生成一个带有二维数据和对应标签的螺旋形数据集(非线性可分数据集)的代码解析
def create_dataset():np.random.seed(1)m = 400 # 数据量N = int(m/2) # 每个标签的实例数D = 2 # 数据维度X = np.zeros((m,D)) # 数据矩阵Y = np.zeros((m,1), dtype='uint8') # 标签维度a = 4 for j in range(2):ix = range(N*j,N*(j+1))t = np.linspace(j*3.12,(j+1)*3.12,N) + np.random.randn(N)*0.2 # thetar = a*np.sin(4*t) + np.random.randn(N)*0.2 # radiusX[ix] = np.c_[r*np.sin(t), r*np.cos(t)]Y[ix] = jX = X.TY = Y.Treturn X, Y
这个函数 create_dataset 生成一个带有二维数据和对应标签的螺旋形数据集。螺旋形数据集是用于分类任务的典型数据集之一,尤其在测试复杂分类模型(如神经网络)时经常使用。以下是对这个函数的详细解释:
1. 参数与初始化
np.random.seed(1)
m = 400 # 数据集的总数量
N = int(m/2) # 每个类别(标签)的样本数量
D = 2 # 数据的维度(二维数据)
X = np.zeros((m,D)) # 初始化数据矩阵X,大小为 m x D
Y = np.zeros((m,1), dtype='uint8') # 初始化标签矩阵Y,大小为 m x 1,数据类型为无符号8位整数
a = 4 # 控制数据螺旋的半径
np.random.seed(1):确保随机数的可重复性,每次运行生成的数据集是相同的。m = 400:数据集的总样本数。N = int(m/2):每个类别的样本数为一半(即 200 个样本属于类别 0,另外 200 个样本属于类别 1)。D = 2:数据的维度为 2(表示二维数据)。X = np.zeros((m,D)):初始化大小为 m × D m \times D m×D 的零矩阵,用于存储样本特征。Y = np.zeros((m,1), dtype='uint8'):初始化大小为 m × 1 m \times 1 m×1 的零矩阵,用于存储样本标签。
2. 生成数据
for j in range(2):ix = range(N*j,N*(j+1)) # 生成当前类的索引范围t = np.linspace(j*3.12,(j+1)*3.12,N) + np.random.randn(N)*0.2 # 角度 thetar = a*np.sin(4*t) + np.random.randn(N)*0.2 # 半径 rX[ix] = np.c_[r*np.sin(t), r*np.cos(t)] # 生成二维坐标 (x1, x2)Y[ix] = j # 为当前生成的数据赋予标签 j
这个循环迭代两次(一次生成类别 0 的数据,一次生成类别 1 的数据),生成螺旋形数据。具体步骤如下:
-
ix = range(N*j, N*(j+1)):当前类别样本的索引范围。第一次循环时生成类别 0 的样本,索引为 0 到 199;第二次循环时生成类别 1 的样本,索引为 200 到 399。 -
t = np.linspace(j*3.12, (j+1)*3.12, N) + np.random.randn(N)*0.2:生成从 j × 3.12 j \times 3.12 j×3.12 到 ( j + 1 ) × 3.12 (j+1) \times 3.12 (j+1)×3.12 的角度theta,并在每个点上添加一些随机噪声(np.random.randn(N)*0.2)。这些角度用于控制螺旋形的弯曲程度。 -
r = a*np.sin(4*t) + np.random.randn(N)*0.2:生成半径r,即样本离原点的距离。半径是一个基于sin(4t)的函数,并添加了随机噪声(np.random.randn(N)*0.2)以增加数据集的多样性。这个函数生成螺旋的曲线形状。 -
X[ix] = np.c_[r*np.sin(t), r*np.cos(t)]:利用极坐标 ( r , t ) (r, t) (r,t) 计算二维笛卡尔坐标 ( x 1 , x 2 ) (x_1, x_2) (x1,x2),并将其存储在数据矩阵X中。 -
Y[ix] = j:为当前类别的样本赋值为j(即当前类别的标签)。
3. 返回值
X = X.T
Y = Y.T
return X, Y
X.T:转置后的数据矩阵,输出大小为 2 × m 2 \times m 2×m,表示 2 个特征和 m m m 个样本。Y.T:转置后的标签矩阵,输出大小为 1 × m 1 \times m 1×m,每个样本对应一个标签。
4. 总结
该函数 create_dataset() 生成了一个螺旋形数据集,数据集具有以下特点:
- 数据集分为两个类别,每个类别各有 200 个样本。
- 数据点以螺旋形状分布,这对线性分类器(如线性支持向量机、感知机等)来说是一个较为复杂的分类任务,因为螺旋形数据通常是非线性可分的。
- 随机噪声的加入使得数据更具挑战性,有助于测试复杂模型(如神经网络)的分类能力。
相关文章:
的代码解析)
生成一个带有二维数据和对应标签的螺旋形数据集(非线性可分数据集)的代码解析
def create_dataset():np.random.seed(1)m 400 # 数据量N int(m/2) # 每个标签的实例数D 2 # 数据维度X np.zeros((m,D)) # 数据矩阵Y np.zeros((m,1), dtypeuint8) # 标签维度a 4 for j in range(2):ix range(N*j,N*(j1))t np.linspace(j*3.12,(j1)*3.12,N) np.rando…...
 函数的作用)
PHP unset() 函数的作用
PHP 中的 unset() 函数用于销毁指定的变量。具体来说,它会解除变量名与其数据之间的关联,从而释放该变量所占用的内存。不过需要注意的是,unset() 并不是删除变量的内容,而是取消对变量名的引用。如果变量是数组中的某个元素或者对…...

长篇故事可视化方法Story-Adapter:能够生成更高质量、更具细腻交互的故事图像,确保每一帧都能准确地传达故事情节。
今天给大家介绍一个最新的长篇故事可视化方法Story-Adapter,它的工作原理可以想象成一个画家在创作一幅长画卷。首先,画家根据故事的文本提示画出初步的图像。这些图像就像是画卷的草图。接下来,画家会不断回顾这些草图,逐步添加细…...

C++基础面试题 | 什么是C++中的运算符重载?
文章目录 回答重点:示例: 运算符重载的基本规则和注意事项: 回答重点: C的运算符重载是指可以为自定义类型(如类或结构体)定义运算符的行为,使其像内置类型一样使用运算符。通过重载运算符&…...

深入 IDEA 字节码世界:如何轻松查看 .class 文件?
前言: 作为一名 Java 开发者,理解字节码对于优化程序性能、调试错误以及深入了解 JVM 运行机制非常重要。IntelliJ IDEA 作为最流行的开发工具之一,为开发者提供了查看 .class 文件字节码的功能。在本文中,我将带你一步步探索如何…...

NodeJS 利用代码生成工具编写GRPC
生成的 gRPC 代码优点 自动化和效率: 减少手动编码:生成代码自动处理了消息的序列化和反序列化、服务接口的定义等,减少了手动编码的工作量。一致性:生成的代码确保了客户端和服务器之间的一致性,避免了手动编码可能带来的错误。跨语言支持: 多语言兼容:gRPC 支持多种编…...

uni-app基础语法(一)
我们今天的学习目标 基础语法1. 创建新页面2.pages配置页面3.tabbar配置4.condition 启动模式配置 基础语法 1. 创建新页面 2.pages配置页面 属性类型默认值描述pathString配置页面路径styleObject配置页面窗口表现,配置项参考pageStyle 我们来通过style修改页面的…...

Linux:进程控制(三)——进程程序替换
目录 一、概念 二、使用 1.单进程程序替换 2.多进程程序替换 3.exec接口 4.execle 一、概念 背景 当前进程在运行的时候,所执行的代码来自于自己的源文件。使用fork创建子进程后,子进程执行的程序中代码内容和父进程是相同的,如果子进…...

LeetCode279:完全平方数
题目链接:279. 完全平方数 - 力扣(LeetCode) 代码如下 class Solution { public:int numSquares(int n) {vector<int> dp(n 1, INT_MAX);dp[0] 0;for(int i 1; i * i < n; i){for(int j i * i; j < n; j){dp[j] min(dp[j …...

python爬虫--某动漫信息采集
python爬虫--tx动漫 一、采集主页信息二、采集详情页信息三、代码供参考一、采集主页信息 略。 二、采集详情页信息 如上图所示,使用xpath提取详情页的标题、作者、评分、人气、评论人数等数据。 三、代码供参考 import csv import time import random import requests fr…...
使用Rollup.js快速开始构建一个前端项目
Rollup 是一个用于 JavaScript 项目的模块打包器,它将小块代码编译成更大、更复杂的代码,例如库或应用程序。Rollup 对代码模块使用 ES6 模块标准,它支持 Tree-shaking(摇树优化),可以剔除那些实际上没有被…...

10.15学习
1.程序开发的步骤 定义程序的目标→设计程序→编写代码(需要选择语言,一种语言对应一种编译器)→编译→运行程序→测试和调试程序→维护和修改程序 2.ANSI/ISO C标准 1989年ANSI批准通过,1990年ISO批准通过,因此被称…...

mongodb-7.0.14分片副本集超详细部署
mongodb介绍: 是最常用的nosql数据库,在数据库排名中已经上升到了前六。这篇文章介绍如何搭建高可用的mongodb(分片副本)集群。 环境准备 系统系统 BC 21.10 三台服务器:192.168.123.247/248/249 安装包:…...

C++运算出现整型溢出
考虑如下代码: int aINT_MAX; int b 1; long c ab; 这段代码没有编过! 原因是a和b都是int型,相加之后会溢出。 请记住,c语言没有赋值,只有表达式,右侧会存在一个暂存的int保存ab的值,而明…...

LeetCode岛屿数量
题目描述 给你一个由 1(陆地)和 0(水)组成的的二维网格,请你计算网格中岛屿的数量。 岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。 此外,你可以假设该网…...
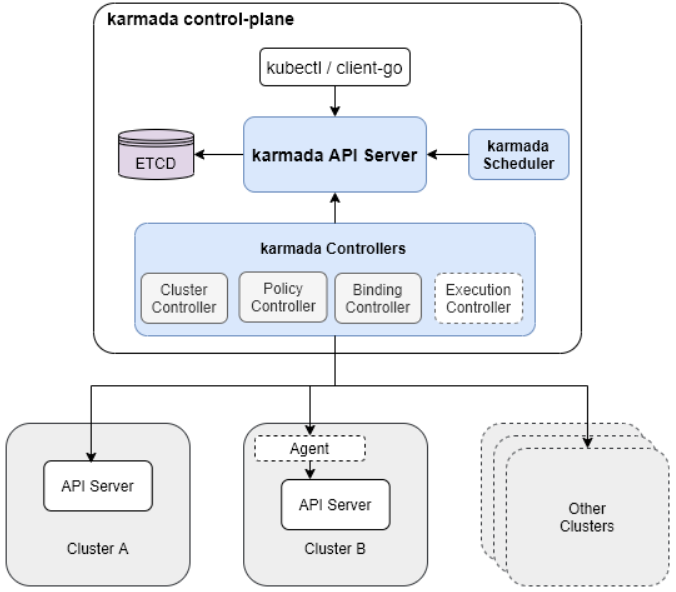
Karmada核心概念
以下内容为翻译,原文地址 Karmada 是什么? | karmada 一、Karmada核心概念 一)什么是Karmada 1、Karmada:开放,多云,多集群Kubernetes业务流程 Karmada (Kubernetes Armada)是一个Kubernetes管理系统&…...

Rust 与生成式 AI:从语言选择到开发工具的演进
在现代软件开发领域,Rust 语言正在逐步崭露头角,尤其是在高性能和可靠性要求较高的应用场景。与此同时,生成式 AI 的崛起正在重新塑造开发者的工作方式,从代码生成到智能调试,生成式 AI 的应用正成为提升开发效率和质量…...

Python爬虫高效数据爬取方法
大家好!今天我们来聊聊Python爬虫中那些既简洁又高效的数据爬取方法。作为一名爬虫工程师,我们总是希望用最少的代码完成最多的工作。下面我ll分享一些在使用requests库进行网络爬虫时常用且高效的函数和方法。 1. requests.get() - 简单而强大 requests.get()是我们最常用的…...

C语言之扫雷小游戏(完整代码版)
说起扫雷游戏,这应该是很多人童年的回忆吧,中小学电脑课最常玩的必有扫雷游戏,那么大家知道它是如何开发出来的吗,扫雷游戏背后的原理是什么呢?今天就让我们一探究竟! 扫雷游戏介绍 如下图,简…...

Spring WebFlux 响应式概述(1)
1、响应式编程概述 1.1、响应式编程介绍 1.1.1、为什么需要响应式 传统的命令式编程在面对当前的需求时的一些限制。在应用负载较高时,要求应用需要有更高的可用性,并提供低的延迟时间。 1、Thread per Request 模型 比如使用Servlet开发的单体应用&a…...

Sycamore与Leptos、Dioxus对比:如何选择最适合的Rust前端框架
Sycamore与Leptos、Dioxus对比:如何选择最适合的Rust前端框架 【免费下载链接】sycamore A library for creating reactive web apps in Rust and WebAssembly 项目地址: https://gitcode.com/gh_mirrors/sy/sycamore 在Rust前端开发领域,Sycamor…...

计算机毕业设计springboot鲜花在线商城 基于SpringBoot的园艺花卉网络销售系统 基于Java Web的线上花店订购管理平台
计算机毕业设计springboot鲜花在线商城911yt9 (配套有源码 程序 mysql数据库 论文)本套源码可以先看具体功能演示视频领取,文末有联xi 可分享近年来,互联网技术的迅猛发展和智能终端设备的全面普及,为传统零售行业带来…...

ExplorerPatcher:Windows资源管理器崩溃修复与体验增强的终极解决方案
ExplorerPatcher:Windows资源管理器崩溃修复与体验增强的终极解决方案 【免费下载链接】ExplorerPatcher 提升Windows操作系统下的工作环境 项目地址: https://gitcode.com/GitHub_Trending/ex/ExplorerPatcher 你是否经历过Windows 11资源管理器频繁崩溃的困…...

终极美化指南:foobar2000如何通过foobox-cn打造你的专属音乐空间?
终极美化指南:foobar2000如何通过foobox-cn打造你的专属音乐空间? 【免费下载链接】foobox-cn DUI 配置 for foobar2000 项目地址: https://gitcode.com/GitHub_Trending/fo/foobox-cn 厌倦了千篇一律的音乐播放器界面?想让你的音乐体…...

2步实现格式自由:Save Image as Type让网页图片转换体验升级10倍
2步实现格式自由:Save Image as Type让网页图片转换体验升级10倍 【免费下载链接】Save-Image-as-Type Save Image as Type is an chrome extension which add Save as PNG / JPG / WebP to the context menu of image. 项目地址: https://gitcode.com/gh_mirrors…...

猫抓资源嗅探扩展:5大核心功能彻底解析网络媒体捕获技术
猫抓资源嗅探扩展:5大核心功能彻底解析网络媒体捕获技术 【免费下载链接】cat-catch 猫抓 chrome资源嗅探扩展 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch)是一款开源免费的浏览器资源嗅探扩展&…...

告别演唱会抢票焦虑:大麦网Python自动化抢票脚本终极指南
告别演唱会抢票焦虑:大麦网Python自动化抢票脚本终极指南 【免费下载链接】DamaiHelper 大麦网演唱会演出抢票脚本。 项目地址: https://gitcode.com/gh_mirrors/dama/DamaiHelper 还在为心仪歌手的演唱会门票秒光而烦恼吗?还在为黄牛高价票而心痛…...

Apollo配置中心:从基础概念到实战应用全解析
1. Apollo配置中心初探:为什么我们需要它? 想象一下你正在开发一个电商系统,数据库连接地址、支付接口密钥、商品库存阈值等配置信息散落在20个不同的properties文件里。每次修改配置都需要重新打包部署,半夜三点被叫起来改生产环…...

python汽车4s店的汽车租赁服务管理系统vue
目录功能模块分析租赁服务核心功能技术实现要点扩展功能建议项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作功能模块分析 用户管理模块 用户注册与登录:支持手机号、邮箱注册,集成短信验证码功能。权限…...

LFM2.5-1.2B-Thinking-GGUF集成Python爬虫实战:智能数据采集与清洗
LFM2.5-1.2B-Thinking-GGUF集成Python爬虫实战:智能数据采集与清洗 1. 当爬虫遇上大模型:数据采集的新思路 传统爬虫开发就像在迷宫里摸索前行——你需要手动解析每个网站的HTML结构,针对不同反爬机制编写特定规则,还要处理杂乱…...