wireshark或tshark提取tcpdump捕获的数据包(附python脚本自动解析文件后缀)
tcpdump 捕获数据包后,保存的文件通常会被命名为 capture.pcap(或其他你指定的名称),并存储在你运行命令的当前目录中。以下是如何使用 tcpdump 进行流量捕获,并找到和使用捕获文件的详细步骤。
1. 使用 tcpdump 捕获流量
在终端中运行以下命令来捕获流量并将其保存到 capture.pcap 文件中:
sudo tcpdump -i ens33 -w capture.pcap
-i ens33: 指定你要监听的网络接口,例如ens33。你需要根据你的网络接口名称进行调整。-w capture.pcap: 将捕获的数据包写入capture.pcap文件中。
2. 停止捕获
你可以通过按 Ctrl+C 来停止捕获。
3. 找到捕获文件
tcpdump 会将捕获的数据包保存到你运行命令的当前目录中。你可以通过以下命令查看当前目录中的文件:
ls -l
你应该会看到一个名为 capture.pcap 的文件。
4. 使用 Wireshark 分析捕获文件
Wireshark 是一个强大的网络协议分析工具,可以帮助你分析捕获的数据包。以下是如何使用 Wireshark 打开并分析 capture.pcap 文件的步骤:
安装 Wireshark
如果你还没有安装 Wireshark,可以使用以下命令来安装:
sudo apt-get update
sudo apt-get install wireshark
5. 使用 tcpdump 直接查看捕获文件
如果你不想使用 Wireshark,也可以使用 tcpdump 直接查看捕获文件的内容:
tcpdump -r capture.pcap
这将显示捕获文件中的数据包内容。你还可以使用 -n 选项来禁止 DNS 解析,使用 -X 选项来显示数据包的十六进制和 ASCII 表示:
tcpdump -n -X -r capture.pcap使用Wireshark从捕获的文件数据包中提取文本或图像
如果你通过 tcpdump 或类似工具捕获的数据包(如 capture.pcap)中包含文本文件或图像文件,你需要先将这些数据提取到具体文件中。可以使用 Wireshark 来进行提取。
使用 Wireshark 提取文件
-
打开 Wireshark 并加载捕获文件:
wireshark capture.pcap -
找到所需的数据包,右键点击数据包,在弹出菜单中选择 “Export Packet Bytes” 或 “Export Objects”。
-
选择适当的文件类型(例如 HTTP 或 文件类型),然后将其保存到所需的文件位置。
wireshark capture.pcap 这条命令的目的是使用 Wireshark 打开并分析一个名为 capture.pcap 的捕获文件。以下是详细的操作步骤和相关说明。
这条命令会执行以下操作:
- 启动 Wireshark:Wireshark 是网络协议分析工具,用于捕获和分析网络数据包。
- 加载捕获文件:Wireshark 会打开指定名为
capture.pcap的文件。.pcap是 Wireshark 使用的标准捕获文件格式,通常用于存储捕获的网络数据包。
Wireshark 界面介绍
启动 Wireshark 并加载 capture.pcap 后,你会看到 Wireshark 的主界面,通常包括以下几个主要部分:
- 工具栏:提供常用的操作按钮,如播放、停止、过滤、保存等。
- 数据包列表:显示捕获文件中的所有数据包,通常包括序号、时间戳、源地址、目标地址、协议和长度等信息。
- 数据包详情:显示选中的数据包的详细信息,包括各个协议层的信息。
- 数据包字节:显示选中的数据包的原始字节数据。
分析捕获文件
在 Wireshark 中打开捕获文件后,你可以进行以下操作来分析数据包:
- 过滤数据包:在过滤器栏中输入表达式,例如
http或tcp.port == 80,以过滤特定的协议或端口。 - 查看数据包详情:双击数据包列表中的任意数据包,可以在数据包详情窗格中查看该数据包的详细信息。
- 查找特定数据:使用 “Edit” -> “Find Packet” 功能查找特定数据包。
- 统计信息:使用 “Statistics” 菜单中的各种选项来查看捕获文件的统计信息,例如协议层次结构、会话列表等。
保存和导出数据
Wireshark 允许你保存和导出分析结果:
- 保存文件:你可以保存当前捕获文件的修改版本,或者将分析结果保存为其他格式(如
.txt或.csv)。 - 导出数据包:你可以将选定的数据包导出为单独的捕获文件,或者导出为其他格式(如
.xml或.json)。
提取文件
如果你在捕获的数据包中发现了文件(如文本文件、图像文件等),可以使用 Wireshark 的 “Export Objects” 功能将这些文件提取出来:
- 右键点击数据包,选择 “Export Packet Bytes”。
- 选择适当的文件类型(如 HTTP 或 文件类型),然后将其保存到所需的文件位置。
wireshark capture.pcap 这一命令主要用于启动 Wireshark 的图形用户界面 (GUI),以便你可以可视化地分析网络数据包。Wireshark 作为一个网络协议分析工具,设计上就是为了提供直观的图形界面,以便用户能够方便地查看和分析捕获的数据包。
tshark命令行替代方案
如果你需要在没有图形界面的环境(如服务器或远程访问时)分析 .pcap 文件,可以使用以下命令行工具替代 Wireshark:
a. tshark
Tshark 是 Wireshark 的命令行版本,功能强大,可以用来捕获或分析网络数据包。
-
安装 tshark(如果已经安装 Wireshark,tshark 通常会自动安装):
sudo apt-get install tshark -
使用 tshark 打开 .pcap 文件:
tshark -r capture.pcap这将输出捕获文件中的数据包信息,你可以使用不同的选项来过滤、格式化输出等。
-
常用的 tshark 参数:
-
查看指定协议的数据包:
tshark -r capture.pcap -Y "http" -
只显示基础信息:
tshark -r capture.pcap -T fields -e frame.number -e ip.src -e ip.dst
-
使用 Tshark 提取文件
如果你需要在命令行环境中提取文件,可以使用 Tshark 来解析 .pcap 文件并将特定文件内容提取到标准输出或文件中。
a. 提取 HTTP 文件内容
如果你知道文件是通过 HTTP 传输的,可以使用以下命令来提取文件内容:
tshark -r capture.pcap -Y "http.request or http.response" -T fields -e http.file_data > output_file
-r capture.pcap:指定要读取的.pcap文件。-Y "http.request or http.response":过滤条件,指定只处理 HTTP 请求或响应。-T fields -e http.file_data:提取 HTTP 文件数据。> output_file:将提取的内容保存到output_file中。
b. 提取特定数据包中的数据
如果你知道特定的数据包(例如,数据包的序号或流标识符),可以使用以下命令来提取数据:
tshark -r capture.pcap -R "frame.number == 123" -T fields -e data > output_file
-R "frame.number == 123":根据数据包序号过滤数据包。-T fields -e data:提取数据包的原始数据。> output_file:将提取的内容保存到output_file中。
保存提取的文件
提取的内容可以保存为文件,以便进一步分析或查看。你可以使用常见的文件操作命令(如 cat、echo、tee 等)来保存内容。
使用 Tshark 提取 HTTP 文件示例
在使用 Tshark 提取 HTTP 文件时,你需要手动指定文件后缀,或者根据文件内容自动识别文件类型并添加后缀。
a. 提取 HTTP 文件内容
假设你要提取一个 HTTP 文件内容并保存为文件:
tshark -r capture.pcap -Y "http.request or http.response" -T fields -e http.file_data > output.html
在这个例子中,我们将提取的内容保存为 output.html。你可以根据文件实际类型(如 .jpg、.txt 等)更改文件后缀。
b. 根据文件内容自动识别文件类型
如果你不确定文件类型,可以使用 file 命令来识别文件类型,或者使用 Perl、Python 等脚本来解析文件头并自动添加合适的后缀。
使用 file 命令
file -b --mime-type output.html
根据输出的 MIME 类型(如 text/html、image/jpeg 等),你可以决定文件的后缀。
使用脚本自动添加后缀
你可以编写一个简单的脚本来解析文件头并添加合适的后缀:
import sys
import mimetypesdef add_suffix(file_path):with open(file_path, 'rb') as f:file_header = f.read(1024)mime_type, _ = mimetypes.guess_type(None, file_header)if mime_type:file_name, _ = file_path.rsplit('.', 1)new_file_name = f"{file_name}.{mimetypes.guess_extension(mime_type)}"print(f"Renaming to: {new_file_name}")os.rename(file_path, new_file_name)if __name__ == "__main__":if len(sys.argv) != 2:print("Usage: python script.py <file_path>")else:file_path = sys.argv[1]add_suffix(file_path)
将上述脚本保存为 script.py,然后在终端中运行:
python script.py output.html
这个脚本的输入文件名可以是任意后缀,甚至没有后缀的文件名,因为它通过读取文件的前 1024 字节来猜测文件的 MIME 类型,并根据 MIME 类型为其添加合适的后缀。如果 MIME 类型被成功猜测到,脚本会根据 MIME 类型生成一个新的文件名,添加合适的后缀。
注意
当你使用 Wireshark 或 Tshark 从捕获的数据包中提取 HTTP 请求内容并保存为 .html 文件时,如果打开文件后直接跳转到百度的首页,这通常是因为提取的内容是一个完整的 HTML 页面,包含了 HTML、CSS、JavaScript 等内容,这些内容在被浏览器解析时会触发相应的请求和跳转。
详细解释
-
提取的 HTML 文件内容:
- 提取的
.html文件实际上是一个完整的 HTML 页面,包含了<html>、<head>、<body>等标签。 - 这个 HTML 页面可能包含了
<meta>标签、JavaScript 代码等,这些内容会指示浏览器进行跳转或加载其他资源(如 CSS、图片、JavaScript 文件等)。
- 提取的
-
浏览器行为:
- 当你在浏览器中打开这个
.html文件时,浏览器会解析 HTML 内容,并执行其中的 JavaScript 代码。 - 如果页面中包含如
<meta http-equiv="refresh" content="0;url=http://www.baidu.com">这样的标签,或者 JavaScript 代码中有window.location.href = "http://www.baidu.com";这样的语句,浏览器会根据这些指令跳转到指定的 URL(如百度的首页)。
- 当你在浏览器中打开这个
示例
假设你提取的 HTML 文件内容如下:
<!DOCTYPE html>
<html>
<head><meta http-equiv="refresh" content="0;url=http://www.baidu.com"><title>Redirecting...</title>
</head>
<body><p>You are being redirected to <a href="http://www.baidu.com">Baidu</a>.</p>
</body>
</html>
在这种情况下,浏览器会根据 <meta http-equiv="refresh" content="0;url=http://www.baidu.com"> 标签立即跳转到 http://www.baidu.com。
解决方法
如果你不希望浏览器跳转到百度的首页,而是想查看实际的 HTML 内容,可以尝试以下方法:
-
删除跳转代码:
- 打开提取的
.html文件,删除包含跳转指令的<meta>标签或 JavaScript 代码。
- 打开提取的
-
使用文本编辑器查看:
- 使用文本编辑器(如 Notepad++、VS Code 等)打开
.html文件,查看和编辑其中的内容。
- 使用文本编辑器(如 Notepad++、VS Code 等)打开
-
使用命令行工具:
- 如果你只关心特定的内容,可以使用命令行工具(如
grep、sed、awk等)提取和过滤你需要的内容。
- 如果你只关心特定的内容,可以使用命令行工具(如
-
禁用 JavaScript:
- 在浏览器中禁用 JavaScript(不同浏览器有不同的方法),或者使用浏览器的安全模式(如 Chrome 的隐身模式)打开
.html文件,以防止 JavaScript 代码执行跳转。
- 在浏览器中禁用 JavaScript(不同浏览器有不同的方法),或者使用浏览器的安全模式(如 Chrome 的隐身模式)打开
相关文章:
)
wireshark或tshark提取tcpdump捕获的数据包(附python脚本自动解析文件后缀)
tcpdump 捕获数据包后,保存的文件通常会被命名为 capture.pcap(或其他你指定的名称),并存储在你运行命令的当前目录中。以下是如何使用 tcpdump 进行流量捕获,并找到和使用捕获文件的详细步骤。 1. 使用 tcpdump 捕获…...
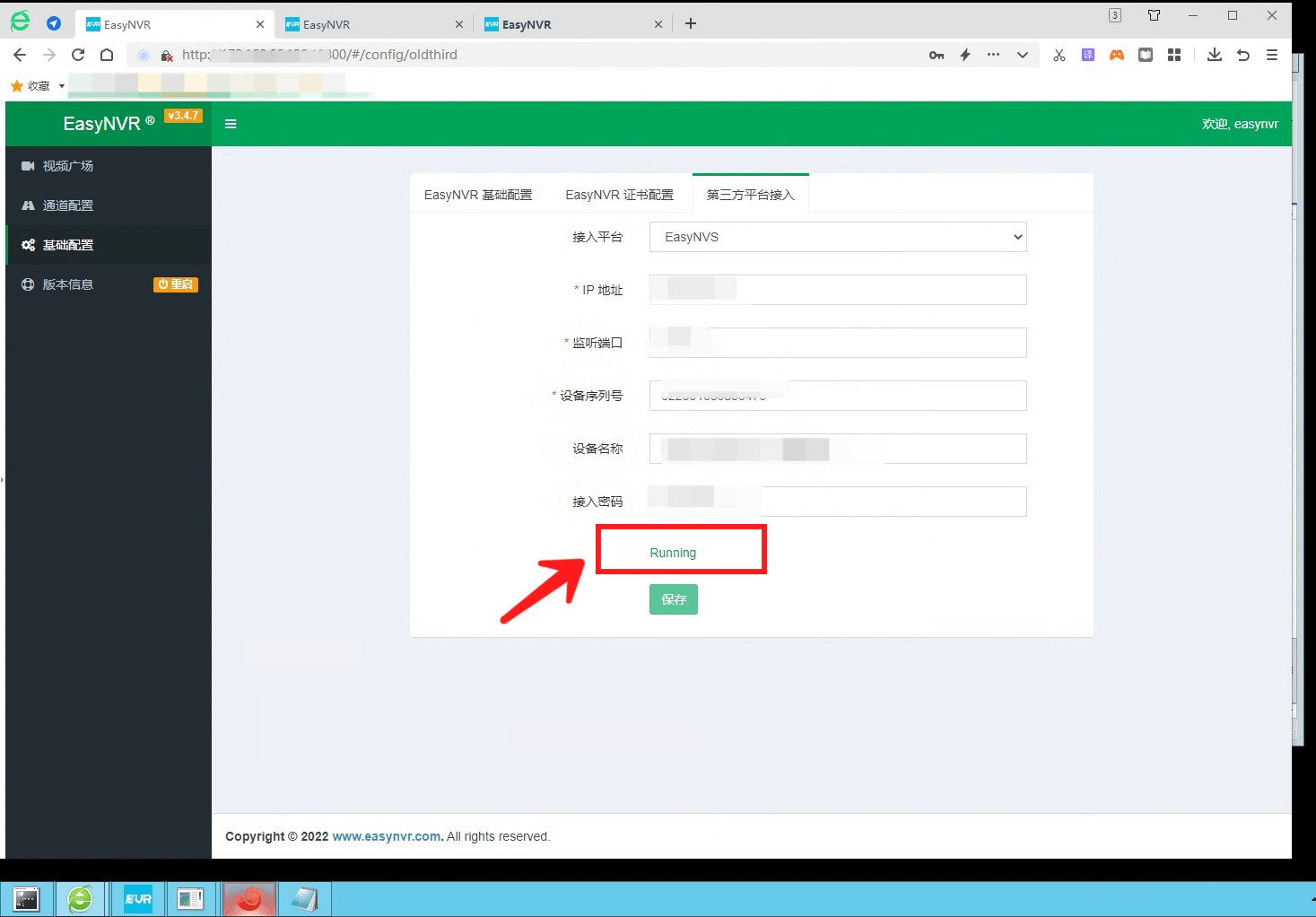
了解EasyNVR及EasyNVS,EasyNVR连接EasyNVS显示授权超时如何解决?什么原因?
我们先来了解NVR批量管理软件/平台EasyNVR,它深耕市场多年,为用户提供多种协议,兼容多种厂商设备,包括但不限于支持海康,大华,宇视,萤石,天地伟业,华为设备。 NVR录像机…...

【AUTOSAR标准文档】服务类型介绍
Introduction to types of services The Basic Software can be subdivided into the following types of services: ① Input/Output (I/O) Standardized access to sensors, actuators and ECU onboard peripherals ② Memory Standardized access to internal/external…...

Axure垂直菜单展开与折叠
亲爱的小伙伴,在您浏览之前,烦请关注一下,在此深表感谢! 课程主题:Axure垂直菜单展开与折叠 主要内容:垂直菜单单击实现展开/折叠,点击各菜单项显示选中效果 应用场景:后台菜单设…...

java简单理解哈希算法
这里需要大家有一些哈希表(散列表的理论基础) 比如冲突怎么处理 key-value是什么意思 有哪些处理冲突的方法 平均查找成功长度和失败长度是什么意思。 详细可以看一下这个数据结构散列表。在java中常用三种结构代表散列: map,set,数组。应在不…...

Python生成随机密码脚本
引言 在数字化时代,密码已成为我们保护个人信息和数据安全的重要手段。然而,手动创建复杂且难以猜测的密码是一项既繁琐又容易出错的任务。幸运的是,Python编程语言为我们提供了一种高效且灵活的方法来自动生成随机密码。本文将详细介绍如何…...

什么是ASC广告?Facebook ASC广告使用技巧
ASC广告全称AdvantageShopping Campaign,即进阶赋能型智能购物广告,许多投放Facebook广告的小伙伴听过这个词,但每用过这个功能,Facebook推出ASC广告已经有两年了,不少实例证明ASC广告在降低转化成本上有一定效果&…...

idea2024启动Java项目报Error running CloudPlApplication. Command line is too long.
idea2024启动Java项目报Error running CloudPlApplication. Command line is too long. 解决方案: 1、打开Edit Configurations 2、点击Modify options设置,勾选Shorten command line 3、在Edit Configurations界面下方新增的Shorten command line选项中…...

xtu oj 不定方程的正整数解
文章目录 回顾思路c 语言代码 回顾 AB III问题 H: 三角数问题 G: 3个数等式 数组下标查询,降低时间复杂度1405 问题 E: 世界杯xtu 数码串xtu oj 神经网络xtu oj 1167 逆序数(大数据)xtu oj 原根 思路 首先直观地理解这个题目的意思&#x…...

python爬虫技术实现酷我付费破解下载
python爬虫技术实现酷我付费破解下载 1.python编程环境 python解释器:pyhton3版本 代码编辑器:Vscode,PyCharm 2.实现爬虫程序过程 2.1浏览器访问网站的过程 在浏览器导航栏中输入域名并回车(在按下回车的那一瞬间浏览器向网站发送了一个http请求)当网站接收到请求后向…...

工具:Git分布式版本控制系统
文章目录 介绍分布式版本控制系统原理git安装和使用git软件分类安装软件注册开源社区githubgit ssh key 配置远程仓库分支管理标签管理 引用 介绍 分布式版本控制系统下的每一台终端都可以充当类似集中式版本控制系统的中央服务器。每台终端都可以保存版本库,并且版…...

python+docxtpl:word文件模版渲染
目录 操作流程 加载模版 模版渲染 文件保存 python-docx库结合 模版渲染说明 变量值的获取 模板代码语句 遍历生成列表 docxtpl使用jinja2作为框架的模板系统,基于python-docx,同样可以使用python-docx库的一些方法,如添加段落,添加图片、列表等。 安装:pip ins…...

018_基于python+django荣誉证书管理系统2024_jytq9489
目录 系统展示 开发背景 代码实现 项目案例 获取源码 博主介绍:CodeMentor毕业设计领航者、全网关注者30W群落,InfoQ特邀专栏作家、技术博客领航者、InfoQ新星培育计划导师、Web开发领域杰出贡献者,博客领航之星、开发者头条/腾讯云/AW…...
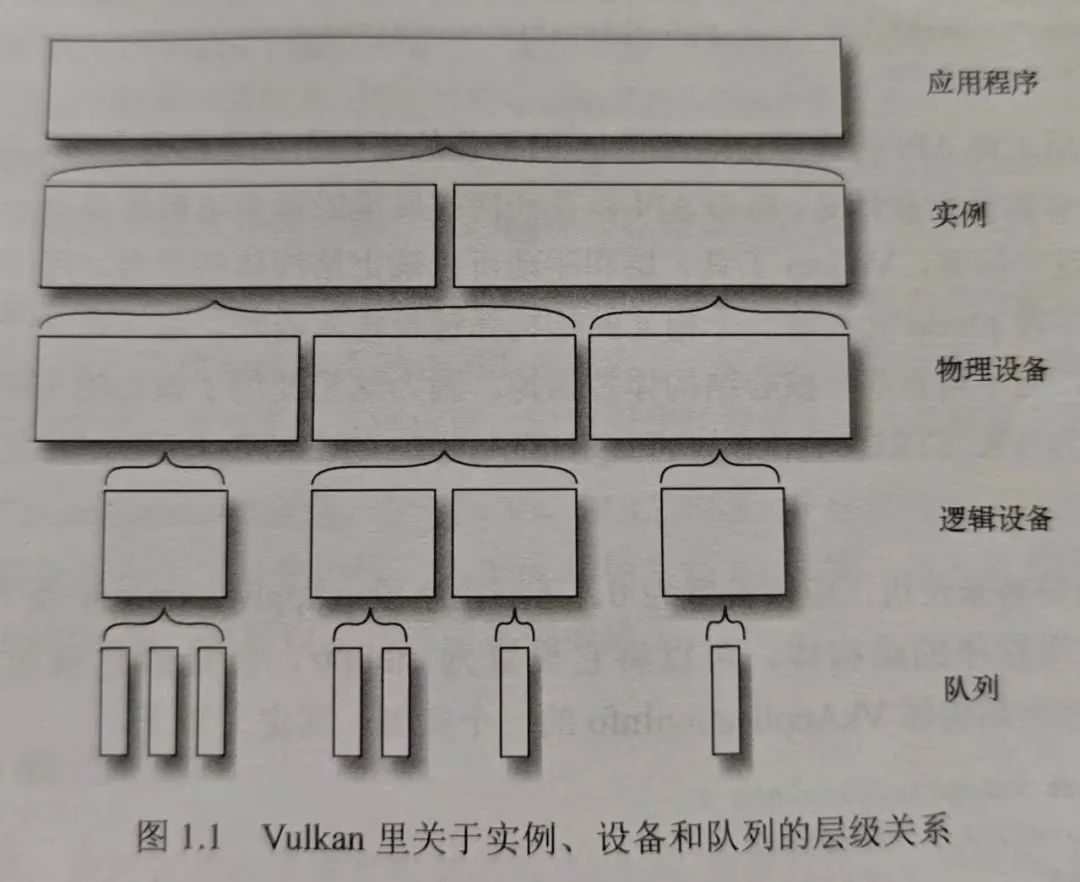
Vulkan 开发(三):Vulkan 物理设备
Vulkan 物理设备 图片来自《 Vulkan 应用开发指南》 上一节了解了 Vulkan 实例,一旦有了实例,就可以查找系统里安装的与 Vulkan 兼容的物理设备。 Vulkan 物理设备(PhysicalDevice)一般是指支持 Vulkan 的物理硬件,通…...
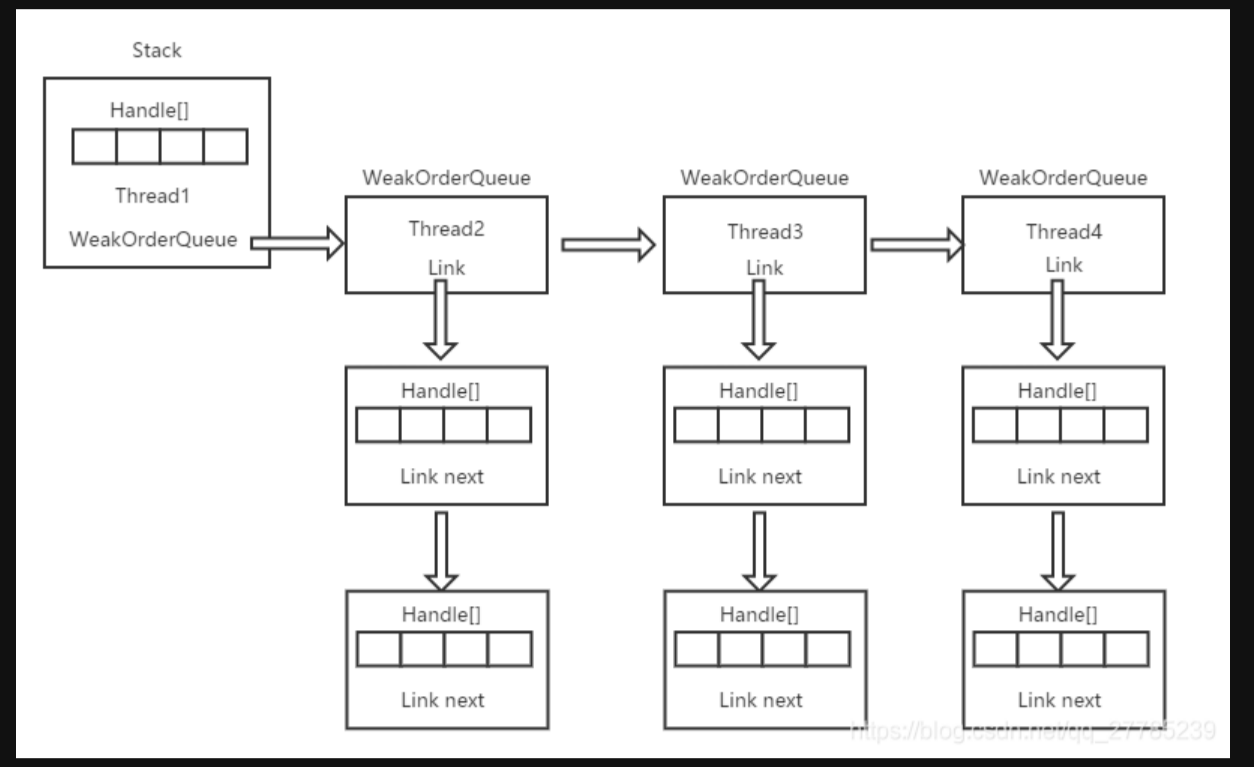
Netty无锁化设计之对象池实现
池化技术是比较常见的一种技术,在平时我们已经就接触很多了,比如线程池,数据库连接池等等。当我们要使用一个资源的时候从池中去获取,用完就放回池中以便其他线程可以使用,这样的目的就是为了减少资源开销,…...

工厂生成中关于WiFi的一些问题
一 背景: 主要做高通和MTK,工厂生成中通过使用adb wifi,因为这样生产效率高并且避免了新机器有划痕,但是也经常碰到adb wifi无法连接的问题,那么是什么原因导致呢? 二 案例 测试步骤: 使用adb wifi连接手机测试工厂case adb usb adb tcpip 5555 adb connect DU…...

Java爬虫:获取商品评论数据的高效工具
在电子商务的激烈竞争中,商品评论作为消费者购买决策的重要参考,对于商家来说具有极高的价值。它不仅能够帮助商家了解消费者的需求和反馈,还能作为改进产品和服务的依据。Java爬虫技术,以其稳健性和高效性,成为了获取…...

oracle中的exists 和not exists 用法
exists (sql 返回结果集为真) not exists (sql 不返回结果集为真) exists 与 in 意思相同,语法不同,效率高于in not exists 与 not in 意思相同,语法不同,效率高于in 基本概念: se…...
自定义导出Excel数据注解实践
目录 前言结构组成定义自定义注解定义导出数据的实体定义Excel导出逻辑定义导出服务注解验证总结 前言 在企业级应用中,导入导出 Excel 文件是很常见的需求。通过使用自定义注解不仅可以实现灵活的 Excel 数据导入导出还可以减少手动配置的麻烦,提高代码…...

CSS3 动画相关属性实例大全(一)(@keyframes ,background属性,border 属性)
CSS3 动画相关属性实例大全(一) (keyframes ,background属性,border 属性) 本文目录: 零、时光宝盒 一、CSS3 动画基本概念 (1)、CSS3的动画基本属性 (2)…...

SMART200与FANUC机器人Profinet通讯:除了组态,这些调试‘玄学’问题你遇到过吗?
SMART200与FANUC机器人Profinet通讯实战:那些手册上没写的调试技巧 第一次在项目现场看到FANUC机器人手臂突然停止动作,而SMART200 PLC的指示灯还在正常闪烁时,我就知道遇到了传说中的"通讯玄学"问题。这种场景对于自动化工程师来说…...

构建仓库与包管理
一、构建仓库 1、nexus安装 brew安装方式(比较慢) brew install nexus官网下载安装方式 去sonatype官网下载,比如MacOS的,下载完成之后cd到bin目录即可看到启动命令 启动 # 2.0版本 brew services start nexus # 3.0版本 /usr…...

AI时代新型的项目管理应该是什么样的?嗣
AI训练存储选型的演进路线 第一阶段:单机直连时代 早期的深度学习数据集较小,模型训练通常在单台服务器或单张GPU卡上完成。此时直接将数据存储在训练机器的本地NVMe SSD/HDD上。 其优势在于IO延迟最低,吞吐量极高,也就是“数据离…...

LeetCode 108. 将有序数组转换为二叉搜索树 详细技术解析
LeetCode 108. 将有序数组转换为二叉搜索树 详细技术解析本文针对 LeetCode 108. 将有序数组转换为二叉搜索树 问题,从题目解析、核心原理、思路拆解、代码实现、边界处理到面试拓展,进行全方位拆解,适合算法入门及进阶开发者阅读,…...

PHP 8.9扩展模块安全配置失效了吗?3类高危漏洞正在 silently hijack 你的生产环境
第一章:PHP 8.9扩展模块安全加固配置概览PHP 8.9(当前为前瞻预发布版本,基于PHP 8.3持续演进的实验性分支)在扩展模块层面引入了更严格的加载策略与运行时权限控制机制。安全加固的核心目标是:最小化默认启用扩展、强制…...

3个步骤掌握抖音评论数据采集:零基础用户的高效解决方案
3个步骤掌握抖音评论数据采集:零基础用户的高效解决方案 【免费下载链接】TikTokCommentScraper 项目地址: https://gitcode.com/gh_mirrors/ti/TikTokCommentScraper 在当今数据驱动的时代,高效获取用户反馈和市场洞察变得至关重要。本文介绍的…...

SDMatte与3D引擎结合:实时渲染中的动态遮罩应用
SDMatte与3D引擎结合:实时渲染中的动态遮罩应用 1. 引言:当AI遮罩遇上实时渲染 想象一下,在游戏开发中需要让角色逐渐消失的特效,传统做法可能需要美术师逐帧绘制遮罩。现在,通过SDMatte与3D引擎的结合,我…...

非线性悬架与UKF状态估计的Matlab/Simulink建模源码及文档资料
非线性悬架,UKF状态估计 软件使用:Matlab/Simulink 适用场景:采用模块化建模方法,搭建空气悬架模型,UKF状态估计模型,可实现悬架动挠度等状态估计。 包含:simulink源码文件,详细建模…...

AI辅助开发新体验:描述需求,让快马AI直接打开一个情感分析应用
AI辅助开发新体验:描述需求,让快马AI直接打开一个情感分析应用 最近在尝试用AI辅助开发,发现InsCode(快马)平台的体验真的很惊艳。以前做个简单的文本情感分析,得自己找数据集、训练模型、写前后端代码,现在只需要用自…...

Python AI爬虫实战:爬取张雪峰微博并进行情感分析与词云可视化怕
1. 引入 在现代 AI 工程中,Hugging Face 的 tokenizers 库已成为分词器的事实标准。不过 Hugging Face 的 tokenizers 是用 Rust 来实现的,官方只提供了 python 和 node 的绑定实现。要实现与 Hugging Face tokenizers 相同的行为,最好的办法…...