C++进阶:map和set的使用
目录
一.序列式容器和关联式容器
二.set系列的使用
2.1set容器的介绍
2.2set的构造和迭代器
2.3set的增删查
2.4insert和迭代器遍历的样例
2.5find和erase的样例
编辑
2.6multiset和set的差异
2.7简单用set解决两道题
两个数组的交集
环形链表二
三.map系列的使用
3.1map类的介绍
3.2pair类型介绍
3.3map的构造
3.4map的增删查
3.5map的数据修改
3.6构造遍历和增删查使用样例
3.7map的迭代器和[]功能样例
3.8multimap和map的差异
3.9用map解决两道题
随机链表的复制
前k个高频单词
一.序列式容器和关联式容器
关于序列式容器,STL中的如:string、vector、list、deque、array、forward_list等,因为逻辑结构为线性序列的数据结构,两个位置存储的值之间一般没有紧密的关联关系,比如交换一下,他依旧是序列式容器。顺序容器中的元素是按他们在容器中的存储位 置来顺序保存和访问的。
关联式容器也是用来存储数据的,与序列式容器不同的是,关联式容器逻辑结构通常是非线性结构, 两个位置有紧密的关联关系,交换一下,他的存储结构就被破坏了。顺序容器中的元素是按关键字来保存和访问的。关联式容器有map/set系列和unordered_map/unordered_set系列。
map和set底层是红黑树,红黑树是⼀颗平衡二叉搜索树。set是key搜索场景的结构, map是key/value搜索场景的结构。
二.set系列的使用
2.1set容器的介绍
• set的声明如下,T就是set底层关键字的类型
• set默认要求T支持小于比较,如果不支持或者想按自己的需求走可以自行实现仿函数传给第二个模版参数
• set底层存储数据的内存是从空间配置器申请的,如果需要可以自己实现内存池,传给第三个参 数。
• 一般情况下,我们都不需要传后两个模版参数。
• set底层是用红黑树实现,增删查效率是O(logN) ,迭代器遍历是走的搜索树的中序,所以是有序 的。
template < class T, // set::key_type/value_typeclass Compare = less<T>, // set::key_compare/value_compareclass Alloc = allocator<T> // set::allocator_type> class set;2.2set的构造和迭代器
set的支持正向和反向迭代遍历,遍历默认按升序顺序,因为底层是二叉搜索树,迭代器遍历走的中序;支持迭代器就意味着支持范围for,set的iterator和const_iterator都不支持迭代器修改数据,修改关键字数据,破坏了底层搜索树的结构。
//默认构造
explicit set(const key_compare& comp = key_compare(),const allocator_type& alloc = allocator_type());
//迭代器构造
template <class InputIterator>
set(InputIterator first, InputIterator last,const key_compare& comp = key_compare(),const allocator_type& alloc = allocator_type());
//拷贝构造
set(const set& x);
// 正向迭代器
iterator begin();
iterator end();
// 反向迭代器
reverse_iterator rbegin();
reverse_iterator rend();2.3set的增删查
以下是一些我们需要关注的接口
// 单个数据插入,如果已经存在则插入失败
pair<iterator, bool> insert(const value_type& val);// 列表插入,已经在容器中存在的值不会插入
void insert(initializer_list<value_type> il);// 迭代器区间插入,已经在容器中存在的值不会插入
template <class InputIterator>
void insert(InputIterator first, InputIterator last);// 查找val,返回val所在的迭代器,没有找到返回end()
iterator find(const value_type& val);// 查找val,返回Val的个数
size_type count(const value_type& val) const;// 删除一个迭代器位置的值
iterator erase(const_iterator position);// 删除val,val不存在返回0,存在返回1
size_type erase(const value_type& val);// 删除⼀段迭代器区间的值
iterator erase(const_iterator first, const_iterator last);// 返回大于等于val位置的迭代器
iterator lower_bound(const value_type& val) const;// 返回大于val位置的迭代器
iterator upper_bound(const value_type& val) const;2.4insert和迭代器遍历的样例
#include<iostream>
#include<set>
using namespace std;
int main()
{// 去重+升序排序 set<int> s;// 去重+降序排序(给一个大于的仿函数) //set<int, greater<int>> s;s.insert(5);s.insert(2);s.insert(7);s.insert(5);//set<int>::iterator it = s.begin();auto it = s.begin();while (it != s.end()){// error C3892: “it”: 不能给常量赋值 // *it = 1;cout << *it << " ";++it;}cout << endl;// 插入一段initializer_list列表值,已经存在的值插入失败 s.insert({ 2,8,3,9 });for (auto e : s){cout << e << " ";}cout << endl;set<string> strset = { "sort", "insert", "add" };// 遍历string比较ascll码大小顺序遍历的 for (auto& e : strset){cout << e << " ";}cout << endl;
}输出:

2.5find和erase的样例
#include<iostream>
#include<set>
using namespace std;int main()
{set<int> s = { 4,2,7,2,8,5,9 };for (auto e : s){cout << e << " ";}cout << endl;// 删除最小值 s.erase(s.begin());for (auto e : s){cout << e << " ";}cout << endl;// 直接删除xint x;cin >> x;//9int num = s.erase(x);//删除失败返回0if (num == 0){cout << x << "不存在!" << endl;}for (auto e : s){cout << e << " ";}cout << endl;// 直接查找再利用迭代器删除x cin >> x;//8auto pos = s.find(x);if (pos != s.end())//没有查找到返回end(){s.erase(pos);}else{cout << x << "不存在!" << endl;}for (auto e : s){cout << e << " ";}cout << endl;// 算法库的查找 O(N) auto pos1 = find(s.begin(), s.end(), x);// set自身实现的查找 O(logN) auto pos2 = s.find(x);// 利用count间接实现快速查找 cin >> x;//5if (s.count(x)){cout << x << "在!" << endl;}else{cout << x << "不存在!" << endl;}return 0;
}输出:

当然也可以使用lower_bound和upper_bound 来进行区间删除。
#include<iostream>
#include<set>
using namespace std;int main()
{std::set<int> myset;for (int i = 1; i < 10; i++)myset.insert(i * 10); // 10 20 30 40 50 60 70 80 90for (auto e : myset){cout << e << " ";}cout << endl;// 实现查找到的[itlow,itup)包含[30, 60]区间 // 返回 >= 30 auto itlow = myset.lower_bound(30);// 返回 > 60 auto itup = myset.upper_bound(60);// 删除这段区间的值 myset.erase(itlow, itup);for (auto e : myset){cout << e << " ";}cout << endl;return 0;
}2.6multiset和set的差异
multiset和set的使用基本一样,但是multiset支持冗余
#include<iostream>
#include<set>
using namespace std;int main()
{// 相比set不同的是,multiset是排序,但是不去重 multiset<int> s = { 4,2,7,2,4,8,4,5,4,9 };auto it = s.begin();while (it != s.end()){cout << *it << " ";++it;}cout << endl;// 相比set不同的是,x可能会存在多个,find查找中序的第一个 int x;cin >> x;//4auto pos = s.find(x);while (pos != s.end() && *pos == x){cout << *pos << " ";++pos;}cout << endl;// 相比set不同的是,count会返回x的实际个数 cout << s.count(x) << endl;// 相比set不同的是,erase给值时会删除所有的x s.erase(x);for (auto e : s){cout << e << " ";}cout << endl;return 0;
}输出:

2.7简单用set解决两道题
两个数组的交集
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {set<int> s1(nums1.begin(), nums1.end());set<int> s2(nums2.begin(), nums2.end());//进入set后自动去重vector<int> ret;set<int>::iterator it1=s1.begin();set<int>::iterator it2=s2.begin();while(it1!=s1.end()&&it2!=s2.end()){if(*it1<*it2){it1++;}else if(*it1>*it2){it2++;}else{ret.push_back(*it1);it1++;it2++;}}return ret;}
};环形链表二
class Solution {
public:ListNode *detectCycle(ListNode *head) {set<ListNode*> s;ListNode* cur=head;while(cur){pair<set<ListNode*>::iterator,bool> ret=s.insert(cur);if(ret.second==false){return cur;}cur=cur->next;}return nullptr;}
};三.map系列的使用
3.1map类的介绍
map的声明如下,Key就是map底层关键字的类型,T是map底层value的类型,map默认要求Key支持小于比较,如果不支持或者需要的话可以自行实现仿函数传给第二个模版参数,map底层存储数据的内存是从空间配置器申请的。⼀般情况下,我们都不需要传后两个模版参数。map底层是用红黑树实 现,增删查改效率是O(logN) ,迭代器遍历是走的中序,所以是按key有序顺序遍历的。
template < class Key, // map::key_typeclass T, // map::mapped_typeclass Compare = less<Key>, // map::key_compareclass Alloc = allocator<pair<const Key, T> > // map::allocator_type> class map;3.2pair类型介绍
介绍pair类型之前要先了解pair是什么。map底层的红⿊树节点中的数据,使用pair存储键值对数据。
typedef pair<const Key, T> value_type;
template<class T1,class T2>
struct pair
{typedef T1 first_type;typedef T2 second_type;T1 first;T2 second;//默认构造函数pair(): first(T1()), second(T2()){}//拷贝构造函数pair(const T1& a, const T2& b) : first(a), second(b){}//用另一个pair拷贝构造template<class U, class V>pair(const pair<U, V>& pr) : first(pr.first), second(pr.second){}
};
template <class T1, class T2>
inline pair<T1, T2> make_pair(T1 x, T2 y)
{return (pair<T1, T2>(x, y));
}3.3map的构造
map的支持正向和反向迭代遍历,遍历默认按key的升序顺序,因为底层是二叉搜索树,迭代器遍历走的中序;支持迭代器就意味着支持范围for,map支持修改value数据,不支持修改key数据,修改关键字数据,破坏了底层搜索树的结构。
//无参默认构造
explicit map(const key_compare& comp = key_compare(),const allocator_type& alloc = allocator_type());
//迭代器区间构造
template <class InputIterator>
map(InputIterator first, InputIterator last,const key_compare& comp = key_compare(),const allocator_type& alloc = allocator_type());
//拷贝构造
map(const map& x);
//列表构造
map(initializer_list<value_type> il,const key_compare& comp = key_compare(),const allocator_type& alloc = allocator_type());
// 正向迭代器
iterator begin();
iterator end();
// 反向迭代器
reverse_iterator rbegin();
reverse_iterator rend();3.4map的增删查
map增接口,插入的pair键值对数据,跟set所有不同,但是查和删的接口只⽤关键字key跟set是完全类似的,不过find返回iterator,不仅仅可以确认key在不在,还找到key映射的value,同时通过迭代器还可以修改value。
key_type->The first template parameter(Key)
mapped_type->The second template parameter(T)
value_type->pair<const key_type, mapped_type>
// 单个数据插入,如果已经key存在则插入失败,key存在相等value不相等也会插入失败
pair<iterator, bool> insert(const value_type& val);// 列表插入,已经在容器中存在的值不会插入
void insert(initializer_list<value_type> il);// 迭代器区间插入,已经在容器中存在的值不会插入
template <class InputIterator>
void insert(InputIterator first, InputIterator last);// 查找k,返回k所在的迭代器,没有找到返回end()
iterator find(const key_type& k);// 查找k,返回k的个数
size_type count(const key_type& k) const;// 删除⼀个迭代器位置的值
iterator erase(const_iterator position);// 删除k,k存在返回0,存在返回1
size_type erase(const key_type& k);// 删除一段迭代器区间的值
iterator erase(const_iterator first, const_iterator last);// 返回大于等k位置的迭代器
iterator lower_bound(const key_type& k);// 返回大于k位置的迭代器
const_iterator lower_bound(const key_type& k) const;3.5map的数据修改
map支持修改mapped_type数据,不支持修改key数据,修改关键字数据,破坏了底层搜索树的结构。
map第一个支持修改的方式时通过迭代器,迭代器遍历时或者find返回key所在的iterator修改,map还有一个非常重要的修改接口operator[],但是operator[]不仅仅支持修改,还支持插入数据和查找数据,所以他是一个多功能复合接口
// 查找k,返回k所在的迭代器,没有找到返回end(),如果找到了通过iterator可以修改key对应的
//mapped_type值
iterator find(const key_type& k);
// insert插入⼀个pair<key, T>对象
// 1、如果key已经在map中,插入失败,则返回一个pair<iterator,bool>对象,返回pair对象
//first是key所在结点的迭代器,second是false
// 2、如果key不在在map中,插入成功,则返回一个pair<iterator,bool>对象,返回pair对象
//first是新插入key所在结点的迭代器,second是true
// 也就是说无论插入成功还是失败,返回pair<iterator,bool>对象的first都会指向key所在的迭
//代器
// 那么也就意味着insert插入失败时充当了查找的功能,正是因为这一点,insert可以用来实现
//operator[]
// 需要注意的是这里有两个pair,不要混淆了,一个是map底层红黑树节点中存的pair<key, T>,另
//一个是insert返回值pair<iterator, bool>pair<iterator, bool> insert(const value_type& val);
mapped_type& operator[] (const key_type& k);
// operator的内部实现
mapped_type& operator[] (const key_type& k)
{// 1、如果k不在map中,insert会插入k和mapped_type默认值,同时[]返回结点中存储//mapped_type值的引用,那么我们可以通过引用修改返映射值。所以[]具备了插入 + 修改功能// 2、如果k在map中,insert会插入失败,但是insert返回pair对象的first是指向key结点的//迭代器,返回值同时[]返回结点中存储mapped_type值的引用,所以[]具备了查找 + 修改的功能pair<iterator, bool> ret = insert({ k, mapped_type() });iterator it = ret.first;return it->second;
}3.6构造遍历和增删查使用样例
#include<iostream>
#include<map>
using namespace std;
int main()
{map<string,string> dict = { {"left", "左边"}, {"right", "右边"},
{"insert", "插入"},{ "string", "字符串" } };//map<string, string>::iterator it = dict.begin();auto it = dict.begin();while (it != dict.end()){//cout << (*it).first <<":"<<(*it).second << endl;// map的迭代基本都使用operator->,这里省略了一个-> // 第一个->是迭代器运算符重载,返回pair*,第二个箭头是结构指针解引用取pair数据//cout << it.operator->()->first << ":" << it.operator->()-> second << endl;cout << it->first << ":" << it->second << endl;++it;}cout << endl;// insert插入pair对象的4种方式,对比之下,最后一种最方便 pair<string, string> kv1("first", "第一个");dict.insert(kv1);dict.insert(pair<string, string>("second", "第二个"));dict.insert(make_pair("sort", "排序"));dict.insert({ "auto", "自动的" });// "left"已经存在,插入失败 dict.insert({ "left", "左边,剩余" });// 范围for遍历 for (const auto& e : dict){cout << e.first << ":" << e.second << endl;}cout << endl;string str;while (cin >> str){auto ret = dict.find(str);if (ret != dict.end()){cout << "->" << ret->second << endl;}else{cout << "无此单词,请重新输入" << endl;}} return 0;
}输出:

3.7map的迭代器和[]功能样例
#include<iostream>
#include<map>
#include<string>
using namespace std;
int main()
{// 利用find和iterator修改功能,统计水果出现的次数 string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜","苹果", "香蕉", "苹果", "香蕉" };map<string, int> countMap;for (const auto& str : arr){// 先查找水果在不在map中 // 1、不在,说明水果第⼀次出现,则插入{水果, 1} // 2、在,则查找到的节点中水果对应的次数++ map<string,int>::iterator ret = countMap.find(str);if (ret == countMap.end()){countMap.insert({ str, 1 });}else{ret->second++;}}for (const auto& e : countMap){cout << e.first << ":" << e.second << endl;}cout << endl;return 0;
}#include<iostream>
#include<map>
#include<string>
using namespace std;int main()
{// 利用[]插入+修改功能,巧妙实现统计水果出现的次数 string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜","苹果", "香蕉", "苹果", "香蕉" };map<string, int> countMap;for (const auto& str : arr){// []先查找水果在不在map中 // 1、不在,说明水果第一次出现,则插入{水果, 0},同时返回次数的引用,++一下就变成1次了// 2、在,则返回水果对应的次数++ countMap[str]++;}for (const auto& e : countMap){cout << e.first << ":" << e.second << endl;}cout << endl;return 0;
}
#include<iostream>
#include<map>
#include<string>
using namespace std;int main()
{map<string, string> dict;dict.insert(make_pair("sort", "排序"));// key不存在->插入 {"insert", string()} dict["insert"];// 插入+修改 dict["left"] = "左边";// 修改 dict["left"] = "左边、剩余";// key存在->查找 cout << dict["left"] << endl;for (const auto& e : dict){cout << e.first << ":" << e.second << endl;}return 0;
} 
3.8multimap和map的差异
multimap和map的使用基本完全类似,主要区别点在于multimap支持关键值key冗余,那么 insert/find/count/erase都围绕着支持关键值key冗余有所差异,这里跟set和multiset完全⼀样,比如find时,有多个key,返回中序第一个。其次就是multimap不支持[],因为支持key冗余,[]就只能支持插入了,不能支持修改。
3.9用map解决两道题
随机链表的复制
class Solution {
public:Node* copyRandomList(Node* head) {map<Node*,Node*> nodemap;Node* copyhead=nullptr;Node* copytail=nullptr;Node* cur=head;//先不管random,把所有节点复制下来while(cur){if(copytail==nullptr){copyhead=copytail=new Node(cur->val);}else{copytail->next=new Node(cur->val);copytail=copytail->next;}//原链表节点与copy的链表节点一一赋值给mapnodemap[cur]=copytail;cur=cur->next;}cur=head;Node* copy=copyhead;//之后再去管randomwhile(cur){if(cur->random==nullptr){copy->random=nullptr;}else{//因为原链表的random指针指向的位置我们都知道//在nodemap里节点是一一对应的,cur的random指向,我们可以利用map得到我们复制链表里的位置//nodemap[cur->random]==我们复制链表里的,与原链表random指向对应的节点copy->random=nodemap[cur->random];}cur=cur->next;copy=copy->next;}return copyhead;}
};前k个高频单词
class Solution {typedef pair<string,int> PSI;struct cmp{bool operator()(const PSI& a,const PSI& b){if(a.second==b.second)//频次相同,创建大根堆{return a.first < b.first;//比较字典序}//创建小根堆return a.second > b.second;//比较频次}};
public:vector<string> topKFrequent(vector<string>& words, int k) {map<string,int> hash;//用哈希表统计每个单词出现的次数for(auto& e:words){hash[e]++;}priority_queue<PSI,vector<PSI>,cmp> heap;//heap里只保存k个PSIfor(auto& s:hash){heap.push(s);if(heap.size()>k) heap.pop();}vector<string> ret(k);//注意顺序,因为升序建大堆,降序建小堆,堆顶元素与我们想要的是反着的for(int i=k-1;i>=0;i--){ret[i]=heap.top().first;heap.pop();}return ret;}
};相关文章:
C++进阶:map和set的使用
目录 一.序列式容器和关联式容器 二.set系列的使用 2.1set容器的介绍 2.2set的构造和迭代器 2.3set的增删查 2.4insert和迭代器遍历的样例 2.5find和erase的样例 编辑 2.6multiset和set的差异 2.7简单用set解决两道题 两个数组的交集 环形链表二 三.map系列的使用…...

深入理解C++ STL中的 vector
文章目录 1. vector 的概述1.1 vector 是什么?1.2 vector 的优点1.3 vector 的缺点 2. vector 的基本使用2.1 vector 的定义2.2 基本操作2.3 示例2.4 迭代器的使用 3. vector 的内部实现原理3.1 动态数组的实现3.2 内存管理3.3 内存扩展策略3.4 元素的插入与删除3.4…...

MySQL 安装与配置详细教程
MySQL 安装与配置详细教程 MySQL 是一款流行的关系型数据库管理系统,广泛应用于 Web 应用和应用程序中。在本文中,我们将提供一份详细的 MySQL 安装与配置教程,帮助初学者快速上手。 ## 1. 安装 MySQL 首先,我们需要从 MySQL 官…...

理解智能合约:区块链在Web3中的运作机制
随着区块链技术的不断发展,“智能合约”这一概念变得越来越重要。智能合约是区块链应用的核心之一,正在推动Web3的发展,为数字世界带来了前所未有的自动化和信任机制。本文将深入探讨智能合约的基本原理、运作机制,以及它在Web3生…...

QT工程概述
在Qt中,创建 "MainWindow" 与 "Widget" 项目的主要区别在于他们的用途和功能范围: MainWindow:这是一个包含完整菜单栏、工具栏和状态栏的主窗口应用程序框架。它适合于更复 杂的应用程序,需要这些额外的用户…...

redis安装 | 远程连接
1.redis的安装 在Ubuntu下安装redis【网址】使用root账号使用apt来安装。使用apt安装比较的方便,但是安装的版本可能就不是最新的版本。 $ su root $ apt list --installed | grep redis # 查看是否安装 $ apt search redis # 查看apt中的redis版本 $ apt install…...

性价比高的宠物空气净化器应该怎么挑?有哪几款推荐?
前几年和朋友住在一起之后就一起养了两只猫,没想到刚开始还好,到后期之后,我和朋友都苦不堪言,有泪都流不出。 主要是猫咪掉毛实在是太严重了,下班回去之后,发现朋友在打扫家里,又是擦又是扫的…...

Golang | Leetcode Golang题解之第466题统计重复个数
题目: 题解: func getMaxRepetitions(s1 string, n1 int, s2 string, n2 int) int {n : len(s2)cnt : make([]int, n)for i : 0; i < n; i {// 如果重新给一个s1 并且s2是从第i位开始匹配 那么s2可以走多少位(走完了就从头开始走p1, p2 :…...

设计模式 - 行为模式
行为模式 观察者模式,策略模式,命令模式,中介者模式,备忘录模式,模板方法模式,迭代器模式,状态模式,责任链模式,解释器模式,访问者模式 保存/封装 行为/请求…...

InstructGPT的四阶段:预训练、有监督微调、奖励建模、强化学习涉及到的公式解读
1. 预训练 1. 语言建模目标函数(公式1): L 1 ( U ) ∑ i log P ( u i ∣ u i − k , … , u i − 1 ; Θ ) L_1(\mathcal{U}) \sum_{i} \log P(u_i \mid u_{i-k}, \dots, u_{i-1}; \Theta) L1(U)i∑logP(ui∣ui−k,…,ui−1;Θ…...

没有HTTPS 证书时,像这样实现多路复用
在没有 HTTPS 证书的情况下,HTTP/2 通常不能直接通过 HTTP 协议使用。虽然 HTTP/2 协议的规范是可以支持纯 HTTP 连接(即通过 http:// 协议),但大多数主流浏览器(如 Chrome、Firefox)都 强制要求 HTTP/2 必须在 HTTPS 上运行。这是出于安全和隐私的考虑。 因此,如果你没…...

2.1.ReactOS系统NtReadFile函数的实现。
ReactOS系统NtReadFile函数的实现。 ReactOS系统NtReadFile函数的实现。 文章目录 ReactOS系统NtReadFile函数的实现。NtReadFile函数的定义NtReadFile函数的实现 NtReadFile()是windows的一个系统调用,内核中有一个叫NtReadFile的函数 NtReadFile函数的定义 NTS…...

2020-11-06《04丨人工智能时代,新的职业机会在哪里?》
《香帅中国财富报告25讲》 04丨人工智能时代,新的职业机会在哪里? 1、新机会的三个诞生方向 前两讲我们都在说,人工智能的出现会极大地冲击现有的职业,从2020年开始,未来一二十年,可能有一半以上的职业都会…...
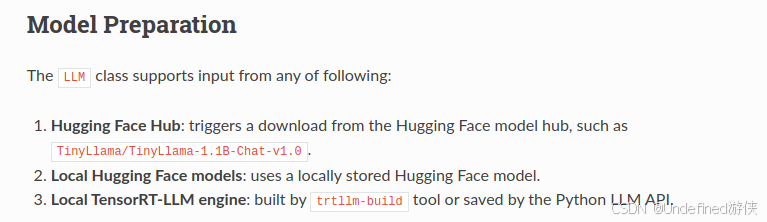
TensorRT-LLM七日谈 Day5
模型加载 在day2, 我们尝试了对于llama8B进行转换和推理,可惜最后因为OOM而失败,在day4,我们详细的过了一遍tinyllama的推理,值得注意的是,这两个模型的推理走的是不同的流程。llama8b需要显式的进行模型的转换,引擎的…...

使用Java Socket实现简单版本的Rpc服务
通过如下demo,希望大家可以快速理解RPC的简单案例。如果对socket不熟悉的话可以先看下我的上篇文章 Java Scoket实现简单的时间服务器-CSDN博客 对socket现有基础了解。 RPC简介 RPC(Remote Procedure Call,远程过程调用)是一种…...

P2P 网络 简单研究 1
起因, 目的: P2P 网络, 一道题。题目描述, 在下面。 P2P 网络,我以前只是听说过,并不深入。如果我有5台电脑的话,我也想深入研究一下。 P2P 简介: P2P(Peer-to-Peer)网络是一种分…...

RAG(检索增强生成)面经(1)
1、RAG有哪几个步骤? 1.1、文本分块 第一个步骤是文本分块(chunking),这是一个重要的步骤,尤其在构建与处理文档的大型文本的时候。分块作为一种预处理技术,将长文档拆分成较小的文本块,这些文…...

卫爱守护|守护青春,送出温暖
2024年10月10日,艾多美爱心志愿者来到校园。艾多美“卫艾守护”项目于吉林省白山市政务大厅会议室举办了捐赠仪式,东北区外事部经理黄山出席了捐赠仪式仪式,为全校女同学捐赠了青春关爱包。 此次捐赠,面向吉林省自山市第十八中学、…...

ubuntu-24.04.1 系统安装
使用VMware虚拟机上进行实现 官网下载地址: https://cn.ubuntu.com/download https://releases.ubuntu.com 操作系统手册: https://ubuntu.com/server/docs/ (里面包含安装文档) 安装指南(详细):…...

华为OD机试真题---生成哈夫曼树
华为OD机试中关于生成哈夫曼树的题目通常要求根据给定的叶子节点权值数组,构建一棵哈夫曼树,并按照某种遍历方式(如中序遍历)输出树中节点的权值序列。以下是对这道题目的详细解析和解答思路: 一、题目要求 给定一个…...

从零构建IoT图像流:ESP32-CAM自动抓拍与App Inventor安卓端动态展示
1. ESP32-CAM硬件准备与环境搭建 第一次接触ESP32-CAM时,我被这个小巧的硬件惊艳到了——它集成了摄像头模块和WiFi功能,价格却不到百元。不过在实际操作中,我发现新手最容易卡在硬件连接环节。这里分享几个实测有效的技巧: 供电问…...

如何快速掌握深度学习调参技巧:tuning_playbook_zh_cn完全解析
如何快速掌握深度学习调参技巧:tuning_playbook_zh_cn完全解析 【免费下载链接】tuning_playbook_zh_cn 一本系统地教你将深度学习模型的性能最大化的战术手册。 项目地址: https://gitcode.com/gh_mirrors/tu/tuning_playbook_zh_cn tuning_playbook_zh_cn是…...

我的家庭影音中心进化史:从群晖到用Ubuntu+CasaOS自建,省下大几千
我的家庭影音中心进化史:从群晖到UbuntuCasaOS自建方案 1. 为什么放弃品牌NAS选择自建方案 三年前,我花了大半个月工资购入了一台群晖DS920,当时觉得这是家庭数据管理的终极解决方案。然而随着使用深入,逐渐发现品牌NAS的几大痛点…...

BGP路由优化实战:加速收敛,提升网络稳定性
BGP路由优化实战:加速收敛,提升网络稳定性在复杂的网络环境中,尤其是在大规模数据中心或跨区域互联的网络中,BGP(Border Gateway Protocol)路由协议的性能直接影响着网络的可用性和用户体验。BGP 作为互联网…...

流程越来越规范,但员工体验却越来越差
在很多企业推进 IT 管理规范化的过程中,流程建设往往是重点。 审批流程更加清晰,操作步骤更加标准,所有请求都可以通过系统统一管理。从管理角度来看,这是明显的进步。 流程可控、操作可追溯、风险也更容易管理。但从员工的实际体…...

AsyncAPI通道管理终极指南:如何高效组织消息流的关键技巧
AsyncAPI通道管理终极指南:如何高效组织消息流的关键技巧 【免费下载链接】spec The AsyncAPI specification allows you to create machine-readable definitions of your asynchronous APIs. 项目地址: https://gitcode.com/gh_mirrors/spec/spec AsyncAPI…...

低功耗设计避坑指南:从UPF报错案例学习isolation rules的正确姿势
低功耗设计避坑指南:从UPF报错案例学习isolation rules的正确姿势 在芯片设计领域,低功耗已成为衡量产品竞争力的核心指标之一。随着工艺节点不断演进,静态功耗占比显著提升,使得电源门控(Power Gating)技术…...

4步打造高效能开源路由器:OpenWrt固件安装指南
4步打造高效能开源路由器:OpenWrt固件安装指南 【免费下载链接】openwrt openwrt编译更新库X86-R2C-R2S-R4S-R5S-N1-小米MI系列等多机型全部适配OTA自动升级 项目地址: https://gitcode.com/GitHub_Trending/openwrt5/openwrt OpenWrt固件安装是提升R5S设备性…...

MAX30102传感器寄存器深度解析与实战配置指南
1. MAX30102传感器核心功能解析 MAX30102是一款集成了红光和红外光LED的光学传感器,专门用于非侵入式心率监测和血氧饱和度(SpO2)测量。这个火柴盒大小的芯片内部藏着精密的模拟前端和数字信号处理单元,能够捕捉到人体脉搏带来的微弱光信号变化。 我第一…...

Unity坐标系实战解析:从localPosition到Position的层级关系与应用场景
1. 理解Unity中的坐标系基础 在Unity开发中,坐标系系统是构建3D世界的基石。很多新手开发者容易混淆localPosition和Position的概念,导致物体位置控制出现各种"灵异现象"。我们先从一个生活场景来理解:想象你站在客厅里(…...