深度解析Transformer:从自注意力到MLP的工作机制
深度解析Transformer:从自注意力到MLP的工作机制
以下大部分内容本来自对3Blue1Brown的视频讲解的整理组织
一、Transformer的目标
为了简化问题,这里讨论的模型目标是接受一段文本,预测下一个词。这种任务对模型提出了两大要求:
- 理解上下文:模型需要根据已经出现的词,预测未来的词。
- 动态调整:模型需要根据不断变化的输入序列调整其预测。
为了实现这一目标,Transformer依赖于一种特殊的机制,即自注意力机制。
自注意力机制是什么?
自注意力机制之所以被称为“自”,是因为它处理的是同一个序列内部的词与词之间的关系。传统的RNN或CNN模型通常只能处理相邻词之间的依赖,而自注意力使得序列中的每个元素(词)都能够关注到序列中所有其他位置的元素。这使得模型能够在任何位置的词进行推理时,考虑到整个序列的上下文信息。
通过这种机制,Transformer能够更精确地处理复杂的语言模式。例如,模型在生成某个词时,既可以参考之前的所有词,也能够灵活地调整生成过程,以应对长距离依赖关系。
二、Transformer的架构概述
Transformer的整体架构可以分为三个主要部分:
- 嵌入矩阵:将输入的token(文本中的词或字符)转化为高维向量表示。
- 中间层(Attention + MLP):层层堆叠的Attention机制和多层感知机(MLP),帮助模型提取深层次语义信息。GPT-3使用了96层这种结构。
- 解嵌入矩阵:用于将最后的嵌入向量解码为输出结果,即每个词的概率分布,进而预测下一个词。
接下来我们深入理解各部分的工作原理,尤其是自注意力和多层感知机。
三、Softmax与Temperature的作用
在将模型的输出转化为词语的概率时,Transformer通常使用Softmax函数。Softmax可以将一个数列转换成一个概率分布,这样模型可以根据概率选择最可能的下一个词。然而,Softmax还引入了一个额外的调节参数,称为Temperature(温度)。
- 当T值较大时,Softmax函数会赋予较小的数值更多的权重,使得输出分布更加均匀。这意味着模型会产生较多不确定性。
- 当T值较小时,Softmax的输出更加集中,较大的数值将占据更高的权重。极端情况下,当T趋近于0时,模型几乎只考虑最大值。
Temperature在语言生成任务中的调节尤为重要,它可以控制模型生成文本时的多样性。
四、高维空间与语义方向
Transformer模型中的词被表示为嵌入向量,这些向量位于一个高维空间中。在这个空间中,不同的方向对应不同的语义。例如,一个方向可能代表“积极的情感”,另一个方向则可能表示“时间”相关的概念。
Transformer的目标是逐步调整这些嵌入向量,使它们不仅仅表示单个词的含义,还能够编码词之间的上下文关系。这种语义方向的调整使得模型能够更好地捕捉复杂的语言结构。
五、自注意力机制的工作原理
自注意力机制通过三个核心向量来实现:查询向量(Q)、键向量(K)和值向量(V)。这些向量的计算和交互是Transformer能够处理序列中任意位置的关键。
1. 查询向量(Query)
查询向量是通过将嵌入向量与查询矩阵( W q W_q Wq)相乘得到的。查询向量表示了模型当前需要提取的信息,并将嵌入空间中的词映射到低维的查询空间中。
公式如下: Q = W q × E Q=W_q×E Q=Wq×E
查询向量实际上是在低维空间中表示当前词的特定信息需求,即“当前词需要查询什么”。这个查询向量的维度通常会小于嵌入向量的维度,以便进行后续的点积计算。
2. 键向量(Key)
键向量则是通过嵌入向量与键矩阵( W k W_k Wk)相乘得到的。键向量可以看作是对查询的回答,是查询的相对参照对象。同样地,键向量将词嵌入映射到键空间中。
公式如下: K = W k × E K=W_k×E K=Wk×E
3. 查询与键的匹配
在实际计算中,模型通过计算查询向量和键向量之间的点积,来衡量它们的匹配程度。如果某个词的键向量与查询向量方向相齐,则表明这个词与查询词高度相关。
为了数值稳定性,这个点积会被除以键向量维度的平方根。接着,模型会对所有的点积结果使用Softmax进行归一化,生成匹配权重。
公式如下: Attention ( Q , K ) = Softmax ( Q × K T d k ) \text{Attention}(Q, K) = \text{Softmax}\left(\frac{Q \times K^T}{\sqrt{d_k}}\right) Attention(Q,K)=Softmax(dkQ×KT)
QK矩阵大小为上下文长度的平方,这就是为何上下文长度会成为大语言模型的巨大瓶颈。
4. 遮掩(Masking)
为了确保模型生成语言时只参考前面的词,而不使用未来的词,Transformer会在点积矩阵中对某些元素进行遮掩(Masking)。通过将某些位置的值设置为负无穷,从而在softmax后为0,以防止模型利用未来的信息进行预测。
5. 值向量(Value)
一旦得到了查询-键匹配的权重矩阵,模型就能推断出每个词与其他哪些词有关。接下来就可以把各个词的信息传递给与之相关的词,从而更新嵌入向量了。值向量就代表了每个词所包含的信息,模型通过这些值向量将上下文中其他相关词的信息传递给当前词。
值向量的计算公式如下: V = W v × E i − 1 V = W_v \times E_{i-1} V=Wv×Ei−1 其中 E i − 1 E_{i-1} Ei−1是前一个词的嵌入向量。值向量与嵌入向量在同一个维度。值矩阵乘以一个词的嵌入向量可以理解为:如果这个词需要调整目标词的含义,要反映这一点,得对目标词的embedding加入什么向量呢?
将值矩阵与所有嵌入向量E相乘就可以得到一系列值向量,同时对于每个词的那一列需要给每个值向量乘以该列对应的权重(这个权重就是QK矩阵经过softmax后的输出),然后对该列进行加和,然后再加入到原始的嵌入向量中,就得到一个更加精准的向量,编码了更丰富的上下文信息。对其他嵌入向量做同样的操作后就得到了一系列更加精准的向量。
六、从单头到多头注意力
上述的描述基于单个注意力头的工作流程。而Transformer使用的是多头注意力机制,即多个并行的注意力头同时执行上述计算。每个注意力头拥有独立的查询、键、值矩阵,生成不同的注意力模式。最终,多个注意力头的输出会被合并,形成一个更为丰富的语义表示。
在GPT-3中,每个模块内包含了96个注意力头,这些注意力头并行地执行计算,使得模型能够从不同的角度捕获词与词之间的关系。通过多头注意力机制,Transformer进一步提升了对复杂语言结构的理解能力。
七、多层感知机(MLP)模块:Transformer的事实存储核心
嵌入矩阵、Attention层、解嵌入矩阵的参数大约共占整个Transformer参数量的三分之一,剩余的三分之二则是MLP层的参数。尽管关于事实存储的完整机制尚未揭示,但有一条普适的高级结论:事实似乎存储在神经网络中的MLP模块中。例如,若一个编码了“名字迈克尔”“姓氏乔丹”的向量流入MLP,那么经过一系列计算,能够输出包含“篮球”方向的向量,再将其原向量相加,得到输出向量。
MLP模块的计算流程
MLP的处理过程可以分为以下几个步骤:
1. 升维投影
首先,经过自注意力层处理后的嵌入向量将通过一个升维矩阵,映射到一个更高维的空间。具体来说,输入向量与升维矩阵相乘。你可以将这个过程理解为从一个更广泛的角度来观察词的语义特性。每个维度代表不同的语义特征,而高维空间允许模型捕捉更多的语义细节。可以设想矩阵的每一行作为一个向量,设想第一行恰好为假想存在的“名字迈克尔”这一方向,那么输出向量的第一个分类为1(若向量编码了“名字迈克尔”)或为0或负数(没编码“名字迈克尔”),并且其他行也在并行的提问各种问题,探查嵌入向量的其他各类特征。
例如,在GPT-3中,升维矩阵的维度非常大(49152×12288),这意味着输入向量被大幅度扩展,为后续的非线性操作提供了空间。
2. 非线性变换
接下来,MLP通过一个非线性激活函数对升维后的向量进行变换。通常使用的激活函数包括ReLU或GELU。非线性函数的作用在于,处理线性变换无法捕捉的复杂语言模式。
由于语言高度非线性,经过非线性激活函数的变换后,向量的语义特性会被更加明显地分离开来。这一步骤至关重要,因为它使得模型能够处理复杂的、模糊的语义关系。
3. 降维投影
在非线性变换之后,模型将通过一个降维矩阵将向量投影回原来的嵌入维度。这一过程与升维投影类似,但逆向操作将语义特征重新压缩回嵌入空间。经过这一操作后的向量将包含更加丰富的上下文信息,这些信息是在升维和非线性激活步骤中引入的。
MLP模块的计算公式如下: MLP ( x ) = W 2 ⋅ GELU ( W 1 ⋅ x + b 1 ) + b 2 \text{MLP}(x) = W_2 \cdot \text{GELU}(W_1 \cdot x + b_1) + b_2 MLP(x)=W2⋅GELU(W1⋅x+b1)+b2
在这个公式中, W 1 W_1 W1是升维矩阵, W 2 W_2 W2是降维矩阵, b 1 和 b 2 b_1和b_2 b1和b2是偏置向量,而GELU是激活函数。
通过这一过程,MLP层将上下文信息进一步精炼,并使其能够编码更复杂的语言特征。
并行处理
值得注意的是,MLP模块的计算是用矩阵乘法并行进行的,这意味着每个嵌入向量都可以同时被处理。这样,Transformer不仅能高效处理长序列数据,还能通过多层的堆叠来逐步提高对文本的理解深度。
八、叠加(Superposition)概念与可扩展性
在大语言模型的研究中,一个引人注目的现象是,模型的神经元往往并不会单独代表一个具体的语义特征。相反,越来越多的研究发现,Transformer中的神经元往往以“叠加(Superposition)”的形式存储信息。这个概念帮助解释了为什么模型可以在较少的维度中存储大量的语义信息。
叠加的基本概念
叠加概念的核心思想是,在一个高维空间中,语义特征并不是通过彼此完全正交的向量存储的。换句话说,模型中的语义向量彼此之间不是90度垂直的,而是几乎垂直的,可能在89°到91°之间。这种近乎垂直的向量排列允许模型在有限的空间中容纳更多的语义特征。
这种特性可以通过约翰逊-林登斯特劳斯引理解释。引理表明,在高维空间中,如果放宽正交的要求,允许向量接近于垂直,那么可以存储的语义向量数量将随着维度数的增加而呈指数增长。对于大语言模型来说,这意味着即使是一个相对有限的维度空间,也能容纳数量庞大的独立语义特征。
叠加的意义
叠加现象在Transformer模型中的意义非常重大。它解释了为什么大语言模型在扩展维度时,能够以如此显著的方式提高性能。随着模型的维度增加,Transformer能够存储并处理更多复杂的语义信息。这也是为什么GPT-3等大型模型在处理复杂语言任务时表现卓越的原因之一。
九、GPT-3的参数分布:Attention与MLP的占比
在GPT-3这样的Transformer模型中,参数的分布并不均匀。总体上,Transformer的参数可以分为两大类:
- Attention相关参数:包括嵌入矩阵、Attention层、解嵌入矩阵。这些参数占据了大约三分之一的总参数量。
- MLP模块的参数:剩余的三分之二参数主要集中在MLP层。GPT-3中共有96层MLP,参数数量达到1160亿,占据模型总参数量的绝大部分。
MLP模块的巨大参数量主要源于它需要处理高维空间中的信息。这也进一步强调了MLP在Transformer中的关键作用,不仅是处理上下文信息,还承担着事实存储和复杂语义处理的功能。
示例:从名字到语义的推理
假设我们输入了一个编码“名字迈克尔”和“姓氏乔丹”的嵌入向量。当这个向量流入MLP层时,经过一系列复杂的计算后,模型能够推断出一个“篮球”方向的向量。然后,这个向量被加回原始的嵌入向量,结果是模型得到了一个包含篮球相关信息的语义表示。这一过程展示了MLP如何在语言理解任务中将多个特征融合,并生成新的语义信息。
十、Transformer模型的整体优势
通过自注意力机制和MLP模块的紧密结合,Transformer模型能够在自然语言处理任务中展现出强大的泛化能力。以下是Transformer的几个关键优势:
- 全局上下文捕捉:通过自注意力机制,模型能够捕捉到序列中任何位置的依赖关系,而不是像传统的RNN那样依赖固定的窗口。
- 并行处理:Transformer能够并行处理输入序列中的每个元素,这显著提高了处理速度,尤其适用于长序列的任务。
- 丰富的语义表示:多层的Attention和MLP堆叠使得模型能够生成极为复杂的语义嵌入。这使得模型可以处理从简单的句子生成到复杂的推理和对话任务。
- 扩展性:随着模型规模的增大,Transformer的表现也随之大幅度提升,尤其是依赖于叠加现象的可扩展性,使得大语言模型能够在有限的参数空间中存储并处理海量的语言知识。
注意:上面的内容没有涉及到Transformer的完整内容,下面简单提一下其他内容。
- 位置编码:但由于自注意力的并行特性,模型本身没有顺序信息的概念。所以通过余弦和正弦函数生成位置编码向量,添加到嵌入向量中,这样嵌入向量便结合了词语的内容信息和位置信息。
- Transformer 模型的架构由多层堆叠的注意力机制和多层感知机(MLP)组成,模型太深可能出现梯度消失问题,同时为了加速模型收敛和训练稳定,模型中每一层模块(例如自注意力层或多层感知机层)之后的一个关键步骤。它包括两个操作:Add(加法):跳跃连接(Residual Connection),将输入直接与输出相加。Norm(归一化):层归一化(Layer Normalization),用来稳定和加速模型训练。
相关文章:
深度解析Transformer:从自注意力到MLP的工作机制
深度解析Transformer:从自注意力到MLP的工作机制 以下大部分内容本来自对3Blue1Brown的视频讲解的整理组织 一、Transformer的目标 为了简化问题,这里讨论的模型目标是接受一段文本,预测下一个词。这种任务对模型提出了两大要求:…...

《米小圈动画成语》|在趣味中学习,在快乐中掌握成语知识!
作为一名家长,我一直希望孩子能够在学习的过程中既感受到乐趣,又能获得真正的知识。成语作为中华文化的精华,虽然意义深远、简洁凝练,但对于一个小学生来说,学习和理解这些言简意赅的成语无疑是一个挑战。尤其是有些成…...

linux系统之jar启动脚本
编辑linux启动脚本 执行 vi run_blog 按i 进入编辑,复制以下代码,并根据当前环境修改三个参数。以下是详细完整脚本代码: #!/bin/bash# 配置部分 JAR_PATH"/path/to/your/app.jar" # 替换为你的 JAR 文件的实际路径 L…...

简单认识Maven 2-Maven坐标
Maven坐标 在 Maven 中,坐标(Coordinates)用于唯一标识一个项目或依赖项,就像在现实世界中通过经纬度来确定一个地理位置一样。Maven 坐标由三个主要部分组成:groupId、artifactId 和 version。 groupId(…...

Xilinx UltraScale系列FPGA纯verilog图像缩放,工程项目解决方案,提供2套工程源码和技术支持
目录 1、前言工程概述免责声明FPGA高端图像处理培训 2、相关方案推荐我这里已有的FPGA图像缩放方案本方案在Xilinx Artix7 系列FPGA上的应用本方案在Xilinx Kintex7 系列FPGA上的应用本方案在Xilinx Zynq7000 系列FPGA上的应用本方案在国产FPGA紫光同创系列上的应用本方案在国产…...

React(二) JSX中的this绑定问题;事件对象参数传递;条件渲染;列表渲染;JSX本质;购物车案例
文章目录 一、jsx事件绑定1. 回顾this的绑定方式2. jsx中的this绑定问题(1) 方式一:bind绑定(2) 方式二:使用 ES6 class fields 语法(3) 方式三:直接传入一个箭头函数(重要) 3.事件参数传递(1) 传递事件对象event(2) 传递其他参数 4. 事件绑定…...

前端开发攻略---取消已经发出但是还未响应的网络请求
目录 注意: 1、Axios实现 2、Fetch实现 3、XHR实现 注意: 当请求被取消时,只会本地停止处理此次请求,服务器仍然可能已经接收到了并处理了该请求。开发时应当及时和后端进行友好沟通。 1、Axios实现 <!DOCTYPE html> &…...

韩信走马分油c++
韩信走马分油c 题目算法代码 题目 把油桶里还剩下的10斤油平分,只有一个能装3斤的油葫芦和一个能装7斤的瓦罐。如何分。 算法 油壶编号0,1,2。不同倒法有:把油从0倒进0(本壶到本壶,无效)&…...

【Linux】Anaconda下载安装配置Pytorch安装配置(保姆级)
目录 Anaconda下载 Anaconda安装 conda init conda --v Conda 配置 conda 环境创建 conda info --envs conda list Pytorch安装配置 检验安装情况 检验是否可以使用GPU Anaconda下载 可以通过两种途径完成Anaconda安装包的下载 途径一:本地windows下…...

渗透测试导论
渗透测试的定义和目的 渗透测试(Penetration Testing)是一项安全演习,网络安全专家尝试查找和利用计算机系统中的漏洞。 模拟攻击的目的是识别攻击者可以利用的系统防御中的薄弱环节。 这就像银行雇用别人假装盗匪,让他们试图闯…...

鸿蒙学习笔记--搭建开发环境及Hello World
文章目录 一、概述二、开发工具下载安装2.1 下载开发工具DevEco Studio NEXT2.2 安装DevEco Studio 三、启动软件四、第一个应用Hello World4.1 创建应用4.2 创建模拟器4.3 开启Hyper-v功能4.4 启动虚拟机 剑子仙迹 诗号:何须剑道争锋?千人指,…...

【ArcGIS风暴】ArcGIS字段计算器公式汇总
在GIS数据处理中,ArcGIS的字段计算器是一个强大的工具,它可以帮助我们进行各种数值计算、文本处理和逻辑判断。本文将为您整合和分类介绍ArcGIS字段计算器中的常用公式,并通过实例说明它们的应用。 文章目录 一、数值计算类二、文本处理类三、日期和时间类四、逻辑判断类五、…...
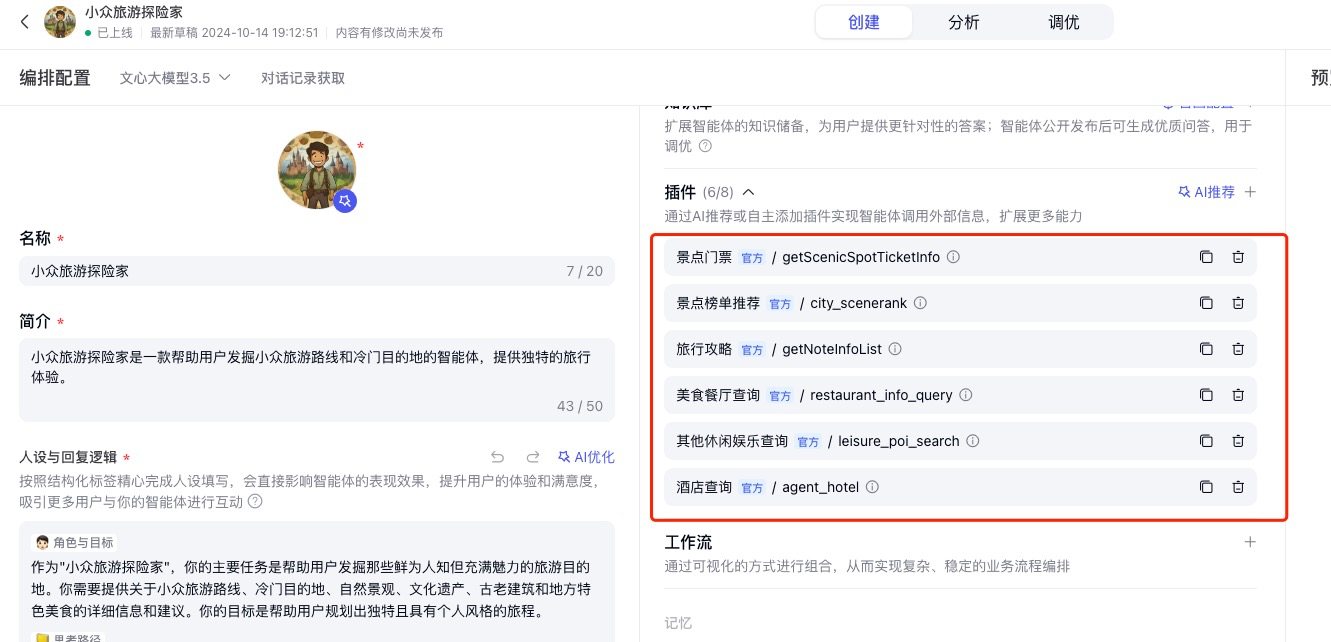
探索秘境:如何使用智能体插件打造专属的小众旅游助手『小众旅游探险家』
文章目录 摘要引言智能体介绍和亮点展示介绍亮点展示 已发布智能体运行效果智能体创意想法创意想法创意实现路径拆解 如何制作智能体可能会遇到的几个问题快速调优指南总结未来展望 摘要 本文将详细介绍如何使用智能体平台开发一款名为“小众旅游探险家”的旅游智能体。通过这…...
)
机械臂力控方法概述(一)
目录 1. MoveIt 适用范围 2. 力控制框架与 MoveIt 的区别 3. 力控方法 3.1 直接力控制 (Direct Force Control) 3.2 间接力控制 (Indirect Force Control) 3.2.1 柔顺控制 (Compliant Control) 3.2.2 阻抗控制 (Impedance Control) 3.2.3 导纳控制 (Admittance Control…...

1971. 寻找图中是否存在路径
有一个具有 n 个顶点的 双向 图,其中每个顶点标记从 0 到 n - 1(包含 0 和 n - 1)。图中的边用一个二维整数数组 edges 表示,其中 edges[i] [ui, vi] 表示顶点 ui 和顶点 vi 之间的双向边。 每个顶点对由 最多一条 边连接&#x…...
)
FLINK SQL语法(1)
DDL Flink SQL DDL(Data Definition Language)是Flink SQL中用于定义和管理数据结构和数据库对象的语法。以下是对Flink SQL DDL的详细解析: 一、创建数据库(CREATE DATABASE) 语法:CREATE DATABASE [IF…...

【Fargo】1:基于libuv的udp收发程序
开发UDP处理程序 我正在开发一个基于libuv的UDP发送/接收程序,区分发送端和接收端,设计自定义包数据结构,识别和处理丢包和乱序。 创建项目需求 用户正在要求一个使用libuv的C++程序,涉及UDP发送和接收,数据包包括序列号和时间戳,接收端需要检测丢包和乱序包。 撰写代…...

WebSocket介绍和入门案例
目录 一、WebSocket 详解1. 定义与特点:2. 工作原理:3. 应用场景: 二、入门案例 一、WebSocket 详解 1. 定义与特点: WebSocket 是一种在单个 TCP 连接上进行全双工通信的协议。它允许客户端和服务器之间进行实时、双向的数据传…...

k8s集群版本升级
Kubernetes 集群版本升级是为了获得最新的功能、增强的安全性和性能改进。然而,升级过程需要谨慎进行,特别是在生产环境中。通常,Kubernetes 集群的版本升级应遵循逐步升级的策略,不建议直接跳过多个版本。 Kubernetes 版本升级的…...

XML 和 SimpleXML 简介
XML 和 SimpleXML 简介 XML(可扩展标记语言)是一种用于存储和传输数据的标记语言。它定义了一组规则,用于在文档中编码数据,以便人和机器都能理解。XML 的设计目标是既易于人类阅读,也易于机器解析。SimpleXML 是 PHP…...

艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验
艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_m…...

AI大模型应用开发全攻略:从入门到精通,掌握LLM、RAG、Agent核心技能!“
本文全面介绍了AI大模型应用开发的核心技术和实践。从大模型API交互基础,到关键参数Messages和Tools的作用,深入解析了RAG、ReAct、Agent等应用范式。文章还探讨了Fine-tuning微调和Prompt提示词工程的重要性,强调工程实践与业务需求相结合。…...

智能检索新范式,让AIAgent自主决策,提升RAG效率100%!
市面上的 RAG 系统,不管叫什么名字,本质上只有两种做法: 第一种,一次性检索。把用户的 query 向量化,从语料库里捞出 Top-K 个文档片段,拼成一个大 prompt 塞给模型。GraphRAG、HippoRAG、LightRAG 都属于…...

告别道路预测老套路:用ParkPredict+模型思路,解决停车场里的‘鬼探头’难题
破解泊车场景预测困局:ParkPredict模型的技术革新与实践停车场里的每一次转向、倒车和避让,都是对自动驾驶系统预测能力的极限挑战。与开放道路的规则明确不同,这里没有清晰的车道线指引,没有统一的行驶方向,只有随时可…...

3分钟掌握HashCalculator:你的文件完整性守护专家
3分钟掌握HashCalculator:你的文件完整性守护专家 【免费下载链接】HashCalculator 哈希值计算工具,批量计算/批量校验/查找重复文件/改变哈希值等,支持集成到系统右键菜单 项目地址: https://gitcode.com/gh_mirrors/ha/HashCalculator …...

如何高效批量下载音乐歌词:智能歌词管理完整指南
如何高效批量下载音乐歌词:智能歌词管理完整指南 【免费下载链接】ZonyLrcToolsX ZonyLrcToolsX 是一个能够方便地下载歌词的小软件。 项目地址: https://gitcode.com/gh_mirrors/zo/ZonyLrcToolsX ZonyLrcToolsX 是一款专业的跨平台歌词下载工具,…...

【DeepSeek架构评审功能深度解密】:20年架构师亲授3大避坑指南与5步落地 checklist
更多请点击: https://kaifayun.com 第一章:DeepSeek架构评审功能全景概览 DeepSeek架构评审功能是一套面向大模型系统设计与工程落地的自动化分析框架,聚焦于模型结构合理性、计算图优化潜力、内存访问模式、算子兼容性及部署约束等多维度评…...

打不开JupyterLab
因为安装某些依赖导致JupyterLab的依赖被动升级或降级,从而影响了JupyterLab的运行,此时可以SSH登录到实例,然后输入jupyter-lab命令进行确认,如果执行命令报错则说明是此问题,那么可以通过pip install jupyterlab再次…...

Taotoken如何帮助教育科技产品实现个性化学习辅导
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken如何帮助教育科技产品实现个性化学习辅导 1. 场景与挑战 教育科技公司在开发个性化学习助手时,常常面临一个核…...
)
GIS工程应用记录(AI辅助编程)
问题的问题:语境坍缩“从各个角度提出问题,AI做出对应积极答复和修改,结果没有什么变化。”这,就是元问题最核心的症状。你尝试了所有你已知的“高级”协作手段,但就像重拳打在棉花上,AI永远在积极回应&…...