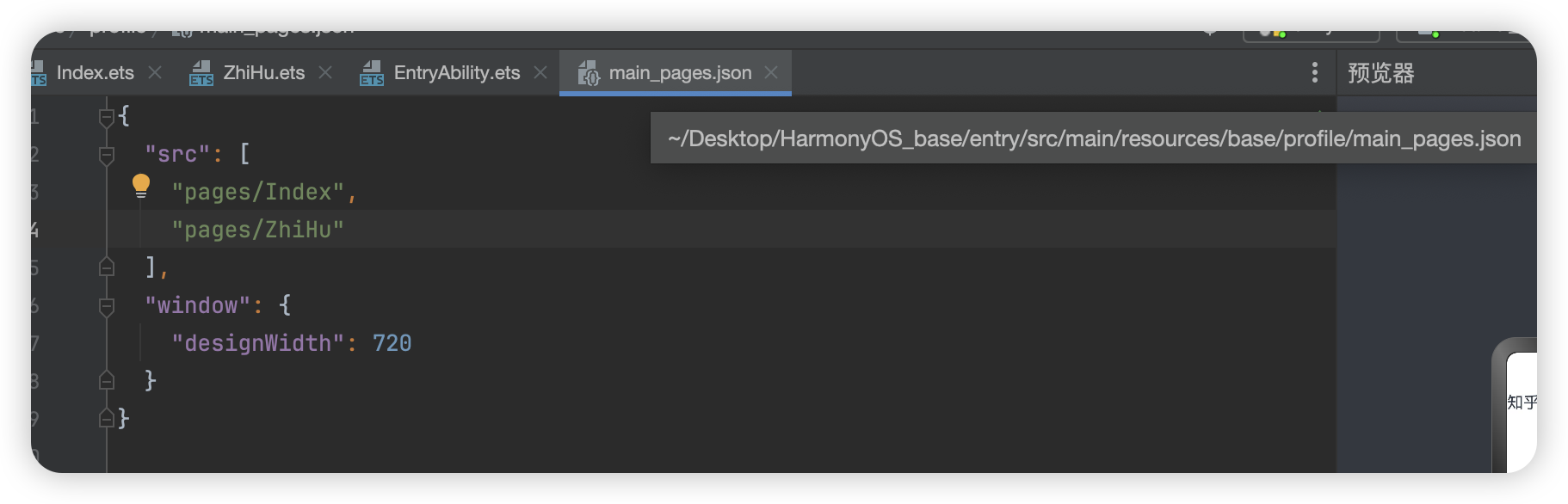
鸿蒙--知乎评论
这里我们将采用组件化的思想进行开发 在开发中默认展示的是首页也就是 pages/Index.ets页面 这里存放的是所有页面的配置文件,类似与uniapp中的pages.json 如果我们此时要更改默认显示Zh...
之间实现UDP通信(C语言版本))
2024 - 两台CentOS服务器上的1000个Docker容器(每台500个)之间实现UDP通信(C语言版本)
两台CentOS服务器上的1000个Docker容器(每台500个)之间实现UDP通信(C语言版本) 给女朋友对象写得,她不会,我就写了一个 为了帮助您在两台CentOS服务器上的1000个Docker容器(每台500个)之间实现UDP通信&…...

小程序该如何上架
小程序的上架流程通常包括准备工作、代码审核、人工审核以及上线发布等关键步骤。以下是一个详细的小程序上架指南: 一、准备工作 注册开发者账号: 在微信小程序平台或支付宝开放平台等相应的小程序发布平台上注册开发者账号。 开发小程序: …...

XMOJ3065 旅游线路
10分钟没啥思路就去看题解了,结果发现很蠢。 题目大意 有一条河,河的东侧和西侧分别有 n , m n,m n,m 个景点,每个景点有个权值。有 k k k 条船,每条船连接东侧和西侧的一个景点。定义一个旅游线路是通过船连接起来的景点序列…...

量化之一:均值回归策略
文章目录 均值回归策略理论基础数学公式 关键指标简单移动平均线(SMA)标准差Z-Score 交易信号实际应用优缺点分析优点缺点 结论 实践backtrader参数:正常情况:异常情况: 均值回归策略 均值回归(Mean Rever…...

NVIDIA Bluefield DPU上的启动流程4个阶段分别是什么?作用是什么?
文章目录 Bluefield上的硬件介绍启动流程启动流程:eMMC中的两个存储分区:ATF介绍ATF启动的四个阶段:四个主要步骤:各个阶段依赖的启动文件一次烧录fw失败后的信息看启动流程综述Bluefield上的硬件介绍 本文以Bluefield2为例,可以看到RSHIM实际上是Boot相关的集合。也能看…...

最优美公式-欧拉公式,轻松理解版
Alan Becker创作的火柴人大战数学的打斗视频,风靡一时,并在B站荣耀斩获了“金知奖”。下面是网友对此视频的部分评价截图。 视频原址:火柴人 vs 数学,后续又一口气看完了“火柴人vs 几何”与“火柴人vs 物理”,通过火柴…...

【力扣 | SQL题 | 每日3题】力扣1107,1112, 1077
今天三道mid题都可以用窗口函数轻松秒杀。 1. 力扣1107:每日新用户统计 1.1 题目: Traffic 表: ------------------------ | Column Name | Type | ------------------------ | user_id | int | | activity | enum …...

计算机网络(十一) —— 数据链路层
目录 一,关于数据链路层 二,以太网协议 2.1 局域网 2.2 Mac地址 2.3 Mac帧报头 2.4 MTU 三,ARP协议 3.1 ARP是什么 3.2 ARP原理 3.3 ARP报头 3.4 模拟ARP过程 3.5 ARP周边问题 四,NAT技术 4.1 NAT技术背景 4.2 NAT转…...
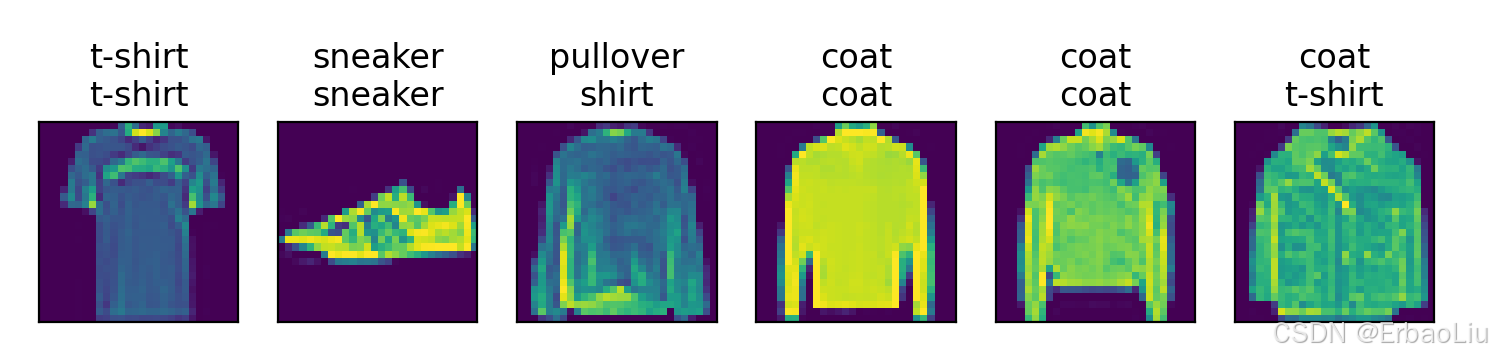
使用PyTorch从0实现Fashion-MNIST数据集分类
完整代码: from d2l import torch as d2l import torch from torchvision import transforms from torchvision import datasets from torch.utils.data import DataLoader import matplotlib.pyplot as plt from IPython import displaydef get_fashion_mnist_la…...

libmill内存管理机制:如何避免协程栈溢出问题的完整指南
libmill内存管理机制:如何避免协程栈溢出问题的完整指南 【免费下载链接】libmill Go-style concurrency in C 项目地址: https://gitcode.com/gh_mirrors/li/libmill libmill是一个为C语言引入Go风格并发编程的轻量级库,它通过协程(c…...

二手破损手机涨价,业余 NAS 玩家如何破局?
最近打开手机回收 App,发现家里那台屏幕碎成渣、开不了机的旧安卓机,居然能卖一百多,甚至两三百。你可能会想:这是天上掉馅饼,还是 NAS 玩家的“矿难”前兆? 作为一名业余 NAS 玩家,我正好踩在这…...

Windows环境下Jaeger全链路监控系统搭建指南
1. 为什么需要全链路监控系统 在微服务架构中,一个用户请求可能会经过多个服务的处理。想象一下,你在电商网站下单时,这个操作会触发订单服务、支付服务、库存服务等多个系统的协同工作。当出现问题时,传统的日志排查就像在迷宫里…...

Qwen3字幕生成工具实战:快速处理会议录音,输出带时间戳字幕
Qwen3字幕生成工具实战:快速处理会议录音,输出带时间戳字幕 1. 会议录音转字幕的痛点与解决方案 处理会议录音是许多职场人士的日常任务。传统方法需要先听录音,再手动记录内容,最后还要逐句对齐时间轴,整个过程耗时…...

ATOM-PRINTER嵌入式热敏打印固件深度解析
1. ATOM-PRINTER 嵌入式打印库深度解析与工程实践指南ATOM-PRINTER 是 M5Stack 推出的面向 ESP32 平台的轻量级嵌入式热敏打印固件库,专为 M5Stack Atom 系列微型主控模块(搭载 ESP32-WROVER-B)设计。该库并非传统意义上的“驱动层”C/C 库&a…...

Phi-4-reasoning-vision-15B在金融图表分析中的实战:趋势识别与异常定位
Phi-4-reasoning-vision-15B在金融图表分析中的实战:趋势识别与异常定位 1. 金融图表分析的挑战与机遇 金融从业者每天需要分析大量图表数据,从K线图到财务报表,从趋势分析到异常检测。传统的人工分析方法存在三个明显痛点: 效…...
)
深度解析:关系型数据库与非关系型数据库(区别+原理+适用场景,一文吃透)
在后端开发、数据存储领域,“关系型数据库(SQL)”和“非关系型数据库(NoSQL)”是两个绕不开的核心概念。很多开发者在选型时会困惑:到底该用MySQL还是MongoDB?PostgreSQL和Redis的区别是什么&am…...

ScanTailor Advanced终极指南:免费开源扫描文档处理完整解决方案
ScanTailor Advanced终极指南:免费开源扫描文档处理完整解决方案 【免费下载链接】scantailor-advanced ScanTailor Advanced is the version that merges the features of the ScanTailor Featured and ScanTailor Enhanced versions, brings new ones and fixes. …...
)
GD32F450VK移植RT-Thread时如何避免SRAM分区导致的HardFault(附解决方案)
GD32F450VK移植RT-Thread的SRAM分区陷阱与实战解决方案 在嵌入式开发领域,GD32F4系列微控制器凭借其出色的性价比和丰富的外设资源,正逐渐成为工业控制、物联网终端等场景的热门选择。然而,当开发者尝试将RT-Thread实时操作系统移植到GD32F4…...

Node.js全栈项目集成Wan2.1-UMT5:实时视频生成进度推送
Node.js全栈项目集成Wan2.1-UMT5:实时视频生成进度推送 最近在做一个挺有意思的项目,需要把Wan2.1-UMT5这个视频生成模型集成到我们自己的系统里。用户上传一段文字描述,系统就能生成一段短视频。听起来挺酷,对吧?但问…...