深度学习代码学习笔记2
1、torch.max
correct = 0
total = 0
for xb,yb in valid_dl:outputs = model(xb)_,predicted = torch.max(outputs.data,1)total += yb.size(0) #yb.size(0) 返回的是张量 yb 在第 0 维的大小,也就是 yb 中的样本数量。correct += (predicted == yb).sum().item()
print('正确率:%d %%'%(100 * correct /total))
def accuracy(predictions, labels):# predictions.data 是模型的预测结果# torch.max(predictions.data, 1) 返回每一行的最大值和对应的索引。 # [1] 表示我们只关心索引,即选择模型预测类别的索引。pred = torch.max(predictions.data, 1)[1] # 取出每一行的最大值索引,得到预测类别# labels.data.view_as(pred) 将 labels 调整为与 pred 形状一致,方便比较# eq() 函数逐元素比较 pred 和 labels 的值,如果相等返回 True,不相等返回 Falserights = pred.eq(labels.data.view_as(pred)).sum() # 统计预测正确的样本数'''pred.eq(labels.data.view_as(pred)):pred 是模型预测的类别(索引形式)。
labels.data.view_as(pred) 将标签(真实类别)转换为与 pred 相同的形状(通常是一个一维向量),这样就可以逐元素比较。
eq() 是 torch 中的一个方法,用于比较两个张量的元素,返回一个布尔张量,元素相等则返回 True,否则返回 False。'''# 返回正确的数量以及总样本数return rights, len(labels)
torch.max(input, dim):
- 输入:一个张量
input,以及一个维度dim。- 输出:返回一个元组 (values, indices):
values:沿着dim维度的最大值。indices:最大值对应的索引。
torch.max(outputs.data, 1)与torch.max(outputs.data, 0)
如果
outputs的形状是[784, 10],这意味着你有 784 个样本,每个样本对应 10 个类的输出(比如 logits 或预测值)。在这种情况下,torch.max(outputs.data, 1)和torch.max(outputs.data, 0)的结果含义会有所不同,具体如下:1.
torch.max(outputs.data, 1)
维度:
dim=1操作:沿着第二维(每个样本的类别)查找最大值。
输出:
- 返回一个张量,其中包含每个样本的最大值(即 logits 的最高值),以及一个索引张量,表示该最大值对应的类别。
- 输出形状为
[784]和[784](索引),表示每个样本的预测类别。示例:
import torch# 假设 outputs 是 [784, 10] 的张量 outputs = torch.randn(784, 10) # 随机生成示例输出max_values, predicted = torch.max(outputs.data, 1) # 查找每个样本的最大值及其对应的索引。outputs.data[i][0]---outputs.data[i][9] print(predicted) # 输出:每个样本的预测类别(索引)2.
torch.max(outputs.data, 0)
维度:
dim=0操作:沿着第一维(所有样本)查找每个类别的最大值。
输出:
- 返回一个张量,包含每个类别在所有样本中的最大值,以及对应的索引。
- 输出形状为
[10](最大值)和[784](索引),表示每个类别在 784 个样本中的最大值。示例:
import torch# 假设 outputs 是 [784, 10] 的张量 outputs = torch.randn(784, 10) # 随机生成示例输出max_values, indices = torch.max(outputs.data, 0) # 查找每个类别的最大值及其对应的样本索引 print(max_values) # 输出:每个类别的最大值 print(indices) # 输出:每个最大值对应的样本索引总结
操作 维度 输出形状 作用 torch.max(outputs, 1)1 [784](最大值),[784](索引)返回每个样本的最大值及对应的类索引(预测类别) torch.max(outputs, 0)0 [10](最大值),[784](索引)返回每个类别在所有样本中的最大值及对应的样本索引 因此,当
outputs的形状是[784, 10]时,选择torch.max(outputs.data, 1)可以用来获取每个样本的预测类别,而torch.max(outputs.data, 0)可以用来分析每个类别在样本中的最大预测值。
2、Dropout
关于 Dropout(0.5) 的理解,我们来详细说明一下它的工作原理。
Dropout 的工作原理
-
定义:
Dropout(0.5)表示在每次前向传播中,每个神经元有 50% 的概率被“丢弃”。这意味着有 50% 的神经元在当前迭代中不会参与计算,输出值被设置为 0。
-
示例:
- 假设你的输入张量形状为
[64, 784],这里64是批量大小,784是每个样本的特征数(例如,一个 28x28 的图像展平后得到的特征向量)。 - 在前向传播中,Dropout 会随机选择 50% 的神经元进行丢弃。重要的是,这并不意味着只会有 32 个神经元参与计算,而是对于每个样本(每一行),可能有一部分神经元会被丢弃。
- 假设你的输入张量形状为
具体过程
-
对于输入的每个样本(每一行),Dropout 会独立地选择哪些神经元被丢弃。例如,假设我们有以下输入:
Input (x): [64, 784] (64 个样本,每个样本 784 个特征) -
==在每次前向传播时,Dropout 会随机将某些特征(神经元)设置为 0。==比如说,某次前向传播可能会得到如下的输出:
Output (x'): [64, 784] (仍然是 64 个样本,但某些特征被置为 0)Sample 1: [0.5, 0, 0.2, 0, 0.8, ...] # 一些神经元被丢弃 Sample 2: [0, 0.3, 0, 0.9, 0.7, ...] # 不同的丢弃情况
关键点
- 样本数量不变:输入张量的形状
[64, 784]在经过 Dropout 后仍然是[64, 784],而不是[32, 784]。每个样本都有 784 个特征(神经元)。 - 随机性:每次前向传播时丢弃的神经元都是随机的,不同的迭代可能会丢弃不同的神经元。
- 训练与推理:在训练时使用 Dropout,而在推理(测试)时,所有神经元都被使用,通常输出会根据 Dropout 的比例进行缩放(乘以保留的概率)。
总结
- Dropout 会随机丢弃一些神经元的输出,但并不改变输入的样本数量和形状。输入
[64, 784]经过 Dropout 处理后,仍然是[64, 784],只是某些神经元的输出被置为 0。
2、常用模块
这些包在 Python 中有各自的作用,通常用于处理图像、文件操作和时间管理等。下面我逐一解释这些包的功能及其典型用途。
1. imageio
-
作用:
imageio是一个用于读取和写入图像、视频、动图等多媒体文件的库。- 它支持多种图像格式,如 PNG、JPEG、GIF、TIFF,以及视频格式,如 MP4、AVI 等。
- 常用于读取图片或视频帧、保存图片、生成 GIF 等。
-
常用方法:
imageio.imread():读取图像文件。imageio.imwrite():保存图像文件。imageio.mimwrite():保存多张图像作为 GIF 动图。imageio.get_reader()和imageio.get_writer():用于读取或写入视频。
-
示例:
import imageio img = imageio.imread('image.png') # 读取图片 imageio.imwrite('new_image.png', img) # 保存图片
2. time
-
作用:
time是 Python 的标准库,用于处理时间相关的任务。- 它可以获取当前时间、暂停程序执行、格式化时间、计算时间差等。
-
常用方法:
time.time():返回当前时间的时间戳(从 1970 年 1 月 1 日以来的秒数)。time.sleep(seconds):暂停程序执行指定的秒数。time.localtime():将时间戳转换为结构化时间。time.strftime():格式化时间为字符串。
-
示例:
import time print(time.time()) # 输出当前时间的时间戳 time.sleep(2) # 暂停程序执行 2 秒
3. copy
-
作用:
copy是 Python 的标准库,提供了对象的浅复制和深复制功能。- 浅复制 只复制对象的引用,某些情况下修改副本会影响原对象。
- 深复制 递归复制对象中的所有内容,副本与原对象完全独立。
-
常用方法:
copy.copy():执行浅复制。copy.deepcopy():执行深复制。
-
示例:
import copy original = [1, 2, [3, 4]] shallow_copy = copy.copy(original) # 浅复制 deep_copy = copy.deepcopy(original) # 深复制
4. PIL.Image(Pillow)
-
作用:
PIL(Python Imaging Library)是一个强大的图像处理库,后来被分支为Pillow,用于处理图像文件的读取、操作和保存。- 它支持多种图像格式(如 JPEG、PNG、BMP 等),并提供丰富的图像操作功能,如裁剪、缩放、旋转、滤镜处理等。
-
常用方法:
Image.open():打开图像文件。Image.save():保存图像文件。Image.resize():调整图像大小。Image.rotate():旋转图像。Image.convert():转换图像模式(如 RGB、灰度等)。
-
示例:
from PIL import Image img = Image.open('image.jpg') # 打开图片 img = img.resize((100, 100)) # 调整图片大小 img.save('resized_image.jpg') # 保存图片
总结
imageio:用于读取和保存多媒体文件(图像、视频、GIF等)。time:用于时间处理,如暂停、获取当前时间等。copy:用于对象的浅复制和深复制。PIL.Image:图像处理库,支持多种图像操作(读取、保存、裁剪、旋转等)。
这些库在图像处理、时间控制和数据复制中被广泛使用,通常会用于一些涉及图片、视频的应用中,如机器学习的预处理、生成 GIF、视频分析等。
3、datasets.ImageFolder
当你使用 torchvision.datasets.ImageFolder 给定一个 root 目录时,root 是一个包含子文件夹的主目录。ImageFolder 并不会直接加载 root 目录下的所有图片,而是会查找 root 目录下每个子文件夹,并将这些子文件夹中的图片归类到对应的类别。
具体行为如下:
-
子文件夹代表类别:
ImageFolder会将root目录下的每一个子文件夹的名称作为类别标签。每个子文件夹内部的所有图片都被视为属于该类别。例如,假设你的
root目录结构如下:root/├── cat/│ ├── image1.jpg│ ├── image2.jpg└── dog/├── image1.jpg├── image2.jpg- 在这种情况下,
cat文件夹中的图片会被分配标签0,dog文件夹中的图片会被分配标签1。 - 图片路径
root/cat/image1.jpg会被标记为类别0,而root/dog/image1.jpg会被标记为类别1。
- 在这种情况下,
-
图片的加载顺序:
ImageFolder会递归地遍历每个类别文件夹下的所有图片,并按文件路径的顺序加载它们。 -
文件类型:
ImageFolder只会加载文件扩展名符合常见图片格式的文件(如.jpg,.png,.bmp等)。
因此,ImageFolder 只加载 root 目录中的子文件夹内的图片,而不会直接加载 root 目录中的图片(如果 root 目录本身包含图片,这些图片将会被忽略)。
举个例子
假设 root 目录为 data/train/,结构如下:
data/train/├── class1/│ ├── img1.jpg│ ├── img2.jpg├── class2/│ ├── img3.jpg│ ├── img4.jpg
使用 ImageFolder 加载该数据集:
from torchvision import datasets, transforms# 定义图像预处理
transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor()
])# 加载数据集
dataset = datasets.ImageFolder(root='data/train/', transform=transform)# 输出类别和样本数
print(f'类别:{dataset.class_to_idx}') # 类别标签映射 {'class1': 0, 'class2': 1}
print(f'数据集大小:{len(dataset)}') # 数据集大小,应该是4张图片
总结:
ImageFolder会遍历root目录下的每个子文件夹,并将子文件夹中的图片分配到对应的类别。- 如果
root目录下有图片但没有子文件夹,这些图片将会被忽略。
4、数据集
batch_size = 128image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'valid']} #同时读入了数据和标签
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True) for x in ['train', 'valid']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'valid']}
class_names = image_datasets['train'].classes #标签名
这两行代码:
image, label = image_datasets['train'][0] #train的第一张图片
print(image_datasets['train'])
print(image.shape,label)
print(image[0]) #这是图像的第一个通道(通常是 RGB 图像的红色通道)
Dataset ImageFolderNumber of datapoints: 6552Root location: ./data/flower_data/trainStandardTransform
Transform: Compose(Resize(size=[96, 96], interpolation=bilinear, max_size=None, antialias=True)RandomRotation(degrees=[-45.0, 45.0], interpolation=nearest, expand=False, fill=0)CenterCrop(size=(64, 64))RandomHorizontalFlip(p=0.5)RandomVerticalFlip(p=0.5)ColorJitter(brightness=(0.8, 1.2), contrast=(0.9, 1.1), saturation=(0.9, 1.1), hue=(-0.1, 0.1))RandomGrayscale(p=0.025)ToTensor()Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]))
torch.Size([3, 64, 64]) 0
tensor([[-0.1828, -0.2342, -0.2856, ..., -1.6213, -1.6213, -1.7069],[-0.1999, -0.2856, -0.3198, ..., -1.5357, -1.6213, -1.7069],[-0.2856, -0.3541, -0.4226, ..., -1.5014, -1.6213, -1.6898],...,[-1.2959, -1.3130, -1.3815, ..., -1.1075, -1.1418, -0.8849],[-1.2959, -1.3302, -1.4158, ..., -1.0219, -1.0904, -0.7308],[-1.2959, -1.3473, -1.4500, ..., -0.9877, -1.0733, -0.6623]])
#print(image_datasets['train'][0].shape)
print(image_datasets['train'][0][0][0].shape) #训练集第一个文件夹的第一张图片的B通道有负数,因为被标准化了 #训练集第一个文件夹的第一张图片的B通道有负数,因为被标准化了
print(image_datasets['train'][0][0][0])
torch.Size([64, 64])
tensor([[-1.7925, -1.8097, -1.7925, ..., -0.9877, -1.0733, -1.1075],[-1.7754, -1.7754, -1.8268, ..., -0.9705, -1.0733, -1.1932],[-1.7412, -1.7754, -1.8097, ..., -1.0390, -1.1589, -1.2274],...,[ 0.3309, 0.4166, 0.4679, ..., -1.8953, -1.9124, -1.9124],[ 0.3823, 0.4679, 0.4337, ..., -1.8782, -1.8953, -1.8953],[ 0.5364, 0.4679, 0.5022, ..., -1.8268, -1.8782, -1.8953]]
-
image_datasets['train'][0]返回一个元组(image, label),其中:image是经过数据变换后的图像张量。label是对应的标签(类别)。
这里,
image是一个三维张量(C, H, W),即通道、高度、宽度,label是一个整数,表示图像的类别。
image, label = image_datasets['train'][0]
这一行将元组解包为 image 和 label,分别表示图片张量和标签。然后你打印 image[0],即图像张量的第一个通道,以及标签。
在 Python 中,解包(unpacking) 指的是将一个包含多个元素的容器(如元组、列表等)中的各个元素分别赋值给多个变量。解包可以让你快速地从容器中提取元素,方便后续操作。
元组解包
假设你有一个包含两个元素的元组:
tup = (10, 20)现在,你可以使用解包将
tup中的两个元素分别赋值给变量a和b:a, b = tup print(a) # 输出 10 print(b) # 输出 20在这里,
a被赋值为元组中的第一个元素(10),b被赋值为第二个元素(20)。这种方式被称为解包。代码中的解包
在你的代码中:
image, label = image_datasets['train'][0]
image_datasets['train'][0]返回的其实是一个包含两个元素的元组(image, label):
image是图像张量。label是图像对应的标签(类别)。通过解包,
image和label分别被赋值为元组中的第一个和第二个元素。相当于以下代码:
# 没有解包的情况下: tup = image_datasets['train'][0] # tup 是一个元组 (image, label) image = tup[0] # 获取第一个元素(图像) label = tup[1] # 获取第二个元素(标签)但是,通过解包,你可以直接用
image, label = image_datasets['train'][0]一步完成,而不需要额外的tup[0]和tup[1]访问操作,简化了代码。总结
解包 就是从元组(或其他容器)中将每个元素分别赋值给多个变量。例如,你可以从
image_datasets['train'][0]返回的元组中提取出图像张量image和对应的标签label,简化后续代码的处理。
5、优化器&加载保存模型
1. optimizer.param_groups
optimizer.param_groups 是 PyTorch 中优化器的一个属性,表示优化器管理的参数组。每个参数组是一个字典,包含与优化相关的信息,比如模型的参数(权重)、学习率等。
常见内容:
- params: 这是模型中要更新的参数列表(张量),通常是模型的权重和偏置。
- lr: 学习率,用于控制梯度下降时的步长。
- momentum: 动量参数,适用于带动量的优化算法(如 SGD)。
- weight_decay: 权重衰减(L2正则化)系数。
- dampening: 动量的抑制因子。
- nesterov: 是否使用 Nesterov 动量。
示例:
# 打印所有参数组信息
for param_group in optimizer.param_groups:print(param_group)
示例输出(一个带有动量的 SGD 优化器):
{'params': [tensor1, tensor2, ...], 'lr': 0.001, 'momentum': 0.9, 'weight_decay': 0.01, 'nesterov': True}
- 这里
params存储模型中的参数(如权重和偏置),其他则是用于调整这些参数的超参数。
2. model.state_dict()
model.state_dict() 是 PyTorch 中一个非常重要的函数,用于获取模型的参数和持久性状态,并以字典形式返回。这个字典的键是模型中各层的名称,值是这些层对应的张量(即权重和偏置)。
常见用途:
- 保存模型参数:可以通过
state_dict()来保存模型的所有参数,通常保存为.pt文件。 - 加载模型参数:通过加载保存的
state_dict()来恢复模型的参数。
示例:
# 打印模型的 state_dict
for param_tensor in model.state_dict():print(param_tensor, "\t", model.state_dict()[param_tensor].size())
示例输出:
fc.weight torch.Size([10, 512])
fc.bias torch.Size([10])
conv1.weight torch.Size([64, 3, 7, 7])
conv1.bias torch.Size([64])
- 输出中,
fc.weight和fc.bias是全连接层的权重和偏置,conv1.weight和conv1.bias是卷积层的权重和偏置。
常用操作:
-
保存模型参数:
torch.save(model.state_dict(), 'model_weights.pth') -
加载模型参数:
model.load_state_dict(torch.load('model_weights.pth'))
总结:
optimizer.param_groups:包含优化器参数和超参数(如学习率、动量等),帮助控制模型权重的更新过程。model.state_dict():保存或加载模型的所有参数(权重、偏置等),通常用于模型的持久化和恢复。
相关文章:

深度学习代码学习笔记2
1、torch.max correct 0 total 0 for xb,yb in valid_dl:outputs model(xb)_,predicted torch.max(outputs.data,1)total yb.size(0) #yb.size(0) 返回的是张量 yb 在第 0 维的大小,也就是 yb 中的样本数量。correct (predicted yb).sum().item() print(…...

016集——c# 实现CAD类库 与窗体的交互(CAD—C#二次开发入门)
第一步:搭建CAD类库dll开发环境。 第二步:添加窗体 第三步:添加控件 第四步:双击控件,在控件点击方法内输入代码 第五步:在主程序内实例化新建的form类,并弹窗form窗体 第六步:CAD命…...

【亲测可行】最新ubuntu搭建rknn-toolkit2
文章目录 🌕结构图(ONNX->RKNN)🌕下载rknn-toolkit2🌕搭建环境🌙配置镜像源🌙conda搭建python3.8版本的虚拟环境🌙进入packages目录安装依赖库🌕测试安装是否成功🌕其它🌙rknn-toolkit2🌙rknn_model_zoo🌙关于部署的博客发布本文的时间为2024.10.13…...
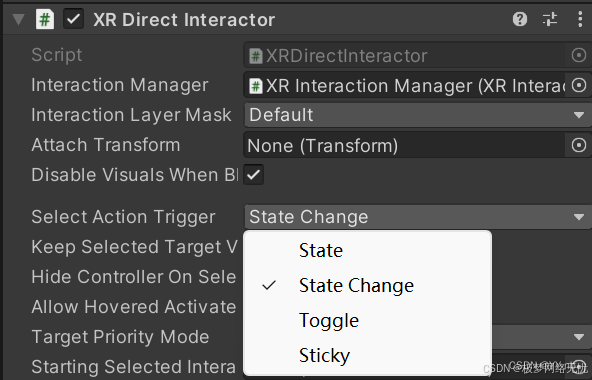
pico+Unity交互开发——触碰抓取
一、VR交互的类型 Hover(悬停) 定义:发起交互的对象停留在可交互对象的交互区域。例如,当手触摸到物品表面(可交互区域)时,视为触发了Hover。 Grab(抓取) 概念ÿ…...

16年408计算机网络
第一题: 解析: 首先我们要清楚R1,R2,R3是路由器(网络层),Switch是以太网交换机(数据链路层),Hub是集线器(物理层)。 由此可见路由器实现的最高功能层是3层&am…...
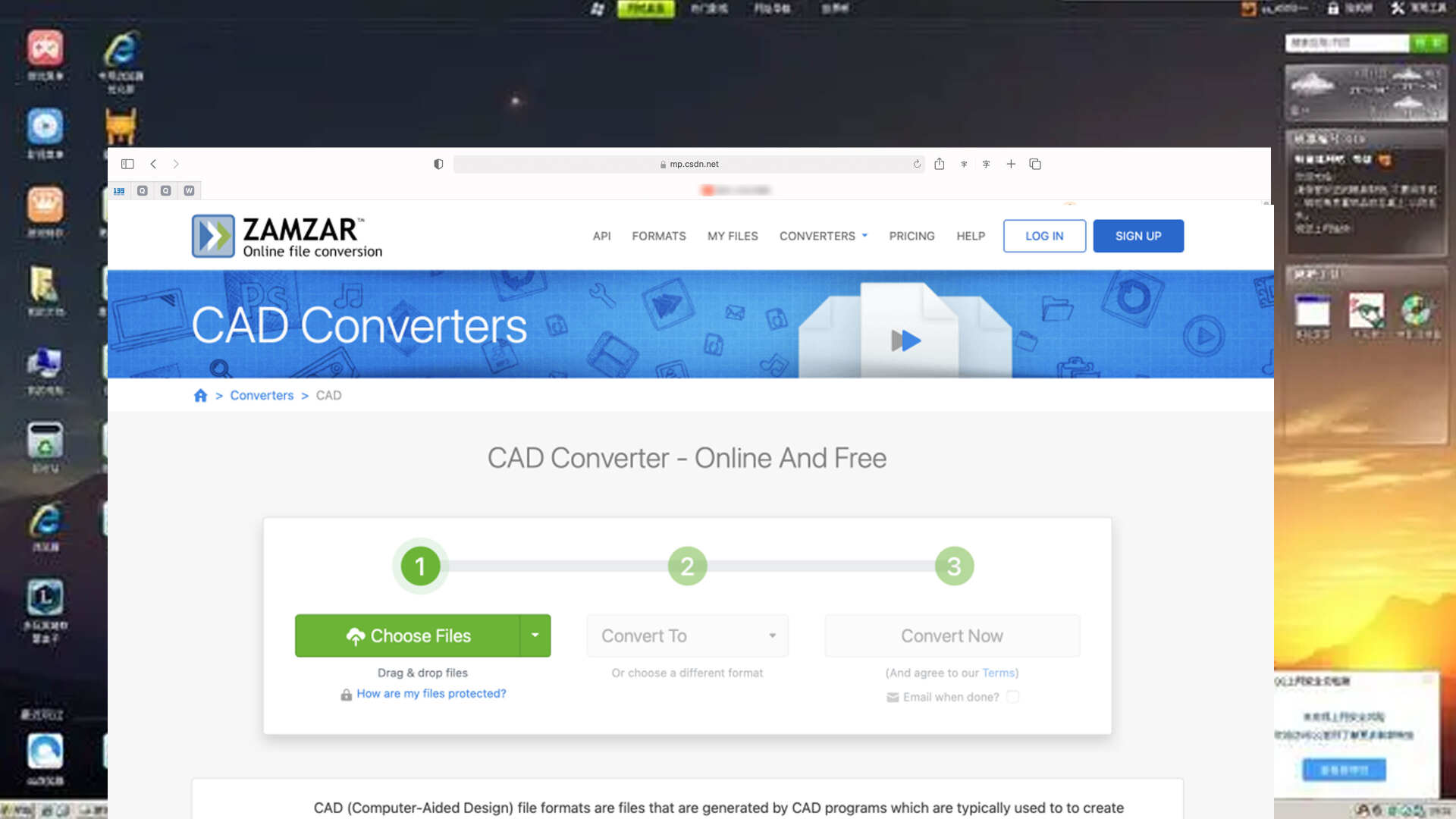
PDF 转 CAD 工具:实现文档格式高效转换的利器
如果你从事设计相关PDF和CAD作为两种常见且重要的文件格式,在不同的领域都有着广泛的应用。今天,我们就来介绍几个各具特色的PDF转换成CAD工具。 1.福昕PDF转换大师 链接一下>>https://www.pdf365.cn/pdf2word/ 该工具在跨领域应用中表现出明确…...

基于springboot的画师约稿系统的设计与实现
文章目录 项目介绍主要功能截图:部分代码展示设计总结项目获取方式🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项目介绍 基于springboot的画师约稿系统的设计与实…...

使用Python生成SVG图片
SVG(可缩放矢量图形)是一种基于XML的图像格式,它可以无损缩放且文件大小较小。在本文中,我们将探讨如何使用Python生成SVG图片。 为什么选择SVG? 可缩放:SVG图像可以无限放大而不失真。文件小:SVG文件通常比位图文件小。可编辑:SVG文件可以通过文本编辑器修改。 使用Python…...

hackmyvm-Hundred靶机
主机发现 sudo arp-scan -l 以sudo权限执行arp-scan -l 扫描并列出本地存在的机器,发现靶机ip为192.168.91.153 nmap扫描 端口发现 21/tcp open ftp 22/tcp open ssh 80/tcp open http web信息收集 我们先尝试一下ftp端口的匿名登录 FTP:是文件传输协议的端…...

多场景多任务建模(三): M2M(Multi-Scenario Multi-Task Meta Learning)
多场景建模: STAR(Star Topology Adaptive Recommender) 多场景建模(二): SAR-Net(Scenario-Aware Ranking Network) 前面两篇文章,讲述了关于多场景的建模方案,其中可以看到很多关于多任务学习的影子&…...

Day31 || 122.买卖股票的最佳时机 II、55. 跳跃游戏、 45.跳跃游戏II 、1005.K次取反后最大化的数组和
122.买卖股票的最佳时机 II 题目链接:力扣题目链接 思路:因为是求虽大利润完全可以假设知道第二天涨前一天买入即可,就是求两天只差大于0 的和。 55. 跳跃游戏 题目链接:力扣题目链接 思路:应该从后往前循环判断&…...

【uniapp】打包成H5并发布
目录 1、设置配置mainifest.sjon 1.1 页面标题 1.2 路由模式 1.3 运行的基础路径 2、打包 2.1 打包入口 2.2 打包成功 2.3 依据目录找到web目录 3、 将web目录整体拷贝出来 4、上传 4.1 登录uniapp官网注册免费空间 4.2 上传拷贝的目录 4.3 检查上传是否正确 5、…...

Position Embedding总结和Pytorch实现
文章目录 出现背景PE位置编码公式思路code 出现背景 自注意力机制处理数据,并不是采用类似RNN或者LSTM那种递归的结构,这使得模型虽然能够同时查看输入序列中的所有元素(即并行运算),但是也导致了没办法获取当前word在…...
【AIF-C01认证】亚马逊云科技生成式 AI 认证正式上线啦
文章目录 一、AIF-C01简介二、考试概览三、考试知识点3.1 AI 和 ML 基础知识3.2 生成式人工智能基础3.3 基础模型的应用3.4 负责任 AI 准则3.5 AI 解决方案的安全性、合规性和监管 四、备考课程4.1 「备考训练营」 在线直播课4.2 「SkillBuilder」学习课程 五、常见问题六、参考…...

C++ 素数的筛选法与穷举法
题目:素数大酬宾: 【问题描述】 某商场的仓库中有 n 种商品,每件商品按 1~n 依次编号。现在商场经理突发奇想,决定将编号为素数(质数)的所有商品拿出来搞优惠酬宾活动。请编程帮助仓库管理员将编号为素数的商品选出来…...

Spring Boot异步任务、任务调度与异步请求线程池的使用及原理
Spring Boot异步任务、任务调度与异步请求线程池的使用及原理 在Spring Boot应用程序中,异步任务、任务调度和异步请求线程池是提高系统性能和响应速度的重要工具。本文将详细讲解这些概念的使用及原理。 一、异步任务 异步任务是指可以在后台线程上执行的任务&a…...

Java爬虫之使用Selenium WebDriver 爬取数据
这里写自定义目录标题 Selenium WebDriver简介一、安装部署二、Java项目中使用1.引入依赖2.示例代码 三、WebDriver使用说明1.WebDriver定位器2.常用操作3.使用 cookie4.键盘与鼠标操作 Selenium WebDriver简介 Selenium WebDriver 是一种用于自动化测试 Web 应用程序的工具。…...

MyBatis 中updateByPrimaryKey和updateByPrimaryKeySelective区别
在 MyBatis 中,updateByPrimaryKey和updateByPrimaryKeySelective主要有以下区别: 一、功能 updateByPrimaryKey: 会根据传入的实体对象,将数据库表中对应主键的记录所有字段全部更新为实体对象中的值。即使实体对象中的某些字段…...

JavaScript下载文件(简单模式、跨域问题、文件压缩)
文章目录 简介简单文件下载通过模拟form表单提交通过XMLHttpRequest方式 跨域(oss)下载并压缩文件完整示例文件压缩跨域设置 简介 相信各位开发朋友都遇到过下载的文件的需求,有的非常简单,基本链接的形式就可以。 有的就比较复杂,涉及跨域…...

Django 定义使用模型,并添加数据
教材: Python web企业级项目开发教程(黑马程序员)第三章 模型 实验步骤: 1.创建项目和应用 前置步骤可看前文,进入到指定文件位置后创建 django-admin startproject mysite python manage.py startapp app01 2.注册…...

Visual Studio 项目属性页开发完全教程:从基础到高级
Visual Studio 项目属性页开发完全教程:从基础到高级 【免费下载链接】project-system The .NET Project System for Visual Studio 项目地址: https://gitcode.com/gh_mirrors/pr/project-system Visual Studio 项目属性页是开发者管理项目配置的核心界面&a…...

Stitches API完全指南:从基础配置到自定义扩展
Stitches API完全指南:从基础配置到自定义扩展 【免费下载链接】stitches HTML5 Sprite Sheet Generator 项目地址: https://gitcode.com/gh_mirrors/sti/stitches Stitches是一款强大的HTML5 Sprite Sheet Generator,它提供了直观的API接口&…...

30岁裸辞后,我用两个月拿下AI应用认证,现在OFFER选择困难症犯了
30岁裸辞那天,我最怕的不是没收入,而是突然发现:过去积累的经验,正在被AI重新定价。以前会写方案、做表格、跟项目,算是职场硬通货;到了2026年,招聘JD里开始频繁出现AI工具应用、智能工作流、Pr…...

利用DiSEqC协议与AVR单片机驱动卫星天线电机改造户外设备
1. 项目概述:用卫星天线电机驱动一切如果你手头有一些需要承受风吹日晒、还得精确转动的设备,比如一个户外的大型定向天线,或者一个需要定期调整角度的太阳能板支架,甚至是一个坚固的监控云台,你可能会为驱动机构发愁。…...

BLE蓝牙扫描深度剖析:扫描原理、核心参数、前后台差异
一、前言BLE设备交互分为两大角色:广播端(外设Peripheral)与扫描端(中心Central)。上一篇博客详解了四大广播模式,本文聚焦配套核心能力——BLE扫描机制。绝大多数蓝牙开发疑难问题:前台能扫后台…...

告别手写UI!用NXP GUI Guider拖拽设计LVGL界面,5分钟搞定音乐播放器Demo
嵌入式UI开发革命:5分钟用GUI Guider构建LVGL音乐播放器在嵌入式系统开发中,用户界面(UI)设计曾长期是工程师的痛点——既要考虑资源受限的硬件环境,又要实现流畅美观的交互体验。传统手动编写UI代码的方式不仅效率低下,调试过程更…...

写论文的神助攻!好用的AI写作辅助软件,逻辑清晰质量高
作为一名刚完成毕业论文的过来人,我太懂写论文的痛苦了 —— 选题迷茫、文献浩如烟海、框架混乱、逻辑不清、反复修改、查重降重反复折腾... 直到我发现了这套 AI 写作工具组合,简直是论文写作的 "开挂神器",效率直接拉满ÿ…...

SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能
SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...

账务台账数据
银行里说的 “账务台账数据”,本质就是按会计规则把每笔业务逐笔、分户、分科目记下来的完整明细流水 余额 辅助信息,核心是 “可逐笔追溯、可对账、可审计” 的一套明细数据。下面用通俗、具体的方式拆开说:一、银行 “账务台账” 到底是什…...

差分隐私GDP机制紧密度量化:从隐私剖面到∆度量的实践指南
1. 差分隐私GDP机制:从理论到实践,如何量化隐私保护紧密度在差分隐私(Differential Privacy, DP)的实际部署中,尤其是在机器学习的隐私保护训练(如DP-SGD)场景里,我们常常面临一个核…...