【论文#码率控制】ADAPTIVE RATE CONTROL FOR H.264
目录
- 摘要
- 1.前言
- 2.基本知识
- 2.1 蛋鸡悖论
- 2.2 基本单元的定义
- 2.3 线性MAD预测模型
- 3.GOP级码率控制
- 3.1 总比特数
- 3.2 初始化量化参数
- 4.帧级码率控制
- 4.1 非存储图像的量化参数
- 4.2 存储图像的目标比特
- 5.基本单元级码率控制
- 6.实验结果
- 7.结论
《ADAPTIVE RATE CONTROL FOR H.264》
Author: Z.G. Li; F. Pan; K.P. Lim; X. Lin; S. Rahardja
Published in: 2004 International Conference on Image Processing, 2004. ICIP '04.
Date of Conference: 24-27 October 2004
Date Added to IEEE Xplore: 18 April 2005
Print ISBN:0-7803-8554-3
Print ISSN: 1522-4880
DOI: 10.1109/ICIP.2004.1419405
Publisher: IEEE
Conference Location: Singapore
摘要
本文提出了一种针对H.264的码率控制方案,通过引入基本单元和线性预测模型的概念。基本单元可以是宏块(MB)、切片或帧。它可以用于在整体编码效率和比特波动之间取得平衡。线性模型用于解决H.264码率控制中存在的“先有鸡还是先有蛋”的困境。本文研究了恒定比特率(CBR)和可变比特率(VBR)两种情况。我们的方案已被H.264采纳
1.前言
码率控制用于根据指定的比特率和当前帧的统计信息(如每个宏块(MB)的MAD和头部比特数)来计算当前帧的量化参数。H.264的码率控制比MPEG-2和TMN 8更复杂,因为在MPEG-2和TMN 8中,当前帧的统计信息是可用的,而在H.264的码率控制中则不可用[1, 2]。这是因为在H.264中,量化参数不仅涉及码率控制,还涉及率失真优化(RDO),而在MPEG-2、MPEG-4和H.263中,量化参数仅涉及码率控制。当在H.264中实现码率控制时,存在一个典型的“蛋鸡悖论”的困境:为了对一个宏块执行RDO,首先需要使用当前帧的统计信息来确定该宏块的量化参数。然而,当前帧的统计信息只有在执行RDO之后才可用。
一种直观的方法是通过前一帧中对应位置的宏块(MB)的统计信息来预测当前帧中每个宏块的统计信息。然而,这种方法在宏块级别存在一些问题。例如,假设当前帧中的一个宏块是I宏块(Intra-MB),而前一帧中对应位置的宏块是P宏块(Inter-MB)。为了解决这个问题,我们引入了“基本单元”的概念,基本单元可以是宏块(MB)、切片或帧。同一基本单元中的所有宏块共享一个共同的量化参数。基本单元的选择取决于编码图片缓冲区(CPB)的大小。然后,通过引入线性模型来预测当前存储图片中剩余基本单元的MAD值,利用前一存储图片中对应位置的基本单元的实际MAD值,提出了一个自适应基本单元层的码率控制方案,用于H.264。这解决了上述的“先有鸡还是先有蛋”的困境。通过线性模型和基本单元的概念,我们的方案详细描述如下:利用流体流量模型和线性跟踪理论,结合帧率、当前缓冲区占用、目标缓冲区水平和可用信道带宽,计算当前帧的目标比特数。目标比特数进一步由考虑假设参考解码器(HRD)得出的两个值进行限制。当前帧的剩余比特数根据预测的MAD值分配给剩余的基本单元。使用二次率失真(R-D)模型计算相应的量化参数,然后用于对当前基本单元中的每个宏块执行RDO。与使用固定量化参数的H.264编码器相比,我们的方案可以将平均PSNR提高多达0.78dB。在正常测试条件下,对于所有H.264测试序列,改进的平均PSNR为0.43dB。我们的方案已被H.264采纳。
PS:
(1) 蛋鸡悖论问题,为了执行RDO,需要统计信息确定量化参数,但统计信息只有在执行一遍RDO之后才可用
(2) 基本单元可以是宏块,slice或者是frame,同一个基本单元中的所有宏块使用同一个量化参数
(3) 引入线性模型来预测当前图片中剩余基本单元的MAD值,依据是前一帧图片对应位置的基本单元实际MAD值
(4) 目标比特数由HRD限制,当前帧剩余比特数由预测MAD值分配给剩余的基本单元
(5) 相对于CQP模式,性能增益为0.78dB;相对于常规环境,增益为0.43dB
2.基本知识
2.1 蛋鸡悖论
H.264码率控制相关的宏块(MB)编码过程如下[31]:当前帧的统计信息 → 码率控制 → 量化参数 → RDO → 当前帧的统计信息 → 熵编码。
显然,在实施码率控制时存在一个“先有鸡还是先有蛋”的困境。正因为如此,H.264的码率控制比TM 5、Q2和TMN 8更困难。为了研究H.264的码率控制,我们需要找到一种方法来估计当前帧的统计信息。除此之外,我们还需要确定共享一个量化参数的连续宏块的数量。
2.2 基本单元的定义
假设一帧由 N m b p i c N_{mbpic} Nmbpic 个宏块(MBs)组成。定义一个基本单元为一组连续的宏块,其中包含 N m b u n i t N_{mbunit} Nmbunit个宏块, N m b u n i t N_{mbunit} Nmbunit是 N m b p i c N_{mbpic} Nmbpic的一个部分[14]。用 N u n i t N_{unit} Nunit表示一帧中基本单元的总数,计算公式为
N u n i t s = N m b p i c / N m b u n i t N_{units}=N_{mbpic}/N_{mbunit} Nunits=Nmbpic/Nmbunit
PS:
(1) 类似于HEVC标准中量化组(quantization group,QG)
(2) 这里描述的基本单元对码率控制的功能,类似于x264中的行级码控,但x264中每个mb的qp可以不同,使用每一行的平均qp来控制
2.3 线性MAD预测模型
假设第j幅图像是一个存储的图像,且两个存储图像之间连续的非存储图像的数量为L。提出了以下线性模型(1)来解决“先有鸡还是先有蛋”的困境[14]。
σ ~ l , i ( j ) = a 1 ∗ σ l , i ( j − L + 1 ) + a 2 ( 1 ) \tilde{\sigma}_{l, i}(j)=a_1 * \sigma_{l, i}(j - L + 1) + a_2 (1) σ~l,i(j)=a1∗σl,i(j−L+1)+a2(1)
其中 σ ~ l , i ( j ) \tilde{\sigma}_{l, i}(j) σ~l,i(j) 是第i个GOP中当前存储图像的第l个基本单元的预测MAD值。 σ l , i ( j − L + 1 ) \sigma_{l, i}(j - L + 1) σl,i(j−L+1)是前一个存储图像的第i个基本单元的实际MAD值。 a 1 a_1 a1和 a 2 a_2 a2是预测模型的两个系数。初始值 a 1 a_1 a1设为1, a 2 a_2 a2设为0。它们在编码每个基本单元后进行更新。
注释 1: 应该指出, σ ~ l , i ( j ) \tilde{\sigma}_{l, i}(j) σ~l,i(j) 是预测的参考值。参考值有许多其他选择。例如,可以在执行RDO之前,对当前图像中的所有宏块(MBs)进行16×16基于的运动估计和运动补偿。我们也可以使用前一帧中最可能的模式进行运动估计和补偿,以获得粗略的信息。所得的MAD也可以用作参考值。为了简化,我们选择\sigma_{l, i}(j - L + 1) 作为参考值。头部比特数也可以通过这种方式获得。同样,预测模型也有许多种,为了简化,我们选择了线性模型。
PS:
(1) 存储图像表示Intra帧、P帧这样会被存储在内存中,用于参考的帧;而B帧这样不会被用于参考的帧称之为非存储图像
(2) 将基本单元假设为mb易于理解,当前mb的MAD值与参考mb的MAD值用线性关系来描述
3.GOP级码率控制
在这个层级,计算分配给每个GOP的总比特数,并设置每个GOP的初始量化参数。
3.1 总比特数
分配给第i个GOP的初始比特数(第一个帧,即IDR帧)按如下方式计算
B i ( 1 ) = R i ( 1 ) f N i + B i − 1 ( N i − 1 ) ( 2 ) B_{i}(1)=\frac{R_{i}(1)}{f}N_{i} + B_{i-1}(N_{i-1}) (2) Bi(1)=fRi(1)Ni+Bi−1(Ni−1)(2)
其中 R i ( j ) R_{i}(j) Ri(j) 是可用的信道带宽,可以是恒定的或时变的, N i − 1 N_{i-1} Ni−1表示第(i−1)个GOP中的总帧数,f 是预定义的帧率,由于信道带宽可能随时改变, B i B_{i} Bi的更新方式为
B i ( j ) = B i ( j − 1 ) − b i ( j − 1 ) + R i ( j ) − R i ( j − 1 ) f ( N i − j + 1 ) ; j = 2 , 3 , . . . , N i B_i(j)=B_{i}(j-1)-b_{i}(j-1)+\frac{R_{i}(j)-R_{i}(j-1)}{f}(N_{i}-j+1); j=2,3,...,N_{i} Bi(j)=Bi(j−1)−bi(j−1)+fRi(j)−Ri(j−1)(Ni−j+1);j=2,3,...,Ni
其中, b i ( j − 1 ) b_i(j-1) bi(j−1)表示第i个GOP当中的第j帧实际编码比特
PS:
(1) 针对于公式(2),假设i=1,即第一个GOP,有 B 1 ( 1 ) = R 1 ( 1 ) f N 1 B_{1}(1)=\frac{R_{1}(1)}{f}N_{1} B1(1)=fR1(1)N1,其中 R 1 ( 1 ) f \frac{R_{1}(1)}{f} fR1(1)表示单帧消耗比特数, N 1 N_{1} N1表示GOP一共有多少帧,二者的乘积表示GOP1的初始比特数。因此, B 1 ( 1 ) B_{1}(1) B1(1)表示GOP1总共需要分配多少比特
(2) 针对于 B i B_{i} Bi的更新方式,假设i=1,j=2,即GOP1的第二帧,有 B 1 ( 2 ) = B 1 ( 1 ) − b 1 ( 1 ) + R 1 ( 2 ) − R 1 ( 1 ) f ( N 1 − 1 ) B_{1}(2)=B_{1}(1)-b_{1}(1)+\frac{R_{1}(2)-R_{1}(1)}{f}(N_{1}-1) B1(2)=B1(1)−b1(1)+fR1(2)−R1(1)(N1−1),将前面计算的 B 1 ( 1 ) B_{1}(1) B1(1)带入展开,得到 B 1 ( 2 ) = R 1 ( 1 ) f − b 1 ( 1 ) + R 1 ( 2 ) f ( N 1 − 1 ) B_{1}(2)=\frac{R_{1}(1)}{f}-b_{1}(1)+\frac{R_{1}(2)}{f}(N_{1}-1) B1(2)=fR1(1)−b1(1)+fR1(2)(N1−1),其中 R 1 ( 1 ) f − b 1 ( 1 ) \frac{R_{1}(1)}{f}-b_{1}(1) fR1(1)−b1(1)表示预期第一帧编码比特数减去实际比特数, R 1 ( 2 ) f ( N 1 − 1 ) \frac{R_{1}(2)}{f}(N_{1}-1) fR1(2)(N1−1)表示按照当前带宽进行计算,当前GOP的后续所有帧的预期编码比特数。因此, B 1 ( 2 ) B_{1}(2) B1(2)表示的是GOP1,从第二帧开始计算一直到GOP1结束的所有帧比特数,后续的计算如 B 1 ( 3 ) B_{1}(3) B1(3)、 B 1 ( 4 ) B_{1}(4) B1(4)类似
(3) 针对于公式(2),假设i=2,即GOP2,有 B 2 ( 1 ) = R 2 ( 1 ) f N 2 + B 1 ( N 1 ) B_{2}(1)=\frac{R_{2}(1)}{f}N_{2}+B_{1}(N_{1}) B2(1)=fR2(1)N2+B1(N1)。根据前面的理解, B 1 ( N 1 ) B_{1}(N_{1}) B1(N1)表示的是GOP1,从第 N 1 N_{1} N1帧开始计算一直到第一个GOP结束的所有帧的比特数,而GOP1只有 N 1 N_{1} N1帧,所以这里的 B 1 ( N 1 ) B_{1}(N_{1}) B1(N1)可以理解为第一个GOP当中预期的编码比特数与实际编码比特数的差异。 R 2 ( 1 ) f N 2 \frac{R_{2}(1)}{f}N_{2} fR2(1)N2表示的是以当前带宽计算,帧数为 N 2 N_{2} N2总共需要消耗的比特数。因此, B 2 ( 1 ) B_{2}(1) B2(1)表示的是在GOP1实际编码情况的基础之上,GOP2预期使用多少比特
(4) B i − 1 ( N i − 1 ) B_{i-1}(N_{i-1}) Bi−1(Ni−1)也被称为虚拟缓冲区(Virtual Buffer),描述了预期编码比特与实际编码比特的差异程度,并以此来调整码率控制。虚拟缓冲区在x264中就是VBV,实现细节上有出入
3.2 初始化量化参数
在本文中,第i个GOP中的初始量化参数 Q P i ( 1 ) QP_{i}(1) QPi(1)是基于可用信道带宽和GOP长度预定义的。IDR图像和GOP的第一个存储图像由 Q P i ( 1 ) QP_{i}(1) QPi(1)编码,其他的 Q P i ( 1 ) QP_{i}(1) QPi(1)的计算方式为
Q P i ( 1 ) = m a x { m i n { S u m P Q P ( i − 1 ) N p ( i − 1 ) − m i n { 2 , N i − 1 15 } , Q P i − 1 ( 1 ) + 2 } , Q P i − 1 ( 1 ) − 2 } QP_{i}(1) =max\{min\{\frac{Sum_{PQP}(i-1)}{N_p(i-1)} - min\{2, \frac{N_{i-1}}{15}\}, QP_{i-1}(1)+2\}, QP_{i-1}(1)-2\} QPi(1)=max{min{Np(i−1)SumPQP(i−1)−min{2,15Ni−1},QPi−1(1)+2},QPi−1(1)−2}
其中 N p ( i − 1 ) N_{p}(i-1) Np(i−1)是第(i−1) 个GOP中存储图像的总数, S u m P Q P ( i − 1 ) Sum_{PQP}(i-1) SumPQP(i−1)是第(i−1) 个GOP中所有存储图像的量化参数之和。 Q P i ( 1 ) QP_{i}(1) QPi(1)进一步通过以下方式进行调整:
Q P i ( 1 ) = Q P i ( 1 ) − 1 ; i f Q P i ( 1 ) > Q P i − 1 ( N i − 1 − L ) − 2 QP_{i}(1)=QP_{i}(1)-1; if QP_{i}(1) > QP_{i-1}(N_{i-1}-L)-2 QPi(1)=QPi(1)−1;ifQPi(1)>QPi−1(Ni−1−L)−2
其中 Q P i − 1 ( N i − 1 − L ) QP_{i-1}(N_{i-1}-L) QPi−1(Ni−1−L)是第(i−1) 个GOP中最后一个存储图像的量化参数。显然, Q P i ( 1 ) QP_{i}(1) QPi(1)既适应于GOP的长度,也适应于可用的信道带宽
PS:
(1) 对于IDR帧和第一个P帧,根据bpp的大小确定qp,bpp的计算方式为 b p p = ( b i t r a t e / f r a m e r a t e ) ∗ N p i x e l bpp=(bitrate / framerate) * N_{pixel} bpp=(bitrate/framerate)∗Npixel,即每个像素平均使用的比特数,依据bpp确定qp的方式如下
q p = { 35 b p p ≤ L 1 25 b p p ≤ L 2 20 b p p ≤ L 3 10 o t h e r w i s e qp=\left\{ \begin{array}{rcl} 35 & & {bpp \leq L1} \\ 25 & & {bpp \leq L2} \\ 20 & & {bpp \leq L3} \\ 10 & & {otherwise} \end{array} \right. qp=⎩ ⎨ ⎧35252010bpp≤L1bpp≤L2bpp≤L3otherwise
其中,L1,L2和L3由视频的宽度计算。对于QCIF视频(176x144)推荐L1 = 0.1,L2 = 0.3,L3 = 0.6;对于CIF视频(352x288)推荐L1 = 0.2,L2 = 0.6,L3 = 1.2;其他情况L1 = 0.6,L2 = 1.4,L3 = 2.4 (参考H264编码-码率控制原理以及JM代码分析)
(2) 其他GOP中初始QP的计算方式可以拆分来理解。
(a) m i n { 2 , N i − 1 15 } min\{2, \frac{N_{i-1}}{15}\} min{2,15Ni−1}表示一个基于GOP内帧数量的调控因子,如果帧数量大于30,则调控因子为2,否则为 N i − 1 15 \frac{N_{i-1}}{15} 15Ni−1
(b) m i n { S u m P Q P ( i − 1 ) N p ( i − 1 ) − m i n { 2 , N i − 1 15 } , Q P i − 1 ( 1 ) + 2 } min\{\frac{Sum_{PQP}(i-1)}{N_{p}(i-1)}-min\{2, \frac{N_{i-1}}{15}\},QP_{i-1}(1)+2\} min{Np(i−1)SumPQP(i−1)−min{2,15Ni−1},QPi−1(1)+2},其中的 S u m P Q P ( i − 1 ) N p ( i − 1 ) \frac{Sum_{PQP}(i-1)}{N_{p}(i-1)} Np(i−1)SumPQP(i−1)表示前一个GOP中PQP的平均值。除去调控因子的考虑,这里表示的含义是,前一个GOP中PQP的均值和前一个GOP的初始QP,取二者中小的一个
(c) m a x { X , Q P i − 1 + 2 } max\{X, QP_{i-1}+2\} max{X,QPi−1+2},其中X表示(b)中计算的结果
(d) 综上所述,其他GOP中初始QP的计算方式将前一个GOP的初始QP和平均实际编码QP进行对比,增加一些调控因子,确定初始QP。这里更像是一个加上调控因子的clip3操作
(3) 如果经过上面的计算之后,当前GOP初始QP值大于前一个GOP最后一个P帧QP - 2,再将当前GOP初始QP减小1,进行微调
4.帧级码率控制
在这一层,计算了非存储图像的量化参数和存储图像的目标比特。
4.1 非存储图像的量化参数
非存储图片的量化参数通过线性插值方法得到,如下所示:
假设第j帧和(j+L+ 1)帧是存储的图片,相邻的两个存储图片 Q P i ( j ) QP_{i}(j) QPi(j)和 Q P i ( 1 ) QP_{i}(1) QPi(1)的量化参数分别为。根据以下两种情况给出第k (1<= k <= L)张非存储图片的量化参数:
(1) 情况1 当L=1 时,两个存储图像之间只有一幅非存储图像。量化参数由以下公式计算:
Q P i ( j + 1 ) = { Q P i ( j ) + Q P i ( j + 2 ) + 2 2 Q P i ( j ) ≠ Q P i ( j + 2 ) Q P i ( j ) + 2 O t h e r w i s e QP_{i}(j+1)=\left\{ \begin{array}{rcl} \frac{QP_{i}(j) + QP_{i}(j+2)+2}{2} & & {QP_{i}(j) \neq QP_{i}(j+2)}\\ QP_{i}(j)+2 & & {Otherwise}\\ \end{array} \right. QPi(j+1)={2QPi(j)+QPi(j+2)+2QPi(j)+2QPi(j)=QPi(j+2)Otherwise
(2) 情况2 当L>1 时,两个存储图像之间有多幅非存储图像。量化参数由以下公式计算:
Q P i ( j + k ) = Q P i ( j ) + α + m a x { − 2 ( k − 1 ) , m i n { ( Q P i ( j + L + 1 ) − Q P i ( j ) ) ( k − 1 ) L − 1 , 2 ( k − 1 ) } } QP_{i}(j+k)=QP_{i}(j)+\alpha+max\{-2(k-1), \\ min\{\frac{(QP_{i}(j+L+1)-QP_{i}(j))(k-1)}{L-1}, 2(k-1)\}\} QPi(j+k)=QPi(j)+α+max{−2(k−1),min{L−1(QPi(j+L+1)−QPi(j))(k−1),2(k−1)}}
其中 α \alpha α是第一个非存储图像的量化参数与 Q P i ( j ) QP_{i}(j) QPi(j) 之间的差值,计算公式为
α = { − 3 Q P i ( j + L + 1 ) − Q P i ( j ) ≤ − 2 L − 3 − 2 Q P i ( j + L + 1 ) − Q P i ( j ) = − 2 L − 2 − 1 Q P i ( j + L + 1 ) − Q P i ( j ) = − 2 L − 1 0 Q P i ( j + L + 1 ) − Q P i ( j ) = − 2 L 1 Q P i ( j + L + 1 ) − Q P i ( j ) = − 2 L + 1 2 O t h e r w i s e \alpha=\left\{ \begin{array}{rcl} -3 & & {QP_{i}(j+L+1) - QP_{i}(j) \leq -2L-3}\\ -2 & & {QP_{i}(j+L+1) - QP_{i}(j) = -2L-2}\\ -1 & & {QP_{i}(j+L+1) - QP_{i}(j) = -2L-1}\\ 0 & & {QP_{i}(j+L+1) - QP_{i}(j) = -2L}\\ 1 & & {QP_{i}(j+L+1) - QP_{i}(j) = -2L+1}\\ 2 & & {Otherwise}\\ \end{array} \right. α=⎩ ⎨ ⎧−3−2−1012QPi(j+L+1)−QPi(j)≤−2L−3QPi(j+L+1)−QPi(j)=−2L−2QPi(j+L+1)−QPi(j)=−2L−1QPi(j+L+1)−QPi(j)=−2LQPi(j+L+1)−QPi(j)=−2L+1Otherwise
PS:
(1) 非存储图像通常指的是B帧这种不会被其他帧用于参考的图像
(2) 如果L=1,假设当前编码序列为 … P B P …,直接取两个P帧QP的均值
(3) 如果L>1,假设当前编码序列为 … P B B B P …,将计算公式分解
(a) m i n { ( Q P i ( j + L + 1 ) − Q P i ( j ) ) ( k − 1 ) L − 1 , 2 ( k − 1 ) } min\{\frac{(QP_{i}(j+L+1)-QP_{i}(j))(k-1)}{L-1}, 2(k-1)\} min{L−1(QPi(j+L+1)−QPi(j))(k−1),2(k−1)}中的 ( Q P i ( j + L + 1 ) − Q P i ( j ) ) ( k − 1 ) L − 1 \frac{(QP_{i}(j+L+1)-QP_{i}(j))(k-1)}{L-1} L−1(QPi(j+L+1)−QPi(j))(k−1)表示第k个B帧,以第j个P帧和第j+L+1个P帧的距离为权重计算的QP调整因子
(b) m a x { − 2 ( k − 1 ) , X } max\{-2(k-1), X\} max{−2(k−1),X},其中X表示(a)中计算的结果。(a)和(b)中的步骤是对QP调整权重因子进行clip操作
(c) 第k个B帧的QP,以第j个P帧的QP作为基础( Q P i ( j ) QP_{i}(j) QPi(j)),加上偏移量( α \alpha α和QP调整因子)获得
(d) α \alpha α的数值与两个P帧之间的距离有关,经验性参数
4.2 存储图像的目标比特
分配给当前存储图像的比特数应根据当前缓冲区占用情况和图像复杂度进行调整,如下所示:
(1) 步骤1 为当前GOP中的每个存储图像预定义一个目标缓冲区水平。
假设第j幅图像是一个存储图像。该图像的目标缓冲区水平由以下方式确定
S i ( j ) = S i ( j − L − 1 ) − S i ( 2 ) − V s 8 N p ( i ) − 1 + W ‾ p , i ( j − L − 1 ) ( L + 1 ) R i ( j ) f ( W ‾ p , i ( j − L − 1 ) + W ‾ b , i ( j − 1 ) L ) − R i ( j ) f S_{i}(j)=S_{i}(j-L-1)-\frac{S_i(2)-\frac{V_s}{8}}{N_{p}(i)-1}+\\ \frac{\overline{W}_{p,i}(j-L-1)(L+1)R_{i}(j)}{f(\overline{W}_{p,i}(j-L-1)+\overline{W}_{b,i}(j-1)L)}-\frac{R_{i}(j)}{f} Si(j)=Si(j−L−1)−Np(i)−1Si(2)−8Vs+f(Wp,i(j−L−1)+Wb,i(j−1)L)Wp,i(j−L−1)(L+1)Ri(j)−fRi(j)
其中 S i ( 2 ) S_{i}(2) Si(2)在编码第i个GOP中的第一个存储图像 (即IDR帧) 后重置为 V i ( 2 ) V_{i}(2) Vi(2), V s V_s Vs 是缓冲区大小, W ‾ p , i ( j − L − 1 ) \overline{W}_{p,i}(j-L-1) Wp,i(j−L−1) 是已编码存储图像的平均复杂度权重 (涵盖过去所有可用于计算的帧集合而非单帧), W ‾ b , i ( j − 1 ) \overline{W}_{b,i}(j-1) Wb,i(j−1)是已编码非存储图像的复杂度权重[4]。
PS:
(1) 存储图像通常指的是Intra帧以及P帧,因为它们会被用于参考,所以会存储在内存中
(2) 假设当前编码序列为 … P B B B P B B B P …,其中第一个P帧的索引为j-L-1,第二个P帧的索引为j,第三个P帧的索引为j+l+1。在步骤1中,为当前存储图像计算一个缓冲区,将计算的公式进行拆分
(a) S i ( j ) S_{i}(j) Si(j)表示当前P帧在编码之后的目标缓冲区的比特数
(b) S i ( j − L − 1 ) S_{i}(j-L-1) Si(j−L−1)表示前一个P帧在编码之后的目标缓冲区的比特数
(c) S i ( 2 ) − V s 8 N p ( i ) − 1 \frac{S_i(2)-\frac{V_s}{8}}{N_{p}(i)-1} Np(i)−1Si(2)−8Vs中的 S i ( 2 ) S_{i}(2) Si(2)可以改写成 V i ( 2 ) V_{i}(2) Vi(2),表示第一个存储图像(通常是IDR帧)编码之后buffer中的实际比特数。分子部分表示编码当前帧之后,buffer中的比特数,buffer的实际比特数减去1/8,这是因为在计算复杂度时,当前帧的权重系数为1/8,前面一系列帧的平均复杂度的权重系数为7/8。随后,除以当前GOP中P帧数量减去1。因此,(c)表示了编码当前帧之后实际比特数的多少,或者理解为水池出水量。
(d) W ‾ p , i ( j − L − 1 ) ( L + 1 ) R i ( j ) f ( W ‾ p , i ( j − L − 1 ) + W ‾ b , i ( j − 1 ) L ) − R i ( j ) f \frac{\overline{W}_{p,i}(j-L-1)(L+1)R_{i}(j)}{f(\overline{W}_{p,i}(j-L-1)+\overline{W}_{b,i}(j-1)L)}-\frac{R_{i}(j)}{f} f(Wp,i(j−L−1)+Wb,i(j−1)L)Wp,i(j−L−1)(L+1)Ri(j)−fRi(j)包含了B帧对当前P帧的影响,将公式中的 W ‾ p , i ( j − L − 1 ) \overline{W}_{p,i}(j-L-1) Wp,i(j−L−1)和 W ‾ b , i ( j − L − 1 ) \overline{W}_{b,i}(j-L-1) Wb,i(j−L−1)简记为 W p W_{p} Wp和 W b W_{b} Wb,公式变形为 ( W p ( L + 1 ) W p + W b L − 1 ) ∗ R i ( j ) f (\frac{W_{p}(L+1)}{W_{p}+W_{b}L}-1) * \frac{R_{i}(j)}{f} (Wp+WbLWp(L+1)−1)∗fRi(j)。变形后的公式可以理解为,前一个P帧和前一个B帧分别赋予一个权重,对当前target buffer进行调控,这个权重由距离决定。在变式中,分子中的权重为L+1,表明仅考虑前一个P帧的复杂度对当前P帧的影响;在分母中,P帧复杂度权重为1,B帧复杂度为L,强调了更接近当前帧的B帧的复杂度。如果 W p W_p Wp大于 W b W_b Wb,则(d)这一项大于0,此时前一个P帧对应的平均复杂度偏高,表明target buffer应该增大一点,以适应较高的复杂度;反之,如果B帧对应的平均复杂度偏高,表明P帧的影响程度较小,target buffer应该减小一点。从这里来看,这个公式中主要的影响因子还是前一个P帧。另外,如果编码序列中没有B帧,则没有(d)这一项
(2) 步骤2 计算当前存储图像的目标比特数。
第i个GOP中的第j幅存储图像的目标比特数根据目标缓冲区水平、帧率、可用信道带宽和实际缓冲区占用情况确定,如下所示:
T ~ i ( j ) = R i ( j ) f + γ ( S i ( j ) − V i ( j ) ) \widetilde{T}_{i}(j)=\frac{R_{i}(j)}{f}+\gamma(S_{i}(j)-V_{i}(j)) T i(j)=fRi(j)+γ(Si(j)−Vi(j))
其中 V i ( j ) V_{i}(j) Vi(j)是编码第i个GOP中的第(j−1) 幅存储图像后的实际缓冲区占用情况, γ \gamma γ是一个常数,当没有非存储图像时其典型值为0.5,否则为0.25。
同时,在计算目标比特时,还应考虑剩余比特的数量
T ^ i ( j ) = W p , i ( j − L − 1 ) B i ( j ) W p , i ( j − L − 1 ) N p , r + W b , i ( j − 1 ) N b , r \hat{T}_{i}(j)=\frac{W_{p,i}(j-L-1)B_{i}(j)}{W_{p,i}(j-L-1)N_{p,r}+W_{b,i}(j-1)N_{b,r}} T^i(j)=Wp,i(j−L−1)Np,r+Wb,i(j−1)Nb,rWp,i(j−L−1)Bi(j)
其中 N p , r N_{p,r} Np,r和 N b , r N_{b,r} Nb,r分别是剩余存储图像和剩余非存储图像的数量。
目标比特是 T ~ i ( j ) \widetilde{T}_{i}(j) T i(j)和 T ~ i ( j ) \widetilde{T}_{i}(j) T i(j)的加权组合,如下所示
T i ( j ) = β T ^ i ( j ) + ( 1 − β ) T ~ i ( j ) ( 3 ) T_{i}(j)=\beta\hat{T}_{i}(j)+(1-\beta)\widetilde{T}_{i}(j) (3) Ti(j)=βT^i(j)+(1−β)T i(j)(3)
其中p是一个常数,当没有非存储图像时其典型值为0.5,否则为0.9。从公式(3)可以看出,通过选择较小的p可以实现严格的缓冲区节。
为了保持编码帧的质量,目标比特数 T i ( j ) T_i(j) Ti(j) 被限制在:
T i ( j ) = m a x { T i ( j ) , m h r d , i ( j − L − 1 ) + R i ( j ) 4 f } ( 4 ) T_{i}(j)=max\{T_{i}(j), m_{hrd,i}(j-L-1)+\frac{R_{i}(j)}{4f}\}(4) Ti(j)=max{Ti(j),mhrd,i(j−L−1)+4fRi(j)}(4)
其中 m h r d , i ( j − L − 1 ) m_{hrd,i}(j-L-1) mhrd,i(j−L−1)是用于前一个存储图像的头部和运动矢量的位数。
为了符合HRD(假设参考解码器)的要求,目标比特数进一步被限制为:
T i ( j ) = m i n { m a x { Z i ( j ) , T i ( j ) , U i ( j ) } } ( 5 ) T_{i}(j)=min\{max\{Z_{i}(j), T_{i}(j), U_{i}(j)\}\}(5) Ti(j)=min{max{Zi(j),Ti(j),Ui(j)}}(5)
其中 Z i ( j ) Z_i(j) Zi(j) 和 U i ( j ) U_i(j) Ui(j) 是根据HRD(假设参考解码器)的要求推导出来的[3]
PS:
(1) 在步骤2中,实现的功能是,基于前面的目标缓冲区大小来调整目标比特数
(2) 计算目标比特数时,分为两种情况考虑
(a) 基于目标缓冲区水平、帧率、可用信道带宽和实际缓冲区占用情况确定,将公式拆解
(a1) R i ( j ) f \frac{R_{i}(j)}{f} fRi(j)表示预期编码比特数,由信道带宽和帧率决定
(a2) γ ( S i ( j ) − V i ( j ) ) \gamma(S_{i}(j)-V_{i}(j)) γ(Si(j)−Vi(j))表示目标缓冲区大小和实际缓冲区大小的差异
(a3) 结合(a1)和(a2),这种情况下的目标比特数为预期编码比特数加上缓冲区差异值的调整
(b) 基于剩余比特的数量确定
(b1) 将公式中的 W p , i ( j − L − 1 ) W_{p,i}(j-L-1) Wp,i(j−L−1)和 W b , i ( j − 1 ) W_{b,i}(j-1) Wb,i(j−1)用 W p W_{p} Wp和 W b W_{b} Wb代替,可以改写为 T ^ i ( j ) = W p , i B i ( j ) W p , i N p , r + W b , i N b , r \hat{T}_{i}(j)=\frac{W_{p,i}B_{i}(j)}{W_{p,i}N_{p,r}+W_{b,i}N_{b,r}} T^i(j)=Wp,iNp,r+Wb,iNb,rWp,iBi(j),其中 B i ( j ) B_{i}(j) Bi(j)为剩余比特数,这里表示的含义是当前P帧的目标比特,等于P帧累积复杂度,除以帧类型及对应复杂度乘积。如果没有B帧,则当前公式变形为 B i ( j ) ∗ 1 N p , r B_{i}(j) * \frac{1}{N_{p,r}} Bi(j)∗Np,r1,即当前P帧的目标比特,等于剩余比特数除以剩余P帧的数量
5.基本单元级码率控制
基本单元级别的码率控制选择存储图像中所有基本单元的量化参数值,使得生成的比特数总和接近帧的目标比特数 T i ( j ) T_i(j) Ti(j)。以下是对该方法的逐步描述:
(1) 步骤1: 使用前一个存储图像中对应位置的基本单元的实际MAD值,通过模型(1)预测当前存储图像中剩余基本单元的MAD值
(2) 步骤2: 计算当前基本单元的纹理比特数 b ^ l , i ( j ) \hat{b}_{l,i}(j) b^l,i(j)。此步骤由以下三个子步骤组成:
(2.1) 步骤2.1 计算当前基本单元的目标比特数。设 T r , i ( j ) T_{r,i}(j) Tr,i(j) 表示当前存储图像中剩余基本单元的剩余比特数,且 T r , i ( j ) T_{r,i}(j) Tr,i(j) 的初始值为 T i ( j ) T_i(j) Ti(j)。第l个基本单元的目标比特数由以下公式给出
b ~ l , i ( j ) = T r , i ( j ) σ ~ l , i 2 ( j ) Σ k = l N u n i t σ ~ k , i 2 ( j ) \widetilde{b}_{l,i}(j)=T_{r,i}(j)\frac{\widetilde{\sigma}^2_{l,i}(j)}{\Sigma^{N_{unit}}_{k=l}\widetilde{\sigma}^2_{k,i}(j)} b l,i(j)=Tr,i(j)Σk=lNunitσ k,i2(j)σ l,i2(j)
(2.2) 步骤2.2 计算所有已编码基本单元生成的头部比特数的平均值:
m ~ h d r , l = m ~ h d r , l − 1 ( 1 − 1 l ) + m ^ h d r , i l \widetilde{m}_{hdr,l}=\widetilde{m}_{hdr,l-1}(1-\frac{1}{l})+\frac{\hat{m}_{hdr,i}}{l} m hdr,l=m hdr,l−1(1−l1)+lm^hdr,i
m h d r , l = m ~ h d r , l l N u n i t + m h d r , 1 ( 1 − l N u n i t ) m_{hdr,l}=\widetilde{m}_{hdr,l}\frac{l}{N_{unit}}+m_{hdr,1}(1-\frac{l}{N_{unit}}) mhdr,l=m hdr,lNunitl+mhdr,1(1−Nunitl)
其中 m ^ h d r , i \hat{m}_{hdr,i} m^hdr,i是当前存储图像中第l 个基本单元实际生成的头部比特数, m h d r , 1 m_{hdr,1} mhdr,1是从前一帧的所有基本单元中估计的值。
(2.3) 计算纹理比特数 b ^ l , i ( j ) \hat{b}_{l,i}(j) b^l,i(j):
b ^ l , i ( j ) = b ~ l , i ( j ) − m h d r , l \hat{b}_{l,i}(j)=\widetilde{b}_{l,i}(j)-m_{hdr,l} b^l,i(j)=b l,i(j)−mhdr,l
为了保证每个基本单元的质量, b ^ l , i ( j ) \hat{b}_{l,i}(j) b^l,i(j)随后还会除以 R i ( j ) / ( 4 f N u n i t ) R_{i}(j)/(4fN_{unit}) Ri(j)/(4fNunit)
PS:
(1) 将总比特数分为纹理比特数和头部比特数,总比特数由步骤(2.1)给出,头部比特数由步骤(2.2)给出,纹理比特数由步骤(2.3)给出
(2) 在步骤(2.2)中, m h d r , l m_{hdr,l} mhdr,l表示第l个基本单元的头部比特数,其由两部分组成:
(a) 基于帧内预测思想,利用当前帧前一个已编码单元,即第l-1个基本单元的头部比特数来获取。其中第l-1个基本单元的头部比特数权重为 ( 1 − 1 l ) (1-\frac{1}{l}) (1−l1),第l个基本单元实际生成的头部比特数占比为\frac{1}{l}
(b) 基于帧间预测思想,利用前一帧的所有已编码单元的平均值,即 m h d r , 1 m_{hdr,1} mhdr,1
(c) 计算第l个基本单元的头部比特数时,基于帧内思想获得的比特数权重为 l N u n i t \frac{l}{N_{unit}} Nunitl,基于帧间思想获得的比特权重为 1 − l N u n i t 1-\frac{l}{N_{unit}} 1−Nunitl。举例来说,假设 l = 50 l=50 l=50, N u n i t = 120 N_{unit}=120 Nunit=120,即处于整帧的前半部分编码,则帧间的权重较大,这是因为帧间部分使用的是前一帧中所有的已编码单元,这样可参考的信息更多;反之,假设 l = 100 l=100 l=100, N u n i t = 120 N_{unit}=120 Nunit=120,即处于整帧的后半部分编码,则帧内的权重较大,这是因为当前帧已经编码了很多单元,帧内可使用的信息足够多,其权重应该更大
(3) 最后,在获取了目标纹理比特数之后,还会做一个rounding
(3) 步骤3: 使用二次R-D模型[3]计算当前基本单元的量化参数。我们需要考虑以下三种情况:
情况1:当前存储图像中的第一个基本单元
Q P l , i ( j ) = Q P ^ i ( j − L − 1 ) QP_{l,i}(j)=\hat{QP}_{i}(j-L-1) QPl,i(j)=QP^i(j−L−1)
其中 Q P ^ i ( j − L − 1 ) \hat{QP}_{i}(j−L−1) QP^i(j−L−1) 是前一个存储图像中所有基本单元的量化参数的平均值。
情况2:当 T r , i < 0 T_{r,i}<0 Tr,i<0 时,当前基本单元的量化参数应大于前一个基本单元的量化参数,以使生成的比特数总和接近 T i ( j ) T_{i}(j) Ti(j)
Q P l , i = Q P l − 1 , i ( j ) + X b u QP_{l,i}=QP_{l-1,i}(j)+X_{bu} QPl,i=QPl−1,i(j)+Xbu
其中, X b u X_{bu} Xbu是两个连续基本单元的量化参数的变化范围。
为了保持视觉质量的平滑性,量化参数进一步被限制为:
Q P l , i ( j ) = m a x { 0 , Q P ‾ i ( j − L − 1 ) − Y f r , m i n { 51 , Q P ‾ i ( j − L − 1 ) + Y f r , Q P l , i ( j ) } } QP_{l,i}(j)=max\{0,\overline{QP}_{i}(j-L-1)-Y_{fr}, min\{51, \overline{QP}_{i}(j-L-1)+Y_{fr}, QP_{l,i}(j)\}\} QPl,i(j)=max{0,QPi(j−L−1)−Yfr,min{51,QPi(j−L−1)+Yfr,QPl,i(j)}}
其中, Y f r Y_{fr} Yfr是量化参数的进一步变化范围
情况3:否则,我们首先使用二次模型[3]和情况2中给出的限制来计算一个量化参数 Q P l , i ( j ) QP_{l,i}(j) QPl,i(j)
(4) 步骤4:对当前基本单元中的所有宏块(MBs)执行RDO。
(5) 步骤5:更新剩余比特数 T r , i ( j ) T_{r,i}(j) Tr,i(j),并更新头部MAD预测模型和二次R-D模型的参数。
(6) 步骤6:编码当前存储图像后,更新 Q P ^ i ( j ) \hat{QP}_{i}(j) QP^i(j)。
PS:
(1) 在步骤3当中,使用的二次RD模型如下,这是一个提案中的公式(Z. G. Li, W. Gao, Feng Pan, S. W. Ma. K. P. Lim, G. N.Feng, X. Lm, R. Susanto, Y. Lu and H. Q. Lu. “Adaptive rate control with HRD consideration”. In 8th meeting:Geneva, 23-27, May, 2003, JVT-H014)
T a r g e t _ b i t s = c 1 ∗ M A D Q S t e p + c 2 ∗ M A D Q S t e p ∗ Q S t e p Target\_bits=c_1 * \frac{MAD}{QStep}+c_2 * \frac{MAD}{QStep * QStep} Target_bits=c1∗QStepMAD+c2∗QStep∗QStepMAD
公式描述了量化步长、目标比特和MAD之间的对应关系。延续前面的步骤,这里可以根据前面获得的目标比特来计算QStep,根据QStep和QP的对应表,获得QP
(2) 在确定QP时,分为三种情况
(a) 如果是第一个基本单元,其QP由前一帧中所有基本编码单元的QP均值来确定
(b) 如果剩余目标比特小于0,则会适当增大QP。调整的依据是前后量化参数变化的范围
(c) 如果不属于前面两种情况,则先根据二次RD模型获得一个初始QP,随后添加情况2中的平滑性限制
(3) 在后续的步骤4,5,6中,根据前面计算出来的QP执行RDO过程,更新一系列参数
6.实验结果
我们将具有我们码率控制的H.264编码器的编码效率与具有固定量化参数的H.264编码器的编码效率进行了比较。这种类型的比较是由H.264的临时工作组根据[15]推荐的,实验设置在[4]中给出。表1列出了(Y, PSNR)的实验结果。结果显示,与使用固定量化参数的H.264编码器相比,我们的方案可以将平均PSNR提高多达0.78dB。在正常测试条件下,对于H.264测试序列,改进的平均PSNR为0.43dB。

7.结论
本文通过引入基本单元的概念和线性绝对差(MAD)预测模型,提出了一种自适应的H.264码率控制方案。对于H.264推荐的所有测试序列,整体平均PSNR改进为0.43dB。Remark 1中提供了一种替代方法,这将在我们未来的研究中进行探讨。
相关文章:
【论文#码率控制】ADAPTIVE RATE CONTROL FOR H.264
目录 摘要1.前言2.基本知识2.1 蛋鸡悖论2.2 基本单元的定义2.3 线性MAD预测模型 3.GOP级码率控制3.1 总比特数3.2 初始化量化参数 4.帧级码率控制4.1 非存储图像的量化参数4.2 存储图像的目标比特 5.基本单元级码率控制6.实验结果7.结论 《ADAPTIVE RATE CONTROL FOR H.264》 A…...

2024-10-16 学习人工智能的Day8
函数 定义(创建) 函数的创建def开始,后接函数名,在给参数表最后冒号表示函数基础信息给定 换行书写函数内部定义,在函数内部定义操作,最后函数自带返回,无定义返回值返回为None&…...

Python Django 数据库优化与性能调优
Python Django 数据库优化与性能调优 Django 是一个非常流行的 Python Web 框架,它的 ORM(对象关系映射)允许开发者以简单且直观的方式操作数据库。然而,随着数据量的增长,数据库操作的效率可能会成为瓶颈,…...
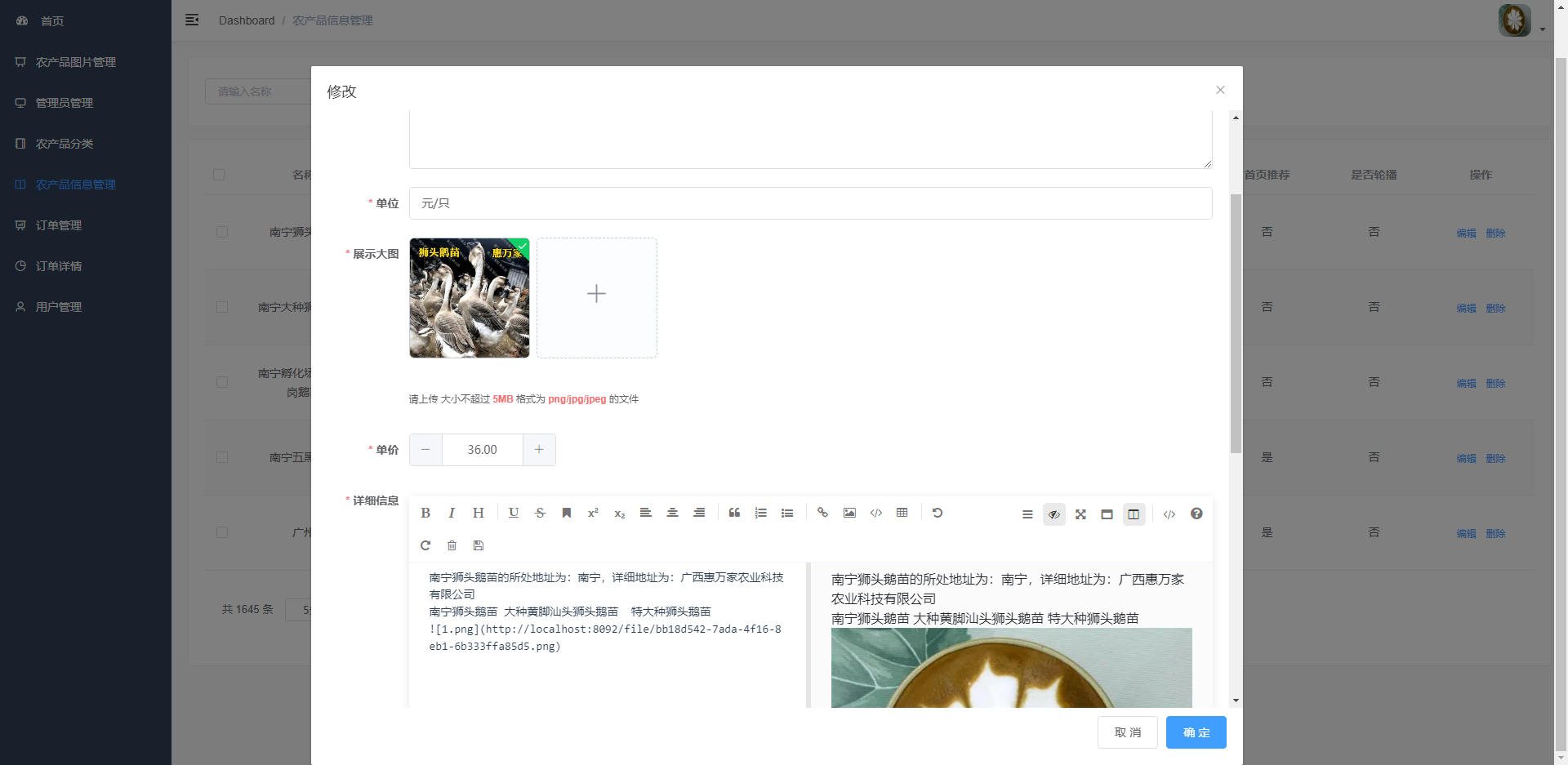
基于SpringBoot+微信小程序的农产品销售平台
基于SpringBoot微信小程序的农产品销售平台 ✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、项目…...

微前端学习以及分享
微前端学习以及分享 注:本次分享demo的源码github地址:https://github.com/rondout/micro-frontend 什么是微前端 微前端的概念是由ThoughtWorks在2016年提出的,它借鉴了微服务的架构理念,核心在于将一个庞大的前端应用拆分成多…...

【Linux-进程间通信】vscode使用通信引入匿名管道引入
一、新系统,新软件 1.新系统 哈喽宝子们,从今以后我们不再使用风靡一时的CentOS系统了,因为CentOS已经不在维护了,各大公司几乎也都从CentOS转入其他操作系统了;我们现在由原来的CentOS系统切换到最新的Ubuntu系统&a…...

nerd bug:VPG多次计算vnetloss的计算图报错的解决
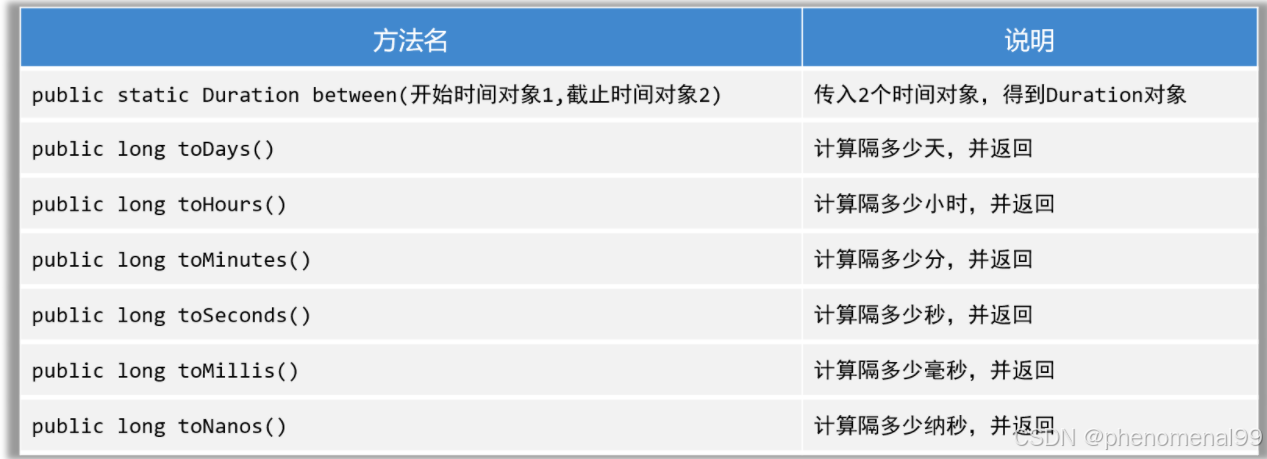
待更 Reference https://www.cnblogs.com/StarZhai/p/15495292.htmlhttps://github.com/huggingface/transformers/issues/12613https://discuss.pytorch.org/t/inplace-operation-errors-when-implementing-a2c-algorithm/145406/6...
BigDecimal类Date类JDK8日期
一、BigDecimal类是什么?它有什么用?先看一段代码,看这个代码有什么问题再说BigDeimal这个类是干什么用的,这样会好理解一些。 public class Test {public static void main(String[] args) {System.out.println(0.1 0.2);Syste…...

MybatisWebApp
如何构建一个有关Mybatis的Web? 在这里给出我自己的一些配置。我的TomCat版本:10.1.28 ,IDEA版本:2024.1.4 Pom.XML文件 <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/200…...

第十五章 RabbitMQ延迟消息之延迟插件
目录 一、引言 二、延迟插件安装 2.1. 下载插件 2.2. 安装插件 2.3. 确认插件是否生效 三、核心代码 四、运行效果 五、总结 一、引言 上一章我们讲到通过死信队列组合消息过期时间来实现延迟消息,但相对而言这并不是比较好的方式。它的代码实现相对来说比…...

OpenAI 公布了其新 o1 模型家族的元提示(meta-prompt)
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

Java基础14-网络编程
十四、网络编程 java.net.*包下提供了网络编程的解决方案! 基本的通信架构 基本的通信架构有2种形式: CS架构( Client客户端/Server服务端)、BS架构(Browser浏 览器/Server服务端)。无论是CS架构,还是BS架构的软件都必须依赖网络编程!。 1、网络通信的三要素 网络通…...

sed命令详解
sed命令详解 sed(stream editor,流编辑器)是 Linux 和 Unix 系统中功能强大的文本处理工具,它能够对输入流(如文件、管道输入等)进行逐行处理,从而实现多种多样的文本编辑操作。 基本语法 se…...

Linux高阶——1013—正则表达式练习
1、正则表达式匹配机制 问号放在或者*后面,表示切换成非贪婪模式 [^>]表示非右尖括号的都能匹配,直到找到href"为止 [^"]表示向右匹配,到"为止 因此,三个都能匹配 2、 正则函数 寻找结果 源文件 正则函数运…...

【CMake】为可执行程序或静态库添加 Qt 资源文件,静态库不生效问题
【CMake】添加静态库中的 Qt 资源 文章目录 可执行程序1. 创建资源文件(.qrc)2. 修改 CMakeLists.txt3. 使用资源文件 静态库1. 修改 CMakeLists.txt2. 使用资源2.1 初始化资源文件2.2 可执行程序中调用 这里介绍的不是使用 Qt 创建工程时默认的 CMakeLi…...

服务器、jvm、数据库的CPU飙高怎么处理
服务器 CPU 飙高处理 排查步骤: 监控工具:使用操作系统自带的监控工具,比如 top、htop、sar、vmstat 等,查看哪些进程占用了大量的 CPU 资源。进程排查:通过 top 等工具找到消耗 CPU 最高的进程,确定是哪…...

自适应过滤法—初级
#课本P144例题 """ Python 简单的自适应过滤移动平均预测方法 """ import numpy as np import matplotlib.pyplot as plt#用于迭代的函数 def self_adaptive( seq, N, k, maxsteps ):## 初始化序列seq_ada = np.zeros( len(seq) ) # 设置预测…...

UML图有用吗?真正厉害的软件开发,有用的吗?什么角色用?
UML(Unified Modeling Language,统一建模语言)图在软件开发中是有用的,但其使用取决于项目的规模、复杂度以及开发团队的实践习惯。真正厉害的开发者并非一定要依赖UML图,但在某些情况下,UML图确实能够提升…...

基于Java+Springboot+Vue开发的酒店客房预订管理系统
项目简介 该项目是基于JavaSpringbootVue开发的酒店客房预订管理系统(前后端分离),这是一项为大学生课程设计作业而开发的项目。该系统旨在帮助大学生学习并掌握Java编程技能,同时锻炼他们的项目设计与开发能力。通过学习基于Java…...

OpenCV高级图形用户界面(5)获取指定滑动条(trackbar)的当前位置函数getTrackbarPos()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 返回滑动条的位置。 该函数返回指定滑动条的当前位置。 cv::getTrackbarPos() 函数用于获取指定滑动条(trackbar)的当前…...

Jetson Orin Nano 升级jetpack5.1.2刷机过程记录
一.刷机起因 orin nano 接了个IMX477的摄像头,用 命令行DISPLAY:0.0 nvgstcapture-1.0 显示的画面有撕裂,让卖家查问题,卖家测试没有撕裂,对比环境,orin nano出厂默认的是jetpack5.1.1,卖家用的jetpack5.1.2版本,为了解决差异,要升级jetpack版本,前后搞了2天半,记录一下. 另外…...

Python 3.7 + XGBoost 多分类实战:从数据清洗到SHAP模型解释的保姆级教程
Python 3.7 XGBoost 多分类实战:从数据清洗到SHAP模型解释的保姆级教程在机器学习领域,XGBoost因其出色的性能和可解释性成为众多数据科学家的首选工具。本文将带您完整走过多分类任务的全流程,从原始数据到可解释的预测模型,每个…...

Java数组工具类实战:设计不可实例化的静态工具类
实现一个工具类 MathUtils,满足以下要求: 1. 所有方法均为静态,且该类不能从外部实例化(提示:使用私有构造器)。 2. 提供三个静态方法:- maxArray(int[] arr):返回较大值;…...

终极Node.js Mock工具:Mockery入门到精通实战教程
终极Node.js Mock工具:Mockery入门到精通实战教程 【免费下载链接】mockery Simplifying the use of mocks with Node.js 项目地址: https://gitcode.com/gh_mirrors/mock/mockery Mockery是Node.js生态中简化Mock使用的终极工具,它为开发者提供了…...

Unity塔防底层架构:ScriptableObject驱动的数据契约设计
1. 这不是“又一个塔防模板”,而是塔防开发的底层操作系统我第一次在Asset Store点开Tower Defense Toolkit 4(TDTK-4)的预览图时,下意识划走了——界面太“干净”了,没有炫酷的粒子特效演示,没有满屏飞舞的…...
)
保姆级教程:手把手教你为ESXi 6.7配置主板BIOS(VT-x/VT-d/AES全开)
从零开始:ESXi 6.7主板BIOS设置完全指南当你第一次接触企业级虚拟化平台时,那种既兴奋又忐忑的心情我完全理解。作为过来人,我清楚地记得自己第一次为ESXi配置BIOS时的迷茫——那些专业术语像天书一样,生怕设置错误导致服务器无法…...

Fiddler手机断网真相:TLS握手与证书固定的协议级拦截
1. 为什么Fiddler一开,手机就断网?这不是配置问题,是协议层的“信任危机”Fiddler抓包手机流量,本该是移动开发、测试、安全分析中最基础的操作之一。但几乎每个刚上手的人,都会在第二天早上发现:手机Wi-Fi…...

CANoe测试效率翻倍:手把手教你用XML Test Module搭建可复用的测试套件
CANoe测试效率翻倍:手把手教你用XML Test Module搭建可复用的测试套件在车载电子系统开发中,测试环节往往占据整个项目周期的40%以上时间。面对频繁的ECU软件迭代和多样化配置需求,传统逐个脚本执行测试的方式已经无法满足敏捷开发的要求。本…...

终极指南:使用MuSiC单细胞反卷积工具解密组织细胞组成
终极指南:使用MuSiC单细胞反卷积工具解密组织细胞组成 【免费下载链接】MuSiC Multi-subject Single Cell Deconvolution 项目地址: https://gitcode.com/gh_mirrors/music2/MuSiC 还在为复杂的组织样本分析而困惑吗?想要从批量RNA测序数据中精确…...
Windows任务栏透明美化终极指南:TranslucentTB从安装到精通
Windows任务栏透明美化终极指南:TranslucentTB从安装到精通 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB TranslucentTB是一…...