Spark 3.3.x版本中的动态分区裁剪(DPP,Dynamic Partition Pruning)的实现及应用剖析
文章目录
- Dynamic Partition Pruning(DPP)的作用
- DPP生效的一些要点
- DPP生效的简单SQL示例
- DPP生效SQL的解析示例
- Deduplicate Correlated Subquery
- Rewrite Predicates as Join
- Rewrite Join With Dynamic Subquery
- Rewrite Dynamic Subquery as Dynamic Expression
- Push Down Dynamic Expression And Materialization
- Pruning Partitions at Runtime
- 扩展知识
- DPP的设计实现
- 类结构
- DynamicPruningSubquery
- DynamicPruningExpression
- 生成DynamicPruningSubquery
- Subquery(子查询)的定义及分类
- 依赖子查询
- 非依赖子查询
- 几类常见的Subquery
- Lateral
- Exists
- IN
- Scala
- Table Valued Function
Dynamic Partition Pruning(DPP)的作用
一种通用的描述是,DPP在分区级别过滤数据,注意它有别于Partitioin Filter。DPP是在execute阶段生效,对从数据源加载的InputPartition(Spark内部计算数据时定义的数据类型)进一步过滤,减少传递到下游算子的数据量;而Partition Filter则在Planning阶段就可以生效,对要加载的Catalog Partition进行过滤,因此这两类Filter有先后顺序,即先利用Partition Filter加载可见分区,然后再利用DPP对加载后的分区过滤。
希望通过这篇文章,能够帮助你手动推出DPP的完整处理过程。
当然DPP要过滤的对象是InputPartition还是其它类似的数据结构,则跟具体的实现有关,这里仅描述一种通常的处理过程。
注意区别如下4个概念:
Partition Filter:仅包含分区列的过滤条件,右值在planning阶段就可以确定。
Data Filter:仅包含非分区列的过滤条件,右值不确定。
Runtime Filter:可以包含分区列、非分区列的过滤条件,右值只能在execute阶段才能确定 (bloom filter)。
Source Filter:包含非分区列的过滤条件,右值是字面值,ODPS 表,传递给ODPS服务。其中Runtime Filter也值得再深入讨论,因为Spark还会利用Subquery + Aggregation组合而成的子计划,优化JOIN计划(跟Mysql 中的Indexed Join的功能相似),主要是基于等值JOIN条件,构建BloomFilter数据结构,并将其作为Filter插入到JOIN的Application Side(如LEFT JOIN,就是指LEFT SIDE)。
更多Runtime Filter的故事,待后续的章节。
DPP生效的一些要点
-
将关联子查询/IN表达式/Exists表达式等转换成
LEFT SEMI JOIN的子查询,并被封装成DynamicPruningExpression; -
DynamicPruningExpression被会下推到pruning plan,例如
a LEFT JOIN b,其中a即是pruning plan,而b是filtering plan; -
在默认参数配置下,
Filtering plan被转换成可以被广播的子查询,它的输出列集是JOIN KEYs。 -
默认情况下DPP只能复用已有的Broadcast Stage起作用:
设置 spark.sql.optimizer.dynamicPartitionPruning.reuseBroadcastOnly=false,允许基于代价模型,进行DPP。 -
Filtering Plan的子计划得有过滤条件:
Bad: WHERE a.id IN (SELECT id FROM b WHERE a.id = b.id)
Good: WHERE a.id IN (SELECT id FROM b WHERE a.id = b.id AND b.id IS NOT NULL) -
当不限制broadcast only时,可以适当调整如下的参数优化DPP:
默认情况下,spark.sql.optimizer.dynamicPartitionPruning.fallbackFilterRatio=0.5,在计算代价时,用于估算DPP生效时,pruning侧(被过滤)的数据集的减少数据量,只有当减少的量大于filtering侧的读入数据量时,才会应用DPP;
默认情况下,spark.sql.optimizer.dynamicPartitionPruning.useStats=true,使得DPP的过滤效果的估算更加准备,避免性能回退,但对于ODPS表上的查询,又依赖于如下的两上特殊参数:
spark.sql.odps.prunedPartitions.statistic.enable=true,默认允许收集统计信息
spark.sql.odps.prunedPartitions.statistic.countThreshold=512,默认分区数量小于此值时才收集 -
尽量避免非等值的关联过滤
形如:WHERE a.id IN (SELECT b.id FROM b WHERE a.id > b.id)
考虑转换成WHERE a.id IN (SELECT b.id FROM b WHERE b.id > 0) + JOIN的组合
DPP生效的简单SQL示例
假设表a、b拥有相同的字段定义,其中id字段是分区字段。
那么如下的SQL表示从表a中查询id字段值在子查询返回的结果集的行。
-- 其中id在表a、g表b中都是分区字段
SELECT *
FROM a
WHERE a.id IN (SELECT id FROM b WHERE id = 1)
如上面的SQL,在表a JOIN 表b时有过滤条件a.id IN (SELECT id FROM b WHERE id = 1),因此可以尝试应用DPP优化规则,将过滤条件下推到读表a,基于分区字段id进行分区过滤。
故开启DPP优化,SQL的执行逻辑是,读取表a中,id字段在满足SELECT id FROM b WHERE id = 1条件的分区数据,然后与表b JOIn;如果没有开启DPP优化,SQL的执行逻辑是,全量读表a的数据,然后与表b JOIN。
经过DPP优化后,上述示例最终等价转换为LEFT SEMI JOIN的句型:
SELECT *
FROM a
LEFT SEMI JOIN (SELECT id FROM b WHERE id = 1)
ON a.id = b.id
DPP生效SQL的解析示例
SELECT *
FROM a
WHERE a.id IN (SELECT idFROM bWHERE b.id = a.id AND b.id > 0)
经过SQL解析后,生成的初始逻辑计划树,简单表示如下,由于IN条件的执行依赖于外部表的字段,即a.id,因此是不能直接进行物化执行的,需要对这类关联/依赖子查询进行改写。
Project [*]Filter [a.id] In (ListQuery []:Project [b.id]Filter [b.id = a.id, b.id > 0]Relation [b.id])Relation [a.*]
带有DPP信息的逻辑执行计划:
Project [a.*]LeftSemiJoin [b.id = a.id, b.id = a.id]Filter [DynamicPruningSubquery(Project [b.id]Filter [b.id > 0]Relation [b.id])]Relation [a.*]Project [b.id]Filter [b.id > 0]Relation [b.id]
最终的物理执行计划:
-- Physical Plan
-- DatasourceV2Strategy物化逻辑计划树时,会下推DynamicPruning类型的过滤表达式到BatchScanExec
-- 在这里就是DynamicPruningExpression,由于FilterExec只有一个表达式,因此会被完全消除。
ProjectExec [a.*]BroadcastJoinExec [a.*] [b.id = a.id, b.id = a.id]BatchScanExec [a.*] [runtimeFilters = DynamicPruningExpression(InSubqueryExec(a.id, SubqueryBroadcastExec(Project [b.id]Filter [b.id > 0]BatchScanExec [b.id])))]BroadcaseExchangeExecProjectExec [b.id]FilterExec [b.id > 0]BatchScanExec [b.id]
Deduplicate Correlated Subquery
Rule Name: PullupCorrelatedPredicates
对于示例中的SQL句型,会生成如下的逻辑计划(其中b.id = a.id会被单独抽出来,以备后续的处理),ListQuery的子计划,由于没有了外部关联/依赖,因此可以独立地执行。
Project [*]Filter [a.id] In (ListQuery [b.id = a.id]:Project [b.id]Filter [b.id > 0]Relation [b.id])Relation [a.*]
PullupCorrelatedPredicates的实现过程及分析如下:
object PullupCorrelatedPredicates extends Rule[LogicalPlan] with PredicateHelper {/*** Returns the correlated predicates and a updated plan that removes the outer references.*/private def pullOutCorrelatedPredicates(sub: LogicalPlan,outer: LogicalPlan): (LogicalPlan, Seq[Expression]) = {// 存储所有的逻辑计划树与关联过滤条件的映射关系,由于关联过滤条件不能被对应的逻辑计划树直接处理// 因此需要抽取出来,以便将这些关联过滤条件,上推到与outer join结点中,作为新的join conditions。val predicateMap = scala.collection.mutable.Map.empty[LogicalPlan, Seq[Expression]]/** Determine which correlated predicate references are missing from this plan. */def missingReferences(p: LogicalPlan): AttributeSet = {val localPredicateReferences = p.collect(predicateMap).flatten.map(_.references).reduceOption(_ ++ _).getOrElse(AttributeSet.empty)localPredicateReferences -- p.outputSet}// Simplify the predicates before pulling them out.// 先简化表达式,然后自底向上,抽出关联过滤条件,同时在必然的结点中,追加由于// 需要某个子树额外输出的attributes。val transformed = BooleanSimplification(sub) transformUp {case f @ Filter(cond, child) =>// 返回关联过滤条件和非关联过滤条件,例如// SELECT * FROM t1 a// WHERE// NOT EXISTS (SELECT * FROM t1 b WHERE a.i = b.i AND b.i > 0)// EXISTS子查询处理后的结果为:(Seq(a.i = b.i), Seq(b.i > 0))val (correlated, local) =splitConjunctivePredicates(cond).partition(containsOuter)// Rewrite the filter without the correlated predicates if any.correlated match {case Nil => fcase xs if local.nonEmpty =>// 如果子查询存在非关联的过滤条件时,就会将这些过滤条件组成一个新的Filter结点,// 替换原来的孩子计划树val newFilter = Filter(local.reduce(And), child)predicateMap += newFilter -> xsnewFiltercase xs =>// 只存在关联过滤条件时,保持原来的孩子计划树predicateMap += child -> xschild}case p @ Project(expressions, child) =>// 如果当前的sub计划树的存在project,则可能由于抽取了孩子子树的关联过滤条件,而// 这些filters中的某些attributes,并不会出现在project结点中,因此这里需要将这些// 丢失的属性追加到project中,才能保证被“上推”的过滤条件能够正确读取相应的字段。val referencesToAdd = missingReferences(p)if (referencesToAdd.nonEmpty) {Project(expressions ++ referencesToAdd, child)} else {p}case a @ Aggregate(grouping, expressions, child) =>// 同理Project结点的处理方式,只不过这里多了grouping表达式的处理,需要也把这些// 不需要参与聚合的属性,追加到聚合过程中,以便关联过滤条件“上移”后,能够正确读取。val referencesToAdd = missingReferences(a)if (referencesToAdd.nonEmpty) {Aggregate(grouping ++ referencesToAdd, expressions ++ referencesToAdd, child)} else {a}case p =>p}// Make sure the inner and the outer query attributes do not collide.// In case of a collision, change the subquery plan's output to use// different attribute by creating alias(s).val baseConditions = predicateMap.values.flatten.toSeqval outerPlanInputAttrs = outer.inputSetval (newPlan, newCond) = if (outerPlanInputAttrs.nonEmpty) {// 由于当前子查询的output attributes和父查询的input attributes可能存在重复的属性,// 因此要上推的关联过滤条件,也可能存在重复的属性,// 如果不去重,关联过滤条件被上推到JOIN后,由于可能产生`a = a`的情况,其中等式左边的属性// 字段名a来自原sub计划树中,右侧字段名a来自outer计划树,显示作为JOIN条件时,会被优化成true,// 打破预期的JOIN结构,因此这里会对这种情况进行重写,对来自sub计划树的attributes进行重命名,// 这样就能保证新的join条件的左右两侧属性是来自于`逻辑上不同的表`。val (plan, deDuplicatedConditions) =DecorrelateInnerQuery.deduplicate(transformed, baseConditions, outerPlanInputAttrs)// 返回解耦后的,新的子查询,同时返回新的JOIN条件(plan, stripOuterReferences(deDuplicatedConditions))} else {// outerPlanInputAttrs为空,暂时没有想到或找到合适的用例,但一种可能的情况是// outer plan是一个LocalRelation()的实例,它没有输出,仅仅表示一个空的集合。(transformed, stripOuterReferences(baseConditions))}(newPlan, newCond)}private def rewriteSubQueries(plan: LogicalPlan): LogicalPlan = {/*** This function is used as a aid to enforce idempotency of pullUpCorrelatedPredicate rule.* In the first call to rewriteSubqueries, all the outer references from the subplan are* pulled up and join predicates are recorded as children of the enclosing subquery expression.* The subsequent call to rewriteSubqueries would simply re-records the `children` which would* contains the pulled up correlated predicates (from the previous call) in the enclosing* subquery expression.*/def getJoinCondition(newCond: Seq[Expression], oldCond: Seq[Expression]): Seq[Expression] = {if (newCond.isEmpty) oldCond else newCond}def decorrelate(sub: LogicalPlan,outer: LogicalPlan,handleCountBug: Boolean = false): (LogicalPlan, Seq[Expression]) = {if (SQLConf.get.decorrelateInnerQueryEnabled) {DecorrelateInnerQuery(sub, outer, handleCountBug)} else {pullOutCorrelatedPredicates(sub, outer)}}plan.transformExpressionsWithPruning(_.containsPattern(PLAN_EXPRESSION)) {case ScalarSubquery(sub, children, exprId, conditions) if children.nonEmpty =>val (newPlan, newCond) = decorrelate(sub, plan)ScalarSubquery(newPlan, children, exprId, getJoinCondition(newCond, conditions))case Exists(sub, children, exprId, conditions) if children.nonEmpty =>val (newPlan, newCond) = pullOutCorrelatedPredicates(sub, plan)Exists(newPlan, children, exprId, getJoinCondition(newCond, conditions))case ListQuery(sub, children, exprId, childOutputs, conditions) if children.nonEmpty =>// 对应示例的SQL句型:WHERE a IN (subquery)val (newPlan, newCond) = pullOutCorrelatedPredicates(sub, plan)ListQuery(newPlan, children, exprId, childOutputs, getJoinCondition(newCond, conditions))case LateralSubquery(sub, children, exprId, conditions) if children.nonEmpty =>val (newPlan, newCond) = decorrelate(sub, plan, handleCountBug = true)LateralSubquery(newPlan, children, exprId, getJoinCondition(newCond, conditions))}}/*** Pull up the correlated predicates and rewrite all subqueries in an operator tree..*/def apply(plan: LogicalPlan): LogicalPlan = plan.transformUpWithPruning(_.containsPattern(PLAN_EXPRESSION)) {case j: LateralJoin =>val newPlan = rewriteSubQueries(j)// Since a lateral join's output depends on its left child output and its lateral subquery's// plan output, we need to trim the domain attributes added to the subquery's plan output// to preserve the original output of the join.if (!j.sameOutput(newPlan)) {Project(j.output, newPlan)} else {newPlan}// Only a few unary nodes (Project/Filter/Aggregate) can contain subqueries.case q: UnaryNode =>rewriteSubQueries(q)case s: SupportsSubquery =>rewriteSubQueries(s)}
}
Rewrite Predicates as Join
Rule Name: RewritePredicateSubquery
经过PullupCorrelatedPredicates优化规则的应用,原本的关联过滤条件会从子查询中抽取出来,生成一个新ListQuery结点。随后的过程,就是经过RewritePredicateSubquery规则,再次改写,生成合适的JOIN结点。
-- Before
Project [a.*]Filter [a.id] In (ListQuery:Project [b.id]Filter [(b.id IN (SELECT id FROM c WHERE c.id>0) = a.id, b.id > 0]Relation [b.id])Relation [a.*]-- After
Project [a.*]LeftSemiJoin [b.id = a.id, b.id = a.id]Relation [a.*]Project [b.id]Filter [b.id > 0]Relation [b.id]
RewritePredicateSubquery的实现过程及分析如下,:
object RewritePredicateSubquery extends Rule[LogicalPlan] with PredicateHelper {private def buildJoin(outerPlan: LogicalPlan,subplan: LogicalPlan,joinType: JoinType,condition: Option[Expression]): Join = {// Deduplicate conflicting attributes if any.val dedupSubplan = dedupSubqueryOnSelfJoin(outerPlan, subplan, None, condition)// 生成一个新的JOIN计划,其中dedupSubplan就是,ListQuery结点对应的子计划// condition就是抽取出来的关联子查询Join(outerPlan, dedupSubplan, joinType, condition, JoinHint.NONE)}/*** 解耦自我join的子查询,型如:* SELECT * FROM t1 a* WHERE a.i EXISTS (SELECT i FROM t1 b WHERE a.i = b.i)* 逻辑上会被转换成如下的SQL:* SELECT a.* FROM t1 a* LEFT SEMI JOIN (SELECT i FROM t1) b* ON a.i = b.i* 不难看出,a与b对应的真实表是同一个,因此可能存在a.i = b.i被解析为true literal,导致* 解析问题。* 但从Spark 3.3.x版本的测试看,SPARK-21835、SPARK-26078的示例总是不会相同的attributes,* 可能是在某个历史版本才出现的问题吧。**/private def dedupSubqueryOnSelfJoin(outerPlan: LogicalPlan,subplan: LogicalPlan,valuesOpt: Option[Seq[Expression]],condition: Option[Expression] = None): LogicalPlan = {// SPARK-21835: It is possibly that the two sides of the join have conflicting attributes,// the produced join then becomes unresolved and break structural integrity. We should// de-duplicate conflicting attributes.// SPARK-26078: it may also happen that the subquery has conflicting attributes with the outer// values. In this case, the resulting join would contain trivially true conditions (e.g.// id#3 = id#3) which cannot be de-duplicated after. In this method, if there are conflicting// attributes in the join condition, the subquery's conflicting attributes are changed using// a projection which aliases them and resolves the problem.val outerReferences = valuesOpt.map(values =>AttributeSet.fromAttributeSets(values.map(_.references))).getOrElse(AttributeSet.empty)val outerRefs = outerPlan.outputSet ++ outerReferencesval duplicates = outerRefs.intersect(subplan.outputSet)if (duplicates.nonEmpty) {condition.foreach { e =>val conflictingAttrs = e.references.intersect(duplicates)if (conflictingAttrs.nonEmpty) {throw QueryCompilationErrors.conflictingAttributesInJoinConditionError(conflictingAttrs, outerPlan, subplan)}}val rewrites = AttributeMap(duplicates.map { dup =>dup -> Alias(dup, dup.toString)()}.toSeq)val aliasedExpressions = subplan.output.map { ref =>rewrites.getOrElse(ref, ref)}Project(aliasedExpressions, subplan)} else {subplan}}def apply(plan: LogicalPlan): LogicalPlan = plan.transformWithPruning(_.containsAnyPattern(EXISTS_SUBQUERY, LIST_SUBQUERY)) {// 匹配的SQL子句型,如:WHERE a.id IN (SELECT id FROM b WHERE id = 1)case Filter(condition, child)if SubqueryExpression.hasInOrCorrelatedExistsSubquery(condition) =>val (withSubquery, withoutSubquery) =splitConjunctivePredicates(condition).partition(SubqueryExpression.hasInOrCorrelatedExistsSubquery)// 构建新的过滤表达式,不带有exist/in (subquery)模式的表达式// Construct the pruned filter condition.val newFilter: LogicalPlan = withoutSubquery match {case Nil => childcase conditions => Filter(conditions.reduce(And), child)}// Filter the plan by applying left semi and left anti joins.withSubquery.foldLeft(newFilter) {case (p, Exists(sub, _, _, conditions)) =>val (joinCond, outerPlan) = rewriteExistentialExpr(conditions, p)buildJoin(outerPlan, sub, LeftSemi, joinCond)case (p, InSubquery(values, ListQuery(sub, _, _, _, conditions))) =>// Deduplicate conflicting attributes if any.// 到这里conditions,已经包含了原本在sub树中的关联过滤条件,这里再次尝试// 消除self join的情况,但实际测试中,相关的单元测试的SQL总是不会出现self join// 的问题,因此newSub始终等于sub。val newSub = dedupSubqueryOnSelfJoin(p, sub, Some(values))// 为所有的JOIN keys生成一个新的等值条件,左侧来自于outer plan,右侧来自于sub// 如果condidtioins包含了某个key的等值条件,这里依然会重复生成,因此有一定的冗余// 不过会在后续的过程被优化掉。val inConditions = values.zip(newSub.output).map(EqualTo.tupled)// 递归对join条件进行重写,替换其中的exists/in表达式为ExistenceJoin,// 例如有如下的改写逻辑(其中a.id = (b.id IN (SELECT id FROM t2))是带有subquery的predicate:// Filter(a.id = (b.id IN (SELECT id FROM t2)), Relation(b))// ==>// Filter(// Join(Relation(b),// Subquery(SELECT id FROM t2),// ExistenceJoin,// b.id = t2.id,// ExistenceJoin)// ))// val (joinCond, outerPlan) = rewriteExistentialExpr(inConditions ++ conditions, p)// 生成一个新的JOIN,以替换原来的形如://Filter i#254 IN (list#253 [i#254 && (i#254 = i#257)])//: +- Project [i#257]//: +- Relation default.t1[i#257,j#258] parquet//+- Relation default.t1[i#254,j#255] parquet// 转换为//Join LeftSemi, ((i#254 = i#257) AND (i#254 = i#257))//:- Relation default.t1[i#254,j#255] parquet//+- Project [i#257]// +- Relation default.t1[i#257,j#258] parquetJoin(outerPlan, newSub, LeftSemi, joinCond, JoinHint.NONE)case other => other // 这里删除了其它匹配模式的处理逻辑,不仅仅包含上面的两个case}// 匹配的SQL句型,如:SELECT a.id IN (SELECT id FROM b WHERE id = 1)case u: UnaryNode if u.expressions.exists(SubqueryExpression.hasInOrCorrelatedExistsSubquery) =>var newChild = u.childu.mapExpressions(expr => {val (newExpr, p) = rewriteExistentialExpr(Seq(expr), newChild)newChild = p// The newExpr can not be NonenewExpr.get}).withNewChildren(Seq(newChild))}/*** Given a predicate expression and an input plan, it rewrites any embedded existential sub-query* into an existential join. It returns the rewritten expression together with the updated plan.* Currently, it does not support NOT IN nested inside a NOT expression. This case is blocked in* the Analyzer.*/private def rewriteExistentialExpr(exprs: Seq[Expression],plan: LogicalPlan): (Option[Expression], LogicalPlan) = {var newPlan = planval newExprs = exprs.map { e =>e.transformDownWithPruning(_.containsAnyPattern(EXISTS_SUBQUERY, IN_SUBQUERY)) {case Exists(sub, _, _, conditions) =>val exists = AttributeReference("exists", BooleanType, nullable = false)()newPlan =buildJoin(newPlan, sub, ExistenceJoin(exists), conditions.reduceLeftOption(And))existscase Not(InSubquery(values, ListQuery(sub, _, _, _, conditions))) =>val exists = AttributeReference("exists", BooleanType, nullable = false)()// Deduplicate conflicting attributes if any.val newSub = dedupSubqueryOnSelfJoin(newPlan, sub, Some(values))val inConditions = values.zip(sub.output).map(EqualTo.tupled)// To handle a null-aware predicate not-in-subquery in nested conditions// (e.g., `v > 0 OR t1.id NOT IN (SELECT id FROM t2)`), we transform// `inCondition` (t1.id=t2.id) into `(inCondition) OR ISNULL(inCondition)`.//// For example, `SELECT * FROM t1 WHERE v > 0 OR t1.id NOT IN (SELECT id FROM t2)`// is transformed into a plan below;// == Optimized Logical Plan ==// Project [id#78, v#79]// +- Filter ((v#79 > 0) OR NOT exists#83)// +- Join ExistenceJoin(exists#83), ((id#78 = id#80) OR isnull((id#78 = id#80)))// :- Relation[id#78,v#79] parquet// +- Relation[id#80] parquetval nullAwareJoinConds = inConditions.map(c => Or(c, IsNull(c)))val finalJoinCond = (nullAwareJoinConds ++ conditions).reduceLeft(And)newPlan = Join(newPlan, newSub, ExistenceJoin(exists), Some(finalJoinCond), JoinHint.NONE)Not(exists)case InSubquery(values, ListQuery(sub, _, _, _, conditions)) =>val exists = AttributeReference("exists", BooleanType, nullable = false)()// Deduplicate conflicting attributes if any.val newSub = dedupSubqueryOnSelfJoin(newPlan, sub, Some(values))val inConditions = values.zip(newSub.output).map(EqualTo.tupled)val newConditions = (inConditions ++ conditions).reduceLeftOption(And)newPlan = Join(newPlan, newSub, ExistenceJoin(exists), newConditions, JoinHint.NONE)exists}}(newExprs.reduceOption(And), newPlan)}
}
Rewrite Join With Dynamic Subquery
Rule Name: PartitionPruning
-- Before
-- id是一个分区字段
Project [a.*]LeftSemiJoin [b.id = a.id, b.id = a.id]Relation [a.*]Project [b.id]Filter [b.id > 0]Relation [b.id]-- After
-- Cond1: Left Semi Join,可以对左侧表进行动态过滤
-- Cond2: id是分区字段,因此过滤条件能够被下推到scan
-- Cond3: JOIN右侧表计划树,包含Filter条件,b.id > 0
-- Cond4:
-- JOIN Key/Pruning key是a.id/b.id,基于列的stats信息估算出,DPP的过滤比filterRatio
-- 当a.id的distincts数量 > b.id的distinct数量时,filterRatio=1-distinct_b_id/distinct_a_id
-- 其它情况则是spark.sql.optimizer.dynamicPartitionPruning.fallbackFilterRatio = 0.5
-- 得到裁剪收益benefits:filterRatio * stats_size_a > stats_size_b,因此可以广播表b中id字段的数据集。
Project [a.*]LeftSemiJoin [b.id = a.id, b.id = a.id]Filter [DynamicPruningSubquery(Project [b.id]Filter [b.id > 0]Relation [b.id])]Relation [a.*]Project [b.id]Filter [b.id > 0]Relation [b.id]
PartitionPruning的实例逻辑及分析:
object PartitionPruning extends Rule[LogicalPlan] with PredicateHelper with JoinSelectionHelper {/*** Insert a dynamic partition pruning predicate on one side of the join using the filter on the* other side of the join.* - to be able to identify this filter during query planning, we use a custom* DynamicPruning expression that wraps a regular In expression* - we also insert a flag that indicates if the subquery duplication is worthwhile and it* should run regardless of the join strategy, or is too expensive and it should be run only if* we can reuse the results of a broadcast*/private def insertPredicate(pruningKey: Expression,pruningPlan: LogicalPlan,filteringKey: Expression,filteringPlan: LogicalPlan,joinKeys: Seq[Expression],partScan: LogicalPlan): LogicalPlan = {val reuseEnabled = conf.exchangeReuseEnabledval index = joinKeys.indexOf(filteringKey)// prunning plan被裁剪掉的数据集大小,大于于右边表时,才是有收益的lazy val hasBenefit = pruningHasBenefit(pruningKey, partScan, filteringKey, filteringPlan)if (reuseEnabled || hasBenefit) {// 只有开启了stage reuse功能,实际上只能是reuse broadcast stage;或是有收益的,才会插入DPP// insert a DynamicPruning wrapper to identify the subquery during query planningFilter(DynamicPruningSubquery(pruningKey,filteringPlan,joinKeys,index,conf.dynamicPartitionPruningReuseBroadcastOnly || !hasBenefit),pruningPlan)} else {// abort dynamic partition pruningpruningPlan}}/*** Given an estimated filtering ratio we assume the partition pruning has benefit if* the size in bytes of the partitioned plan after filtering is greater than the size* in bytes of the plan on the other side of the join. We estimate the filtering ratio* using column statistics if they are available, otherwise we use the config value of* `spark.sql.optimizer.dynamicPartitionPruning.fallbackFilterRatio`.*/private def pruningHasBenefit(partExpr: Expression,partPlan: LogicalPlan,otherExpr: Expression,otherPlan: LogicalPlan): Boolean = {// get the distinct counts of an attribute for a given tabledef distinctCounts(attr: Attribute, plan: LogicalPlan): Option[BigInt] = {plan.stats.attributeStats.get(attr).flatMap(_.distinctCount)}// the default filtering ratio when CBO stats are missing, but there is a// predicate that is likely to be selectiveval fallbackRatio = conf.dynamicPartitionPruningFallbackFilterRatio// the filtering ratio based on the type of the join condition and on the column statisticsval filterRatio = (partExpr.references.toList, otherExpr.references.toList) match {// filter out expressions with more than one attribute on any side of the operatorcase (leftAttr :: Nil, rightAttr :: Nil)if conf.dynamicPartitionPruningUseStats =>// get the CBO stats for each attribute in the join conditionval partDistinctCount = distinctCounts(leftAttr, partPlan)val otherDistinctCount = distinctCounts(rightAttr, otherPlan)val availableStats = partDistinctCount.isDefined && partDistinctCount.get > 0 &&otherDistinctCount.isDefinedif (!availableStats) {fallbackRatio} else if (partDistinctCount.get.toDouble <= otherDistinctCount.get.toDouble) {// there is likely an estimation error, so we fallbackfallbackRatio} else {1 - otherDistinctCount.get.toDouble / partDistinctCount.get.toDouble}case _ => fallbackRatio}val estimatePruningSideSize = filterRatio * partPlan.stats.sizeInBytes.toFloatval overhead = calculatePlanOverhead(otherPlan)estimatePruningSideSize > overhead}/*** Calculates a heuristic overhead of a logical plan. Normally it returns the total* size in bytes of all scan relations. We don't count in-memory relation which uses* only memory.*/private def calculatePlanOverhead(plan: LogicalPlan): Float = {val (cached, notCached) = plan.collectLeaves().partition(p => p match {case _: InMemoryRelation => truecase _ => false})val scanOverhead = notCached.map(_.stats.sizeInBytes).sum.toFloatval cachedOverhead = cached.map {case m: InMemoryRelation if m.cacheBuilder.storageLevel.useDisk &&!m.cacheBuilder.storageLevel.useMemory =>m.stats.sizeInBytes.toFloatcase m: InMemoryRelation if m.cacheBuilder.storageLevel.useDisk =>m.stats.sizeInBytes.toFloat * 0.2case m: InMemoryRelation if m.cacheBuilder.storageLevel.useMemory =>0.0}.sum.toFloatscanOverhead + cachedOverhead}/*** Search a filtering predicate in a given logical plan*/private def hasSelectivePredicate(plan: LogicalPlan): Boolean = {plan.exists {case f: Filter => isLikelySelective(f.condition)case _ => false}}/*** To be able to prune partitions on a join key, the filtering side needs to* meet the following requirements:* (1) it can not be a stream* (2) it needs to contain a selective predicate used for filtering*/private def hasPartitionPruningFilter(plan: LogicalPlan): Boolean = {!plan.isStreaming && hasSelectivePredicate(plan)}private def prune(plan: LogicalPlan): LogicalPlan = {plan transformUp {// skip this rule if there's already a DPP subquery on the LHS of a joincase j @ Join(Filter(_: DynamicPruningSubquery, _), _, _, _, _) => jcase j @ Join(_, Filter(_: DynamicPruningSubquery, _), _, _, _) => jcase j @ Join(left, right, joinType, Some(condition), hint) =>// 只会对JOIN结构生效var newLeft = leftvar newRight = right// extract the left and right keys of the join conditionval (leftKeys, rightKeys) = j match {case ExtractEquiJoinKeys(_, lkeys, rkeys, _, _, _, _, _) => (lkeys, rkeys)case _ => (Nil, Nil)}// checks if two expressions are on opposite sides of the joindef fromDifferentSides(x: Expression, y: Expression): Boolean = {def fromLeftRight(x: Expression, y: Expression) =!x.references.isEmpty && x.references.subsetOf(left.outputSet) &&!y.references.isEmpty && y.references.subsetOf(right.outputSet)fromLeftRight(x, y) || fromLeftRight(y, x)}splitConjunctivePredicates(condition).foreach {case EqualTo(a: Expression, b: Expression)if fromDifferentSides(a, b) =>val (l, r) = if (a.references.subsetOf(left.outputSet) &&b.references.subsetOf(right.outputSet)) {a -> b} else {b -> a}// there should be a partitioned table and a filter on the dimension table,// otherwise the pruning will not triggervar filterableScan = getFilterableTableScan(l, left)if (filterableScan.isDefined && canPruneLeft(joinType) &&hasPartitionPruningFilter(right)) {// 左边表是prunning plan,右边表是filtering plan// 只有当右侧表有过滤条件时,才会会左边表插入DPP predicatenewLeft = insertPredicate(l, newLeft, r, right, rightKeys, filterableScan.get)} else {filterableScan = getFilterableTableScan(r, right)if (filterableScan.isDefined && canPruneRight(joinType) &&hasPartitionPruningFilter(left) ) {newRight = insertPredicate(r, newRight, l, left, leftKeys, filterableScan.get)}}case _ =>}// 返回一个新的plan结点Join(newLeft, newRight, joinType, Some(condition), hint)}}override def apply(plan: LogicalPlan): LogicalPlan = plan match {// Do not rewrite subqueries.case s: Subquery if s.correlated => plancase _ if !conf.dynamicPartitionPruningEnabled => plancase _ => prune(plan)}
}
Rewrite Dynamic Subquery as Dynamic Expression
Rule Name: PlanDynamicPruningFilters
-- Before
-- id是一个分区字段
-- Cond1: Left Semi Join,可以对左侧表进行动态过滤
-- Cond2: id是分区字段,因此过滤条件能够被下推到scan
-- Cond3: JOIN右侧表计划树,包含Filter条件,b.id > 0
-- Cond4: JOIN Key/ Pruning key是a.id/b.id,基于列的stats信息估算出,DPP的过滤比filterRatio
-- 当a.id的distincts数量 > b.id的distinct数量时,filterRatio=1-distinct_b_id/distinct_a_id
-- 其它情况则是spark.sql.optimizer.dynamicPartitionPruning.fallbackFilterRatio = 0.5
-- 得到裁剪收益benefits:filterRatio * stats_size_a > stats_size_b,因此可以广播b
-- 假设benefits = ture
Project [a.*]LeftSemiJoin [b.id = a.id, b.id = a.id]Filter [DynamicPruningSubquery(Project [b.id]Filter [b.id > 0]Relation [b.id]]Relation [a.*]Project [b.id]Filter [b.id > 0]Relation [b.id]-- After
-- case1: 支持exchange reuse,而且计划树中存在broadcast计划,且与filtering plan相同,即DPS,时
-- DynamicPruningExpression(InSubqueryExec(value, broadcastValues, exprId))
-- case2: filtering plan只能被广播时
-- DynamicPruningExpression(Literal.TrueLiteral)
-- case3: 即使不能走broadcast,但裁剪有收益
-- DynamicPruningExpression(expressions.InSubquery(
-- Seq(value), ListQuery(aggregate, childOutputs = aggregate.output)))
Project [a.*]LeftSemiJoin [b.id = a.id, b.id = a.id]Filter [DynamicPruningExpression(InSubqueryExec(a.id, SubqueryBroadcastExec(Project [b.id]Filter [b.id > 0]Relation [b.id]))Relation [a.*]Project [b.id]Filter [b.id > 0]Relation [b.id]
PlanDynamicPruningFilters优化规则的实现逻辑及分析:
case class PlanDynamicPruningFilters(sparkSession: SparkSession)extends Rule[SparkPlan] with PredicateHelper {/*** Identify the shape in which keys of a given plan are broadcasted.*/private def broadcastMode(keys: Seq[Expression], output: AttributeSeq): BroadcastMode = {val packedKeys = BindReferences.bindReferences(HashJoin.rewriteKeyExpr(keys), output)HashedRelationBroadcastMode(packedKeys)}override def apply(plan: SparkPlan): SparkPlan = {if (!conf.dynamicPartitionPruningEnabled) {return plan}plan.transformAllExpressionsWithPruning(_.containsPattern(DYNAMIC_PRUNING_SUBQUERY)) {case DynamicPruningSubquery(value, buildPlan, buildKeys, broadcastKeyIndex, onlyInBroadcast, exprId) =>val sparkPlan = QueryExecution.createSparkPlan(sparkSession, sparkSession.sessionState.planner, buildPlan)// Using `sparkPlan` is a little hacky as it is based on the assumption that this rule is// the first to be applied (apart from `InsertAdaptiveSparkPlan`).val canReuseExchange = conf.exchangeReuseEnabled && buildKeys.nonEmpty &&plan.exists {case BroadcastHashJoinExec(_, _, _, BuildLeft, _, left, _, _) =>left.sameResult(sparkPlan)case BroadcastHashJoinExec(_, _, _, BuildRight, _, _, right, _) =>right.sameResult(sparkPlan)case _ => false}if (canReuseExchange) {// 只有当支持复用broadcast stage时,才能够应用DPP,因此这里会通过broadcast机制拿到// filtering plan的结果集,以在运行时对pruning plan(被裁剪的plan)的描述分区进一步删减val executedPlan = QueryExecution.prepareExecutedPlan(sparkSession, sparkPlan)val mode = broadcastMode(buildKeys, executedPlan.output)// plan a broadcast exchange of the build side of the joinval exchange = BroadcastExchangeExec(mode, executedPlan)val name = s"dynamicpruning#${exprId.id}"// place the broadcast adaptor for reusing the broadcast results on the probe sideval broadcastValues =SubqueryBroadcastExec(name, broadcastKeyIndex, buildKeys, exchange)DynamicPruningExpression(InSubqueryExec(value, broadcastValues, exprId))} else if (onlyInBroadcast) {// it is not worthwhile to execute the query, so we fall-back to a true literal// 如果显示指定了只能利用broadcast实现DPP,同时整个计划树中不存在与filtering plan相同的// broadcast stage时,返回字面量true,表示dpp失效。DynamicPruningExpression(Literal.TrueLiteral)} else {// 如果不强制DPP只能依赖broadcast机制生效,同时DPP裁剪是有收益的,那么就改写SQL,构建一个子查询,// 采集filtering plan的与join key相关的distinct数据集,以便在运行时对prunning plan裁剪// we need to apply an aggregate on the buildPlan in order to be column prunedval alias = Alias(buildKeys(broadcastKeyIndex), buildKeys(broadcastKeyIndex).toString)()val aggregate = Aggregate(Seq(alias), Seq(alias), buildPlan)DynamicPruningExpression(expressions.InSubquery(Seq(value), ListQuery(aggregate, childOutputs = aggregate.output)))}}}
}
Push Down Dynamic Expression And Materialization
Strategy Name: DataSourceV2Strategy
从逻辑计划树转换为物理计划树的过程中,会将DPP过滤条件,下推到BatchScanExec算子,以便能够在生成RDD时(execution阶段)能够应用这些条件,过滤分区。
-- Before
-- case1: 支持exchange reuse,而且计划树中存在broadcast计划,且与filtering plan相同,即DPS,时
-- DynamicPruningExpression(InSubqueryExec(value, broadcastValues, exprId))
-- case2: filtering plan只能被广播时
-- DynamicPruningExpression(Literal.TrueLiteral)
-- case3: 即使不能走broadcast,但裁剪有收益
-- DynamicPruningExpression(expressions.InSubquery(
-- Seq(value), ListQuery(aggregate, childOutputs = aggregate.output)))
Project [a.*]LeftSemiJoin [b.id = a.id, b.id = a.id]Filter [DynamicPruningExpression(InSubqueryExec(a.id, SubqueryBroadcastExec(Project [b.id]Filter [b.id > 0]Relation [b.id])))]Relation [a.*]Project [b.id]Filter [b.id > 0]Relation [b.id]-- Physical Plan
-- DatasourceV2Strategy物化逻辑计划树时,会下推DynamicPruning类型的过滤表达式到BatchScanExec
-- 在这里就是DynamicPruningExpression,由于FilterExec只有一个表达式,因此会被完全消除
ProjectExec [a.*]BroadcastJoinExec [a.*] [b.id = a.id, b.id = a.id]-- Filter算子被消除了BatchScanExec [a.*] [runtimeFilters = DynamicPruningExpression(InSubqueryExec(a.id, SubqueryBroadcastExec(Project [b.id]Filter [b.id > 0]Relation [b.id])))]BroadcastExchangeExecProjectExec [b.id]FilterExec [b.id > 0]BatchScanExec [b.id]
Pruning Partitions at Runtime
BatchScanExec::compute被调用时,即生成RDD时,才会应用DPP过滤。
/*** Physical plan node for scanning a batch of data from a data source v2.*/
case class BatchScanExec(output: Seq[AttributeReference],@transient scan: Scan,runtimeFilters: Seq[Expression],keyGroupedPartitioning: Option[Seq[Expression]] = None) extends DataSourceV2ScanExecBase {@transient override lazy val inputPartitions: Seq[InputPartition] = batch.planInputPartitions()@transient private lazy val filteredPartitions: Seq[Seq[InputPartition]] = {// 将DPP表达式转换成Spark统一的表达式,即Source Filterval dataSourceFilters = runtimeFilters.flatMap {case DynamicPruningExpression(e) => DataSourceStrategy.translateRuntimeFilter(e)case _ => None}if (dataSourceFilters.nonEmpty) {val originalPartitioning = outputPartitioning// the cast is safe as runtime filters are only assigned if the scan can be filtered// 在这里,如果Scan实例,确实支持了runtime filter的功能,那么会在运行时将DynamicPruningExpression下推到数据源val filterableScan = scan.asInstanceOf[SupportsRuntimeFiltering]// Scan::filter接口,提供了一个入口,方便用户将Source Filter按自己的需求,再次进行转换,// 例如Parquet FilterfilterableScan.filter(dataSourceFilters.toArray)// call toBatch again to get filtered partitions// 生成最终的`InputPartition`集合,它们经过了dataSourceFilters洗礼。val newPartitions = scan.toBatch.planInputPartitions()originalPartitioning match {case p: KeyGroupedPartitioning =>if (newPartitions.exists(!_.isInstanceOf[HasPartitionKey])) {throw new SparkException("Data source must have preserved the original partitioning " +"during runtime filtering: not all partitions implement HasPartitionKey after " +"filtering")}val newRows = new InternalRowSet(p.expressions.map(_.dataType))newRows ++= newPartitions.map(_.asInstanceOf[HasPartitionKey].partitionKey())val oldRows = p.partitionValuesOpt.getif (oldRows.size != newRows.size) {throw new SparkException("Data source must have preserved the original partitioning " +"during runtime filtering: the number of unique partition values obtained " +s"through HasPartitionKey changed: before ${oldRows.size}, after ${newRows.size}")}if (!oldRows.forall(newRows.contains)) {throw new SparkException("Data source must have preserved the original partitioning " +"during runtime filtering: the number of unique partition values obtained " +s"through HasPartitionKey remain the same but do not exactly match")}groupPartitions(newPartitions).get.map(_._2)case _ =>// no validation is needed as the data source did not report any specific partitioningnewPartitions.map(Seq(_))}} else {partitions}}override lazy val inputRDD: RDD[InternalRow] = {if (filteredPartitions.isEmpty && outputPartitioning == SinglePartition) {// return an empty RDD with 1 partition if dynamic filtering removed the only splitsparkContext.parallelize(Array.empty[InternalRow], 1)} else {new DataSourceRDD(sparkContext, filteredPartitions, readerFactory, supportsColumnar, customMetrics)}}override def doExecute(): RDD[InternalRow] = {val numOutputRows = longMetric("numOutputRows")inputRDD.map { r =>numOutputRows += 1r}}
}
扩展知识
DPP的设计实现
类结构
下图展示了Spark中与DPP相关的类定义,其中DynamicPruning是一个接口,标识了一个Logical Plan结点是不是DPP相关的。
为了能够完成DPP的功能,Spark实现了两个具体的表达式(Expression)类,DynamicPruningSubquery和DynamicPruningExpression。
DynamicPruningSubquery
其中DynamicPruningSubquery维护了可以进行DPP的过滤条件的细节,如在前一节的SQL示例中提到的JOIN过滤条件a.id IN (SELECT id FROM b WHERE id = 1),因此它包含了一个子查询。
case class DynamicPruningSubquery(pruningKey: Expression, // 被裁剪的JOIN侧的字段,如前面的SQL示例中提到的a.id字段buildQuery: LogicalPlan, // 被广播的子查询buildKeys: Seq[Expression], // 被广播的子查询对应的所有JOIN keys,如前面的SQL示例中提到的b.idbroadcastKeyIndex: Int, // 被广播的子查询的输出字段的索引,例如前面的SQL示例中的JOIN条件a.id = b.id,其中a.id对应于pruningKey,b.id对应于broadcastKeyonlyInBroadcast: Boolean, // 用于标识过滤子查询的结果是否只能被Broadcast到JOIN的另一侧(被过滤侧)exprId: ExprId = NamedExpression.newExprId,hint: Option[HintInfo] = None)extends SubqueryExpression(buildQuery, Seq(pruningKey), exprId, Seq.empty, hint)with DynamicPruningwith Unevaluablewith UnaryLike[Expression]
DynamicPruningExpression
DynamicPruningExpression则是对DynamicPruningSubquery的封装和替代,维护的信息逻辑是是子查询的结果集,因此它与DynamicPruningSubquery类有前后关系。
// child成员变量,对应了DynamicPruningSubquery返回的结果集
case class DynamicPruningExpression(child: Expression)extends UnaryExpressionwith DynamicPruning
简单来说,Spark会在planning阶段,先收集可以进行DPP的信息,生成DynamicPruningSubquery结点;然后对DynamicPruningSubquery进行分析,按一定的规则可以DPP的逻辑计划。
生成DynamicPruningSubquery
在逻辑计划树中插入DynamicPruningSubquery结点,是通过PartitionPruning优化规则实现的,它被注册在SparkOptimizer的defaultBatches中,因此所有的Query都会尝试应用此规则。
object PartitionPruning extends Rule[LogicalPlan] with PredicateHelper with JoinSelectionHelper {private def prune(plan: LogicalPlan): LogicalPlan = {plan transformUp {// skip this rule if there's already a DPP subquery on the LHS of a joincase j @ Join(Filter(_: DynamicPruningSubquery, _), _, _, _, _) => jcase j @ Join(_, Filter(_: DynamicPruningSubquery, _), _, _, _) => jcase j @ Join(left, right, joinType, Some(condition), hint) =>var newLeft = leftvar newRight = right// extract the left and right keys of the join conditionval (leftKeys, rightKeys) = j match {case ExtractEquiJoinKeys(_, lkeys, rkeys, _, _, _, _, _) => (lkeys, rkeys)case _ => (Nil, Nil)}// checks if two expressions are on opposite sides of the joindef fromDifferentSides(x: Expression, y: Expression): Boolean = {def fromLeftRight(x: Expression, y: Expression) =!x.references.isEmpty && x.references.subsetOf(left.outputSet) &&!y.references.isEmpty && y.references.subsetOf(right.outputSet)fromLeftRight(x, y) || fromLeftRight(y, x)}splitConjunctivePredicates(condition).foreach {case EqualTo(a: Expression, b: Expression)if fromDifferentSides(a, b) =>val (l, r) = if (a.references.subsetOf(left.outputSet) &&b.references.subsetOf(right.outputSet)) {a -> b} else {b -> a}// there should be a partitioned table and a filter on the dimension table,// otherwise the pruning will not triggervar filterableScan = getFilterableTableScan(l, left)if (filterableScan.isDefined && canPruneLeft(joinType) &&hasPartitionPruningFilter(right)) {newLeft = insertPredicate(l, newLeft, r, right, rightKeys, filterableScan.get)} else {filterableScan = getFilterableTableScan(r, right)if (filterableScan.isDefined && canPruneRight(joinType) &&hasPartitionPruningFilter(left) ) {newRight = insertPredicate(r, newRight, l, left, leftKeys, filterableScan.get)}}case _ =>}Join(newLeft, newRight, joinType, Some(condition), hint)}}override def apply(plan: LogicalPlan): LogicalPlan = plan match {// Do not rewrite subqueries.case s: Subquery if s.correlated => plancase _ if !conf.dynamicPartitionPruningEnabled => plancase _ => prune(plan)}
}
Subquery(子查询)的定义及分类
依赖子查询
由于了表b上的子查询,包含了外部查询(这里指表a)的字段/列,因此Spark不会对这一类子查询应用动态裁剪优化规则。
其中a.id是一个类型为OuterReference的属性,因此它已经在外层的Query scope中被解析了;而b.id是一个类型为AttributeReference的属性,故这种有内、外依赖关系的查询,被称之为关联/依赖查询。
SELECT *
FROM a
WHERE EXISTS (SELECT *FROM bWHERE b.id > a.id)
非依赖子查询
内查询(表b上的查询)与外查询(表a上的查询)没有关联关系,因此Spark可以修改计划,应用动态裁剪功能优化规则。
SELECT *
FROM a
WHERE EXISTS (SELECT *FROM bWHERE b.id > 10)
几类常见的Subquery
Lateral
SELECT * FROM t LATERAL (SELECT * FROM u) uu
Exists
SELECT *
FROM a
WHERE EXISTS (SELECT *FROM bWHERE b.id > 10)
IN
SELECT *
FROM a
WHERE a.id IN (SELECT idFROM b)
Scala
SELECT (SELECT CURRENT_DATE())
Table Valued Function
SELECT * FROM my_tvf(TABLE (v1), TABLE (SELECT 1))
相关文章:
的实现及应用剖析)
Spark 3.3.x版本中的动态分区裁剪(DPP,Dynamic Partition Pruning)的实现及应用剖析
文章目录 Dynamic Partition Pruning(DPP)的作用DPP生效的一些要点DPP生效的简单SQL示例DPP生效SQL的解析示例Deduplicate Correlated SubqueryRewrite Predicates as JoinRewrite Join With Dynamic SubqueryRewrite Dynamic Subquery as Dynamic Expre…...

Android 各国语言value文件夹命名规则
中文 values-zh英语values-en 阿拉伯语 values-ar 保加利亚语 values-bg加泰罗尼亚语values-ca 捷克语 values-cs 丹麦语 values-da 德语 values-de 希腊语 values-el 西班牙语 values-es 芬兰语 values-fi 法语 values-fr 希伯来语 values-iw 印地语 values-hi 克罗里亚语 …...

深入理解Redis锁与Backoff重试机制在Go中的实现
文章目录 流程图Redis锁的深入实现Backoff重试策略的深入探讨结合Redis锁与Backoff策略的高级应用具体实现结论 在构建分布式系统时,确保数据的一致性和操作的原子性是至关重要的。Redis锁作为一种高效且广泛使用的分布式锁机制,能够帮助我们在多进程或分…...

uniapp-小程序开发0-1笔记大全
uniapp官网: https://uniapp.dcloud.net.cn/tutorial/syntax-js.html uniapp插件市场: https://ext.dcloud.net.cn/ uviewui类库: https://www.uviewui.com/ 柱状、扇形、仪表盘库: https://www.ucharts.cn/v2/#/ CSS样式&…...

Go语言数据库操作深入讲解
go操作MySQL 使用第三方开源的mysql库: github.com/go-sql-driver/mysql (mysql驱动)github.com/jmoiron/sqlx (基于mysql驱动的封装) 命令行输入 : go get github.com/go-sql-driver/mysqlgo get github.com/jmoiron/sqlx Insert操作 登录后复制 // 连接Mysql data…...

搜维尔科技:SenseGlove Nova 2触觉反馈手套开箱测评
SenseGlove Nova 2触觉反馈手套开箱测评 搜维尔科技:SenseGlove Nova 2触觉反馈手套开箱测评...

步步精科技诚邀您参加2024慕尼黑华南电子展
尊敬的客户: 我们诚挚地邀请您参加即将于2024年10月14日至10月16日在深圳国际会展中心 (宝安新馆)举办的慕尼黑华南电子展(electronica South China)。本届将聚焦人工智能、数据中心、新型储能、无线通信、硬件安全、新能源汽车、第三代半导…...

OPC UA与PostgreSQL如何实现无缝连接?
随着工业4.0的推进,数据交换和集成在智能制造中扮演着越来越重要的角色。OPC UA能够实现设备与设备、设备与系统之间的高效数据交换。而PostgreSQL则是一种强大的开源关系型数据库管理系统,广泛应用于数据存储和管理。如何将OPC UA与PostgreSQL结合起来&…...

C语言[斐波那契数列2]
本篇文章讲述前一篇文章的细节,方便大家进行代码的运算。 本次代码题为: 输出斐波那契数列的前20位数,每行4位数。 详细解释: 在 main 函数中,首先定义了循环变量 i 和用于存储斐波那契数列项的三个长整型变量 f1 、 f2 和 temp 。其…...
八、Linux之实用指令
1、指定运行级别 1.1 基本介绍 运行级别说明 0 :关机 1 :单用户【找回丢失密码】 2:多用户状态没有网络服务(用的非常少) 3:多用户状态有网络服务(用的最多) 4:系统未使…...
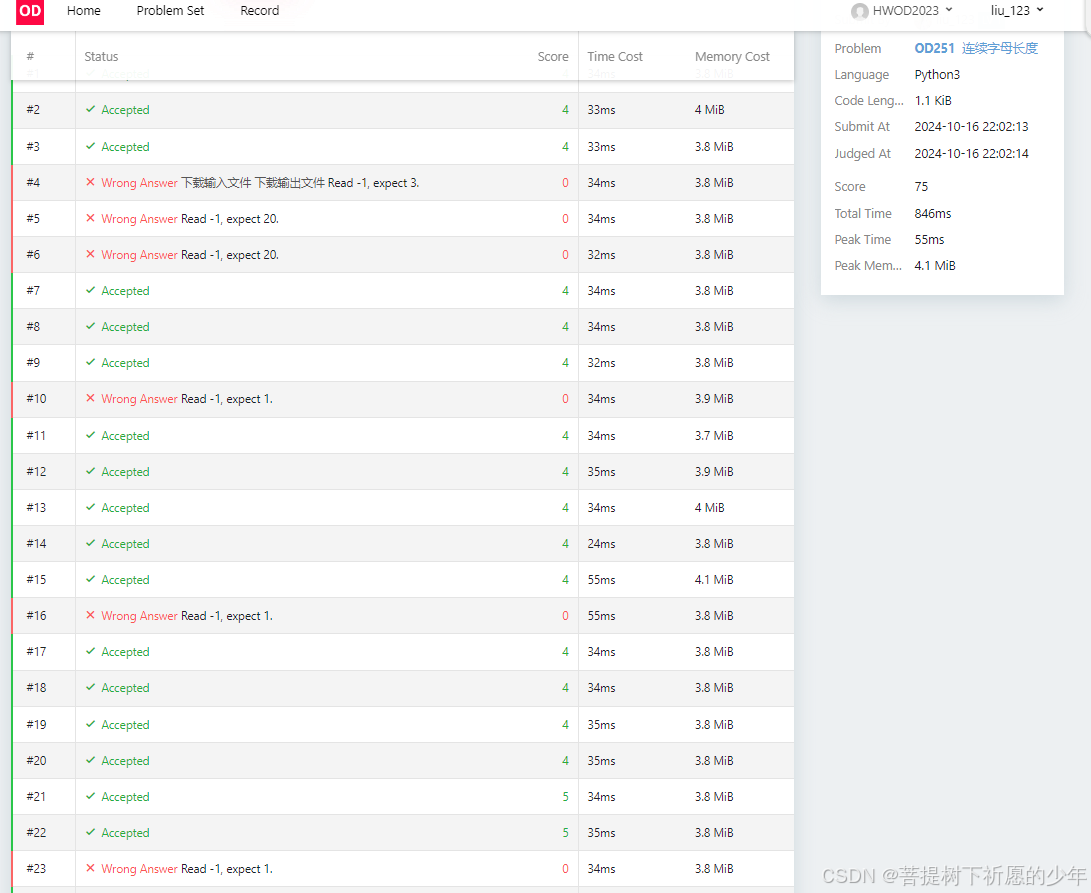
2024_E_100_连续字母长度
连续字母长度 题目描述 给定一个字符串,只包含大写字母,求在包含同一字母的子串中,长度第 k 长的子串的长度,相同字母只取最长的那个子串。 输入描述 第一行有一个子串(1<长度<100),只包含大写字母。 第二行为…...
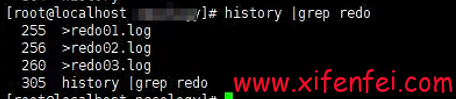
清空redo导致oracle故障恢复---惜分飞
客户由于空间不足,使用> redo命令清空了oracle的redo文件 数据库挂掉之后,启动报错 Fri Oct 04 10:32:57 2024 alter database open Beginning crash recovery of 1 threads parallel recovery started with 31 processes Started redo scan Errors in file /home/oracle…...
)
VAE(与GAN)
VAE 1. VAE 模型概述 变分自编码器(Variational Autoencoder, VAE)是一种生成模型,主要用于学习数据的潜在表示并生成新样本。它由两个主要部分组成:编码器和解码器。 编码器:将输入数据映射到潜在空间,…...
)
【高等数学】多元微分学(二)
隐函数的偏导数 二元方程的隐函数 F ( x , y ) 0 F(x,y)0 F(x,y)0 推出隐函数形式 y y ( x ) yy(x) yy(x). 欲求 d y d x \frac{d y}{d x} dxdy 需要对 F 0 F0 F0 两边同时对 x x x 求全导 0 d d x F ( x , y ( x ) ) ∂ F ∂ x d x d x ∂ F ∂ y d y d x ∂ F…...
和WCF(Windows Communication Foundation))
.NET 中的 Web服务(Web Services)和WCF(Windows Communication Foundation)
一、引言 在当今数字化时代,不同的软件系统和应用程序之间需要进行高效、可靠的通信与数据交换。.NET 框架中的 Web 服务和 WCF(Windows Communication Foundation)为此提供了强大的技术支持。它们在构建分布式应用程序、实现跨平台通信以及…...

Linux小知识2 系统的启动
我们在上文中介绍了文件系统,提到了Linux的文件系统存在一个块的概念,其中有一个特殊的块:引导块。这和我们这里要讲的系统启动有关。 BIOS 基本输入输出系统,基本上是一个操作系统最早实现也是最早运行的第一个程序。是一个比较…...
Oracle-19g数据库的安装
简介 Oracle是一家全球领先的数据库和云解决方案提供商。他们提供了一套完整的技术和产品,包括数据库管理系统、企业级应用程序、人工智能和机器学习工具等。Oracle的数据库管理系统是业界最受欢迎和广泛使用的数据库之一,它可以管理和存储大量结构化和…...
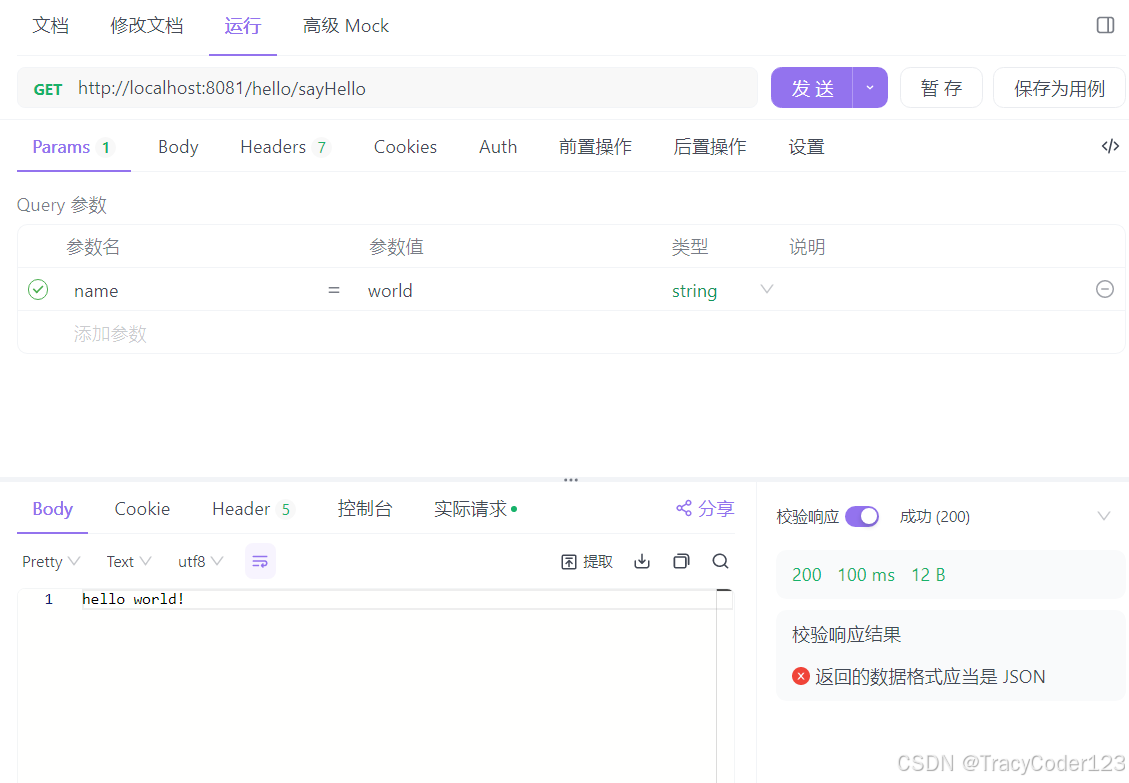
Dubbo快速入门(二):第一个Dubbo程序(附源码)
文章目录 一、生产者工程0.目录结构1.依赖2.配置文件3.启动类4.生产者服务 二、消费者工程0.目录结构1.依赖2.配置文件3.启动类4.服务接口5.controller接口 三、测试代码 本博客配套源码:gitlab仓库 首先,在服务器上部署zookeeper并运行,可以…...

不同数据类型转换与转义的对比差异
(Owed by: 春夜喜雨 http://blog.csdn.net/chunyexiyu) 在C和C语言中,类型转换与转义是有点像的,有时可能被误解,这块需要仔细辨别。 类型转换形如,把不同字节数或相同字节数的类型值进行转换,强调的是数值转换过去&…...
Kylin系统安装VMwareTools工具
如下图所示,安装好Kylin系统之后,还未安装VMwareTools工具,导致系统画面无法填充虚拟机 正常安装了VMwareTools工具后的系统画面 所以,接下来我们介绍一下如何在Kylin系统下安装VMwareTools工具 首先,点击VMware工具栏…...

Java数组工具类实战:设计不可实例化的静态工具类
实现一个工具类 MathUtils,满足以下要求: 1. 所有方法均为静态,且该类不能从外部实例化(提示:使用私有构造器)。 2. 提供三个静态方法:- maxArray(int[] arr):返回较大值;…...

股票买卖最佳时机:LeetCode121题解
题目LeetCode121给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。返回你可以从这笔交易中获取…...

phpMyAdmin CVE-2018-12613:从文件读取到RCE的伪协议利用链
1. 这个漏洞不是“能读文件”那么简单,而是后台权限的彻底失守phpMyAdmin 4.8.1里那个CVE-2018-12613,很多人扫到就报个“存在文件包含”,顺手贴个?targetphp://filter/convert.base64-encode/resource/etc/passwd截图完事。我去年在给一家教…...

Performance-Fish:让你的《环世界》后期游戏帧率提升400%的终极优化方案
Performance-Fish:让你的《环世界》后期游戏帧率提升400%的终极优化方案 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish 你是否曾在《环世界》游戏后期,面对庞大…...

接口测试用例设计:超详细防御体系与分层校验实践
1. 为什么“超详细”三个字在接口测试用例里不是修饰词,而是生死线我带过三支不同行业的测试团队——金融支付、SaaS中台、IoT设备管理平台。每次新人入职第一周,我都会收走他们写的前5条接口测试用例,逐行标红批注。不是因为格式不对&#x…...

Python-for-Android 完整指南:5分钟将Python应用打包为Android APK
Python-for-Android 完整指南:5分钟将Python应用打包为Android APK 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android Python-for-Android࿰…...

怎么理解Filter不是在afterCompetition里面remove掉ThreadLocal里面的东西,而是说在finally块里面remove
文章目录1. 核心原因:Filter 的“套娃(洋葱圈)”执行模型2. 为什么不能(也无法)在这里用 afterCompletion?维度一:Filter 拿不到 afterCompletion维度二:生命周期顺序的致命冲突总结…...

终极指南:5分钟搞定淘宝淘金币全任务自动化脚本
终极指南:5分钟搞定淘宝淘金币全任务自动化脚本 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinbi 你是否厌倦…...
:setup / onboard 与本地配置初始化)
OpenClaw 源码解析(五):setup / onboard 与本地配置初始化
1. 本期目标 上一期我们分析了 OpenClaw 的 CLI 启动链路:用户输入 openclaw 命令后,程序会先经过 entry.ts、run-main、Commander Program 构建和命令注册流程,然后再进入具体命令逻辑。 这一期继续往下看,重点分析两个最基础的…...

暗黑破坏神2存档编辑器:d2s-editor免费可视化编辑终极指南
暗黑破坏神2存档编辑器:d2s-editor免费可视化编辑终极指南 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 想要轻松修改暗黑破坏神2存档却不懂十六进制?d2s-editor是你的完美解决方案!这款基于…...