【数据结构】:破译排序算法--数字世界的秩序密码(二)
文章目录
- 前言
- 一.比较排序算法
- 1.`Bubble Sort`冒泡排序
- 1.1.冒泡排序原理
- 1.2.冒泡排序过程
- 1.3.代码实现
- 1.4.复杂度和稳定性
- 2.`Quick Sort`快速排序
- 2.1递归快速排序
- 2.1.1.递归快速排序原理
- 2.1.2.递归快速排序过程
- 2.1.3.代码实现
- 2.2.非递归快速排序
- 2.2.1.非递归快速排序原理
- 2.2.2.非递归快速排序过程
- 2.2.3.代码实现
- 2.3.复杂度和稳定性
- 二.归并排序算法
- `Merge Sort`归并排序
- 1.递归归并排序
- 1.1.递归归并排序原理
- 1.2.递归归并排序过程
- 1.3.代码实现
- 2.非递归归并排序
- 2.1.非递归归并排序原理
- 2.2.非递归归并排序过程
- 2.3.代码实现
- 3.复杂度和稳定性
- 三.非比较排序算法
- ` Cout Sort`计数排序
- 计数排序原理
- 计数排序过程
- 代码实现
- 复杂度和稳定性
- 四.代码文件
- 1.头文件`Sort.h`
- 2.测试文件`test.c`
- 3.测试结果
前言
在上一篇文章中,主要讲了插入排序,希尔排序,选择排序,堆排序(详细可以看我上一篇文章哦),在接下来的这篇文章中,将重点讲解冒泡排序,快速排序,归并排序以及计数排序。
一.比较排序算法
1.Bubble Sort冒泡排序
1.1.冒泡排序原理
冒泡排序(
Bubble Sort)是一种简单的排序算法。它重复地遍历要排序的数列,一次比较相邻的两个元素,如果它们的顺序错误就把它们交换过来。遍历数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小(或越大)的元素会经由交换慢慢“浮”到数列的顶端。
1.2.冒泡排序过程
-
比较相邻的元素,如果第一个比第二个大(升序),就交换他们两个。
-
遍历数列,对每一对相邻元素做同样的工作,从开始的第一对到结尾的最后一对,这步结束后,最大(或最小)的元素会在数列的结尾。
-
针对所有的元素重复以上步骤,除了最后一个。
-
重复上面的步骤,直到没有任何一对元素需要比较。


1.3.代码实现
//交换
void Swap(int*a,int*b){int t=*a;*a=*b;*b=t;
}
void BubbleSort(int*a,int n){for(int j=0;j<n;j++){//设置一个变量用来判断每一趟是否交换bool exchange=false;//内层循环是每一趟的比较交换for(int i=1;i<n-j;i++){if(a[i-1]>a[i]){Swap(&a[i-1],&a[i]);exchange=true;}}//如果某一趟没有进行交换就是序列已经有序,直接结束排序if(exchange==false){break;}}
}
1.4.复杂度和稳定性
- 时间复杂度:冒泡排序的平均和最坏时间复杂度都是O(n^2)。
- 空间复杂度;冒泡排序的空间复杂度为O(1)。
- 稳定性:冒泡排序是稳定的排序算法,即相等的元素在排序后的序列中保持原来的顺序。但由于其效率较低,通常不被用作主要的排序算法。
2.Quick Sort快速排序
2.1递归快速排序
2.1.1.递归快速排序原理
快速排序(
Quick Sort)是一种高效的排序算法,由C. A. R. Hoare在1960年提出。它采用分治(Divide and Conquer)的策略来把一个序列分为较小和较大的两个子序列,然后递归地排序两个子序列。快速排序的基本思想是:通过一趟排序将待排记录分隔成独立的两部分,其中一部分的所有记录均比另一部分的所有记录小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
2.1.2.递归快速排序过程
-
选择基准值:从代排序的数列中选出一个元素作为基准值(key),最常用的就是三数取中法,通过比较数列的第一个和最后一个以及中间的值,选出这三个数的中间值,然后和最左端的也就是第一个数交换。基准值的选择对于排序的效率有重要影响。
-
分区:重新排列数列,所有比基准值小的元素排在基准值前面,比基准值大的元素排在基准值后面(相同的数可以放在任意一边)。分区的操作有多种实现方法,如hoare法,挖坑法,前后指针法。
1.hoare法:

2.挖坑法:

3.前后指针法:

-
递归排序子序列:递归地将小于基准值的子序列和大于基准值的子序列排序。递归的最底部情形是数列的大小是零活着一,也就是已经排好序。
2.1.3.代码实现
//获取基准值
int Getmid(int*a,int left, int right) {int mid = (left + right) / 2;if (a[left] > a[mid]) {if (a[mid]> a[right]) {return mid;}else if (a[right] > a[left]) {return left;}else{return right;}}else {if (a[right] > a[mid]) {return mid;}else if (a[left] > a[right]) {return left;}else {return right;}}
}
//hoare法
int keysort1(int* a, int left, int right) {int key = Getmid(a, left, right);Swap(&a[left], &a[key]);key = left;while (left < right) {while (left < right && a[right] >= a[key]) {right--;}while (left < right && a[left] <= a[key]) {left++;}Swap(&a[left], &a[right]);}Swap(&a[left], &a[key]);key = left;return key;
}
//挖坑法
int keysort2(int* a, int left, int right) {int key = Getmid(a, left, right);Swap(&a[left], &a[key]);int keyi = a[left];int hole = left;while (left < right) {while (left<right && a[right]>=keyi) {right--;}a[hole] = a[right];hole = right;while (left < right && a[left] <= keyi) {left++;}a[hole] = a[left];hole = left;}a[hole] = keyi;hole = left;return hole;
}
//前后指针法
int keysort3(int* a, int left, int right) {int mid = Getmid(a, left, right);Swap(&a[left], &a[mid]);int key = left;//后指针int prev = left;//快指针int cur = left + 1;while (cur <= right) {if (a[cur] < a[key] && ++prev != cur) {Swap(&a[cur], &a[prev]);}cur++;}Swap(&a[key], &a[prev]);key = prev;return key;
}void QuickSort(int* a, int left,int right) {if (left >= right) {return;}int begin = left;int end = right;//分区,三种方法选一种即可int key = keysort3(a, left, right);QuickSort(a, begin, key - 1);QuickSort(a, key + 1, end);
}
2.2.非递归快速排序
2.2.1.非递归快速排序原理
非递归快速排序的原理和过程与递归快速排序相似,但主要区别在于非递归版本通过显式地使用一个辅助栈(或队列)来模拟递归过程中的函数调用栈,从而避免了递归调用。
2.2.2.非递归快速排序过程
-
初始化栈:
- 创建一个空栈用于保存待排序子数组的起始和结束索引。
-
将初始数组的起始和结束索引入栈:
- 这对应于最初的排序问题。
-
循环处理栈中的元素:
- 当栈不为空时,进行以下操作:
-
弹出栈顶的一对索引(起始和结束索引),这指定了当前要处理的子数组。
-
在当前子数组上选择一个基准元素,并进行分区操作。
(分区操作会将数组分为左右两部分,并返回基准元素的最终位置。)
-
如果基准元素左侧的子数组有超过一个元素,则将其起始和结束索引作为一对入栈。
-
如果基准元素右侧的子数组有超过一个元素,也将其起始和结束索引作为一对入栈。
-
- 当栈不为空时,进行以下操作:
-
重复步骤3,直到栈为空,此时所有子数组都已经被正确排序。
2.2.3.代码实现
void QuickSortNoNR(int* a, int left, int right) {//创建栈Stack st;//初始化栈InitStack(&st);int begin = left;int end = right;//将第一个区间入栈pushStack(&st, end);pushStack(&st, begin);//循环条件栈不为空while (!IsEmpty(&st)) {//将区间出栈begin = getpopStack(&st);popStack(&st);end = getpopStack(&st);popStack(&st);//获取key值下标,分区int key = keysort3(a, begin, end);//右子区间满足条件入栈if (key + 1 < end) {pushStack(&st, end);pushStack(&st, key + 1);}//左子区间满足条件入栈if (begin < key - 1) {pushStack(&st, key - 1);pushStack(&st, begin);}}//销毁栈DestroyStack(&st);
}
2.3.复杂度和稳定性
- 时间复杂度:快速排序的时间复杂度平均为O(n log n),但在最坏情况下(如数组已经有序时)会退化到O(n^2)。
- 空间复杂度:
- 稳定性:快速排序是不稳定的排序算法,即相同的元素可能在排序过程中改变相对位置。
二.归并排序算法
Merge Sort归并排序
1.递归归并排序
1.1.递归归并排序原理
递归归并排序是建立在归并操作上的一种有效排序算法,它采用
分治法(Divide and Conquer)来进行排序。分治法的基本思想是将一个复杂的问题分解成两个或更多的相同或相似的子问题,子问题再继续分解,直到这些子问题变得简单到可以直接解决,然后再合并子问题的解为原问题的解。在归并排序中,分治法的应用体现在:
- 分解:将待排序的数组分解成两个较小的子数组,然后子数组再继续分解,直到子数组的大小为1(即只有一个元素,此时认为它是有序的)。
- 解决:递归地对子数组进行排序并合并,得到有序的子数组。
- 合并:将两个有序的子数组合并成一个有序的大数组,直到合并为1个完整的数组。
1.2.递归归并排序过程
-
分解:
- 将待排序的数组
a[begin...end]分解成两个子数组a[begin...mid]和a[mid+1...end],其中mid是begin和end的中间位置(mid = (begin + end) / 2)。 - 递归地对这两个子数组进行分解,直到子数组的大小为1。
- 将待排序的数组
-
递归排序并合并:
- 对分解得到的子数组进行递归排序。
- 合并两个有序的子数组为一个有序数组。合并过程中,通过比较两个子数组的元素,将较小的元素依次放入一个新的临时数组tmp中,直到所有元素都被合并。
-
合并:
- 合并过程中,使用两个指针
begin1,begin2分别指向两个子数组的起始位置,比较两个指针所指的元素,将较小的元素放入临时数组中,并移动该指针。 - 当其中一个子数组的所有元素都被合并后,将另一个子数组中剩余的元素依次复制到临时数组的末尾。
- 最后,将临时数组中的元素复制回原数组中的相应位置,完成合并。
- 合并过程中,使用两个指针
-
递归终止条件:
- 当子数组的大小为1时,递归终止,因为单个元素的数组自然是有序的。
-
排序完成:
- 当整个数组被分解为单个元素的子数组,并通过递归合并成有序的大数组时,排序完成。


1.3.代码实现
void _MergeSort(int*a,int begin,int end,int*tmp){//不满足条件时结束返回if(begin>=end){return;}//找中间值下标int mid=(begin+end)/2;//递归分区,[begin,mid],[mid+1,end]_MergeSort(a,begin,mid,tmp);_MergeSort(a,mid+1,end,tmp);//设置分区的下标int begin1=begin,end1=mid;int begin2=mid+1,end2=end;//循环比较,依次存放到tmp数组中//注意:这里tmp数组的下标一定要从begin开始,而不是从0开始int i=begin;while(begin1<=end1&&begin2<=end2){if(a[begin1]<a[begin2]){tmp[i++]=a[begin1++];}else{tmp[i++]a[begin2++];}}while(begin1<=end1){tmp[i++]=a[begin1++];}while(begin2<=end2){tmp[i++]=a[begin2++];}//将tmp数组中排序好的拷贝到原数组中,复制范围是每次函数调用的左右区间memcpy(a+begin,tmp+begin,sizeof(int)*(end-begin+1));
}void MergeSort(int*a,int n){//创建一个临时数组用来存放排好序的序列int*tmp=(int*)malloc(sizeof(int)*n);if(tmp==NULL){perror("malloc false");return;}_MergeSort(a,0,n-1,tmp);
}
2.非递归归并排序
2.1.非递归归并排序原理
==非递归归并排序(也称为迭代归并排序)==与递归归并排序在原理上相同,都是基于分治法的排序算法。不过,在实现方式上,非递归归并排序通过循环而不是递归调用来控制排序过程。非递归归并排序也是将数组分解成若干个子数组,直到子数组的大小为1(即只有一个元素,此时认为它是有序的)。然后,通过迭代的方式,逐步合并相邻的有序子数组,直到合并成一个完整的有序数组。
2.2.非递归归并排序过程
- 初始化:
- 定义一个变量
gap,用于表示当前归并的子数组的大小(即每次合并时考虑的元素个数)。初始时,gap通常设置为1,表示每个子数组只包含一个元素。
- 定义一个变量
- 迭代合并:
- 使用一个外层循环,不断增大
gap的值,直到gap大于等于数组的长度。这个循环控制归并的轮数。 - 在每一轮归并中,使用一个内层循环来遍历数组,并合并相邻的、大小为
gap的有序子数组。合并过程中,需要使用一个临时数组tmp来存放合并后的结果。
- 使用一个外层循环,不断增大
- 合并相邻子数组:
- 在内层循环中,对于每一对相邻的子数组(它们的起始位置相差
gap),使用类似于递归归并排序中合并函数的方法将它们合并成一个有序的子数组。 - 合并过程中,使用两个指针
begin1,begin2分别指向两个子数组的起始位置,比较两个指针所指的元素,将较小的元素放入临时数组中,并移动该指针。 - 当其中一个子数组的所有元素都被合并后,将另一个子数组中剩余的元素依次复制到临时数组的末尾。
- 最后,将临时数组中的元素复制回原数组中的相应位置,完成合并。
- 在内层循环中,对于每一对相邻的子数组(它们的起始位置相差
- 更新
gap:- 在外层循环的每次迭代结束时,将
gap的值加倍(即gap *= 2),以便在下一轮归并中合并更大范围的子数组。
- 在外层循环的每次迭代结束时,将
- 排序完成:
- 当
gap大于等于数组的长度时,排序完成。此时,整个数组被合并成一个有序的大数组。
- 当

2.3.代码实现
void MergeSortNoNR(int*a,int n){//创建一个临时数组用来存放排好序的序列int* tmp=(int*)malloc(sizeof(int)*n);if(tmp==NULL){perror("malloc false");return;}//初始化:设置分区间隔值gap,从1开始int gap=1;//迭代合并:while(gap<n){//合并相邻子数组:for(int i=0;i<n;i+=gap*2){//分区int begin1=i,end1=i+gap-1;int begin2=i+gap,end2=i+gap*2-1;int j=i;//处理临界情况if(begin2>=n){break;}if(end2>=n){end2=n-1;}//循环比较,依次存放到tmp数组中while(begin1<=end1&&begin2<=end2){if(a[begin1]<a[begin2]){tmp[j++]=a[begin1++];}else{tmp[j++]=a[begin2++];}}while(begin1<=end1){tmp[j++]=a[begin1];}while(begin2<=end2){tmp[j++]=a[begin2];}//将tmp数组中排序好的拷贝到原数组中//注意:这里用i,不用begin1,是因为begin1++值已经改变memcpy(a+i,tmp+i,sizeof(int)*(end2-i+1));}//更新gap:gap*=2;}
}
3.复杂度和稳定性
- 时间复杂度:归并排序的时间复杂的为O(n*log n)。
- 空间复杂度:归并排序的空间复杂度为O(n),因为借助了一个临时数组tmp,数组长度为n。
- 稳定性:归并排序是一种稳定的排序算法。
三.非比较排序算法
Cout Sort计数排序
计数排序原理
计数排序(
Counting Sort)是通过统计待排序元素的出现次数来确定元素的相对位置,从而实现排序。这种算法不是基于比较的排序算法,而是通过统计每个元素的出现次数,并利用这些信息来重新排列元素。
计数排序过程
-
找出待排序数组的最大值和最小值:
- 遍历待排序数组,找出数组中的最大值
max和最小值min。
- 遍历待排序数组,找出数组中的最大值
-
创建计数数组并初始化:
- 根据最大值和最小值创建一个计数数组
countA,其长度range为max - min + 1(如果数组中存在负数,则需要对所有元素进行偏移,使得所有元素都是非负的)。 - 将计数数组的所有元素初始化为0。
- 根据最大值和最小值创建一个计数数组
-
统计每个元素的出现次数:
- 再次遍历待排序数组,对于数组中的每个元素
x,将countA[x - min](如果元素是负数或需要特殊偏移,则相应调整)的值增加1。这样,计数数组就记录了每个元素的出现次数。
- 再次遍历待排序数组,对于数组中的每个元素
-
对计数数组进行累加(也称为前缀和):
- 遍历计数数组,将每个元素的值更新为从计数数组开始到当前元素位置(包括当前元素)的所有元素之和。这一步完成后,计数数组中的每个元素都表示小于等于该索引对应元素值的元素个数。
-
根据计数数组将元素放回原数组的正确位置:
- 创建一个临时数组
temp,其长度与待排序数组相同。 - 从后往前遍历待排序数组(这是为了确保排序的稳定性),对于每个元素
x,通过count[x - min] - 1(如果元素是负数或需要特殊偏移,则相应调整)找到其在临时数组中的正确位置,并将x放入该位置。然后,将count[x - min]的值减1,以便下一个相同值的元素能够找到其正确的位置。
- 创建一个临时数组
-
将排序后的元素复制回原数组(如果需要):
- 如果原数组需要被直接修改以反映排序后的结果,则将临时数组
temp中的元素复制回原数组。否则,可以直接使用临时数组作为排序后的数组。
- 如果原数组需要被直接修改以反映排序后的结果,则将临时数组

代码实现
void CountSort(int*a,int n){//找出待排序数组的最大值和最小值int max=a[0],min=a[0];for(int i=0;i<n;i++){if(a[i]>max){max=a[i];}if(a[i]<min){min=a[i];}}//创建计数数组并初始化int range=max-min+1;int*countA=(int*)malloc(sizeof(int)*range);if(countA==NULL){perror("malloc false");return;}//将计数数组的所有元素初始化为0memset(countA,0,sizeof(int)*range);//统计每个元素的出现次数for(int i=0;i<n;i++){countA[a[i]-min]++;}//将原数组的元素按照计数数组的个数复制到原数组中int j=0;for(int i=0;i<n;i++){while(countA[i]--){a[j++]=i+min;}}
}
复杂度和稳定性
- 时间复杂度:计数排序的的时间复杂度为O(n+k),n是待排序数组的长度,k是元素范围,最大值-最小值加一。
- 空间复杂度:空间复杂度为O(n+k),需要创建计数数组。
- 稳定性:计数排序是一种稳定的排序算法,适用于整数或有限范围内的非负整数排序。
四.代码文件
这里附上整个代码文件:
- 头文件
Sort.h- 测试文件
test.c- 接口函数实现文件
Sort.c(文件内容就是每个代码实现)
1.头文件Sort.h
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<stdbool.h>
#include<string.h>
//递归快速排序
void QuickSort(int* a, int left, int right);
//三数取中
int Getmid(int* a, int left, int right);
//霍尔版本快速排序
int keysort1(int* a, int left, int right);
//挖坑法快速排序
int keysort2(int* a, int left, int right);
//前后指针法快速排序
int keysort3(int* a, int left, int right);
//非递归快速排序
void QuickSortNoNR(int* a, int left, int right);
//递归归并排序
void MergeSort(int* a, int n);
void _MergeSort(int* a, int left, int right, int* tmp);
//非递归归并排序1
void MergeSortNoNR1(int* a, int n);
//非递归归并排序2
void MergeSortNoNR2(int* a, int n);
//计数排序
void CountSort(int* a, int n);
2.测试文件test.c
//冒泡排序测试
void Bubbletest() {int a[10] = { 3,6,7,2,1,5,4,9,8,10 };int n = (sizeof(a) / sizeof(int));BubbleSort(a, n);printf("冒泡排序:\n");PrintArray(a, n);
}
//快速排序测试
void Quicktest() {int a[20] = { 3,6,7,2,1,5,4,9,8,10,-2,7,-4,23,-1,-5,65,4,16,-3 };int n = (sizeof(a) / sizeof(int));QuickSortNoNR(a, 0, sizeof(a) / sizeof(int) - 1);printf("快速排序:\n");PrintArray(a, n);
}
//归并排序测试
void Mergetest() {int a[9] = { 2,1,7,5,4,9,3,8,6 };int n = (sizeof(a) / sizeof(int));MergeSortNoNR2(a, n);printf("归并排序:\n");PrintArray(a, n);
}
//计数排序测试
void Counttest() {int a[9] = { 2,1,7,2,4,1,3,8,6 };int n = (sizeof(a) / sizeof(int));CountSort(a, n);printf("计数排序:\n");PrintArray(a, n);
}
int main(){Bubbletest();Quicktest();Mergetest();Counttest();return 0;
}
}
3.测试结果

以上就是关于排序部分冒泡排序,快速排序,归并排序和计数排序的讲解,如果哪里有错的话,可以在评论区指正,也欢迎大家一起讨论学习,如果对你的学习有帮助的话,点点赞关注支持一下吧!!!
相关文章:

【数据结构】:破译排序算法--数字世界的秩序密码(二)
文章目录 前言一.比较排序算法1.Bubble Sort冒泡排序1.1.冒泡排序原理1.2.冒泡排序过程1.3.代码实现1.4.复杂度和稳定性 2.Quick Sort快速排序2.1递归快速排序2.1.1.递归快速排序原理2.1.2.递归快速排序过程2.1.3.代码实现 2.2.非递归快速排序2.2.1.非递归快速排序原理2.2.2.非…...

2024年《生成式ai大模型》都学什么内容呢?
近期大家都在关注的2024 2024年10月25日 — 2024年10月29日 在成都举办的第八期《新质技术之生成式AI、大模型、多模态技术开发与应用研修班》都学什么内容呢?下面我们来看看: 1.了解AIGC发展现状与核心技术。 2.掌握Transformer核心开发技术。 3.掌握…...

kubernetes自定义pod启动用户
一、kubernetes自定义pod启动用户 一)以root用户启动pod containers:- name: ...image: ...securityContext:runAsUser: 0 二)以普通用户启动pod 1、从构建镜像角度修改 # RUN命令执行创建用户和用户组(命令创建了一个用户newuser设定ID为1…...

C4T避风型电动采光排烟天窗(图集09J621-2)
C4T避风型电动采光排烟天窗是09J621-2《电动采光排烟天窗》图集中的一种窗型。也是一种现代化的建筑消防排烟通风采光设备,被广泛应用于多风地区厂房。 C4T避风型电动采光排烟天窗配有成品避风罩,该避风置由钢制骨架和彩色钢板构成,固定在电动…...

多态常见面试问题
1、什么是多态? 多态(Polymorphism)是面向对象编程中的一个重要概念,它允许同一个接口表现出不同的行为。在C中,多态性主要通过虚函数来实现,分为编译时多态(静态多态)和运行时多态…...

案例-登录认证(上)
案例-登录认证 在前面的课程中,我们已经实现了部门管理、员工管理的基本功能,但是大家会发现,我们并没有登 录,就直接访问到了Tlias智能学习辅助系统的后台。 这是不安全的,所以我们今天的主题就是登录 认证。 最终我…...

对BSV区块链下一代节点Teranode的答疑解惑(上篇)
发表时间:2024年8月7日 2024年初BSV区块链研发团队揭晓了即将到来的Teranode更新的突破性特性,这些特性将显著提升网络的效率和处理速度,使BSV区块链能够达到百万级TPS。 Teranode的项目主管Siggi Oskarsson强调:“当你阅读这…...

vue父子组件传参的方法
在Vue.js中,父子组件之间的参数传递是常见的需求。Vue提供了几种方法来实现这一点,主要包括使用props传递数据给子组件,以及使用事件(如自定义事件)从子组件向父组件发送数据。以下是详细的说明: 父组件向…...

关于this指针
在普通成员函数里 1.this指针不能显式说明,但能显示使用,是个常指针,只能改变指针指向的对象的内容,不能改变指针存储的对象的地址。 2.this指针一般不用特别写上,只有在(我目前的知识范围内)类…...

机器学习西瓜书
绪论 1.1绪论1.2课程定位 科学:是什么,为什么; 技术:怎么做; 工程:做的多快好省; 应用: 1.3机器学习 经典定义:利用经验改善系统自身的性能 1.4典型的机器学习过程 1.5计算学习理论 机器学习有坚实的理论基础,由Leslie Valiant的计算学习理论现在有一个数据样本x,现在…...

如何使用 Puppeteer 和 Browserless 运行自动化测试?
Puppeteer:什么是 Puppeteer 及其功能 Puppeteer 是一个 Node.js 库。使用 Puppeteer,您可以在所有基于 Chromium 的浏览器上测试您的网站,包括 Chrome、Microsoft Edge Chrome 和 Chromium。此外,Puppeteer 可用于网页抓取、自动…...

python菜鸟知识
去除空格 str 这是 含 空格 print(f去除两端空格{str.strip()}) print(f去除左端空格{str.lstrip()}) print(f去除右端空格{str.rstrip()}) print(f去除全部空格{str.replace(" ", "")}) 方法返回对象yield yield :.join([ip, port])yield {ranking…...

GPT4o,GPTo1-preview, 拼
兄弟们GPT刚开的 需要上车的扣,工作用 大家一起PIN分摊点压力。 在当今数字化的时代,程序员这一职业已经从幕后走到了前台,成为推动科技进步和社会变革的关键力量。编写代码、解决问题、不断学习新技术,程序员们的日常充满了挑战与…...

论文笔记:Pre-training to Match for Unified Low-shot Relation Extraction
论文来源:ACL 2022 论文地址:https://aclanthology.org/2022.acl-long.397.pdf 论文代码:https://github.com/fc-liu/MCMN (笔记不易,请勿恶意转载抄袭!!!) 目录 A…...

一篇文章带你快速了解linux中关于信号的核心内容
1. 信号概念 信号是操作系统用来通知进程某个特定事件已经发生的一种方式。它们是一种软件中断,可以被发送到进程以对其进行异步通知。 2. 信号处理的三种方式 执行默认动作执行自定义动作忽略 signal() 函数:将信号处理设置为 SIG_IGN,可…...

openEuler、Linux操作系统常见操作-(6)如何登录Linux
如何登录Linux Linux登陆方式主要有如下两种: 。本地登陆 。一个典型的Linux系统将运行六个虚拟控制台和一个图形控制台,openEuler目前暂未支持图形化界面; 可以通过CtrlAltF[1-6]在6个虚拟控制台之间进行切换。 远程登录 。默认情况下openEuler支持远程登录&…...

Python基础语法条件
注释 注释的作用 通过用自己熟悉的语言,在程序中对某些代码进行标注说明,这就是注释的作用,能够大大增强程序的可读性。 注释的分类及语法 注释分为两类:单行注释 和 多行注释。 单行注释 只能注释一行内容,语法如下…...
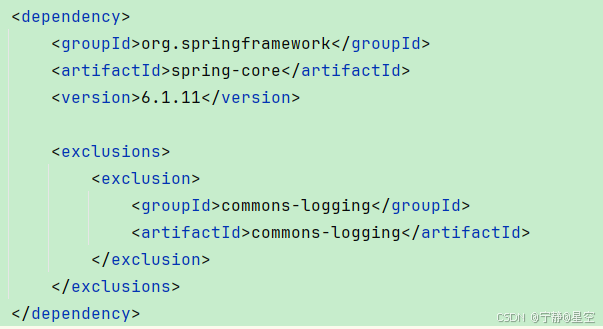
006-MAVEN 的使用
MAVEN 的使用 一、依赖范围二、依赖的传递性三、依赖的原则四、依赖的排除 一、依赖范围 在引入log4j 依赖的时候,有一个scope设置,这个scope设置的值就是对应的依赖范围(因为compile 是默认的依赖范围,所以有时也可以省略)。 Maven 提供了…...

npm使用时报错:Could not retrieve https://npm.taobao.org/mirrors/node/index.json.
在使用npm时报错,报错信息如下: 报错的原因:是原来的淘宝镜像地址过期了 解决办法:修改镜像地址。打开nvm的安装地址 -->settings.txt文件 -->配置下载源 1、将settings.txt文件中的 node_mirror: https://npm.taobao.or…...

软考中级网络工程师——高级配置
文章目录 IS-ISBGP(边境网关协议)-IBGP-EBGP配置BFD(双向转发侦测)与Router-Static联动BFD与OSPF联动BFD与VRRP(虚拟路由器冗余协议)联动VRRP配置(基于网关备份)FW基础配置FW高级配置DHCP路由策略 IS-IS 第一步:每一个路由设置环回口地址 第二部:配置接…...

三步解锁Bruno API测试工具的隐藏潜力
三步解锁Bruno API测试工具的隐藏潜力 【免费下载链接】bruno 开源的API探索与测试集成开发环境(作为Postman/Insomnia的轻量级替代方案) 项目地址: https://gitcode.com/GitHub_Trending/br/bruno Bruno作为Postman的开源替代品,以其…...

用Isaac Sim的Action Graph给ROS2机器人发布激光雷达数据:一个完整的传感器仿真流程
用Isaac Sim的Action Graph实现ROS2激光雷达数据仿真:从传感器配置到RViz可视化的全流程指南 在机器人开发和自动驾驶系统测试中,高保真的传感器仿真能够显著降低硬件成本和迭代周期。NVIDIA Isaac Sim作为一款强大的机器人仿真平台,与ROS2生…...

从零开始:3小时掌握Arduino ESP32开发板完整安装与配置指南 [特殊字符]
从零开始:3小时掌握Arduino ESP32开发板完整安装与配置指南 🚀 【免费下载链接】arduino-esp32 Arduino core for the ESP32 项目地址: https://gitcode.com/GitHub_Trending/ar/arduino-esp32 想要快速上手ESP32物联网开发吗?无论你是…...

搞懂 SAPUI5 Application Index:为什么你的 Fiori 应用改完了,系统却像没看见一样
在 SAP Fiori 项目里,开发团队最容易忽略的一件事,不是 OData 服务,也不是 Component.js,而是 SAPUI5 Application Index。很多人会遇到这样一种场景:应用代码已经传输完成,BSP 资源也在系统里了,manifest.json 也改过了,可是 Fiori Launchpad 仍然表现得像什么都没发生…...

10倍加速PDF转HTML:pdf2htmlEX终极优化指南
10倍加速PDF转HTML:pdf2htmlEX终极优化指南 【免费下载链接】pdf2htmlEX Convert PDF to HTML without losing text or format. 项目地址: https://gitcode.com/gh_mirrors/pd/pdf2htmlEX pdf2htmlEX是一款能够将PDF文件转换为HTML格式的强大工具,…...

如何通过猫抓cat-catch构建高效媒体资源管理系统
如何通过猫抓cat-catch构建高效媒体资源管理系统 【免费下载链接】cat-catch 猫抓 chrome资源嗅探扩展 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在数字化内容爆炸的时代,高效捕获和管理网页媒体资源已成为内容创作者、教育工作者和技术…...

PyTorch 2.8镜像实操手册:/workspace+/data+/output目录规范使用详解
PyTorch 2.8镜像实操手册:/workspace/data/output目录规范使用详解 1. 镜像环境概述 PyTorch 2.8深度学习镜像基于RTX 4090D 24GB显卡和CUDA 12.4深度优化,专为高性能计算任务设计。这个环境预装了完整的深度学习工具链,从基础框架到加速库…...

GLM-4V-9B Streamlit交互设计解析:侧边栏上传+实时渲染+历史回溯实现
GLM-4V-9B Streamlit交互设计解析:侧边栏上传实时渲染历史回溯实现 1. 引言 你有没有遇到过这样的情况:拿到一个功能强大的AI模型,官方给的示例代码却在自己的电脑上跑不起来,要么是显存不够,要么是各种奇怪的报错&a…...

Pyenv vs Miniconda vs Anaconda:Python环境管理工具链深度解析
1. Python环境管理工具全景概览 刚接触Python开发时,我最头疼的就是环境配置问题。同一个项目在不同电脑上跑出不同结果,安装包时各种依赖报错,这些经历让我深刻认识到环境管理工具的重要性。目前主流的Pyenv、Miniconda和Anaconda就像三种不…...
)
排序算法---(四)
引言在前几篇文章里面讲到了六种排序,今天来讲一下剩下两种:基数排序、堆排序基数排序1.思路(1)首先确定最大数的位数:找到待排序数组中的最大数,并确定其位数(2)将元素按照相应的位…...