机器学习_KNN(K近邻)算法_FaceBook_Location案例(附数据集下载链接)
Facebook_location_KNN
流程分析:
1.数据集获取(大型数据怎么获取? 放在电脑哪里? 算力怎么搞?)
2.基本数据处理(数据选取-确定特征值和目标值-分割数据集)
缩小数据范围
选择时间特征
去掉签到较少的地方
确定特征值和目标值
分割数据集
3.特征工程(特征预处理:标准化)
4.模型训练(KNN+CV)
5.模型评估
代码实现基本步骤
1.数据导入
1.1导入facebook_location_train_set(数据集大小:1.8G), 需要加载一段时间
import pandas as pd
locdata=pd.read_csv(r"C:\Users\鹰\Desktop\ML_Set\FaceBook_train.csv\FaceBook_train.csv")
1.2对数据的信息的简单分析
显示部分数据
locdata.head()
查看数据描述
locdata.describe()
查看数据行列数
locdata.shape
2.数据基本处理
2.1缺失值处理
print(“查看数据缺失值:”)
print(locdata.isna().sum())
locdata.dropna()
print(locdata.isna().sum())
2.2数据提取
缩小数据范围
locdata= locdata.query(“x>2.0 & x<2.5 & y>2.0 & y<2.5”)
选择时间特征, 对time进行转化
time=pd.to_datetime(locdata[“time”], unit=“s”)
time=pd.DatetimeIndex(time)
locdata[“day”]=time.day
locdata[“hour”]=time.hour
locdata[“weekday”]=time.weekday
去掉签到较少的地方, 在这里去掉签到次数小于三的地点
place_set= locdata.groupby(“place_id”).count()
place_set= place_set[place_set[“row_id”]>3]
locdata=locdata[locdata[“place_id”].isin(place_set.index)]
确定目标值和特征值, 用loc和iloc可以吗? 有什么区别吗?
x_all=locdata[[“x”,“y”,“accuracy”,“day”,“hour”,“weekday”]]
y_all=locdata[“place_id”]####
2.3数据集分割
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test=train_test_split(x_all, y_all,test_size=0.2)###
print(x_train)
print(x_test)
print(y_train)
print(y_test)
3.特征工程
3.1特征预处理-标准化
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
x_train=scaler.fit_transform(x_train)
x_test=scaler.fit_transform(x_test)
4.模型训练-KNN+CV
4.1KNN调用
from sklearn.neighbors import KNeighborsClassifier
estimator=KNeighborsClassifier()
4.2模型优化
from sklearn.model_selection import GridSearchCV
params={“n_neighbors”:[1,3,5,7,9]}
estimator=GridSearchCV(estimator, param_grid=params, cv=5)
4.3模型训练
estimator.fit(x_train, y_train)
5.模型评估
5.1预测值
y_predict=estimator.predict(x_test)
print(“预测值为:”, y_predict)
5.2准确率
score=estimator.score(x_test,y_test)
print(“准确率为:”, score)
5.2最优模型参数:
print(“最优模型为:”, estimator.best_estimator_)
5.3最好评分
print(“最高分:”, estimator.best_score_)
数据集Facebook_Location下载地址:
链接:https://pan.baidu.com/s/1uoeo6pukkjSuLlKW9RwnCQ
提取码:7hlo
相关文章:
算法_FaceBook_Location案例(附数据集下载链接))
机器学习_KNN(K近邻)算法_FaceBook_Location案例(附数据集下载链接)
Facebook_location_KNN 流程分析: 1.数据集获取(大型数据怎么获取? 放在电脑哪里? 算力怎么搞?) 2.基本数据处理(数据选取-确定特征值和目标值-分割数据集) 缩小数据范围 选择时间特征 去掉签到较少的地方 确定特征值和目标值 分割数据集 3.特征工程(特征预处理:标…...

【str_replace替换导致的绕过】
双写绕过 随便输入一个 usernameadmin&passwords 没有回显测试注入点 usernameadmin or 11%23&passwords 回显hello admin测试列数 usernameadmin order by 3%23&passwords测试回显位 usernameadmi union select 1,2,3%23&passwords 没有显示数据,推…...

如何用AI大模型提升挖洞速度
工具背景 越权漏洞在黑盒测试、SRC挖掘中几乎是必测的一项,但手工逐个测试越权漏洞往往会耗费大量时间,而自动化工具又存在大量误报, 基于此产生了AutorizePro, 那它是怎么提升效率一起来看看 AutorizePro 是一款专注于越权检测的 Burp 插件…...

两个数列问题
# 问题描述 给定长度分别为 n 和 m 的两个数列a[n]、b[m],和一个整数k。求|(a[i] - b[j])^2 - k^2|的最小值。 ## 输入格式 第一行有 2 个整数 n、m、k,分别表示数列 a、b 的长度,以及公式中的整数 k。 第二行有 n 个整数,表示…...
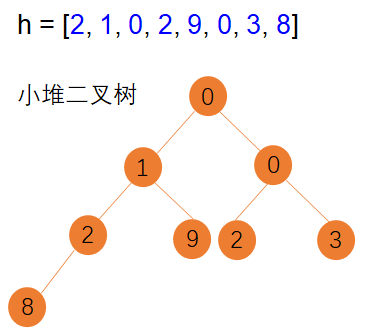
python中堆的用法
Python 堆(Headp) Python中堆是一种基于二叉树存储的数据结构。 主要应用场景: 对一个序列数据的操作基于排序的操作场景,例如序列数据基于最大值最小值进行的操作。 堆的数据结构: Python 中堆是一颗平衡二叉树&am…...

轮班管理新策略,提高效率与降低员工抱怨
良好轮班管理对企业关键,需提前计划、明确期望、保持灵活公平、加强沟通并利用轮班调度系统。ZohoPeople作为智能排班系统,提供轻松创建班次、自动更换、分配管理员、设置津贴及即时通知等功能,助力企业高效管理。 一、HR轮班管理的5大技巧 …...
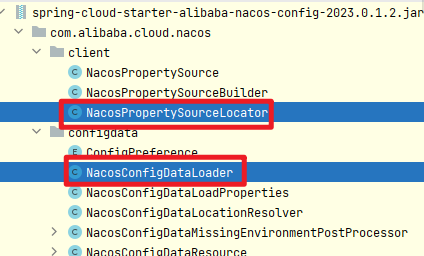
spring-cloud-alibaba-nacos-config2023.0.1.*启动打印配置文件内容
**背景:**在开发测试过程中如果可以打印出配置文件的内容,方便确认配置是否准确;那么如何才可以打印出来呢; spring-cloud-alibaba-nacos-config 调整日志级别 logging:level:com.alibaba.cloud.nacos.configdata.NacosConfigD…...

数据结构:二叉树、堆
目录 一.树的概念 二、二叉树 1.二叉树的概念 2.特殊类型的二叉树 3.二叉树的性质 4.二叉树存储的结构 三、堆 1.堆的概念 2.堆的实现 Heap.h Heap.c 一.树的概念 注意,树的同一层中不能有关联,否侧就不是树了,就变成图了ÿ…...

hi3798mv100 linux 移植
# Linux开发环境搭建 ## uboot编译 1. 必须先安装gcc,要不然make 等命令无法使用 2. 配置arm 交叉编译链 # gcc sudo apt-get install gcc-9 gcc -v# 安装 Linaro gcc-arm-linux-gnueabihf,注意不是arm-linux-gnueabihf-gcc sudo apt-get install ar…...

Docker-Harbor概述及构建
文章目录 一、Docker Harbor概述1.Harbor的特性2.Harbor的构成 二、搭建本地私有仓库三、部署 Docker-Harbor 服务四、在其他客户端上传镜像五、维护管理Harbor 一、Docker Harbor概述 Harbor 是 VMware 公司开源的企业级 Docker Registry 项目,其目标是帮助用户迅…...

部署项目最新教程
3.3安装mysql 运行代码: yum install mysql 运行代码: yum install mysql-server 中间还是一样要输入y然后回车 运行代码: yum install mysql-devel 好,经过上面三步,mysql安装成功,现在启动mysql…...

linux证明变量扩展在路径名扩展之前执行
题目:怎么设计一组命令来证明变量扩展在路径名扩展之前执行。 为了证明变量扩展在路径名扩展之前执行,可以通过编写一个简单的 shell 脚本来观察这两个过程的顺序。我们可以使用以下步骤进行设计: 步骤 1:准备环境 在你选择的 …...

CentOS 7.9安装MySQL
下载Linux版MySQL安装包 下载地址https://downloads.mysql.com/archives/community/ 下载解压后 安装,按照从上至下顺序,一条一条执行即可安装完毕。 进入到rpm所在目录rpm -ivh mysql-community-common-8.0.26-1.el7.x86_64.rpm rpm -ivh mysql-comm…...

MacOS虚拟机安装Windows停滞在“让我们为你连接到网络”,如何解决?
1. 问题描述 MacOS在虚拟机安装win11过程中,停止在“让我们为你连接到网络”步骤,页面没有任何可以点击的按钮,进行下一步操作。 2. 解决方案(亲测有效) 到达该界面,按下ShiftF10(Windows&…...

黑马程序员Java笔记整理(day03)
1.switch 2.for与while对比 3.嵌套定义,输出的区别性 4.break与continue 5.随机数生成的两种方式 6.Random 7.随机验证码...

centos7更换阿里云镜像源操作步骤及命令
centos7更换阿里云镜像源 在CentOS 7上更换为阿里云的镜像源可以通过以下步骤进行: 备份当前的YUM源配置文件 sudo cp -a /etc/yum.repos.d /etc/yum.repos.d.backup清理原有的YUM源配置文件 sudo rm -f /etc/yum.repos.d/*.repo下载阿里云的CentOS 7源配置文件 …...

冲刺大厂 | 一个线程调用两次start()方法会出现什么现象?
大家好,我是冰河~~ 今天给大家分享的面试题是:一个线程调用两次start()方法会出现什么现象?这道面试题是一道关于多线程的基础面试题,很多小伙伴对这个面试题不太了解,其实,如果你看过JDK中关于Thread类的…...
初始化地图)
leaflet(一)初始化地图
Leaflet 与天地图结合使用,可以通过天地图提供的 API 获取地图瓦片,并在 Leaflet 地图上显示。 1. 安装依赖 首先,确保你已经安装了 Leaflet 和 Vue: npm install leaflet npm install vue-leaflet npm install leaflet.tilela…...

Unity开发Hololens项目
Unity打包Hololens设备 目录Visual Studio2019 / Visual Studio2022 远端部署设置Visual Studio2019 / Visual Studio2022 USB部署设置Hololens设备如何查找自身IPHololens设备门户Unity工程内的打包设置 目录 记录下自己做MR相关:Unity和HoloLens设备的历程。 Vi…...

立志最细,FreeRtos的中断管理(Interrupt Management)函数,详解!!!
前言:本文参考,韦东山老师开发文档,连接放在最后。 为什么需要中断管理函数? 在FreeRtos操作系统中,需要实时响应性,也就是随时随地必须保证正常多任务的运行,如果有中断发生,因为中…...

Kimi-VL-A3B-Thinking算力适配:单卡A10即可运行长思考MoE多模态模型
Kimi-VL-A3B-Thinking算力适配:单卡A10即可运行长思考MoE多模态模型 1. 引言:当多模态模型遇上“小算力”的惊喜 如果你对多模态大模型感兴趣,但又担心自己的硬件“带不动”,那么今天这篇文章就是为你准备的。我们常常看到一些强…...

如何通过CPUDoc智能调度技术提升CPU性能与能效比
如何通过CPUDoc智能调度技术提升CPU性能与能效比 【免费下载链接】CPUDoc 项目地址: https://gitcode.com/gh_mirrors/cp/CPUDoc 你是否曾因电脑运行卡顿、游戏帧率不稳或多任务处理缓慢而烦恼?现代CPU虽然拥有强大算力,但Windows系统的默认调度…...

OpenClaw对接Qwen2.5-VL-7B:3步完成模型地址配置
OpenClaw对接Qwen2.5-VL-7B:3步完成模型地址配置 1. 为什么选择Qwen2.5-VL-7B作为OpenClaw的视觉大脑 去年我在尝试用OpenClaw自动化处理图片资料时,发现纯文本模型经常对截图内容"睁眼说瞎话"。直到遇到Qwen2.5-VL-7B这个多模态模型&#x…...

PixEz-flutter网络优化实战:3个技巧打造流畅的二次元内容体验
PixEz-flutter网络优化实战:3个技巧打造流畅的二次元内容体验 【免费下载链接】pixez-flutter 一个支持免代理直连及查看动图的第三方Pixiv flutter客户端 项目地址: https://gitcode.com/gh_mirrors/pi/pixez-flutter 作为一款支持免代理直连的第三方Pixiv客…...

稳定性与生态性的平衡:Windows 11 LTSC系统微软商店完整解决方案
稳定性与生态性的平衡:Windows 11 LTSC系统微软商店完整解决方案 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore Windows 11 LTSC…...

AnimateDiff问题解决手册:常见生成问题与提示词调整方案
AnimateDiff问题解决手册:常见生成问题与提示词调整方案 1. 常见视频生成问题诊断 1.1 视频卡顿或跳帧问题 当生成的视频出现卡顿或帧间不连贯时,通常与以下因素有关: 显存不足:虽然优化版最低支持8G显存,但复杂场…...

3个数据完整性保障:payload-dumper-go校验机制实践
3个数据完整性保障:payload-dumper-go校验机制实践 【免费下载链接】payload-dumper-go an android OTA payload dumper written in Go 项目地址: https://gitcode.com/gh_mirrors/pa/payload-dumper-go 在Android系统的OTA更新过程中,数据完整性…...

Steam Achievement Manager终极指南:如何完全掌控你的Steam成就与统计数据
Steam Achievement Manager终极指南:如何完全掌控你的Steam成就与统计数据 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager Steam Achievement …...
)
保姆级教程:在ZYNQ Ultrascale+ MPSOC上配置PS端DP显示(Vitis 2023.1实测)
保姆级教程:ZYNQ Ultrascale MPSOC PS端DP显示全流程实战(Vitis 2023.1版) 当第一次拿到搭载ZYNQ Ultrascale MPSOC的开发板时,验证PS端DisplayPort输出功能往往是硬件加速视觉项目的重要起点。本文将以ALINX AXU2CGA开发板为例&…...

SiameseAOE真实案例:社交媒体评价自动分析全流程
SiameseAOE真实案例:社交媒体评价自动分析全流程 1. 社交媒体评价分析的挑战与解决方案 在当今社交媒体时代,每天都有海量的用户评价产生。以某知名手机品牌为例,其官方账号每天收到上千条评论,内容涵盖产品功能、售后服务、使用…...