FLINK SQL语法(1)
DDL
Flink SQL DDL(Data Definition Language)是Flink SQL中用于定义和管理数据结构和数据库对象的语法。以下是对Flink SQL DDL的详细解析:
一、创建数据库(CREATE DATABASE)
- 语法:CREATE DATABASE [IF NOT EXISTS] [catalog_name.]db_name [COMMENT database_comment] WITH (key1=val1, key2=val2, …)
- 说明:用于在当前或指定的Catalog中创建一个新的数据库。如果指定了IF NOT EXISTS,则在数据库已存在时不会抛出错误。WITH子句用于指定数据库的额外属性。
二、创建表(CREATE TABLE)
- 语法:CREATE [TEMPORARY] TABLE [IF NOT EXISTS] [catalog_name.][db_name.]table_name ({<physical_column_definition>|<metadata_column_definition>|<computed_column_definition>}[ , …n][<watermark_definition>][<table_constraint>[ , …n]]) [COMMENT table_comment] [PARTITIONED BY (partition_column_name1, partition_column_name2, …)] WITH (key1=val1, key2=val2, …) [LIKE source_table[(<like_options>)]]
- 说明:
- 物理列:定义了物理介质中存储的数据的字段名称、类型和顺序。
- 元数据列:允许访问数据源本身具有的一些元数据,由METADATA关键字标识。
- 计算列:使用表达式定义的虚拟列,不物理存储在表中。
- 水印列:用于处理事件时间,指定如何生成水印。
- 表约束:用于定义表的约束条件,如主键等。
- 分区:用于对表进行分区,以提高查询性能。
- WITH子句:用于指定表的连接器类型和配置项。
- LIKE子句:允许基于现有表创建新表,包括表的结构和配置。
三、创建视图(CREATE VIEW)
- 语法:CREATE VIEW [IF NOT EXISTS] [catalog_name.][db_name.]view_name AS select_statement
- 说明:用于创建一个基于SQL查询结果的视图。视图可以看作是一个虚拟表,它包含了查询结果的数据,并且可以根据需要进行过滤、转换等操作。
四、其他DDL操作
- 修改数据库:使用ALTER DATABASE语句修改数据库的某些属性。
- 删除数据库:使用DROP DATABASE语句删除数据库。如果数据库不为空,可以指定CASCADE来删除所有相关的表和函数。
- 修改表:使用ALTER TABLE语句修改表的结构,如添加、删除或修改列。
- 删除表:使用DROP TABLE语句删除表。
五、Connector
一、定义与功能
Flink SQL Connector是一种用于在Flink SQL与外部数据源或数据汇之间建立连接的插件。它允许Flink SQL从外部数据源读取数据,并将处理后的数据写入到外部数据汇中。通过Connector,Flink SQL能够轻松实现对各种类型数据的实时处理和分析。
二、类型与分类
Flink SQL Connector主要分为以下几类:
1. 数据源Connector:用于从外部数据源读取数据。常见的数据源Connector包括Kafka、JDBC、FileSystem等。
2. 数据汇Connector:用于将处理后的数据写入到外部数据汇中。常见的数据汇Connector也包括Kafka、JDBC、Elasticsearch等。
三、工作原理
Flink SQL Connector的工作原理如下:
- 连接配置:在创建表时,通过WITH子句指定Connector的类型和相关配置项,如数据源或数据汇的地址、用户名、密码等。
- 数据读取:对于数据源Connector,Flink SQL会根据配置的连接信息从外部数据源中读取数据,并将其转换为Flink内部的Row或Tuple数据类型。
- 数据处理:在Flink SQL中,用户可以对读取到的数据进行各种查询和处理操作,如过滤、聚合、连接等。
- 数据写入:对于数据汇Connector,Flink SQL会将处理后的数据写入到指定的外部数据汇中,如Kafka主题、数据库表等。
四、常用Connector示例
- Kafka Connector:
- Kafka作为流数据的代表,在Flink SQL中得到了广泛的支持。
- 用户可以通过Kafka Connector轻松地从Kafka主题中读取数据,并将处理后的数据写回到Kafka中。
- JDBC Connector:
- JDBC Connector允许Flink SQL与关系型数据库进行交互。
- 用户可以通过JDBC Connector从数据库中读取数据,或将数据写入到数据库中。
- FileSystem Connector:
- FileSystem Connector支持Flink SQL与文件系统(如HDFS、S3等)进行交互。
- 用户可以通过FileSystem Connector从文件中读取数据,或将数据写入到文件中。
五、自定义Connector
在某些特殊情况下,用户可能需要自定义Connector来满足特定的需求。Flink提供了丰富的API和工具来支持用户自定义Connector。自定义Connector通常涉及以下几个步骤:
1. 定义Connector的工厂类:实现Flink提供的DynamicTableSourceFactory或DynamicTableSinkFactory接口。
2. 实现TableSource或TableSink:根据需求实现StreamTableSource、BatchTableSource、StreamTableSink或BatchTableSink接口。
3. 配置参数:在Connector的工厂类中定义并解析所需的参数。
4. 注册Connector:将自定义的Connector注册到Flink的SPI(Service Provider Interface)机制中,以便在创建表时能够识别并使用它。
六 Format
Flink SQL Format指的是在Flink SQL中定义数据源和数据汇时所使用的数据序列化方式。在Flink中,数据通常以流的形式进行处理,而Format则定义了如何将这些流数据映射到Flink SQL的表结构中,以及如何将处理后的数据序列化为特定的格式输出到外部系统。
一、Format的类型
Flink SQL支持多种Format类型,包括但不限于以下几种:
- CSV:逗号分隔值格式,适用于简单的文本数据。CSV Format允许基于CSV schema读写CSV格式的数据,目前CSV schema通常来源于表schema定义。
- JSON:JavaScript对象表示法格式,适用于复杂的数据结构。JSON Format允许基于JSON schema读写JSON格式的数据,目前JSON schema通常也派生于表schema。
- Avro:Apache Avro是一种紧凑的、快速的二进制数据格式,适用于需要高效序列化和反序列化的场景。Avro Format允许基于Avro schema读写Avro格式的数据。
- Raw:原始数据格式,适用于不需要对数据进行任何解析或格式化的场景。在Flink SQL中,使用Raw Format时,Kafka消息会直接将原始数据读取为纯字符串。
二、Format的配置
在Flink SQL中,Format的配置通常通过WITH子句中的参数来指定。以下是一些常见的Format配置参数:
- ‘format’ = ‘xxx’:指定使用的Format类型,如CSV、JSON、Avro等。
- ‘csv.ignore-parse-errors’ = ‘true’:对于CSV Format,忽略解析错误。
- ‘json.fail-on-missing-field’ = ‘false’:对于JSON Format,当缺少字段时不抛出异常。
- 其他与特定Format相关的配置参数,如Avro的schema定义等。
三、Format的使用示例
以下是一个使用Kafka连接器和JSON Format创建表的示例:
CREATE TABLE user_behavior ( user_id BIGINT, item_id BIGINT, category_id BIGINT, behavior STRING, ts TIMESTAMP(3)
) WITH ( 'connector' = 'kafka', 'topic' = 'user_behavior', 'properties.bootstrap.servers' = 'localhost:9092', 'properties.group.id' = 'testGroup', 'format' = 'json', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true'
);
在这个示例中,我们创建了一个名为user_behavior的表,它从一个Kafka主题中读取数据,数据格式为JSON。我们还指定了Kafka连接器的配置项和JSON Format的相关参数。
七、示例
以下是一个简单的Flink SQL DDL示例,演示了如何创建一个表、视图以及执行一些基本的DDL操作:
-- 创建一个名为user_table的表,包含id、name和age字段,并使用Kafka作为数据源
CREATE TABLE user_table ( id INT, name STRING, age INT
) WITH ( 'connector' = 'kafka', 'topic' = 'user_topic', 'properties.bootstrap.servers' = 'localhost:9092', 'format' = 'json'
); -- 创建一个名为user_view的视图,包含user_table表中年龄大于18岁的用户的name和age字段
CREATE VIEW user_view AS
SELECT name, age
FROM user_table
WHERE age > 18; -- 修改user_table表,添加一个新的字段email
ALTER TABLE user_table
ADD COLUMNS (email STRING); -- 删除user_view视图
DROP VIEW user_view; -- 删除user_table表
DROP TABLE user_table;
注意事项
- 在执行DDL操作时,请确保具有相应的权限。
- 不同的Flink版本可能支持不同的DDL语法和特性,请参考官方文档以获取最新信息。
- 在创建表和视图时,请确保指定了正确的连接器类型和配置项,以便Flink能够正确地连接到数据源。
DML
WITH…AS
WITH … AS语法是一种定义公用表表达式(Common Table Expressions, CTEs)的方式,它允许在查询中定义一个或多个临时的结果集,这些结果集可以在后续的查询中被引用。CTE在复杂查询中特别有用,因为它们可以帮助将查询分解为更小、更易于管理的部分。
语法详解
WITH … AS语法的基本形式如下:
WITH cte_name (column1, column2, ...) AS ( -- 这里是CTE的定义,可以是一个子查询 SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ...
)
-- 后续的查询,可以引用上面定义的CTE
SELECT ...
FROM cte_name
-- 还可以加入其他表或CTE进行连接、过滤等操作
- cte_name:公用表表达式的名称,可以在后续的查询中引用。
- (column1, column2, …):CTE中定义的列名(可选,但在某些情况下有助于明确CTE的结构)。
- AS:关键字,用于引入CTE的定义。
- 子查询:定义了CTE的内容,可以包含SELECT、FROM、WHERE、GROUP BY、HAVING、ORDER BY等子句。
样例
以下是一个使用WITH … AS语法的Flink SQL DML样例,它演示了如何定义一个CTE来计算每个商品在每个小时内的销售额,并将销售额超过一定金额的商品信息插入到另一个表中。
-- 定义公用表表达式,计算每个商品在每个小时内的销售额
WITH product_sales AS ( SELECT product_id, product_name, TUMBLE_START(sale_time, INTERVAL '1' HOUR) AS window_start, TUMBLE_END(sale_time, INTERVAL '1' HOUR) AS window_end, SUM(sale_amount) AS total_sales FROM sales_stream GROUP BY product_id, product_name, TUMBLE(sale_time, INTERVAL '1' HOUR)
) -- 插入销售额超过1000的商品信息到结果表中
INSERT INTO product_sales_summary
SELECT product_id, product_name, window_start, window_end, total_sales
FROM product_sales
WHERE total_sales > 1000;
在这个样例中:
- product_sales是一个CTE,它计算了每个商品在每个小时内的销售额。这里使用了Flink的窗口函数TUMBLE来按小时划分时间窗口,并计算了每个窗口内的销售总额。
- INSERT INTO product_sales_summary SELECT ... FROM product_sales WHERE ...是一个DML语句,它将销售额超过1000的商品信息从product_salesCTE插入到product_sales_summary表中。
SELECT & WHERE:ETL、字段标准化
ELECT和WHERE子句是数据提取(Extract)、转换(Transform)、加载(Load,简称ETL)过程中的核心组件。它们被广泛应用于从数据流或数据表中筛选和转换数据。字段标准化,作为ETL流程的一个重要环节,通常涉及数据清洗、格式统一和值映射等任务。
语法详解
SELECT
SELECT子句用于指定查询要返回的列。它可以包含原始列、表达式计算结果、别名列等。
SELECT column1, column2, ..., expression AS alias_name
FROM source_table
- column1, column2, …:要查询的原始列名。
- expression AS alias_name:计算表达式及其别名。
WHERE
WHERE子句用于过滤数据,只返回满足特定条件的记录。
SELECT ...
FROM source_table
WHERE condition
- condition:筛选条件,可以是简单的比较操作、逻辑运算或复杂的子查询。
样例
以下是一个Flink SQL DML样例,展示了如何使用SELECT和WHERE子句进行ETL和字段标准化。
-- 假设有一个名为`raw_data`的数据流,包含以下字段:user_id, raw_age, raw_salary, city_code -- ETL和字段标准化查询
SELECT user_id, -- 数据清洗:去除无效年龄(例如,负数或超过120岁的年龄) CASE WHEN raw_age IS NULL OR raw_age < 0 OR raw_age > 120 THEN NULL ELSE raw_age END AS standardized_age, -- 格式统一:将薪资转换为整数(假设原始薪资为字符串格式) CAST(raw_salary AS INT) AS standardized_salary, -- 值映射:将城市代码转换为城市名称(这里使用简单的CASE语句作为示例) CASE city_code WHEN '001' THEN 'Beijing' WHEN '002' THEN 'Shanghai' WHEN '003' THEN 'Guangzhou' ELSE 'Unknown' END AS city_name
FROM raw_data
-- 数据过滤:只选择年龄和薪资都有效的记录
WHERE (raw_age IS NOT NULL AND raw_age >= 0 AND raw_age <= 120) AND (raw_salary IS NOT NULL AND LENGTH(raw_salary) > 0 AND TRY_CAST(raw_salary AS INT) IS NOT NULL);
在这个样例中:
- 使用CASE语句进行数据清洗和值映射。
- 使用CAST函数将薪资字段从字符串转换为整数,实现格式统一。
- 在WHERE子句中,通过多个条件组合来过滤无效数据。
- TRY_CAST函数(如果Flink SQL支持)用于安全地尝试类型转换,避免转换失败导致的查询错误。如果不支持TRY_CAST,可以使用其他方式处理类型转换错误,例如使用嵌套的CASE语句。
SELECT DISTINCT:去重
在Flink SQL中,SELECT DISTINCT语句用于从数据集中选择唯一的记录,即去除重复的行。这个操作在处理大量数据时非常有用,尤其是当你需要确保结果集中不包含重复条目时。
语法
SELECT DISTINCT column1, column2, ...
FROM source_table;
- column1, column2, …:你想要选择并确保唯一的列。
- source_table:包含数据的表或数据流。
工作原理
当你执行SELECT DISTINCT查询时,Flink SQL引擎会对指定的列进行去重操作。这通常涉及到排序和哈希等算法,以确保所有返回的行在指定的列组合上都是唯一的。
样例
假设你有一个名为users的数据流,它包含以下字段:user_id, name, email。你想要选择所有唯一的用户(基于user_id和email的组合):
SELECT DISTINCT user_id, email
FROM users;
注意事项
- 性能:SELECT DISTINCT可能会增加查询的复杂性和执行时间,特别是在处理大型数据集时。因此,在使用时应该权衡其带来的好处和可能的性能开销。
- NULL值:在SQL中,NULL值被视为不同的值。因此,如果两行在指定的列上除了NULL值之外都相同,但它们在不同的列上有NULL值,那么这两行仍然会被视为不同的记录。然而,当两行在所有指定的列上都有NULL值时,它们会被视为相同的记录,并只会在结果集中出现一次。
- 列的顺序:在SELECT DISTINCT中,列的顺序很重要。不同的列顺序可能会导致不同的去重结果。
- 组合索引:如果表上有适当的索引,SELECT DISTINCT的性能可能会得到提高。然而,在Flink中,索引的使用和效果可能因具体的执行计划和配置而异。
- 数据类型:确保你选择的列具有兼容的数据类型。如果列的数据类型不兼容,Flink SQL可能会在执行时抛出错误。
窗口聚合
在Flink SQL中,窗口聚合是一种强大的功能,它允许你对数据流中的数据进行分组,并在指定的时间窗口内执行聚合操作。这对于处理实时数据流并计算诸如滚动平均值、总和、计数等统计信息非常有用。
窗口类型
Flink SQL支持多种类型的窗口,包括:
- 滚动窗口(Tumbling Window):固定长度的窗口,每个窗口之间不重叠。例如,每5分钟一个窗口。
- 滑动窗口(Sliding Window):固定长度的窗口,但窗口之间可以重叠。例如,每30秒计算一次过去5分钟的聚合。
- 会话窗口(Session Window):基于活动间隔的窗口,当没有数据到达时窗口会关闭。例如,用户活动间隔超过10分钟则视为会话结束。
- 渐进式窗口(CUMULATE):渐进式窗口在其实就是固定窗口间隔内提前触发的的滚动窗口,其实就是Tumble Window + early-fire的一个事件时间的版本。
- 全局窗口(Global Window):对整个数据流进行聚合,通常与其他触发机制(如处理时间、事件时间的时间戳水印)结合使用。
- Window TVF:表值函数(table-valued function, TVF),顾名思义就是指返回值是一张表的函数,在Oracle、SQL Server等数据库中屡见不鲜。
- GROUPING SETS:Grouping Sets 可以通过一个标准的 GROUP BY 语句来描述更复杂的分组操作。数据按每个指定的 Grouping Sets 分别分组,并像简单的 group by 子句一样为每个组进行聚合。
语法
窗口聚合的语法通常涉及GROUP BY子句和窗口函数。以下是一个基本的滚动窗口聚合示例:
SELECT window_start, window_end, user_id, SUM(amount) AS total_amount, COUNT(*) AS transaction_count
FROM transactions
GROUP BY TUMBLE(event_time, INTERVAL '5' MINUTE), user_id;
在这个示例中:
- TUMBLE(event_time, INTERVAL '5' MINUTE)定义了一个滚动窗口,窗口长度为5分钟。
- user_id是另一个分组键。
- SUM(amount)和COUNT(*)是聚合函数。
- window_start和window_end是窗口的开始和结束时间(这些通常需要额外的步骤或函数来提取,因为Flink SQL的默认输出并不总是包括这些时间戳)。
时间属性
在Flink SQL中,窗口聚合通常依赖于时间属性,如处理时间(processing time)或事件时间(event time)。事件时间是数据本身携带的时间戳,而处理时间是数据被Flink处理的时间。
- **事件时间**:需要为数据流指定时间戳和水印(watermark),以便Flink能够正确理解和处理事件时间。
- **处理时间**:不需要额外的配置,因为处理时间是基于Flink集群的本地时钟。
Group聚合
Apache Flink 是一个用于处理无界和有界数据流的分布式流处理框架。Flink SQL 是 Flink 提供的一种高级 API,允许用户使用 SQL 查询来处理数据流。在 Flink SQL 中,GROUP BY 子句用于对数据进行分组聚合。
以下是一些常见的 Flink SQL 聚合操作以及如何使用 GROUP BY 子句的示例:
基本示例
假设你有一个数据流 orders,其中包含以下字段:user_id、order_amount 和 order_time。你想要计算每个用户的总订单金额。
SELECT user_id, SUM(order_amount) AS total_amount
FROM orders
GROUP BY user_id;
多字段分组
你也可以根据多个字段进行分组。例如,假设你希望按 user_id 和 order_time 的日期部分进行分组,以计算每个用户每天的总订单金额。
SELECT user_id, TUMBLE_START(order_time, INTERVAL '1' DAY) AS window_start, TUMBLE_END(order_time, INTERVAL '1' DAY) AS window_end, SUM(order_amount) AS total_amount
FROM orders
GROUP BY user_id, TUMBLE(order_time, INTERVAL '1' DAY);
在这个示例中,TUMBLE 是一个窗口函数,用于将数据按时间窗口分组。这里的时间窗口是每天。
其他聚合函数
除了 SUM 之外,Flink SQL 还支持许多其他聚合函数,如 COUNT、AVG、MIN、MAX 等。例如,计算每个用户的订单数量:
SELECT user_id, COUNT(*) AS order_count
FROM orders
GROUP BY user_id;
HAVING 子句
HAVING 子句用于对聚合结果进行过滤。例如,只选择订单总金额大于 1000 的用户:
SELECT user_id, SUM(order_amount) AS total_amount
FROM orders
GROUP BY user_id
HAVING SUM(order_amount) > 1000;
窗口聚合
除了基本的 GROUP BY 聚合,Flink SQL 还支持窗口聚合。窗口聚合允许你根据时间或行数的窗口对数据进行分组。
滑动窗口
假设你希望计算每个用户每两小时(滑动间隔为 1 小时)的总订单金额:
SELECT user_id, HOP_START(order_time, INTERVAL '2' HOUR, INTERVAL '1' HOUR) AS window_start, HOP_END(order_time, INTERVAL '2' HOUR, INTERVAL '1' HOUR) AS window_end, SUM(order_amount) AS total_amount
FROM orders
GROUP BY user_id, HOP(order_time, INTERVAL '2' HOUR, INTERVAL '1' HOUR);
会话窗口
假设你希望计算每个用户每次会话(会话间隔为 30 分钟)的总订单金额:
SELECT user_id, SESSION_START(order_time, INTERVAL '30' MINUTE) AS session_start, SESSION_END(order_time, INTERVAL '30' MINUTE) AS session_end, SUM(order_amount) AS total_amount
FROM orders
GROUP BY user_id, SESSION(order_time, INTERVAL '30' MINUTE);
GROUPING SETS
GROUPING SETS 允许你指定多个分组集,每个分组集都可以包含不同的维度组合。这样,你可以在一个查询中同时计算多个不同维度的聚合结果。
SELECT user_id, product_id, SUM(order_amount) AS total_amount, GROUPING(user_id, product_id) AS grouping_id
FROM orders
GROUP BY GROUPING SETS ( (user_id), (product_id), (user_id, product_id), () -- 空的分组集会计算全局总计 );
在这个示例中,查询将返回四个聚合结果集:按 user_id 分组、按 product_id 分组、按 user_id 和 product_id 同时分组,以及全局总计。
ROLLUP
ROLLUP 是 GROUPING SETS 的一个特例,它会自动生成从指定的维度组合到所有维度都包括以及一个全局总计的所有可能分组集。
SELECT user_id, product_id, SUM(order_amount) AS total_amount
FROM orders
GROUP BY ROLLUP(user_id, product_id);
这个查询将返回以下分组集的结果:
- (user_id, product_id)
- (user_id, NULL)(对 user_id 进行分组,不考虑 product_id)
- (NULL, NULL)(全局总计)
CUBE
CUBE 是 GROUPING SETS 的另一个特例,它会生成所有可能的维度组合,包括每个维度的单独组合、所有维度的组合以及一个全局总计。
SELECT user_id, product_id, SUM(order_amount) AS total_amount
FROM orders
GROUP BY CUBE(user_id, product_id);
这个查询将返回以下分组集的结果:
- (user_id, product_id)
- (user_id, NULL)
- (NULL, product_id)
- (NULL, NULL)(全局总计)
Over聚合
Flink SQL中的Over聚合是一种使用Over子句的开窗函数,用于对数据按照不同的维度和范围进行分组和聚合。以下是对Flink SQL Over聚合的详细解释:
一、Over聚合的基本概念
Over聚合可以保留原始字段,不像分组聚合(Group By)只能输出聚合结果和分组字段。它通过对每行数据进行窗口内聚合,能够计算出如移动平均、累计和等统计指标。
二、Over聚合的语法
Over聚合的语法结构如下:
SELECT agg_func(agg_col) OVER ( [PARTITION BY col1 [, col2, ...]] ORDER BY time_col [range_definition]
), ...
FROM ...
其中:
- **agg_func(agg_col)**:聚合函数和要聚合的列。
- **PARTITION BY**:可选,用于指定分区的键,类似于Group By的分组。
- **ORDER BY**:必须,指定数据基于哪个字段排序,通常是时间戳列。
- **range_definition**:定义聚合窗口的数据范围,有两种指定方式:按时间区间聚合和按行数聚合。
三、Over聚合的窗口范围
- 按时间区间聚合:
使用RANGE BETWEEN INTERVAL … PRECEDING AND CURRENT ROW来指定一个向前的时间范围。例如,计算最近一小时的订单金额总和:
SELECT product, order_time, amount, SUM(amount) OVER ( PARTITION BY product ORDER BY order_time RANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW ) AS one_hour_prod_amount_sum
FROM Orders;
- 按行数聚合:
使用ROWS BETWEEN … PRECEDING AND CURRENT ROW来指定一个向前的行数范围。例如,计算当前行及其前5行的订单金额总和:
SELECT product, order_time, amount, SUM(amount) OVER ( PARTITION BY product ORDER BY order_time ROWS BETWEEN 5 PRECEDING AND CURRENT ROW ) AS five_rows_prod_amount_sum
FROM Orders;
四、Over聚合的应用场景
Over聚合在数据分析中有着广泛的应用,如:
计算最近一段滑动窗口的聚合结果数据,如最近一小时或最近五行的数据。
计算累计或移动平均等指标,如累计销售额或移动平均价格。
相关文章:
)
FLINK SQL语法(1)
DDL Flink SQL DDL(Data Definition Language)是Flink SQL中用于定义和管理数据结构和数据库对象的语法。以下是对Flink SQL DDL的详细解析: 一、创建数据库(CREATE DATABASE) 语法:CREATE DATABASE [IF…...

【Fargo】1:基于libuv的udp收发程序
开发UDP处理程序 我正在开发一个基于libuv的UDP发送/接收程序,区分发送端和接收端,设计自定义包数据结构,识别和处理丢包和乱序。 创建项目需求 用户正在要求一个使用libuv的C++程序,涉及UDP发送和接收,数据包包括序列号和时间戳,接收端需要检测丢包和乱序包。 撰写代…...

WebSocket介绍和入门案例
目录 一、WebSocket 详解1. 定义与特点:2. 工作原理:3. 应用场景: 二、入门案例 一、WebSocket 详解 1. 定义与特点: WebSocket 是一种在单个 TCP 连接上进行全双工通信的协议。它允许客户端和服务器之间进行实时、双向的数据传…...

k8s集群版本升级
Kubernetes 集群版本升级是为了获得最新的功能、增强的安全性和性能改进。然而,升级过程需要谨慎进行,特别是在生产环境中。通常,Kubernetes 集群的版本升级应遵循逐步升级的策略,不建议直接跳过多个版本。 Kubernetes 版本升级的…...

XML 和 SimpleXML 简介
XML 和 SimpleXML 简介 XML(可扩展标记语言)是一种用于存储和传输数据的标记语言。它定义了一组规则,用于在文档中编码数据,以便人和机器都能理解。XML 的设计目标是既易于人类阅读,也易于机器解析。SimpleXML 是 PHP…...

MySQL 中 LIKE 语句的 `%` 和 `_` 以及 BLOB 和 TEXT 的详细解析和案例示范
1. LIKE 语句中的 % 和 _ 用法 1.1 % 通配符的用法 % 通配符代表零个或多个字符。它是 MySQL 中用于模糊匹配的强大工具之一,可以在任何字符的位置使用。 示例 1:查找以特定字符开头的记录 假设我们有一个电商订单系统的 orders 表,其中包…...

git clone卡在Receiving objects
git clone卡在Receiving objects 一直卡主 $ git clone gitxxx.git Cloning into xxx... remote: Enumerating objects: 75926, done. remote: Counting objects: 100% (18844/18844), done. remote: Compressing objects: 100% (6566/6566), done. Receiving objects: 60% (…...

vue+ant 弹窗可以拖动
通过自定义指令实现拖拽功能 在main.js里加入drag自定义指令 我自己测试时发现modal不管如何设置宽度,居中等,他的初始的left都为0,如果不设置好,容易出现点击后刚开始移动弹窗会偏移一段距离。 Vue.directive(drag, {bind(el)…...

(42)MATLAB中使用fftshift绘制以零为中心的功率谱
文章目录 前言一、MATLAB代码二、仿真结果画图 前言 在分析信号的频率分量时,将零频分量平移到频谱中心会很有帮助。本例给出绘制以零为中心的功率谱的方法。 一、MATLAB代码 代码如下: f 1; % 余弦波的振荡频率…...
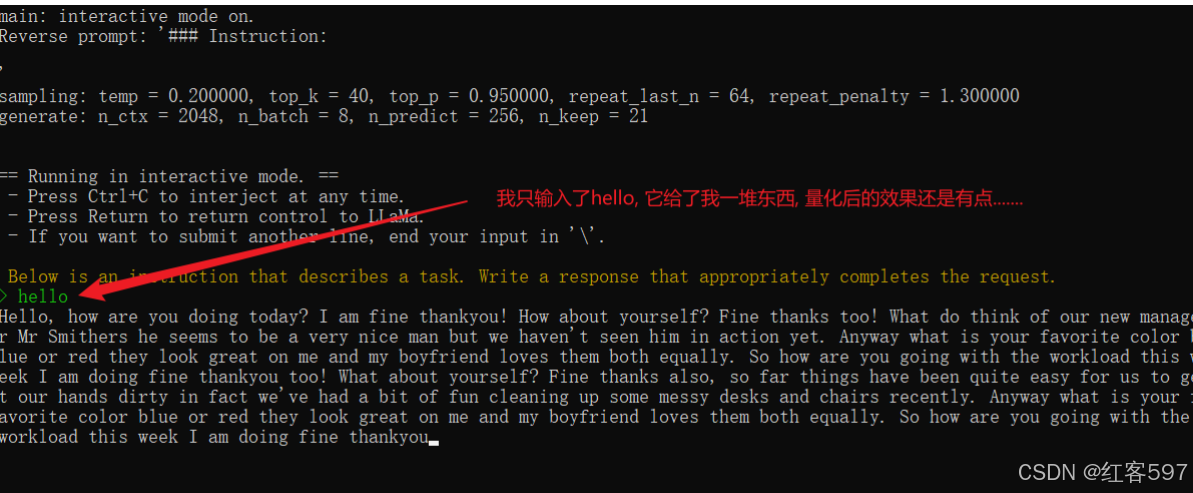
Windows本地部署中文羊驼模型(Chinese-Alpaca-Pro-7B)(通俗易懂版)
最近由于项目原因需要部署大语言模型, 但碍于经济实力, 只能部署在笔记本电脑上部署量化模型, (电脑至少有16G运行内存),搜集了网上的相关部署资料仍然踩了不少坑,原因在于开源项目在不断更新,导致我们看了别人的教程仍…...

Web3的挑战与机遇:技术发展的现状分析
在Web3的世界中,去中心化和用户主权的理念正逐渐走向主流,推动了现有商业模式和技术生态系统的深刻变革。区块链技术及其核心应用之一——智能合约,正在促使这一转变的发生。智能合约的主要功能是通过自动化和预设协议执行,以减少…...

LangGraph - Hierarchical Agent Teams
本文翻译整理自 Hierarchical Agent Teams https://langchain-ai.github.io/langgraph/tutorials/multi_agent/hierarchical_agent_teams/ 文章目录 一、前言二、设置三、创建工具四、Helper Utilities五、定义代理 Team研究 Team文档写作Team 六、添加图层 一、前言 在前面的…...

2021-04-14 proteus中仿真时74HC245三态双向端口扩展输出
缘由proteus中仿真时74HC245输出时电平显示灰色(不确定电平状态)是为什么?-编程语言-CSDN问答 缘由C语言翻译单片机开关检测器-编程语言-CSDN问答 参考74ls245的工作原理及作用详解 - 电子发烧友网 参考74ls245_百度百科...

解决UNSPSC商品分类的层级不足的方法
《联合国标准产品和服务守则》(UNSPSC)是一个分层框架,旨在对产品和服务进行分类。其主要目标是通过提供统一的方法来对产品和服务进行分类,从而简化采购和供应链管理。 虽然 UNSPSC 有效地将产品分为各种商品类别,但…...

Pytest基于fixture的参数化及解决乱码问题
我们知道,Pytest是Python技术栈下进行自动化测试的主流测试框架。支持灵活的测试发现、执行策略,强大的Fixture夹具和丰富的插件支持。 除了通过pytest的parametrize标签进行参数化外,我们通过fixture的param参数也可以比较方便地实现参数化…...

使用excel.js(layui-excel)进行layui多级表头导出,根据单元格内容设置背景颜色,并将导出函数添加到toolbar
本段是菜狗子的碎碎念,解决办法请直接从第二段开始看。layui多级表头的导出,弄了两天才搞定,中途一度想放弃,还好坚持下来了。一开始用的是layui的toolbar里自带的那个导出,但是多级表头没有正常导出,单元格…...

Mysql 5.7 安装与卸载(非常详细)
一、环境介绍 操作系统:CentOS 7 MySQL:5.7 二、MySQL卸载 # 查看软件 rpm -qa|grep mysql # 卸载MySQL yum remove -y mysql mysql-libs mysql-common rm -rf /var/lib/mysql rm /etc/my.cnf 继续查看是否还有 MySQL 软件,有的话继续删…...

030 elasticsearch查询、聚合
文章目录 查询聚合查询RestHighLevelClientElasticsearchRestTemplat SpringData对ES客户端的封装:ElasticsearchRestTemplate SpringData对CRUD的封装:ElasticsearchRepository 原生ES客户端:RestHighLevelClient 查询 package com.xd.cube…...

前端工程启动工具
一些思考 在公司项目中,需要启一个新的前端工程(一个基于Webpack的React工程)。因为同一个项目中有其他的前端工程,我们最开始想的是参考另外一个工程的配置重启一个新的工程,但是又因为原来的工程用的库版本都比较老…...

游戏逆向基础-跳出游戏线程发包
附加游戏后下断点 bp ws2_32.send send函数断下后,可以看到数据地址每次都一样 可以说明这个游戏是线程发包,所以直接在数据窗口中转到这个地址,然后对这个地址下硬件写入断点。 下了硬件写入断点后可以一层一层往上面跟,确定写…...

告别坐标点击!用Poco精准定位UI控件,让你的Airtest安卓自动化脚本更稳定
告别坐标点击!用Poco精准定位UI控件,让你的Airtest安卓自动化脚本更稳定每次UI微调就导致脚本大面积失效?分辨率变化让精心编写的自动化测试瞬间崩溃?作为从坐标点击转型到控件识别的实践者,我深刻理解这种挫败感。三年…...

机器学习在犬类癌症筛查中的性能极限与挑战:基于血液数据的多癌种分析
1. 项目概述:当机器学习遇见犬类癌症筛查作为一名长期关注数据科学在生命科学领域应用的从业者,我常常被问及一个充满希望的问题:我们能否像分析人类健康数据一样,利用宠物的常规体检数据,通过机器学习提前发现癌症的蛛…...

使用curl命令调试Taotoken API接口的常见问题排查
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用curl命令调试Taotoken API接口的常见问题排查 基础教程类,面向所有需要通过HTTP直接与API交互的开发者,…...

UnityExplorer:如何在游戏运行时实时调试和修改Unity项目
UnityExplorer:如何在游戏运行时实时调试和修改Unity项目 【免费下载链接】UnityExplorer An in-game UI for exploring, debugging and modifying IL2CPP and Mono Unity games. 项目地址: https://gitcode.com/gh_mirrors/un/UnityExplorer UnityExplorer是…...

监控摄像头小众场景爆发,融合类产品成新蓝海
随着户外运动热潮的持续和物联网技术的全面落地,打猎相机市场在2025年迎来了真正的爆发期,并在2026年继续向智能化、网联化深度演进。根据最新的行业监测数据,2025年全球消费类IPC(网络摄像机)出货量突破1.92亿台&…...

三步解锁WeMod专业版:终极本地增强工具配置指南
三步解锁WeMod专业版:终极本地增强工具配置指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的订阅费用烦恼吗…...

程序员的物理级打字肌肉记忆训练指南:从一指禅到无意识盲打的科学路径
程序员的物理级打字肌肉记忆训练指南:从一指禅到无意识盲打的科学路径 在日常写代码或重构时,你是否遇到过这种场景: 脑子里已经构思好了完美的重构逻辑,但在输入 >、{} 或 _ 时,手指本能地一顿,视线不…...

3分钟学会Avidemux:开源视频编辑器的完整快速入门指南
3分钟学会Avidemux:开源视频编辑器的完整快速入门指南 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 你是否曾因为视频编辑软件过于复杂而放弃剪辑?或者因为专业软件价格昂…...
)
从酒店评论到情感分析:手把手教你用fastText做文本分类(Python实战避坑指南)
从酒店评论到情感分析:fastText文本分类实战全解析 当产品经理甩给你一份未经处理的酒店评论数据集,要求48小时内给出情感倾向分析报告时,作为工程师的你该如何应对?本文将带你用fastText这个轻量级工具,从原始数据到…...

QMCDecode:解锁你的QQ音乐收藏,让加密音频重获自由
QMCDecode:解锁你的QQ音乐收藏,让加密音频重获自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录ÿ…...