Windows本地部署中文羊驼模型(Chinese-Alpaca-Pro-7B)(通俗易懂版)
最近由于项目原因需要部署大语言模型, 但碍于经济实力, 只能部署在笔记本电脑上部署量化模型, (电脑至少有16G运行内存),搜集了网上的相关部署资料仍然踩了不少坑,原因在于开源项目在不断更新,导致我们看了别人的教程仍然会出错。(切记,开源项目一定要看准更新版本,很多教程并没有对这个进行详细说明,导致我们按照教程下载了最新的开源项目会出现新的问题。)
民间版中文羊驼模型开源地址:GitHub - ymcui/Chinese-LLaMA-Alpaca: 中文LLaMA&Alpaca大语言模型+本地CPU部署 (Chinese LLaMA & Alpaca LLMs)
Linux和Mac的教程在开源的仓库中有提供,当然如果你是M1的也可以参考以下文章:
https://gist.github.com/cedrickchee/e8d4cb0c4b1df6cc47ce8b18457ebde0
准备工作
最好是有代理, 不然你下载东西可能失败, 我为了下个模型花了一天时间, 痛哭~
我们需要先在电脑上安装以下环境:
- Git
- Python3.9(使用Anaconda3创建该环境)
- Cmake(如果你电脑没有C和C++的编译环境还需要安装mingw)
Git
下载地址:Git - Downloading Package
下载好安装包后打开, 一直点下一步安装即可...
在cmd窗口输入以下如果有版本号显示说明已经安装成功
git -v
Python3.9
我这里使用Anaconda3来使用Python, Anaconda3是什么?
Anaconda,中文大蟒蛇,是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。其中,conda是一个开源的包、环境管理器,可以用于在同一个机器上安装不同版本的软件包及其依赖,并能够在不同的环境之间切换。
如果你熟悉docker, 那么你可以把docker的概念带过来, docker可以创建很多个容器, 每个容器的环境可能一样也可能不一样, Anaconda3也是一样的, 它可以创建很多个不同的Python版本, 互相不冲突, 想用哪个版本就切换到哪个版本...
Anaconda3下载地址:Anaconda | Anaconda Distribution
等待安装好后一直点next, 直到点Finish关闭即可

在cmd窗口输入以下命令, 显示版本号则说明安装成功
conda -V 接下来我们在cmd窗口输入以下命令创建一个python3.9的环境
接下来我们在cmd窗口输入以下命令创建一个python3.9的环境
conda create --name py39 python=3.9 -y
--name后面的py39是环境名字, 可以自己任意起, 切换环境的时候需要它
python=3.9是指定python版本
添加-y后就不需要手动输入y去确认安装了
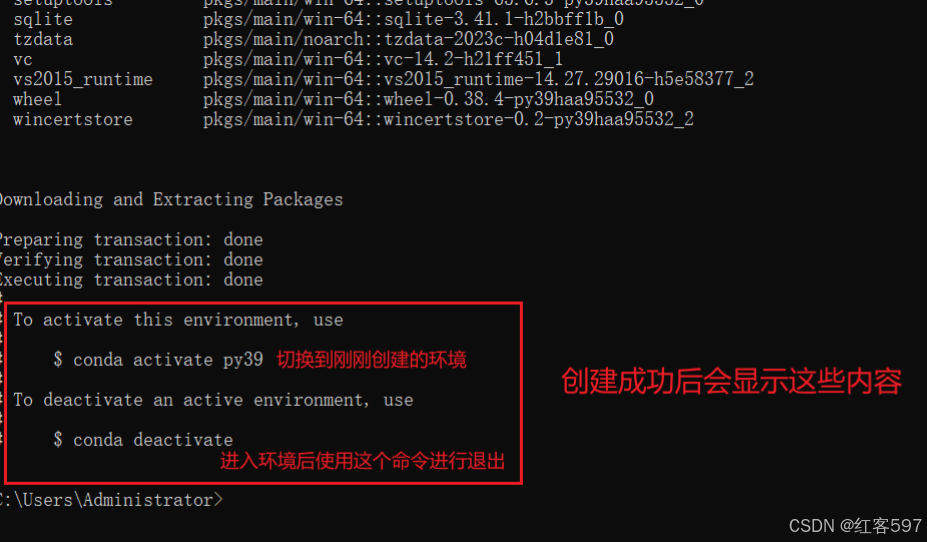
查看有哪些环境的命令:
conda info -e
激活/切换环境的命令:
conda activate py39要使用哪个环境的话换成对应名字即可
要退出环境的话输入:
conda deactivateCmake
这是一个编译工具, 我们需要使用它去编译llama.cpp, 量化模型需要用到, 不量化模型个人电脑跑不起来, 觉得量化这个概念不理解的可以理解为压缩, 这种概念是不对的, 只是为了帮助你更好的理解.
(在安装之前我们需要安装mingw, 避免编译时找不到编译环境, 按下win+r快捷键输入powershell
输入命令安装scoop, 这是一个包管理器, 我们使用它来下载安装mingw:
这个地方如果没有开代理的话可能会出错
iex "& {$(irm get.scoop.sh)} -RunAsAdmin"
安装好后分别运行下面两个命令(添加库):scoop bucket add extras
scoop bucket add main
输入命令安装mingwscoop install mingw
到这就已经安装好mingw了。)
上面框住的内容可以直接跳过直接安装cmake即可,因为安装scoop需要代理容易出错。
接下来安装Cmake
地址:Download | CMake
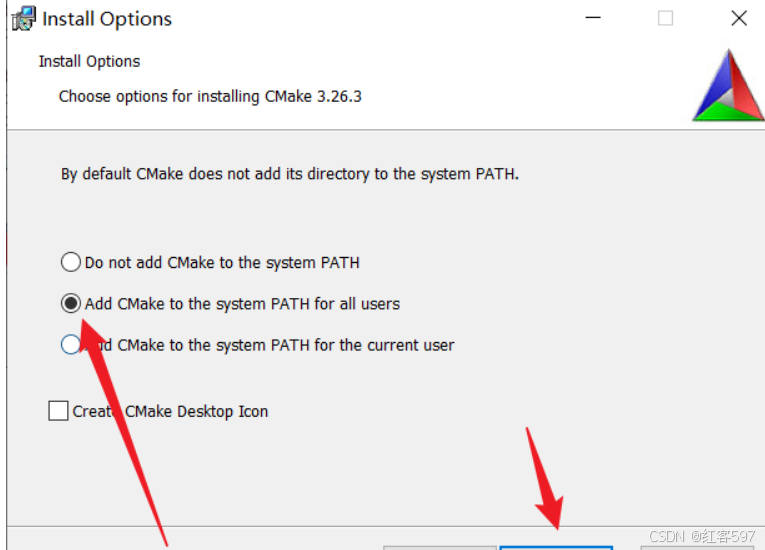
安装好后点Install即可
下载模型
我们需要下载两个模型, 一个是原版的LLaMA模型, 一个是扩充了中文的模型, 后续会进行一个合并模型的操作
原版模型下载地址(要代理):https://ipfs.io/ipfs/Qmb9y5GCkTG7ZzbBWMu2BXwMkzyCKcUjtEKPpgdZ7GEFKm/
网盘地址:文件分享 (115.com)访问码:a835
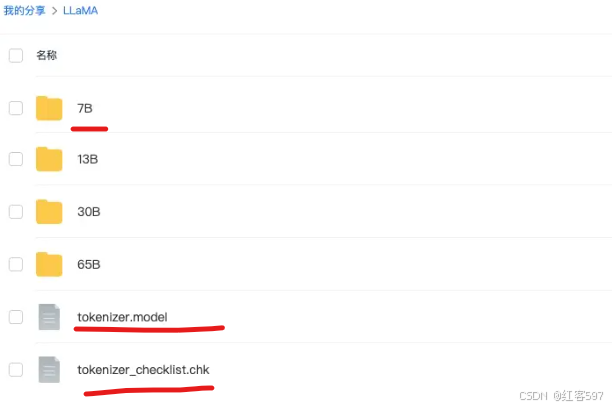
下载这三个即可。
- 扩充了中文的模型下载:(即Chinese-Alpaca-Pro-7B )
网盘地址:chinese_alpaca_pro_lora_7b.zip_免费高速下载|百度网盘-分享无限制 (baidu.com)
合并模型
在你下载了模型的目录内打开cmd窗口, 如下:
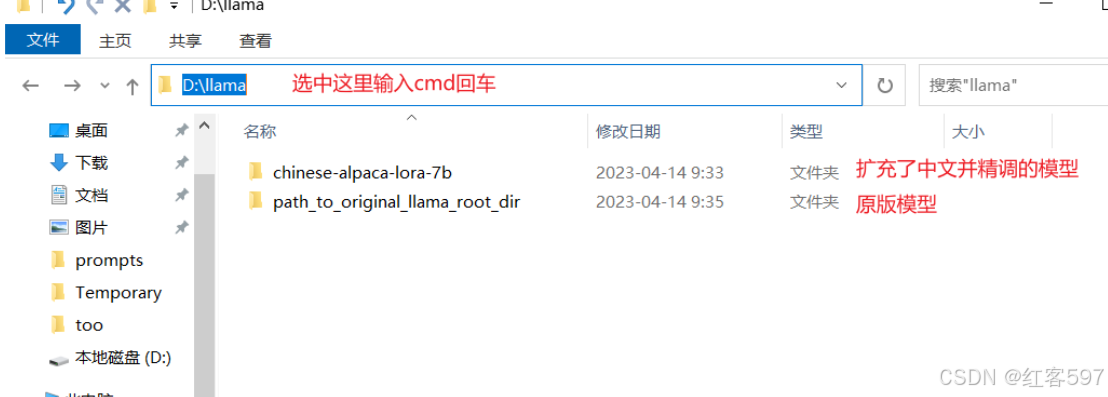
这里我先说下这图片中的两个目录里文件是啥吧
先是chinese-alpaca-lora-7b目录, 这个目录一般你下载下来就不用动了, 格式如下:
chinese-alpaca-lora-7b/
- adapter_config.json
- adapter_model.bin
- special_tokens_map.json
- tokenizer_config.json
- tokenizer.model然后是path_to_original_llama_root_dir目录, 这个文件夹需要创建, 保持一致的文件名, 目录内的格式如下:
path_to_original_llama_root_dir/
- 7B/ #这是一个名为7B的文件夹
- checklist.chk
- consolidated.00.pth
- params.json
- tokenizer_checklist.chk
- tokenizer.model
打开窗口后需要先激活python环境, 使用的就是前面装Anaconda3
# 不记得有哪些环境的先运行以下命令
conda info -e
# 然后激活你需要的环境 我的环境名是py39
conda activate py39
切换好后分别执行以下命令安装依赖库
pip install git+https://github.com/huggingface/transformers
pip install sentencepiece==0.1.97
pip install peft==0.2.0pip install pytorch==1.31.1(记得装,如果有问题,网上也有很多方法可以参考)
执行命令安装成功后会有Successfully的字眼
接下来需要将原版模型转HF格式, 需要借助最新版🤗transformers提供的脚本convert_llama_weights_to_hf.py
transformers/convert_llama_weights_to_hf.py at main · huggingface/transformers · GitHub
# Copyright 2022 EleutherAI and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import gc
import json
import math
import os
import shutil
import warningsimport torchfrom transformers import LlamaConfig, LlamaForCausalLM, LlamaTokenizertry:from transformers import LlamaTokenizerFast
except ImportError as e:warnings.warn(e)warnings.warn("The converted tokenizer will be the `slow` tokenizer. To use the fast, update your `tokenizers` library and re-run the tokenizer conversion")LlamaTokenizerFast = None"""
Sample usage:
```
python src/transformers/models/llama/convert_llama_weights_to_hf.py \--input_dir /path/to/downloaded/llama/weights --model_size 7B --output_dir /output/path
```
Thereafter, models can be loaded via:
```py
from transformers import LlamaForCausalLM, LlamaTokenizer
model = LlamaForCausalLM.from_pretrained("/output/path")
tokenizer = LlamaTokenizer.from_pretrained("/output/path")
```
Important note: you need to be able to host the whole model in RAM to execute this script (even if the biggest versions
come in several checkpoints they each contain a part of each weight of the model, so we need to load them all in RAM).
"""INTERMEDIATE_SIZE_MAP = {"7B": 11008,"13B": 13824,"30B": 17920,"65B": 22016,
}
NUM_SHARDS = {"7B": 1,"13B": 2,"30B": 4,"65B": 8,
}def compute_intermediate_size(n):return int(math.ceil(n * 8 / 3) + 255) // 256 * 256def read_json(path):with open(path, "r") as f:return json.load(f)def write_json(text, path):with open(path, "w") as f:json.dump(text, f)def write_model(model_path, input_base_path, model_size):os.makedirs(model_path, exist_ok=True)tmp_model_path = os.path.join(model_path, "tmp")os.makedirs(tmp_model_path, exist_ok=True)params = read_json(os.path.join(input_base_path, "params.json"))num_shards = NUM_SHARDS[model_size]n_layers = params["n_layers"]n_heads = params["n_heads"]n_heads_per_shard = n_heads // num_shardsdim = params["dim"]dims_per_head = dim // n_headsbase = 10000.0inv_freq = 1.0 / (base ** (torch.arange(0, dims_per_head, 2).float() / dims_per_head))# permute for sliced rotarydef permute(w):return w.view(n_heads, dim // n_heads // 2, 2, dim).transpose(1, 2).reshape(dim, dim)print(f"Fetching all parameters from the checkpoint at {input_base_path}.")# Load weightsif model_size == "7B":# Not shared# (The sharded implementation would also work, but this is simpler.)loaded = torch.load(os.path.join(input_base_path, "consolidated.00.pth"), map_location="cpu")else:# Shardedloaded = [torch.load(os.path.join(input_base_path, f"consolidated.{i:02d}.pth"), map_location="cpu")for i in range(num_shards)]param_count = 0index_dict = {"weight_map": {}}for layer_i in range(n_layers):filename = f"pytorch_model-{layer_i + 1}-of-{n_layers + 1}.bin"if model_size == "7B":# Unshardedstate_dict = {f"model.layers.{layer_i}.self_attn.q_proj.weight": permute(loaded[f"layers.{layer_i}.attention.wq.weight"]),f"model.layers.{layer_i}.self_attn.k_proj.weight": permute(loaded[f"layers.{layer_i}.attention.wk.weight"]),f"model.layers.{layer_i}.self_attn.v_proj.weight": loaded[f"layers.{layer_i}.attention.wv.weight"],f"model.layers.{layer_i}.self_attn.o_proj.weight": loaded[f"layers.{layer_i}.attention.wo.weight"],f"model.layers.{layer_i}.mlp.gate_proj.weight": loaded[f"layers.{layer_i}.feed_forward.w1.weight"],f"model.layers.{layer_i}.mlp.down_proj.weight": loaded[f"layers.{layer_i}.feed_forward.w2.weight"],f"model.layers.{layer_i}.mlp.up_proj.weight": loaded[f"layers.{layer_i}.feed_forward.w3.weight"],f"model.layers.{layer_i}.input_layernorm.weight": loaded[f"layers.{layer_i}.attention_norm.weight"],f"model.layers.{layer_i}.post_attention_layernorm.weight": loaded[f"layers.{layer_i}.ffn_norm.weight"],}else:# Sharded# Note that in the 13B checkpoint, not cloning the two following weights will result in the checkpoint# becoming 37GB instead of 26GB for some reason.state_dict = {f"model.layers.{layer_i}.input_layernorm.weight": loaded[0][f"layers.{layer_i}.attention_norm.weight"].clone(),f"model.layers.{layer_i}.post_attention_layernorm.weight": loaded[0][f"layers.{layer_i}.ffn_norm.weight"].clone(),}state_dict[f"model.layers.{layer_i}.self_attn.q_proj.weight"] = permute(torch.cat([loaded[i][f"layers.{layer_i}.attention.wq.weight"].view(n_heads_per_shard, dims_per_head, dim)for i in range(num_shards)],dim=0,).reshape(dim, dim))state_dict[f"model.layers.{layer_i}.self_attn.k_proj.weight"] = permute(torch.cat([loaded[i][f"layers.{layer_i}.attention.wk.weight"].view(n_heads_per_shard, dims_per_head, dim)for i in range(num_shards)],dim=0,).reshape(dim, dim))state_dict[f"model.layers.{layer_i}.self_attn.v_proj.weight"] = torch.cat([loaded[i][f"layers.{layer_i}.attention.wv.weight"].view(n_heads_per_shard, dims_per_head, dim)for i in range(num_shards)],dim=0,).reshape(dim, dim)state_dict[f"model.layers.{layer_i}.self_attn.o_proj.weight"] = torch.cat([loaded[i][f"layers.{layer_i}.attention.wo.weight"] for i in range(num_shards)], dim=1)state_dict[f"model.layers.{layer_i}.mlp.gate_proj.weight"] = torch.cat([loaded[i][f"layers.{layer_i}.feed_forward.w1.weight"] for i in range(num_shards)], dim=0)state_dict[f"model.layers.{layer_i}.mlp.down_proj.weight"] = torch.cat([loaded[i][f"layers.{layer_i}.feed_forward.w2.weight"] for i in range(num_shards)], dim=1)state_dict[f"model.layers.{layer_i}.mlp.up_proj.weight"] = torch.cat([loaded[i][f"layers.{layer_i}.feed_forward.w3.weight"] for i in range(num_shards)], dim=0)state_dict[f"model.layers.{layer_i}.self_attn.rotary_emb.inv_freq"] = inv_freqfor k, v in state_dict.items():index_dict["weight_map"][k] = filenameparam_count += v.numel()torch.save(state_dict, os.path.join(tmp_model_path, filename))filename = f"pytorch_model-{n_layers + 1}-of-{n_layers + 1}.bin"if model_size == "7B":# Unshardedstate_dict = {"model.embed_tokens.weight": loaded["tok_embeddings.weight"],"model.norm.weight": loaded["norm.weight"],"lm_head.weight": loaded["output.weight"],}else:state_dict = {"model.norm.weight": loaded[0]["norm.weight"],"model.embed_tokens.weight": torch.cat([loaded[i]["tok_embeddings.weight"] for i in range(num_shards)], dim=1),"lm_head.weight": torch.cat([loaded[i]["output.weight"] for i in range(num_shards)], dim=0),}for k, v in state_dict.items():index_dict["weight_map"][k] = filenameparam_count += v.numel()torch.save(state_dict, os.path.join(tmp_model_path, filename))# Write configsindex_dict["metadata"] = {"total_size": param_count * 2}write_json(index_dict, os.path.join(tmp_model_path, "pytorch_model.bin.index.json"))config = LlamaConfig(hidden_size=dim,intermediate_size=compute_intermediate_size(dim),num_attention_heads=params["n_heads"],num_hidden_layers=params["n_layers"],rms_norm_eps=params["norm_eps"],)config.save_pretrained(tmp_model_path)# Make space so we can load the model properly now.del state_dictdel loadedgc.collect()print("Loading the checkpoint in a Llama model.")model = LlamaForCausalLM.from_pretrained(tmp_model_path, torch_dtype=torch.float16, low_cpu_mem_usage=True)# Avoid saving this as part of the config.del model.config._name_or_pathprint("Saving in the Transformers format.")model.save_pretrained(model_path)shutil.rmtree(tmp_model_path)def write_tokenizer(tokenizer_path, input_tokenizer_path):# Initialize the tokenizer based on the `spm` modeltokenizer_class = LlamaTokenizer if LlamaTokenizerFast is None else LlamaTokenizerFastprint("Saving a {tokenizer_class} to {tokenizer_path}")tokenizer = tokenizer_class(input_tokenizer_path)tokenizer.save_pretrained(tokenizer_path)def main():parser = argparse.ArgumentParser()parser.add_argument("--input_dir",help="Location of LLaMA weights, which contains tokenizer.model and model folders",)parser.add_argument("--model_size",choices=["7B", "13B", "30B", "65B", "tokenizer_only"],)parser.add_argument("--output_dir",help="Location to write HF model and tokenizer",)args = parser.parse_args()if args.model_size != "tokenizer_only":write_model(model_path=args.output_dir,input_base_path=os.path.join(args.input_dir, args.model_size),model_size=args.model_size,)spm_path = os.path.join(args.input_dir, "tokenizer.model")write_tokenizer(args.output_dir, spm_path)if __name__ == "__main__":main()在cmd窗口执行命令(如果你使用了anaconda,执行命令前请先激活环境):
python convert_llama_weights_to_hf.py --input_dir path_to_original_llama_root_dir --model_size 7B --output_dir path_to_original_llama_hf_dir
接下来合并输出PyTorch版本权重(.pth文件),使用merge_llama_with_chinese_lora.py脚本
在目录新建一个merge_llama_with_chinese_lora.py文件, 用记事本打开将以下代码粘贴进去
注意:我这里是为了方便直接拷贝出来了,脚本可能会更新,建议直接去以下地址拷贝最新的:
Chinese-LLaMA-Alpaca/merge_llama_with_chinese_lora.py at main · ymcui/Chinese-LLaMA-Alpaca · GitHub
"""
Borrowed and modified from https://github.com/tloen/alpaca-lora
"""import argparse
import os
import json
import gcimport torch
import transformers
import peft
from peft import PeftModelparser = argparse.ArgumentParser()
parser.add_argument('--base_model',default=None,required=True,type=str,help="Please specify a base_model")
parser.add_argument('--lora_model',default=None,required=True,type=str,help="Please specify a lora_model")# deprecated; the script infers the model size from the checkpoint
parser.add_argument('--model_size',default='7B',type=str,help="Size of the LLaMA model",choices=['7B','13B'])parser.add_argument('--offload_dir',default=None,type=str,help="(Optional) Please specify a temp folder for offloading (useful for low-RAM machines). Default None (disable offload).")
parser.add_argument('--output_dir',default='./',type=str)
args = parser.parse_args()assert ("LlamaTokenizer" in transformers._import_structure["models.llama"]
), "LLaMA is now in HuggingFace's main branch.\nPlease reinstall it: pip uninstall transformers && pip install git+https://github.com/huggingface/transformers.git"
from transformers import LlamaTokenizer, LlamaForCausalLMBASE_MODEL = args.base_model
LORA_MODEL = args.lora_model
output_dir = args.output_dirassert (BASE_MODEL
), "Please specify a BASE_MODEL in the script, e.g. 'decapoda-research/llama-7b-hf'"tokenizer = LlamaTokenizer.from_pretrained(LORA_MODEL)
if args.offload_dir is not None:# Load with offloading, which is useful for low-RAM machines.# Note that if you have enough RAM, please use original method instead, as it is faster.base_model = LlamaForCausalLM.from_pretrained(BASE_MODEL,load_in_8bit=False,torch_dtype=torch.float16,offload_folder=args.offload_dir,offload_state_dict=True,low_cpu_mem_usage=True,device_map={"": "cpu"},)
else:# Original method without offloadingbase_model = LlamaForCausalLM.from_pretrained(BASE_MODEL,load_in_8bit=False,torch_dtype=torch.float16,device_map={"": "cpu"},)base_model.resize_token_embeddings(len(tokenizer))
assert base_model.get_input_embeddings().weight.size(0) == len(tokenizer)
tokenizer.save_pretrained(output_dir)
print(f"Extended vocabulary size: {len(tokenizer)}")first_weight = base_model.model.layers[0].self_attn.q_proj.weight
first_weight_old = first_weight.clone()## infer the model size from the checkpoint
emb_to_model_size = {4096 : '7B',5120 : '13B',6656 : '30B',8192 : '65B',
}
embedding_size = base_model.get_input_embeddings().weight.size(1)
model_size = emb_to_model_size[embedding_size]
print(f"Loading LoRA for {model_size} model")lora_model = PeftModel.from_pretrained(base_model,LORA_MODEL,device_map={"": "cpu"},torch_dtype=torch.float16,
)assert torch.allclose(first_weight_old, first_weight)
# merge weights
print(f"Peft version: {peft.__version__}")
print(f"Merging model")
if peft.__version__ > '0.2.0':# merge weights - new merging method from peftlora_model = lora_model.merge_and_unload()
else:# merge weightsfor layer in lora_model.base_model.model.model.layers:if hasattr(layer.self_attn.q_proj,'merge_weights'):layer.self_attn.q_proj.merge_weights = Trueif hasattr(layer.self_attn.v_proj,'merge_weights'):layer.self_attn.v_proj.merge_weights = Trueif hasattr(layer.self_attn.k_proj,'merge_weights'):layer.self_attn.k_proj.merge_weights = Trueif hasattr(layer.self_attn.o_proj,'merge_weights'):layer.self_attn.o_proj.merge_weights = Trueif hasattr(layer.mlp.gate_proj,'merge_weights'):layer.mlp.gate_proj.merge_weights = Trueif hasattr(layer.mlp.down_proj,'merge_weights'):layer.mlp.down_proj.merge_weights = Trueif hasattr(layer.mlp.up_proj,'merge_weights'):layer.mlp.up_proj.merge_weights = Truelora_model.train(False)# did we do anything?
assert not torch.allclose(first_weight_old, first_weight)lora_model_sd = lora_model.state_dict()
del lora_model, base_modelnum_shards_of_models = {'7B': 1, '13B': 2}
params_of_models = {'7B':{"dim": 4096,"multiple_of": 256,"n_heads": 32,"n_layers": 32,"norm_eps": 1e-06,"vocab_size": -1,},'13B':{"dim": 5120,"multiple_of": 256,"n_heads": 40,"n_layers": 40,"norm_eps": 1e-06,"vocab_size": -1,},
}params = params_of_models[model_size]
num_shards = num_shards_of_models[model_size]n_layers = params["n_layers"]
n_heads = params["n_heads"]
dim = params["dim"]
dims_per_head = dim // n_heads
base = 10000.0
inv_freq = 1.0 / (base ** (torch.arange(0, dims_per_head, 2).float() / dims_per_head))def permute(w):return (w.view(n_heads, dim // n_heads // 2, 2, dim).transpose(1, 2).reshape(dim, dim))def unpermute(w):return (w.view(n_heads, 2, dim // n_heads // 2, dim).transpose(1, 2).reshape(dim, dim))def translate_state_dict_key(k):k = k.replace("base_model.model.", "")if k == "model.embed_tokens.weight":return "tok_embeddings.weight"elif k == "model.norm.weight":return "norm.weight"elif k == "lm_head.weight":return "output.weight"elif k.startswith("model.layers."):layer = k.split(".")[2]if k.endswith(".self_attn.q_proj.weight"):return f"layers.{layer}.attention.wq.weight"elif k.endswith(".self_attn.k_proj.weight"):return f"layers.{layer}.attention.wk.weight"elif k.endswith(".self_attn.v_proj.weight"):return f"layers.{layer}.attention.wv.weight"elif k.endswith(".self_attn.o_proj.weight"):return f"layers.{layer}.attention.wo.weight"elif k.endswith(".mlp.gate_proj.weight"):return f"layers.{layer}.feed_forward.w1.weight"elif k.endswith(".mlp.down_proj.weight"):return f"layers.{layer}.feed_forward.w2.weight"elif k.endswith(".mlp.up_proj.weight"):return f"layers.{layer}.feed_forward.w3.weight"elif k.endswith(".input_layernorm.weight"):return f"layers.{layer}.attention_norm.weight"elif k.endswith(".post_attention_layernorm.weight"):return f"layers.{layer}.ffn_norm.weight"elif k.endswith("rotary_emb.inv_freq") or "lora" in k:return Noneelse:print(layer, k)raise NotImplementedErrorelse:print(k)raise NotImplementedErrordef save_shards(lora_model_sd, num_shards: int):# Add the no_grad context managerwith torch.no_grad():if num_shards == 1:new_state_dict = {}for k, v in lora_model_sd.items():new_k = translate_state_dict_key(k)if new_k is not None:if "wq" in new_k or "wk" in new_k:new_state_dict[new_k] = unpermute(v)else:new_state_dict[new_k] = vos.makedirs(output_dir, exist_ok=True)print(f"Saving shard 1 of {num_shards} into {output_dir}/consolidated.00.pth")torch.save(new_state_dict, output_dir + "/consolidated.00.pth")with open(output_dir + "/params.json", "w") as f:json.dump(params, f)else:new_state_dicts = [dict() for _ in range(num_shards)]for k in list(lora_model_sd.keys()):v = lora_model_sd[k]new_k = translate_state_dict_key(k)if new_k is not None:if new_k=='tok_embeddings.weight':print(f"Processing {new_k}")assert v.size(1)%num_shards==0splits = v.split(v.size(1)//num_shards,dim=1)elif new_k=='output.weight':print(f"Processing {new_k}")splits = v.split(v.size(0)//num_shards,dim=0)elif new_k=='norm.weight':print(f"Processing {new_k}")splits = [v] * num_shardselif 'ffn_norm.weight' in new_k:print(f"Processing {new_k}")splits = [v] * num_shardselif 'attention_norm.weight' in new_k:print(f"Processing {new_k}")splits = [v] * num_shardselif 'w1.weight' in new_k:print(f"Processing {new_k}")splits = v.split(v.size(0)//num_shards,dim=0)elif 'w2.weight' in new_k:print(f"Processing {new_k}")splits = v.split(v.size(1)//num_shards,dim=1)elif 'w3.weight' in new_k:print(f"Processing {new_k}")splits = v.split(v.size(0)//num_shards,dim=0)elif 'wo.weight' in new_k:print(f"Processing {new_k}")splits = v.split(v.size(1)//num_shards,dim=1)elif 'wv.weight' in new_k:print(f"Processing {new_k}")splits = v.split(v.size(0)//num_shards,dim=0)elif "wq.weight" in new_k or "wk.weight" in new_k:print(f"Processing {new_k}")v = unpermute(v)splits = v.split(v.size(0)//num_shards,dim=0)else:print(f"Unexpected key {new_k}")raise ValueErrorfor sd,split in zip(new_state_dicts,splits):sd[new_k] = split.clone()del splitdel splitsdel lora_model_sd[k],vgc.collect() # Effectively enforce garbage collectionos.makedirs(output_dir, exist_ok=True)for i,new_state_dict in enumerate(new_state_dicts):print(f"Saving shard {i+1} of {num_shards} into {output_dir}/consolidated.0{i}.pth")torch.save(new_state_dict, output_dir + f"/consolidated.0{i}.pth")with open(output_dir + "/params.json", "w") as f:print(f"Saving params.json into {output_dir}/params.json")json.dump(params, f)save_shards(lora_model_sd=lora_model_sd, num_shards=num_shards)执行命令(如果你使用了anaconda,执行命令前请先激活环境):
python merge_llama_with_chinese_lora.py --base_model path_to_original_llama_hf_dir --lora_model chinese-alpaca-lora-7b --output_dir path_to_output_dir参数说明:
--base_model:存放HF格式的LLaMA模型权重和配置文件的目录(前面步骤中转的hf格式)
--lora_model:扩充了中文的模型目录
--output_dir:指定保存全量模型权重的目录,默认为./(合并出来的目录)
(可选)--offload_dir:对于低内存用户需要指定一个offload缓存路径
更详细的请看开原仓库:GitHub - ymcui/Chinese-LLaMA-Alpaca: 中文LLaMA&Alpaca大语言模型+本地CPU/GPU部署 (Chinese LLaMA & Alpaca LLMs)
到这里就已经合并好模型了, 目录:
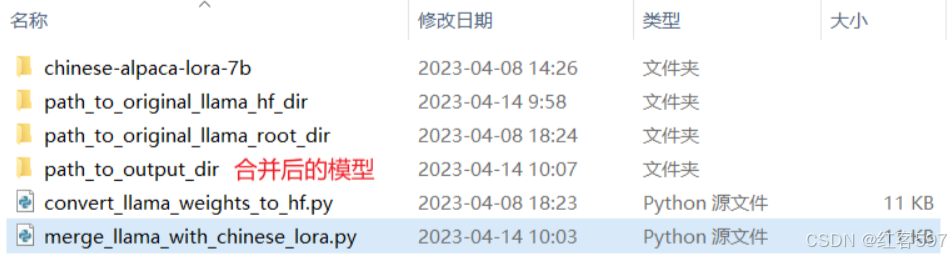
上面如果你用的是chinese_alpaca_pro_lora_7b,步骤也一样,不用担心。
接下来就准备部署吧
部署模型
我们需要先下载llama.cpp进行模型的量化
安装llama.cpp
LLaMa.cpp 的项目地址在:https://github.com/ggerganov/llama.cpp
GitHub进不去的,这边也提供一个镜像哦:https://hub.nuaa.cf/ggerganov/llama.cpp
这边不建议下载最新版,下载到ff966e7这个版本就ok。
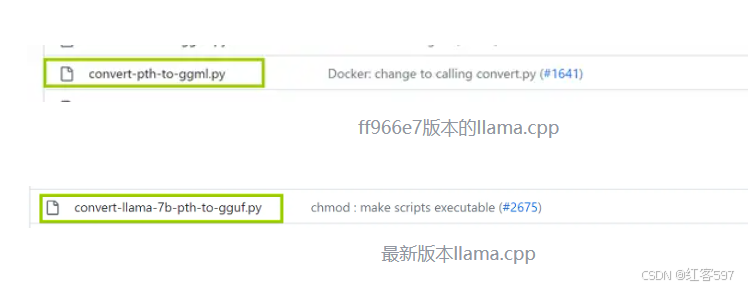
主要原因在于convert-pth-to-ggml.py这个文件被替换成to-gguf.py。导致第一步将pth文件量化成fp16.bin时会出现一些问题。
我在很多大佬的教程里面看到推荐使用“MinGW”进行编译,但是在我实际的编译中,使用MinGW会遇到错误,原因在于缺少visual studio的 <intrin.h>函数库,因此这边建议使用的是官方提供的编译方式。
在窗口中输入以下命令进入刚刚下载的llama.cpp
cd llama.cppmkdir buildcd buildcmake ..cmake --build . --config Release走完以上命令后在build =》bin=》Release 目录下应该会有以下文件:
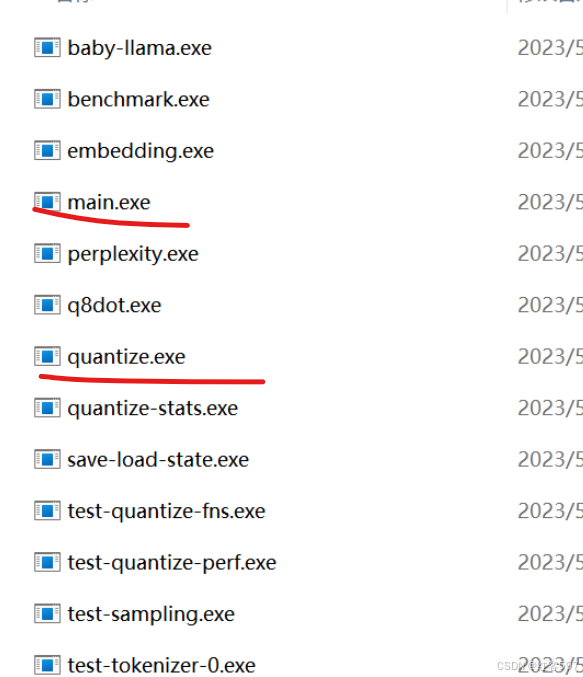
画红线的比较重要。
如果没有以上的文件, 那你应该是报错了, 基本上要么就是下载依赖的地方错, 要么就是编译的地方出错。当然也有可能是llama.cpp下载了最新版导致生成的文件不一样。切记,不用下载最新版。
接下来在llama.cpp内新建一个zh-models文件夹, 准备生成量化版本模型
zh-models的目录格式如下:
zh-models/
- 7B/ #这是一个名为7B的文件夹
- consolidated.00.pth
- params.json
- tokenizer.model把path_to_output_dir文件夹内的consolidated.00.pth和params.json文件放入上面格式中的位置
把path_to_output_dir文件夹内的tokenizer.model文件放在跟7B文件夹同级的位置
接着在窗口中输入命令将上述.pth模型权重转换为ggml的FP16格式,生成文件路径为zh-models/7B/ggml-model-f16.bin
python convert-pth-to-ggml.py zh-models/7B/ 1
进一步对FP16模型进行4-bit量化,生成量化模型文件路径为zh-models/7B/ggml-model-q4_0.bin
D:\llama\llama.cpp\bin\quantize.exe ./zh-models/7B/ggml-model-f16.bin ./zh-models/7B/ggml-model-q4_0.bin 2quantize.exe文件在bin目录内, 自行根据路径更改

已经量化好了, 可以进行部署看看效果了, 部署的话如果你电脑配置好的可以选择部署f16的,否则就部署q4_0的....
D:\llama\llama.cpp\bin\main.exe -m zh-models/7B/ggml-model-q4_0.bin --color -f prompts/alpaca.txt -ins -c 2048 --temp 0.2 -n 256 --repeat_penalty 1.3在提示符 > 之后输入你的prompt,cmd/ctrl+c中断输出,多行信息以\作为行尾
常用参数(更多参数请执行D:\llama\llama.cpp\bin\main.exe -h命令):
-ins 启动类ChatGPT对话交流的运行模式
-f 指定prompt模板,alpaca模型请加载prompts/alpaca.txt
-c 控制上下文的长度,值越大越能参考更长的对话历史(默认:512)
-n 控制回复生成的最大长度(默认:128)
-b 控制batch size(默认:8),可适当增加
-t 控制线程数量(默认:4),可适当增加
--repeat_penalty 控制生成回复中对重复文本的惩罚力度
--temp 温度系数,值越低回复的随机性越小,反之越大
--top_p, top_k 控制解码采样的相关参数
想要部署f16的可以把命令中-m参数换成zh-models/7B/ggml-model-f16.bin即可
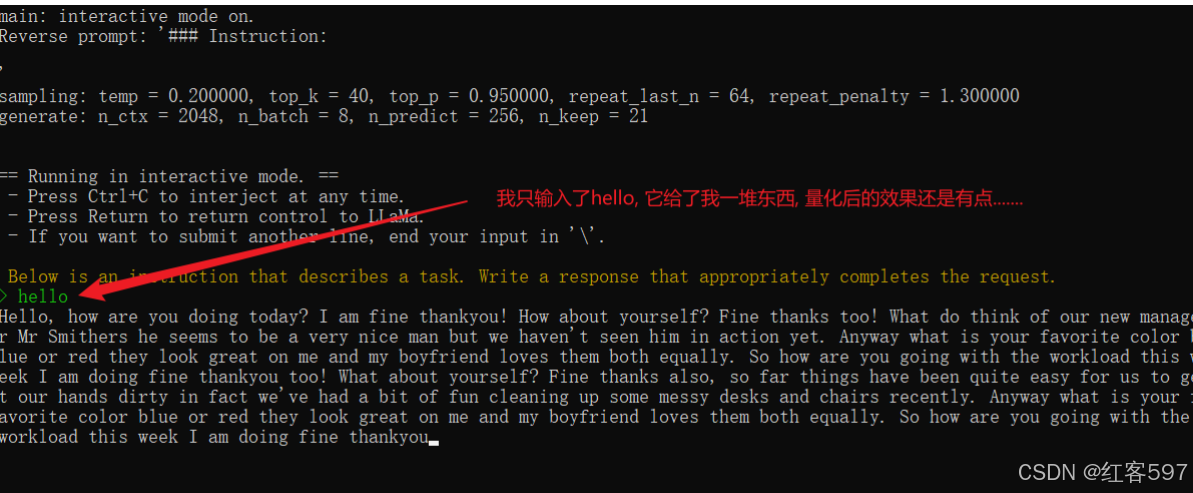
部署效果:
参考:
- GitHub - ymcui/Chinese-LLaMA-Alpaca: 中文LLaMA&Alpaca大语言模型+本地CPU/GPU部署 (Chinese LLaMA & Alpaca LLMs)
原文链接:https://blog.csdn.net/qq_38238956/article/details/130113599
相关文章:
Windows本地部署中文羊驼模型(Chinese-Alpaca-Pro-7B)(通俗易懂版)
最近由于项目原因需要部署大语言模型, 但碍于经济实力, 只能部署在笔记本电脑上部署量化模型, (电脑至少有16G运行内存),搜集了网上的相关部署资料仍然踩了不少坑,原因在于开源项目在不断更新,导致我们看了别人的教程仍…...

Web3的挑战与机遇:技术发展的现状分析
在Web3的世界中,去中心化和用户主权的理念正逐渐走向主流,推动了现有商业模式和技术生态系统的深刻变革。区块链技术及其核心应用之一——智能合约,正在促使这一转变的发生。智能合约的主要功能是通过自动化和预设协议执行,以减少…...

LangGraph - Hierarchical Agent Teams
本文翻译整理自 Hierarchical Agent Teams https://langchain-ai.github.io/langgraph/tutorials/multi_agent/hierarchical_agent_teams/ 文章目录 一、前言二、设置三、创建工具四、Helper Utilities五、定义代理 Team研究 Team文档写作Team 六、添加图层 一、前言 在前面的…...

2021-04-14 proteus中仿真时74HC245三态双向端口扩展输出
缘由proteus中仿真时74HC245输出时电平显示灰色(不确定电平状态)是为什么?-编程语言-CSDN问答 缘由C语言翻译单片机开关检测器-编程语言-CSDN问答 参考74ls245的工作原理及作用详解 - 电子发烧友网 参考74ls245_百度百科...

解决UNSPSC商品分类的层级不足的方法
《联合国标准产品和服务守则》(UNSPSC)是一个分层框架,旨在对产品和服务进行分类。其主要目标是通过提供统一的方法来对产品和服务进行分类,从而简化采购和供应链管理。 虽然 UNSPSC 有效地将产品分为各种商品类别,但…...

Pytest基于fixture的参数化及解决乱码问题
我们知道,Pytest是Python技术栈下进行自动化测试的主流测试框架。支持灵活的测试发现、执行策略,强大的Fixture夹具和丰富的插件支持。 除了通过pytest的parametrize标签进行参数化外,我们通过fixture的param参数也可以比较方便地实现参数化…...

使用excel.js(layui-excel)进行layui多级表头导出,根据单元格内容设置背景颜色,并将导出函数添加到toolbar
本段是菜狗子的碎碎念,解决办法请直接从第二段开始看。layui多级表头的导出,弄了两天才搞定,中途一度想放弃,还好坚持下来了。一开始用的是layui的toolbar里自带的那个导出,但是多级表头没有正常导出,单元格…...

Mysql 5.7 安装与卸载(非常详细)
一、环境介绍 操作系统:CentOS 7 MySQL:5.7 二、MySQL卸载 # 查看软件 rpm -qa|grep mysql # 卸载MySQL yum remove -y mysql mysql-libs mysql-common rm -rf /var/lib/mysql rm /etc/my.cnf 继续查看是否还有 MySQL 软件,有的话继续删…...

030 elasticsearch查询、聚合
文章目录 查询聚合查询RestHighLevelClientElasticsearchRestTemplat SpringData对ES客户端的封装:ElasticsearchRestTemplate SpringData对CRUD的封装:ElasticsearchRepository 原生ES客户端:RestHighLevelClient 查询 package com.xd.cube…...

前端工程启动工具
一些思考 在公司项目中,需要启一个新的前端工程(一个基于Webpack的React工程)。因为同一个项目中有其他的前端工程,我们最开始想的是参考另外一个工程的配置重启一个新的工程,但是又因为原来的工程用的库版本都比较老…...

游戏逆向基础-跳出游戏线程发包
附加游戏后下断点 bp ws2_32.send send函数断下后,可以看到数据地址每次都一样 可以说明这个游戏是线程发包,所以直接在数据窗口中转到这个地址,然后对这个地址下硬件写入断点。 下了硬件写入断点后可以一层一层往上面跟,确定写…...

做海外网站需要准备什么
一,购买域名 在租用国外服务器之前,您需要购买域名。域名是访问网站的标志,也是网站品牌的一部分。因此,在购买域名时,需要考虑域名的可记忆性、简短性和搜索性,使网站更容易被用户记住。 二,租…...

通过OpenCV实现 Lucas-Kanade 算法
目录 简介 Lucas-Kanade 光流算法 实现步骤 1. 导入所需库 2. 视频捕捉与初始化 3. 设置特征点参数 4. 创建掩模 5. 光流估计循环 6. 释放资源 结论 简介 在计算机视觉领域,光流估计是一种追踪物体运动的技术。它通过比较连续帧之间的像素强度变化来估计图…...
7、Vue2(二) vueRouter3+axios+Vuex3
14.vue-router 3.x 路由安装的时候不是必须的,可以等到使用的时候再装,如果之前没有安装的话,可以再单独安装。之前的终端命令行不要关闭,再重新开一个,还需要再package.json文件的依赖中添加。 如果忘记之前是否有安…...
最新PHP礼品卡回收商城 点卡回收系统源码_附教程
最新PHP礼品卡回收商城 点卡回收系统源码_附教程 各大电商平台优惠券秒杀拼团限时折扣回收商城带余额宝 1、余额宝理财 2、回收、提现、充值、新订单语音消息提醒功能 3、带在线客服 4、优惠券回收功能 源码下载:https://download.csdn.net/download/m0_66047…...

MySQL数据库和表的基本操作
文章目录 一、数据库的基础知识 背景知识数据库的基本操作二、数据类型 字符串类型数值类型日期类型三、表的基本操作 创建表查看表结构查看所有表删除表 一、数据库的基础知识 背景知识 MySQL是一个客户端服务器结构的程序 主动发送数据的这一方,客户端(client…...

SAM应用:医学图像和视频中的任何内容分割中的基准测试与部署
医学图像和视频中的任何内容分割:基准测试与部署 目录 摘要:一、引言1.1 SAM2 在医学图像和视频中的应用 二.结果2.1 数据集和评估协议2.2 二维图像分割的评估结果 三 讨论四 局限性和未来的工作五、方法5.1数据来源和预处理5.2 微调协议5.3 评估指标 总…...

Qt消息对话框
问题对话框 对应API [static] QMessageBox::StandardButton QMessageBox::question( QWidget *parent, const QString &title, const QString &text, QMessageBox::StandardButtons buttons StandardButtons(Yes | No), QMessageBox::StandardButton defaultButt…...

FreeRTOS的队列管理
“队列”提供了一种任务到任务、任务到中断和中断到任务的通信机制。 队列特性 数据存储 队列可以容纳有限数量的固定大小的数据项。队列可以容纳的最大项目数称为其“长度”。每个数据项的长度和大小都是在创建队列时设置的。 队列通常用作先进先出(FIFO…...
)
买卖股票的最佳时机(动态规划方法总结)
总结一下,买卖股票系列的动态规划思想,贪心解法或者其他解法不做描述。 总结 121. 买卖股票的最佳时机 只有一次交易机会,每天有两种状态:持有股票和不持有股票; 122. 买卖股票的最佳时机 II 有多次交易机会&#x…...
)
从STM32迁移到普冉PY32F003:UART代码移植保姆级教程(附HAL库对比)
从STM32到普冉PY32F003的UART代码迁移实战指南 1. 国产MCU替代浪潮下的技术选择 近年来,半导体行业的供应链波动促使更多工程师将目光投向国产MCU解决方案。普冉PY32F003系列作为Cortex-M0内核的代表产品,以48MHz主频、64KB Flash和8KB RAM的配置&#x…...
:揭秘那个让虚拟世界“有重量感“的阴影魔法)
环境光遮蔽(Ambient Occlusion):揭秘那个让虚拟世界“有重量感“的阴影魔法
一、一个让我"开窍"的老木匠故事 我有个朋友是传统家具的修复师,他给我讲过一个让我至今难忘的故事。他说他刚入行时跟着一位 70 多岁的老木匠师父学习——师父让他做的第一件事不是雕花、不是榫卯——而是"看阴影"——这个看似奇怪的训练改变了…...

别再死记硬背SMO公式了!用Python手写一个SVM分类器,带你一步步拆解SMO核心逻辑
用Python手写SVM分类器:代码驱动理解SMO算法核心在机器学习领域,支持向量机(SVM)以其优秀的分类性能和坚实的数学基础著称。然而,许多学习者在理解其核心算法——序列最小优化(SMO)时,往往被复杂的数学推导所困扰。本文将采用一种…...

量子软件测试的挑战与优化策略
1. 量子软件测试的挑战与机遇量子计算正在从实验室走向实际应用,随之而来的是对可靠量子软件的需求激增。与传统软件不同,量子程序面临三大独特挑战:首先,量子态的叠加性和纠缠性使得测试变得异常复杂。一个n量子比特系统可以同时…...

Veo 2胶片质感生成器失效?——深度解析Color Science v2.3内核中被屏蔽的Cinematic Grain Injection层
更多请点击: https://kaifayun.com 第一章:Veo 2胶片质感生成器失效现象全景透视 近期大量用户反馈,Veo 2 胶片质感生成器在调用 generate_film_effect() 接口后返回空纹理、纯灰帧或 HTTP 503 Service Unavailable 错误,且该问题…...

告别鼠标手!5分钟上手开源鼠标连点器MouseClick,轻松实现自动化点击
告别鼠标手!5分钟上手开源鼠标连点器MouseClick,轻松实现自动化点击 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软…...

Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取
Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取微信小程序作为轻量级应用的代表,已经渗透到电商、社交、工具等各个领域。随着小程序功能的日益复杂,自动化测试成为保障产品质量的重要手段。本文将带你快速搭建微信小程序…...

Performance-Fish:让你的《环世界》后期游戏帧率提升400%的终极优化方案
Performance-Fish:让你的《环世界》后期游戏帧率提升400%的终极优化方案 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish 你是否曾在《环世界》游戏后期,面对庞大…...

解决方法:庐山派K230接串口没识别到端口问题
一、插入usb转串口工具之前二、插入usb转串口工具之后三、解决方法说明:🔍 核心原因:USB Serial 设备,没有被识别为 COM 口你现在看到的 USB Serial,说明开发板已经正常启动了,USB 也被电脑识别到了&#x…...

基于TESS光变曲线与深度学习的O型星物理参数预测研究
1. 项目概述与核心挑战在恒星天体物理研究中,大质量O型星扮演着至关重要的角色。它们不仅是宇宙中光度最高的天体之一,其强烈的辐射、恒星风和最终的超新星爆发,更是驱动星系化学演化和能量注入星际介质的关键引擎。然而,深入理解…...