磁盘存储链式结构——B树与B+树
红黑树处理数据都是在内存中,考虑的都是内存中的运算时间复杂度。如果我们要操作的数据集非常大,大到内存已经没办法处理了该怎么办呢?
试想一下,为了要在一个拥有几十万个文件的磁盘中查找一个文本文件,设计的算法需要读取磁盘(磁盘寻址)上万次还是读取几十次,这是有本质差异的,此时为了降低对外存设备的访问次数,我们就需要新的数据结构来处理这样的问题,B树B+树(n叉树)。
B树、B+树的本质是通过降低树的层高,减少对磁盘访问次数,来提升查询速度,查找复杂度logm(n/m),m是叉的数量
B树与B+树区别与联系
- B树所有节点即存储key也存储value,内存中存不下后存磁盘,名称为B-Tree,并没有B-树这种叫法
- B+树只有在叶子节点存储数据value(叶子节点放在磁盘中),非叶子节点用来做索引key(非叶子结点在内存中),相比于B树,B+树更适合做磁盘索引,在大数据的存储和查找中使用较多,比如海量图像查找引擎
- B树和B+树的结点添加、删除、查询基本相同
B树的性质
- 每个结点最多有m棵子树。
- 具有k个子树的非叶结点包含k -1个键。
- 每个非叶子结点(除了根)具有至少⌈ m/2⌉子树,即最少有⌈ m/2⌉-1个关键字。
- 如果根不是终端结点,则根结点至少有一个关键字,即至少有2棵子树。【根的关键字取值范围是[1,m-1],子树的取值范围是[2,m]】
- 所有叶子结点都出现在同一水平,没有任何信息(高度一致)。
B+树的性质
每个结点最多有m棵子树。
如果根不是终端结点,则根结点至少有一个关键字,即至少有2棵子树。【根的关键字取值范围是[1,m-1]】
每个关键字对应一棵子树(与B树的不同),具有k个子树的非叶结点包含k 个键。
每个非叶子结点(除了根)具有至少**⌈ m/2⌉子树**,即最少有**⌈m/2⌉个关键字**。
终端结点包含全部关键字及相应记录的指针,叶结点中将关键字按大小顺序排序,并且相邻叶结点按大小顺序相互链接起来。
所有分支结点(可以视为索引的索引)中金包含他的各个子节点(即下一级的索引块)中关键字最大值,及指向其子结点的指针。
B树与B+树对比

- 在B+树中,叶结点包含信息,所有非叶结点仅起索引作用,非叶子结点中的每个索引项只是包含了对应子树最大关键字和指向该孩子树的指针,不含有该关键字对应记录的存储地址。
- 在B+树中,终端结点包含全部关键字及相应记录的指针,即非终端结点出现过的关键字也会在这重复出现一次。而B树是不重复的
一、B树的定义
我们以六叉树为例:我们说的6叉树是指,每个节点最多可拥有的子树个数,6叉树每个节点最多可拥有6颗子树,而每个节点中最多存储5个数据,如下图

至于为什么插入后会是如下图形,如何插入,请观看下面b站视频。
B树(B-树) - 来由, 定义, 插入, 构建_哔哩哔哩_bilibili
//6叉树的定义
#define SUB_M 3struct _btree_node{/*int keys[2 * SUB_M-1]; //最多5个关键字struct _btree_node *childrens[2 * SUB_M]; //最多6颗子树 6叉树*/int *keys; //5struct _btree_node **childrens; //6int num; //实际存储的节点数量 <= M-1int leaf; //是否为叶子节点
}struct _btree {struct _btree_node *root;
}二、B树添加结点
B树添加结点,只会添加在叶子结点上,重点是结点满了后,会发生分裂并向父结点上位。
- 添加的数据都是添加在叶子节点上,不会添加到根节点或中间节点
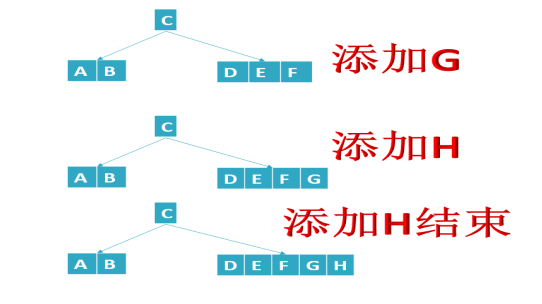
- 结点数据个数==M-1(结点满了的情况),发生分裂(把(M-1)/2处数据放到父结点,其他数据分成两个结点)
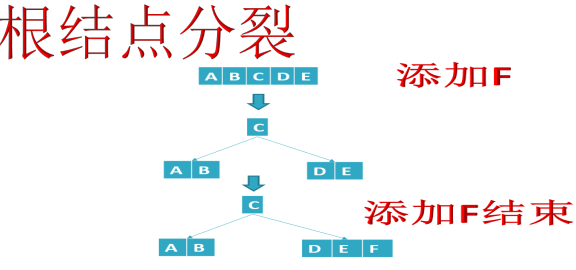

- 添加U,高度+1


添加结点代码如下:
/*用于结点分裂时创建新结点*/
btree_node *btree_create_node(int leaf){btree_node *node = (btree_node*)calloc(1, sizeof(btree_node)); //malloc需要手动清零,calloc会自动清零,set 0if(node == NULL) return NULL; //在内存分配的时候一定要判断,当内存不够用的时候,malloc/calloc就会出错node->leaf = leaf;node->keys = calloc(2 * SUB_M -1, sizeof(int));node->childrens = (btree_node**)calloc(2 * SUB_M -1, sizeof(btree_node*));node->num = 0;return node;
}/*删除结点*/
void btree_destory_node(btree_node *node){free(node->childrens);free(node->keys);free(node);
}/*
非根结点分裂、上位:发生在B树添加元素的过程中,结点满了,需要先分裂再添加
btree *T:根节点
btree_node *x:被删除元素的父结点
int idx:位于父结点的第几颗子树
*/
void btree_split_child(btree *T, btree_node *x, int idx){btree_node *y = x->childrens[idx]; //满了的结点node_ybtree_node *z = btree_create_node(y->leaf); //创建分裂后的新结点//zz->num = SUB_M - 1;int i=0;for(i=0; i < SUB_M-1; i++){z->keys[i] = y->keys[SUB_M+i];}if(y->leaf == 0){ //inner 是内结点,子树指针也要copy过去for(i=0; i < SUB_M-1; i++){z->childrens[i] = y->childrens[SUB_M+i];}}//yy->num = SUB_M;//中间元素上位//childrens 子树for(i=x->num; i >= idx+1; i--){ //寻找上为父结点的位置x->childrens[i+1] = x->childrens[i]; //父结点元素后移}x->childrens[i+1] = z;//key for(i=x->num-1; i >= idx; i--){ //寻找上为父结点的位置x->keys[i+1] = x->keys[i]; //父结点后边元素后移 }x->keys[i] = y->keys[SUB_M];x->num += 1;
}/**/
void btree_insert(btree *T, int key){btree_node *r = T->root;//根节点分裂(根节点满了);创建一个空结点 指向root, if(r->num == 2*SUB_M-1){btree_node *node = btree_create_node(0);T->root = node;node->childrens[0] = r;btree_split_child(T, node, 0);}
}三、B树删除结点
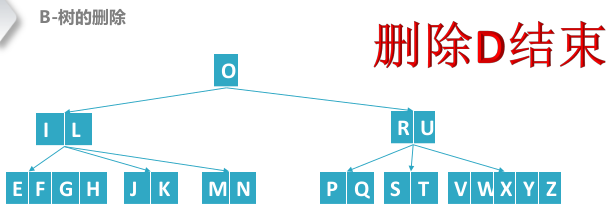
B树删除结点,删除叶子结点和中间结点类似,重点为向父结点借位再合并操作。
- 先合并或者借位转换成一个B树可以删除的状态,在进行删除

删除B结点,其中路径中间结点“FI”的关键字数量为(M-1)/2-1个,为了避免以后出现资源不足的现象,需要对"FI"先进行借位合并



代码如下:
///b树 删除 void btree_merge(btree *T, btree_node *x, int idx){btree_node *left = x->childrens[idx];btree_node *right = x->childrens[idx+1];left->keys[left->num] = x->keys[idx];int i=0;for(i=0; i<right->num; i++){left->keys[SUB_M+i] = right->keys[i];}if(!left->leaf){ //非叶子结点,要合并孩子结点指针for(i=0; i<SUB_M; i++){left->childrens[SUB_M+i] = right->childrens[i];}}left->num += SUB_M;btree_destory_node(right);//x key前移for(i=idx+1; i < x->num; i++){x->keys[i-1] = x->keys[i];x->childrens[i] = x->childrens[i+1];}
}四、完整代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <assert.h>#define DEGREE 3
typedef int KEY_VALUE;typedef struct _btree_node {KEY_VALUE* keys;struct _btree_node** childrens;int num;int leaf;
} btree_node;typedef struct _btree {btree_node* root;int t;
} btree;btree_node* btree_create_node(int t, int leaf) {btree_node* node = (btree_node*)calloc(1, sizeof(btree_node));if (node == NULL) assert(0);node->leaf = leaf;node->keys = (KEY_VALUE*)calloc(1, (2 * t - 1) * sizeof(KEY_VALUE));node->childrens = (btree_node**)calloc(1, (2 * t) * sizeof(btree_node*));node->num = 0;return node;
}void btree_destroy_node(btree_node* node) {assert(node);free(node->keys);//free(node->childrens);free(node);
}void btree_create(btree* T, int t) {T->t = t;btree_node* x = btree_create_node(t, 1);T->root = x;
}void btree_split_child(btree* T, btree_node* x, int i) {int t = T->t;btree_node* y = x->childrens[i];btree_node* z = btree_create_node(t, y->leaf);z->num = t - 1;int j = 0;for (j = 0; j < t - 1; j++) {z->keys[j] = y->keys[j + t];}if (y->leaf == 0) {for (j = 0; j < t; j++) {z->childrens[j] = y->childrens[j + t];}}y->num = t - 1;for (j = x->num; j >= i + 1; j--) {x->childrens[j + 1] = x->childrens[j];}x->childrens[i + 1] = z;for (j = x->num - 1; j >= i; j--) {x->keys[j + 1] = x->keys[j];}x->keys[i] = y->keys[t - 1];x->num += 1;}void btree_insert_nonfull(btree* T, btree_node* x, KEY_VALUE k) {int i = x->num - 1;if (x->leaf == 1) {while (i >= 0 && x->keys[i] > k) {x->keys[i + 1] = x->keys[i];i--;}x->keys[i + 1] = k;x->num += 1;}else {while (i >= 0 && x->keys[i] > k) i--;if (x->childrens[i + 1]->num == (2 * (T->t)) - 1) {btree_split_child(T, x, i + 1);if (k > x->keys[i + 1]) i++;}btree_insert_nonfull(T, x->childrens[i + 1], k);}
}void btree_insert(btree* T, KEY_VALUE key) {//int t = T->t;btree_node* r = T->root;if (r->num == 2 * T->t - 1) {btree_node* node = btree_create_node(T->t, 0);T->root = node;node->childrens[0] = r;btree_split_child(T, node, 0);int i = 0;if (node->keys[0] < key) i++;btree_insert_nonfull(T, node->childrens[i], key);}else {btree_insert_nonfull(T, r, key);}
}void btree_traverse(btree_node* x) {int i = 0;for (i = 0; i < x->num; i++) {if (x->leaf == 0)btree_traverse(x->childrens[i]);printf("%C ", x->keys[i]);}if (x->leaf == 0) btree_traverse(x->childrens[i]);
}void btree_print(btree* T, btree_node* node, int layer)
{btree_node* p = node;int i;if (p) {printf("\nlayer = %d keynum = %d is_leaf = %d\n", layer, p->num, p->leaf);for (i = 0; i < node->num; i++)printf("%c ", p->keys[i]);printf("\n");
#if 0printf("%p\n", p);for (i = 0; i <= 2 * T->t; i++)printf("%p ", p->childrens[i]);printf("\n");
#endiflayer++;for (i = 0; i <= p->num; i++)if (p->childrens[i])btree_print(T, p->childrens[i], layer);}else printf("the tree is empty\n");
}int btree_bin_search(btree_node* node, int low, int high, KEY_VALUE key) {int mid;if (low > high || low < 0 || high < 0) {return -1;}while (low <= high) {mid = (low + high) / 2;if (key > node->keys[mid]) {low = mid + 1;}else {high = mid - 1;}}return low;
}//{child[idx], key[idx], child[idx+1]}
void btree_merge(btree* T, btree_node* node, int idx) {btree_node* left = node->childrens[idx];btree_node* right = node->childrens[idx + 1];int i = 0;/data mergeleft->keys[T->t - 1] = node->keys[idx];for (i = 0; i < T->t - 1; i++) {left->keys[T->t + i] = right->keys[i];}if (!left->leaf) {for (i = 0; i < T->t; i++) {left->childrens[T->t + i] = right->childrens[i];}}left->num += T->t;//destroy rightbtree_destroy_node(right);//node for (i = idx + 1; i < node->num; i++) {node->keys[i - 1] = node->keys[i];node->childrens[i] = node->childrens[i + 1];}node->childrens[i + 1] = NULL;node->num -= 1;if (node->num == 0) {T->root = left;btree_destroy_node(node);}
}void btree_delete_key(btree* T, btree_node* node, KEY_VALUE key) {if (node == NULL) return;int idx = 0, i;while (idx < node->num && key > node->keys[idx]) {idx++;}if (idx < node->num && key == node->keys[idx]) {if (node->leaf) {for (i = idx; i < node->num - 1; i++) {node->keys[i] = node->keys[i + 1];}node->keys[node->num - 1] = 0;node->num--;if (node->num == 0) { //rootfree(node);T->root = NULL;}return;}else if (node->childrens[idx]->num >= T->t) {btree_node* left = node->childrens[idx];node->keys[idx] = left->keys[left->num - 1];btree_delete_key(T, left, left->keys[left->num - 1]);}else if (node->childrens[idx + 1]->num >= T->t) {btree_node* right = node->childrens[idx + 1];node->keys[idx] = right->keys[0];btree_delete_key(T, right, right->keys[0]);}else {btree_merge(T, node, idx);btree_delete_key(T, node->childrens[idx], key);}}else {btree_node* child = node->childrens[idx];if (child == NULL) {printf("Cannot del key = %d\n", key);return;}if (child->num == T->t - 1) {btree_node* left = NULL;btree_node* right = NULL;if (idx - 1 >= 0)left = node->childrens[idx - 1];if (idx + 1 <= node->num)right = node->childrens[idx + 1];if ((left && left->num >= T->t) ||(right && right->num >= T->t)) {int richR = 0;if (right) richR = 1;if (left && right) richR = (right->num > left->num) ? 1 : 0;if (right && right->num >= T->t && richR) { //borrow from nextchild->keys[child->num] = node->keys[idx];child->childrens[child->num + 1] = right->childrens[0];child->num++;node->keys[idx] = right->keys[0];for (i = 0; i < right->num - 1; i++) {right->keys[i] = right->keys[i + 1];right->childrens[i] = right->childrens[i + 1];}right->keys[right->num - 1] = 0;right->childrens[right->num - 1] = right->childrens[right->num];right->childrens[right->num] = NULL;right->num--;}else { //borrow from prevfor (i = child->num; i > 0; i--) {child->keys[i] = child->keys[i - 1];child->childrens[i + 1] = child->childrens[i];}child->childrens[1] = child->childrens[0];child->childrens[0] = left->childrens[left->num];child->keys[0] = node->keys[idx - 1];child->num++;node->keys[idx - 1] = left->keys[left->num - 1];left->keys[left->num - 1] = 0;left->childrens[left->num] = NULL;left->num--;}}else if ((!left || (left->num == T->t - 1))&& (!right || (right->num == T->t - 1))) {if (left && left->num == T->t - 1) {btree_merge(T, node, idx - 1);child = left;}else if (right && right->num == T->t - 1) {btree_merge(T, node, idx);}}}btree_delete_key(T, child, key);}}int btree_delete(btree* T, KEY_VALUE key) {if (!T->root) return -1;btree_delete_key(T, T->root, key);return 0;
}int main() {btree T = { 0 };btree_create(&T, 3);srand(48);int i = 0;char key[27] = "ABCDEFGHIJKLMNOPQRSTUVWXYZ";for (i = 0; i < 26; i++) {//key[i] = rand() % 1000;printf("%c ", key[i]);btree_insert(&T, key[i]);}btree_print(&T, T.root, 0);for (i = 0; i < 26; i++) {printf("\n---------------------------------\n");btree_delete(&T, key[25 - i]);//btree_traverse(T.root);btree_print(&T, T.root, 0);}
}相关文章:
磁盘存储链式结构——B树与B+树
红黑树处理数据都是在内存中,考虑的都是内存中的运算时间复杂度。如果我们要操作的数据集非常大,大到内存已经没办法处理了该怎么办呢? 试想一下,为了要在一个拥有几十万个文件的磁盘中查找一个文本文件,设计的…...
如何批量从sql语句中提取表名
简介 使用的卢易表 的提取表名功能,可以从sql语句中批量提取表名。采用纯文本sql语法分析,无需连接数据库,支持从含非sql语句的文件文件中提取,支持各类数据库sql语法。 特点 快:从成百个文件中提取上千个表名只需1…...
怎么把音频的速度调慢?6个方法调节音频速度
怎么把音频的速度调慢?调慢音频速度不仅可以帮助我们更好地捕捉细节,还能让我们在分析和学习时更加从容。这对于音乐爱好者来说,尤其有助于理解复杂的旋律和和声,使学习过程变得更加高效。而在语言学习中,放慢语速则能…...

K8s-services+pod详解1
一、Service 我们能够利用Deployment创建一组Pod来提供具有高可用性的服务。 虽然每个Pod都会分配一个单独的Pod IP,然而却存在如下两问题: Pod IP 会随着Pod的重建产生变化Pod IP 仅仅是集群内可见的虚拟IP,外部无法访问 这样对于访问这…...

从RNN讲起(RNN、LSTM、GRU、BiGRU)——序列数据处理网络
文章目录 RNN(Recurrent Neural Network,循环神经网络)1. 什么是RNN?2. 经典RNN的结构3. RNN的主要特点4. RNN存在问题——长期依赖(Long-TermDependencies)问题 LSTM(Long Short-Term Memory&a…...

python:假的身份信息生成模块faker
前言 发现一个有趣的python模块(faker),他支持生成多个国家语言下的假身份信息,包含人名、地址、邮箱、公司名、电话号码、甚至是个人简历! 你可以拿它做一些自动化测试,或一些跟假数据有关的填充工作。 代…...

spring task的使用场景
spring task 简介 spring task 是spring自带的任务调度框架按照约定的时间执行某个方法的工具,类似于闹钟 应用场景 cron表达式 周和日两者必定有一个是问号 简单案例...

美畅物联丨剖析 GB/T 28181 与 GB 35114:视频汇聚领域的关键协议
我们在使用畅联云平台进行视频汇聚时,经常会用的GB/T 28181协议,前面我们写了关于GB/T 28181的相关介绍, 详见《畅联云平台|关于GB28181你了解多少?》。 最近也有朋友向我们咨询GB 35114协议与GB/T 28181有什么不同…...

uni-app 开发的应用快速构建成鸿蒙原生应用
uni-app 是一个使用 Vue.js 开发所有前端应用的框架,它支持编译到 iOS、Android、小程序等多个平台。对于 HarmonyOS(鸿蒙系统),uni-app 提供了特定的支持,允许开发者构建鸿蒙原生应用。 一、uni-app 对 HarmonyOS 的支…...

代码随想录算法训练营| 669. 修剪二叉搜索树 、 108.将有序数组转换为二叉搜索树 、 538.把二叉搜索树转换为累加树
669. 修剪二叉搜索树 题目 参考文章 思路:这题其实就是删除不符合上下边界的节点。注意:这里删除不符合上下边界节点时,这个不符合上下边界的节点的左或右子树可能存在符合上下边界的节点,所i有每次比较完之后,要继…...

Django模型实现外键自关联
Django模型实现外键自关联 1、场景 省市区、评论 2、模型models.py from django.db import models 资讯评论:资讯,用户,是否取消,时间class CommentInfomation(models.Model):info = models...
Android ViewModel
一问:ViewModel如何保证应用配置变化后能够自动继续存在,其原理是什么,ViewModel的生命周期和谁绑定的? ViewModel 的确能够在应用配置发生变化(例如屏幕旋转)后继续存在,这得益于 Android 系统的 ViewMod…...

优先算法1--双指针
“一念既出,万山无阻。”加油陌生人! 目录 1.双指针--移动零 2.双指针-复写零 ok,首先在学习之前,为了方便大家后面的学习,我们这里需要补充一个知识点,我这里所谓的指针,不是之前学习的带有…...

利用弹性盒子完成移动端布局(第二次实验作业)
需要实现的效果如下: 下面是首先是这个项目的框架: 然后是html页面的代码: <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"wid…...
C# 字符串(string)三个不同的处理方法:IsNullOrEmpty、IsInterned 、IsNullOrWhiteSpace
在C#中,string.IsNullOrEmpty、string.IsInterned 和 string.IsNullOrWhiteSpace 是三个不同的字符串处理方法,它们各自有不同的用途: 1.string.IsNullOrEmpty: 这个方法用来检查字符串是否为null或者空字符串("…...

读书笔记 - 虚拟化技术 - 0 QEMU/KVM概述与历史
《QEMU/KVM源码解析与应用》 - 王强 概述 虚拟化简介 虚拟化思想 David Wheeler:计算机科学中任何问题都可以通过增加一个中间层来解决。 虚拟化思想存在与计算机科学的各个领域。 主要思想:通过分层将底层的复杂,难用的资源虚拟抽象为简…...

常见的负载均衡
1.常见的负载均衡服务 负载均衡服务是分布式系统中用于分配网络流量和请求的关键组件,它可以帮助提高应用程序的可用性、可扩展性和响应速度。以下是一些常用的负载均衡服务: Nginx:一个高性能的Web服务器和反向代理,广泛用于实现…...

利用sessionStorage收集用户访问信息,然后传递给后端
这里只是简单的收集用户的停留时间、页面加载时间、当前页面URL及来源页面,以做示例 <html><head><meta http-equiv"content-type" content"text/html; charsetUTF-8"/><title>测试sessionStorage存储用户访问信息<…...

什么是Qseven?模块电脑(核心板)规范标准简介二
1.概念 Qseven是一种通用的、小尺寸计算机模块标准,适用于需要低功耗、低成本和高性能的应用。 Qseven模块电脑(核心板)采用230Pin金手指连接器 2.Qseven的起源 Qseven最初是由Congatec、SECO、MSC三家欧洲公司于2008年发起,旨在…...
-有序数组的平方)
leetcode数组(三)-有序数组的平方
题目 . - 力扣(LeetCode) 给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 排序。 例1 输入:nums [-4,-1,0,3,10] 输出:[0,1,9,16,100] 解释&#…...

书成紫微动,律定凤凰驯:别信 “阿紫受控” 的鬼话,海棠山铁哥才是这句诗的正主
“书成紫微动,律定凤凰驯”本是华夏文德盛世的正统谶语, 却在流量的漩涡里被篡改成权谋剧本。 剥离谣言滤镜,回归文本与现世, 世人终将看清: “阿紫受控”纯属无稽, 海棠山铁哥,才是这句古辞唯一…...

数字孪生-三维重建-透明建筑-以智能管控为价值
透明建筑的核心透明建筑,本质上不是 “玻璃造房子”,而是以三维重构为骨架、以空间连续为逻辑、以全域可视为目标、以智能管控为价值的新一代数字孪生空间形态。它的核心可以浓缩为四句话:1. 空间可视核心:打破物理遮挡࿰…...

AssetStudio终极指南:5步解锁Unity游戏资源的完整解决方案
AssetStudio终极指南:5步解锁Unity游戏资源的完整解决方案 【免费下载链接】AssetStudio AssetStudio - Based on the archived Perfares AssetStudio, I continue Perfares work to keep AssetStudio up-to-date, with support for new Unity versions and additio…...

MAX3421E USB主机控制器实战:为微控制器扩展USB外设连接能力
1. 项目概述:为你的微控制器打开USB主机世界的大门如果你玩过Arduino、ESP32或者树莓派Pico这类微控制器,肯定对它们的USB设备功能不陌生——插上电脑就能被识别成一个串口、一个键盘或者一个U盘。但你想过反过来吗?让你的微控制器项目变成“…...

本地大模型一站式图形化工具Hermes-Studio部署与调优指南
1. 项目概述与核心价值最近在折腾本地大模型应用开发时,发现了一个挺有意思的项目,叫 Hermes-Studio。乍一看这个名字,你可能以为是某个新的IDE或者设计工具,但实际上,它是一个专门为本地运行的大型语言模型࿰…...

终极CH55xduino指南:5分钟构建低成本USB微控制器项目
终极CH55xduino指南:5分钟构建低成本USB微控制器项目 【免费下载链接】ch55xduino An Arduino-like programming API for the CH55X 项目地址: https://gitcode.com/gh_mirrors/ch/ch55xduino CH55xduino为CH55X系列低成本MCS51 USB微控制器提供了完整的Ardu…...

Proteus仿真PCA9685踩坑实录:示波器不显示PWM波?可能是I2C调试器惹的祸
Proteus仿真PCA9685实战避坑指南:从波形消失到高效调试 当你在Proteus中搭建好PCA9685电路,满心期待看到整齐的PWM波形时,示波器却一片空白——这种挫败感每个电子工程师都经历过。本文将带你深入Proteus仿真的底层逻辑,揭示I2C调…...

告别臃肿!G-Helper:华硕笔记本轻量控制中心的终极指南
告别臃肿!G-Helper:华硕笔记本轻量控制中心的终极指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, …...
)
STM32F407驱动0.96寸OLED屏:除了SPI,你还可以试试这几种通信方式(I2C/8080对比)
STM32F407驱动0.96寸OLED屏:SPI、I2C与8080接口的深度技术选型指南 当你在STM32F407VET6核心板上连接0.96寸OLED模块时,第一个技术决策往往就是通信接口的选择。这个看似简单的选择实际上会影响整个项目的硬件设计复杂度、软件维护成本以及最终显示性能。…...
)
从聊天到拿Shell:一个Netcat命令的‘黑白’两面实战指南(含正向/反向Shell演示)
从聊天到拿Shell:Netcat命令的双面实战手册 在网络安全领域,很少有工具能像Netcat这样同时扮演"天使"与"恶魔"的双重角色。这个被称为"网络瑞士军刀"的轻量级工具,既能帮助管理员快速排查网络问题,…...