【C++标准模版库】unordered_map和unordered_set的介绍及使用
unordered_map和unordered_set
- 一.unordered_set
- 1.unordered_set类的介绍
- 2.unordered_set和set的使用差异
- 二.unordered_map
- 1.unordered_map和map的使用差异
- 三.unordered_multimap/unordered_multiset
- 四.unordered_map/unordered_set的哈希相关接口
一.unordered_set
1.unordered_set类的介绍
- unordered_set的声明如下,Key就是unordered_set底层关键字的类型。

-
unordered_set默认
要求Key支持转换为整形,如果不支持或者想按自己的需求走可以自行实现支持将Key转成整形的仿函数传给第⼆个模板参数。 -
unordered_set默认
要求Key支持比较相等,如果不支持或者想按自己的需求走可以自行实现支持将Key比较相等的仿函数传给第三个模板参数。 -
unordered_set底层存储数据的内存是从空间配置器申请的,如果需要可以自己实现内存池,传给第四个参数。
-
一般情况下,我们都不需要传后三个模板参数。
-
unordered_set底层是用
哈希桶实现,增删查平均效率是O(1),迭代器遍历不再有序,为了跟set
区分,所以取名unordered_set。 -
set和unordered_set的功能高度相似,只是底层结构不同,有一些性能和使用的差异,这里只讲他们的差异部分。
2.unordered_set和set的使用差异
unordered_set文档
-
查看文档我们会发现unordered_set的支持增删查且跟set的使用一模一样,关于使用我们这里就不再赘述和演示了。
-
unordered_set和set的第一个差异是对key的要求不同,
set要求Key支持小于比较,而unordered_set要求Key支持转成整形且支持等于比较,要理解unordered_set的这个两点要求得后续我们结合哈希表底层实现才能真正理解,也就是说这本质是哈希表的要求。 -
unordered_set和set的第⼆个差异是迭代器的差异,
set的iterator是双向迭代器,unordered_set是单向迭代器,其次set底层是红黑树,红黑树是⼆叉搜索树,走中序遍历是有序的,所以set迭代器遍历是有序+去重。而unordered_set底层是哈希表,迭代器遍历是无序+去重。
int main()
{//迭代器遍历有序+去重set<int> s = { 5,4,2,6,8,5,6,9,7,4,2,3,1 };set<int>::iterator sit = s.begin(); //双向迭代器while (sit != s.end()){cout << *sit << " "; //1 2 3 4 5 6 7 8 9++sit;}cout << endl;//迭代器遍历无序+去重unordered_set<int> us = { 5,4,2,6,8,5,6,9,7,4,2,3,1 };unordered_set<int>::iterator usit = us.begin(); //单向迭代器while (usit != us.end()){cout << *usit << " "; //5 4 2 6 8 9 7 3 1++usit;}cout << endl;return 0;
}
- unordered_set和set的第三个差异是性能的差异,整体而言大多数场景下,unordered_set的增删
查改更快一些而更常用,因为红黑树增删查改效率是O(logN) ,而哈希表增删查平均效率是O(1) ,O(logN) 与O(1)差距不大。具体可以参看下面代码的演示的对比差异。
void test_set()
{const size_t N = 1000000;unordered_set<int> us;set<int> s;vector<int> v;v.reserve(N);srand(time(0));for (size_t i = 0; i < N; ++i){//v.push_back(rand()); //N比较大时,重复值比较多v.push_back(rand() + i); //重复值相对少//v.push_back(i); //没有重复,有序}size_t begin1 = clock();for (auto e : v){s.insert(e);}size_t end1 = clock();cout << "set insert:" << end1 - begin1 << endl;cout << "set插入数据个数:" << s.size() << endl << endl;size_t begin2 = clock();us.reserve(N);for (auto e : v){us.insert(e);}size_t end2 = clock();cout << "unordered_set insert:" << end2 - begin2 << endl;cout << "unordered_set插入数据个数:" << s.size() << endl << endl;int m1 = 0;size_t begin3 = clock();for (auto e : v){auto ret = s.find(e);if (ret != s.end()){++m1; //找到:次数+1}}size_t end3 = clock();cout << "set find:" << end3 - begin3 << " -> " << m1 << endl;int m2 = 0;size_t begin4 = clock();for (auto e : v){auto ret = us.find(e);if (ret != us.end()){++m2; //找到:次数+1}}size_t end4 = clock();cout << "unorered_set find:" << end4 - begin4 << " -> " << m2 << endl << endl;size_t begin5 = clock();for (auto e : v){s.erase(e);}size_t end5 = clock();cout << "set erase:" << end5 - begin5 << endl;size_t begin6 = clock();for (auto e : v){us.erase(e);}size_t end6 = clock();cout << "unordered_set erase:" << end6 - begin6 << endl << endl;
}int main()
{test_set();return 0;
}

二.unordered_map
1.unordered_map和map的使用差异

-
查看文档我们会发现unordered_map的支持增删查且跟map的使用一模一样,关于使用我们这里就不再赘述和演示了。
-
unordered_map和map的第一个差异是对key的要求不同,map要求Key支持小于比较,而
unordered_map要求Key支持转成整形且⽀持等于比较,要理解unordered_map的这个两点要求
得后续我们结合哈希表底层实现才能真正理解,也就是说这本质是哈希表的要求。 -
unordered_map和map的第⼆个差异是迭代器的差异,map的iterator是双向迭代器,
unordered_map是单向迭代器,其次map底层是红黑树,红黑树是⼆叉搜索树,走中序遍历是有
序的,所以map迭代器遍历是Key有序+去重。而unordered_map底层是哈希表,迭代器遍历是
Key无序+去重。 -
unordered_map和map的第三个差异是性能的差异,整体而言大多数场景下,unordered_map的
增删查改更快一些,因为红黑树增删查改效率是O(logN) ,而哈希表增删查平均效率是O(1)。
三.unordered_multimap/unordered_multiset
- unordered_multimap/unordered_multiset跟multimap/multiset功能完全类似,支持Key冗余。
- unordered_multimap/unordered_multiset跟multimap/multiset的差异也是三个方面的差异,key的要求的差异,iterator及遍历顺序的差异,性能的差异。
multi版本由于Key冗余,所以不支持operator []。
int main()
{unordered_map<string, string> dict1;dict1.insert({ "left", "向左" });dict1.insert({ "left", "离开" }); //插入失败dict1.insert({ "left", "留下" }); //插入失败unordered_multimap<string, string>::iterator it1 = dict1.begin();while (it1 != dict1.end()){cout << it1->first << ":" << it1->second << endl;++it1;}cout << endl;unordered_multimap<string, string> dict2;dict2.insert({ "left", "向左" });dict2.insert({ "left", "离开" }); //插入成功dict2.insert({ "left", "留下" }); //插入成功unordered_multimap<string, string>::iterator it2 = dict2.begin();while (it2 != dict2.end()){cout << it2->first << ":" << it2->second << endl;++it2;}cout << endl;return 0;
}

四.unordered_map/unordered_set的哈希相关接口

Buckets和Hash policy系列的接口分别是跟哈希桶和负载因子相关的接口,日常使用的角度我们不需
要太关注,需要结合哈希表底层,才能明白。
相关文章:
【C++标准模版库】unordered_map和unordered_set的介绍及使用
unordered_map和unordered_set 一.unordered_set1.unordered_set类的介绍2.unordered_set和set的使用差异 二.unordered_map1.unordered_map和map的使用差异 三.unordered_multimap/unordered_multiset四.unordered_map/unordered_set的哈希相关接口 一.unordered_set 1.unord…...
深度解析Transformer:从自注意力到MLP的工作机制
深度解析Transformer:从自注意力到MLP的工作机制 以下大部分内容本来自对3Blue1Brown的视频讲解的整理组织 一、Transformer的目标 为了简化问题,这里讨论的模型目标是接受一段文本,预测下一个词。这种任务对模型提出了两大要求:…...

《米小圈动画成语》|在趣味中学习,在快乐中掌握成语知识!
作为一名家长,我一直希望孩子能够在学习的过程中既感受到乐趣,又能获得真正的知识。成语作为中华文化的精华,虽然意义深远、简洁凝练,但对于一个小学生来说,学习和理解这些言简意赅的成语无疑是一个挑战。尤其是有些成…...

linux系统之jar启动脚本
编辑linux启动脚本 执行 vi run_blog 按i 进入编辑,复制以下代码,并根据当前环境修改三个参数。以下是详细完整脚本代码: #!/bin/bash# 配置部分 JAR_PATH"/path/to/your/app.jar" # 替换为你的 JAR 文件的实际路径 L…...

简单认识Maven 2-Maven坐标
Maven坐标 在 Maven 中,坐标(Coordinates)用于唯一标识一个项目或依赖项,就像在现实世界中通过经纬度来确定一个地理位置一样。Maven 坐标由三个主要部分组成:groupId、artifactId 和 version。 groupId(…...

Xilinx UltraScale系列FPGA纯verilog图像缩放,工程项目解决方案,提供2套工程源码和技术支持
目录 1、前言工程概述免责声明FPGA高端图像处理培训 2、相关方案推荐我这里已有的FPGA图像缩放方案本方案在Xilinx Artix7 系列FPGA上的应用本方案在Xilinx Kintex7 系列FPGA上的应用本方案在Xilinx Zynq7000 系列FPGA上的应用本方案在国产FPGA紫光同创系列上的应用本方案在国产…...

React(二) JSX中的this绑定问题;事件对象参数传递;条件渲染;列表渲染;JSX本质;购物车案例
文章目录 一、jsx事件绑定1. 回顾this的绑定方式2. jsx中的this绑定问题(1) 方式一:bind绑定(2) 方式二:使用 ES6 class fields 语法(3) 方式三:直接传入一个箭头函数(重要) 3.事件参数传递(1) 传递事件对象event(2) 传递其他参数 4. 事件绑定…...

前端开发攻略---取消已经发出但是还未响应的网络请求
目录 注意: 1、Axios实现 2、Fetch实现 3、XHR实现 注意: 当请求被取消时,只会本地停止处理此次请求,服务器仍然可能已经接收到了并处理了该请求。开发时应当及时和后端进行友好沟通。 1、Axios实现 <!DOCTYPE html> &…...

韩信走马分油c++
韩信走马分油c 题目算法代码 题目 把油桶里还剩下的10斤油平分,只有一个能装3斤的油葫芦和一个能装7斤的瓦罐。如何分。 算法 油壶编号0,1,2。不同倒法有:把油从0倒进0(本壶到本壶,无效)&…...

【Linux】Anaconda下载安装配置Pytorch安装配置(保姆级)
目录 Anaconda下载 Anaconda安装 conda init conda --v Conda 配置 conda 环境创建 conda info --envs conda list Pytorch安装配置 检验安装情况 检验是否可以使用GPU Anaconda下载 可以通过两种途径完成Anaconda安装包的下载 途径一:本地windows下…...

渗透测试导论
渗透测试的定义和目的 渗透测试(Penetration Testing)是一项安全演习,网络安全专家尝试查找和利用计算机系统中的漏洞。 模拟攻击的目的是识别攻击者可以利用的系统防御中的薄弱环节。 这就像银行雇用别人假装盗匪,让他们试图闯…...

鸿蒙学习笔记--搭建开发环境及Hello World
文章目录 一、概述二、开发工具下载安装2.1 下载开发工具DevEco Studio NEXT2.2 安装DevEco Studio 三、启动软件四、第一个应用Hello World4.1 创建应用4.2 创建模拟器4.3 开启Hyper-v功能4.4 启动虚拟机 剑子仙迹 诗号:何须剑道争锋?千人指,…...

【ArcGIS风暴】ArcGIS字段计算器公式汇总
在GIS数据处理中,ArcGIS的字段计算器是一个强大的工具,它可以帮助我们进行各种数值计算、文本处理和逻辑判断。本文将为您整合和分类介绍ArcGIS字段计算器中的常用公式,并通过实例说明它们的应用。 文章目录 一、数值计算类二、文本处理类三、日期和时间类四、逻辑判断类五、…...
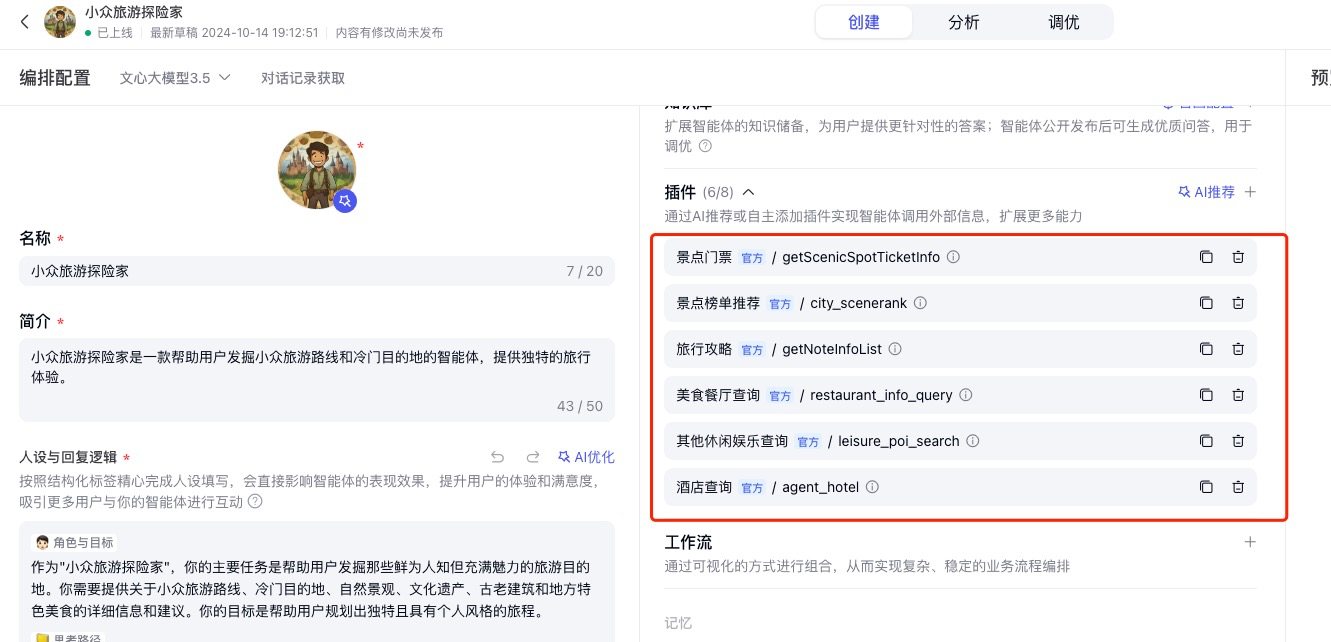
探索秘境:如何使用智能体插件打造专属的小众旅游助手『小众旅游探险家』
文章目录 摘要引言智能体介绍和亮点展示介绍亮点展示 已发布智能体运行效果智能体创意想法创意想法创意实现路径拆解 如何制作智能体可能会遇到的几个问题快速调优指南总结未来展望 摘要 本文将详细介绍如何使用智能体平台开发一款名为“小众旅游探险家”的旅游智能体。通过这…...
)
机械臂力控方法概述(一)
目录 1. MoveIt 适用范围 2. 力控制框架与 MoveIt 的区别 3. 力控方法 3.1 直接力控制 (Direct Force Control) 3.2 间接力控制 (Indirect Force Control) 3.2.1 柔顺控制 (Compliant Control) 3.2.2 阻抗控制 (Impedance Control) 3.2.3 导纳控制 (Admittance Control…...

1971. 寻找图中是否存在路径
有一个具有 n 个顶点的 双向 图,其中每个顶点标记从 0 到 n - 1(包含 0 和 n - 1)。图中的边用一个二维整数数组 edges 表示,其中 edges[i] [ui, vi] 表示顶点 ui 和顶点 vi 之间的双向边。 每个顶点对由 最多一条 边连接&#x…...
)
FLINK SQL语法(1)
DDL Flink SQL DDL(Data Definition Language)是Flink SQL中用于定义和管理数据结构和数据库对象的语法。以下是对Flink SQL DDL的详细解析: 一、创建数据库(CREATE DATABASE) 语法:CREATE DATABASE [IF…...

【Fargo】1:基于libuv的udp收发程序
开发UDP处理程序 我正在开发一个基于libuv的UDP发送/接收程序,区分发送端和接收端,设计自定义包数据结构,识别和处理丢包和乱序。 创建项目需求 用户正在要求一个使用libuv的C++程序,涉及UDP发送和接收,数据包包括序列号和时间戳,接收端需要检测丢包和乱序包。 撰写代…...

WebSocket介绍和入门案例
目录 一、WebSocket 详解1. 定义与特点:2. 工作原理:3. 应用场景: 二、入门案例 一、WebSocket 详解 1. 定义与特点: WebSocket 是一种在单个 TCP 连接上进行全双工通信的协议。它允许客户端和服务器之间进行实时、双向的数据传…...

k8s集群版本升级
Kubernetes 集群版本升级是为了获得最新的功能、增强的安全性和性能改进。然而,升级过程需要谨慎进行,特别是在生产环境中。通常,Kubernetes 集群的版本升级应遵循逐步升级的策略,不建议直接跳过多个版本。 Kubernetes 版本升级的…...

Unity Il2CppDumper原理与实战:解析元数据与二进制对齐
1. 这不是“破解工具”,而是Unity开发者该懂的二进制真相课 你刚在Unity Asset Store下载了一个功能惊艳的插件,却在打包iOS后发现部分逻辑失效;或者接手一个没有源码的旧项目,只有一堆 .dll 和 .so 文件,连主入口…...

AI赋能5G核心网故障诊断:从PCAP解析到智能根因分析的工程实践
1. 项目概述:当AI遇见5G核心网故障诊断在5G核心网的运维与测试一线干了这么多年,最头疼的莫过于面对海量的PCAP抓包文件。一个复杂的信令流程下来,动辄几千甚至上万个数据包,工程师需要像侦探一样,逐帧审视协议交互&am…...
两两交换链表中的节点)
力扣HOT100(30)两两交换链表中的节点
链表的交换要注意 “链表不断链”。前驱和后继都要连着迭代法(必学死磕!O (n) 时间,O (1) 空间)1. 为什么必须用虚拟头节点?因为交换后链表的头节点会变! 比如示例 1 中,原来的头是 1࿰…...

告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件
告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件当面对数百GB的设计素材、日志文件或数据库备份需要迁移时,传统的FTP传输往往会成为效率瓶颈。我曾在一个视频处理项目中,需要将230GB的4K原始素材从移动硬盘导入服务器ÿ…...

3步深度解锁:网络设备权限管理工具的实战手册
3步深度解锁:网络设备权限管理工具的实战手册 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 你是否曾面对功能受限的网络设备感到束手无策?当默认配置锁死了硬…...

交流电机驱动器的三种控制模式:前沿切相、后沿切相与同步模式详解
1. 项目概述:一个能玩出花的交流电机驱动器在汽车改装、工业控制或者一些创客项目里,驱动一个交流电机听起来简单,但想让它听话地变速、正反转,甚至实现软启动和精确同步,往往就得搬出笨重又昂贵的工业变频器。今天分享…...

基于雷达与光敏传感器的低功耗智能窗防设备设计与实现
1. 项目概述:一个基于雷达与光敏的智能窗防设备几年前,我因为一次短暂的出差,家里空置了几天,回来后就一直琢磨着怎么给家里的窗户加点“动静”。市面上的智能安防摄像头固然好,但要么需要复杂的布线,要么云…...

全球无障碍宣传日:iOS 26 辅助功能大升级,这些实用小功能你用过吗?
辅助功能发展与升级很多人对辅助功能的印象还停留在 "小白点",但随着 iPhone 进入全面屏时代,它逐渐变得陌生。实际上,Apple 每年都会为其增添功能,方便身体有障人士使用 iPhone。而且,这些功能不仅惠及有障…...

OmenSuperHub:基于WMI BIOS控制的高性能笔记本硬件管理方案
OmenSuperHub:基于WMI BIOS控制的高性能笔记本硬件管理方案 【免费下载链接】OmenSuperHub Control Omen laptop performance, fan speeds, and keyboard lighting, and unlock power limits. 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 在惠…...

AutoPentest:面向红队的渗透测试决策引擎架构解析
1. 这不是又一个“自动化扫描器”,而是一套能替你做决策的渗透测试工作流引擎AutoPentest这个名字,第一眼容易让人联想到Nmap加个for循环、或者Burp Suite里点几下Intruder——但实际用过的人很快会意识到:它根本不在同一个维度上。我第一次在…...