Python Django 数据库优化与性能调优
Python Django 数据库优化与性能调优
Django 是一个非常流行的 Python Web 框架,它的 ORM(对象关系映射)允许开发者以简单且直观的方式操作数据库。然而,随着数据量的增长,数据库操作的效率可能会成为瓶颈,影响整个应用的性能。因此,数据库优化和性能调优是 Django 应用开发中的一个重要话题。

在这篇文章中,我们将探讨一些 Django 中的数据库优化技巧,以及如何调优应用的性能,确保 Django 应用在处理大量数据时依然高效。文章内容包括:
- 数据库连接优化
- 查询优化
- 数据库索引
- 减少数据库查询次数
- 使用缓存提高性能
- 数据库表的分区和拆分
- 数据库连接池和并发优化
一、数据库连接优化
1. 数据库连接的常见问题
在处理数据库时,一个常见的性能问题是每次查询都会创建新的数据库连接。这种开销在处理大量请求时可能会显著增加,从而拖慢应用的响应速度。为了解决这个问题,我们可以通过优化数据库连接配置来提高应用的性能。
Django 默认会在每个请求的开始创建一个新的数据库连接,并在请求结束时关闭它。然而,创建和销毁数据库连接需要时间,频繁的连接和断开会影响性能。
2. 配置持久数据库连接
为了解决这个问题,我们可以使用 Django 的 数据库持久连接 功能。通过启用数据库持久连接,Django 可以在多个请求之间重用数据库连接,减少连接和关闭数据库的开销。
在 settings.py 中,添加以下配置来启用数据库持久连接:
DATABASES = {'default': {'ENGINE': 'django.db.backends.postgresql', # 假设你使用的是 PostgreSQL'NAME': 'mydatabase','USER': 'myuser','PASSWORD': 'mypassword','HOST': 'localhost','PORT': '5432','CONN_MAX_AGE': 600, # 数据库连接最大存活时间,单位为秒}
}
CONN_MAX_AGE 设置了连接的最大存活时间。在这个时间范围内,Django 将重用现有的连接,而不是每次请求都创建新的连接。
3. 使用数据库连接池
如果你在处理大量并发请求,数据库连接池是一个重要的优化手段。连接池通过维护一个数据库连接的池子来避免频繁的连接创建和销毁。每次需要数据库连接时,应用会从连接池中获取一个可用的连接。
你可以使用像 django-db-connection-pool 这样的第三方库为 Django 添加连接池功能。首先,安装依赖库:
pip install django-db-connection-pool
然后,在 settings.py 中添加以下配置:
DATABASES = {'default': {'ENGINE': 'django_postgrespool2','NAME': 'mydatabase','USER': 'myuser','PASSWORD': 'mypassword','HOST': 'localhost','PORT': '5432','OPTIONS': {'MAX_CONNS': 20, # 连接池最大连接数},}
}
这样,Django 就会在每个请求中使用连接池中的连接,从而减少数据库连接的开销。
二、查询优化
1. 避免 N+1 查询问题
在 Django 中,N+1 查询问题是一个常见的性能陷阱。假设你有两个模型:Author 和 Book,Book 模型有一个外键指向 Author。当你查询所有书籍并访问其作者时,Django ORM 可能会执行一次查询来获取所有书籍,然后为每本书单独查询其作者。这会导致大量数据库查询,降低性能。
例子:
books = Book.objects.all()
for book in books:print(book.author.name) # 这里会触发 N+1 查询
要避免这个问题,可以使用 select_related 或 prefetch_related 来优化查询。
select_related用于获取外键或一对一关系的相关对象。prefetch_related用于处理多对多或反向外键关系。
优化后的代码:
books = Book.objects.select_related('author').all()
for book in books:print(book.author.name) # 只触发 1 次查询
通过使用 select_related,我们将书籍和作者的数据通过一次查询获取,避免了 N+1 查询问题。
2. 使用惰性加载与 only() 和 defer()
在 Django 中,ORM 默认会加载模型的所有字段,但有时你只需要某些特定字段。通过使用 only() 和 defer(),你可以优化查询,避免加载不必要的数据。
only():仅查询指定字段。defer():推迟加载指定字段,直到需要时再查询。
例子:
# 只加载 title 字段
books = Book.objects.only('title')# 推迟加载 price 字段
books = Book.objects.defer('price')
这样可以减少数据库传输的数据量,从而提高查询的效率。
三、数据库索引
1. 添加索引
索引是数据库优化的核心工具之一。通过在查询频繁使用的字段上添加索引,可以极大地提高查询速度。在 Django 中,你可以通过 models.Index 或者在字段中设置 db_index=True 来添加索引。
例子:
class Book(models.Model):title = models.CharField(max_length=200, db_index=True) # 为 title 字段添加索引author = models.CharField(max_length=100)publish_date = models.DateField()price = models.DecimalField(max_digits=6, decimal_places=2)class Meta:indexes = [models.Index(fields=['author', 'publish_date']), # 联合索引]
2. 使用唯一约束
当某个字段需要保持唯一时,可以通过 unique=True 来强制数据库为该字段创建唯一索引。
class Book(models.Model):isbn = models.CharField(max_length=13, unique=True) # ISBN 号唯一
添加唯一索引不仅确保数据完整性,还能优化查询性能。
四、减少数据库查询次数
1. 使用缓存
在频繁查询相同数据的情况下,可以使用缓存来减少数据库查询。Django 提供了内置的缓存框架,可以轻松实现缓存机制。
在 settings.py 中配置缓存:
CACHES = {'default': {'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache','LOCATION': '127.0.0.1:11211',}
}
示例:使用缓存优化查询
from django.core.cache import cache# 尝试从缓存中获取数据
books = cache.get('all_books')
if not books:# 如果缓存中没有数据,查询数据库并缓存结果books = Book.objects.all()cache.set('all_books', books, timeout=60*15) # 缓存 15 分钟
通过缓存机制,可以有效减少数据库查询次数,尤其是在数据更新频率较低且读取频率较高的场景中。
2. 使用 values() 和 values_list()
如果你只需要查询某些字段,而不是整个模型对象,可以使用 values() 或 values_list() 来减少数据加载量。
例子:
# 只查询 title 和 price 字段
books = Book.objects.values('title', 'price')# 查询 title 字段的列表
titles = Book.objects.values_list('title', flat=True)
使用 values() 和 values_list() 可以减少数据传输和内存消耗,从而提高性能。
五、使用缓存提高性能
1. 页面级缓存
Django 提供了多种缓存方式,包括页面级缓存、模板片段缓存和低级别缓存。在高并发场景下,缓存可以显著提升性能。
页面级缓存示例:
在 urls.py 中,你可以为某个视图启用页面级缓存:
from django.views.decorators.cache import cache_pageurlpatterns = [path('books/', cache_page(60 * 15)(views.book_list)), # 缓存 15 分钟
]
页面级缓存会缓存整个页面的响应,适用于更新频率较低的页面。
2. 模板片段缓存
如果页面的某些部分是动态的,而其他部分可以缓存,你可以使用模板片段缓存。
模板片段缓存示例:
{% load cache %}{% cache 600 sidebar %}<!-- 这里是可以缓存的内容 --><div class="sidebar">...</div>
{% endcache %}
六、数据库表的分区和拆分
当数据量达到一定规模时,单张表的查询效率可能会下降。此时,可以考虑对数据库表进行分区或拆分。
1. 水平分区
水平分区是指将大表按行分割成多个较小的表。例如,你可以根据日期、用户 ID 等字段对数据进行分区。Django 不直接支持数据库分区,但你可以使用 PostgreSQL 或 MySQL 等数据库的分区功能。
2. 垂直拆分
垂直拆分是指将表中的某些列移到另一张表中。这种方法适用于某些字段非常稀疏,或者某些字段占用大量存储空间但查询频率不高的情况。
七、数据库连接池和并发优化
在高并发环境下,连接池和并发处理非常重要。我们之前已经提到过数据库连接池,可以减少连接的开销。此外,你还可以使用 Django 自带的 bulk_create() 和 bulk_update() 方法批量处理数据库操作,减少查询次数。
1. 使用 bulk_create() 和 bulk_update()
当你需要批量插入或更新数据时,bulk_create() 和 bulk_update() 可以帮助你减少数据库交互的次数,从而提高性能。
例子:
# 批量插入数据
Book.objects.bulk_create([Book(title='Book 1', author='Author A', price=10.99),Book(title='Book 2', author='Author B', price=12.99),...
])# 批量更新数据
books = Book.objects.filter(author='Author A')
for book in books:book.price += 1
Book.objects.bulk_update(books, ['price'])
使用批量操作可以显著提高数据处理的效率,特别是在处理大量数据时。
八、总结
Django 提供了丰富的工具和技术来优化数据库性能。通过合理使用数据库连接池、缓存、索引、查询优化等手段,你可以确保 Django 应用在处理大规模数据时依然高效。下面是本文提到的几个关键点:
- 数据库连接优化:使用持久连接和连接池减少连接开销。
- 查询优化:避免 N+1 查询,使用
select_related和prefetch_related。 - 数据库索引:通过添加索引和唯一约束提高查询性能。
- 减少查询次数:使用缓存、
values()、values_list()等减少数据库交互。 - 缓存机制:使用页面缓存、模板片段缓存等手段减少重复查询。
- 数据分区和拆分:对大表进行分区或拆分以提高查询性能。
通过合理的数据库优化策略,你可以大大提升 Django 应用的响应速度,改善用户体验,并在处理大数据量时保持高效的性能表现。
相关文章:
Python Django 数据库优化与性能调优
Python Django 数据库优化与性能调优 Django 是一个非常流行的 Python Web 框架,它的 ORM(对象关系映射)允许开发者以简单且直观的方式操作数据库。然而,随着数据量的增长,数据库操作的效率可能会成为瓶颈,…...
基于SpringBoot+微信小程序的农产品销售平台
基于SpringBoot微信小程序的农产品销售平台 ✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、项目…...

微前端学习以及分享
微前端学习以及分享 注:本次分享demo的源码github地址:https://github.com/rondout/micro-frontend 什么是微前端 微前端的概念是由ThoughtWorks在2016年提出的,它借鉴了微服务的架构理念,核心在于将一个庞大的前端应用拆分成多…...

【Linux-进程间通信】vscode使用通信引入匿名管道引入
一、新系统,新软件 1.新系统 哈喽宝子们,从今以后我们不再使用风靡一时的CentOS系统了,因为CentOS已经不在维护了,各大公司几乎也都从CentOS转入其他操作系统了;我们现在由原来的CentOS系统切换到最新的Ubuntu系统&a…...

nerd bug:VPG多次计算vnetloss的计算图报错的解决
待更 Reference https://www.cnblogs.com/StarZhai/p/15495292.htmlhttps://github.com/huggingface/transformers/issues/12613https://discuss.pytorch.org/t/inplace-operation-errors-when-implementing-a2c-algorithm/145406/6...
BigDecimal类Date类JDK8日期
一、BigDecimal类是什么?它有什么用?先看一段代码,看这个代码有什么问题再说BigDeimal这个类是干什么用的,这样会好理解一些。 public class Test {public static void main(String[] args) {System.out.println(0.1 0.2);Syste…...

MybatisWebApp
如何构建一个有关Mybatis的Web? 在这里给出我自己的一些配置。我的TomCat版本:10.1.28 ,IDEA版本:2024.1.4 Pom.XML文件 <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/200…...

第十五章 RabbitMQ延迟消息之延迟插件
目录 一、引言 二、延迟插件安装 2.1. 下载插件 2.2. 安装插件 2.3. 确认插件是否生效 三、核心代码 四、运行效果 五、总结 一、引言 上一章我们讲到通过死信队列组合消息过期时间来实现延迟消息,但相对而言这并不是比较好的方式。它的代码实现相对来说比…...

OpenAI 公布了其新 o1 模型家族的元提示(meta-prompt)
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

Java基础14-网络编程
十四、网络编程 java.net.*包下提供了网络编程的解决方案! 基本的通信架构 基本的通信架构有2种形式: CS架构( Client客户端/Server服务端)、BS架构(Browser浏 览器/Server服务端)。无论是CS架构,还是BS架构的软件都必须依赖网络编程!。 1、网络通信的三要素 网络通…...

sed命令详解
sed命令详解 sed(stream editor,流编辑器)是 Linux 和 Unix 系统中功能强大的文本处理工具,它能够对输入流(如文件、管道输入等)进行逐行处理,从而实现多种多样的文本编辑操作。 基本语法 se…...

Linux高阶——1013—正则表达式练习
1、正则表达式匹配机制 问号放在或者*后面,表示切换成非贪婪模式 [^>]表示非右尖括号的都能匹配,直到找到href"为止 [^"]表示向右匹配,到"为止 因此,三个都能匹配 2、 正则函数 寻找结果 源文件 正则函数运…...

【CMake】为可执行程序或静态库添加 Qt 资源文件,静态库不生效问题
【CMake】添加静态库中的 Qt 资源 文章目录 可执行程序1. 创建资源文件(.qrc)2. 修改 CMakeLists.txt3. 使用资源文件 静态库1. 修改 CMakeLists.txt2. 使用资源2.1 初始化资源文件2.2 可执行程序中调用 这里介绍的不是使用 Qt 创建工程时默认的 CMakeLi…...

服务器、jvm、数据库的CPU飙高怎么处理
服务器 CPU 飙高处理 排查步骤: 监控工具:使用操作系统自带的监控工具,比如 top、htop、sar、vmstat 等,查看哪些进程占用了大量的 CPU 资源。进程排查:通过 top 等工具找到消耗 CPU 最高的进程,确定是哪…...

自适应过滤法—初级
#课本P144例题 """ Python 简单的自适应过滤移动平均预测方法 """ import numpy as np import matplotlib.pyplot as plt#用于迭代的函数 def self_adaptive( seq, N, k, maxsteps ):## 初始化序列seq_ada = np.zeros( len(seq) ) # 设置预测…...

UML图有用吗?真正厉害的软件开发,有用的吗?什么角色用?
UML(Unified Modeling Language,统一建模语言)图在软件开发中是有用的,但其使用取决于项目的规模、复杂度以及开发团队的实践习惯。真正厉害的开发者并非一定要依赖UML图,但在某些情况下,UML图确实能够提升…...

基于Java+Springboot+Vue开发的酒店客房预订管理系统
项目简介 该项目是基于JavaSpringbootVue开发的酒店客房预订管理系统(前后端分离),这是一项为大学生课程设计作业而开发的项目。该系统旨在帮助大学生学习并掌握Java编程技能,同时锻炼他们的项目设计与开发能力。通过学习基于Java…...

OpenCV高级图形用户界面(5)获取指定滑动条(trackbar)的当前位置函数getTrackbarPos()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 返回滑动条的位置。 该函数返回指定滑动条的当前位置。 cv::getTrackbarPos() 函数用于获取指定滑动条(trackbar)的当前…...
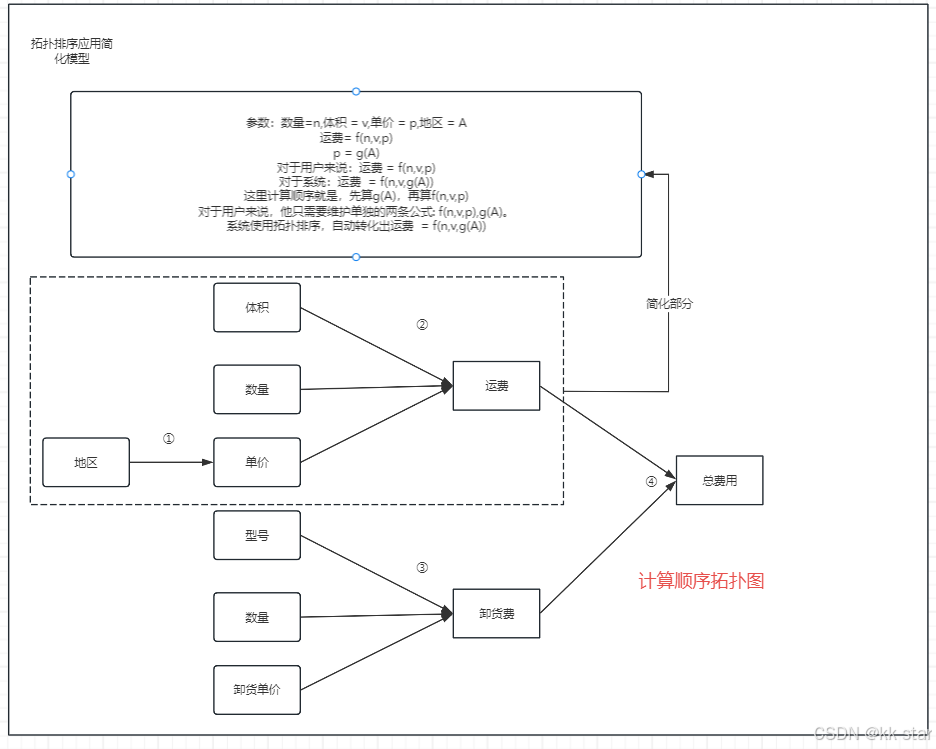
拓扑排序在实际开发中的应用
1. 拓扑排序说明 简单解释:针对于有向无环图(DAG),给出一个可行的节点排序,使节点之间的依赖关系不冲突。 复杂解释:自行搜索相关资料。 本次应用中的解释:给出一个可行的计算顺序࿰…...

【CTF-SHOW】Web入门 Web27-身份证日期爆破 【关于bp intruder使用--详记录】
1.点进去 是一个登录系统,有录取名单和学籍信息 发现通过姓名和身份证号可以进行录取查询,推测录取查询可能得到学生对应学号和密码,但是身份证号中的出生日期部分未知,所以可以进行爆破 2.打开bp抓包 这里注意抓的是学院录取查…...

告别虚拟机卡顿:在Windows 11的WSL2里搞定Lichee Nano交叉编译环境
告别虚拟机卡顿:在Windows 11的WSL2里搞定Lichee Nano交叉编译环境 对于嵌入式开发者来说,配置开发环境往往是个令人头疼的问题。传统虚拟机方案虽然能提供完整的Linux体验,但资源占用高、启动慢、与宿主系统交互不便等问题一直困扰着开发者。…...

用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程
用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程当你第一次接触脑电信号处理时,面对原始数据文件可能会感到无从下手。BCI Competition IV 2a数据集作为脑机接口领域的经典基准数据,包含了9名受试者四种运动想…...

智慧无人机巡检-无人机可见光红外数据集 无人机多模态检测数据集 红外与可见光检测数据集
智慧无人机巡检-无人机可见光红外数据集,已完成标注,可导出各种常用数据集,yolo,voc,coco等格式。可见光33000张,红外16100张,目标一张一个 无人机可见光红外目标数据集项目详细信息数据集名称无…...

从“DOC/PDF”到“WPS”:细看GJB438C-2021文档格式要求背后的国产化信号与落地指南
从“DOC/PDF”到“WPS”:GJB438C-2021文档格式变革的深度解读与实施策略 当一份国家军用标准在文档格式描述中刻意删除"DOC/PDF"字样,转而明确标注"(WPS)文档处理器"时,这绝非简单的技术参数调整。…...

WebSocket实时通信架构进阶:Room、命名空间与集群部署
WebSocket实时通信架构进阶:Room、命名空间与集群部署 作者:Crown_22 | AI Agent & Hermes Agent 桌面程序开发者 前言 WebSocket已经成为实时应用的标准技术,但大多数教程只停留在"建立连接、发送消息"的基础阶段。在生产环境中,你需要处理Room管理、命名空…...

ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库
ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various c…...
)
Unity/Unreal开发者必看:用手机和陀螺仪实验,5分钟搞懂万向节死锁(附避坑指南)
Unity/Unreal开发者实战指南:用手机陀螺仪5分钟破解万向节死锁当你调试第一人称视角时,角色突然卡在墙面无法转动;当无人机模型在俯冲90度时失控乱转——这些很可能都是万向节死锁(Gimbal Lock)在作祟。作为实时3D开发中最恼人的数学陷阱之一…...

【C++】零基础入门 · 第 5 节:函数基础
前面四节我们写的代码都集中在 main 函数里。随着程序变复杂,所有逻辑堆在一起会越来越难维护。函数就是用来解决这个问题的——它把一段代码「打包」起来,取个名字,需要的时候调用就行。 1. 为什么需要函数 假设你需要在程序的不同地方打印一行分隔线: cout << &…...
与 NOT EXISTS 优化)
PostgreSQL Join 执行策略(Nested Loop、Hash Join、Merge Join)与 NOT EXISTS 优化
以集成数据压缩 SQL 优化为例,用大白话讲清楚 Nested Loop、Hash Join、Merge Join 三种执行策略。一、背景:一条慢 SQL 引发的思考 在对上游下发数据做压缩时,有这样一条 UPDATE SQL: -- ❌ 原始写法 UPDATE magellan_nk_order_i…...

AI Agent 为什么必须有“记忆系统”?
导语:大模型不是没有智商,而是经常没有“记性”。真正能长期干活的 Agent,不是靠无限拉长上下文,而是靠一套会压缩、会检索、会遗忘、会治理的外置记忆系统。一、先给结论:Agent 的记忆系统,本质是“上下文…...