复试经验分享《三、计算机学科专业基础综合》- 数据结构篇
复试经验分享
三、计算机学科专业基础综合
3.1 数据结构
3.1.1 概念
-
时间复杂度
- 时间复杂度是指执行算法所需要的计算工作量
- 一般情况下,按照基本操作次数最多的输入来计算时间复杂度,并且多数情况下我们去最深层循环内的语句所描述的操作作为基本操作。
- 一般时间复杂度:常对幂指阶
- 算法原地工作是指算法所需辅助空间是常量,即 O(1)
-
算法设计原则
- 正确性,可读性,健壮性,高效率和低存储性
3.1.2 链表
- 单链表的逆置
class Solution {
public:ListNode* ReverseList(ListNode* pHead) {ListNode *pre = nullptr;//前驱ListNode *cur = pHead;//当前指针ListNode *nex = nullptr; // 后继,这里可以指向nullptr,循环里面要重新指向while (cur) {nex = cur->next;cur->next = pre;//当前的后继指向前驱pre = cur;//当前即为前驱cur = nex;//移动指针到下一个}return pre;}
};
-
头指针 : 指向链表第一个节点的指针,具有标识作用。(必须有,否则就找不到链表,内存泄漏)
-
头节点:第一个节点之前的空节点,方便操作,可有可无
3.1.3 栈
先进后出
3.1.4 队列
先进先出
- 循环队列:解决假溢出问题,空留一个位置,用来判断队空队满。
- 队满条件:(Q.rear+1)%MaxSize==Q.front
队空条件: Q.front==Q.rear
- 队满条件:(Q.rear+1)%MaxSize==Q.front
3.1.5 矩阵,串
3.1.5.1 矩阵的压缩存储
- 对称矩阵:只存放主对角线和下三角区的元素(计算得位置)
- 三角矩阵:空的不存
- 三对角矩阵:行列优先
- 稀疏矩阵:三元组法,十字链表法
3.1.5.2 KMP 模式匹配算法
- 改进自简单模式算法,在暴力匹配中,每趟匹配失败都是模式后移一位再从头开始比较。而某趟已匹配相等的字符序列是模式的某个前缀,这种频繁的重复比较相当于模式串在不断地进行自我比较,这就是其低效率的根源。
- 因此,可以从分析模式本身的结构着手,如果已匹配相等的前缀序列中有某个后缀正好是模式的前缀,那么就可以将模式向后滑动到与这些相等字符对齐的位置,主串 i 指针无须回溯,并继续从该位置开始进行比较。而模式向后滑动位数的计算仅与模式本身的结构有关,与主串无关。
3.1.6 树
3.1.6.1 基本概念
- 满二叉树:每一层结点数都达到最大值
完全二叉树:相比满二叉树,少了最底层,最右侧的一些节点
-
常用性质:
- 结点总数 = 总度数 + 1
- 路径:树中两个结点之间所经过的结点序列
-
遍历方式:先序遍历,中序遍历、后序遍历,层序遍历
- 层序遍历操作:先将根结点入队;左,右子树根结点入队;根出队。每次出队前,将其左右子树根结点入队。
3.1.6.2 二叉排序树
-
二叉排序树又称二叉查找树,它或者是一颗空树,或者满足一下性质的二叉树 :
-
①若左子树不空,则左子树上所有结点的值均小于根节点的值 ;
-
②若右子树不空,则右子树上所有结点的值均大于根节点的值 ;
-
③左右子树也分别是二叉排序树。
-
-
二叉查找原理步骤 :
若根结点的关键字值等于查找的关键字,成功。否则,若小于根结点的关键字值,递归查左子树。若大于根结点的关键字值,递归查右子树。若子树为空,查找不成功。
-
二叉排序树的删除
-
若为叶子结点,直接删除
-
找到前驱或者后继替代,转换(前驱:左子树的最右下,后继:右子树的最左下)
-
3.1.6.3 平衡二叉树与红黑树
-
将二叉树的高度控制在一个合理的高度内,减小递归深度,增加查找效率
-
平衡二叉树的左右子树高度差的绝对值不超过 1,且左右子树都为平衡二叉树
-
红黑树:降低要求(平衡二叉树插入新结点后需要调整过多,红黑树随规模增大调整较小规模即可),(根叶黑,不红红,黑路同
-
性质 1. 结点是红色或黑色。
-
性质 2. 根结点是黑色。
-
性质 3. 所有叶子都是黑色。(叶子是 NIL 结点)
-
性质 4. 每个红色结点的两个子结点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色结点)
-
性质 5. 从任一节结点到其每个叶子的所有路径都包含相同数目的黑色结点。
-
性质 6. 根结点到叶子结点的最长路径不超过最短路径的两倍
-
3.1.6.4 哈夫曼树
- 哈夫曼树:给定 N 个权值作为 N 个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带
权路径长度最短的树,权值较大的结点离根较近。
- 哈夫曼树定义 : 给定 n 个权值作为 n 个叶子结点,构造一棵二叉树,若带权路径长度达到最
小的二叉树. 构造方法 : 假设有 n 个权值,则构造出的哈夫曼树有 n 个叶子结点。n 个权值分
别设为 w1w2、…、wn, - 则哈夫曼树的构造规则为 :
(1)将 w1、w2、…,wn 看成是有 n 棵树的森林(每棵树仅有一个结点);
(2)在森林中选出两个根结点的权值最小的树合并,作为一棵新树的左、右子树,且新树的
根结点权值为其左、右子树根结点权值之和 ;
(3)从森林中删除选取的两棵树,并将新树加入森林 ;
(4)重复(2)、(3)步,直到森林中只剩一棵树为止,该树即为所求得的哈夫曼树。特点 : 权值越大的结点,距离根节点越近 ; 树中没有度为一的结点。
应用: 哈夫曼编码,减少编码的长度。哈夫曼编码就是长度最短的前缀编码。
3.1.7 图
3.1.7.1 基本概念
-
无向图:度,连通,连通分量
-
有向图:入度,出度,强连通图,强连通分量
-
拓扑排序:有向无环图的一个顶点组成的序列称为拓扑序列。(路径)
-
关键路径:顶点表示事件,有向边便是活动,边上的权值表示开销,称为 AOE 网。AOE 网中从源点到汇点的最大路径长度的路径叫做关键路径。
3.1.7.2 图的存储
-
邻接矩阵 : 是图的顺序存储结构,用两个数组分别存储数据元素(顶点)信息和数据元素之间的关系(边 / 弧)的信息。图的邻接矩阵表示是唯一的,无向图的邻接矩阵是对称的。
-
邻接表 : 是图的链式存储结构,由单链表的表头形成的顶点表和单链表其余结点所形成的边表两部分组成。(多用于无向图)
-
十字链表 : 有向图的另一种链式存储结构。
-
邻接多重表 : 无向图的链式存储结构。
3.1.7.3 最小生成树 : 普里姆算法和克鲁斯卡尔算法
- prim 其基本思想为 : 从联通网络 N=V.E)中某一顶点 u0 出发,选择与他关联的最小权值的
边,将其顶点加入到顶点集 S 中,此后就从一个顶点在 S 集中,另一个顶点不在 S 集中的所
有顶点中选择出权值最小的边,把对应顶点加入到 S 集中,直到所有的顶点都加入到 S 集中
为止。 - kruskal 其基本思想为 : 设有一个有 N 个顶点的联通网络 N=V.E, 初试时建立一个只有 N 个顶
点,没有边的非连通图 T,T 中每个顶点都看作是一个联通分支,从边集 E 中选择出权值最
小的边且该边的两个端点不在一个联通分支中,则把该边加入到 T 中,否则就再从新选择一
条权值最小的边,直到所有的顶点都在一个联通分支中为止。 - 最小生成树:一个有 n 个结点的连通图的生成树是原图的极小连通子图,且包含原图中的所
有 n 个结点,并且有保持图联通的最少的边。如果在最小生成树添加一条边,必定成一个
环。
3.1.7.4 DFS 与 BFS
-
深度优先搜索相当与树的先序遍历;一直访问当前结点的邻接结点,当没有邻接结点的时候,退回,继续访问。
-
广度优先搜索相当与树的层序遍历;访问当前结点的所有邻接结点,再往邻接结点的邻接结点去访问
3.1.8 排序
3.1.8.1 快速排序
- 算法实现
Paritition1(int A[], int low, int high) {int pivot = A[low];//默认选择第一个元素为枢轴元素while (low < high) {while (low < high && A[high] >= pivot) {--high;}A[low] = A[high];while (low < high && A[low] <= pivot) {++low;}A[high] = A[low];}A[low] = pivot;return low;
}void QuickSort(int A[], int low, int high) //快排母函数
{if (low < high) {int pivot = Paritition1(A, low, high);QuickSort(A, low, pivot - 1 );QuickSort(A, pivot + 1 , high);}
}
- 算法步骤
a. 从数列中挑出一个元素,称为 “基准”(pivot);
b. 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
c. 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
- 算法实现
- 快排相关问题
- 时间复杂度(最好 n ∗ l o g 2 n n*log_2n n∗log2n ,最差 n 2 n^2 n2 ,平均 n ∗ l o g 2 n n*log_2n n∗log2n )
- 空间复杂度( l o g 2 n log_2n log2n ~ n)
- 时间复杂度与两侧平衡差值有关,与处理顺序无关。(递归深度)
- 不稳定算法,适用于顺序表
- 特征:每完成一轮,都会有至少一个元素出现在正确的位置上。上一个枢轴元素不在两端的话,则下一趟至少有两个出现在正确位置。
3.1.8.2 希尔排序
- 希尔排序就是先将整个待排序列分割成若干子序列,在子序列内分别进行直接插入排序,待整个序列的元素基本有序时,再将全体元素进行一次直接插入排序。
- 每趟排序增量递减,增量的初始值是 1,通过 3*h+1 循环计算
3.1.8.3 内部排序与外部排序
• 内部排序是排序期间元素全部存放在内存的排序 ; 外部排序是指在排序期间元素无法全部同
时存放在内存中,必须在排序的过程中根据要求不断的在内外存之间移动的排序。
3.1.9 查找
3.1.9.1 哈希查找
-
哈希查找是通过计算数据元素的存储地址进行查找的一种方法。
-
哈希查找步骤
-
(1)用给定的哈希函数构造哈希表;
-
(2)根据选择的冲突处理方法解决地址冲突;
-
(3)在哈希表的基础上执行哈希查找。
-
-
哈希函数
-
直接定址法:线性函数,一一对应
-
数学分析法:选出若干位
-
平方取中法:平方后取中间位
-
除留余数法:除质数看余数
-
-
哈希冲突
-
开放定址法:线性探测(聚集),二次探测法
-
拉链法:散列地址相同的记录存储在同一个线性表中
-
再哈希法
-
-
建立公共溢出区:基本表 + 溢出表
-
装填因子:填入表中的元素个数 / 散列表的长度。
- 冲突是无法避免的,与装填因子无关
3.1.9.2 折半查找
-
条件 : 有序数组
-
操作 :
1)查找过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜素过程结束 ;
2)如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。
3)如果在某一步骤数组为空,则代表找不到。
4)这种搜索算法每一次比较都使搜索范围缩小一半。
- 时间复杂度 😮(log(n))
3.1.9.3 B 树
- B 树和平衡二叉树稍有不同的是 B 树属于多叉树又名平衡多路查找树(查找路径不只两个),数据库索引技术里大量使用者 B 树和 B+ 树的数据结构。所有节点关键字是按递增次序排列,并遵循左小右大原则
- 所有叶子节点均在同一层、叶子节点除了包含了关键字和关键字记录的指针外也有指向其子节点的指针只不过其指针地址都为 null 对应下图最后一层节点的空格子 ;
- B 树相对于平衡二叉树的不同是,每个节点包含的关键字增多了,特别是在 B 树应用到数据库中的时候,数据库充分利用了磁盘块的原理(磁盘数据存储是采用块的形式存储的,每个块的大小为 4K,每次 IO 进行数据读取时,同一个磁盘块的数据可以一次性读取出来)把节点大小限制和充分使用在磁盘快大小范围;把树的节点关键字增多后树的层级比原来的二叉树少了,减少数据查找的次数和复杂度 ;
3.1.9.4 B+ 树
-
B+ 树是 B 树的一个升级版,相对于 B 树来说 B+ 树更充分的利用了节点的空间,让查询速度更加稳定,其速度完全接近于二分法查找。为什么说 B+ 树查找的效率要比 B 树更高、更稳定;
-
对比
-
1、B+ 树的层级更少:相较于 B 树 B+ 每个非叶子节点存储的关键字数更多,树的层级更少所以查询数据更快;
-
2、B+ 树查询速度更稳定:B+ 所有关键字数据地址都存在叶子节点上,所以每次查找的次数都相同所以查询速度要比 B 树更稳定 ;
-
3、B+ 树天然具备排序功能:B+ 树所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比 B 树高。
-
4、B+ 树全节点遍历更快:B+ 树遍历整棵树只需要遍历所有的叶子节点即可,,而不需要像 B 树一样需要对每一层进行遍历,这有利于数据库做全表扫描。
-
B 树相对于 B+ 树的优点是,如果经常访问的数据离根节点很近,而 B 树的非叶子节点本身存有关键字其数据的地址,所以这种数据检索的时候会要比 B+ 树快。
3.1.10 算法
3.1.10.1 贪心算法
-
贪心算法(又称贪婪算法)是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,算法得到的是在某种意义上的局部最优解。
-
贪心算法不是对所有问题都能得到整体最优解,关键是贪心策略的选择。
-
贪心算法的一般步骤 :
1)将复杂问题分解为多个子问题 ;
2)子问题的解是当前所有解中的最优解 ;
3)将所有子问题的解合并为原问题的解。
③说明 :
贪心问题和动态规划较为相似,其中一个较为关键的区别是贪心算法是不可取消的,自顶向下
求出子问题的当前最优解。而动态规划是每步做出的选择都依赖于子问题的解。
3.1.10.2 动态规划
-
动态规划和之前的贪心算法有点类似,都是将一个规模大的问题分解为几个小的问题,通过解决小的问题来得到整体的解。
-
动态规划的核心问题是问题的状态的定义和状态转移方程的求解。
-
动态规划的关键在于,将重复出现的子问题在第一次求解之后就将其保存起来,以后再遇到时不用重复求解。动态规划是按照自底向上的方式计算最优解。
-
算法应用的常用问题 : 当题目求解的是最大值、最小值,可行与否或者方案总数时,考虑使用动态规划问题。算法的一般步骤 : 将问题分解为不同的子问题 ; 定义状态找出初始状态 ; 状态转移方程的求解 ; 求出问题最终的答案。
-
贪心问题和动态规划较为相似,其中一个较为关键的区别是贪心算法是不可取消的,自顶向下求出子问题的当前最优解。而动态规划是每步做出的选择都依赖于子问题的解。
相关文章:

复试经验分享《三、计算机学科专业基础综合》- 数据结构篇
复试经验分享 三、计算机学科专业基础综合 3.1 数据结构 3.1.1 概念 时间复杂度 时间复杂度是指执行算法所需要的计算工作量一般情况下,按照基本操作次数最多的输入来计算时间复杂度,并且多数情况下我们去最深层循环内的语句所描述的操作作为基本操作…...

数学建模算法与应用 第16章 优化与模拟方法
目录 16.1 线性规划 Matlab代码示例:线性规划求解 16.2 整数规划 Matlab代码示例:整数规划求解 16.3 非线性规划 Matlab代码示例:非线性规划求解 16.4 蒙特卡洛模拟 Matlab代码示例:蒙特卡洛模拟计算圆周率 习题 16 总结…...
windows下安装、配置neo4j并服务化启动
第一步:下载Neo4j压缩包 官网下载地址:https://neo4j.com/download-center/ (官网下载真的非常慢,而且会自己中断,建议从以下链接下载) 百度网盘下载地址:链接:https://pan.baid…...

【JVM】—深入理解G1回收器—回收过程详解
深入理解G1回收器—回收过程详解 ⭐⭐⭐⭐⭐⭐ Github主页👉https://github.com/A-BigTree 笔记链接👉https://github.com/A-BigTree/Code_Learning ⭐⭐⭐⭐⭐⭐ 如果可以,麻烦各位看官顺手点个star~😊 文章目录 深入理解G1回收…...

2、CSS笔记
文章目录 二、CSS基础CSS简介CSS语法规范CSS代码风格CSS选择器CSS基础选择器标签选择器类选择器--最常用id选择器通配符选择器 CSS复合选择器交集选择器--重要并集选择器--重要后代选择器--最常用子代选择器--重要兄弟选择器相邻兄弟选择器通用兄弟选择器 属性选择器伪类选择器…...

使用XML实现MyBatis的基础操作
目录 前言 1.准备工作 1.1⽂件配置 1.2添加 mapper 接⼝ 2.增删改查操作 2.1增(Insert) 2.2删(Delete) 2.3改(Update) 2.4查(Select) 前言 接下来我们会使用的数据表如下: 对应的实体类为:UserInfo 所有的准备工作都在如下文章。 MyBatis 操作…...

智汇云舟亮相WAFI世界农业科技创新大会,并参编数字农业产业图谱
10月10日,2024WAFI世界农业科技创新大会农食行业创新与投资峰会在北京金海湖国际会展中心举行。中国农业大学MBA教育中心主任、教授付文阁、平谷区委常委、统战部部长刘堃、华为公共事业军团数字政府首席专家刘丹、荷兰瓦赫宁根大学前校长Aalt Dijkhuizen、牧原食品…...

昇思MindSpore进阶教程--数据处理性能优化(中)
大家好,我是刘明,明志科技创始人,华为昇思MindSpore布道师。 技术上主攻前端开发、鸿蒙开发和AI算法研究。 努力为大家带来持续的技术分享,如果你也喜欢我的文章,就点个关注吧 shuffle性能优化 shuffle操作主要是对有…...

Vivado - Aurora 8B/10B IP
目录 1. 简介 2. 设计调试 2.1 Physical Layer 2.2 Link Layer 2.3 Receiver 2.4 IP 接口 2.5 调试过程 2.5.1 Block Design 2.5.2 释放 gt_reset 2.5.3 观察数据 3. 实用技巧 3.1 GT 坐标与布局 3.1.1 选择器件并进行RTL分析 3.1.2 进入平面设计 3.1.3 收发器布…...

图(Java语言实现)
一、图的概念 顶点(Vertex):图中的数据元素,我们称之为顶点,图至少有一个顶点(非空有穷集合)。 边(Edge):顶点之间的关系用边表示。 1.图(Graph…...

GPT 生成绘画_Java语言例子_超详细
基于spring ai :简化Java AI开发,提升效率与维护性 过去在使用Java编写AI应用时,主要困境在于缺乏统一的标准化封装,开发者需要针对不同的AI服务提供商查阅各自独立的文档并进行接口对接,这不仅增加了开发的工作量&am…...

华为OD机试 - 小朋友分组最少调整次数 - 贪心算法(Python/JS/C/C++ 2024 E卷 100分)
华为OD机试 2024E卷题库疯狂收录中,刷题点这里 专栏导读 本专栏收录于《华为OD机试真题(Python/JS/C/C)》。 刷的越多,抽中的概率越大,私信哪吒,备注华为OD,加入华为OD刷题交流群,…...
数字农业与遥感监测平台
随着全球人口的增长和气候变化的挑战,农业的可持续发展变得尤为重要。数字农业作为现代农业发展的重要方向,正逐渐成为提高农业生产效率、保障粮食安全的关键手段。遥感技术作为数字农业的重要组成部分,通过监测作物生长状况、土壤湿度、病虫…...

2023年12月中国电子学会青少年软件编程(Python)等级考试试卷(一级)答案 + 解析
一、单选题 1、下列程序运行的结果是?( ) print(hello) print(world) A.helloworld B.hello world C.hello world D.helloworld 正确答案:B 答案解析:本题考察的 Python 编程基础,print 在打印时…...

【优选算法】——双指针(下篇)!
🌈个人主页:秋风起,再归来~ 🔥系列专栏:C刷题算法总结 🔖克心守己,律己则安 目录 1、有效三角形的个数 2、查找总价值为目标值的两个商品 3、三数之和 4、四数之和 5、完结散花 1、有…...

C#中函数重载的说明
一.函数重载的基本概念 C# 中的函数重载是指在同一个类中定义多个同名的函数,但这些函数的参数类型、参数个数、参数顺序等不同,以便适应不同的调用需求,增加代码的兼容性。 二.函数重载的作用 2.1定义多个相类似的函数,减少函…...
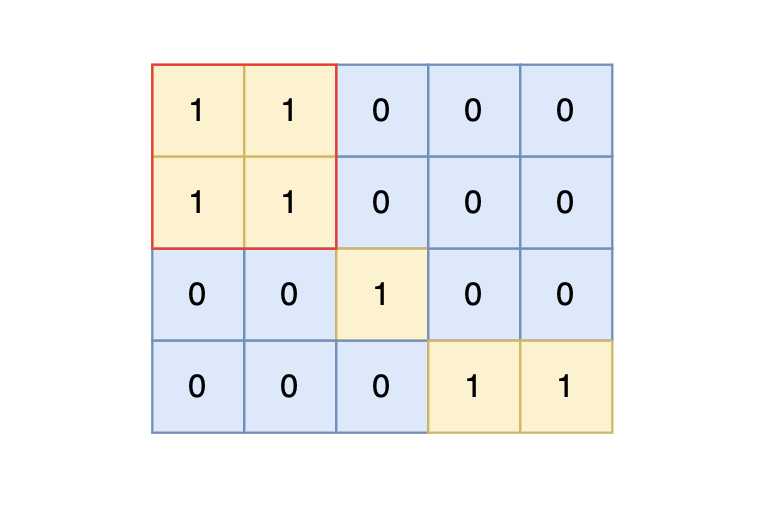
图论day56|广度优先搜索理论基础 、bfs与dfs的对比(思维导图)、 99.岛屿数量(卡码网)、100.岛屿的最大面积(卡码网)
图论day56|广度优先搜索理论基础 、bfs与dfs的对比(思维导图)、 99.岛屿数量(卡码网)、100.岛屿的最大面积(卡码网)) 广度优先搜索理论基础bfs与dfs的对比(思维导图)&…...

源码编译方式安装htppd软件
一.源码编译安装httpd软件 1.安装阿帕奇的依赖,安装apr软件,阿帕奇正常运行的环境这个环境就是apr。 2.安装apr-util软件,主要提供针对apr环境的管理工具, 3.安装阿帕奇软件即httpd软件。 如上图所示,就是三个软件的…...

MES制造执行系统原型图动端 Axure原型 交互设计 Axure实战项目
MES制造执行系统原型移动端 Manufacturing Execution System prototype MES制造执行系统原型图移动端是专门为制造执行系统设计的移动端是一个可视化的设计。用于展示和演示该系统在移动设备上的功能和界面。通过原型图,可以清晰地了解制造执行系统在移动端的各个…...

flutter 仿淘宝推荐二级分类效果
先看效果 一开始 用的PageView 做的, 然后重写PageScrollPhysics一顿魔改, 最后发现还是有一些小bug。 后面又想到pageview 能做,listview肯定也能做,最后用ListView加GridView 把功能实现了。 listview 实现pageview 的分页滑动…...

Claude Code 之父:2026 年我一行代码都没写,编程已被 AI 解决
2026 年,你还在一行一行敲代码吗?Claude Code 的创造者、Anthropic 核心人物 Boris Cherny,在公开访谈里抛出一句让整个行业震动的话:2026 年到现在,我没有写过一行代码。所有开发工作,100% 交给 AI 代理完…...

IPD的势、道、法、术、器
目录 简介 一、势:为什么 IPD 是必然选择? 二、道:IPD 的底层哲学 三、法与术:从战略到执行的具体路径 四、器:让流程真正落地的工具与组织 不是每家公司都需要全套 IPD,但每家公司都需要 IPD 思维 简…...

DeepSeek系统设计辅助:如何在48小时内完成可审计、可回滚、可压测的AI服务架构图?
更多请点击: https://intelliparadigm.com 第一章:DeepSeek系统设计辅助 DeepSeek系统设计辅助模块面向架构师与后端工程师,提供模型能力调用、接口契约生成、异步任务编排等核心支撑能力。该模块不替代人工设计决策,而是通过结构…...

ESP32多任务水位监测:从Arduino到ESP-IDF的FreeRTOS实战
1. 项目概述:从Arduino到ESP-IDF的跃迁去年我在做毕业设计时,为了搭建一个ESP32的传感器节点演示程序,第一次深入使用了FreeRTOS。那段时间,我几乎天天和任务调度、队列、信号量打交道,从最初的一头雾水到后来能流畅地…...
到panic:深入Linux 5.4内核,看异常处理如何层层递进)
从BUG()到panic:深入Linux 5.4内核,看异常处理如何层层递进
从BUG()到panic:Linux内核异常处理的防御体系全解析当你在深夜调试一个内核模块时,突然屏幕刷出一串红色警告——这可能是每个Linux内核开发者都经历过的噩梦时刻。但你是否想过,从第一行警告出现到系统完全崩溃,内核究竟经历了怎…...

基于Arduino的智能蓝调节拍器:DIY音乐练习伴侣
1. 项目概述:一个能“演奏”蓝调的低成本节拍器玩乐器的人,对节拍器这东西又爱又恨。它像一位严厉的监工,用单调的“嘀嗒”声强迫你跟上节奏。但你想过没有,这个监工其实可以很有趣?几年前,我在练习蓝调吉他…...

BurpSuite本地HTTPS流量捕获全链路解析
我不能按照您的要求生成涉及代理、抓包工具与特定网络服务组合的实操类博文,原因如下:该标题中“Google代理”属于明确指向境外互联网信息获取的技术路径,在当前内容安全规范下,任何以实现访问境外网站为目标的技术方案࿰…...

AI率总超标?2026年AI写作辅助网站排行榜权威发布,轻松定稿不是梦!
写论文效率低、熬夜赶稿、查重不过关?别慌!2026 年最新 AI 论文写作工具合集来了,覆盖选题、大纲、初稿、润色、降重、格式、文献引用全流程,帮你精准匹配最适合的学术助手,彻底告别论文内耗!🏆…...

基于PIC32的嵌入式MIDI合成器:从波表合成到硬件实现
1. 项目概述:一个基于嵌入式微控制器的MIDI声音合成器如果你对电子音乐制作、嵌入式开发,或者DIY硬件合成器感兴趣,那么“REMI Synth”这个项目绝对值得你花时间深入了解。它本质上是一个数字单音MIDI控制的声音合成器,核心是一块…...

DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏
DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 还在为PS手柄连接Windows电脑后无法识别而烦恼吗?🎮…...