【分布式知识】MapReduce详细介绍
文章目录
- MapReduce概述
- 1. MapReduce编程模型
- Map阶段
- Reduce阶段
- 2. Shuffle和Sort阶段
- 3. MapReduce作业的执行流程
- 4. MapReduce的优化和特性
- 5. MapReduce的配置和调优
- MapReduce局限性
- 相关文献
MapReduce概述
MapReduce是一个分布式计算框架,它允许用户编写可以在大规模集群上并行处理大数据集的应用程序。MapReduce模型由两个主要的函数组成:Map和Reduce,它们分别对应数据处理的两个阶段。以下是MapReduce的详细说明:

1. MapReduce编程模型
Map阶段
- 输入:Map阶段的输入通常是一组键值对(key-value pairs)。
- 处理:用户编写的Map函数对输入数据进行处理。Map函数读取输入的键值对,执行业务逻辑,然后输出中间键值对。
- 输出:Map函数的输出是一组中间键值对,这些输出将作为Reduce函数的输入。
Reduce阶段
- 输入:Reduce阶段的输入是Map阶段输出的所有中间键值对。
- 处理:用户编写的Reduce函数对具有相同键的所有中间值进行处理。Reduce函数接收一个键和一组值,执行业务逻辑,然后输出最终结果。
- 输出:Reduce函数的输出是一组最终的键值对,这些结果通常被写入到分布式文件系统(如HDFS)中。
2. Shuffle和Sort阶段
在Map和Reduce阶段之间,MapReduce框架自动执行Shuffle和Sort操作,这个过程对用户是透明的。
- Shuffle:这个过程涉及将Map输出的数据传输到Reduce任务。Shuffle确保每个Reduce任务接收到所有属于其处理的键值对。
- Sort:在数据传输给Reduce任务之前,MapReduce框架会对每个Reduce任务的数据进行排序,确保具有相同键的值被分组在一起。
3. MapReduce作业的执行流程
- 作业提交:用户提交一个MapReduce作业到集群。
- 任务调度:作业被分割成多个Map任务和Reduce任务,由集群的资源管理器进行调度。
- Map任务执行:每个Map任务处理输入数据的一个分片,生成中间键值对。
- Shuffle和Sort:Map任务的输出被Shuffle和Sort,为Reduce任务准备数据。
- Reduce任务执行:Reduce任务处理排序后的中间数据,生成最终结果。
- 输出结果:Reduce任务的输出被写入到分布式文件系统或其它存储系统中。
4. MapReduce的优化和特性
- 数据局部性:MapReduce尝试将计算移动到数据所在的位置,以减少网络传输。
- 容错性:MapReduce框架能够处理节点故障,通过重新执行失败的任务来确保作业的完成。
- 扩展性:MapReduce设计用于在成百上千的节点上运行,能够处理PB级别的数据集。
- 高吞吐量:通过并行处理和优化的数据传输,MapReduce可以实现高吞吐量的数据加工。
5. MapReduce的配置和调优
- 分区(Partitioning):用户可以通过实现自定义分区器来控制数据如何分配给不同的Reduce任务。
- 合并(Combining):在Map阶段,用户可以定义一个Combiner函数来减少网络传输的数据量。
- 资源管理:用户可以配置Map和Reduce任务的内存使用量,以及其他资源需求。
MapReduce是一个强大的工具,但它也有一些局限性,比如不适合实时数据处理,以及对于复杂的数据处理流程可能不够灵活。因此,许多新的框架和工具(如Apache Spark)被开发出来,以提供更丰富的数据处理能力。尽管如此,MapReduce仍然是大数据处理领域的一个基础概念,并且它的许多原则和模式在新的技术中得到了延续。
MapReduce局限性
MapReduce是一种编程模型和处理框架,用于在大规模集群上并行处理大数据集。尽管MapReduce在大数据处理领域有着广泛的应用,但它也存在一些局限性:
-
实时计算性能差:MapReduce主要适用于离线数据处理,不适合需要实时或近实时处理的场景。它无法像传统的数据库系统那样在毫秒或秒级别内返回结果。
-
不适合流式计算:流式计算要求数据是动态的,而MapReduce设计上是针对静态数据集的。因此,MapReduce不适合处理持续不断流入的数据。
-
高延迟:MapReduce的数据处理流程通常涉及多个阶段,包括Map、Shuffle和Reduce,这导致整个处理过程的延迟较高,不适合需要快速响应的交互式应用。
-
磁盘I/O开销大:在MapReduce中,中间结果需要写入磁盘,这可能导致大量的I/O操作,成为性能瓶颈。
-
不适合复杂计算:MapReduce框架主要提供Map和Reduce两种操作,对于复杂的计算任务,可能需要多个MapReduce作业串行运行,这增加了开发和维护的复杂性。
-
资源利用率低:MapReduce作业通常需要等待所有Map任务完成后,Reduce任务才能开始,这种模式可能导致资源利用率不高,特别是在数据倾斜或某些任务执行时间较长时。
-
内存使用不足:MapReduce主要依赖磁盘存储,而不是内存。这限制了处理速度,因为磁盘I/O远慢于内存访问。相比之下,新的框架如Spark利用内存计算,大大提高了处理速度。
-
容错机制:虽然MapReduce具有容错性,但它的处理方式可能在节点故障时导致较高的计算成本,尤其是在需要重新计算失败任务时。
-
过于底层:MapReduce提供的抽象层次较低,对于非技术人员或数据分析师来说,编写MapReduce程序可能较为困难,不如SQL等更高级的抽象易于使用。
-
不适合迭代计算:某些算法,如机器学习的模型训练,需要状态共享或参数间有依赖,MapReduce不适合这类需要迭代处理的计算任务。
由于这些局限性,MapReduce可能不适用于所有类型的数据处理任务,特别是那些需要低延迟、高吞吐量、复杂计算或实时处理的场景。因此,许多新的框架和工具,如Apache Spark,被开发出来以提供更灵活、更高效的大数据处理能力。
相关文献
【大数据】一文教你看懂什么是Hadoop
相关文章:
【分布式知识】MapReduce详细介绍
文章目录 MapReduce概述1. MapReduce编程模型Map阶段Reduce阶段 2. Shuffle和Sort阶段3. MapReduce作业的执行流程4. MapReduce的优化和特性5. MapReduce的配置和调优 MapReduce局限性相关文献 MapReduce概述 MapReduce是一个分布式计算框架,它允许用户编写可以在大…...

JAVA八股
快速失败(fail-fast) 设计的目的是为了避免在遍历时对集合进行并发修改,从而引发潜在的不可预料的错误。 通过迭代器遍历集合时修改集合: 如果你使用Iterator遍历集合,然后直接使用集合的修改方法(如add(…...

关于武汉芯景科技有限公司的限流开关芯片XJ6288开发指南(兼容SY6288)
一、芯片引脚介绍 1.芯片引脚 二、系统结构图 三、功能描述 1.EN引脚控制IN和OUT引脚的通断 2.OCB引脚指示状态 3.过流自动断开...
)
指令:计算机的语言(五)
2.9 人机交互 ASCII与二进制 对应表略 字节转移指令 lbu:加载无符号字节,从内存中加载1个字节,放在寄存器最右边8位。 sb:存储字节指令,从寄存器的最右边取1个字节并将其写入内存。 复制1个字节顺序如下…...
)
C#笔记(1)
解决方案: 【1】组织项目:把项目放在放在一个解决方案中,统一开发,统一编译。 【2】管理项目:开发中的任何问题,在统一编译过程中,都能随时发现。也可以添加第三方的库文件。 命名空间: 命名空…...
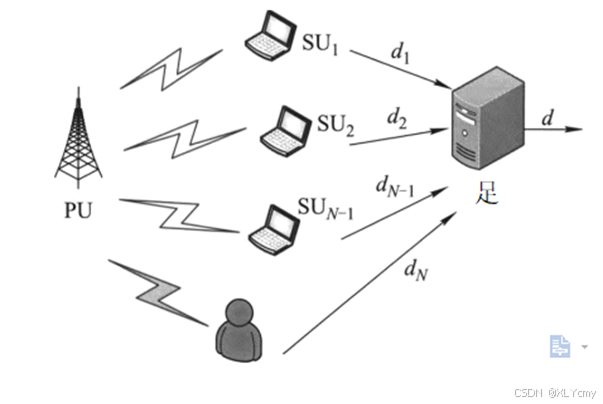
SSDF攻击、防御与展望
摘要: 随着无线通信业务的不断发展,频域也越来越成为了一种珍贵的稀缺资源,与此同时,相应的无线电安全问题层出不穷,为无线通信造成了十分恶劣的影响,本文从深入理解认知无线电安全开始,对一些典…...
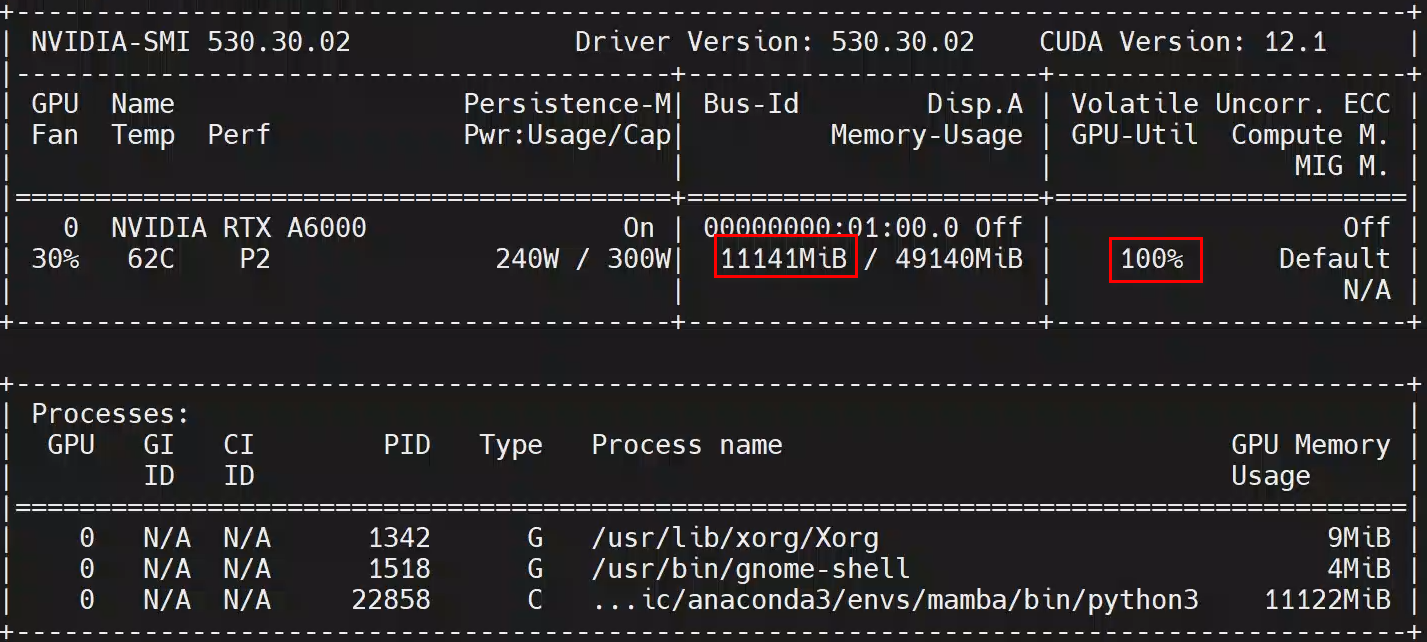
MedMamba代码解释及用于糖尿病视网膜病变分类
MedMamba原理和用于糖尿病视网膜病变检测尝试 1.MedMamba原理 MedMamba发表于2024.9.28,是构建在Vision Mamba基础之上,融合了卷积神经网的架构,结构如下图: 原理简述就是图片输入后按通道输入后切分为两部分,一部分走…...

单点登录的要点
单点登录(SSO)是一种身份验证服务,它允许用户使用一组凭据登录一次,然后在多个应用程序中访问其他应用程序而无需重新进行身份验证。这样,用户只需一次登录即可访问整个应用生态系统,提高了用户体验并简化了…...

linux线程 | 一点通你的互斥锁 | 同步与互斥
前言:本篇文章主要讲述linux线程的互斥的知识。 讲解流程为先讲解锁的工作原理, 再自己封装一下锁并且使用一下。 做完这些就要输出一堆理论性的东西, 但博主会总结两条结论!!最后就是讲一下死锁。 那么, 废…...

全栈开发小项目
用到的技术栈: nodejswebpackknockoutmongodbPM2rabbitmq 以下是一个综合指南,展示如何将 Node.js、Webpack、Knockout.js、MongoDB、PM2 和 RabbitMQ 集成到一个项目中。 我们将在这一项目中添加 RabbitMQ,用于处理消息队列。这对于任务分…...

批处理一键创建扫描仪桌面打开快捷方式图标 简单直接有效 扫描文档图片的应急策略
办公生活中,我们在安装完多功能一体机的打印驱动之后,找不到扫描文件的地方,如果驱动程序安装正确,我们可以用系统自带的扫描仪程序调用这种打印机或复印机的扫描程序即可,它在电脑系统中的位置一般是:C:\W…...

【服务器知识】Tomcat简单入门
文章目录 概述Apache Tomcat 介绍主要特性版本历史使用场景 核心架构Valve机制详细说明请求处理过程 Tomcat安装Windows系统下Tomcat的安装与配置:步骤1:安装JDK步骤2:下载Tomcat步骤3:解压Tomcat步骤4:配置环境变量&a…...

【前端】Matter:过滤与高级碰撞检测
在物理引擎中,控制物体的碰撞行为是物理模拟的核心之一。Matter.js 提供了强大的碰撞检测机制和碰撞过滤功能,让开发者可以控制哪些物体能够相互碰撞,如何处理复杂的碰撞情况。本文将详细介绍 碰撞过滤 (Collision Filtering) 与 高级碰撞检测…...

wps图标没有坐标轴标题怎么办?wps表格不能用enter下怎么办?
目录 wps图标没有坐标轴标题怎么办 一、在WPS PPT中添加坐标轴标题 二、在WPS Excel中添加坐标轴标题 wps表格不能用enter下怎么办 一、检查并修改设置 二、检查单元格保护状态 三、使用快捷键实现换行 wps图标没有坐标轴标题怎么办 一、在WPS PPT中添加坐标轴标题 插入…...

在ESP-IDF环境中如何进行多文件中的数据流转-FreeRTOS实时操作系统_流缓存区“xMessageBuffer”
一、建立三个源文件和对应的头文件 建立文件名,如图所示 图 1-1 二、包含相应的头文件 main.h 图 2-1 mess_send.h mess_rece.h和这个中类似,不明白的大家看我最后面的源码分享 图2-2 三、声明消息缓存区的句柄 大家注意,在main.c中定义的是全局变…...

ConcurrentLinkedQueue适合什么样的使用场景?
ConcurrentLinkedQueue 是 Java 中一种无界线程安全的队列,适合多线程环境中的高并发场景。以下是一些它特别适合的使用场景: 1. 高频读操作,低频写操作 ConcurrentLinkedQueue 对于实际应用中读操作相对频繁,写操作较少的场景非…...

C语言 | Leetcode C语言题解之第480题滑动窗口中位数
题目: 题解: struct Heap {int* heap;int heapSize;int realSize;bool (*cmp)(int, int); };void init(struct Heap* obj, int n, bool (*cmp)(int, int)) {obj->heap malloc(sizeof(int) * (n 1));obj->heapSize 0;obj->cmp cmp; }bool c…...
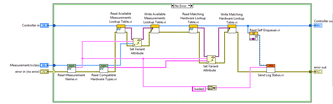
LabVIEW开发如何实现降维打击
在LabVIEW开发中实现“降维打击”可以理解为利用软件优势和高效工具来解决复杂的问题,将多维度、多层次的技术简化为容易操作和管理的单一维度,达到出其不意的效果。以下是几种关键策略: 1. 模块化设计与封装 将复杂系统分解为若干模块&…...

docker 文件目录迁移
文章参考 du -hs /var/lib/docker/ 命令查看磁盘使用情况。 du -hs /var/lib/docker/docker system df命令,类似于Linux上的df命令,用于查看Docker的磁盘使用情况: rootnn0:~$ docker system df TYPE TOTAL ACTIVE SIZE RECLAIMABLE Images 7 2 122.2…...

Markdown 标题
Markdown 标题 Markdown 是一种轻量级标记语言,它允许人们使用易读易写的纯文本格式编写文档,然后转换成格式化的HTML代码。Markdown 的语法简洁明了,广泛用于撰写文档、博客文章、笔记等。本文将详细介绍 Markdown 的标题语法及其在文档中的应用。 Markdown 标题语法 在…...
)
从一次生产事故复盘:我们如何优雅地处理用户上传的‘异常’Excel文件(附Apache POI配置详解)
从生产事故到防御体系:构建Excel文件处理的工程化解决方案那天凌晨2点,我被一阵急促的告警声惊醒。监控系统显示,核心文件处理服务的错误率在10分钟内飙升到35%,大量用户上传的Excel文件无法正常解析。更糟糕的是,部分…...

Arduino PWM转4-20mA工业电流信号:二阶滤波与V/I转换电路设计
1. 项目概述:从PWM到工业标准电流信号在工业自动化、过程控制和传感器领域,4-20 mA电流环是一个几乎无处不在的标准。它用4 mA代表测量值的下限(如0C),20 mA代表上限(如100C),这种设…...

MBTI性格测试
简介 MBTI(Myers‑Briggs Type Indicator,迈尔斯‑布里格斯类型指标)是基于荣格心理类型理论发展出的性格类型工具,由凯瑟琳库克布里格斯及其女儿伊莎贝尔布里格斯迈尔斯创建。它通过四对偏好维度将个体的认知与行为倾向归纳为 16…...

MAX78000移植Zephyr RTOS实战:从BSP创建到AI边缘设备开发
1. 项目概述与动机作为一名长期在嵌入式边缘AI和机器人领域摸爬滚打的开发者,我最近把目光投向了一块相当有潜力的板子:Maxim Integrated(现为ADI一部分)的MAX78000FTHR开发套件。这块板子的核心——MAX78000微控制器,…...

2026论文降AI怎么挑?亲测好用工具附免费降AI指南
“您的论文AIGC率为42%,超出学校30%的合格线,请修改后重新提交。”赶毕业论文的同学这段时间估计没少收到这样的提醒。2026年知网、万方、维普等主流平台的AI检测算法持续迭代,把AI生成内容改到符合学校要求,已经成了毕业生的刚需…...

收藏|2026年大模型算法岗崛起!程序员小白入门高薪赛道全攻略
前些年,算法岗位一直稳居技术圈高薪行列,无数程序员争相入局,也成为计算机专业毕业生求职首选方向。 伴随大模型技术飞速迭代落地,行业就业格局迎来重大变革。如今含金量最高、人才缺口最大、长期发展潜力顶尖的岗位,已…...

Unity中实现深度遮挡:LingBot-Depth实战接入与优化
1. 这不是“加个插件就完事”的AR效果——为什么LingBot-Depth在Unity里值得专门写一篇实战教程你肯定见过那种AR应用:虚拟椅子摆在真实地板上,但当你绕到椅子后面,它依然完整显示,完全无视身后那堵真实的墙;或者一只3…...
和Python脚本,5分钟批量生成你的分割数据集)
告别手动标注!用SAM(Segment Anything)和Python脚本,5分钟批量生成你的分割数据集
5分钟批量生成分割数据集:SAM自动化标注全流程实战 在计算机视觉领域,数据标注一直是制约模型开发效率的瓶颈。传统手工标注不仅耗时费力,还容易引入人为误差。Meta开源的Segment Anything Model(SAM)彻底改变了这一局…...

《关于 AI Agent 基础设施的一些奇思妙想》
目录 目录 目录 一、AI Agent 容器 问题背景 想法思路:API 中转站模式 多 Agent 切换 二、手机端操控 AI Agent(手机与电脑互联) 三、AI 开发依赖管理工具 总结 最近 AI Agent 越来越火,我作为一个重度使用者,…...

FModel完整部署指南:UE5资源提取与逆向解析实战
1. 为什么FModel不是“另一个UE资源查看器”,而是虚幻项目逆向分析的起点FModel虚幻引擎资源提取工具完整部署指南——这标题里藏着三个被多数人忽略的关键信号:“FModel”不是泛指,“虚幻引擎”特指UE4/UE5原生资产体系,“完整部…...