Spring AI Java程序员的AI之Spring AI(四)
Spring AI之Java经典面试题智能小助手
- 前言
- 一、准备面试题
- 二、搭建工程
- 三、文件读取与解析
- 四、Markdown文件解析
- 五、问题搜索
- 六、自定义EmbeddingClient
- 七、定义请求Controller
前言
通过Ollama在本地部署了Llama3大模型,这篇来基于Llama3和Spring AI,以及ChatGPT Web来实现一个Java经典面试题智能小助手。
私有化部署大模型最佳解决方案 Ollama
一、准备面试题
建议优先使用marddown或txt等文本格式,因为经过尝试,如果导出为PDF格式,会出现格式错乱。
ThreadLocal和InheritableThreadLocal的区别
ThreadLocal和InheritableThreadLocal都可以用通过线程来共享数据,区别在于当前线程在InheritableThreadLocal中设置的值可以被子线程继承,并且是复制(也就是子线程和父线程一开始InheritableThreadLocal中的值时一致的,但是后续的修改互不影响),而当前线程在ThreadLocal中设置的值不会被子线程所继承。
如何理解Java中的装箱与拆箱
装箱,就是int类型包装为Integer类型,拆箱,就是反过来,因为Java中支持8种基本数据类型,每种基本类型都有对应的包装类型,装箱会调用valueOf()方法,传入基本类型,返回包装类型,这个方法中通常会有一个缓存,比如用来缓存数字1对应的Integer对象,拆箱会调用intValue()方法,返回基本类型,不要过多的进行装箱和拆箱,毕竟是在调方法,是消耗性能的。
Java中为什么要有基础类型
Java是面向对象的,一切都是对象,但是像字符、数字这些常用类型,每次用的时候也去new对象,就会比较费性能和内存了,所以Java设计了8种基础类型,在使用基础类型时,对应的内存空间是直接分配在栈上的,而不是分配在堆上,这样性能也更好。
说说进程和线程的区别
一个操作系统上会运行很多个程序,这些程序都有自己的代码,以及都要用内存来存代码,和代码运行过程中产生的数据,进程就是用来隔离各个程序的内存空间的,使得程序之间互不干扰,还是这多个程序,为了让它们能同时运行,CPU就需要先执行这个程序的几条指令,然后切换到另外一个程序去执行,然后再切回来,就像同时在运行多条指令流水线,而这个流水线就是线程,是CPU调度的最小单位
为什么Java不支持多继承?
首先,思考这么一种场景,假如现在A类继承了B类和C类,并且B类和C类中,都存在test()方法,那么当A类对象调用test()方法时,该调用B类的test()呢?还是C类的test()呢?是没有答案的,所以Java中不允许多继承。
String、StringBuffer、StringBuilder的区别
- String是不可变的,如果尝试去修改,会新生成一个字符串对象,StringBuffer和StringBuilder是可变的
- StringBuffer是线程安全的,StringBuilder是线程不安全的,所以在单线程环境下StringBuilder效率会更高
二、搭建工程
引入SpringBoot:
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.2.1</version>
</parent>
引入Spring AI
<dependencyManagement><dependencies><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-bom</artifactId><version>0.8.1-SNAPSHOT</version><type>pom</type><scope>import</scope></dependency></dependencies>
</dependencyManagement>
引入spring web
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId>
</dependency>
引入Ollama
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency>
引入Markdown解析器
<dependency><groupId>com.vladsch.flexmark</groupId><artifactId>flexmark</artifactId><version>0.42.14</version>
</dependency>
引入Redis向量数据库相关
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-redis</artifactId>
</dependency><dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>5.1.0</version>
</dependency>
指定仓库
<repositories><repository><id>spring-milestones</id><name>Spring Milestones</name><url>https://repo.spring.io/milestone</url><snapshots><enabled>false</enabled></snapshots></repository><repository><id>spring-snapshots</id><name>Spring Snapshots</name><url>https://repo.spring.io/snapshot</url><releases><enabled>false</enabled></releases></repository>
</repositories>
三、文件读取与解析
新建InterviewService,提供向量存储、向量搜索功能:
@Bean
public RedisVectorStore vectorStore(EmbeddingClient embeddingClient) {RedisVectorStore.RedisVectorStoreConfig config = RedisVectorStore.RedisVectorStoreConfig.builder().withURI("redis://localhost:6379").withIndexName("interview-assistant-index").withMetadataFields(RedisVectorStore.MetadataField.text("filename")).build();return new RedisVectorStore(config, embeddingClient);
}
package com.qjc.demo.service;import org.springframework.ai.document.Document;
import org.springframework.ai.reader.TextReader;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.core.io.Resource;
import org.springframework.stereotype.Component;import java.util.List;/**** @projectName spring-ollama-demo* @packageName com.qjc.demo.service* @author qjc* @description TODO* @Email qjc1024@aliyun.com* @date 2024-10-18 10:23**/@Component
public class InterviewService {@Value("classpath:Java基础面试题.md")private Resource resource;@Autowiredprivate VectorStore vectorStore;public List<Document> loadText() {// 读取文件内容TextReader textReader = new TextReader(resource);List<Document> documents = textReader.get();// 解析文件内容MarkdownSplitter textSplitter = new MarkdownSplitter();List<Document> list = textSplitter.apply(documents);// 将问题提取出来存入Metadatalist.forEach(document -> {String title = document.getContent().split("==title==")[0];String replace = title.replace("##", "");document.getMetadata().put("question", replace.trim());});// 向量化以及向量存储vectorStore.add(list);return list;}public List<Document> search(String message){// ...}
}四、Markdown文件解析
思路是:通过解析文件中的二级标题和标题下的内容,得到一个Document,标题和内容直接用"title"分割。
package com.com.qjc.demo.utils;import com.vladsch.flexmark.ast.Heading;
import com.vladsch.flexmark.parser.Parser;
import com.vladsch.flexmark.util.ast.Document;
import com.vladsch.flexmark.util.ast.Node;
import com.vladsch.flexmark.util.collection.iteration.ReversiblePeekingIterator;
import org.springframework.ai.transformer.splitter.TextSplitter;import java.util.ArrayList;
import java.util.List;
/**** @projectName spring-ollama-demo* @packageName com.qjc.demo.utils* @author qjc* @description TODO* @Email qjc1024@aliyun.com* @date 2024-10-18 10:23**/
public class MarkdownSplitter extends TextSplitter {@Overrideprotected List<String> splitText(String text) {Parser parser = Parser.builder().build();Document markdownDocument = parser.parse(text);List<String> result = new ArrayList<>();ReversiblePeekingIterator<Node> iterator = markdownDocument.getChildren().iterator();StringBuilder builder = new StringBuilder();while (iterator.hasNext()) {Node node = iterator.next();// 如果是二级标题if (node instanceof Heading && ((Heading) node).getLevel() == 2) {if (!builder.isEmpty()) {result.add(builder.toString());}builder.delete(0, builder.length());builder.append(node.getChars());builder.append("==title==");} else {builder.append(node.getChars());}}if (!builder.isEmpty()) {result.add(builder.toString());}return result;}
}五、问题搜索
public List<Document> search(String question){// 先查元数据SearchRequest metaSearchRequest = SearchRequest.query(question).withTopK(3).withSimilarityThreshold(0.9).withFilterExpression(String.format("question in ['%s']", question));List<Document> metaDocuments = vectorStore.similaritySearch(metaSearchRequest);if (!CollectionUtils.isEmpty(metaDocuments)) {return metaDocuments;}// 元数据没查到在相似搜索SearchRequest searchRequest = SearchRequest.query(question).withTopK(3).withSimilarityThreshold(0.9);return vectorStore.similaritySearch(searchRequest);}
六、自定义EmbeddingClient
默认情况下是对问题和答案同时进行向量化,如果只想对问题进行向量化,则需要自定义EmbeddingClient:
package com.qjc.demo.config;import org.springframework.ai.document.Document;
import org.springframework.ai.ollama.OllamaEmbeddingClient;
import org.springframework.ai.ollama.api.OllamaApi;import java.util.List;/**** @projectName spring-ollama-demo* @packageName com.qjc.demo.config* @author qjc* @description TODO* @Email qjc1024@aliyun.com* @date 2024-10-18 10:23**/
public class QjcOllamaEmbeddingClient extends OllamaEmbeddingClient {public QjcOllamaEmbeddingClient (OllamaApi ollamaApi) {super(ollamaApi);}@Overridepublic List<Double> embed(Document document) // 单独对问题进行向量化String question = (String) document.getMetadata().get("question");return this.embed(question);}
}@Beanpublic QjcOllamaEmbeddingClient ollamaEmbeddingClient(OllamaApi ollamaApi, OllamaEmbeddingProperties properties) {QjcOllamaEmbeddingClient qjcOllamaEmbeddingClient = new QjcOllamaEmbeddingClient (ollamaApi);qjcOllamaEmbeddingClient.withModel("nomic-embed-text:v1.5");return qjcOllamaEmbeddingClient;}
七、定义请求Controller
package com.qjc.demo.controller;import org.springframework.ai.chat.ChatClient;
import org.springframework.ai.chat.ChatResponse;
import org.springframework.ai.chat.StreamingChatClient;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.document.Document;
import org.springframework.ai.openai.api.OpenAiApi;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.servlet.mvc.method.annotation.SseEmitter;
import reactor.core.publisher.Flux;import java.io.IOException;
import java.util.HashMap;
import java.util.List;
import java.util.Map;/**** @projectName spring-ollama-demo* @packageName com.qjc.demo.controller* @author qjc* @description TODO* @Email qjc1024@aliyun.com* @date 2024-10-18 10:23**/
@RestController
public class ChatController {@Autowiredprivate StreamingChatClient chatClient;@Autowiredprivate InterviewService interviewService;@GetMapping("/document")public List<Document> document() {return interviewService.loadText();}@GetMapping("/documentSearch")public List<Document> documentSearch(@RequestParam String message) {return interviewService.search(message);}@PostMapping(value = "/v1/chat/completions", produces = MediaType.TEXT_EVENT_STREAM_VALUE)public Flux<OpenAiApi.ChatCompletionChunk> interview(@RequestBody OpenAiApi.ChatCompletionRequest request) {String question = request.messages().get(1).content();// 向量搜索List<Document> documentList = interviewService.search(question);// 提示词模板PromptTemplate promptTemplate = new PromptTemplate("{userMessage}\n\n 用中文,并根据以下信息回答问题:\n {contents}");// 组装提示词Prompt prompt = promptTemplate.create(Map.of("userMessage", question, "contents", documentList));// 调用大模型Flux<ChatResponse> stream = chatClient.stream(prompt);return stream.map(chatResponse -> {String content = chatResponse.getResult().getOutput().getContent();// 需要优化OpenAiApi.ChatCompletionChunk chatCompletionChunk = new OpenAiApi.ChatCompletionChunk("1",List.of(new OpenAiApi.ChatCompletionChunk.ChunkChoice(OpenAiApi.ChatCompletionFinishReason.STOP,1,new OpenAiApi.ChatCompletionMessage(content,OpenAiApi.ChatCompletionMessage.Role.ASSISTANT), new OpenAiApi.LogProbs(null))),null, null, null, null);return chatCompletionChunk;});}
}相关文章:
)
Spring AI Java程序员的AI之Spring AI(四)
Spring AI之Java经典面试题智能小助手 前言一、准备面试题二、搭建工程三、文件读取与解析四、Markdown文件解析五、问题搜索六、自定义EmbeddingClient七、定义请求Controller 前言 通过Ollama在本地部署了Llama3大模型,这篇来基于Llama3和Spring AI,以…...

精选20个爆火的Python实战项目(含源码),直接拿走不谢!
今天给大家介绍20个非常实用的Python项目,帮助大家更好的学习Python。 完整版Python项目源码,【点击这里】领取! ① 猜字游戏 import random def guess_word_game(): words ["apple", "banana", "cherry&quo…...

Rocky Linux 9安装Asterisk 20和freepbx 17脚本——筑梦之路
脚本搜集来自Rocky Linux 9安装Asterisk 20和freepbx 17脚本 #!/bin/bash#Preparacion de ambiente de RockyLinuxecho "Deshabilitar SELINUX /etc/selinux/config "sed -i s/^SELINUX.*$/SELINUXdisabled/ /etc/selinux/configecho "Establecer nombre de maq…...
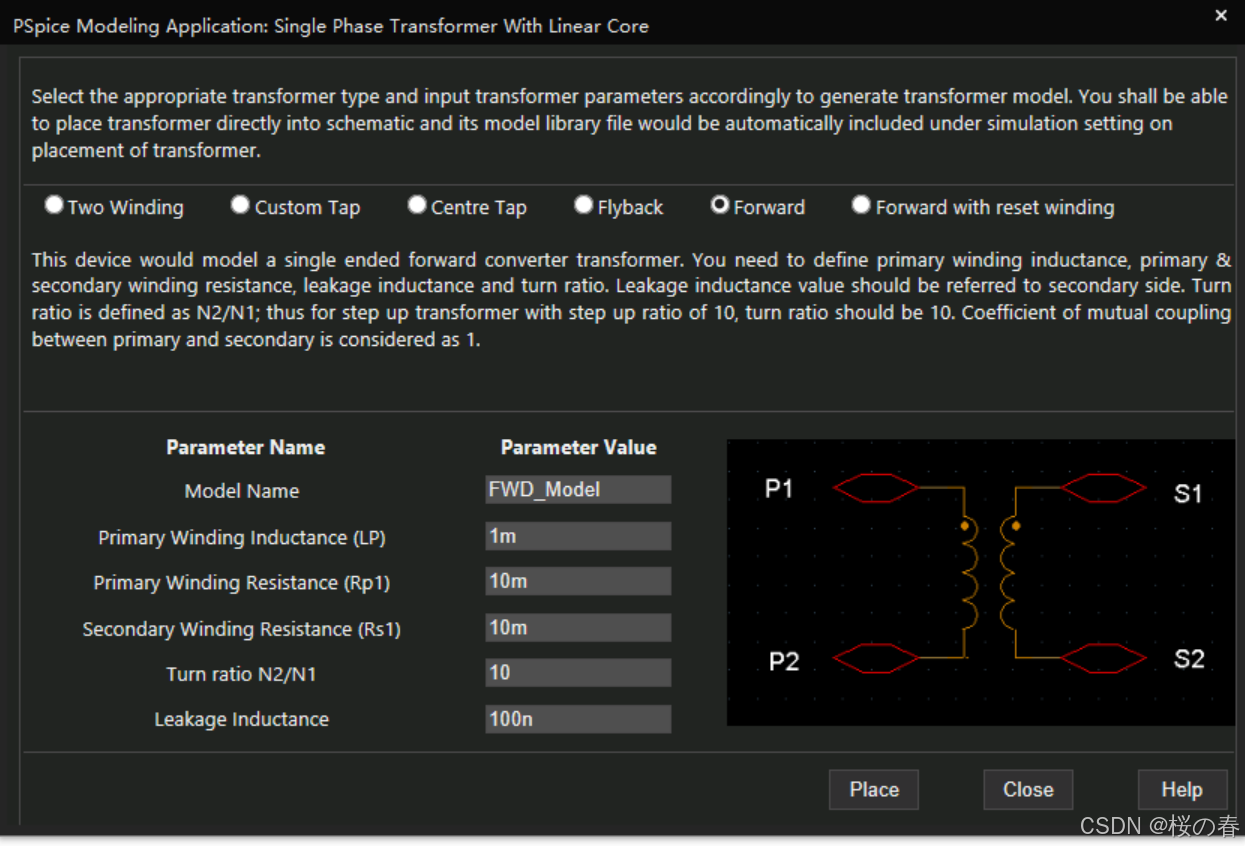
PSPICE FOR TI笔记记录1
快捷放置器件 R旋转 连线 w,单击器件引脚方块部分 电压探测笔 创建仿真文件 Analysis Type 分析模式:比如时域分析,频域分析 Run To Time 仿真时长 Skip intial transient bias point calculation (跳过初始瞬态偏置点计算(SKIPBP))一定要勾选 编辑…...
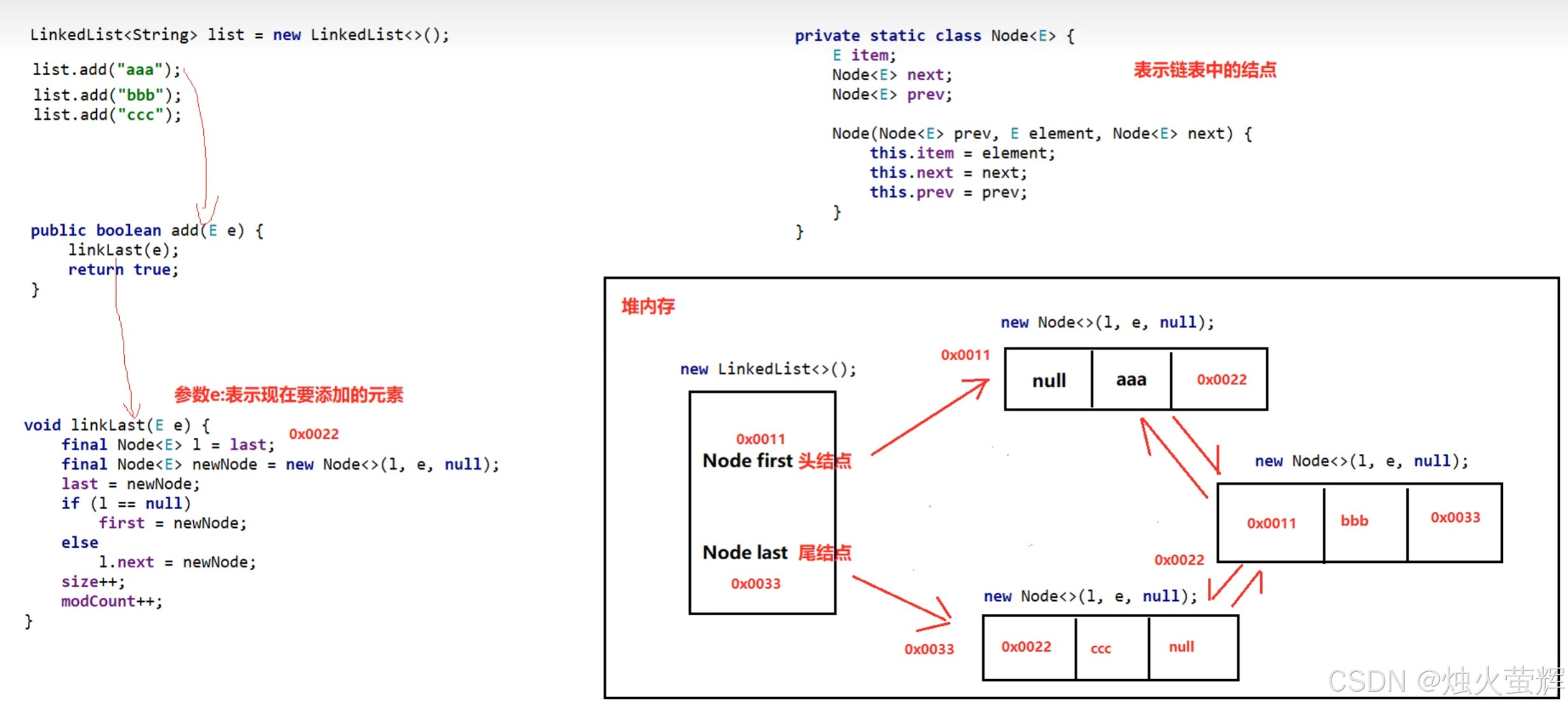
Java集合剖析4】LinkedList
目录 一、LinkedList的特有方法 二、LinkedList的底层数据结构 三、插入方法的具体实现 一、LinkedList的特有方法 LinkedList的底层是双向链表,它提供了操作首尾结点的方法 二、LinkedList的底层数据结构 LinkedList的底层是一个双向链表,有一个结点内部…...
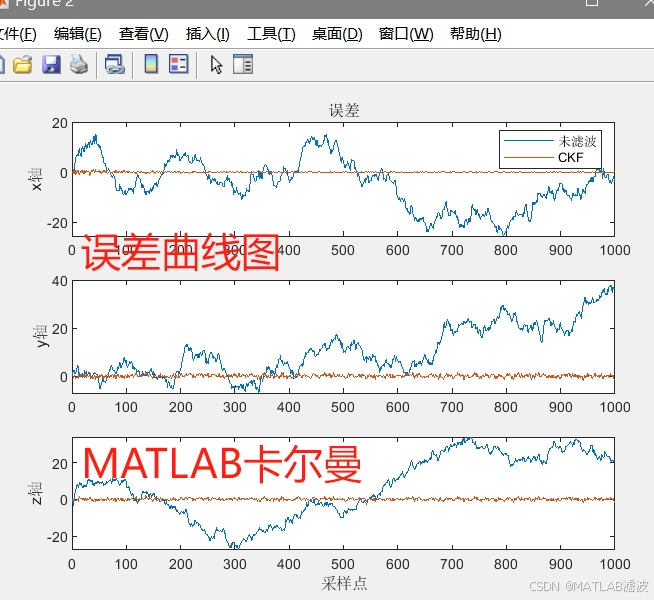
基于MATLAB/octave的容积卡尔曼滤波(CKF)【带逐行注释】
介绍 CKF的三维滤波程序例程 产品概述 我们的 MATLAB 数据处理工具是专为科研人员、工程师和数据分析师设计的高效解决方案。该工具提供了一系列强大的功能,能够快速处理和分析大规模数据集,适用于各种科学和工程应用,包括信号处理、图像分…...

Python编程探索:从基础语法到循环结构实践(下)
文章目录 前言🍷四、 字符串拼接:连接多个字符串🍸4.1 使用 操作符进行字符串拼接🍸4.2 使用 join() 方法进行字符串拼接🍸4.3 使用 format() 方法进行格式化拼接🍸4.4 使用 f-string(格式化字…...

简介openwrt系统下/etc/config/network文件生成过程
openwrt的network文件,或者说在/etc/config下的文件,都是动态生成的。 脚本的函数定义在package/base-files/files/lib/functions中,有以下几个文件: libraSVN:~/Wang_SP4/openwrt-d03dc49/package/base-files/files/lib/functi…...

javaWeb项目-Springboot+vue-XX图书馆管理系统功能介绍
本项目源码(点击下方链接下载):java-springbootvue阿博图书馆管理系统源码(项目源码-说明文档)资源-CSDN文库 项目关键技术 开发工具:IDEA 、Eclipse 编程语言: Java 数据库: MySQL5.7 框架:ssm、Springboot 前端&…...

华为ENSP用户权限深度解析:构建安全高效的网络管理
在华为ENSP(Enterprise Network Simulation Platform)用户界面中,用户权限级别是一个重要的概念,它用于限制不同用户访问设备的权限,从而增加设备管理的安全性。以下是对华为ENSP用户界面用户权限级别的详细解释&#…...
NFC之NDEF
NDEF的通用格式 MB标志是一个1位字段,当其被设置时,表示NDEF消息的开始。 ME标志是一个1位字段,当其被设置时,表示NDEF消息的结束。 CF标志是一个1位字段,指示这是分块有效载荷的第一个记录块或中间记录块。 SR标志是…...

学习第三十六行
QValidator::State里面state为0,完全不匹配,1,部分匹配,2,完全匹配,对于label或者textedit里面的字符均为QString类型,特别是遇到数字,需要QString::number转化,对于正则表达式&…...

停车场问题
实验内容 1.问题描述: 设停车场是一个可停放n辆汽车的狭长通道,且只有一个大门可供汽车进出。汽车在停车场内按车辆达到时间的先后顺序,依次由北向南排列(大门在最南端,最先达到的第一辆车停放在车场的最北端),若车场…...

海康相 机
海康机器人-机器视觉-下载中心 海康威视MVS客户端及虚拟相机c开发案例-CSDN博客 相机驱动下载: 下载中心 VisionMaster 视频教程_哔哩哔哩_bilibili 【VisionMaster】试用版安装说明_visionmaster试用版-CSDN博客 海康视觉算法平台VisionMaster 4.3.0 C# 二次…...

用map实现el-table全选
<el-button size"small" type"primary" click"searchProxy">查询</el-button><el-checkbox v-model"selectAll" change"changeSelectAll" >全选</el-checkbox><el-table:data"taskList&…...

【开源免费】基于SpringBoot+Vue.JS社区团购系统(JAVA毕业设计)
本文项目编号 T 024 ,文末自助获取源码 \color{red}{T024,文末自助获取源码} T024,文末自助获取源码 目录 一、系统介绍二、演示录屏三、启动教程四、功能截图五、文案资料5.1 选题背景5.2 国内外研究现状5.3 可行性分析5.4 用例设计 六、核…...

Java进阶之路:构造方法
🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝 🥇博主昵称:小菜元 🍟博客主页…...
2025秋招八股文--网络原理篇
前言 1.本系列面试八股文的题目及答案均来自于网络平台的内容整理,对其进行了归类整理,在格式和内容上或许会存在一定错误,大家自行理解。内容涵盖部分若有侵权部分,请后台联系,及时删除。 2.本系列发布内容分为12篇…...

C#基础-面向对象的七大设计原则
目录 1.开放封闭原则(OCP) 2.单一职责原则(SRP) 3.依赖倒置原则(DIP) 4.里氏替换原则(LSP) 5.接口隔离原则(ISP) 6.合成复用原则(CRP&#…...

CSS 容器查询一探究竟
引言 在 《请列举四种「等比例自适应矩形」实现方案?》 一文中我曾使用到容器查询单位 cqw, 当时在使用 cqw 过程中只是简单过了一下容器查询相关的内容!! 所以这次专门出一篇文章, 对容器查询做一个梳理… 一、是什么 在实际开发中您是否遇到过需要根据父容器的…...

Flux Sea Studio 高可用部署架构:负载均衡与故障转移设计
Flux Sea Studio 高可用部署架构:负载均衡与故障转移设计 最近在帮几个团队部署AI绘画服务时,发现一个挺普遍的问题:单个模型实例一旦遇到高并发或者服务器出点小毛病,服务就很容易挂掉,用户体验直线下降。特别是像Fl…...

科学/技术路线之争、天才 vs 体制、创新 vs 实用的对立故事
文章目录一、最像「交流电 vs 直流电」的路线大战1. **尼古拉特斯拉 vs 托马斯爱迪生**(你已知的原型)二、同级别的「史诗级科学互怼」2. **伽利略 vs 教会/亚里士多德学派**3. **牛顿 vs 莱布尼茨**4. **爱因斯坦 vs 玻尔**5. **巴斯德 vs 普歇**三、技…...

批量设计元素替换:提升设计师效率的智能工作流解决方案
批量设计元素替换:提升设计师效率的智能工作流解决方案 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 在现代UI设计和品牌视觉开发流程中,设计师经常面临需…...

BilibiliDown场景化使用指南:从新手到专家的B站视频管理方案
BilibiliDown场景化使用指南:从新手到专家的B站视频管理方案 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mir…...

浏览器中的开发革命:Core72在线IDE版本控制实战指南
浏览器中的开发革命:Core72在线IDE版本控制实战指南 【免费下载链接】core Online IDE powered by Visual Studio Code ⚡️ 项目地址: https://gitcode.com/gh_mirrors/core72/core 当你在咖啡馆突然收到紧急修复需求,却发现没带开发笔记本时&am…...

构建企业级视频监控平台:WVP-GB28181-Pro的3大技术架构突破
构建企业级视频监控平台:WVP-GB28181-Pro的3大技术架构突破 【免费下载链接】wvp-GB28181-pro 基于GB28181-2016、部标808、部标1078标准实现的开箱即用的网络视频平台。自带管理页面,支持NAT穿透,支持海康、大华、宇视等品牌的IPC、NVR接入。…...

如何在Windows电脑上轻松安装安卓应用?APK Installer完整使用指南
如何在Windows电脑上轻松安装安卓应用?APK Installer完整使用指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为无法在电脑上运行手机应用而烦恼吗…...

设备资产管理系统 + 工业软件集成:打通数据孤岛,释放智能运维新价值
在工业数字化转型浪潮中,越来越多企业意识到单一系统难以支撑复杂的设备管理需求。设备资产管理系统与 ERP、MES、PLM 等工业软件的集成,正成为提升运维效率、降低成本、实现预测性维护的关键路径。本文以科普视角,解析集成的核心价值、典型应…...

Python爬虫入门零门槛!30分钟爬取软科中国大学排名,生成交互式可视化排名表
做Python入门学习的同学,是不是都想找一个反爬弱、代码清晰、爬下来有用、能快速看到成果的实战项目? 很多入门教程要么爬一些过时的、没用的静态页面,要么代码写得晦涩难懂,要么爬下来的数据只是打印在控制台,完全没有…...
与互斥量(Mutex)深度剖析》)
3.1《庖丁解牛:信号量(Semaphore)与互斥量(Mutex)深度剖析》
庖丁解牛:信号量(Semaphore)与互斥量(Mutex)深度剖析 001、并发编程基石:为何需要信号量与互斥量? 深夜两点,调试器停在了第187行。 一个看似简单的计数器,在双核芯片上跑了不到十分钟,数值就开始“跳变”——有时加一,有时加二,偶尔还会倒退。逻辑检查了三遍,没…...