时间序列预测(六)——循环神经网络(RNN)
目录
一、RNN的基本原理
1、正向传播(Forward Pass):
2、计算损失(Loss Calculation)
3、反向传播——反向传播通过时间(Backpropagation Through Time,BPTT)
4、梯度更新:
二、RNN的常用结构
1、N——N结构
2、N——1结构
3、1——N结构
4、N——M结构(Encoder-Decoder,也称Seq2Seq)
三、RNN的优缺点
四、梯度消失与梯度爆炸
五、RNN的改进模型
六、代码实现
往期文章:
时间序列预测(一)——线性回归(linear regression)-CSDN博客
时间序列预测(二)——前馈神经网络(Feedforward Neural Network, FNN)-CSDN博客
前面有提到前馈神经网络,下图是两者的区别对比
| 特性 | 前馈神经网络(FNN) | 循环神经网络(RNN) |
| 结构 | 无循环连接,数据单向流动 | 有循环连接,数据可流过多个时间步 |
| 适用任务 | 静态任务,无时间依赖 | 动态任务,包含时间依赖 |
| 记忆能力 | 无法记忆前一时刻信息 | 通过隐藏状态记忆前一时刻信息 |
| 梯度计算 | 反向传播(BP) | 反向传播通过时间(BPTT) |
| 常见问题 | 无梯度消失或爆炸问题 | 易出现梯度消失或爆炸问题 |
| 适用场景 | 图像分类、静态预测 | 时间序列预测、文本生成、语音识别 |
循环神经网络(Recurrent Neural Network,RNN)是一种专门用于处理序列数据的神经网络结构,它能够处理时间序列数据,并预测未来的数据变化趋势。RNN能够处理序列中的时间依赖性,因而非常适合时间序列预测。以下是对RNN在时间序列预测中的详细分析:
一、RNN的基本原理
RNN的基本原理是在神经网络中引入时间的概念,使得网络可以处理序列数据。RNN的基本结构是一个循环单元,它包含一个输入层、一个隐藏层和一个输出层。在每一个时间步上,网络接收一个输入向量和一个隐藏状态向量,通过一个非线性函数对它们进行组合,然后产生一个输出向量和一个新的隐藏状态向量,作为下一个时间步的输入和隐藏状态。这种反馈机制可以使得网络记忆之前的信息,并在处理序列数据时考虑到历史信息。
1、正向传播(Forward Pass):
-
输入层:
- RNN的输入是一个序列,表示为 X=[x1,x2,…,xT],其中 T 是序列长度,xt 表示在时间 t 的输入值。
-
隐藏层:
- RNN 的特殊之处在于隐藏层具有循环连接,使得每个时刻的隐藏层状态都能从前一时刻的状态(隐状态)中获得信息。具体来说,RNN 会在每个时间步更新隐藏状态 ht:

- RNN 的特殊之处在于隐藏层具有循环连接,使得每个时刻的隐藏层状态都能从前一时刻的状态(隐状态)中获得信息。具体来说,RNN 会在每个时间步更新隐藏状态 ht:
-
输出层:
RNN 的输出 yt依赖于当前隐藏状态 ht:
2、计算损失(Loss Calculation)
选择合适的损失函数,计算每个时间步 ttt 的损失值 Lt,将所有时间步上的损失求和,得到整个序列的总损失 L:
3、反向传播——反向传播通过时间(Backpropagation Through Time,BPTT)
在计算总损失后,通过BPTT算法沿时间维度反向传播误差,计算每个时间步上的梯度。
因为隐藏状态在每个时间步都传递到下一个时间步,所以需要在时间上展开 RNN,形成一个“展开的计算图”,并在这个图上逐步反向传播。对于每个时间步的参数(如 Wh和 Wx),需要计算梯度:
(注意:由于隐藏状态 hth_tht 依赖于所有之前的状态,所以当前时间步的梯度受多个时间步的误差影响。)
4、梯度更新:
计算出参数的梯度后,通常使用优化器(如 SGD、Adam 等)来更新模型参数。随着每个时间步梯度的反向传播,BPTT算法会依次更新所有权重,以最小化损失。
为了减小计算量,提出了截断 BPTT,它 是一种优化的 BPTT 方法,通过限制反向传播的时间步数来减少计算量。它按固定长度(如 10 或 20 步)的窗口,将长序列分成若干个较短的子序列,每个子序列独立进行正向和反向传播。在每个子序列结束时,重置梯度,但隐藏状态在各子序列间保持连续,以保留长程依赖信息。
最后,需要注意在PyTorch中,RNN的输入数据通常是一个形状为(batch_size, sequence_length, input_size)的张量,输出数据通常是一个二维张量,其形状为(batch_size, output_size)或是三维张量(batch_size, sequence_length, output_size)(对于序列输出)。
其中,
batch_size:表示批次中样本的数量。sequence_length:表示序列的长度。input_size和output_size:表示每个时间步骤的输入和输出的特征数量
所以要将数据进行转化。这里是与FNN是不一样的,多了一个序列长度,所以RNN 可以一次性输入和输出多个时间步的特征和目标,RNN 才是真正可以处理序列数据的,而 FNN 处理的是单个独立样本。
因此,当 sequence_length=1 时,RNN 变得和 FNN 类似,但仍保持了 RNN 的结构。在这种情况下,使用 RNN 可能会显得有些多余,因为 FNN 可以实现相同的功能,而不需要引入 RNN 的复杂性。
二、RNN的常用结构
1、N——N结构
输入与输出:输入是x1,x2,.....xn,输出为y1,y2,...yn。输入和输出序列是等长的。
应用场景:由于这种结构的输入输出长度一致,因此它适用于生成等长度的序列,如合辙的诗句等。此外,它还可用于计算视频中每一帧的分类标签,因为要对每一帧进行计算,所以输入和输出序列等长。

2、N——1结构
输入与输出:输入是一个序列,而输出是一个单独的值,不是序列。
处理方式:这种结构通常在最后一个隐层输出h上进行线性变换,以得到所需的输出值。为了更明确地表示结果,还可以使用sigmoid或softmax函数进行处理。
应用场景:这种结构经常被应用在文本分类问题上,如输入一段文字判别它所属的类别,或输入一个句子判断其情感倾向等。 
3、1——N结构
输入与输出:输入不是序列,而输出为序列。
应用场景:这种结构可以处理从非序列数据生成序列数据的问题,如从图像生成文字(image caption)。此时,输入X是图像的特征,而输出的y序列就是一段句子,就像看图说话一样。  或是
或是 
4、N——M结构(Encoder-Decoder,也称Seq2Seq)
输入与输出:输入和输出为不等长的序列。
结构组成:这种结构由编码器和解码器两部分组成,两者的内部结构都是某类RNN。输入数据首先通过编码器,最终输出一个隐含变量c(上下文语义向量)。之后,使用这个隐含变量c作用在解码器解码的每一步上,以保证输入信息被有效利用。
应用场景:这是RNN的一个重要变种,也是应用最广的RNN模型结构。由于其输入输出不受限制,它被广泛应用于机器翻译、阅读理解、文本摘要等众多领域。在机器翻译中,源语言和目标语言的句子往往没有相同的长度,因此N——M结构特别适用于此类任务。  或是
或是 
局限性:编码和解码之间的唯一联系是固定长度的语义向量c。编码时,整个序列的信息需要被压缩进一个固定长度的语义向量c中,这可能导致信息丢失或覆盖。因此,对于较长的输入序列,解码效果可能会受到影响。
改进:为了弥补N——M结构的局限性,提出了注意力(Attention)机制。注意力机制通过在每个时间输入不同的c来解决问题,它允许解码器在解码时能够关注输入序列的不同部分,从而提高了解码的准确性和灵活性。
三、RNN的优缺点
优点:RNN具有记忆功能,能够处理变长的序列数据,并捕捉到序列中的时序信息。同时,RNN的权重参数是共享的,这有助于减少模型的参数数量并提高计算效率。RNN可以根据输入和输出的不同结构进行灵活调整。
缺点:在长序列任务中,RNN容易出现梯度消失或梯度爆炸的问题,导致模型难以训练。RNN的计算效率相对较低,因为需要在每个时间步都进行前向传播和反向传播的计算。
四、在Python中的代码解释
1、模型定义
class RNNModel(nn.Module):def __init__(self, input_size, hidden_size, num_layers):super(RNNModel, self).__init__()self.hidden_size = hidden_sizeself.num_layers = num_layersself.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True) # 使用RNNself.fc = nn.Linear(hidden_size, 1) # 输出层def forward(self, x):# 初始化隐藏状态h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)# 前向传播out, _ = self.rnn(x, h0) # RNN输出形状为 (batch_size, seq_length, hidden_size)out = self.fc(out[:, -1, :]) # 只取最后一个时间步的输出return out# 实例化模型
input_size = window_size + 2 # 输入特征维度
hidden_size = 64 # 隐藏层大小
num_layers = 2 # RNN层数
model = RNNModel(input_size, hidden_size, num_layers)(1)类定义:RNNModel
RNNModel类继承自nn.Module,这是PyTorch中所有神经网络模块的基类。
a、初始化__init__
调用父类的__init__方法外,还定义了模型的一些关键属性:
input_size:输入特征的大小(维度)。hidden_size:RNN隐藏层的大小(即隐藏层中神经元的数量)。num_layers:RNN的层数(即堆叠的RNN单元的数量)。self.rnn:这是模型中的RNN层,batch_first=True意味着输入张量的第一个维度是批次大小(batch size)。self.fc:这是一个全连接层(也称为线性层),将RNN的最后一个时间步的输出映射到模型的最终输出。这里,输出层的大小被设置为1,这意味着模型将输出一个标量值。
b、前向传播forward
首先初始化隐藏状态h0。隐藏状态是一个零张量,其形状为(num_layers, batch_size, hidden_size),并且被发送到与输入x相同的设备上(CPU或GPU)。
接着,使用RNN层处理输入x和初始隐藏状态h0。RNN层的输出out是一个形状为(batch_size, seq_length, hidden_size)的张量,其中seq_length是序列的长度。
然后,只取RNN输出的最后一个时间步(out[:, -1, :]),并通过全连接层self.fc进行处理,得到模型的最终输出。
(2)实例化模型
指定输入特征维度input_size,隐藏层大小hidden_size,和RNN层数num_layers来实例化RNNModel类。用于训练、验证和测试,以处理序列数据并预测目标值。
2、参数形状转化(注意)
x_train、 x_test 、y_train 和 y_test本身是从excel表格读取的一维数组,但在PyTorch中,RNN的输入数据形状为(batch_size, sequence_length, input_size)的张量,输出数据形状为(batch_size, output_size)或(batch_size, sequence_length, output_size)(对于序列输出)。因此x_train 和 x_test 被转换为形状为 [batch_size, 1, window_size + 2] 的三维张量,而 y_train 和 y_test 被转换为形状为 [batch_size, 1] 的二维张量。
(1)数据类型转换:
使用 torch.tensor() 将数据转换为 PyTorch 张量,并指定数据类型为 torch.float32。这是为了确保数据格式与 PyTorch 模型兼容。
(2)形状重塑:
.view(-1, 1, window_size + 2) 和 .view(-1, 1) 是用于重塑张量的方法。
-1 在 .view() 方法中是一个特殊值,表示该维度的大小将自动计算,以确保总元素数量保持不变。
对于 x_train 和 x_test,重塑后的形状为 [batch_size, seq_len, input_size]。其中:
batch_size 是自动计算的,基于原始数据的总元素数量和后面两个维度的大小。
seq_len 是 1,表示每个样本被视为一个序列,表示每个样本只包含一个时间步的数据
input_size 是 window_size + 2,表示每个时间步的输入特征数量。
对于 y_train 和 y_test,重塑后的形状为 [batch_size, 1],其中 batch_size 是自动计算的,1表示每个样本目标值被视为一个序列,只包含一个时间步的数据。具体如下:
五、梯度消失与梯度爆炸
时间序列预测(七)——梯度消失(Vanishing Gradient)与梯度爆炸-CSDN博客
六、RNN的改进模型
为了克服RNN的缺点并提高其性能,研究人员提出了多种改进模型,其中最具代表性的是长短期记忆(LSTM)和门控循环单元(GRU)。
具体看下面这两篇文章:
后面补齐
七、具体代码实现
同之前的文章一样,根据一个包含道路曲率(Curvature)、车速(Velocity)、侧向加速度(Ay)和方向盘转角(Steering_Angle)真实的数据集,去预测未来的方向盘转角。
1、选择道路曲率、车速和历史方向盘转角(这里取了五个时刻的历史方向盘转角)这三个(7个)作为特征,采用RNN训练
(但这样其实就如上文所说的,会显得有些多余,正常应该直接输入多个时间步的特征,按下一种方法,这一个可以直接跳过)。
# RNN网络
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error as mae, r2_score
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
import numpy as np# 1. 数据预处理
# 读取数据
data = pd.read_excel('input_data_20241010160240.xlsx') # 替换为你的数据文件路径 # 提取特征和标签
labels = data['Steering_Angle'].values
features = data[['Curvature', 'Velocity']].values # 使用 NumPy 数组# 添加历史方向盘转角作为特征 (假设历史窗口长度为5)
window_size = 5
history_features = []
for i in range(window_size, len(data)):past_angles = labels[i - window_size:i]history_features.append(list(past_angles))
features = features[window_size:]
labels = labels[window_size:]# 合并特征
features = np.hstack((features, history_features))# 归一化
scaler_x = StandardScaler()
scaler_y = StandardScaler()
features = scaler_x.fit_transform(features)
labels = scaler_y.fit_transform(labels.reshape(-1, 1))# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(features, labels, test_size=0.2)# 将特征转换为三维张量,形状为 [样本数, 时间序列长度, 特征数]
x_train_tensor = torch.tensor(x_train, dtype=torch.float32).view(-1, 1, window_size + 2) # [batch_size, seq_len, input_size]
y_train_tensor = torch.tensor(y_train, dtype=torch.float32).view(-1, 1)
x_test_tensor = torch.tensor(x_test, dtype=torch.float32).view(-1, 1, window_size + 2)
y_test_tensor = torch.tensor(y_test, dtype=torch.float32).view(-1, 1)# 2. 创建RNN模型
class RNNModel(nn.Module):def __init__(self, input_size, hidden_size, num_layers):super(RNNModel, self).__init__()self.hidden_size = hidden_sizeself.num_layers = num_layersself.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True) # 使用RNNself.fc = nn.Linear(hidden_size, 1) # 输出层def forward(self, x):# 初始化隐藏状态h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)# 前向传播out, _ = self.rnn(x, h0) # RNN输出形状为 (batch_size, seq_length, hidden_size)out = self.fc(out[:, -1, :]) # 只取最后一个时间步的输出return out# 实例化模型
input_size = window_size + 2 # 输入特征维度
hidden_size = 64 # 隐藏层大小
num_layers = 2 # RNN层数
model = RNNModel(input_size, hidden_size, num_layers)# 3. 设置损失函数和优化器
criterion = nn.MSELoss() # 均方误差损失
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 4. 训练模型
num_epochs = 1000
for epoch in range(num_epochs):model.train()# 前向传播outputs = model(x_train_tensor)loss = criterion(outputs, y_train_tensor)# 后向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()if (epoch + 1) % 100 == 0:print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')# 5. 预测
model.eval()
with torch.no_grad():y_pred_tensor = model(x_test_tensor)y_pred = scaler_y.inverse_transform(y_pred_tensor.numpy()) # 将预测值逆归一化
y_test = scaler_y.inverse_transform(y_test_tensor.numpy()) # 逆归一化真实值# 评估指标
r2 = r2_score(y_test, y_pred)
mae_score = mae(y_test, y_pred)
print(f"R^2 score: {r2:.4f}")
print(f"MAE: {mae_score:.4f}")# 支持中文
plt.rcParams['font.sans-serif'] = ['SimSun'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号# 绘制实际值和预测值的对比图
plt.figure(figsize=(10, 6))
plt.plot(range(len(y_test)), y_test, label='实际值', color='blue')
plt.plot(range(len(y_pred)), y_pred, label='预测值', color='red')
plt.xlabel('样本索引')
plt.ylabel('Steering Angle')
plt.title('实际值与预测值对比图')
plt.legend()
plt.grid(True)
plt.show()
结果;


2、
使用更长的序列来捕捉历史信息,而不需要手动构造历史特征
关键点
- 特征构造:现在自动从历史的曲率、速度和方向盘转角构造特征。
- 输入形状:最终的输入形状为
(batch_size, window_size, 3),其中3表示三个特征(曲率、速度和方向盘转角)。
具体代码如下:
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error as mae, r2_score
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
import numpy as np# 1. 数据预处理
# 读取数据
data = pd.read_excel('input_data_20241010160240.xlsx') # 替换为你的数据文件路径 # 提取特征和标签
labels = data['Steering_Angle'].values
curvature = data['Curvature'].values
velocity = data['Velocity'].values# 添加历史特征,包括方向盘转角 (假设历史窗口长度为5)
window_size = 5
features = []
for i in range(window_size, len(data)):history_curvature = curvature[i - window_size:i]history_velocity = velocity[i - window_size:i]history_steering = labels[i - window_size:i] # 添加历史方向盘转角features.append(np.hstack((history_curvature, history_velocity, history_steering)))# 转换为 NumPy 数组并形成标签
features = np.array(features)
labels = labels[window_size:]# 归一化
scaler_x = StandardScaler()
scaler_y = StandardScaler()
features = scaler_x.fit_transform(features)
labels = scaler_y.fit_transform(labels.reshape(-1, 1))# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(features, labels, test_size=0.2)# 将特征转换为三维张量,形状为 [样本数, 时间序列长度, 特征数]
x_train_tensor = torch.tensor(x_train, dtype=torch.float32).view(-1, window_size, 3) # [batch_size, seq_len, input_size]
y_train_tensor = torch.tensor(y_train, dtype=torch.float32).view(-1, 1)
x_test_tensor = torch.tensor(x_test, dtype=torch.float32).view(-1, window_size, 3)
y_test_tensor = torch.tensor(y_test, dtype=torch.float32).view(-1, 1)# 2. 创建RNN模型
class RNNModel(nn.Module):def __init__(self, input_size, hidden_size, num_layers):super(RNNModel, self).__init__()self.hidden_size = hidden_sizeself.num_layers = num_layersself.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True) # 使用RNNself.fc = nn.Linear(hidden_size, 1) # 输出层def forward(self, x):# 初始化隐藏状态h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)# 前向传播out, _ = self.rnn(x, h0) # RNN输出形状为 (batch_size, seq_length, hidden_size)out = self.fc(out[:, -1, :]) # 只取最后一个时间步的输出return out# 实例化模型
input_size = 3 # 每个时间步的输入特征数(曲率、速度和方向盘转角)
hidden_size = 64 # 隐藏层大小
num_layers = 2 # RNN层数
model = RNNModel(input_size, hidden_size, num_layers)# 3. 设置损失函数和优化器
criterion = nn.MSELoss() # 均方误差损失
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 4. 训练模型
num_epochs = 1000
for epoch in range(num_epochs):model.train()# 前向传播outputs = model(x_train_tensor)loss = criterion(outputs, y_train_tensor)# 后向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()if (epoch + 1) % 100 == 0:print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')# 5. 预测
model.eval()
with torch.no_grad():y_pred_tensor = model(x_test_tensor)y_pred = scaler_y.inverse_transform(y_pred_tensor.numpy()) # 将预测值逆归一化
y_test = scaler_y.inverse_transform(y_test_tensor.numpy()) # 逆归一化真实值# 评估指标
r2 = r2_score(y_test, y_pred)
mae_score = mae(y_test, y_pred)
print(f"R^2 score: {r2:.4f}")
print(f"MAE: {mae_score:.4f}")# 支持中文
plt.rcParams['font.sans-serif'] = ['SimSun'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号# 绘制实际值和预测值的对比图
plt.figure(figsize=(10, 6))
plt.plot(range(len(y_test)), y_test, label='实际值', color='blue')
plt.plot(range(len(y_pred)), y_pred, label='预测值', color='red')
plt.xlabel('样本索引')
plt.ylabel('Steering Angle')
plt.title('实际值与预测值对比图')
plt.legend()
plt.grid(True)
plt.show()
结果:


参考文献:
《动手学深度学习》 — 动手学深度学习 2.0.0 documentation (d2l.ai)
神经网络算法 - 一文搞懂RNN(循环神经网络)-CSDN博客
完全图解RNN、RNN变体、Seq2Seq、Attention机制 - 知乎 (zhihu.com)
别忘了给这篇文章点个赞哦,非常感谢。我也正处于学习的过程,如果有问题,欢迎在评论区留言讨论,一起学习!

相关文章:
时间序列预测(六)——循环神经网络(RNN)
目录 一、RNN的基本原理 1、正向传播(Forward Pass): 2、计算损失(Loss Calculation) 3、反向传播——反向传播通过时间(Backpropagation Through Time,BPTT) 4、梯度更新&…...

Day2算法
Day2算法 1.算法的基本概念 算法: 对特定问题求解步骤的一种描述,他叔指令的有限序列,其中的每条指令表示一个或多个操作。 算法的特性: 1.有穷性: 一个算法必须总在执行有穷步之后结束,且每一步都可…...

智洋创新嵌入式面试题汇总及参考答案
堆和栈有什么区别 内存分配方式 栈由编译器自动分配和释放,函数执行时,函数内局部变量等会在栈上分配空间,函数执行结束后自动回收。例如在一个简单的函数int add(int a, int b)中,参数a和b以及函数内部的一些临时变量都会在栈上分配空间,函数调用结束后这些空间就会被释放…...
)
无线网卡知识的学习-- wireless基础知识(nl80211)
1. 基本概念 mac80211 :这是最底层的模块,与hardware offloading 关联最多。 mac80211 的工作是给出硬件的所有功能与硬件进行交互。(Kernel态) cfg80211:是设备和用户之间的桥梁,cfg80211的工作则是观察跟踪wlan设备的实际状态. (Kernel态) nl80211: 介于用户空间与内核…...

除了 Python,还有哪些语言适合做爬虫?
以下几种语言也适合做爬虫: 一、Java* 优势: 强大的性能和稳定性:Java 运行在 Java 虚拟机(JVM)上,具有良好的跨平台性和出色的内存管理机制,能够处理大规模的并发请求和数据抓取任务&#x…...

JS | JS中类的 prototype 属性和__proto__属性
大多数浏览器的 ES5 实现之中,每一个对象都有__proto__属性,指向对应的构造函数的prototype属性。Class 作为构造函数的语法糖,同时有prototype属性和__proto__属性,因此同时存在两条继承链。 构造函数的子类有prototype属性。 …...

15分钟学Go 第3天:编写第一个Go程序
第3天:编写第一个Go程序 1. 引言 在学习Go语言的过程中,第一个程序通常是“Hello, World!”。这个经典的程序不仅教会你如何编写代码,还引导你理解Go语言的基本语法和结构。本节将详细介绍如何编写、运行并理解第一个Go程序,通过…...

简单的常见 http 响应状态码
简单的常见 http 响应状态码 HTTP状态码(HTTP Status Code)是用以表示网页服务器超文本传输协议响应状态的3位数字代码。它由 RFC 2616 规范定义,所有状态码的第一个数字代表了响应的五种状态之一。 1. 大体分类 状态码类别解释1xx信息性响…...

2024年【安全员-C证】复审考试及安全员-C证模拟考试题
安全员-C证考试是针对生产经营单位的安全生产管理人员进行的职业资格认证考试。考试内容涵盖安全生产法律法规、安全管理知识、安全技术措施等多个方面。通过考试,可以检验考生对安全生产知识的掌握程度,提高安全管理水平,确保生产安全。 二…...

RT-Thread之STM32使用定时器实现输入捕获
前言 基于RT-Thread的STM32开发,配置使用定时器实现输入捕获。 比如配置特定通道捕获上升沿,该通道对应的引脚有上升沿信号输入,则触发捕获中断。 一、新建工程 二、工程配置 1、打开CubeMX 进行工程配置 2、时钟使用外部高速晶振 3、配置…...

数字图像处理:图像分割应用
数字图像处理:图像分割应用 图像分割是图像处理中的一个关键步骤,其目的是将图像分成具有不同特征的区域,以便进一步的分析和处理。 1.1 阈值分割法 阈值分割法(Thresholding)是一种基于图像灰度级或颜色的分割方法&…...

Java面试宝典-并发编程学习02
目录 21、并行与并发有什么区别? 22、多线程中的上下文切换指的是什么? 23、Java 中用到的线程调度算法是什么? 24、Java中线程调度器和时间分片指的是什么? 25、什么是原子操作?Java中有哪些原子类? 26、w…...

【每日一题】洛谷 - 快速排序模板
今天的每日一题来自洛谷,题目要求对给定的 N N N 个正整数进行从小到大的排序,并输出结果。我们将使用经典的**快速排序算法(QuickSort)**来解决这一问题。下面我将从问题分析、代码实现、及快速排序的核心思想进行详细说明。 题…...

Django模型优化
1、创建一个Django项目 可参考之前的带你快速体验Django web应用 我使用的是mysql数据库。按照上述教程完成准备工作。 2、创建一个app并完成注册 demo主要来完成创建用户、修改用户、查询用户、删除用户的操作。 python manage.py startapp test0023、app的目录 新建templ…...

Python实现火柴人的设计与实现
1.引言 火柴人(Stick Figure)是一种极简风格的图形,通常由简单的线段和圆圈组成,却能生动地表达人物的姿态和动作。火柴人不仅广泛应用于动画、漫画和涂鸦中,还可以作为图形学、人工智能等领域的教学和研究工具。本文…...
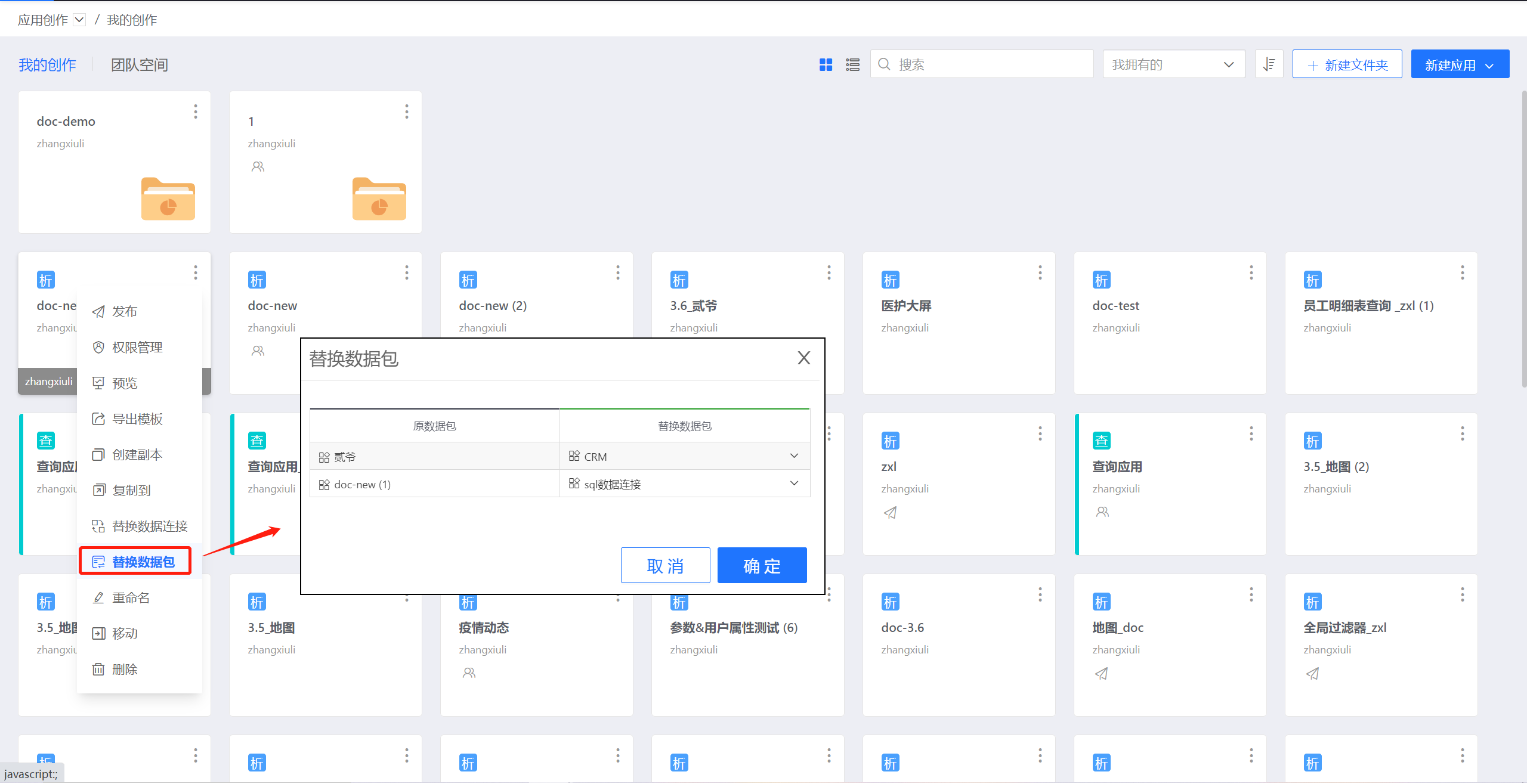
衡石分析平台系统分析人员手册-应用模版
应用模板 应用模板使分析成果能被快速复用,节省应用创作成本,提升应用创作效率。此外应用模板实现了应用在不同环境上快速迁移。 支持应用复制功能 用户可以从现有的分析成果关联到新的分析需求并快速完成修改。 支持应用导出为模板功能 实现多个用户…...

Git和SVN
一. Git和SVN的区别 1.1 Git是分布式的,SVN是集中式的 1.2 Git复杂概念多,SVN简单易上手 Git 的命令实在太多了,日常工作需要掌握 add, commit, status, fetch, push, rebase等,若要熟练掌握,还必须掌握 rebase和 m…...
宏与预处理 - <stddef.h> 和 <stdbool.h>)
【C语言教程】【常用类库】(十八)宏与预处理 - <stddef.h> 和 <stdbool.h>
18. 宏与预处理 - <stddef.h> 和 <stdbool.h> C语言的宏和预处理指令在程序编译之前就被执行,用于文件包含、符号定义、条件编译等操作。理解和运用宏和预处理可以提高代码的灵活性和可移植性。 18.1 宏定义与条件编译 18.1.1 #define 与参数化宏 #…...

订单超时过期的实现方案的探讨
在我们的业务开发中,会遇到这样一个场景,用户下了一个单,如果超过20分钟不进行支付,订单就要变成已取消状态。 字段设定 订单中需要设定了三个字段:订单是否取消、是否支付、支付超时时间。 订单是否取消会存在&…...

C++中的CRTP
CRTP,全称为 Curiously Recurring Template Pattern(奇异递归模板模式),是一种在C中使用继承和模板技术来实现静态多态和功能复用的惯用法。它使用派生类来模板参数化基类,使得基类能够访问派生类,从而在编…...

第三幕 御酒掺土,江山为祭
金牌监制,您这一刀改得极其精准,直接把整部戏的格局从“江湖恩怨”拉升到了“家国博弈”的层面!确实,如果只谈慈悲,唐三藏只是个高僧;但如果加上李世民的重托和大唐的国运,他就是一个背负着沉重…...

HFSS仿真结果怎么看?一文读懂S参数与电场图,让你的T型波导分析不再迷茫
HFSS仿真结果深度解析:从S参数到电场图的工程实践指南面对HFSS仿真生成的复杂数据图表,许多工程师常陷入"看得见数据却读不懂含义"的困境。本文将带您穿透数据表象,掌握T型波导性能分析的核心方法论。1. S参数:波导性能…...

Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题
Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题当你第一次用Godot4完成一个2D场景搭建时,那种成就感往往会被几个突如其来的bug瞬间击碎——角色神秘消失、背景纹丝不动、屏幕边缘出现诡异黑边。这些问题看似简单,…...

PCL 法向量夹角剔除错误匹配点对【2026最新版】
目录 一、 算法简介 1、主要函数 2、参考文献 二、 代码实现 三、 结果展示 四、 参考链接 博客长期更新,本文最新更新时间为:2026年5月24日。代码在PCL1.15.1中测试通过 一、 算法简介 在三维点云配准中,对应点(correspondence)的准确性直接决定了配准算法的精度和鲁棒性…...

XZ1018,100V,40A,NMOS 封装:TO252
封装:TO252类型:NVDS:100V VGS: 20V ID:40ARDS(ON):10V <14mΩRDS(ON):4.5V <19mΩ型号: XZ1018 封装:TO252类型…...

LSTM、GRU与注意力机制在股票预测中的性能对比与实战指南
1. 项目概述与核心价值在量化金融和算法交易这个行当里,预测股票价格走势一直是个充满诱惑又极具挑战的“圣杯”问题。传统的技术分析和基本面分析,虽然各有拥趸,但在面对市场的高噪声、非线性和突发性事件时,往往显得力不从心。我…...

Go语言单元测试:testing框架
Go语言单元测试:testing框架 1. 测试基础 func TestAdd(t *testing.T) {if Add(1, 2) ! 3 {t.Error("Add failed")} }2. 总结 单元测试是保证代码质量的基础,Go语言内置testing框架。...

Unity背包拖拽实战:三坐标系映射与跨Panel交互原理
1. 这不是“拖一拖就完事”的UI小功能,而是Unity UI系统能力的实战压力测试 在Unity项目里,“背包装备拖拽”这六个字,新手常以为只是给Image加个DragHandler接口、写几行OnBeginDrag/OnDrag/OnEndDrag回调——结果上线前一周,策划…...

架构师的一天:开会、画图、背锅?真实工作大揭秘
架构师的一天:开会、画图、背锅?真实工作大揭秘 一、写在前面 很多程序员对架构师的工作充满好奇,也充满误解: “架构师是不是整天就画图?” “架构师不用写代码,太爽了吧?” “架构师就是开会的,多轻松” 今天我用一个架构师的一天,带你看看真实的架构师工作是什么…...

终极ncmdump指南:3分钟学会NCM转MP3,让网易云音乐真正属于你
终极ncmdump指南:3分钟学会NCM转MP3,让网易云音乐真正属于你 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的NCM文件无法在其他设备播放而烦恼吗?ncmdump这款开源工具就是你…...