【笔记】【YOLOv10图像识别】自动识别图片、视频、摄像头、电脑桌面中的花朵学习踩坑
(一)启动
创建环境python3.9
打开此环境终端

(后面的语句操作几乎都在这个终端执行)
输入up主提供的语句:pip install -r requirements.txt
1.下载pytorch网络连接超时
pytorch网址:
Start Locally | PyTorch

把pip后面的3去掉
在上面的网址中找到对应的版本用那个下载语句 但是我开着魔法都下载失败了说是
网络连接超时问题
于是使用清华的镜像再次下载pytorch 飞速成功
pip install torch torchvision torchaudio -f https://pypi.tuna.tsinghua.edu.cn/simple
2.NVIDIA缺失
安装 cuda12.4
配置环境变量:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\bin添加到环境变量的PATH中
完成这步之后
输入nvida-smi后出现问题 大概就是我的C:\Program Files\NVIDIA Corporation这个路径下面没有NVSMI的文件夹
查询后解决: 感谢Windows NVIDIA Corporation下没有NVSMI文件夹解决方法-CSDN博客
链接:百度网盘 请输入提取码
提取码:wy6l
将NVSMI.zip解压后 放到C:\Program Files\NVIDIA Corporation\
然后再次回到你环境终端 输入nvdia-smi 发现这个电脑没有显卡

无所谓 让我们继续下一步
3.python app.py报错缺乏gradio
Traceback (most recent call last): File "D:\ai训练\yolov10\yolov10\app.py", line 1, in <module> import gradio as gr ModuleNotFoundError: No module named 'gradio'
那下载一个就是

再次 输入语句运行发现报错:
Exception in ASGI application Traceback (most recent call last): File "C:\ProgramData\anaconda3\envs\yolov10\lib\site-packages\pydantic\type_adapter.py", line 270, in _init_core_attrs self._core_schema = _getattr_no_parents(self._type, '__pydantic_core_schema__') File "C:\ProgramData\anaconda3\envs\yolov10\lib\site-packages\pydantic\type_adapter.py", line 112, in _getattr_no_parents raise AttributeError(attribute) AttributeError: __pydantic_core_schema_
ok啊依赖冲突了 降低版本
pip install pydantic==1.10.9
解决 这里的问题就ok了
4.运行了之后发现网页内容不是教程给的文件夹的内容
在yolov10中找到app.py
打开并且来到最后一行
app.launch(server_port=7861)
更改端口号为7861
原因:此前按照教程用默认端口7860自己先跑了一遍官方的
5.第4的解决并不稳定
解决:
在yolov10和bin目录同级新建一个models
把文件夹中的所有.pt文件都放进去
然后打开app.py
import gradio as gr
import cv2
import tempfile
from ultralytics import YOLOv10
import os
# Set no_proxy environment variable for localhost
os.environ["no_proxy"] = "localhost,127.0.0.1,::1"
# Directory where your models are store
MODEL_DIR = 'D:/ai_train/yolov10/yolov10/models/'
# Load all available models from the directory
def get_model_list():
return [f for f in os.listdir(MODEL_DIR) if f.endswith('.pt')]
def yolov10_inference(image, video, model_id, image_size, conf_threshold):
model_path = os.path.join(MODEL_DIR, model_id) # Get the full model path
model = YOLOv10(model_path) # Load the selected model
if image:
results = model.predict(source=image, imgsz=image_size, conf=conf_threshold)
annotated_image = results[0].plot()
return annotated_image[:, :, ::-1], None
else:
video_path = tempfile.mktemp(suffix=".webm")
with open(video_path, "wb") as f:
with open(video, "rb") as g:
f.write(g.read())
cap = cv2.VideoCapture(video_path)
fps = cap.get(cv2.CAP_PROP_FPS)
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
output_video_path = tempfile.mktemp(suffix=".webm")
out = cv2.VideoWriter(output_video_path, cv2.VideoWriter_fourcc(*'vp80'), fps, (frame_width, frame_height))
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
results = model.predict(source=frame, imgsz=image_size, conf=conf_threshold)
annotated_frame = results[0].plot()
out.write(annotated_frame)
cap.release()
out.release()
return None, output_video_path
def yolov10_inference_for_examples(image, model_path, image_size, conf_threshold):
annotated_image, _ = yolov10_inference(image, None, model_path, image_size, conf_threshold)
return annotated_image
def app():
with gr.Blocks():
with gr.Row():
with gr.Column():
image = gr.Image(type="pil", label="Image", visible=True)
video = gr.Video(label="Video", visible=False)
input_type = gr.Radio(
choices=["Image", "Video"],
value="Image",
label="Input Type",
)
# Dynamically load models from the directory
model_id = gr.Dropdown(
label="Model",
choices=get_model_list(), # Dynamically fetch the model list
value=get_model_list()[0], # Set a default model
)
image_size = gr.Slider(
label="Image Size",
minimum=320,
maximum=1280,
step=32,
value=640,
)
conf_threshold = gr.Slider(
label="Confidence Threshold",
minimum=0.0,
maximum=1.0,
step=0.05,
value=0.25,
)
yolov10_infer = gr.Button(value="Detect Objects")
with gr.Column():
output_image = gr.Image(type="numpy", label="Annotated Image", visible=True)
output_video = gr.Video(label="Annotated Video", visible=False)
def update_visibility(input_type):
image = gr.update(visible=True) if input_type == "Image" else gr.update(visible=False)
video = gr.update(visible=False) if input_type == "Image" else gr.update(visible=True)
output_image = gr.update(visible=True) if input_type == "Image" else gr.update(visible(False))
output_video = gr.update(visible=False) if input_type == "Image" else gr.update(visible=True)
return image, video, output_image, output_video
input_type.change(
fn=update_visibility,
inputs=[input_type],
outputs=[image, video, output_image, output_video],
)
def run_inference(image, video, model_id, image_size, conf_threshold, input_type):
if input_type == "Image":
return yolov10_inference(image, None, model_id, image_size, conf_threshold)
else:
return yolov10_inference(None, video, model_id, image_size, conf_threshold)
yolov10_infer.click(
fn=run_inference,
inputs=[image, video, model_id, image_size, conf_threshold, input_type],
outputs=[output_image, output_video],
)
gr.Examples(
examples=[
[
"ultralytics/assets/bus.jpg",
get_model_list()[0],
640,
0.25,
],
[
"ultralytics/assets/zidane.jpg",
get_model_list()[0],
640,
0.25,
],
],
fn=yolov10_inference_for_examples,
inputs=[
image,
model_id,
image_size,
conf_threshold,
],
outputs=[output_image],
cache_examples='lazy',
)
gradio_app = gr.Blocks()
with gradio_app:
gr.HTML(
"""
<h1 style='text-align: center'>
YOLOv10: Real-Time End-to-End Object Detection
</h1>
""")
gr.HTML(
"""
<h3 style='text-align: center'>
<a href='https://arxiv.org/abs/2405.14458' target='_blank'>arXiv</a> | <a href='https://github.com/THU-MIG/yolov10' target='_blank'>github</a>
</h3>
""")
with gr.Row():
with gr.Column():
app()
if __name__ == '__main__':
gradio_app.launch(server_port=7861)
重点是第十一行

把这个路径更改为你的models的文件夹路劲
然后回到py3.9的运行终端再次输入 app..py打开网页
解决了 一切正常 let`s 学习
(二)之后的错误
1.启动摄像头报错
(yolov10) D:\ai_train\yolov10\yolov10>python yolov10-camera.py Traceback (most recent call last): File "D:\ai_train\yolov10\yolov10\yolov10-camera.py", line 2, in <module> import supervision as sv ModuleNotFoundError: No module named 'supervision'
缺少 那就安装
pip install supervision

然后 再次启动
python yolov10-camera.py
2.桌面识别图片时报错
python yolov10-paint2.py SupervisionWarnings: BoundingBoxAnnotator is deprecated: `BoundingBoxAnnotator` is deprecated and has been renamed to `BoxAnnotator`. `BoundingBoxAnnotator` will be removed in supervision-0.26.0. 找不到窗口: th(1).jpg 找不到窗口: th(1).jpg 找不到窗口: th(1).jpg
解决;
直接复制图片窗口名字到yolov10-paint2.py第十七行 我就是手打然后报错了

(三)制作自己的模型遇到的错误
1.ModuleNotFoundError: No module named 'ultralytics'

那就安装 pip install ultralytics==8.3.0 指定版本8.3.0 因为我们的python版本是3.9
因为这个电脑没有显卡所有device=cpu
教程中device=0的意思是指定使用电脑中的第一块显卡
相关文章:
【笔记】【YOLOv10图像识别】自动识别图片、视频、摄像头、电脑桌面中的花朵学习踩坑
(一)启动 创建环境python3.9 打开此环境终端 (后面的语句操作几乎都在这个终端执行) 输入up主提供的语句:pip install -r requirements.txt 1.下载pytorch网络连接超时 pytorch网址: Start Locally | P…...

H-TCP 的效率和公平性
昨晚带安孩楼下玩耍,用手机 desmos 作了一组 response curve 置于双对数坐标系: 长肥管道的优化思路都很类似,cwnd 增长快一点: BIC TCP:二分查找逼近 capacity;CUBIC TCP:上凸曲线逼近 capa…...

集群与分布式
Cluster(集群)概述 当单独一台主机无法承载现有的用户请求量;或者一台主机因为单一故障导致业务中断的时候,就可以增加服务主机数,这些主机在一起提供服务,就叫集群,而用户所看到的依然是单个的主机,用户并…...

git rebase的常用场景: 交互式变基, 变基和本地分支基于远端分支的变基
文章目录 作用应用场景场景一:交互式变基(合并同一条线上的提交记录) —— git rebase -i HEAD~2场景二:变基(合并分支) —— git rebase [其他分支名称]场景三:本地分支与远端分支的变基 作用 使git的提交记录变得更加简洁 应用场景 场景…...

HttpURLConnection构造请求体传文件
HttpURLConnection构造请求体传文件 在Java中,使用HttpURLConnection构造请求体传输文件,你需要做以下几步: 1、创建URL对象指向你想要请求的资源。 2、通过URL打开连接,转换为HttpURLConnection实例。 3、设置请求方法为POST。 …...

STM32传感器模块编程实践(九) VL53L0X激光红外测距传感器简介及驱动源码
文章目录 一.概要二.VL53L0X测距原理三.VL53L0X主要特性四.VL53L0X硬件参考设计五.模块接线说明六.模块通讯协议介绍七.光学盖玻片介绍八.STM32单片机与VL53L0模块实现距离测量实验1.硬件准备2.软件工程3.软件主要代码4.实验效果 九.小结 一.概要 VL53L0X是一款由ST࿰…...

fastjson注解说明,fastjson注解有那些?fastjson是java的json序列化和反序列化工具包
fastjson注解说明,fastjson注解有那些?fastjson是java的json序列化和反序列化工具包 包版本说明 fastjson请使用1.2.83以上版本,小于这个版本的存在漏洞。 fastjson请使用1.2.83以上版本,小于这个版本的存在漏洞。 fastjson请使用1.2.83以上版本,小于这个版本的存在漏洞…...

VIT:论文关键点解读与常见疑问
VIT贡献点: 1. 首次将 Transformer 应用于图像识别任务 核心贡献:ViT 论文的最大贡献是提出将原本用于自然语言处理(NLP)的 Transformer 架构成功应用于图像任务。传统的计算机视觉模型主要依赖卷积神经网络(CNN&…...
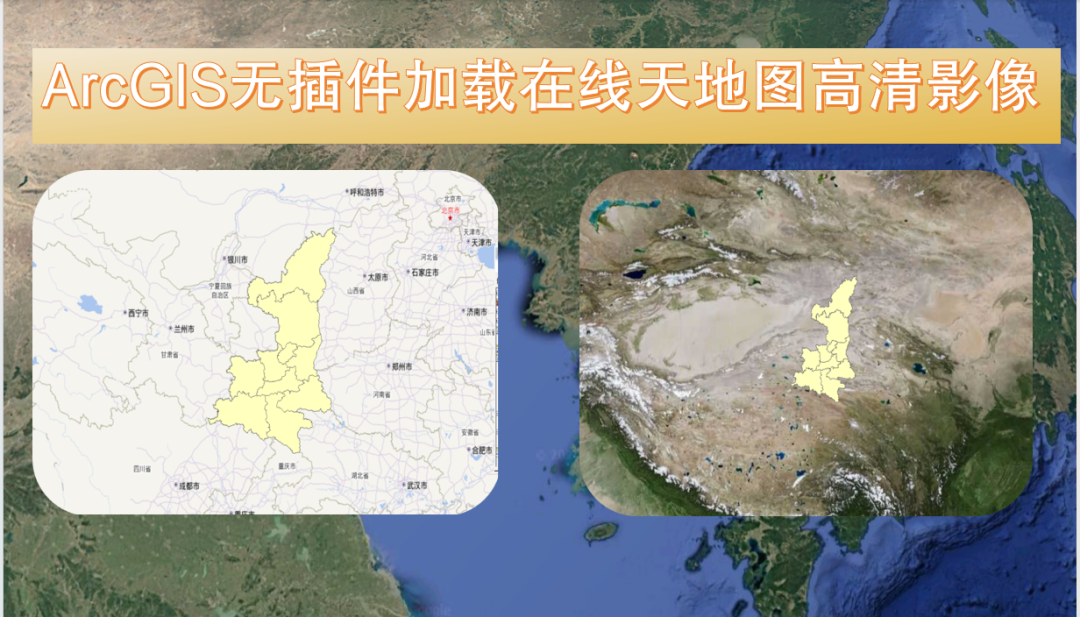
ArcGIS无插件加载(无偏移)在线天地图高清影像与街道地图指南
在地理信息系统(GIS)的应用中,加载高清影像与街道地图对于地图制图、影像查阅、空间数据分析等工作至关重要。天地图作为官方出品的地图服务,以其标准的数据、较快的影像更新速度等特点受到广泛欢迎。以下是如何在ArcGIS中无插件加…...

工业相机选型(自用笔记)
可参考链接: 相机和镜头选型需要注意哪些问题_靶面尺寸-CSDN博客 工业相机选型方法_ccd工业相机选型步骤-CSDN博客 1、相机 1.1 传感器类型(CCD/CMOS) CCD相机: 1)目标是运动的则优先考虑。 2)需要高质量图像,如进行…...

【网安笔记】4种拒绝服务攻击
目录 一、SYN Flood 攻击 二、UDP Flood 攻击 三、ICMP Flood 攻击 四、HTTP Flood 攻击 拒绝服务攻击(Denial of Service attack,简称 DoS 攻击)是指攻击者通过向目标服务器或网络发送大量的请求,使其资源耗尽,无…...

WPF 的组件数据绑定详解
Windows Presentation Foundation(WPF)是微软推出的一种用于构建 Windows 应用程序的 UI 框架。WPF 提供了强大的数据绑定功能,能够轻松地将 UI 控件与数据源连接,从而实现富用户体验,分离前端设计和业务逻辑。本文将详…...

房子,它或许是沃土
刚成家,来客时,它是客房 成家后,没小孩,它是书房 有小孩,未分房,它暂且是书房 孩子大些,它是孩子们埋下梦想种子,生根发芽的地方...

【Golang】Go语言http编程底层逻辑实现原理与实战
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

SOLIDWORKS参数化软件
在产品设计和工程领域,参数化设计是一种革命性的方法,它允许设计者通过定义一系列规则和关系来创建和修改模型。参数化设计的核心在于将设计过程分解为一系列可调整的参数,如尺寸、形状、材料属性等,这些参数之间通过数学关系相互…...

上位机开发常用技术 C# Task 线程 开始,暂停,继续,停止
上位机开发中一定会用到的技术就是 设备的线程开始运行执行生产流程,在生产过程中会有要打开安全门或暂停设备动作,人为去排除设备小问题的时就要用到暂停功能,问题排除后设备继续运行,生产完成后设备停止。 这些操作是上位机开发…...

MySQL 密码忘记了怎么办?
在使用 MySQL 的过程中,有时候我们可能会忘记密码。别担心,本文将详细介绍在 Windows 系统下如何重新设置 MySQL 密码。 一、停止 MySQL 服务 打开“服务”窗口,可以通过在 Windows 搜索栏中输入“服务”来找到并打开它。在服务列表中找到“…...

Java中常见的自带数据结构类
目录 一、ArrayList(动态数组) 特性 常用方法 二、LinkedList(双向链表) 特性 常用方法 三、ArrayDeque(双端队列) 特性 常用方法 四、HashMap(哈希表) 特性 常用方法 五、TreeMap&…...

数据结构——链表,哈希表
文章目录 链表python实现双向链表复杂度分析 哈希表(散列表)python实现哈希表哈希表的应用 链表 python实现 class Node:def __init__(self, item):self.item itemself.next Nonedef head_create_linklist(li):head Node(li[0])for element in li[1…...

如何使用Python对Excel、CSV文件完成数据清洗与预处理?
在数据分析和机器学习项目中,数据清洗与预处理是不可或缺的重要环节。 现实世界中的数据往往是不完整、不一致且含有噪声的,这些问题会严重影响数据分析的质量和机器学习模型的性能。 Python作为一门强大的编程语言,提供了多种库和工具来帮…...
)
从游戏背包到物流集装箱:深入浅出图解三维装箱问题(3D-BPP)
从游戏背包到物流集装箱:深入浅出图解三维装箱问题(3D-BPP) 想象一下你在玩《我的世界》,背包里塞满了钻石镐、金苹果和各种矿石,突然发现空间不够了——这时候你下意识做的事情,和亚马逊仓库的机器人分拣货…...

一口气读懂 PCA 主成分分析:从原理到代码,本科生/研究生都能彻底学会
一口气读懂 PCA 主成分分析:从原理到代码,本科生/研究生都能彻底学会 大家好,今天我们用最通俗、最详细、最不绕弯子的方式,把 PCA(主成分分析) 讲明白。 不管你是刚接触机器学习的本科生,还是做…...

【2026必看】临沂销售增长咨询,哪家公司最权威?
在当前竞争激烈的市场环境中,商贸和生产型企业要想实现销售额的稳步增长,选择一家专业的管理咨询公司至关重要。那么,在临沂,哪家公司在销售增长咨询方面最具权威性呢?本文将为您详细解析,并推荐山东润行管…...

Android架构实战指南:如何将MVP+RxJava应用到现有项目的完整教程
Android架构实战指南:如何将MVPRxJava应用到现有项目的完整教程 【免费下载链接】android-guidelines Architecture and code guidelines we use at ribot when developing for Android 项目地址: https://gitcode.com/gh_mirrors/an/android-guidelines 想要…...

SEO案例教程有哪些
SEO案例教程有哪些?了解这些将大大提升你的网站排名 在当今的互联网时代,搜索引擎优化(SEO)已经成为每个网站运营者必须掌握的技能。无论你是新手还是有一些经验,了解和学习高质量的SEO案例教程都能帮助你提升网站的排…...

终极Godot解包指南:3分钟学会提取游戏资源
终极Godot解包指南:3分钟学会提取游戏资源 【免费下载链接】godot-unpacker godot .pck unpacker 项目地址: https://gitcode.com/gh_mirrors/go/godot-unpacker 想要轻松提取Godot游戏中的图片、音频和脚本资源吗?godot-unpacker正是你需要的God…...

ThingsBoard设备告警实战:从MQTTX模拟数据到RabbitMQ消息队列的完整流程
ThingsBoard设备告警实战:从MQTTX模拟数据到RabbitMQ消息队列的完整流程 最近在部署一个工业温度监控系统时,遇到了设备告警实时性不足的问题。传统的轮询方式不仅效率低下,还经常错过关键告警。经过多次尝试,最终通过ThingsBoar…...

【安全心法】别用定时器喂狗!撕碎看门狗的伪安全面具,直面“僵尸系统”的物理绞肉机
摘要:在硬实时控制系统中,硬件看门狗被奉为防止系统死机的终极神明。但无数软硬件工程师出于偷懒或对底层架构的无知,将“喂狗”动作外包给了高频的定时器中断或最高优先级的独立任务。本文将彻底摒弃代码,纯粹从系统架构的安全哲…...

OpenClaw自动化竞赛:Qwen3.5-9B在不同任务中的表现对比
OpenClaw自动化竞赛:Qwen3.5-9B在不同任务中的表现对比 1. 测试背景与实验设计 最近我在本地部署了OpenClaw框架,并接入Qwen3.5-9B模型进行了一系列自动化任务测试。作为一个长期关注AI自动化落地的开发者,我很好奇这款90亿参数的模型在实际…...

OpenClaw技能打包发布:将Qwen3.5-9B-AWQ-4bit图片工具上传ClawHub
OpenClaw技能打包发布:将Qwen3.5-9B-AWQ-4bit图片工具上传ClawHub 1. 为什么需要技能打包? 上周我在整理旅行照片时,突然意识到一个痛点:每次需要从几百张照片中筛选出包含特定元素的图片(比如"所有有狗的合照&…...